- 1Pytorch 0.3 调参指南&optimizer;learning rate;batch_size;Debug大法&数据集;网络;结构;超参;训练;迷人的坑(持续更新中)_从optimizer中读取learningrate
- 2【Pytorch】torchtext终极安装方法及常见问题_torchtext安装
- 3websocke在django中使用_websocket在django中使用教程
- 4Transformer实战
- 5在线学习|基于SpringBoot的在线学习系统的设计与实现_基于spring boot的网络教育平台设计与实现
- 6librosa | 系统实战(五~十七)_librosa.magphase
- 7Linux进度条_linux 进度条
- 8关于海康工业相机连接电脑时出现链接速度低于1Ggps解决办法_当前网络低于1gbps,请检查网络状态 海康
- 9git的常见命令 - 本地merge两个远程分支_git本地merge
- 10android如何查看app数据(无root权限)_手机app数据怎么查看
kibana 操作es文档详细总结_kibana操作es
赞
踩
前言
在上一篇,分享了使用kibana如何对索引进行增删改查等操作,事实上在日常开发与运维中,操作索引毕竟是比较谨慎的事情,但是对于索引中文档的增删查改却是随处可见的,es对文档的操作不仅频繁,而且涉及到的点比较多,本文将分享对文档的基本的操作;
一、给文档添加数据
首先创建一个索引
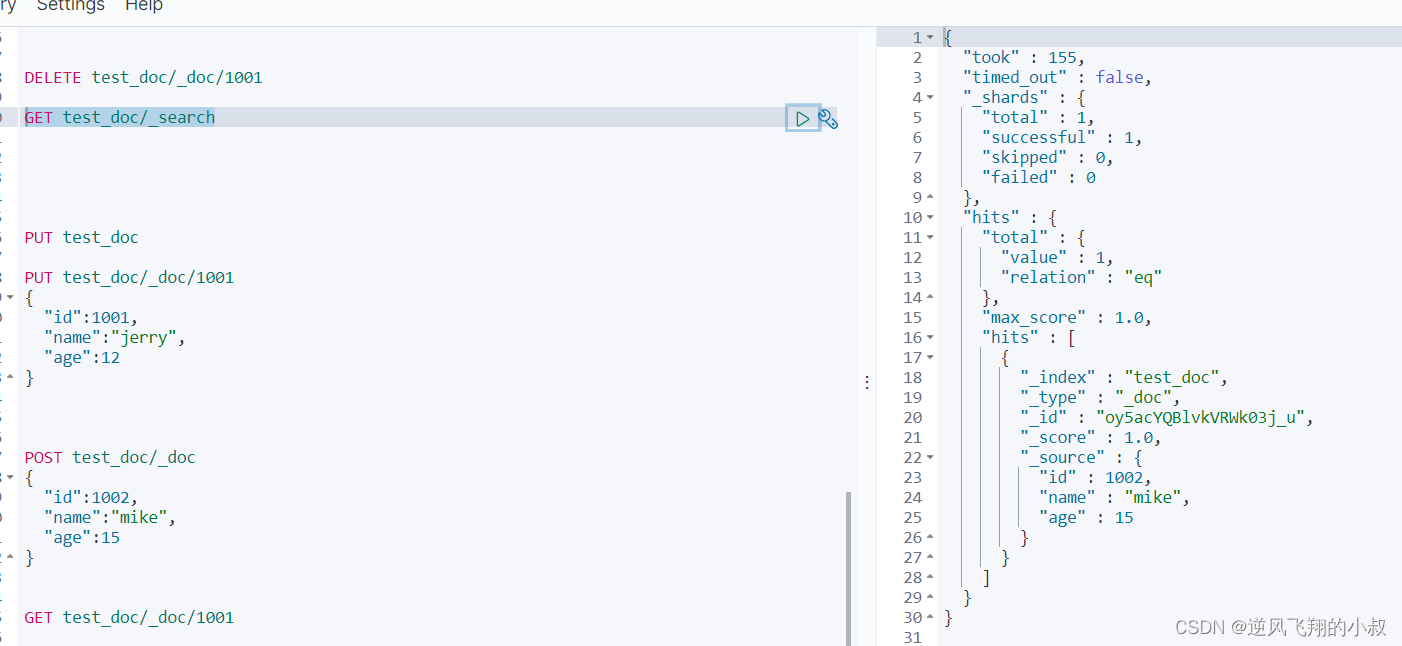
PUT test_doc
使用 put 给文档添加一条数据
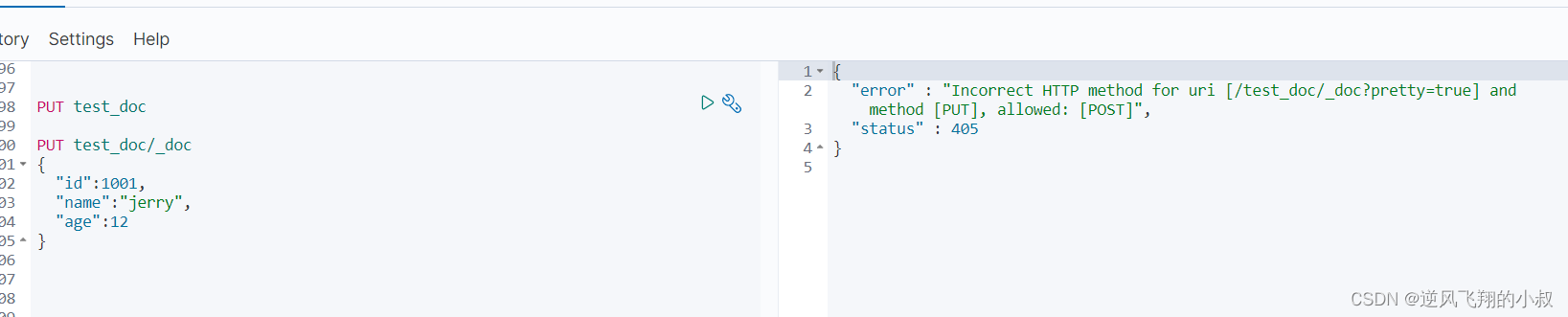
执行上面的语句发现报错了,因为es中的文档数据需要唯一性标识,因此需要添加一个id,修改下执行语句
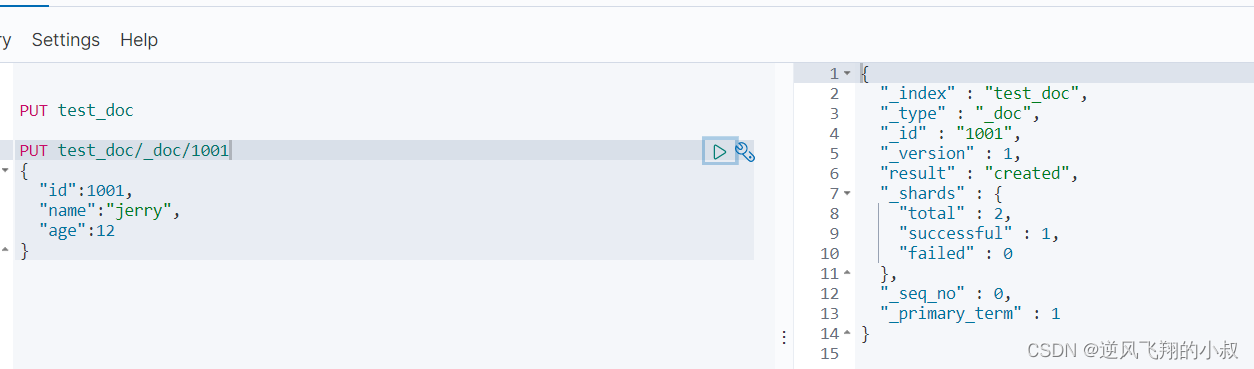
- PUT test_doc/_doc/1001
- {
- "id":1001,
- "name":"jerry",
- "age":12
- }
再次执行后就可以了
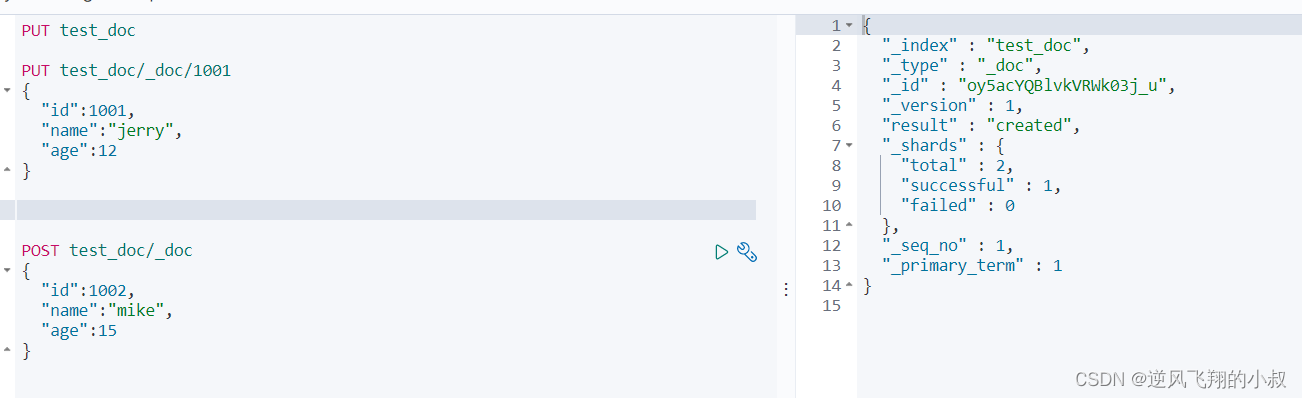
使用 post 给文档添加一条数据
使用post同样可以达到目的,参考下面的语句
- POST test_doc/_doc
- {
- "id":1002,
- "name":"mike",
- "age":15
- }
与put不同的是,post不需要强制在请求URL中添加id值,而是自动为当前这条数据生成一个_id;
二、查询索引文档数据
按照id值进行查询
查询单个数据
GET test_doc/_doc/1001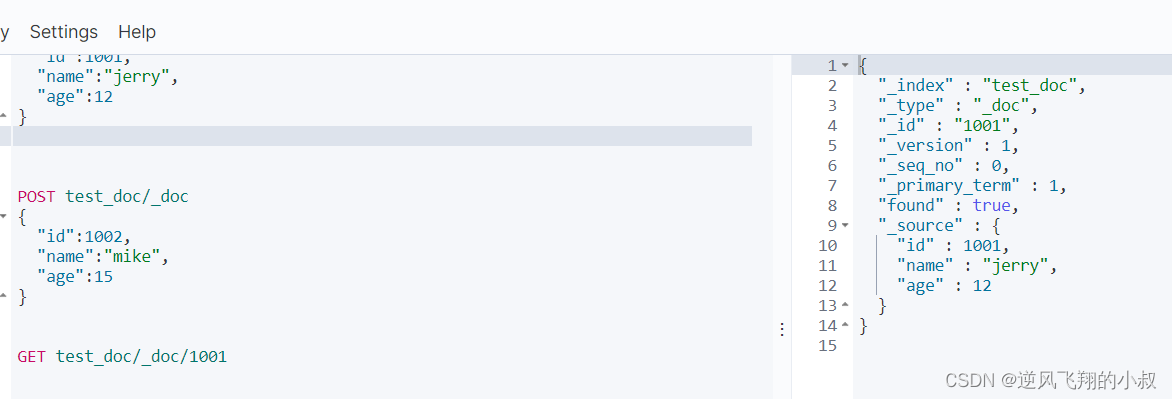
查询索引下所有文档数据
GET test_doc/_search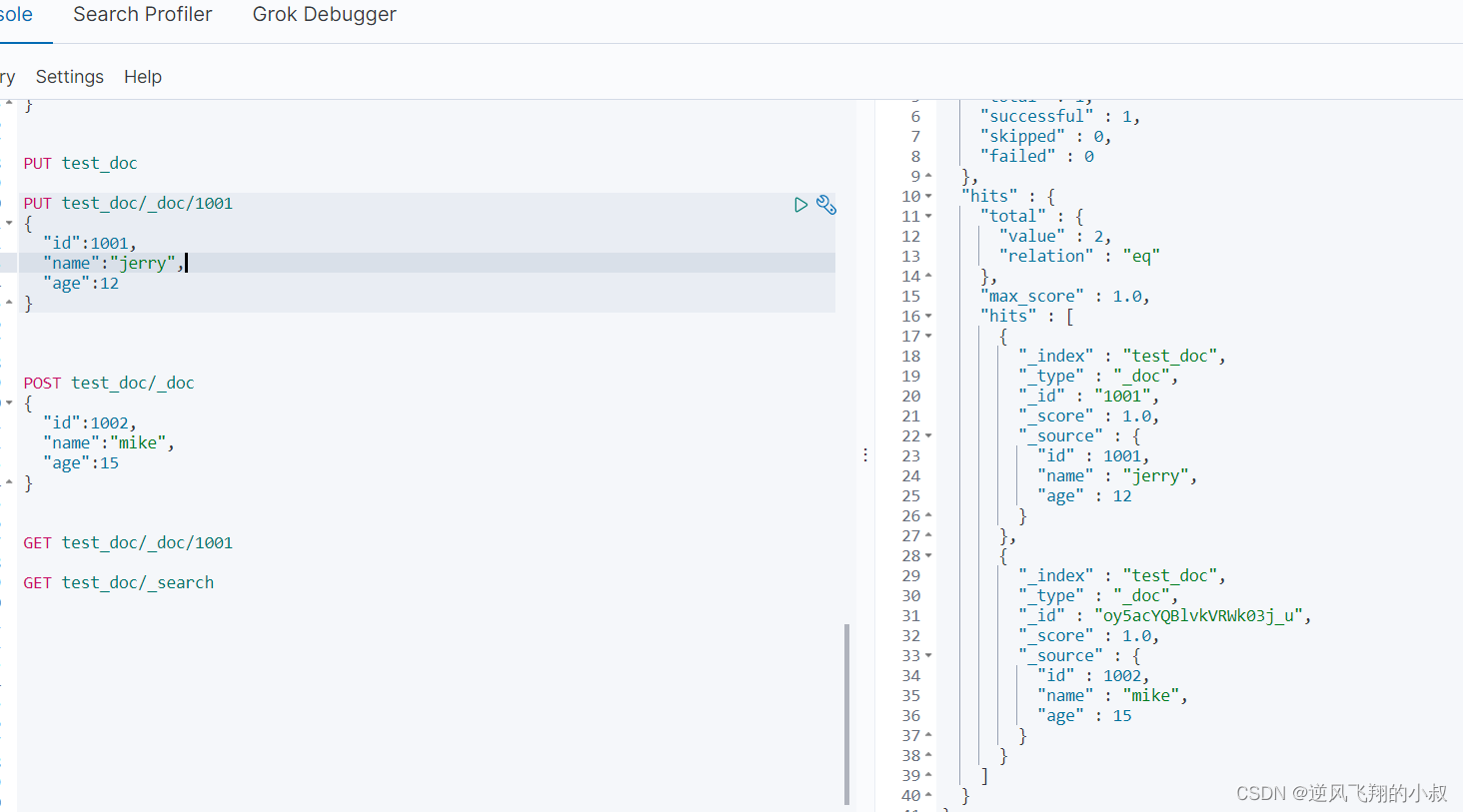
三、修改文档数据
使用put进行修改
根据主键值id进行修改
- PUT test_doc/_doc/1001
- {
- "id":1001,
- "name":"jerry",
- "age":12
- }
可以看到在这种情况下,新增了一个字段仍然可以修改成功
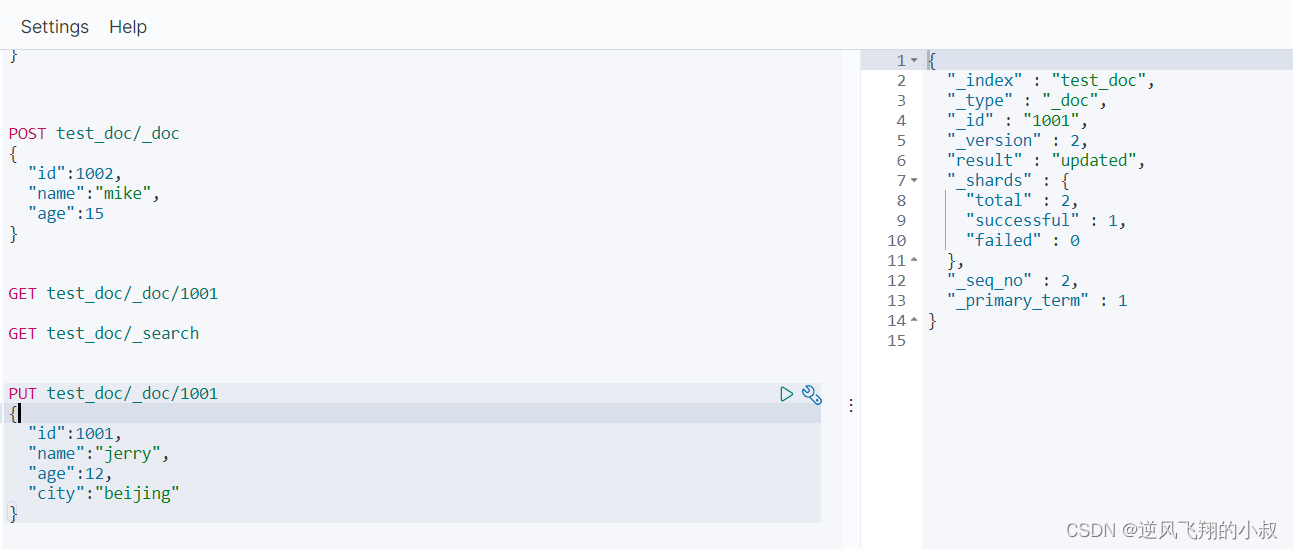
四、删除文档数据
根据主键id值进行删除
DELETE test_doc/_doc/1001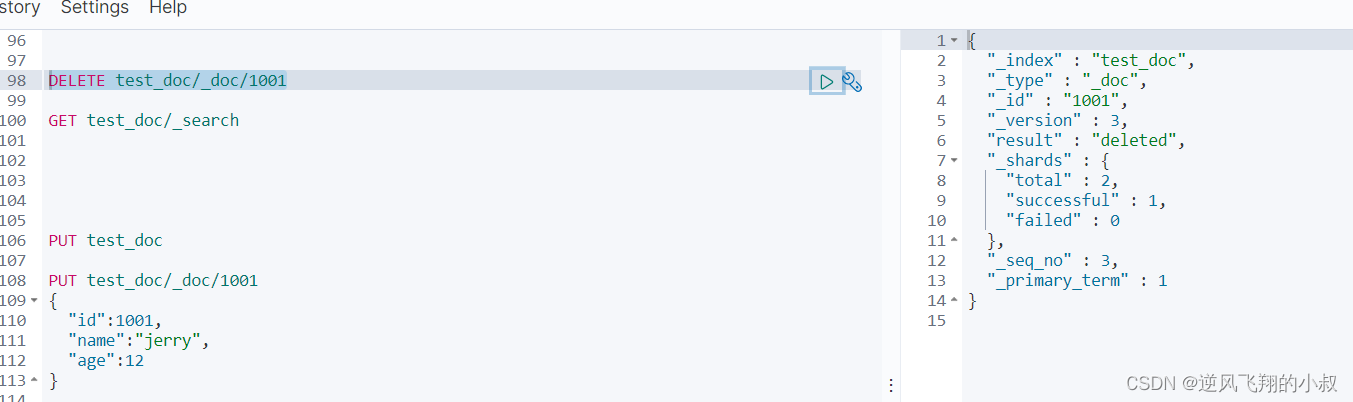
删除后再次查询,数据被删掉了
五、文档搜索
文档搜索是es最强大的功能之一,也是架构设计之初选择es的一个重要原因,es对于文档的搜索提供了丰富的API,下面通过一些实际的操作演示来感受下es文档搜索的强大之处;
前置准备
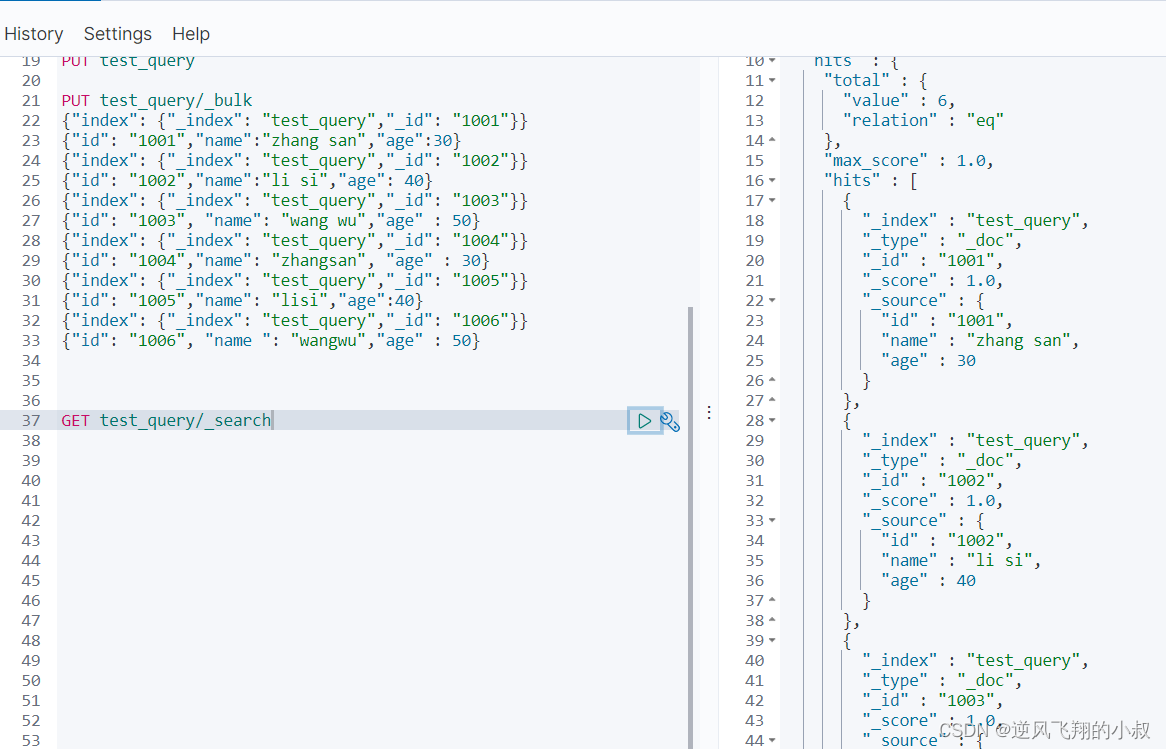
创建一个索引 test_query,并给这个索引下批量插入一些数据
- PUT test_query
-
- PUT test_query/_bulk
- {"index": {"_index": "test_query","_id": "1001"}}
- {"id": "1001","name":"zhang san","age":30}
- {"index": {"_index": "test_query","_id": "1002"}}
- {"id": "1002","name":"li si","age": 40}
- {"index": {"_index": "test_query","_id": "1003"}}
- {"id": "1003", "name": "wang wu","age" : 50}
- {"index": {"_index": "test_query","_id": "1004"}}
- {"id": "1004","name": "zhangsan", "age" : 30}
- {"index": {"_index": "test_query","_id": "1005"}}
- {"id": "1005","name": "lisi","age":40}
- {"index": {"_index": "test_query","_id": "1006"}}
- {"id": "1006", "name ": "wangwu","age" : 50}
单个字段相关查询
1、查询某个索引下的所有数据
GET 索引名称/_search
2、使用match匹配某个字段的关键词
比如name字段中包含 zhangsan 的文档
- GET test_query/_search
- {
- "query": {
- "match": {
- "name": "zhangsan"
- }
- }
- }
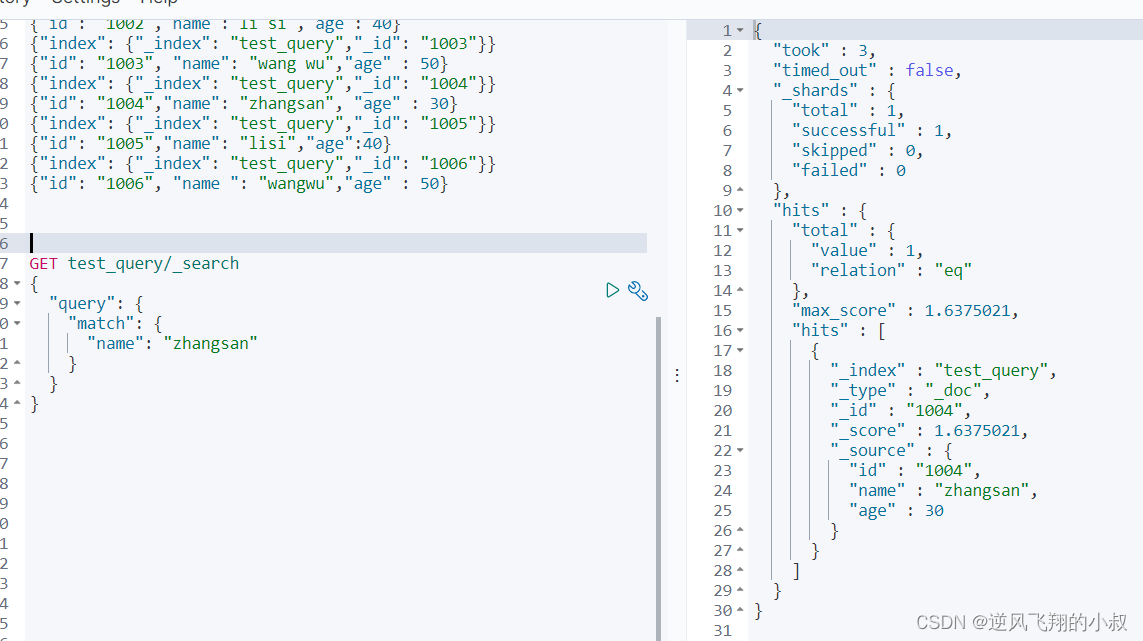
要注意的是,这种方式查询的结果,表示name 中只要包含了zhangsan这个完整的关键词的文档都会查询出来,因为默认情况下,如果我们未对索引中的字段进行属性映射文件的设置的话,es会对字段进行分词处理;
比如我们再增加下面这条数据
- POST test_query/_doc
- {
- "id":"1007",
- "name":"zhang wu",
- "age":37
- }
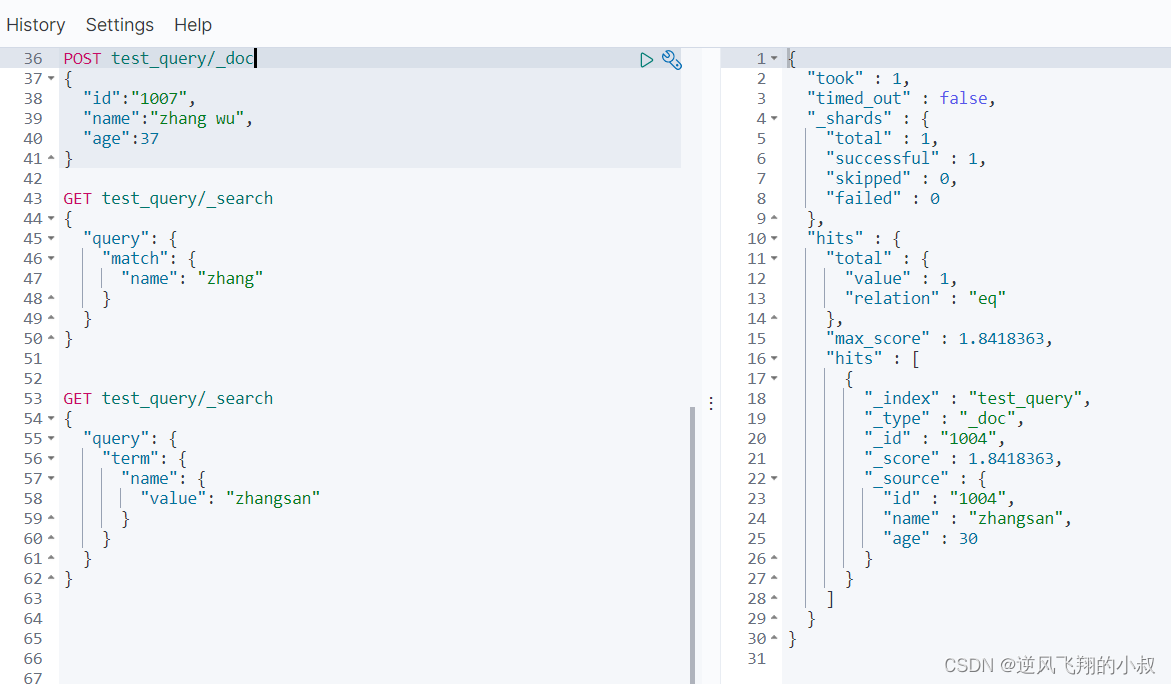
再次使用 zhang 这个关键词进行name字段查询时,可以看到下面的效果,简而言之:使用match查询时会带有分词效果;
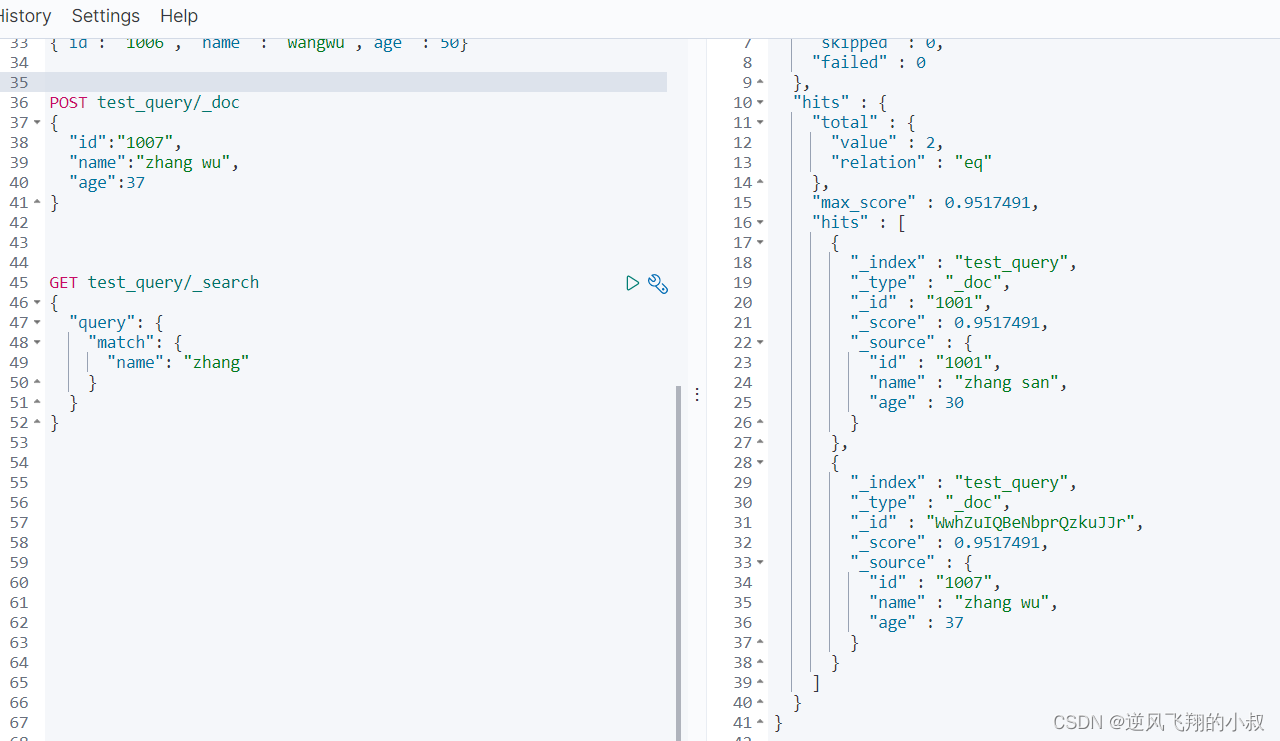
3、使用term精确匹配某个字段的关键词
精准匹配name等于zhangsan这个词的文档,term的效果就像mysql语法中的 where name="XXX"
- GET test_query/_search
- {
- "query": {
- "term": {
- "name": {
- "value": "zhangsan"
- }
- }
- }
- }
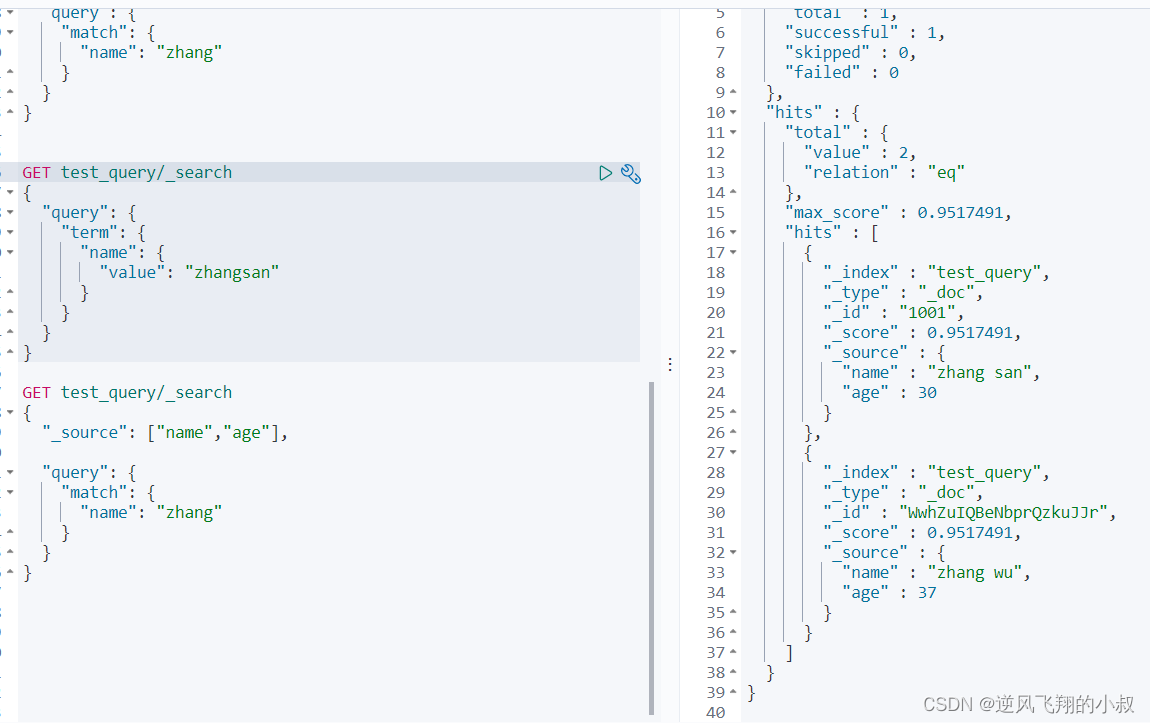
4、查询结果中过滤某些不需要的字段
某些情况下,不需要查询结果中返回所有的字段,就可以通过添加"_source"进行限制
- GET test_query/_search
- {
- "_source": ["name","age"],
-
- "query": {
- "match": {
- "name": "zhang"
- }
- }
- }
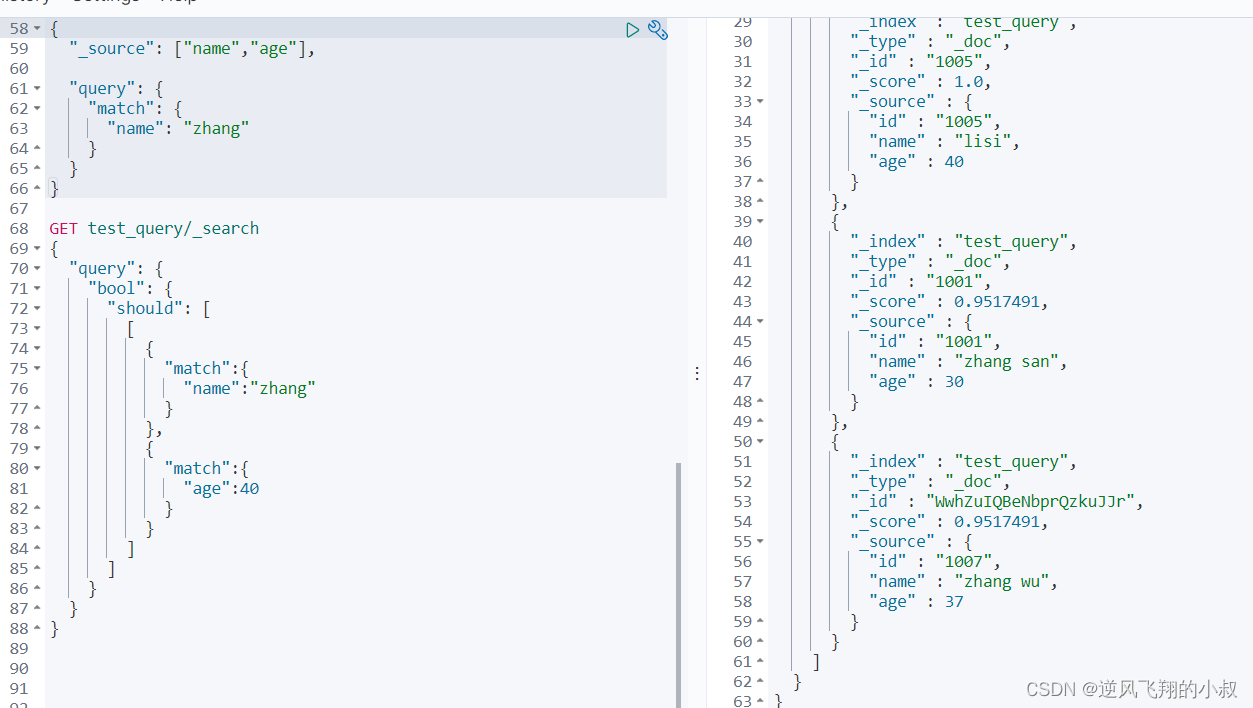
多条件组合查询
组合查询的关键语法是需要在查询条件中使用bool关键字
1、查询name中含有zhang或age为40的数据
这个需求类似于mysql 中的or的语法,在es中使用should可以满足类似的需求
- GET test_query/_search
- {
- "query": {
- "bool": {
- "should": [
- [
- {
- "match":{
- "name":"zhang"
- }
- },
- {
- "match":{
- "age":40
- }
- }
- ]
- ]
- }
- }
- }

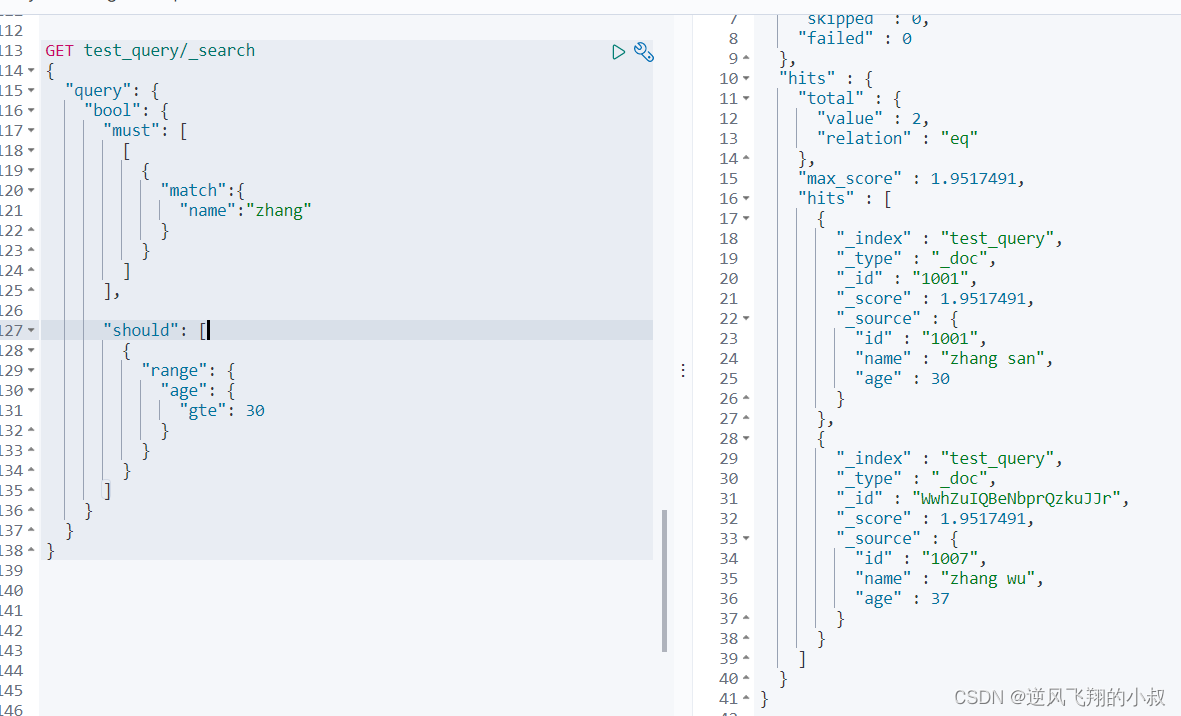
2、查询文档中name中必须含有zhang或者age必须大于等于30岁的数据
组合使用should和must
- GET test_query/_search
- {
- "query": {
- "bool": {
- "must": [
- [
- {
- "match":{
- "name":"zhang"
- }
- }
- ]
- ],
-
- "should": [
- {
- "range": {
- "age": {
- "gte": 30
- }
- }
- }
- ]
- }
- }
- }
查询结果排序
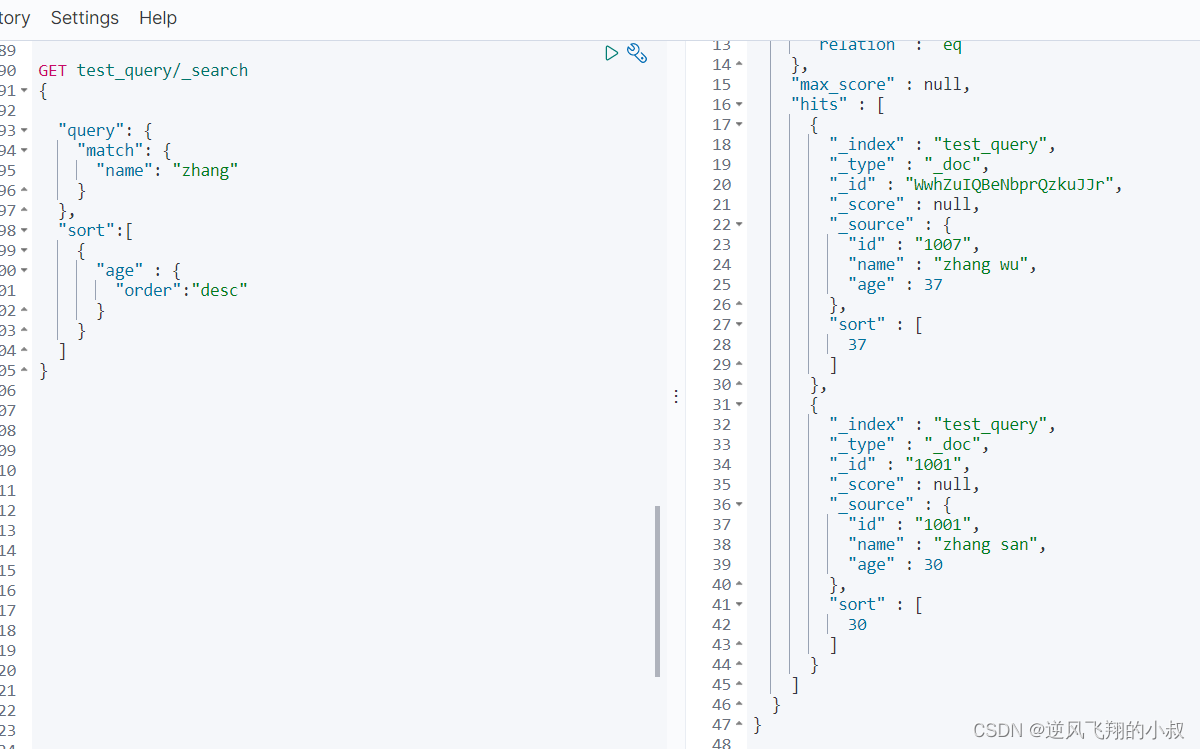
查询name中含有 zhang或li的文档,并按照age排序
- GET test_query/_search
- {
-
- "query": {
- "match": {
- "name": "zhang"
- }
- },
- "sort":[
- {
- "age" : {
- "order":"desc"
- }
- }
- ]
- }
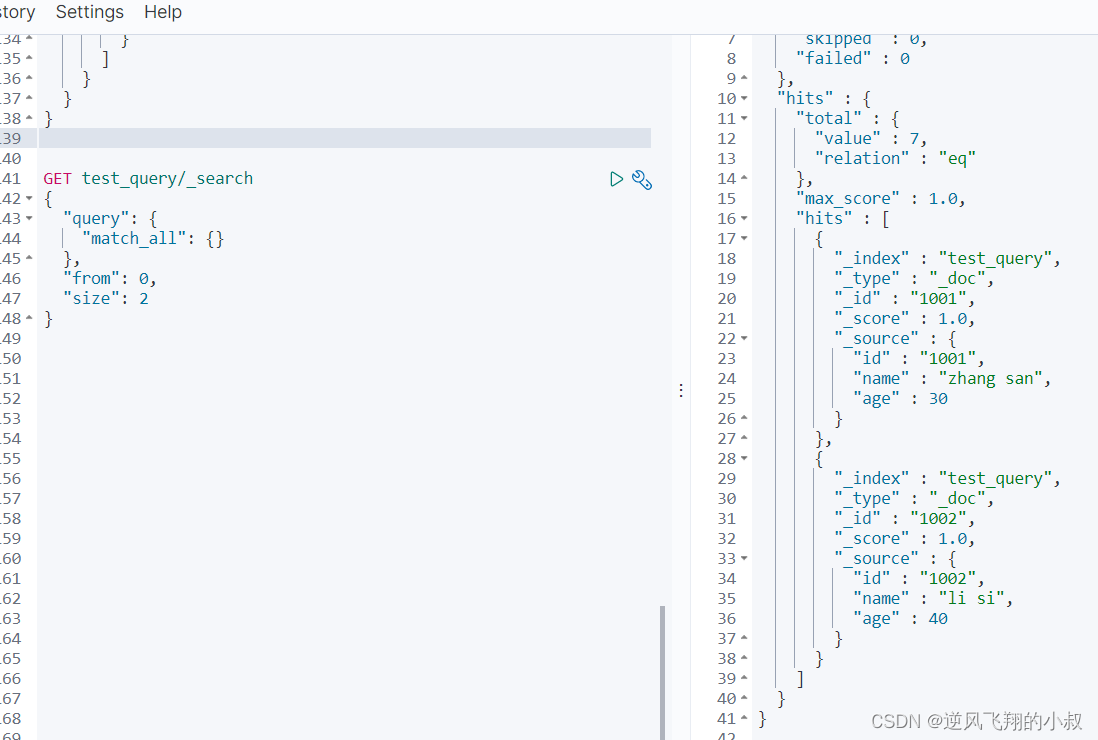
分页查询
语法
GET 索引名称/_search
{
"query": {
"match_all": {}
},
"from": 0, //从第几条开始查询
"size": 2 //每次查询多少数据
}
看下面的查询结果
- GET test_query/_search
- {
- "query": {
- "match_all": {}
- },
- "from": 0,
- "size": 2
- }
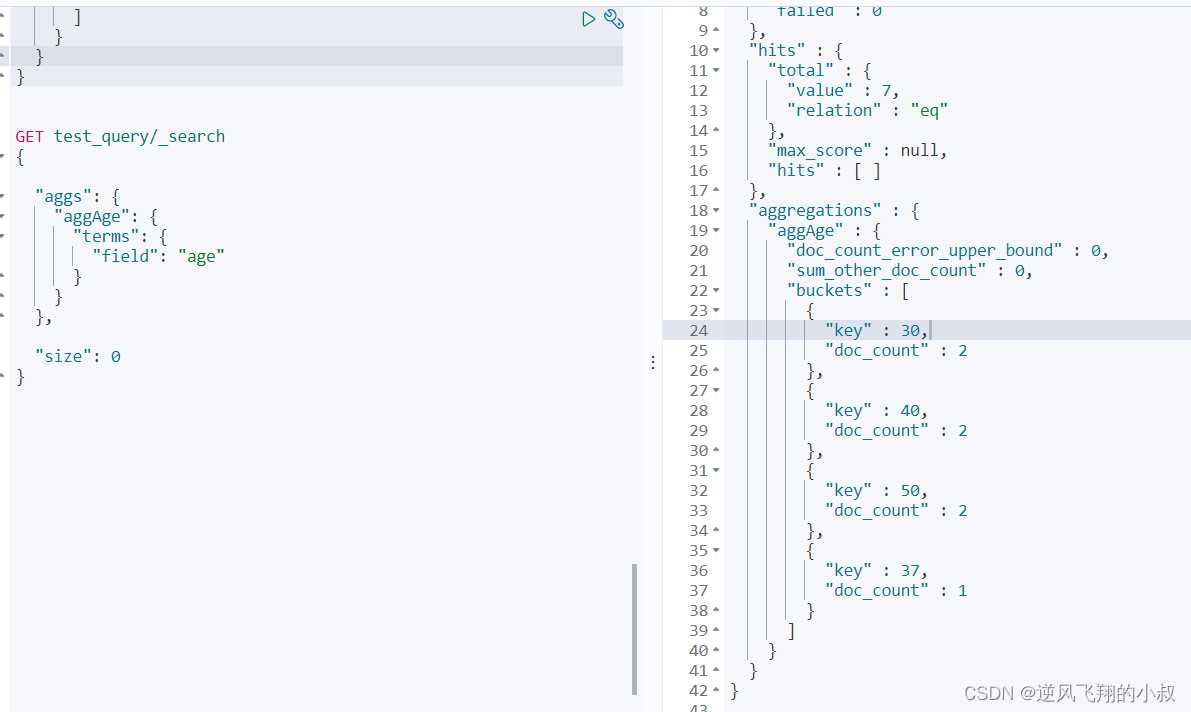
聚合查询
实际业务中,经常会涉及到对查询的结果根据某个或者某些字段进行聚合,类似于mysql中的group by语法;
需求1:根据age将查询结果进行分组聚合
注意点:这里 "size"设置为0表示查询结果中不展示其他非聚合结果的信息;
- GET test_query/_search
- {
-
- "aggs": {
- "aggAge": {
- "terms": {
- "field": "age"
- }
- }
- },
-
- "size": 0
- }
需求2:查询年龄大于等于40岁的,并将结果按照age分组聚合
- GET test_query/_search
- {
-
- "query": {
- "range": {
- "age": {
- "gte": 40
- }
- }
- },
-
- "aggs": {
- "aggAge": {
- "terms": {
- "field": "age"
- }
- }
- },
-
- "size": 0
- }
查询结果如下
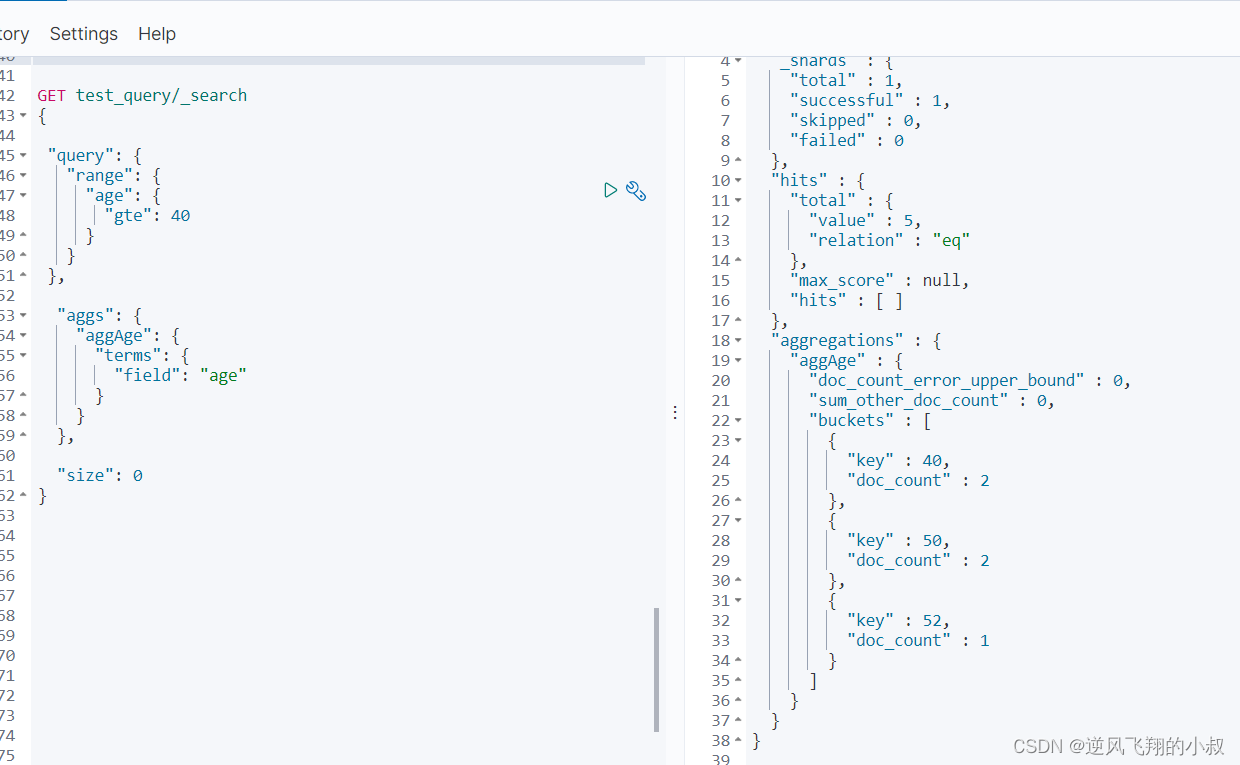
需求3:根据age分组聚合,再对聚合后的结果按照age求平均值
- GET test_query/_search
- {
- "aggs": {
- "ageAgg": {
- "terms": {
- "field": "age"
- },
-
- "aggs": {
- "avgAgg": {
- "avg": {
- "field": "age"
- }
- }
- }
-
- }
- },
- "size": 0
- }
查询结果如下
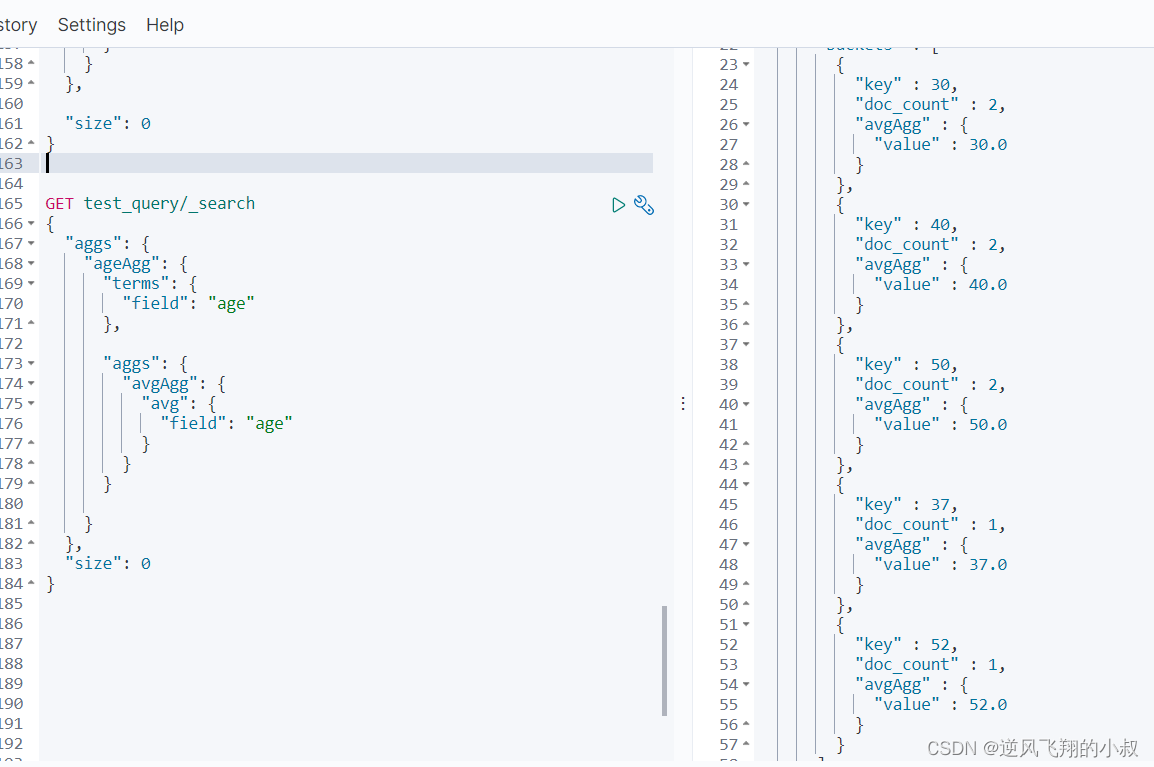
需求4:获取结果集中的前N个数据
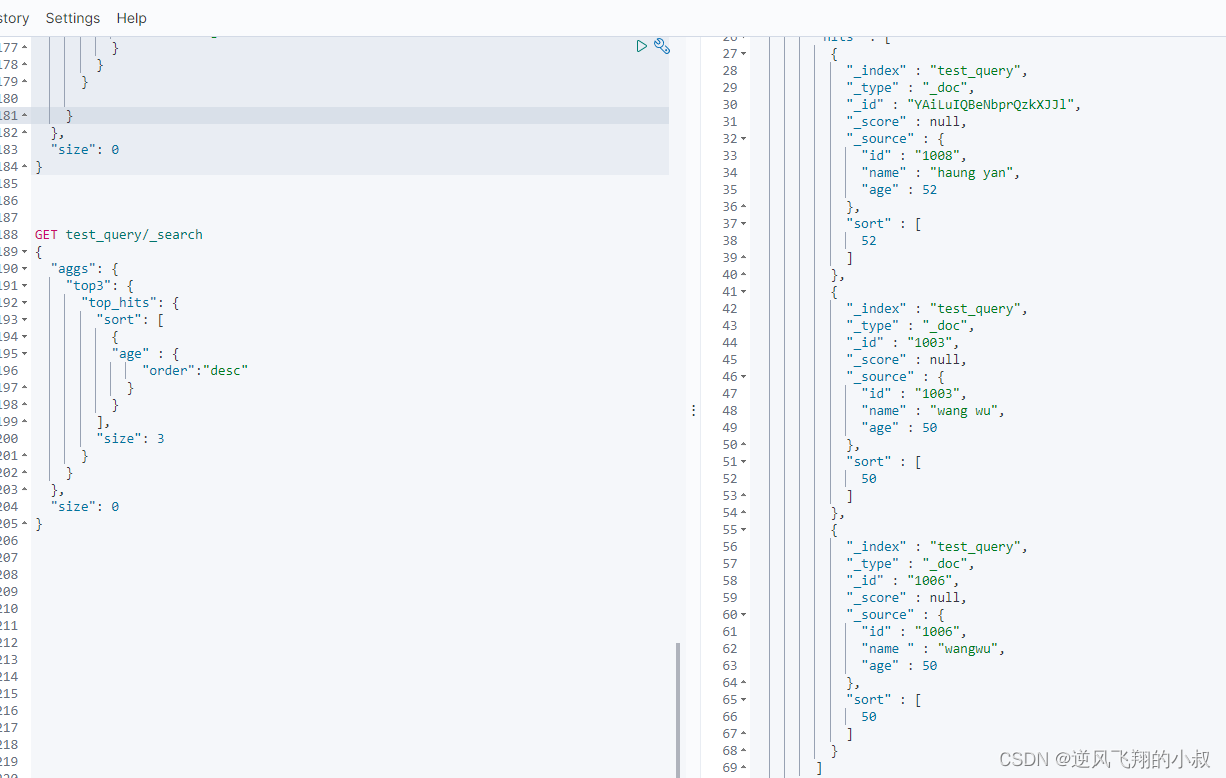
- GET test_query/_search
- {
- "aggs": {
- "top3": {
- "top_hits": {
- "size": 3
- }
- }
- },
- "size": 0
- }
查询结果如下
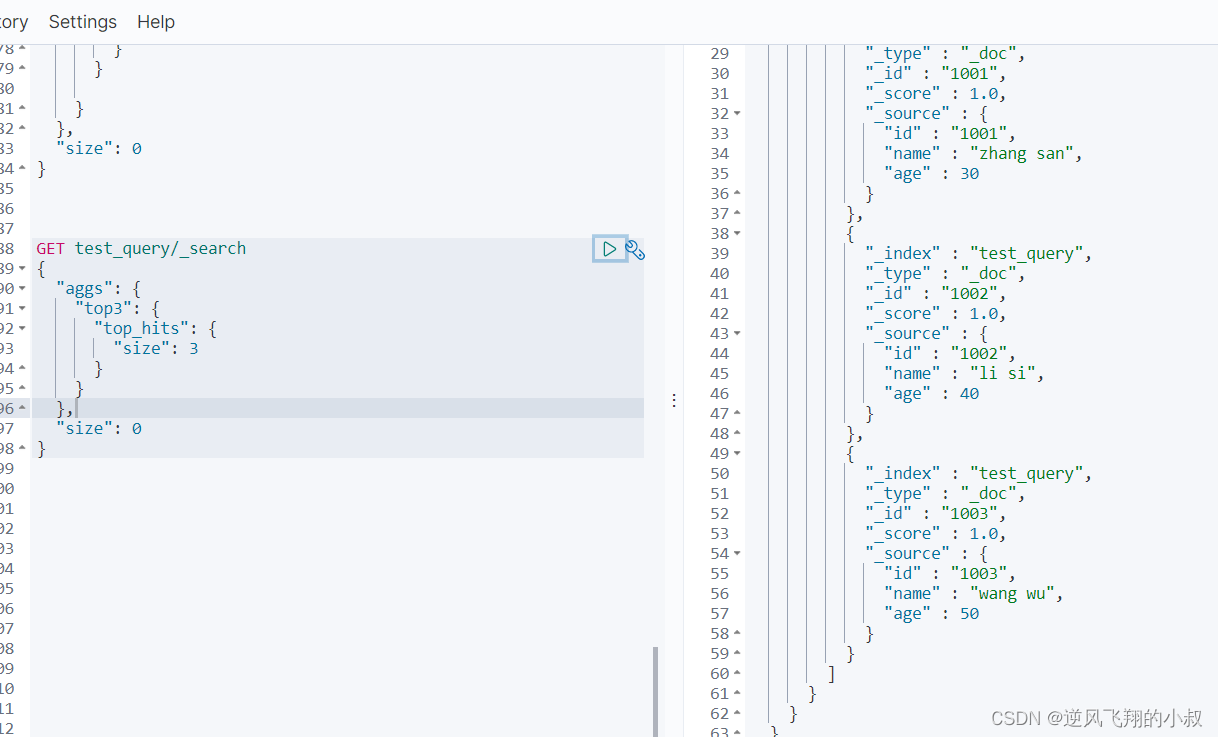
需求5:获取结果集中按照age字段排序后求取前N个数据
- GET test_query/_search
- {
- "aggs": {
- "top3": {
- "top_hits": {
- "sort": [
- {
- "age" : {
- "order":"desc"
- }
- }
- ],
- "size": 3
- }
- }
- },
- "size": 0
- }
查询结果如下