- 1做软件测试,就得去大厂!
- 2Rasa中文聊天机器人开发指南(2):NLU篇_rasa中文文档
- 3《基于音频和文本的多模态语音情感识别的TensorFlow实现》的项目(写的很人性化的哦!)_基于tensorflow的语音情绪分析与运用的研究意义
- 4B端界面设计:页面分类设计_页面结构设计,功能划分
- 5介绍一下gpt模型的原理_gpt原理
- 6芒果YOLOv8改进10:特征融合Neck篇:改进特征融合网络 BiFPN 结构,融合更多有效特征_concat_bifpn yolov8
- 7深入解析《企业级数据架构》:HDFS、Yarn、Hive、HBase与Spark的核心应用_数据仓库 hive hdfs
- 8ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices论文学习
- 9mxnet学习笔记(二)——训练器Trainer()函数详解_gluon.trainer
- 10可视化模型:深度学习中的 Grad-CAM 指南_gcn grad-cam
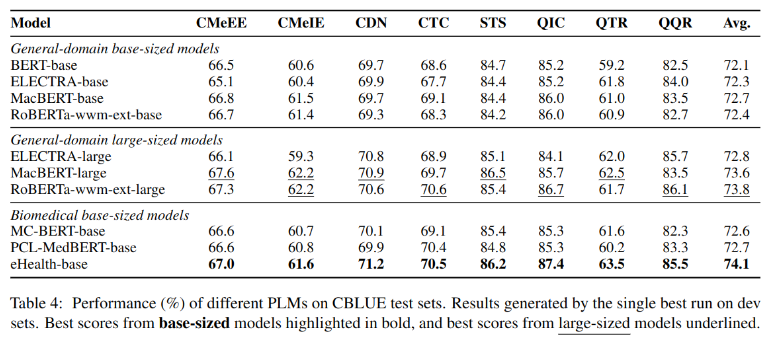
论文阅读_中文医疗模型_ eHealth_医疗数据模型
赞
踩
英文题目:Building Chinese Biomedical Language Models via Multi-Level Text Discrimination
中文题目:基于多层次文本辨析构建中文生物医学语言模型
论文地址:https://arxiv.org/pdf/2110.07244.pdf
领域:自然语言处理,生物医学
发表时间:2021
作者:Quan Wang等,百度
模型下载:https://huggingface.co/nghuyong/ernie-health-zh
模型介绍:https://github.com/PaddlePaddle/Research/tree/master/KG/eHealth
模型代码:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-health
阅读时间:22.06.25
读后感
目前效果最好的生物医学预训练模型,在 CBLUE 比赛数据上亲测真的有明显提升。
介绍
之前生物医疗领域的预训练模型只是使用专门的数据训练,且大多是英文模型,垂直领域的模型常在通用模型的基础上训练,也有一些实验证明,直接用领域数据训练效果更好。
PCL-MedBERT 和 MC-BERT 是中文的医疗领域模型,但它在医学和通用领域使用的效果不是很明显; SMedBERT 和 EMBERT 利用领域知识提升模型效果,但它引入了外部知识,而用到的知识图尚未公开(译者注:SMedBERT 提供模型下载)。
本篇论文提出了eHealth中文语言表示模型,它基于大量生物医疗数据预训练,且修改了模型框架。它基于eHealth模型,包含生成和判别两部分。并在 ELECTRA 的基础上把判别模型又细分为 token 层面和 sequence 层面。eHealth不依赖外部资源,因此,精调模型也比较方便。
它在CBLUE的11项医学NLP任务中效果优于以往的预训练模型,仅用正常的模型大小(非大模型),就在医学和通用领域达到很好效果,甚至超过了大模型。
文章主要贡献如下:
- 建立了中文医学预训练模型,它只依赖文本本身,方便精调。
- 提出了预训练的新方法,可将其迁移到医学以外的其它领域中。
方法
对抗模型包括一般生成器和判别器两部分,其主要原理是:生成器尽量生成更贴近真实的数据,而判别器尽量把生成的假文本判别出来,通过对抗快速改进。
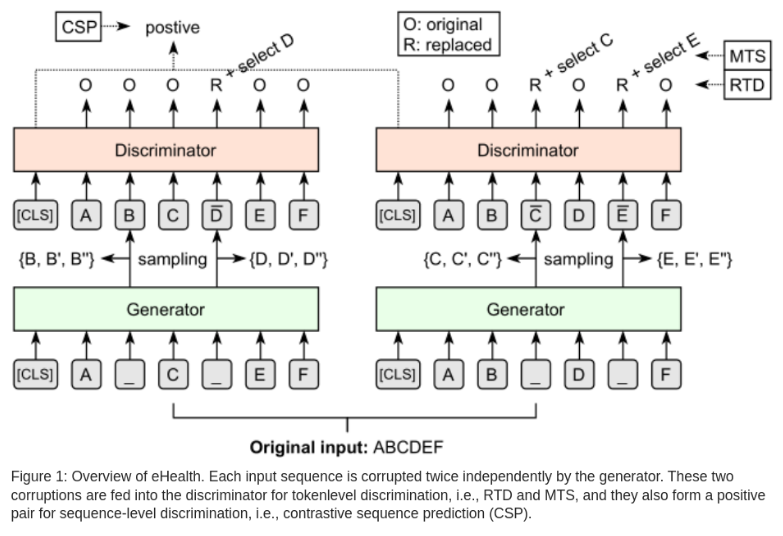
生成器
文中的生成器G是一个 Transforer 编码器,使用MLM方式训练,对于输入文本x=[x1,…,xn],遮蔽其中部分单词,生成xM,然后将其送入编码器生成隐藏层表示hG(xM),再将隐藏表示送入一个softmax来预测每个token的是否为遮蔽后的词:

共中xt指的是第t位置的token,hg(xM)是结合了上下文后对t位置的表示,e是词嵌入,V是包含所有token的词表。损失函数计算方法如下:
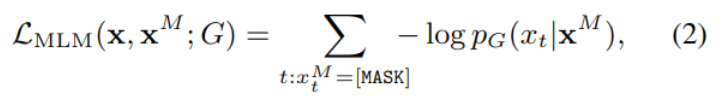
这里只关注真正被遮蔽的token,损失函数的目标是生成最能以假乱真的篡改文本。生成器生成的数据被送入判别器处理。
判别器
判别器D也是最终的编码器,也使用Transformer结构,它的输入是由生成模型篡改过的字符串,训练两层判别器。
Token级判别
Token级别判别器又分为两种,一种是token替换 RTD,另一种是 token 选择 MTS。RTD是在 ELECTRA 中提出的,它用于识别句中被篡改的token,MTS是2020年Xu等提出的,它的目标是从给定的选项中选择被篡改处的原始文本应该是什么。
RTD
设生成篡改后的文本为xR,RTD用于辨别其中的每个token是否被篡改。将模型生成的隐藏层hD(xR)代入二分类sigmoid层,输出每个位置t的token被篡改的概率:
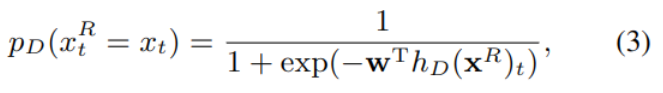
对应的损失函数如下,它对每个位置的结果加和。
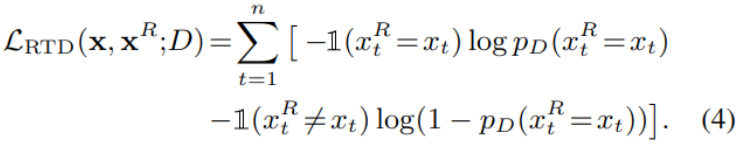
MTS
MTS可作为对RTD的强化,进一步判别被篡改位置的原始文本应该是什么,从候选项中选出该位置最可能是哪一个token。
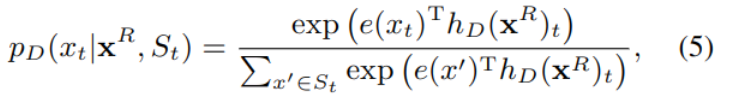
对应的损失函数如下:
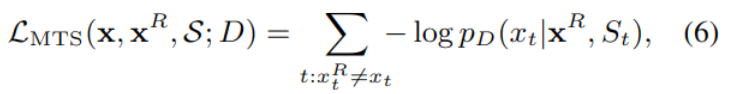
可选项集S是针对所有篡改位置,生成的最能以假乱真的k个token作为候选项,MTS从本质上,是一个k+1类的分类器。
Sequence级判别
另外,还针对序列,设计了对比序列预测CSP (2020年Chen提出),对于每一句原始输入,建立了两个版本的篡改结果。如图-1中左右两部分所示,分别用 XRi 和 XRj 表示,将它们作为一个正例对;选择训练时同一minibatch中的其它序列作为反例,由正例和反例组成候选集N(x)。CSP任务的目标是在已知XRi的条件下,从候选项 N(x) 中选择正确的 XRj。
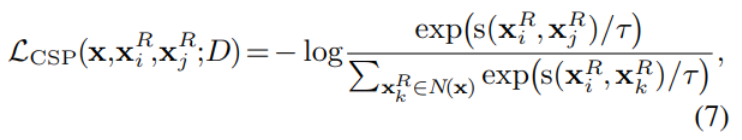
其中s()用于度量相似度, τ 是超参数。
模型训练
最终的目标函数综合了上述损失,λ是超参数:
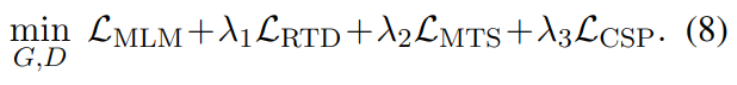
实验
实验包含预训练和针对各个任务的精调。
数据
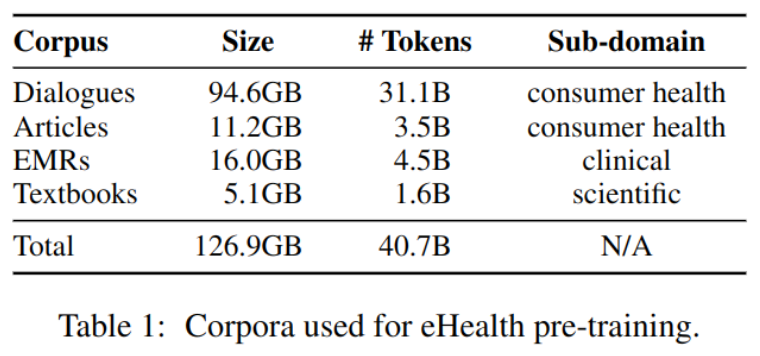
使用四个中文数据集预训练模型,包含:
- 100 million 个未标注的医患对话
- 6.5 million 医疗领域热门文章
- 6.5 million 份电子病历
- 1500本教材包括医学和临床病理学
如表-1所示:
领域内词汇表
之前的实验证明,从一开始就使用领域词表训练的模型效果更好,本文实验中先建立了领域词表:使用Tensor2Tensor library3创建生物医学领域的WordPiece词汇表,丢弃出现次数少于5次的token,并将词汇量保持在20K左右,与通用域中文BERT相似。
如表-2所示,新词表对中文效果并不明显,但能更好的识别英文缩写。

主实验结果