
- 1第六十八篇:从ADAS到自动驾驶(一):自动驾驶发展及分级_自动驾驶与adas系统架构的区别
- 2深入机器学习系列之自然语言处理
- 3为什么现在的LLM都是Decoder only的架构_decode only
- 4ubuntu20.04分区方案 for deeplearning
- 5免费可用chartGPT网站汇总_免费gpt网站
- 6headscale headscale-ui 部署 docker_headscale serve 指定配置文件
- 7Midjourney艺术家分享|By Moebius
- 8新王Claude 3实测!各项能力给跪,打麻将也会,确实比GPT-4好用_claude 3试用
- 9Embedding模型在大语言模型中的重要性
- 10Spark 3.0 - 5.ML Pipeline 实战之电影影评情感分析_spark情感分析
北京大学创新推出ManipLLM黑科技 | 大幅提升机器人操作的鲁棒性与智能性
赞
踩
机器人操作依赖于准确预测接触点和执行器方向以确保成功操作。然而,基于学习的机器人操作,在模拟器中仅针对有限类别进行训练,往往难以实现泛化,特别是在面临大量类别时。
因此,作者提出了一种创新的方法,利用多模态大型语言模型(MLMMs)的强健推理能力来增强操作的稳定性和泛化性。通过微调注入的 Adapter ,作者保留了MLLMs固有的常识和推理能力,同时使它们具有操作能力。该方法的基本洞察在于所引入的微调范式,包括目标类别理解、先验推理和以目标为中心的姿势预测,以激发MLLM在操作上的推理能力。在推理过程中,作者的方法使用RGB图像和文本提示来预测执行器的姿势。在建立初始接触后,引入了一个主动阻尼适应策略,以闭环方式计划接下来的导航点。
此外,在实际场景中,作者设计了一个测试时的适应策略(TTA),以使模型更好地适应当前的实际场景配置。在模拟器和实际场景中的实验表明,ManipLLM的性能令人满意。
有关更多详细信息和演示,请参阅https://sites.google.com/view/manipllm。
1 Introduction
由于机器人操作需要机器人与各种目标进行交互,因此低级动作预测的鲁棒性和可解释性对于操作的可靠性变得至关重要。尽管某些方法展示了令人印象深刻的性能,但它们通常将低级操作预测视为黑箱预测问题,并将人类固有的常识推理能力视为内在能力,从而限制了它们操纵广泛类别目标的能力。
现有多模态大型语言模型(MLLMs)在常识推理和视觉任务上的显著泛化能力得到了突出。然而,直接将多标签语言模型(MLLMs)训练为学习机器人低级动作轨迹(即执行器轨迹)存在泛化挑战,因为它们的预训练数据中低级动作样本很少。因此,MLLMs在这个领域缺乏先验知识,而成功训练这些任务需要大量数据以实现所需泛化能力。相比之下,MLLMs在理解物体和展示显著泛化能力方面表现出强大的能力。
因此,将MLLMs转换为以目标为中心的操纵证明更有效。这提出了一个重要问题:作者如何利用MLLMs促进以目标为中心的机器人操作?主要的挑战是如何使MLLMs理解物体的几何结构(例如它们的轴),以预测目标为中心的操纵的可移动接触位置。此外,这些模型,它们接受2D输入,是否也可以预测3D执行器方向仍然有待探索。
在本研究中,作者旨在利用嵌入在MLLMs(多模态大型语言模型)中的常识和推理能力来实现有前景的机器人操作性能。为此,在训练过程中,为了保留MLLMs的强大能力并赋予它们操作能力,作者只微调注入的可学习 Adapter在MLLMs上。
此外,作者设计了一个复杂的训练范式,并制定了微调任务,包括目标类别识别、先验推理和操作感知的姿势预测。先验推理考虑物体的几何固有属性,并反映了在特定像素上产生运动的概率。通过这种训练范式,作者使MLLMs能够在类别 Level 上识别物体,理解哪些区域可以被操作,哪些不能,并最终在姿势 Level 上生成精确的坐标和方向进行操作。
在推理阶段,作者采用与训练流程一致的连续思维流,使模型的预测更具解释性。这使作者能够理解模型在获得最终姿势预测过程中的思维过程。最终的预测结果如图1所示。给定一个包含物体和文本提示的RGB图像,作者的方法在2D图像上生成接触像素坐标,并预测执行器方向。
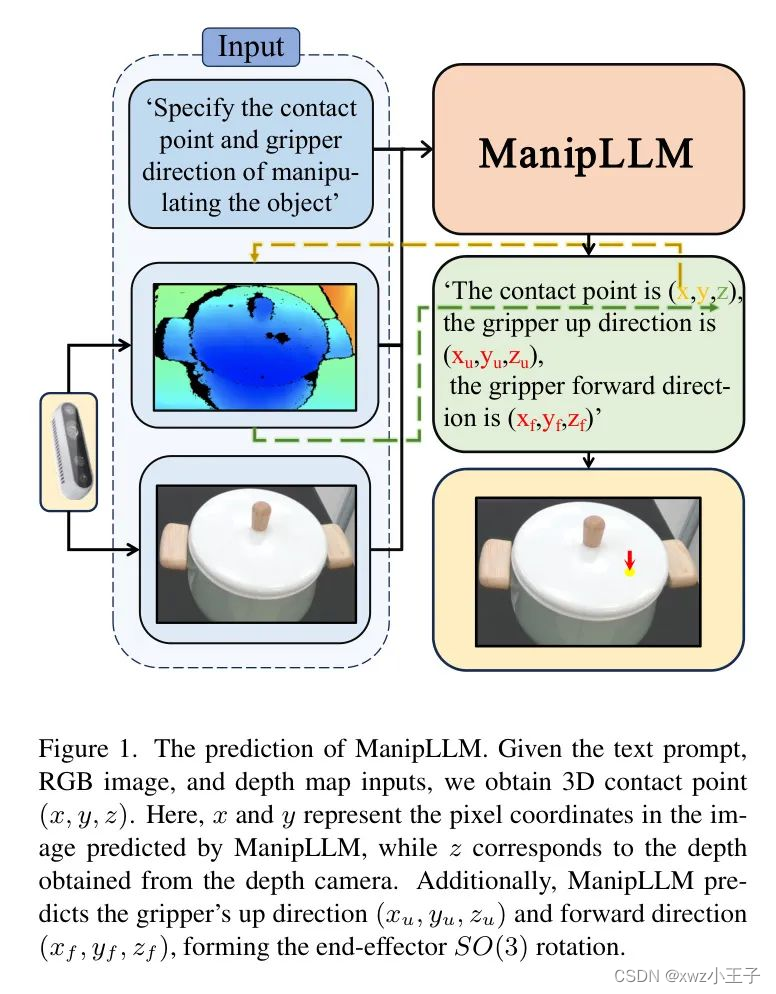
此外,深度信息将像素坐标映射到3D空间。在建立初始接触后,作者设计了一个主动阻尼适应策略,通过预测接下来的导航点来进行闭环运动规划。具体来说,这个模块根据当前姿态在周围方向施加小力。它旨在确定产生最大运动的方向,并将其选择为下一个姿态。这种方法依赖于轴向的力反馈和物体来适应性调整方向并预测轨迹。
在实际测试中,作者观察到一些挑战可能与模拟学习环境有所不同。例如,在实际世界中,使用带手的门,使用短吸盘抓取器可能需要将执行器远离把手以避免碰撞,这与模拟器中的情况不同。为解决这些变化,作者受到测试时自适应(TTA)的启发。TTA涉及在推理过程中根据当前测试样本调整部分模型参数,以增强模型在特定实际场景中的性能。
随后,作者设计了一个针对机器人操作的TTA策略,旨在提高模型对实际世界配置的理解。具体来说,利用当前测试样本,作者使用操作成功或失败的后果来监督模型评估预测姿势是否会导致成功操作,并只更新部分参数。这使得模型能够保留其原有的能力并适应目标域,通过区分目标域中的有效和无效姿势。由于模型已经学会了预测可能导致成功操作的姿势,当面临未来的样本时,模型倾向于预测有效的姿势,从而在特定的实际场景中提高性能。
得益于MLLMs和设计的范式,ManipLLM在操作中表现出泛化和常识推理能力。实验表明,在模拟器中,作者的方法在30个类别中实现了有前景的操纵成功率。同时,在作者的实际实验中,作者的方法在有或没有TTA策略的情况下都展示了强大的泛化能力。更多的实际视频请参阅补充材料。
总之,贡献如下:
创新地提出了一种简单而有效的方法,将MLLMs的能力转变为以目标为中心的机器人操作。
设计了一种连续思维微调推理策略,利用MLLMs的推理能力,以实现具有鲁棒性和可解释性的执行器位姿预测。
在广泛的类别上的实验表明了ManipLLM的泛化能力。
2 Related Works
Robotic Manipulation
机器人操作由于其广泛的应用性而成为一个重要的研究领域。广泛使用的是一种基于状态的强化学习(RL)。一些工作已经识别出使用纯状态作为策略输入的可能性。然而,在更复杂的设置中,视觉基础的观察成为必要,以感知环境并理解复杂场景和目标。Where2Act提出了预测物体中的可操作像素和可移动区域的网络,以实现各种环境中的有意义交互。Flowbot3d也探索了一种基于视觉的方法来感知和操作3D可折叠物体,通过预测点状运动流。
此外,VoxPoser通过从大型语言模型中导出3D价值映射来合成可调整的机器人轨迹,基于自然语言指令。RT2,将信息转移到动作,有望更快地适应新情况。
然而,尽管这些方法取得了显著的成就,它们将任务定义为黑箱预测,降低了其可解释性。当面临大量的物体类别时,这种情况尤为严重。为了克服这种情况,ManipLLM利用嵌入在MLLMs中的常识知识和推理能力来增强机器人操作性能。作者设计复杂的微调推理策略,以实现可解释的以目标为中心的位姿预测。
Multimodal Large Language Models
大量语言模型,即LaMa,GPT3,由于其强大的推理能力,在各种语言任务上表现出熟练。在这些基础上,多模态大型语言模型(Multimodal Large Language Models)被引入,以弥合RGB视觉图像和文本之间的鸿沟。代表性的LaMa-Adapter可以泛化到多模态推理的图像条件,在视觉和多模态任务上都实现了具有竞争力的结果。
然而,尽管MLLMs取得了显著的成就,但它们在以目标为中心的操纵能力方面仍然受到限制。为了填补这一空白,作者的工作首次尝试在保持原有推理能力的同时,向现有MLLMs注入操作能力。通过这样做,微调后的模型不仅具有精确的操作能力,还能够处理各种类别目标在可解释思维下进行操纵。
3 Method
Fine-tuning Strategy
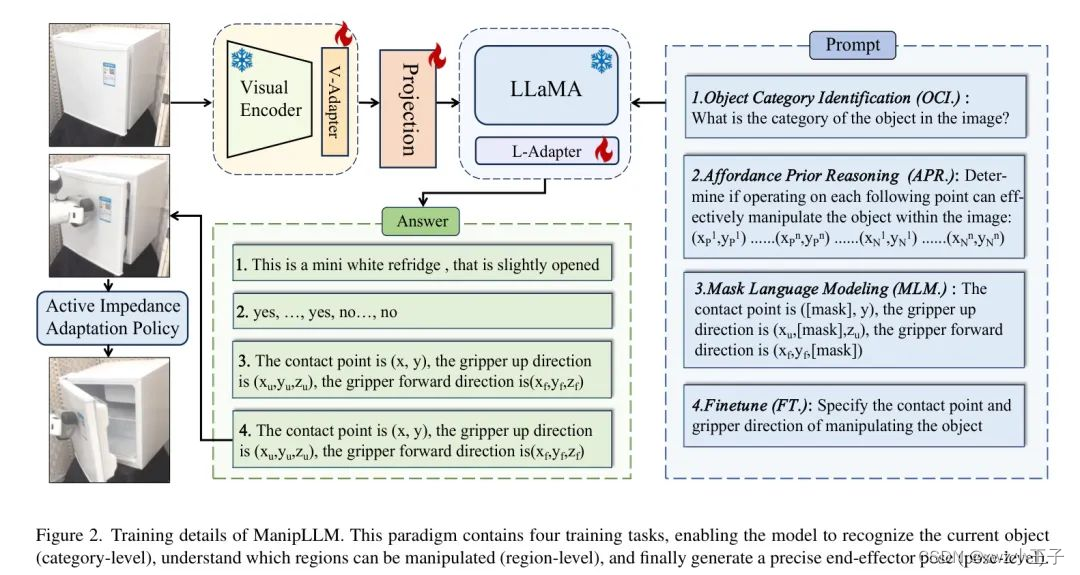
在本节中展示了如何赋予MLLMs操作能力。如图2所示,在类别 Level 、区域 Level 和姿势 Level 设计微调任务,使模型逐步和合理地预测目标为中心的机器人操纵的姿势。
3.1.1 Model Architecture
采用MLLM,LaMa-Adapter作为基础,并遵循其训练策略。给定一个RGB图像,采用CLIP的视觉编码器来提取其视觉特征。同时,将文本提示通过预训练的LaMa的tokenizer编码为文本特征。将视觉和文本特征表示与多模态投影模块对齐后,需要让LaMa进行多模态理解并给出正确答案。
在训练过程中,只微调注入的 Adapter在视觉CLIP和LaMa上,同时冻结主要的参数。这样做的目的是保留现有MLLMs的强大能力,并进一步使模型具有操作能力。
3.1.2 Fine-tuning Tasks Formulation
作者设计了一种训练范式来微调MLLM,并刺激模型为目标为中心的操纵生成可解释的位姿预测。
目标类别识别(OCI)。要成功地操纵目标,模型需要了解它所面对目标的类别,因为同一类别的目标具有共同的几何属性。如图2中第一个提示所示,作者将提示形式化为“图像中的物体属于哪个类别?”。值得注意的是,MLLMs已经在现实世界上的各种物体上进行了训练,因此它们在类别识别和泛化方面非常强大。
相比之下,模拟器中的物体类别非常有限,最多只有30到50个。在模拟器中更新学习过程可能会导致MLLMs强大的目标类别识别能力和稳健的泛化能力丧失。因此,作者在此阶段不更新模型,而是旨在为后续任务提供类别认知的先验,帮助它们提取具有类别特定操作特征。
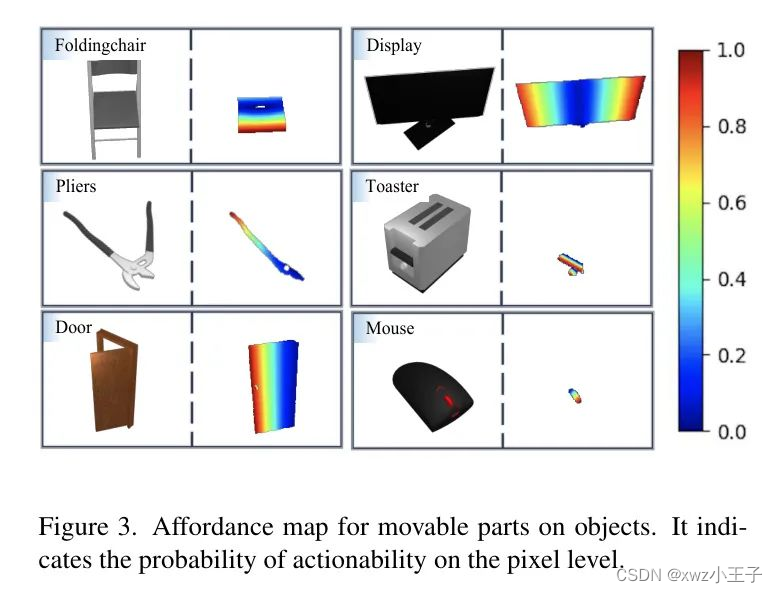
先验力场推理(APR)。这个阶段旨在使模型了解哪些物体区域可以被操作。力场图考虑物体的几何属性,并指示在某些像素上操作物体时获得移动距离的概率,反映了可以操纵物体的区域。它可以在区域 Level 上作为力场先验,使模型具有操作感知的局部化能力。
受到Flowbot3D的启发,将物体部分的动作类型分为“旋转”和“柱面”,并相应地在模拟器中收集力场图。对于旋转部分,首先找到可移动物体部分的轴,然后使该部分沿着轴进行运动。根据公式1获得力场图。
距离图,记作,计算在移动前后每个像素的欧几里得距离。通过应用基于距离图的最大值和最小值进行归一化操作,得到表示像素级行动可能性的力场图。对于柱面部分,即抽屉,在可移动部分的所有点上操作都可以促进运动,因此,抽屉的可动部分的概率图在力场图上都是1。在图3中可视化了力场图。对于旋转部分,力场图反映了操纵可能性的区域,即远离轴的区域。
在获得力场图后,作者的目标是使模型从这样的操作先验中学习。由于作者只有语言解码器(LLaMa),而不是视觉解码器,所以模型无法直接生成力场图。因此,作者的目标是将视觉表示的力场图翻译成语言力场先验。具体来说,作者随机选择个具有大于0.8的力场分数的积极像素作为训练样本,并选择个具有小于0.2的力场分数的消极像素作为训练样本。这些负样本涵盖了无法移动部分的像素以及具有低力场分数但可以移动的部分的像素,即接近旋转轴的像素。
如图2中的第二个提示所示,作者将选择的像素的坐标作为文本提示的"Determine if operating on each following point can effectively manipulate the object within the image: (,)…(,)…(,)…(,)",其中和分别表示积极和消极样本。相应的 GT 答案用"yes, yes… no,…"表示,其中个"yes"和个"no"基于力场分数。在交叉熵损失下进行监督,使模型知道哪些物体的区域可以被操纵,并促进模型预测可以促进运动的接触位置。
微调(FT.)和Mask语言模型(MLM.)这些任务旨在使模型能够生成精确的执行器位姿。在模拟器中,当预先收集训练数据时,如果操作成功,作者将记录RGB图像和相应的执行器位姿,作为模型输入和答案的 GT 值。对于任务微调(FT.),如图2中最后一条提示所示,作者将位姿预测的输入文本提示设计为"指定操作目标的接触点和抓取器方向"。答案形式化为"接触点是(, ),抓取器向上方向是(, , ),抓取器向前方向是(, , )"。为了降低方向回归预测的难度,将连续的归一化方向向量中的数字离散化为100个离散bin [-50,50],每个bin跨越0.02。输出在交叉熵损失下进行监督。
然而,作者发现直接微调模型进行位姿预测会导致不准确性。因此,为了促进位姿预测,在任务Mask语言模型(MLM)中,将输入文本提示中的坐标或方向向量的值进行屏蔽,并促进模型填充缺失的字符,如图2中第三条提示所示。这种预测方式在未屏蔽的答案下进行监督,使用交叉熵损失来刺激模型在位姿预测方面的能力。模型通过学习先验知识,从合理接触位置的预测中受益。
至于预测合适的方向,观察到MLLMs天生具有方向意识,例如能够推理出“将门拉向你”。训练映射将这样的方向认知描述和方向向量转换为一致的表示,从而实现执行器方向的预测。
训练和推理。在训练过程中,同时训练上述任务,在总目标函数下:。在推理阶段,采用连续思维推理来模拟模型,生成精确的初始接触执行器位姿解释性。
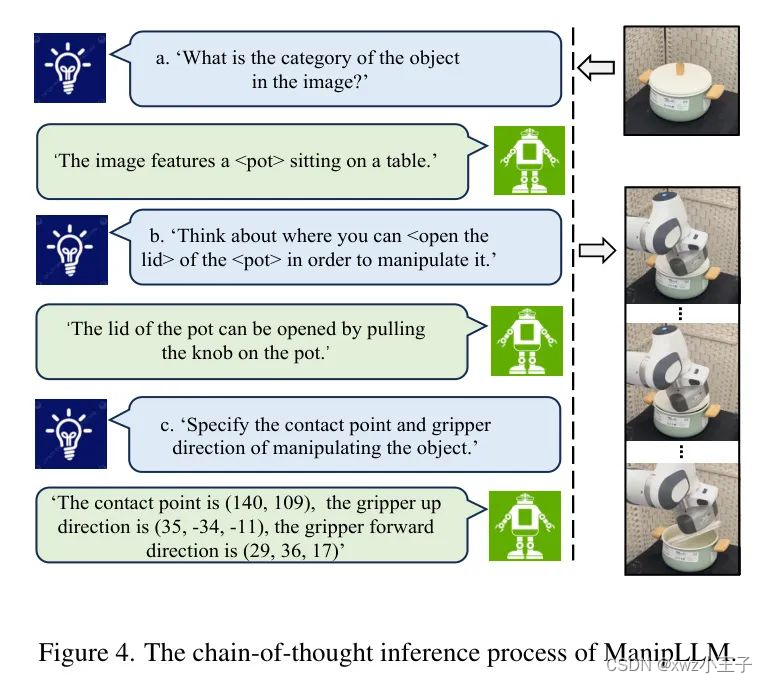
如图4所示,推理过程遵循与训练任务一致的三步。模型最终输出像素坐标,抓取器向上方向,抓取器向前方向。作者使用深度图将接触点投影到3D操作空间。抓取器向上方向和抓取器向前方向共同确定执行器的旋转。与预测方向一起,它们共同确定执行器的位姿,以建立与物体的初始交互。
Active Impedance Adaptation Policy
在与物体建立初始交互后,作者应用一个闭环启发式策略,根据阻力控制适应性生成即将到来的导航点,即打开门的可行轨迹。在操作可折叠物体的情况下,作者受到很大的限制,无法随意移动物体。例如,在尝试打开门时,最有效的方法通常涉及沿着门框轴线非常具体地移动物体。
为了处理这些困难,所提出的策略旨在根据阻力力反馈调整作者与物体的交互方式,从而有效地处理不同的场景。与利用模型预测随后的每个位姿不同,这种启发式策略更加高效。
这种策略在循环中得到应用,逐步完成一个操作任务。在循环的每个迭代中,根据物体的当前状态,基于前一步的前向方向,它适应性预测当前最适合的方向。作者以第一次迭代为例。
给定预测的前向方向,引入一个随机扰动,满足,其中表示一个小正数。这个过程重复次,得到一组表示为的方向,其中表示,。利用阻力控制,在每个方向上施加一个力,其中的方向由和定义,其中表示另一个小正数。然后根据观察到的执行器运动确定最优方向。
假设在受约束的目标操作任务中,更大的运动表示所施加的力的有效性。因此,最佳前向方向是通过以下方法确定当前执行器位姿的:
通过这种方式,作者考虑了沿着轴的力反馈,并确保了平滑的轨迹,从而在给定当前物体状态的情况下确定最优运动姿态。
Sim-to-real Transfer
尽管模型在模拟器中表现良好,但在实际环境中,机器人通常会遇到更多独特的情况,即环境或难以配置的设备,这可能与模拟器模拟的情况显著不同,导致模拟到实际(sim-to-real)差距。为了跨越这个差距,设计了一个针对操纵的测试时自适应(TTA)策略。TTA,如[21, 35]所述,在推理过程中根据当前测试样本更新部分模型参数,增强模型在特定实际场景中的性能。
为了在TTA期间确定应该更新哪些参数以进行位姿预测,作者分析了推理过程中图4中推理步骤的结果。作者观察到ManipLLM的推理能力受益于LaMa,在实际场景中继续表现出强大的性能。它可以准确识别图像中的物体并理解如何操纵它们。它的方向意识也很强大,确保了ManipLLM的定向预测的鲁棒性。尽管存在不精确的方向,但在3.2节中引入的主动阻力自适应策略,作者可以调整方向到更优的状态。
相比之下,位置预测对由照明和纹理等因素引起的域间差距更敏感。因此,在TTA期间,只更新图2中的V-Adapter的视觉感知。
具体来说,在当前测试样本的基础上,作者引入了一个额外的推理步骤,以提示模型评估预测的位姿是否可以导致成功操作。在这个步骤中使用的文本提示与训练阶段的"力场先验推理"一致,即"在图像中的以下点操作是否可以有效地操纵物体:。"模型预测的接触位置是它们认为可以导致成功操作的区域。
因此,对这个问题的回答始终是一致的"是的"。作者根据现实世界中物体是否成功操作得到 GT 结果,形成"是"或"否"作为前一个答案的监督信号。通过实现这个过程,作者使模型能够区分目标域中的有效和无效预测。这个调整使得模型在面临随后的测试样本时能够预测有效的位姿,从而适应特定的实际配置。
4 Experiment Results
Training Details
数据收集。作者采用SAPIEN和PartNet-Mobility数据集来设置一个交互环境,使用基于高效分光栅化的高效渲染器VulkanRenderer。作者使用Franka Panda机器人,配备飞行吸盘作为机器人执行器。作者离线采样约10,000个操作成功样本,覆盖20个类别。作者在可移动部分随机选择一个接触点,并使用其法向量的相反方向作为执行器方向与目标交互。如果成功实现操作,作者将它记录为成功样本。这些任务涉及多个拉动动作原语,其中目标部分的运动方向和执行器方向的相反方向在同一个半球内,即打开抽屉、打开门、旋转钳子、抬盖子等。
训练细节。作者在40G A100 GPU上使用LaMa-Adapter[38]进行微调,共进行10个epoch,每个epoch的成本大约是一个小时。它包括预训练的CLIP[25]作为视觉编码器,7B的LaMa[26]模型作为解码器,以及具有32个transformer层的多元投影模块。在Affordance Prior Reasoning中,n设置为20。
评估指标。作者采用操作成功率来反映操纵的结果,即成功操纵样本数与所有测试样本总数的比例。
关于成功样本的定义,采用二进制成功定义,通过将目标部分的运动距离进行阈值:成功 = 。作者分别设置或作为初始运动或长距离运动,分别表示开始和结束部分1-DoF位姿之间的距离大于0.01或0.1单位长度。初始运动是长距离运动的先决条件,可以有效地反映模型预测的执行器位姿的能力。无论是初始运动还是长距离运动,都应用主动阻力适应策略调整运动方向。
Quantitative Comparison
将ManipLLM与四个代表性的 Baseline 进行了比较,包括Where2Act,UMPNet,Flowbot3D和Implicit3D。为了简单起见,在初始运动设置下进行了比较,因为这样可以反映模型在给定物体初始状态时表现如何,这是实现整个长距离运动的初步条件。为了进行公平的比较,所有方法都在相同的训练/测试划分和执行器设置下进行。
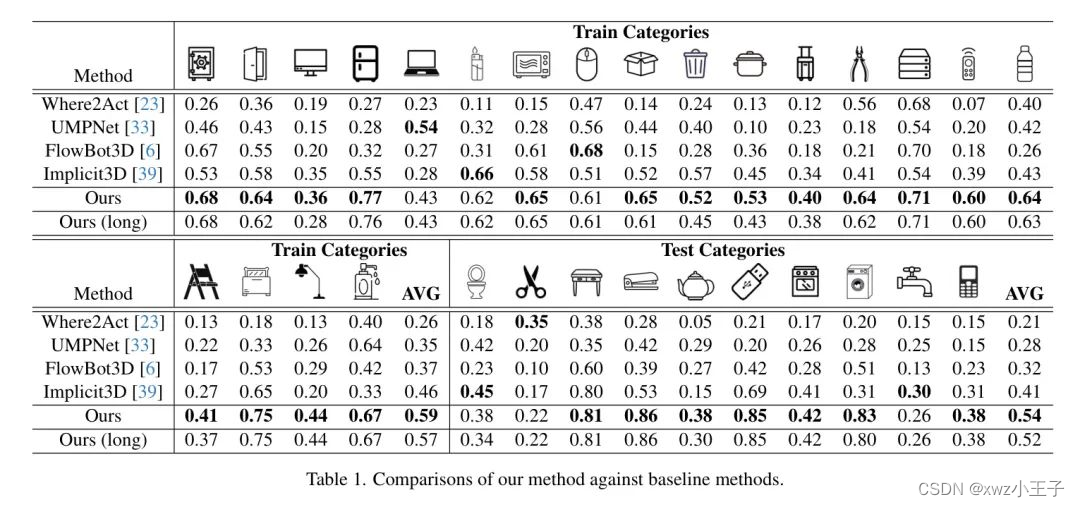
Where2Act: 它将点云作为输入,并估计每个点的分数,选择具有最高分数的点作为接触点。它进一步预测100个执行器姿态,并选择具有最高分数的姿态来构建接触姿态。为了进行公平的比较,作者改变使用的并行夹具为吸盘夹具。
UMPNet: 遵循UMPNet,作者在UMPNet预测的接触点上执行操作,该接触点的方向与物体表面垂直。
Flowbot3D: 它预测点云上的运动方向,将其称为"流"。具有最大流量的点作为交互点,而流的方向表示执行器的位置。
Implicit3D: 它为下游任务开发了一个利用Transporter检测3D可折叠物体关键点的操纵策略。然后使用这些关键点来确定执行器的位置。
作者的实验设置包括在更广泛的物体类别上进行训练。因此,这可能会在这些广泛的类别中提取特征和学习特征的挑战,这可能会导致与原始论文相比的操纵成功率降低。然而,作者的方法通过保留MLLMs的常识推理能力并注入操作能力,确保了在多种类别之间的强泛化。值得注意的是,其他方法在测试时也需要可移动的Mask,而作者的方法可以在不需要可移动部分Mask的情况下实现这一点。
Voxposer: 作者还与VoxPoser进行了"打开抽屉"任务的比较。VoxPoser的成功率为14.0%,而作者的成功率为69.0%。作者发现VoxPoser在处理具有挑战性的案例时,很难找到正确的抓取姿态和合适的移动轨迹。
Ablation and Analysis
为了阐明作者方法中各个模块的贡献和有效性,作者进行了广泛的消融研究。结果是在训练类别的新实例上进行测量,这些实例具有初始运动。
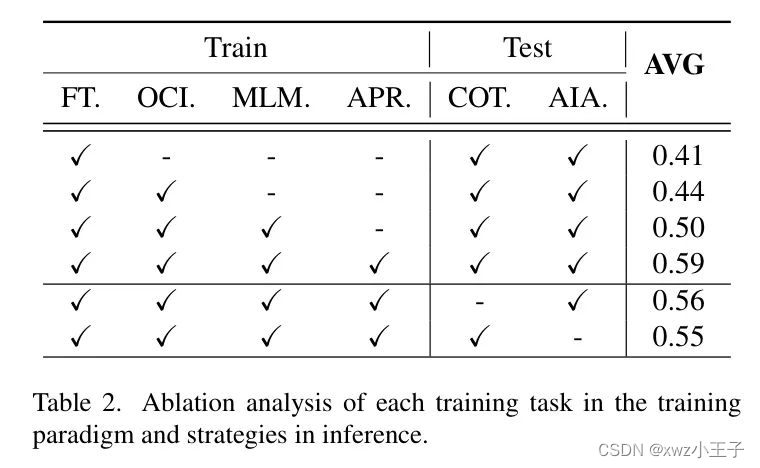
训练范式中任务的有效性。 在表2中逐步将每个任务添加到训练范式中,以显示每个任务的有效性。
微调(FT.): 在表2的第一行中,仅使用微调。图2中的最后一条提示引入这个单一任务使得模型具有某些操作能力,展示了大型模型的强大学习能力。
目标类别识别(OCI.): 接下来,在表2的第二行中引入了目标类别识别任务,即图2中的第一个提示。这使得模型能够发现同一或类似类别中的操作目标的共性,从而通过提高模型的操作能力3%,增强了模型的操作能力。
Mask语言模型(MLM.): 然后,在表2的第三行中,也是图2中的第三个提示,随机屏蔽坐标或方向向量的值,迫使模型预测精确的位姿。这个任务刺激了模型之前缺乏的定位能力,并使模型能够将常识推理的方向映射到SO(3)方向表示,从而提高了性能16%。
先验力场推理(APR.): 最后,在表2的第四行中引入了先验力场推理任务,即图2中的第二个提示。这使得模型能够学习到操作感知的局部化,并预测准确的接触位置。因此,它显著提高了操作成功率,提高了9%。
推理策略的有效性。 连续思维推理(COT):连续思维推理策略旨在使模型在透明和合理思考过程中生成最终位姿预测。为了进行比较,作者在图4中不使用推理过程直接让模型生成最终位姿预测。如图2的最后一行无COT的表2部分所示,作者发现这比在推理过程中应用COT减少了3%的性能。这强调了使模型在透明和可解释的过程中预测的重要性。
主动阻尼自适应(AIA.): 主动阻尼自适应策略在阻尼控制下适应性地调整位姿以适应当前物体状态。在无AIA.的表2最后一行中,作者使用一个直接的控制策略,该策略在不变的方向下直接移动到所需位置。相比之下,主动阻尼自适应策略根据力反馈有效地调整方向,从而在长期运动中实现平滑操纵轨迹,并改善远程运动,减少了4%。这种策略对于远程运动尤其重要,如果没有应用,性能将从0.57下降到0.50。
Real-world Evaluation
作者进行了涉及与各种实际家居目标的交互实验。作者使用Franka Emika机器人手臂,带有Cobot泵吸盘,并使用RealSense 415相机捕捉RGB图像和深度图。
为了应对模拟到实际(sim-to-real)问题:
在训练期间,使用在实际世界中预训练的LLAMA-Adapter,并采用结合注入和微调的 Adapter 方法使其学习新下游任务。这种训练策略允许模型在保留实际世界中的强大感知和推理能力的同时,为其配备执行新操作任务的能力。
在模拟器中收集数据时,使用领域随机化来增加场景多样性,例如更改物体部件姿势、相机视角和照明等因素,以减轻潜在的模拟到实际差距。
在测试期间,设计了一个针对操作任务的测试时自适应策略,以帮助模型更好地适应当前场景的配置。通过仅在视觉模块中微调 Adapter,可以转移其注意力,使MLLMs能够生成更适合当前场景的预测。
实际实验的结果如表3所示。
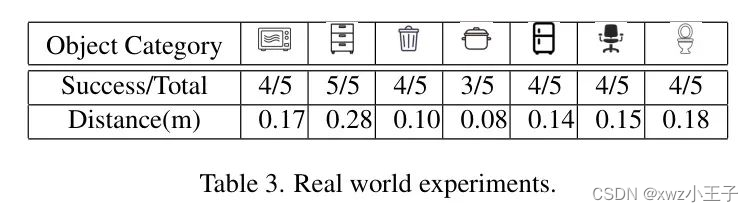
如图5所示设计的TTA策略有效地解决了实际硬件配置带来的差异。在特定的硬件配置中,由于吸盘无法抓住把手,因为表面不平滑。

此外,它的 Head 相对较短,当与突出把手近距离互动时,存在碰撞风险。TTA过程从成功和失败的场景中学习,逐渐适应其预测与当前配置一致。由于这种策略是即插即用的,在补充中,在处理未见过的类别物体时,进一步在模拟器中应用它,以展示其有效性。
5 Conclusion
通过连续思维训练范式将MLLMs转换为机器人操作,并为模型配备预测位姿的能力。作者引入了一个主动阻尼自适应策略,根据正确状态的力反馈调整方向,以确保平滑的运动轨迹。
ManipLLM在广泛的类别和实际场景中展示了强大的泛化能力。

