
- 1【Devin AI】全球首位AI程序员登场,程序员该如何保住饭碗?编程新纪元的革命已到来!_devin ai 官网
- 2ArcGIS支持下SWAT与CENTURY模型的结合:流域水碳氮综合模拟
- 3【第68篇】多目标跟踪:文献综述_目标跟踪文献
- 4自定义神经网络二之模型训练推理_模型推理 训练
- 5vscode 如何创建python项目_vscode创建python项目
- 6智能优化算法(源码)-樽海鞘优化算法(Salp Swarm Algorithm,SSA)_樽海鞘算法
- 7数据可视化redis mysql_开源 5 款超好用的数据库 GUI 带你玩转 MongoDB、Redis、SQL 数据库...
- 8Flutter 三角旋转动画_flutter改变图标的角度
- 9大数据毕业设计选题推荐(二)
- 10BERT(5)---实战[BERT+CNN文本分类]
AAAI 2024 | 首个多模态实体集扩展数据集MESED和多模态模型MultiExpan
赞
踩


论文题目:
MESED: A Multi-modal Entity Set Expansion Dataset with Fine-grained Semantic Classes and Hard Negative Entities
论文链接:
https://arxiv.org/abs/2307.14878
代码链接:
https://github.com/THUKElab/MESED
论文录用:
AAAI 2024 Main Technical Track

动机
实体集扩展(ESE)是一种信息检索任务,旨在通过使用给定的候选实体词汇表和语料库,从中发现属于同一语义类的新实体。这个任务的目标是通过利用已知的一组种子实体,从语料库中检索并扩展出属于相同语义类别的其他实体。这有助于建立更全面、更丰富的实体集,提供更深入的语义理解和关联性,使得 NLP 和 IR 等下游任务受益。
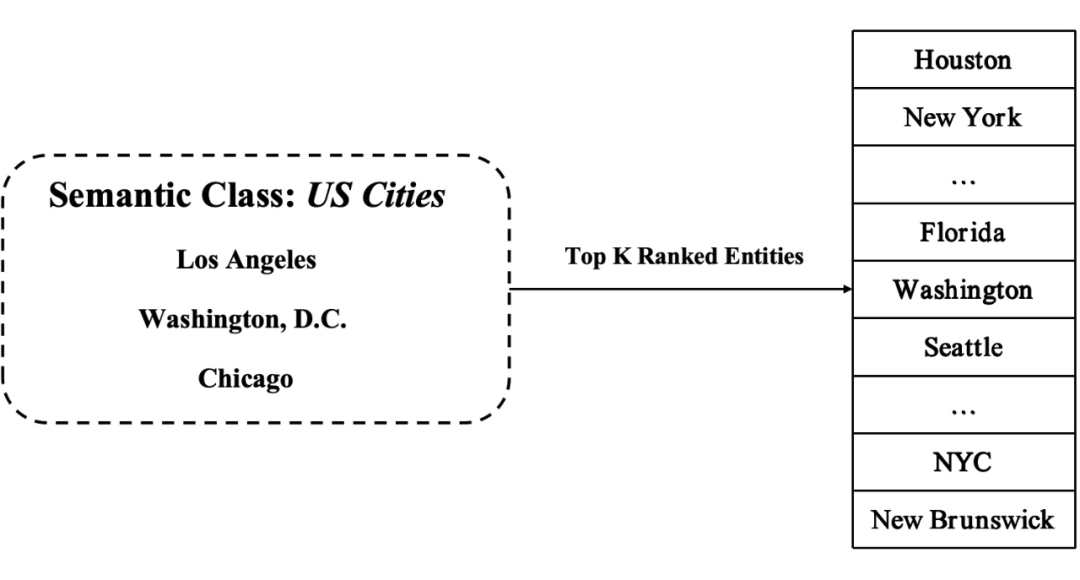
以扩展语义类 US Cities 为例,给定一组种子实体 {Washington D.C., Chicago, Los Angeles},ESE 尝试检索具有目标语义类的其他实体,如 New York, Houston。任务的目的是让扩展出的 Top K 个实体尽可能准确的属于 US Cities。
然而,传统的 ESE 方法基于单模态,通常信息有限且表征稀疏。单模态 ESE 方法面临着一些挑战,主要表现在以下几个方面:
具有细粒度语义差异的负实体:与目标类属于同一粗粒度语义类的实体。在扩展语义类 US Cities 时,必然需要考虑到与目标类别具有相同父语义类(US Location)的实体,例如位于美国的 Florida 和 Texas。由于这些实体在文本上下文中具有相似语义,传统的单模态 ESE 方法往往难以在细节上进行区分。
同义实体:实体的多种别名。ESE 模型可以很容易地理解常见别名,但无法理解上下文相关的别名,如缩写和昵称,因为确定它们的含义需要明确的文本提示。例如,SEA 仅在某些上下文中表示 Seattle,这可能导致检索的遗漏。
一词多义实体:一词多义实体可能存在歧义,因为引用多个实体的文本提及共享相同的 token。由于预训练语言模型通过单词共现学习语义,因此包含相同 token 的实体本质上更接近。例如,从 Washington, D.C. 到 Washington State 的相似度大于到 Austin 等许多其他城市的距离,从而导致错误的结果。
长尾实体:出现频率较低且相对不常见的实体,如晦涩的地名。这些实体由于出现次数有限,其在文本中的描述通常较为零散,且文本上下文匮乏,很难获取关于这些实体的详尽信息。由于文本描述的稀缺性,表示长尾实体往往过于稀疏,使得在检索时可能会错过相关的内容。
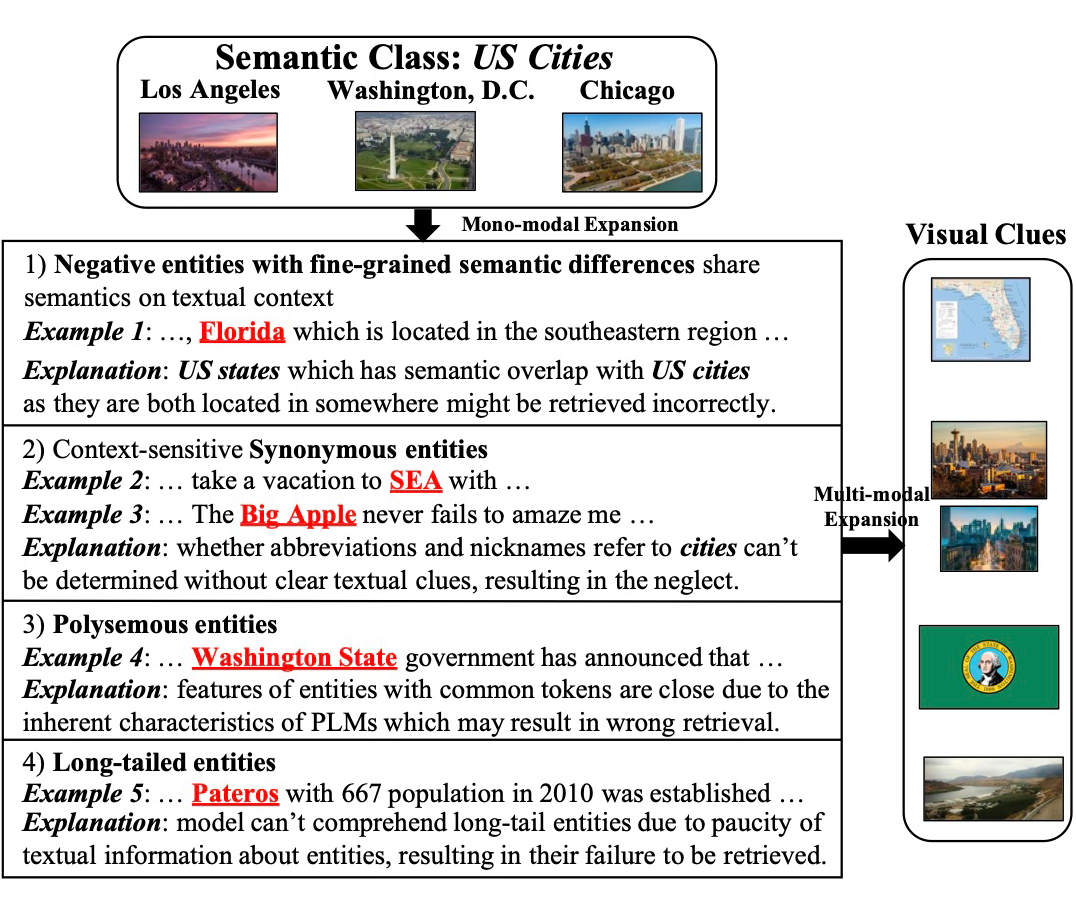
上述情况促使多模态实体集扩展(MESE)任务的出现。MESE 整合来自多种模式的信息来表示实体并将它们扩展到目标语义类,利用多个信息源来克服单模态方法的局限性。
遗憾的是,尽管存在多种多模态数据类型,但目前还没有基于细粒度语义类结构的多模态数据集可用于评估 MESE 的效果。为弥补这一差距,本文构建一个名为 MESED 的大规模人工标注的 MESE 数据集,其中包含来自维基百科的 14489 个实体和 434675 个图像-句子对。
此外,本文提出多模态基线模型 MultiExpan 并探索多种自我监督的预训练目标,用于多模态实体的表示学习。大量实验验证了 MultiExpan 与单模态/多模态模型相比的有效性。

数据集
MESED 是首个用于 ESE 的多模态数据集,具有大规模和精细的人工校准。它由维基百科收集的 14489 个实体和 434675 个图像-句子对组成,具有三层结构,第一层和第二层分别包含 8 个和 26 个粗粒度语义类,最后一层包含 70 个细粒度语义类。MESED 中的 70 个细粒度语义类平均包含 82 个实体,最少 23 个,最多 362 个。每个细粒度类包含 5 个具有 3 个种子实体的查询和 5 个具有 5 个种子实体的查询。


方法
4.1 任务重述
多模态实体集合扩展的输入是一个包含多个种子实体的小集合 ,描述某个语义类和候选实体的词汇表 。此外,语料库 包含每个实体的 多模态上下文 ,其中 是一个包含 的句子, 形成一个图像-句子对。任务目的是向种子集 中加入相同语义类的实体。需要强调的是,在给定的上下文中可能缺少任意模态。
4.2 多模态实体表征
多模态实体表征阶段主要包括多模态实体级编码器和四个预训练任务损失函数的设计:
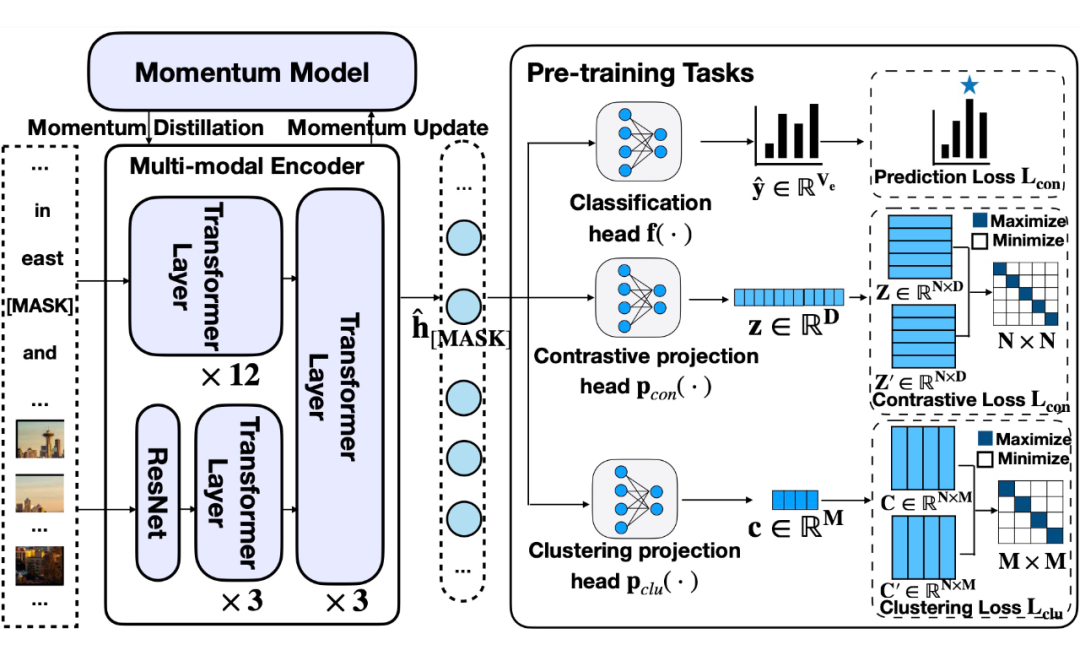
4.2.1 多模态实体级编码器
多模态实体级编码器首先用自注意 Transformer 分别处理文本和图像,然后将它们结合起来进行深度的跨模态交互。
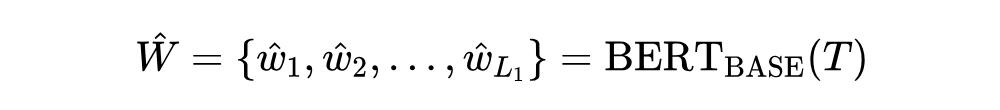
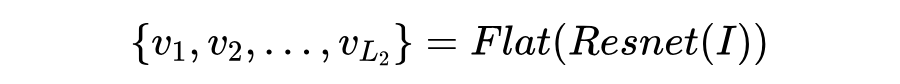
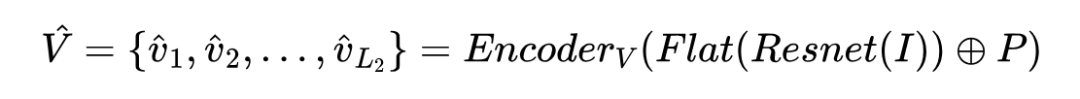
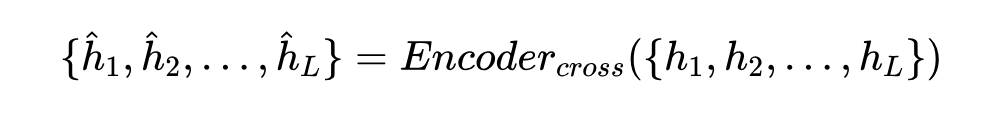
其中 是带有掩码实体提及的上下文文本, 是句子 tokens 的最大长度; 是图像的36个 patch, 是每个patch的位置信息, 是 patch 数量;隐藏状态 通过文本特征和视觉特征的拼接获取:, 。视觉编码器和跨模态编码器均由三层 Transformer 组成,结构相同,但具有不同的参数。
分类头 附加在多模态编码器之后。得到掩码位置的隐藏状态后,通过 MLP 和 Softmax 函数将嵌入向量转化为掩码处实体在可能的候选实体上的概率分布:
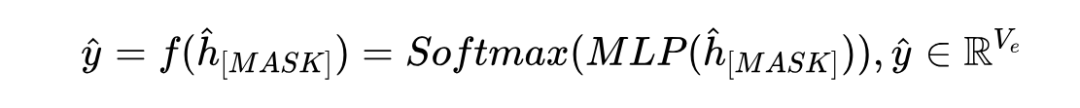
其中 是候选实体词汇表的大小。
4.2.2 四个预训练任务损失函数的设计
掩码实体预测
针对掩码实体预测任务,模型以图像和掩码句子作为输入,得到掩码位置的实体概率分布 。使用带标签平滑的交叉熵损失以允许模型学习实体的底层语义:
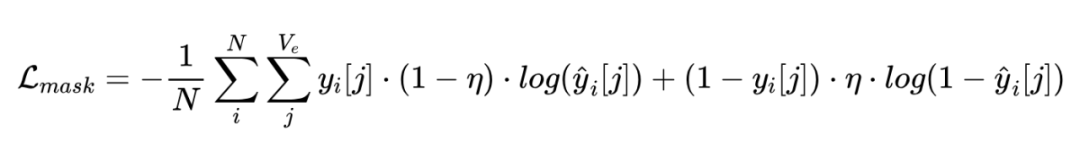
其中真实值 是 one-hot 向量, 是批量大小, 是平滑因子,用于防止与目标实体相同语义的实体被过度抑制。
对比学习
排名在前 位置的实体被定义为正实体,而排名从 到 的实体被认为是负实体,配对形成正负样本对。在多模态编码器后插入一个双层的 MLP ,通过 将隐藏特征映射到归一化子空间。样本对的相似度由点积计算:
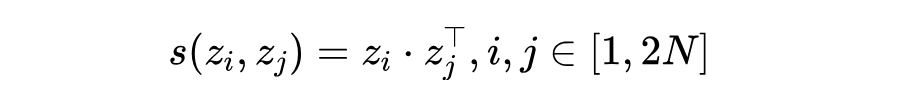
对比学习损失重点关注困难负实体。对于给定的样本 (假设它与 形成正样本对),损失定义为:
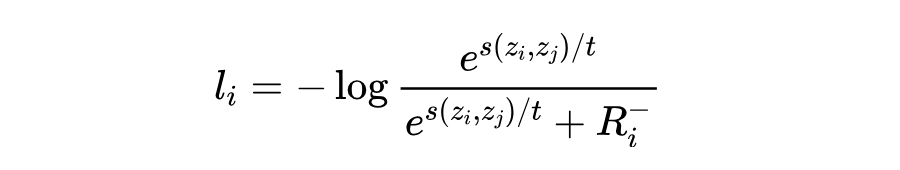
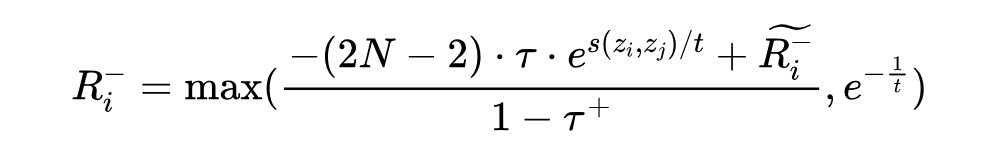
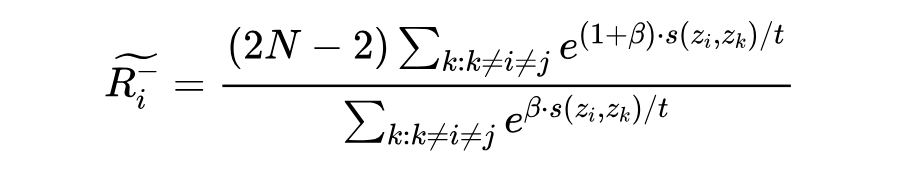
其中 是超参数,分别代表类先验概率、困难负实体浓度水平和温度。对比损失是在批次中的所有样本中计算的:
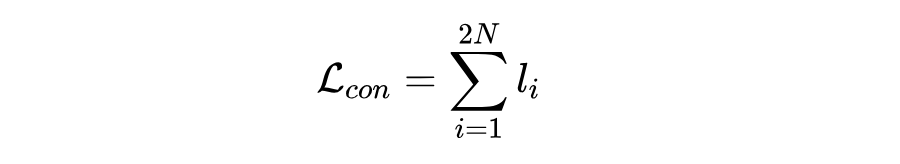
聚类学习
与对比学习类似,聚类学习使用聚类投影头 ,将输入样本 映射到语义类子空间 。 的维度 对应聚类的个数,特征的每个元素表示它属于特定语义类的概率。
令 表示样本 下的类概率分布, 表示样本 下的类概率分布。为简洁起见,将 的第 列表示为 ,将 的第 列表示为 。采用点积来量化 和 之间的相似度:
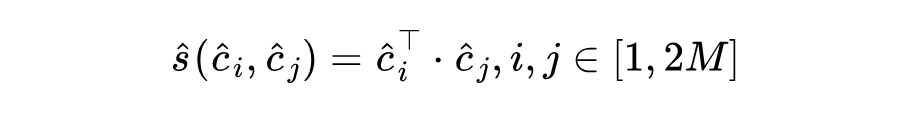
对于每个语义类 ,聚类损失 的计算方式与对比损失相同,最终计算为:
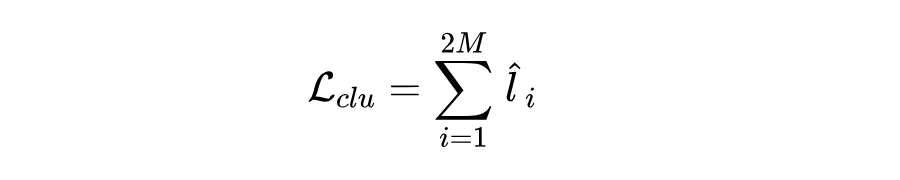
动量蒸馏
为缓解图像-句子对中噪声的影响,在训练期间,模型的动量版本通过以指数方式移动动量因子 来缓慢更新:。动量模型用于生成伪标签作为额外的监督,防止学生模型过度拟合噪声。动量蒸馏损失表示为动量模型生成的伪实体概率分布 与当前迭代中多模态编码器预测值 的 KL 散度:
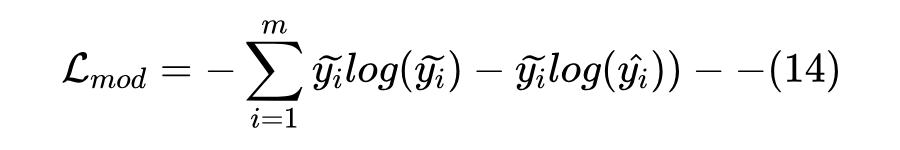
4.3 实体扩展
在获得句子中掩码区域的实体概率分布后,实体被表示为包含它的所有句子的预测实体概率分布的平均值。语义类由当前扩展集中实体的加权平均表示,权重由窗口搜索算法动态维护。这样,具有相似分布的候选实体被放置在由 KL 散度度量的当前集合中。
一旦当前集合中的实体数量达到目标大小时,执行实体重排序算法。评分函数旨在将得分高的实体移动到扩展结果的最前面:
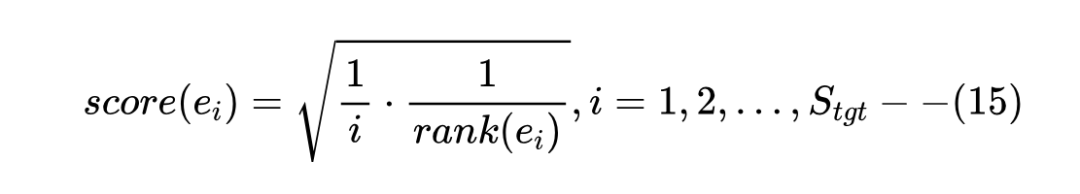
其中 是 在窗口搜索步骤中的原始排名, 是实体 在重新排序列表中的顺序,由 和当前集合之间的 KL 散度排序。通过实体重排序算法,可以得到最终的排名列表。

实验
5.1 主实验
我们比较三类模型,第一是传统的基于文本的 ESE 方法,包括 SetExpan,CaSE,CGExpan,ProbExpan,GPT-3.5。上述模型中,SetExpan、CaSE 是传统的基于统计概率的方法,CGExpan 和 ProbExpan 是最先进的基于预训练语言模型 BERT 的方法。
我们还评估基于视觉的模型:VIT,BEIT 和 CLIP 的图像编码器 CLIP-IMG。对于多模态扩展,我们探索具有不同结构的多模态模型,包括 CLIP 和 ALBEF。上述基于视觉的模型和多模态模型都是通过实体预测任务进一步预训练的。
实验中选择两个广泛使用的评估指标: 和 。 指标计算如下:
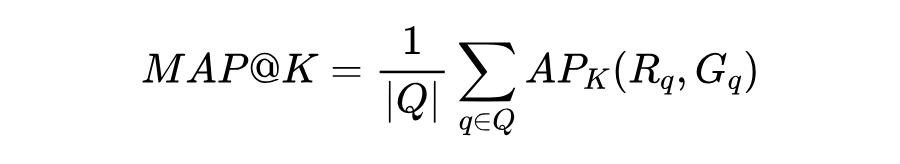
其中, 是每个query 的集合。 表示前 个位置排名列表 和真实列表 的平均精度。 是前 个实体的精度。在实验中,对和 |Seed|= 3 和 5 的 query 分别进行评估:
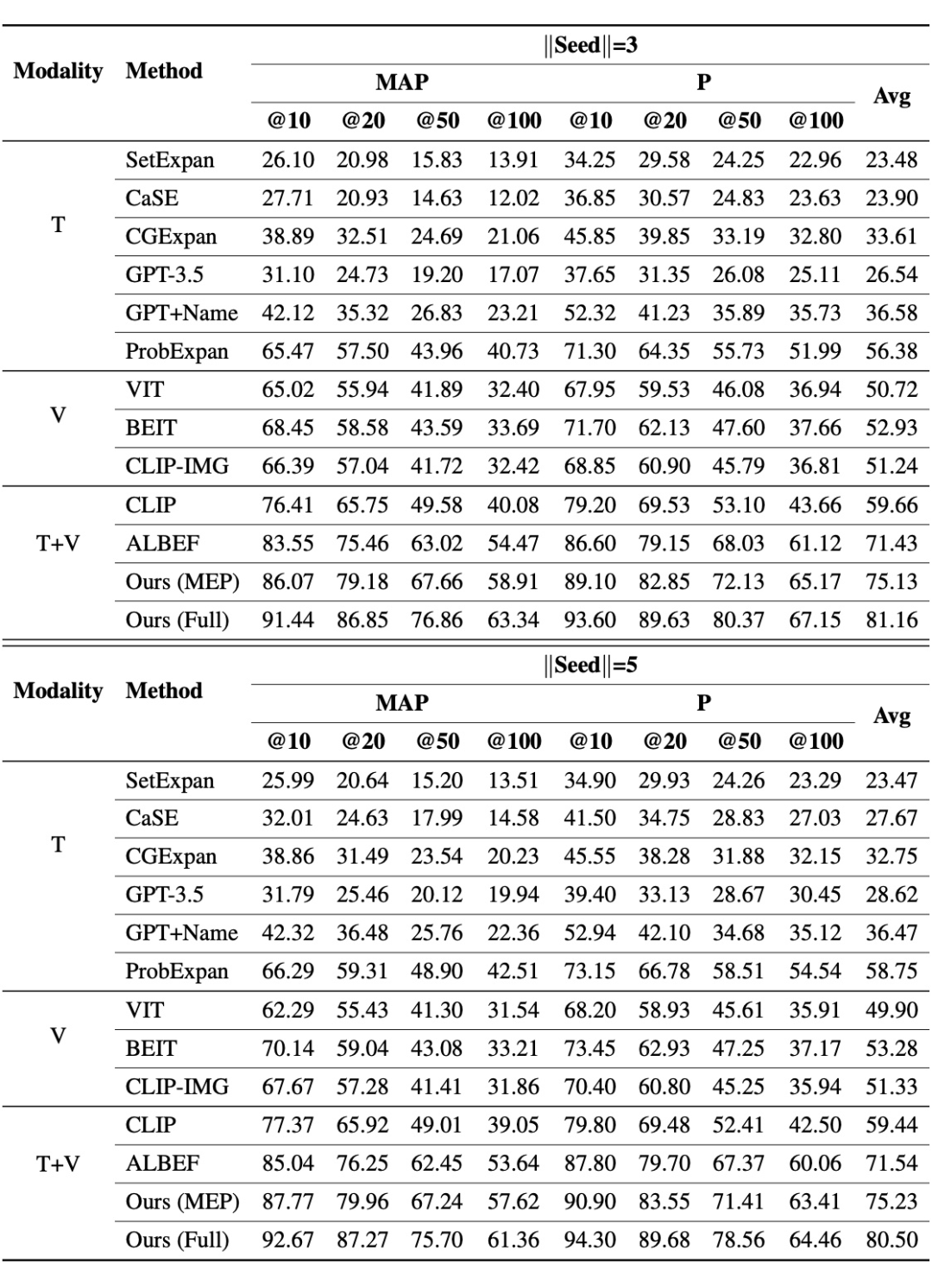
从实验结果可以观察到:
多模态方法总体上优于单模态方法,MultiExpan(MEP)仅通过使用掩码实体预测任务就实现卓越的性能。完整的 MultiExpan 方法实现最佳的整体性能。
在多模态模型的结构方面,ALBEF 和 MultiExpan 通过 Transformer 表现出深度模态交互,与 CLIP 通过点积相似性计算的浅模态相比,它更适合 ESE 任务。这些结果表明,深度模态交互和融合是未来可以探索的方向。
在基于视觉的模型方面,BEIT 通过对掩码图像建模进行预训练,擅长利用更细粒度的图像语义,例如对象和背景信息。与通过图像网络数据集中的图像分类学习整体图像语义的 VIT 模型相比,BEIT 在实体理解方面表现出更好的结果。同时,CLIP 的图像编码器由于与文本模态的联系,还捕获了比 VIT 模型更丰富的语义。然而,仅仅依靠图像模态并不足以产生令人满意的结果,文本模态仍然占主导地位。
|Seed|的增加不一定使得整体性能提升。更多的种子实体可以更精确地描述语义类并更安全地检索一些“必须正确”的实体,因此当 较小(=10,20)时 会提高。然而,更多的种子实体意味着更大的语义类搜索空间,需要分析比当前更细致的公共实体属性。这表示ESE模型的语义漂移问题面临着持续挑战,因此当 较大时, 会降低。当然,增加 |Seed| 有助于消除 query 与属于多个类的实体的歧义。例如在语义类 Light Novel 中,一些种子实体也属于 Manga,增加|Seed|在所有指标上平均获得 17.5% 的提升。
GPT-3.5 没有取得令人满意的结果,甚至不如无监督的 CGExpan。通过仔细检查 GPT-3.5 在特定语义类上的表现,发现该模型在处理复杂类时遇到困难(如 108 Martyrs of World War II)。明确指示 GPT-3.5 先推理类名,然后根据它们进行扩展。与 GPT-3.5 相比,这个名为 GPT+Name 的修改表现出实质性的改进。这种方法与针对大型语言模型的新兴思维链推理的想法一致,即逐步思考。这也建议未来的研究探索思维链和 ESE 任务的结合。
5.2 消融实验
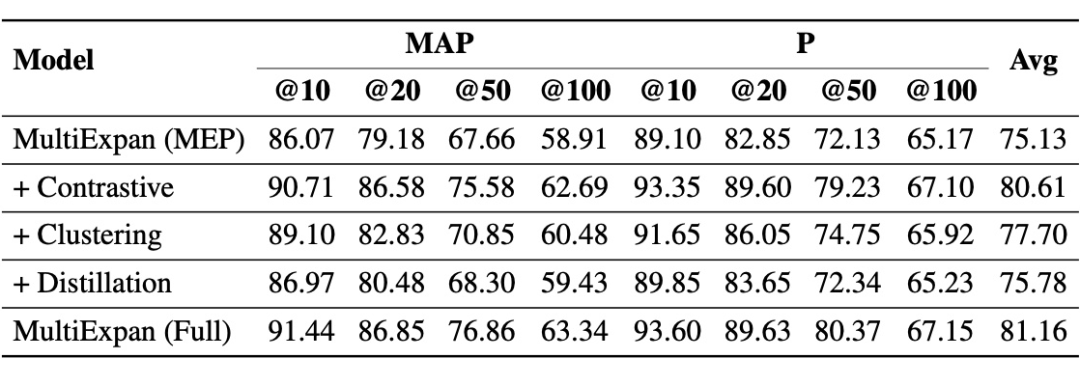
本文比较不同预训练任务对 MultiExpan 的影响。掩码实体预测任务使模型能够学习实体的底层语义,通过添加三个预训练任务进一步增强这一点。表中显示的结果表明,每个预训练任务都会对模型产生有益的影响。
此外,通过提供更清晰的语义边界,使用困难负实体的对比学习为模型带来最大的性能改进。虽然聚类学习在 和 时带来与对比学习相当的收益,但在较大的 时效果较差。这是因为对比学习直接对实体进行操作,并且更直接地将目标实体聚合到紧密的集群中。
相比之下,动量蒸馏学习带来的性能增益较小,这主要归因于它能够在存在噪声数据的情况下防止过度拟合。这一观察结果强调了 MESED 提供的数据的高质量,尤其是句子中实体的准确标注。
5.3 案例分析
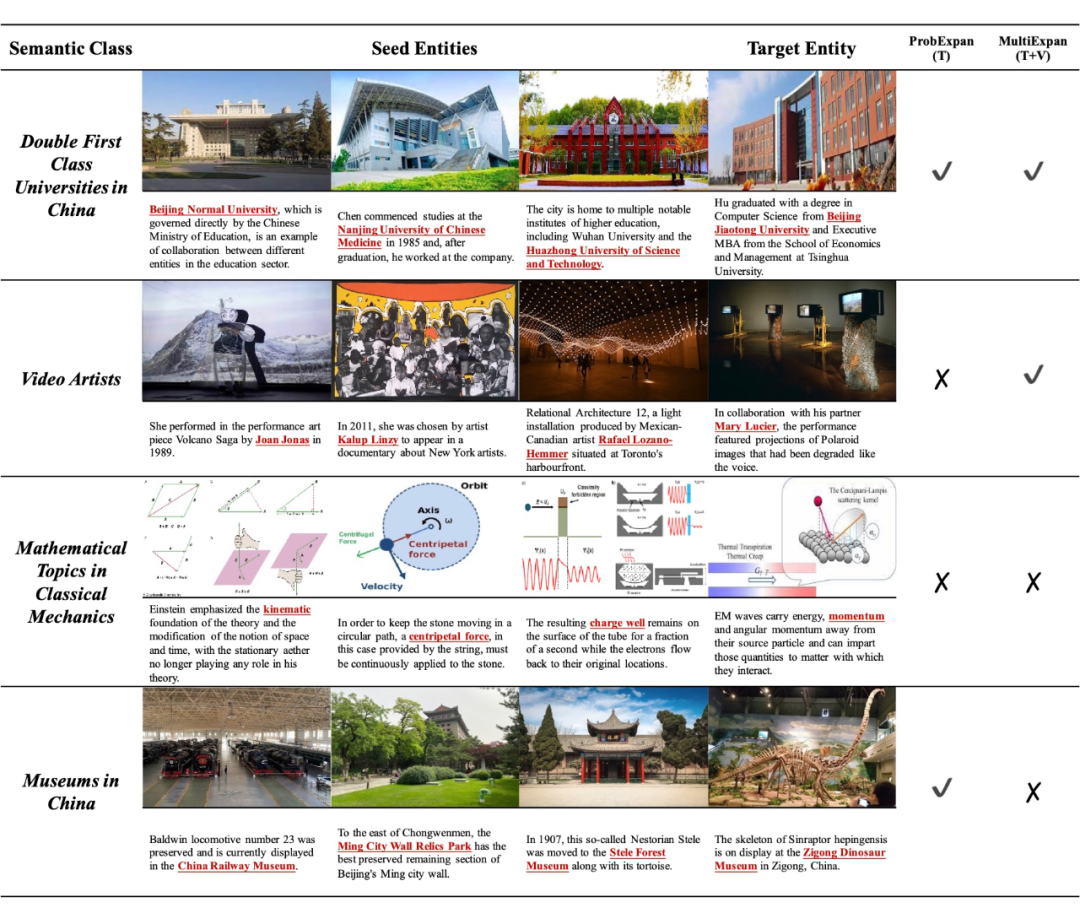
图中展示一系列有趣的案例研究,以说明多模态信息的利用。
在第一行,由于语义类 Double First Class Universities in China 相对简单,仅文本信息就足以准确扩展目标实体 Beijing Jiaotong University。
相比之下,图中第二行的 Video Artists 的概念不能仅通过文本信息来概括。通过以统一的方式展示他们的作品,这些图像为 Artists 的语义类别提供隐含的视觉线索。
相反,对于后两种情况,包含图像并没有产生积极的好处,表明图像利用策略需要进一步改进。
第三行,图像中出现大量的数学符号和几何形状,但目前的 MultiExpan 并没有完全理解和利用它们。这启发通过理解图像中对象的细粒度语义(例如,图像中的文本、区域特征)来探索更好的图像利用方法。
在最后一行,包含图像甚至导致负面影响;将目标实体 Zigong Dinosaur Museum 表示为恐龙骨架导致混淆,模型错误地排除该实体。然而,由于多个语义误导而产生的这个错误显然可以被规避,因为句子中有明确的词表明这个实体是博物馆。这促使未来研究如何利用跨模态交互来排除单模态形式中的嘈杂或误导性信息。

总结
本文研究多模态实体集扩展(MESE)问题,旨在利用多种模态信息来表示和扩展实体,为下游的搜索推荐等任务提供便利。由于之前的研究局限于单模态的数据集,ESE 领域缺乏多模态数据集和模型,故本文构建 MESED 数据集,它是 ESE 任务的第一个具有细粒度语义类和困难负实体的多模态数据集。
此外,本文提出一个强大的多模态模型 MultiExpan,它包含一个多模态实体级编码器,用于获取句中提及掩码处的实体概率分布。模型在四个多模态预训练任务上进行预训练,将四个损失函数结合,训练出最佳的性能。与其他单模态/多模态模型相比,MultiExpan 取得最佳的结果,可以说明图像模态引入的有效性和必要性。之后 MESED 还可以作为评估大型 PLM 的多模态实体理解能力的可靠基准。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

