
吉娃娃or松饼难题被解决!IDEA研究院新模型打通文本视觉Prompt,连黑客帝国的子弹都能数清楚...
赞
踩
白交 发自 凹非寺
量子位 | 公众号 QbitAI
还记得黑客帝国经典的子弹时间吗?
IDEA研究院最新检测模型T-Rex2,可以齐刷刷给全部识别出来~

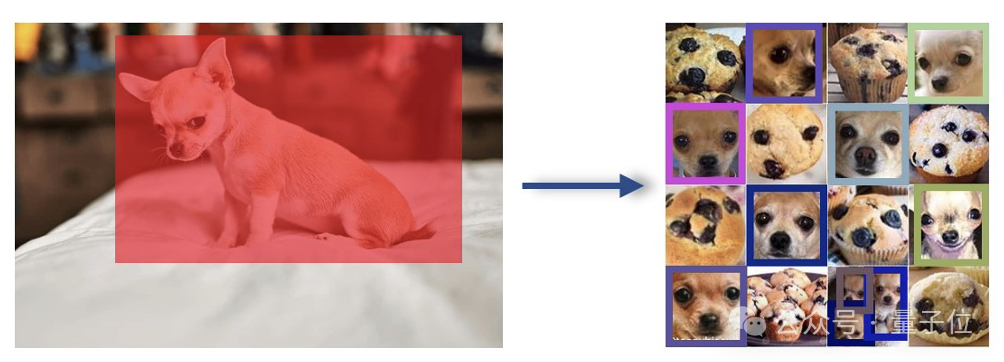
而面对难倒一众大模型「吉娃娃or松饼」的难题,它只需被投喂一张吉娃娃的照片,就能瞬间迎刃而解。
此前,也是同样的团队,推出了基于视觉提示的检测模型T-Rex。
如今,他们将视觉和文本提示融合,相互弥补各自的缺陷,实现了更强的目标检测能力。
并且与多目标跟踪模型结合后,各种视频检测任务也不在话下。

来看新研究到底说了什么。
打通文本和视觉提示
在开集目标检测领域,尽管文本提示受到一定的青睐,但也存在一定的局限性。
比如长尾数据短缺。稀有或者全新的物体类别的数据稀缺可能会削弱其学习效率。还有描述上的局限性,对于一些难以用语言描绘的对象,因受限于无法精确描述,也会削弱效果。
而视觉提示提供了更直观且直接的对象表示方法,但在捕捉常见对象的概念时效果就会很差。
T-Rex2通过对比学习在单个模型中整合两种提示,因此接受多种格式的输入,包括文本提示、视觉提示以及两者的组合。
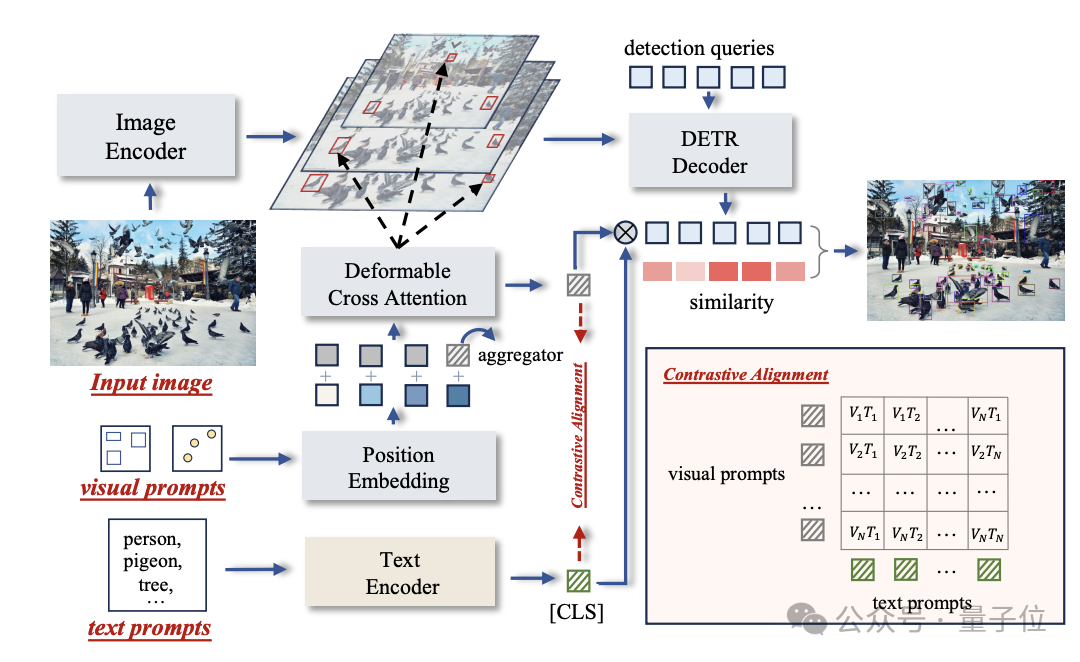
在不同场景中,它可以通过在两种提示方式之间切换来处理。
因此,它大致有三种工作模式:
文本提示模式、交互式视觉提示模式、通用视觉提示模式。

以通用视觉提示模式为例,用户可以通过向模型提供任意数量的示例图片,来自定义特定对象的视觉嵌入,然后使用这个嵌入来检测任意图像中的对象。
也就是不需要用户与模型直接互动,就能完成检测任务。
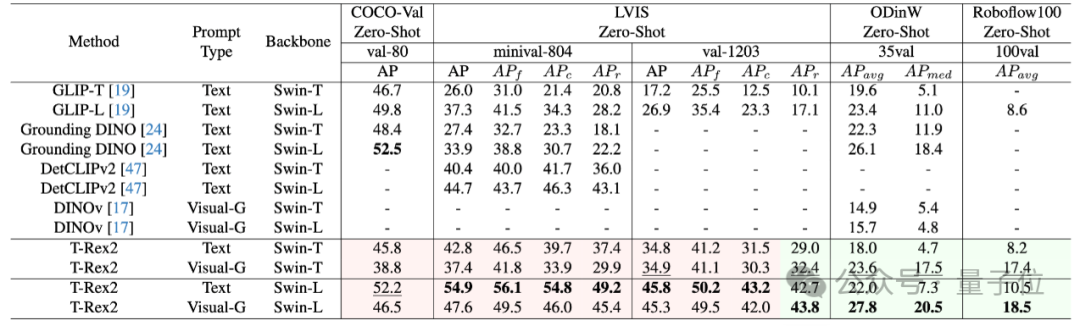
最终在在四个学术基准测试集 COCO, LVIS, ODinW, 和Roboflow100 上取得了 Zero-Shot SOTA的性能。
开箱即用诸多领域
无需重新训练或微调,T-Rex2即可检测模型在训练阶段从未见过的物体。
该模型不仅可应用于包括计数在内的所有检测类任务,还为智能交互标注领域提供新的解决方案。

除此之外,结合现有的多目标跟踪模型( 如ByteTrack ),T-Rex2还可用于视频检测任务。

事实上,这种跨图检测能力,让目标检测技术在生产生活中可以真正开始广泛应用。
比如工业生产流水线器件检测,交通航运领域的船舶、飞机检测,农业领域的农作物、果蔬检测,生物医学领域的细胞、组织检测,物流领域的货物检测,环境领域的野生动物监测等。
现在,T-Rex2让通用物体检测又迈出了新的一步。
试玩链接:
https://deepdataspace.com/playground/ivp
T-Rex2 API:https://github.com/IDEA-Research/T-Rex
论文链接:
https://arxiv.org/abs/2403.14610
— 完 —
评选报名即将截止!
2024年值得关注的AIGC企业&产品
量子位正在评选2024年最值得关注的AIGC企业、 2024年最值得期待的AIGC产品两类奖项,欢迎报名评选!评选报名 截至2024年3月31日 

中国AIGC产业峰会「你好,新应用!」已开启报名!点击报名参会 同时,峰会将进行线上直播 ⬇️
点这里


Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

