
- 1springboot web创建失败,解决Could not find artifact org.springframework.boot:spring-boot-starter-parent:pom
- 2从IT主管到CIO成长之路(2万字)
- 3JSON parse error: Cannot deserialize instance of `java.util.ArrayList` out of START_OBJECT token; ne
- 4ChatGPT使用案例之自然语言处理_chatgpt在自然语言处理中的应用
- 5[附源码]JAVA毕业设计高校校园社交网络(系统+LW)_javaweb校园社交系统
- 6SAP MB52改为ALV显示格式_sap mb52 alv
- 7Android 创建桌面组件Widget——构建应用微件(二)_android 10 自定义widget
- 8零基础学FPGA(六):FPGA时钟架构(Xilinx为例,完整解读)_fpga中的全局时钟
- 9hadoop启动缺少NameNode, 缺少ResourceManager, 缺少NodeManager_hadoop没有namenode
- 10Flutter运行MacOs网络请求报错Unhandled Exception: DioException [connection error]:...
即插即用系列 | Meta 新作 MMViT: 基于交叉注意力机制的多尺度和多视角编码神经网络架构
赞
踩
本文首发于微信公众号 CVHub,严禁私自转载或售卖到其他平台,违者必究。

Title: MMViT: Multiscale Multiview Vision Transformers
Paper: https://arxiv.org/pdf/2305.00104.pdf
导读
本文介绍了一种名为Multiscale Multiview Vision Transformers, MMViT的模型,它将多尺度特征图和多视角编码引入Transformer模型。该模型对输入信号的不同视图进行编码,并构建了几个通道分辨率特征阶段以同时处理输入的多个视图,并在每个尺度阶段使用交叉注意力块来跨视图融合信息,从而使MMViT模型能够获取不同分辨率的复杂高维表征。
动机
Transformer模型通过自注意力机制有效地捕捉了输入序列中的长距离依赖,并从中提取必要的上下文信息。因此,对于需要对输入特征进行复杂关系和依赖建模的任务,Transformer更为适合。此外,Transformer还具有良好的可扩展性,能够处理大规模数据集以及适应多模态的输入。
先前我们介绍多个Transformer主干网络主要在于如何在保证原有的特征提取能力不下降的前提下提升模型推理效率。本文主要从提升表征能力切入。目前主要有两个流派,即
Multi-scale Vision TransformerMulti-view Vision Transformer
前者基于多尺度特征金字塔来构建具有不同分辨率的层次结构特征,从而在视频和图像识别任务上实现更好的性能表现。同时,这种方法还能够减少计算量。而后者则利用不同视角的编码器和横向连接来融合信息,以处理复杂的时空关系。
本文结合这两者的优势,提出了一种基于多尺度和多视角的 Vision Transformer 模型——MMViT。与两者不同的是,本文方法仅对输入进行自注意力计算,同时在每个 stage 引入交叉注意力层,以合并来自多个视角的信息。这使得MMViT模型能够通过同时处理输入的不同分辨率的多个视角,在每个尺度阶段获取多分辨率的时间上下文。此外,MMViT模型使用分层缩放系统来增加通道大小并减小空间分辨率,在网络加深时生成高维复杂特征。通过采用多尺度和多视角特征,MMViT模型增强了其表示学习能力和整体性能。
方法
本文整体框架图如下图所示。下面我们就根据此图按顺序展开来讲,并就主要核心组件进行介绍,大家可以根据框架图一同理解。

Input and Embedding
首先,对于输入图像的不同视角,MMViT 使用 2D 卷积操作将其分成两个视角,并使用不同的卷积核大小和步长来生成不同的视角。与传统的 ViT 不同,MMViT 中使用的补丁化过程通过使用大于步幅的卷积核大小在补丁之间引入了重叠。这种方法从周围的像素中捕获更多的上下文信息,使 MMViT 模型能够在后续的 Transformer 块中并行集成信息。
其次,在生成的两个视图上,对它们应用可学习的时空位置编码。这个位置编码过程有助于模型编码位置信息并克服排列不变性。和其它基于 Transformer 嵌入模型一样,作者在第一个视图的开头添加了一个 [CLS] 标记。这个标记作为输入,用于分类头预测分类结果。
注:在深度学习中,排列不变性
permutation invariance通常是指一个模型对输入的元素排列的顺序不敏感。具体来说,在输入序列中改变元素的顺序不会改变模型的预测结果。例如,对于一个文本分类任务,如果我们将输入文本中的单词顺序打乱,但保留相同的单词,那么分类器的输出应该保持不变。对应到本文,就是将每个输入图像分成多个视图,并且每个视图都被打散成了一系列小块。为了解决这个问题,本文采用了可学习的空间-时间位置编码,用于编码输入序列中的位置信息。这种编码可以帮助模型捕获视图中不同块的位置关系,使得模型对输入的排列顺序不敏感,从而提高模型的鲁棒性和泛化能力。
Scale Stage
类似于大部分 ViT 模型。MMViT 的架构包括四个 stage 共 16 个 Transformer 块,每个层中处理 2 个不同感受野视图。在每个 stage 中,n 个自注意力块紧随其后,分别包含一个交叉注意力块和一个缩放自注意力块。下面我们就这两个模块介绍下。
Self-attention Block

上图为自注意力块的示意图,整体非常简单,一眼看穿。左右两边主要是用于处理两个不同的视图,同原始的自注意力不同之处在于,这里对 QKV 和残差连接分别用一个池化层压缩了下,降低复杂度。
Cross-attention Block
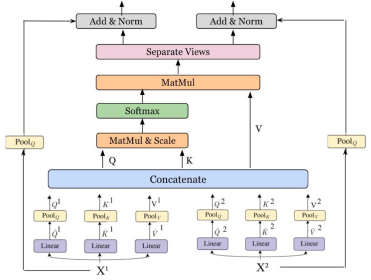
在每个 stage 阶段,交叉注意力机制用于提取全局上下文信息并合并每个视图之间的信息。如图所示,作者是直接将两个视图输出的特征压缩后直接进行拼接,然后又送入一个自注意力块去融合,最后再基于一个 spllit 操作直接拆分成两条路径并结合残差输出。
实验

同预期的差不多,提升并不是很大,实验貌似做的还不够充分~~~就酱啦
总结
本文主要提出了一种新颖的多尺度及多视图视觉 Transformer 模型,作为适用于多种模态的主干网络。该模型将多个视图输入到多尺度阶段层次结构模型中,并结合了多尺度视觉 Transformer(MViT)和多视图 Transformer(MTV)的优点。在每个尺度阶段,使用交叉注意力层来合并不同分辨率的视图信息,从而使网络能够捕捉复杂的高维特征。实验结果表明,MMViT 模型有一定的性能提升。
CVHub是一家专注于计算机视觉领域的高质量知识分享平台,全站技术文章原创率达99%,每日为您呈献全方位、多领域、有深度的前沿AI论文解决及配套的行业级应用解决方案,提供科研 | 技术 | 就业一站式服务,涵盖有监督/半监督/无监督/自监督的各类2D/3D的检测/分类/分割/跟踪/姿态/超分/重建等全栈领域以及最新的AIGC等生成式模型。关注微信公众号,欢迎参与实时的学术&技术互动交流,领取CV学习大礼包,及时订阅最新的国内外大厂校招&社招资讯!

