
- 1炼气期第一式:JUC进阶式学习_总线风暴
- 2根据《机器学习》(周志华)第五章内容,用Python实现标准BP算法_周志华 机器学习bp算法python实现
- 3NLP:自然语言处理常用任务简介(七大任务/两大层次(顶层5种+底层4种)/LLMs四大类)、GLUE基准(通用语言理解评估,四类九个)和SuperGLUE基准的简介(国内系列/国际系列)使用方法之详_glue 以及 superglue 是什么
- 4面向Java开发者的ChatGPT提示词工程(3)GPT自我检查、尽量少的提示词_java chatgpt prompt
- 5Python-基于长短期记忆网络(LSTM)的SP500的股票价格预测 股价预测 Python数据分析实战 数据可视化 时序数据预测 变种RNN 股票预测_python数据分析实战-基于长短期记忆网络(lstm)的sp500的股票价格预测 股价预测
- 6基于Python爬虫智联招聘甘肃省招聘信息可视化和推荐查询系统设计与实现(Django框架) 研究背景与意义、国内外研究现状_基于python爬取招聘岗位数据信息国内外研究现状
- 7医学图像处理SCI期刊介绍_医学图像处理的sci四区期刊有哪些
- 8NLP(六十二)HuggingFace中的Datasets使用_huggingface数据集
- 9[嵌入式AI从0开始到入土]13_orangepi aipro开箱测评_昇腾 orangepi
- 10Linux的修仙之路——安装和基本命令_显示当前目录下的文件和目录列表,复制test目录为testbak目录作为备份。
Vision Transformer原理
赞
踩
ViT(Vision Transformer)解析 - 知乎
Vision Transformer模型

ViT将Transformer结构完全替代卷积结构完成分类任务,并在超大规模数集上取得了超越CNN的效果。它首先将输入图像裁剪为固定尺寸的图像块,并对其进行线性映射后加入位置编码,输入到标准的Transformer编码器。为了实现分类任务,在图像块的嵌入序列中增加一个额外的可学习的类别字符(Class token)。
模型由三个模块组成:
1.Linear Projection of Flattened Patches(Embedding层)
2.Transformer Encoder
3.MLP Head(最终用于分类的层结构)
ViT步骤
按照上面的流程图,一个ViT block可以分为以下几个步骤
(1) patch embedding:例如输入图片大小为224x224,将图片分为固定大小的patch,patch大小为16x16,则每张图像会生成224x224/16x16=196个patch,即输入序列长度为196,每个patch维度16x16x3=768,线性投射层的维度为768xN (N=768),因此输入通过线性投射层之后的维度依然为196x768,即一共有196个token,每个token的维度是768。
这里还需要加上一个特殊字符cls,因此最终的维度是197x768。到目前为止,已经通过patch embedding将一个视觉问题转化为了一个seq2seq问题
(2) positional encoding(standard learnable 1D position embeddings):ViT同样需要加入位置编码,位置编码可以理解为一张表,表一共有N行,N的大小和输入序列长度相同,每一行代表一个向量,向量的维度和输入序列embedding的维度相同(768)。注意位置编码的操作是sum,而不是concat。加入位置编码信息之后,维度依然是197x768
(3) LN/multi-head attention/LN:LN输出维度依然是197x768。多头自注意力时,先将输入映射到q,k,v,如果只有一个头,qkv的维度都是197x768,如果有12个头(768/12=64),则qkv的维度是197x64,一共有12组qkv,最后再将12组qkv的输出拼接起来,输出维度是197x768,然后在过一层LN,维度依然是197x768
(4) MLP:将维度放大再缩小回去,197x768放大为197x3072,再缩小变为197x768
一个block之后维度依然和输入相同,都是197x768,因此可以堆叠多个block。最后会将特殊字符cls对应的输出z0 作为encoder的最终输出 ,代表最终的image presentation(另一种做法是不加cls字符,对所有的tokens的输出做一个平均),如下图公式(4),后面接一个MLP进行图片分类

Class Token
假设我们将原始图像切分成共9个小图像块,最终的输入序列长度却是10,也就是说我们这里人为的增加了一个向量进行输入,我们通常将人为增加的这个向量称为 Class Token。那么这个 Class Token 有什么作用呢?
我们可以想象,如果没有这个向量,也就是将9个向量(1~9)输入 Transformer 结构中进行编码,我们最终会得到9个编码向量,可对于图像分类任务而言,我们应该选择哪个输出向量进行后续分类呢?
因此,ViT算法提出了一个可学习的嵌入向量 Class Token( 向量0),将它与9个向量一起输入到 Transformer 结构中,输出10个编码向量,然后用这个 Class Token 进行分类预测即可。
类似于BERT中的[class] token,ViT引入了class token机制,其目的:因为transformer输入为一系列的patch embedding,输出也是同样长的序列patch feature,但是最后要总结为一个类别的判断,简单方法可以用avg pool,把所有的patch feature都考虑算出image feature。
但是作者没有用这种方式,而是引入一个类似flag的class token,其输出特征加上一个线性分类器就可以实现分类。
关于image presentation
是否可以直接使用average pooling得到最终的image presentation,而不加特殊字符cls,通过实验表明,同样可以使用average pooling,原文ViT是为了尽可能是模型结构接近原始的Transformer,所以采用了类似于BERT的做法,加入特殊字符

学习率的影响较大,注意调参
positional encoding
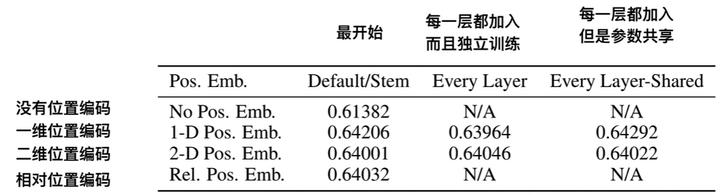
1-D 位置编码:例如3x3共9个patch,patch编码为1到9
2-D 位置编码:patch编码为11,12,13,21,22,23,31,32,33,即同时考虑X和Y轴的信息,每个轴的编码维度是D/2
实际实验结果表明,不管使用哪种位置编码方式,模型的精度都很接近,甚至不适用位置编码,模型的性能损失也没有特别大。原因可能是ViT是作用在image patch上的,而不是image pixel,对网络来说这些patch之间的相对位置信息很容易理解,所以使用什么方式的位置编码影像都不大
关于CNN+Transformer
既然CNN具有归纳偏置的特性,Transformer又具有很强全局归纳建模能力,使用CNN+Transformer的混合模型是不是可以得到更好的效果呢?将224x224图片送入CNN得到16x16的特征图,拉成一个向量,长度为196,后续操作和ViT相同
关于输入图片大小
通常在一个很大的数据集上预训练ViT,然后在下游任务相对小的数据集上微调,已有研究表明在分辨率更高的图片上微调比在在分辨率更低的图片上预训练效果更好(It is often beneficial to fine-tune at higher resolution than pre-training)(参考2019-NIPS-Fixing the train test resolution discrepancy)
当输入图片分辨率发生变化,输入序列的长度也发生变化,虽然ViT可以处理任意长度的序列,但是预训练好的位置编码无法再使用(例如原来是3x3,一种9个patch,每个patch的位置编码都是有明确意义的,如果patch数量变多,位置信息就会发生变化),一种做法是使用插值算法,扩大位置编码表。但是如果序列长度变化过大,插值操作会损失模型性能,这是ViT在微调时的一种局限性

