
- 1用JS写一段调用微信apl可以实现一键打视频的代码
- 2万字长文教你使用安卓内核驱动进行内存读写_安卓读取内存数据
- 3使用selenium驱动浏览器时携带cookie实现模拟登陆_java selenium添加cookie实现登录
- 4【生产力】VSCode 插件 Draw.io Integration_draw.io integration vscode
- 5vue 打包失败 This is probably not a problem with npm. There is likely additional logging output above_vite+vue3项目运行成功打包失败this is probably not a problem
- 6Ubuntu22.04部署K8s集群_ubuntu22关闭虚拟内存
- 7cmd外部命令1ping命令详解
- 8python中文语料分词处理,按字或者词cut_sentence
- 9uniapp 调用安卓原生插件 安卓原生又调用了第三方sdk(第三方原生开发的aar怎么转成uni可以使用的aar)_uniapp调用第三方sdk
- 10Spring Cloud Gateway 彻底解决Exceeded limit on max bytes to buffer : 262144报错问题
大数据毕业设计hadoop+spark+hive知识图谱音乐推荐系统 音乐数据分析可视化大屏 音乐爬虫 LSTM情感分析 大数据毕设 深度学习 机器学习 人工智能 大数据毕业设计 计算机毕业设计
赞
踩
1 本科生毕业论文(设计)开题报告应包括以下六个方面内容:
- 选题的目的和意义;
互联网在如今的爆发式发展已经改变了我们的生活方式,互联网上资源的爆发式增长让获取有效信息成为了新的难题。用户接触到的信息非常有限。于是很多提出帮助用户快速精准找到所需信息的解决方案诞生了,例如搜索引擎,推荐系统等。
目前大型的音乐门户类网站的歌曲库规模往往包含上千万首的歌曲,这些歌曲被划分成不同的语种、流派、年代、主题、心情、场景等,包含的信息非常的丰富,存在着严重的信息过载。对于系统中每一位音乐用户来说,都不可能去收听曲库内的每一首歌, 很多时候用户的需求往往是“一首或几首好听的歌曲”这种模糊的需求,如何根据用户在系统中产生的行为信息去庞大的歌曲库中挖掘出用户可能感兴趣的音乐,这就需要个性化音乐推荐系统综合考虑用户偏好、时间、地点、环境等各种复杂的特征,准确的从上千万的海量歌曲库中挑选出此时此刻最适合这个用户聆听的个性化音乐,给广大的用户带来美的享受,真正做到众口可调。
- 研究(应用)现状;
国内的音乐推荐技术发展相对缓慢。大多数音乐网站采用的技术不够成熟,基本上是针对所有用户,大数据成分太少。不过,经过一段时间的发展,国内也涌现出了一些优秀的音乐推荐网站,比如 SongTaste、虾米网和豆瓣网等。SongTaste 是一个社交性质的音乐网站。在它的社区中,每一个用户都可以看到大家最近在收听什么音乐、有什么新的音乐推荐。它的音乐分类相当齐全,而且推荐排行实时更新。另外,根据用户平时推荐的音乐、听歌行为以及音乐收录信息,还能够找到“相似的品味者”,从而更好地做出推荐。豆瓣网也是一个社交性的音乐推荐网站。它主要通过豆瓣小组、新浪微博、MSN、开心网、人人网等互动平台来分享和传播用户喜欢的音乐。虾米网在注册成为网站会员时会让用户选择至少5位艺人进行收藏,以此来初步确定用户欣赏音乐的倾向。另外,用户还可以从大家的推荐中搜索自己喜爱的音乐,或者从品味相似的好友中找到适合自己的音乐。
国外研究现状:大数据推荐系统的定义是 Resnick 和 Varian 在 1997 年给出的:“它是利用电子商务网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销售人员帮助客户完成购买过程”。从最初在电子商务网站的深度剖析,到当下在的音乐、电影、学习资料等不同领域的广泛应用。在三十多年的时间里,大数据推荐系统一直是学术界和工业界的关注的焦点。其优点在于主动性。它能自发地收集并分析用户的行为数据,为用户的兴趣建模,得到用户的兴趣偏好后,匹配系统中资源的特征,为用户做出有效的大数据推荐。同时,推荐引擎要一直监测系统中的项目变化和用户在不同行为下的兴趣特征变迁,针对不同的变动,做出相应推荐策略的调整。各平台为增加用户的黏着性,以及用户对推荐结果的准确度要求,使得推荐系统的核心技术层出不穷,比较成熟的推荐技术有:基于内容的推荐、协同过滤(基于相似度的最邻近协同过滤算法、基于潜在因子的矩阵分解推荐算法)、深度学习、基于标签的推荐系统、混合推荐算法等。
发展趋势:由音乐治疗的研究成果和临床案例可以发现,音乐的某些物理属性能够与人的神经系统产生共鸣,进而引发人体生理指标的有益变化。并且,音乐还能创造出一种心理律动,这种心理律动与人的生理结构及功能是极为一致的。因此,根据不同人的生理心理反应,可以对应出不同疗效的音乐,由此实现大数据的音乐推荐。
针对目前音乐推荐技术存在的问题,从“人文关怀”的角度出发,提出了一种新的音乐推荐技术的研发方向,即把人的生理指标和心理状态同特定的音乐类型联系起来,通过某些生理参数的变化并结合实时的情绪状态来寻求匹配的音乐资源,由“生理-音乐-心理”模型作为依托,实现音乐推荐的功能,从而达到音乐治疗的目的,帮助用户舒缓压力、愉悦身心。这种推荐模式的建立,需要对大量个体进行实验。
首先,使用医学仪器测量人的生理参数,试图发掘这些参数的变化规律;
其次,通过心理学问卷分析人的心理情绪,由此形成用户信息模型; 再次,对音乐库中的音乐进行人工标注,依据情感特征形成不同分类;
最后,进行音乐试听的主观实验,由统计分析结果得到生理心理和音乐类型之间的关联,由此建立数学模型。这项新技术的研发,可以有效避免音乐推荐的商业化行为。
因为它完全不用比较音乐的点击率、用户关注度和评价信息,因此不会产生冷启动、稀疏性和扩展性问题,而对于用户心理或情绪上的波动又具有明显的针对性,不失为一种大数据的音乐推荐技术。
- 研究(设计)内容;
统采用在线层+离线层的形式,离线层训练数据,在线层搭建应用系统。
功能简介:系统采用在线层+离线层的形式,离线层训练数据,在线层搭建应用系统。
系统开发内容:
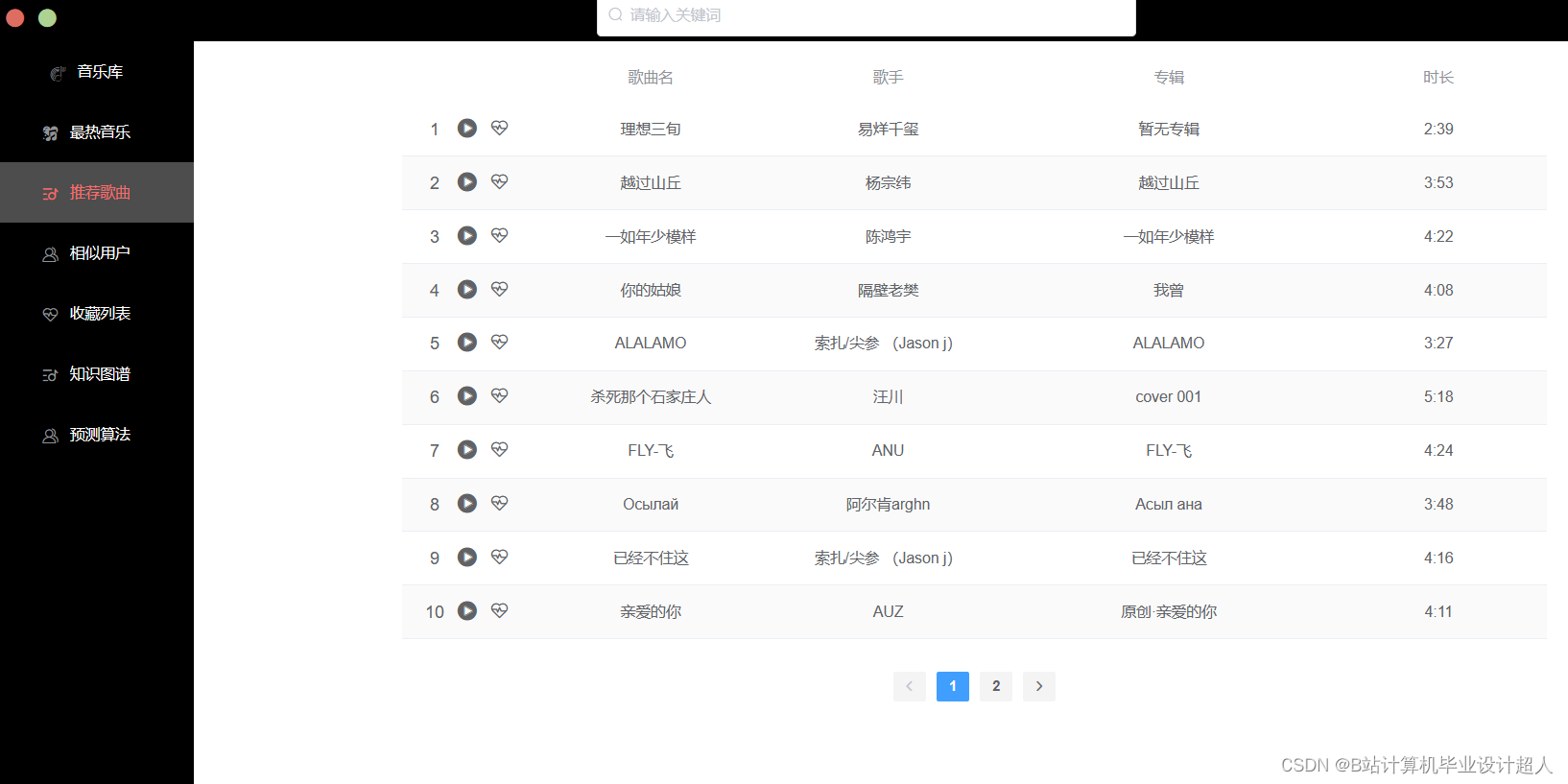
第一部分:爬虫爬取音乐数据(网易云音乐网站),作为测试的数据集
第二部分:离线推荐系统:python+机器学习离线推荐(基于物品的协同过滤算法,相似度衡量方法:皮尔逊相似度) ,必要时可以集成算法框架比如tensflow pytroch等,推荐结果通过pymysql写入mysql
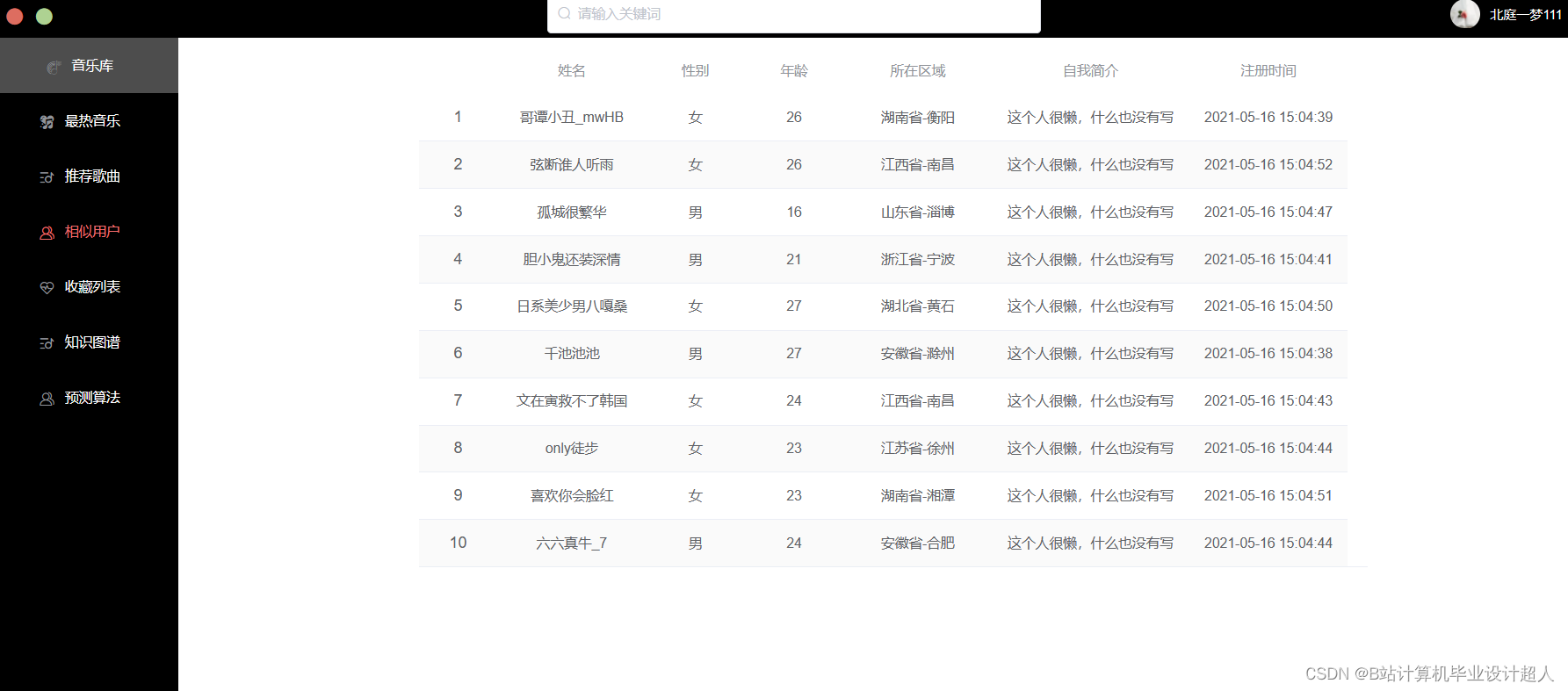
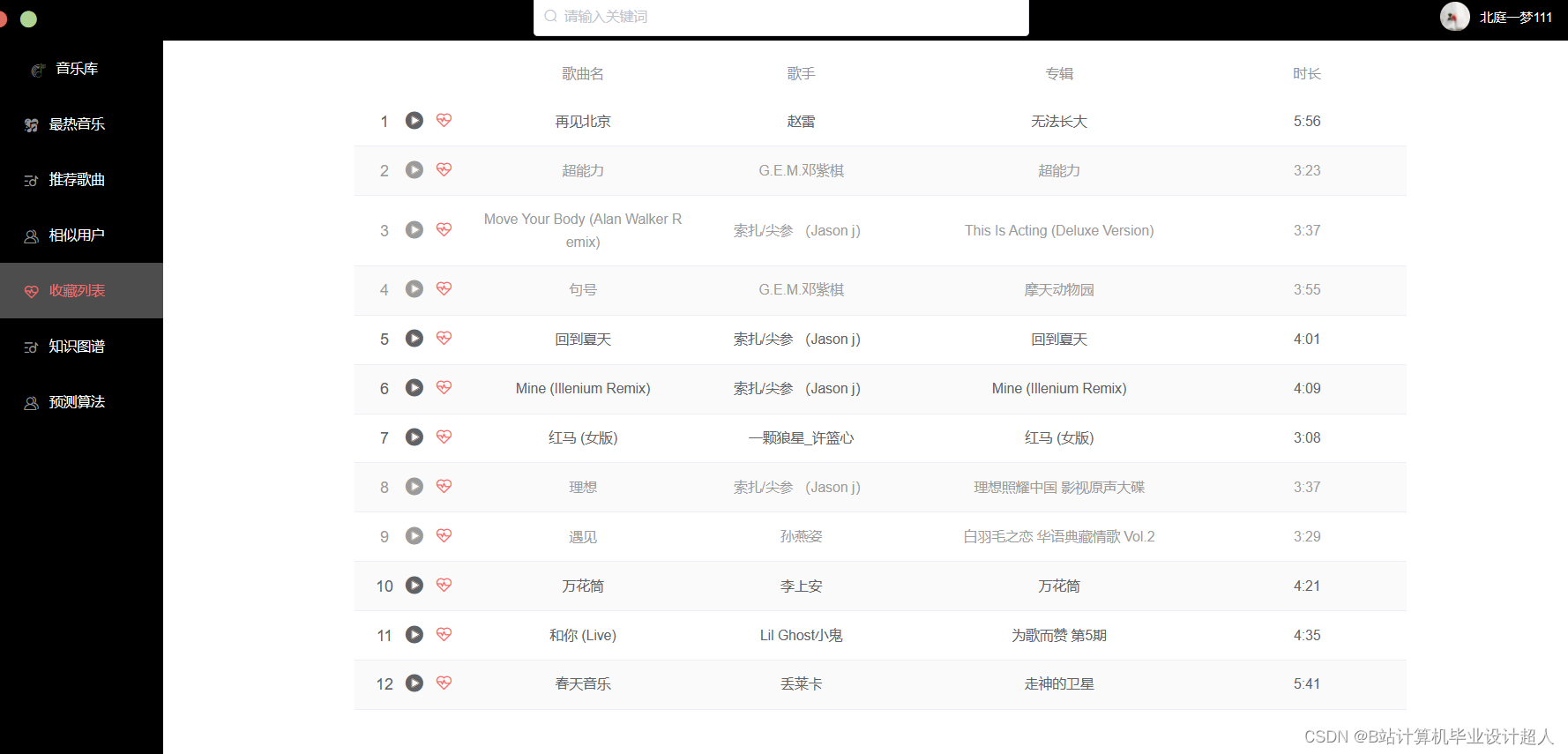
第三部分:在线应用系统: springboot进行在线推荐 vue.js构建推荐页面(含知识图谱)
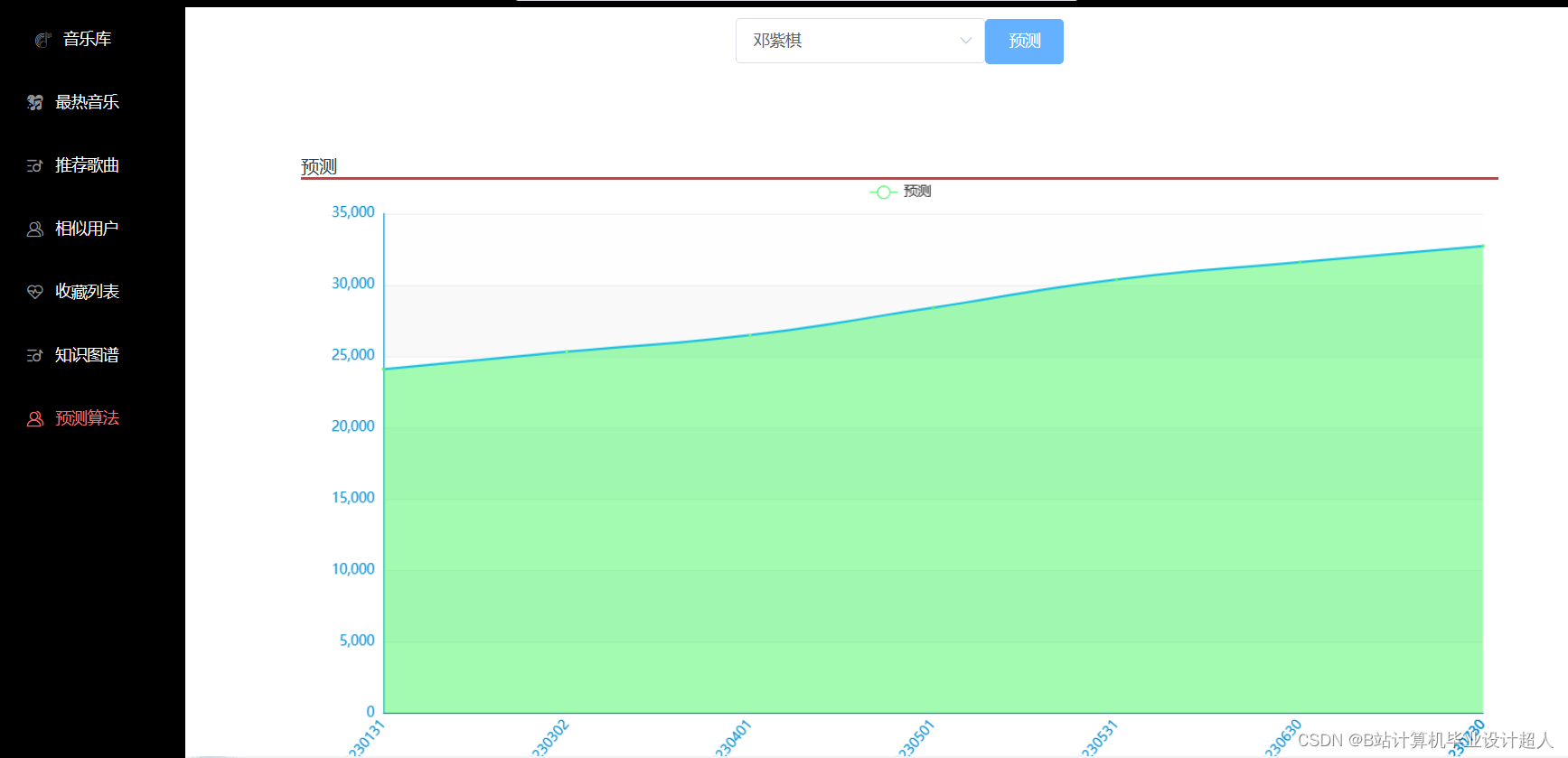
第四部分:使用Spark构建大屏统计
- 研究方法(思路)及技术路线;
思路:
系统实现用户对音乐评分的搜集(python爬虫爬取数据),后端使用大数据推荐算法构造,前端使用Vue框架搭建大数据音乐推荐系统。系统数据库使用了关系型数据库MySQL。前端收集过用户行为数据后传到后端使用基于用户的协同过滤算法来推荐出用户可能喜欢的音乐。采用BS架构,使用Java程序设计语言、MySQL数据库、Spark实时分析、Java开发工具IDEA编写程序、Tomcat模拟服务器、Java的JDK8运行环境、Navicat等工具开发而来。
技术路线:
Hadoop、Spark、SparkSQL、Python、MySQL、协同过滤算法、皮尔逊相关系数、KNN、echarts可视化、阿里云短信接口、支付宝沙箱支付、百度AI身份证自动识别、SpringBoot、Vue.js、MyBatis-Plus
- 预期结果;
基于大数据+知识图谱的音乐推荐管理系统是针对当前火热的大数据技术,在海量歌曲的管理基础上,让用户具有更好的使用体验,对有相同品味的用户,推荐可能喜欢的歌曲,在提升音乐平台的高可用性的同时,通过智能推荐提升用户对此音乐平台的好感度。
- 参考文献;
[1]LAWRENCERD, ALMASIGS, KOTLYARV, et al. Personalization of supermarket product recommendations[ R]. IBM Research Report,2000(7):173-181
[2]徐小伟. 基于信任的协同过滤推荐算法在电子商务推荐系统的应用研究. 东华大学. 2013
[3] 吴正洋. 个性化学习推荐研究. 华南师范大学期刊.2021
[4]李雪. 基于协同过滤的推荐系统研究. 吉林大学. 2010
[5]《数据库系统概论》[M],高等教育出版社
[6]马建红.JSP应用与开发技术.第三版.清华大学出版社.2018
[7] JavaEE架构设计与开发实践[M],方巍著:清华大学出版社.2018.1
[8] Spring Boot编程思想核心篇[M],小马哥著:电子工业出版社.2019.4
[9] Spring Boot开发实战M].吴胜著:清华大学出版社.2018.6
[10]Oleg Sukhoroslov. Building web-based services for practical exercises in parallel and distributed computing[J]. Journal of Parallel and Distri
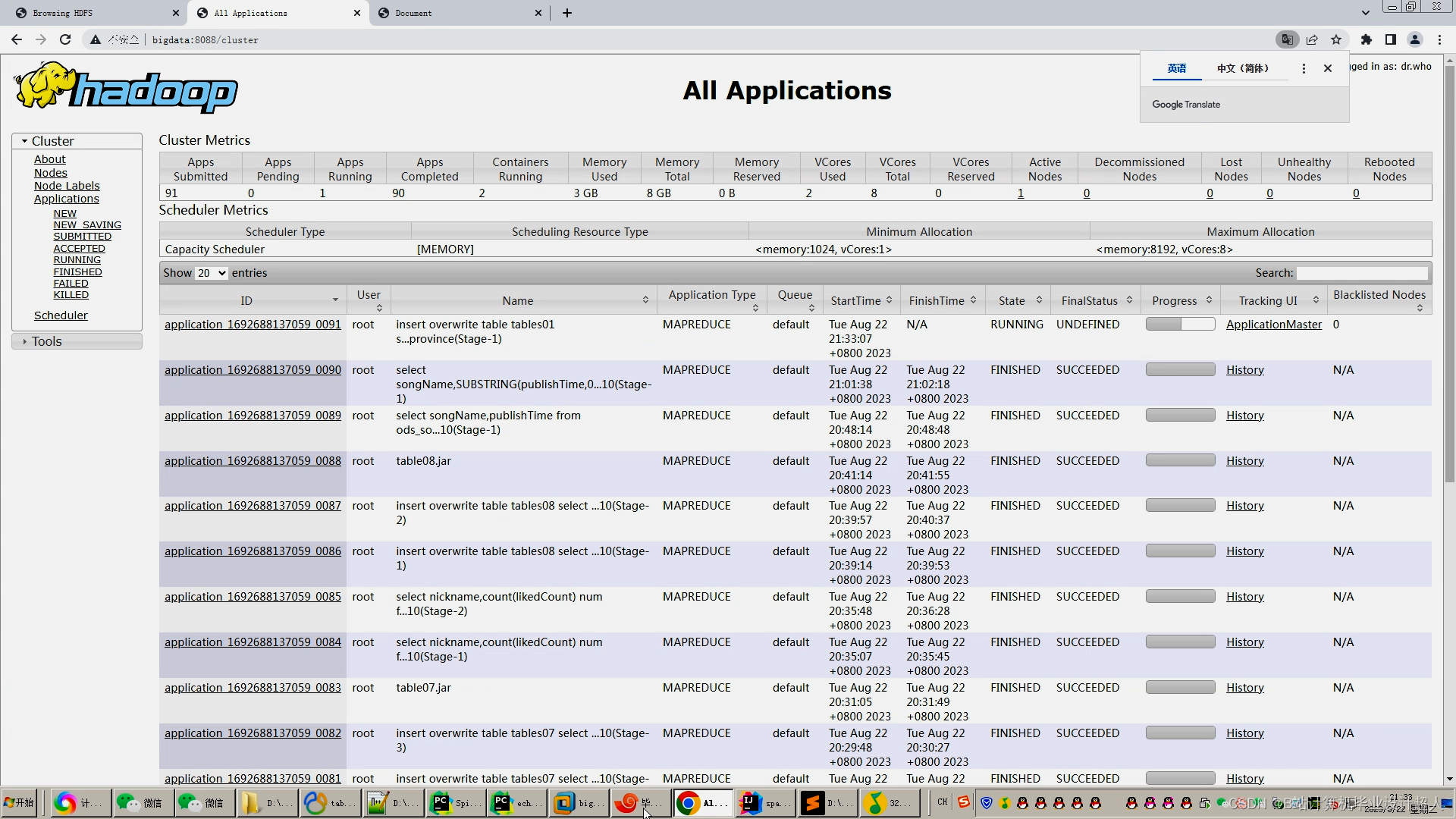

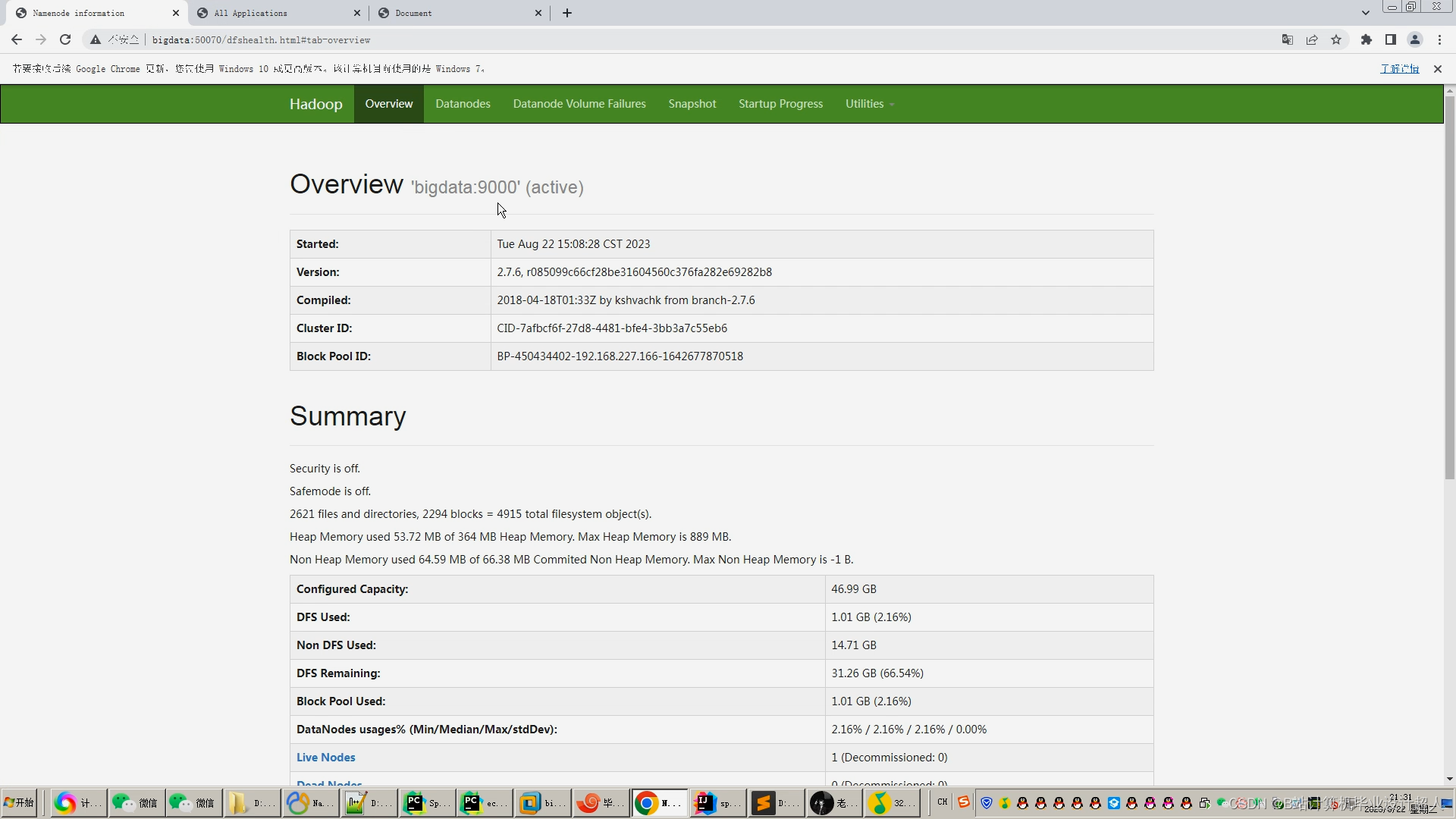

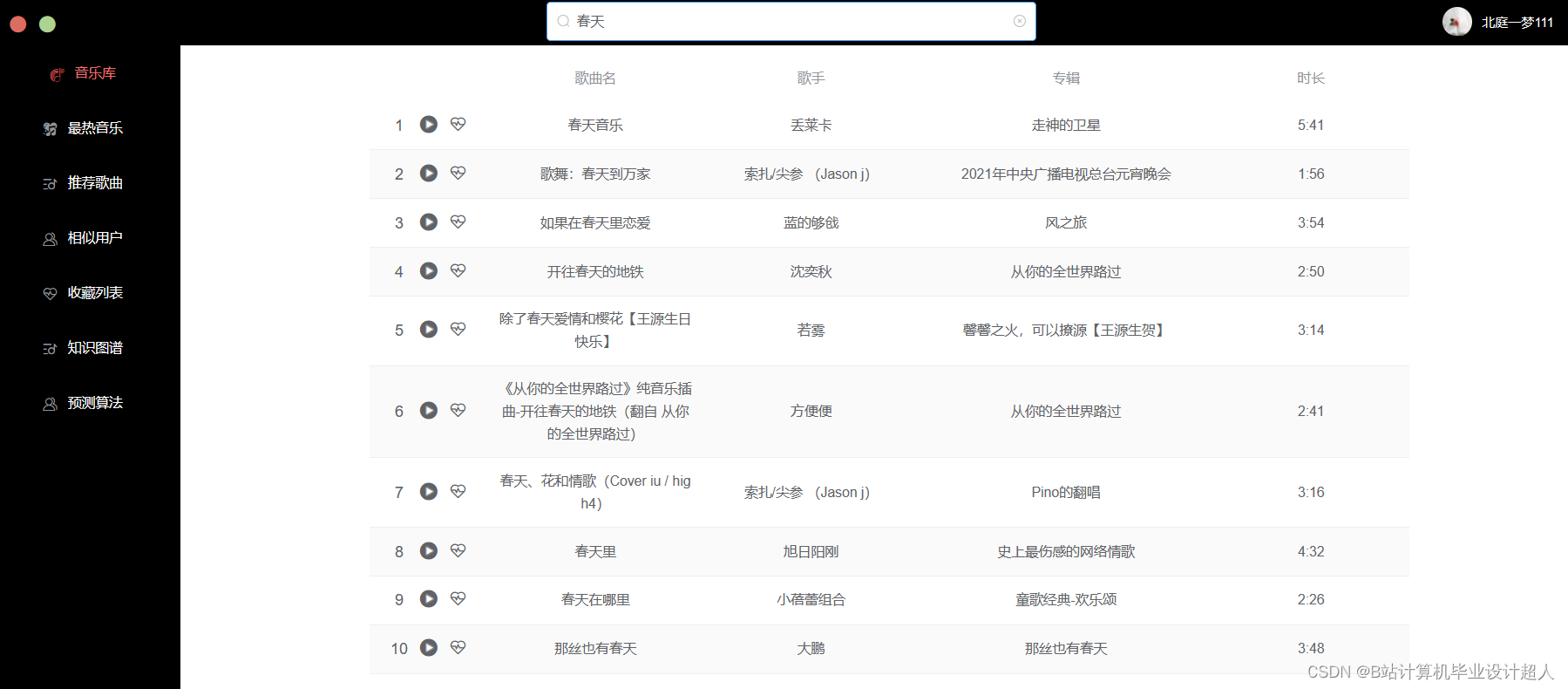
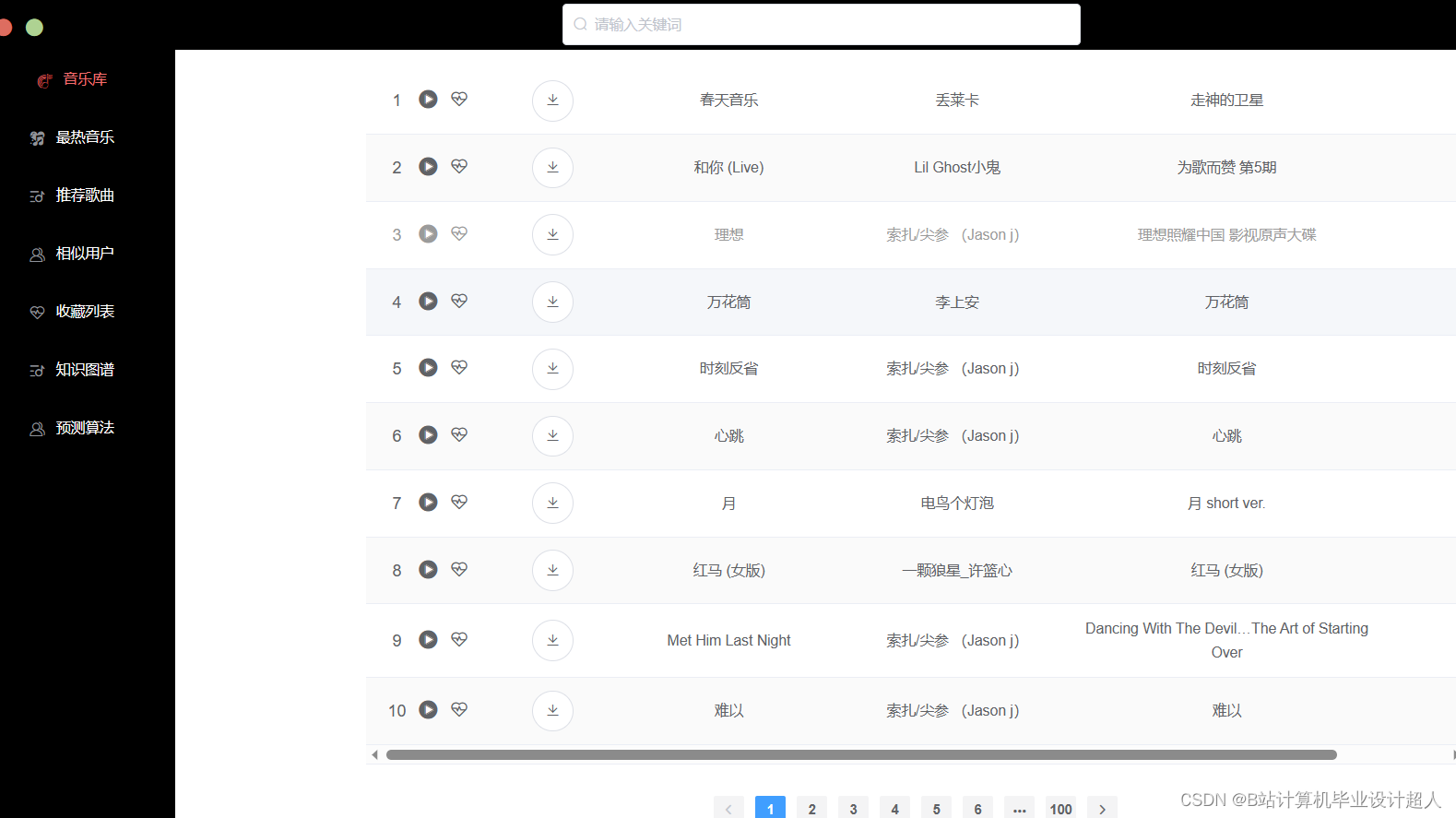


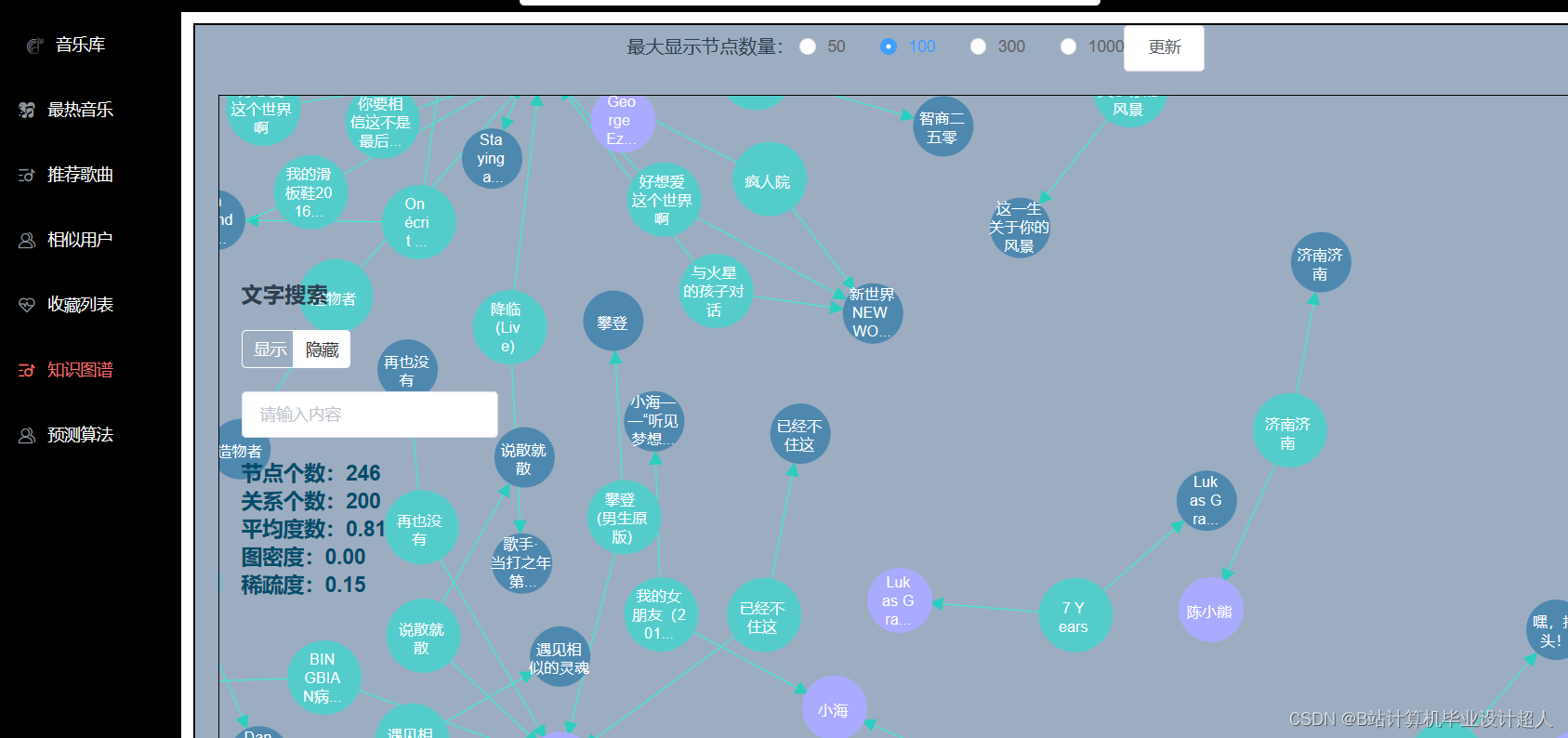
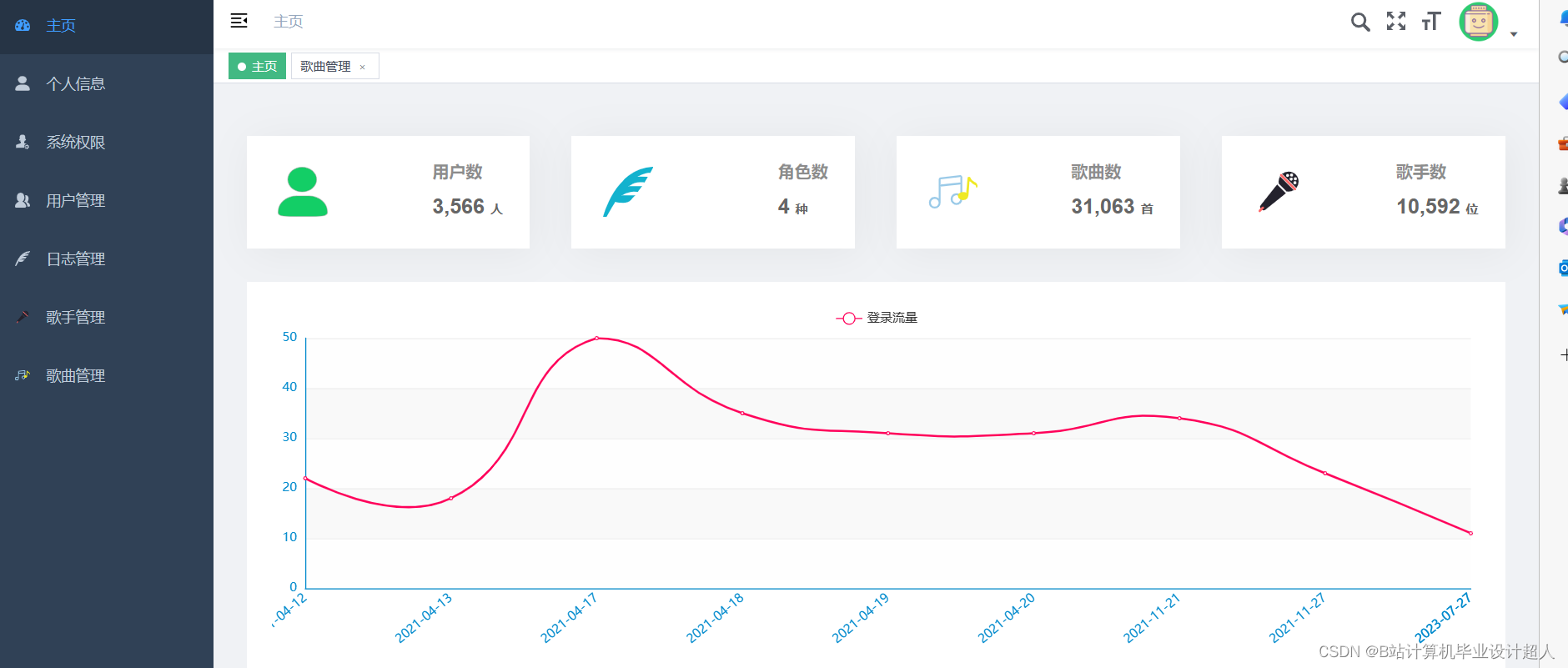
核心代码分享如下:
- # 基于皮尔逊相似的的物品推荐
- from __future__ import (absolute_import, division, print_function
- , unicode_literals)
- import os
- import io
-
- from surprise import KNNBaseline
- from surprise import KNNBasic
- from surprise import SVD
- from surprise import Dataset
- from surprise import Reader
-
-
- # def read_item_names():
- # """
- # 获取歌曲名称到歌曲id 和 歌曲id到歌曲名的映射
- # :return: 两个字典
- # rid_to_name:键为rid,值为name,只有一个键值对
- # name_to_rid = {}键为name,值为rid,只有一个键值对
- # """
- # file_name = ('./dataset/song_info.txt')
- # rid_to_name = {}
- # name_to_rid = {}
- # # 打开文件,并指定编码格式(这里是该数据要求的指定格式)
- # with io.open(file_name, 'r', encoding='utf-8') as f:
- # next(f) # 跳过第一行的列名称,从第二行开始读
- # # 每次读取一行,并且每一行中的各个元素使用制表符 ”\t“ 隔开
- # for line in f:
- # # 将每个元素转存到数组中
- # line = line.split('\t')
- # # 第一个元素为歌曲id,第二个元素为歌曲名称
- # rid_to_name[line[0]] = line[1]
- # name_to_rid[line[1]] = line[0]
- # return rid_to_name, name_to_rid
-
- def get_rid2name(file_name):
- """
- 获得名称到id 和 id到名称的映射,包括歌曲或用户等的映射
- :param file_name: 需要解析的文件路径名,且文件中每行的第一列为id,第二列为名称,使用制表符隔开
- :return: 两个字典
- rid_to_name:键为rid,值为name,只有一个键值对
- name_to_rid = {}键为name,值为rid,只有一个键值对
- """
- rid_to_name = {}
- name_to_rid = {}
- # 打开文件,并指定编码格式(这里是该数据要求的指定格式)
- with io.open(file_name, 'r', encoding='utf-8') as f:
- # next(f) # 跳过第一行的列名称,从第二行开始读
- # 每次读取一行,并且每一行中的各个元素使用制表符 ”\t“ 隔开
- for line in f:
- # 将每个元素转存到数组中
- line = line.split('\t')
- # 第一个元素为id,第二个元素为名称
- rid_to_name[line[0]] = line[1]
- name_to_rid[line[1]] = line[0]
- return rid_to_name, name_to_rid
-
-
- # 获取歌曲名称到歌曲id 和 歌曲id到歌曲名的映射
- item_rid_to_name, item_name_to_rid = get_rid2name('dataset/min_song_info.txt')
-
- # 得到用户名称到id 和 用户id到名称的映射
- user_rid_to_name, user_name_to_rid = get_rid2name('./dataset/user_info.txt')
-
-
- # print(rid_to_name.values())
- # 映射结果如下
- # print(rid_to_name["1"])
- # print(name_to_rid.values())
-
-
- def get_trainset_algo():
- """
- 算法使用训练集进行训练
- :return: 训练之后的结果
- """
- # 指定数据格式
- reader = Reader(line_format='user item rating timestamp', sep='\t', skip_lines=0, rating_scale=(0, 100))
- # 文件路径
- file_path = os.path.expanduser('./dataset/min_user_record.txt')
- # 加载数据集
- data = Dataset.load_from_file(file_path, reader=reader)
- # 将数据集转换成矩阵形式
- trainset = data.build_full_trainset()
- print(trainset.all_items())
- print(trainset.all_users())
-
- # 基于物品的协同过滤算法,相似度衡量方法:皮尔逊相似度
- # 这是一个用户数量N,矩阵大小为 N*N 的稀疏矩阵,然后get_neighbors得到的是topK个相似用户。如果想要得到相似歌曲,则需要使用基于项目的协同过滤算法,
- # 或者从得到的相似用户中,提取他们的播放记录(这是基于用户的协同过滤算法)
- sim_options = {'name': 'pearson_baseline', 'user_based': True}
- # 选择算法
- algo = KNNBaseline(sim_options=sim_options)
- # algo = KNNBasic(sim_options=sim_options)
-
- # 训练数据集
- print('开始训练······')
- algo.fit(trainset)
- print('训练结束')
- return algo
-
-
- # 得到训练之后的结果
- algo = get_trainset_algo()
-
-
- def get_topN_items(current_item_raw_id, topK):
- """
- 得到指定物品的top-N个相似物品
- :param current_item_raw_id: 物品的原始id,必须为字符串类型
- :param topK: 相似度高的前topK首歌曲
- :return: 当前歌曲的相似歌曲id列表
- """
-
- # 得到训练之后的结果
- # algo = get_trainset_algo()
-
- print("歌曲原始id:")
- print(current_item_raw_id)
- # 得到矩阵中的歌曲id(内部id),参数为字符串格式
- current_song_inner_id = algo.trainset.to_inner_iid(current_item_raw_id)
- print("歌曲内部id:")
- print(current_song_inner_id)
- # 相似歌曲推荐,得到的是相似歌曲的内部id,得到topK个
- current_song_neighbors = algo.get_neighbors(current_song_inner_id, k=topK)
- # 推荐歌手的内部id如下
- print("推荐歌曲的内部id:")
- print(current_song_neighbors)
- # 从相似歌曲的内部id得到原始id
- current_song_neighbors = (algo.trainset.to_raw_iid(inner_id)
- for inner_id in current_song_neighbors)
- # 从相似歌曲的原始id得到相似歌曲的名称
- current_song_neighbors = (item_rid_to_name[rid]
- for rid in current_song_neighbors)
- # 存储topN首歌曲的id
- topN_items_id = []
- print("推荐歌曲如下:")
- for song in current_song_neighbors:
- topN_items_id.append(item_name_to_rid[song])
- print(item_name_to_rid[song], song)
-
- return topN_items_id
-
-
- # 32835565对应的歌曲名为:国王与乞丐,返回相似的前30首歌曲
- get_topN_items('448317748', 30)
-
-
- def get_topN_users(current_user_raw_id, topK):
- """
- 获得相似音乐好友推荐
- :param current_user_raw_id: 当前用户id
- :param topK: 相似度高的前topK个相似音乐好友
- :return: 当前用户的相似音乐好友id数组
- """
-
- # 得到训练之后的结果
- # algo = get_trainset_algo()
-
- # 给定一个歌曲名称,并得到它的歌曲id(原始id)
- # current_user_raw_id = user_name_to_rid['北庭一梦']
-
- print("用户原始id:")
- print(current_user_raw_id)
- # 得到矩阵中的用户id(内部id),方法是algo.trainset.to_inner_uid(uid),参数为字符串格式
- current_user_inner_id = algo.trainset.to_inner_uid(current_user_raw_id)
- print("用户内部id:")
- print(current_user_inner_id)
-
- # 相似音乐好友推荐,得到的是相似音乐好友的内部id,得到topK个
- current_user_neighbors = algo.get_neighbors(current_user_inner_id, k=topK)
-
- # 推荐相似好友的内部id如下
- print("推荐用户的内部id:")
- print(current_user_neighbors)
- # 从相似音乐好友的内部id转化为原始id
- current_user_neighbors = (algo.trainset.to_raw_uid(inner_id)
- for inner_id in current_user_neighbors)
- # 从相似音乐好友的原始id得到名字
- current_user_neighbors = (user_rid_to_name[rid]
- for rid in current_user_neighbors)
-
- # 存储topN个用户的id
- topN_users_id = []
- print("推荐相似好友如下:")
- for user in current_user_neighbors:
- topN_users_id.append(user_name_to_rid[user])
- print(user_name_to_rid[user], user)
-
- return topN_users_id
-
-
- # 338663754对应的用户名为:北庭一梦,返回前十个最相似的用户
- # users_id_list = get_topN_users('338663754', 10)
-
- # init_id = '338663754' + '\t'
- # for id in users_id_list:
- # init_id = init_id + id + ','
- # print(init_id.strip(','))
-
- # 获得每首歌曲的相似歌曲推荐
- def get_all_topN_songs():
- """
- 从文件中读取歌曲信息,然后根据基于用户的协同过滤推荐算法,推荐出每一首歌曲的相似歌曲,并将相似歌曲对应的id存到文件汇总,形成倒排链表
- 格式为:当前歌曲id 相似歌曲id1,相似歌曲id2···
- :return:
- """
- song_info_file_name = 'dataset/min_song_info.txt'
- all_topN_songs_file_name = 'resultset/topN_songs_baseline.txt'
- with open(song_info_file_name, 'r', encoding='utf-8') as input_f, open(all_topN_songs_file_name, 'a',
- encoding='utf-8') as output_f:
- for line in input_f:
- # 获得歌曲id
- song_id = line.split('\t')[0]
- print('获得' + item_rid_to_name[song_id] + '的推荐结果:')
- line = song_id + '\t'
- # 将得到的结果拼接成字符串
- for id in get_topN_items(song_id, 20):
- line = line + id + ','
- # 写入到文件中
- output_f.write(line.strip(',') + '\n')
- output_f.flush()
-
- # 关闭文件输入输出流
- input_f.close()
- output_f.close()
-
-
- # get_all_topN_songs()
-
-
- # 获得每个用户的相似音乐好友推荐
- def get_all_topN_users():
- """
- 从文件中读取用户信息,然后根据基于用户的协同过滤推荐算法,推荐出每一个用户的相似音乐好友,并将音乐好友对应的id存到文件汇总,形成倒排链表
- :return:
- """
- # 输入文件路径和结果文件路径
- user_info_file_name = './dataset/user_info.txt'
- all_topN_users_file_name = 'resultset/topN_users_baseline.txt'
-
- with open(user_info_file_name, 'r', encoding='utf-8') as input_f, open(all_topN_users_file_name, 'a',
- encoding='utf-8') as output_f:
- for line in input_f:
- # 获得用户id
- user_id = line.split('\t')[0]
- line = user_id + '\t'
- # 将结果拼接成字符串
- for id in get_topN_users(user_id, 10):
- line = line + id + ','
- # 写入到文件中
- output_f.write(line.strip(',') + '\n')
- output_f.flush()
- # 关闭文件输入输出流
- input_f.close()
- output_f.close()
-
- # 获取所有用户的相似好友
- get_all_topN_users()


