
- 1机器学习之图像识别
- 2html语言中列表的类型有,HTML列表样式有哪些不同类型(Different Types of HTML List Style)?...
- 3自定义view之超级课程表页面的实现_超级课程表页面格式设计
- 4Java API_javaapi
- 5前端中常用的媒体查询详解,sass基础用法概览_sass获取屏幕宽度跟高度比例 media
- 6鸿蒙HarmonyOS开发实战—安全管理(生物特征识别开发)_鸿蒙os人脸识别开发
- 7集群定时任务单点控制解决方案(分布式锁+续期锁解决方案)_excutor分布式锁集群定时任务
- 8动态规划的时间复杂度优化_动态规划 时间复杂度
- 910.一篇文章带你理解及使用CSS(前端邪术-化妆术)
- 10Spring BeanFactory和FactoryBean的区别
Elasticsearch 二、Kibana 操作Elasticsearch,命令操作,数据类型及类型映射_kibana查看字段类型显示confilict
赞
踩
一、简单操作
1、添加索引
###创建索引
PUT /wangsong

2、查询索引
####查询索引
GET /wangsong

3、添加文档(重新添加会覆盖=修改)
####添加文档 /索引名称/类型/id
PUT /wangsong/user/1
{
“name”:“wangsong”,
“sex”:0,
“age”:22
}

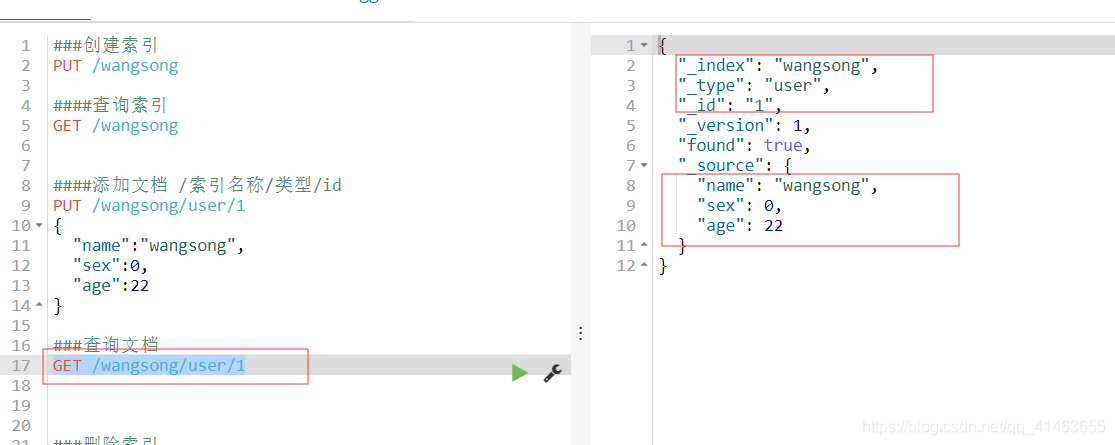
4、查询文档
###查询文档
GET /wangsong/user/1
5、删除索引/文档
###删除索引
DELETE /wangsong

二、高级查询
1、根据id进行查询
GET /mymayikt/user/12
- 1
- 2
2、查询当前所有类型的文档
GET /mymayikt/user/_search
- 1
3、多个ID批量查询
查询多个id分别为1、2
GET /mymayikt/user/_mget
{
"ids":["1","2"]
}
- 1
- 2
- 3
- 4
4、复杂条件查询
查询年龄为年龄21岁
GET /mymayikt/user/_search?q=age:21
- 1
5、区间查询
查询年龄30岁-60岁之间
GET /mymayikt/user/_search?q=age[30 TO 60]
- 1
注意:TO 一定要大写
6、查询条数
查询年龄30岁-60岁之间 并且年龄降序、从0条数据到第1条数据
GET /mymayikt/user/_search?q=age[30 TO 60]&sort=age:desc&from=0&size=1
- 1
7、顺序查询及只返回某些字段
查询年龄30岁-60岁之间 并且年龄降序、从0条数据到第1条数据,展示name和age字段
GET /mymayikt/user/_search?q=age[30 TO 60]&sort=age:desc&from=0&size=1
&_source=name,age
二、DSL语言查询
es中的查询请求有两种方式,一种是简易版的查询,另外一种是使用JSON完整的请求体,叫做结构化查询(DSL)。
由于DSL查询更为直观也更为简易,所以大都使用这种方式。
DSL查询是POST过去一个json,由于post的请求是json格式的,所以存在很多灵活性,也有很多形式。
1、精确查询 term
Term查询不会对字段进行分词查询,会采用精确匹配。
GET mymayikt/user/_search
{
"query": {
"term": {
"name": "xiaoming"
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2、模糊查询 match,及查询条数
Match会根据该字段的分词器,进行分词查询,size查询条数
GET /mymayikt/user/_search
{
"from": 0,
"size": 2,
"query": {
"match": {
"car": "奥迪"
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3、filter过滤查询
过滤age 大于21 小于 51的
size 条数
_source 只返回那些字段
GET /mymayikt/user/_search { "query": { "bool": { "must": [{ "match_all": {} }], "filter": { "range": { "age": { "gt": 21, "lte": 51 } } } } }, "from": 0, "size": 10, "_source": ["name", "age"] }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
三、字段类型及字段映射
文档映射就是给文档中的字段指定字段类型、分词器
ElasticSearch中的映射(Mapping)用来定义一个文档,可以定义所包含的字段以及字段的类型、分词器及属性等等。
1、动态映射(创建文档会动态映射,数字默认long)
我们知道,在关系数据库中,需要事先创建数据库,然后在该数据库实例下创建数据表,然后才能在该数据表中插入数据。而ElasticSearch中不需要事先定义映射(Mapping),文档写入ElasticSearch时,会根据文档字段自动识别类型,这种机制称之为动态映射。
2、静态映射
在ElasticSearch中也可以事先定义好映射,包含文档的各个字段及其类型等,这种方式称之为静态映射。
3、数据类型-基本类型
字符串 text 和 keyword。 Text类型可以分词查询,keyword类型不能分词
数指型:long、integer、short、byte、double、float
日期型:date
布尔型:boolean
二进制型:binary
数组类型(Array datatype)

text 字符串说明:该类型被用来索引长文本,在创建索引前会将这些文本进行分词,转化为词的组合,建立索引;允许es来检索这些词,text类型不能用来排序和聚合。
keyword 字符串说明:该类型不需要进行分词,可以被用来检索过滤、排序和聚合,keyword类型自读那只能用本身来进行检索(不可用text分词后的模糊检索)。
4、数据类型-复杂类型
地理位置类型(Geo datatypes)
地理坐标类型(Geo-point datatype):geo_point 用于经纬度坐标
地理形状类型(Geo-Shape datatype):geo_shape 用于类似于多边形的复杂形状
5、数据类型-特定类型(Specialised datatypes)
Pv4 类型(IPv4 datatype):ip 用于IPv4 地址
Completion 类型(Completion datatype):completion 提供自动补全建议
Token count 类型(Token count datatype):token_count 用于统计做子标记的字段的index数目,该值会一直增加,不会因为过滤条件而减少
mapper-murmur3 类型:通过插件,可以通过_murmur3_来计算index的哈希值
6、数据类型-附加类型(Attachment datatype)
采用mapper-attachments插件,可支持_attachments_索引,例如 Microsoft office 格式,Open Documnet 格式, ePub,HTML等
7、创建文档类型并且指定类型
POST /mymayikt/_mapping/user { "user":{ "properties":{ "age":{ "type":"integer" }, "sex":{ "type":"integer" }, "name":{ "type":"text", "analyzer":"ik_smart", "search_analyzer":"ik_smart" }, "car":{ "type":"keyword" } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
查看数据类型–> 请求地址/索引/_settings
http://192.168.212.181:9200/mymayikt/_settings

