
- 1程序好思路分享 计算机毕业设计Hadoop+Spark交通大数据 地铁客流量分析大数据 数据仓库 大数据毕业设计 大数据毕设_基于hadoop的交通信息分析系统的设计与实现
- 2华为海思校园招聘-芯片-数字 IC 方向 题目分享——第九套
- 3去了阿里巴巴,我才知道年薪百万的软件测试人这么多!_阿里巴巴测试工资待遇
- 4大学生论文AIGC检测率,多少为合格?_aigc检测率为多少合格
- 5在下载huggface当中用了梯子依旧出现host=‘huggingface.co‘, port=443应该怎样解决,必有效版本!_curl huggingface.co
- 6自然语言处理 情绪识别_基于自然语言处理的情感分析实验报告
- 7Flutter和iOS原生性能对比测试
- 8论文阅读——BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- 9Java助农农产品销售平台系统设计与实现(Idea+Springboot+mysql)_基于java web技术农产品销售平台的设计与实现
- 10StarRocks X Flink CDC,打造端到端实时链路_实时数据链路
Prompt提示工程上手指南:基础原理及实践(四)-检索增强生成(RAG)策略下的Prompt_rag常用的prompt设计
赞
踩
前言
此篇文章已经是本系列的第四篇文章,意味着我们已经进入了Prompt工程的深水区,掌握的知识和技术都在不断提高,对于Prompt的技巧策略也不能只局限于局部运用而要适应LLM大模型的整体框架去进行改进休整。较为主流的LLM模型框架设计可以基于链式思考(CoT)、思维树 (ToT)和检索增强生成 (RAG)。其中RAG框架可以算得上是AI平台研发的老生常谈之一了,因为无论是个人还是企业,都想要培养出一个属于自己领域专业的AI。但伴随而来的问题,不限于产生幻觉、缺乏对生成文本的可解释性、专业领域知识理解差,以及对最新知识的了解有限。
相对于成本昂贵的“Post Train”或“SFT”解决办法,最好的技术方案还就是基于RAG框架而设计,RAG框架的核心,就像是一位内置的智能搜索引擎,能够精准地定位到与用户查询最相关的知识库内容或对话历史。这种能力使得RAG不只是回答问题,而是通过创造丰富的提示(prompt),引导模型生成更加准确、信息丰富的输出。如何在保证模型效率的同时,提高其在特定领域的精准度和可靠性?又如何避免过度依赖检索内容,确保生成的文本既新颖又具有创造性?通过探索RAG框架及其精妙的Prompt策略,我们不仅能够解锁大型语言模型的新潜能,还能够为未来的AI研究和应用指明方向。随着本文深入,我们将一起探索RAG框架背后的工作原理以及对应Prompt策略,它将如何成为连接用户需求与海量数据之间桥梁的关键技术,以及在实际应用中如何发挥出惊人的效能。
每篇文章我都会尽可能将简化涉及到垂直领域的专业知识,转化为大众小白可以读懂易于理解的知识,将繁杂的程序创建步骤逐个拆解,以逐步递进的方式由难转易逐渐掌握并实践,欢迎各位学习者关注博主,博主将不断创作技术实用前沿文章。
RAG框架概述
想象一下,当你在写一篇文章或解决一个问题时,如果遇到了难题,你会怎么做?可能会去搜索引擎查找信息,然后基于找到的信息来构建你的答案。这个过程,其实很像是RAG框架在做的事情。化繁为简,我们先来了解RAG到底是什么。先从字母意思开始理解,RAG——Retrieval Augmented Generation,正如其名,是一种将检索(Retrieval)和生成(Generation)结合起来的技术。它首先从一个巨大的知识库中检索出与提出的问题最相关的信息,然后基于这些信息来生成回答。这样做的好处是,它允许模型不仅依赖其已有的知识,还可以实时地利用外部数据来提供更准确、更丰富的回答。
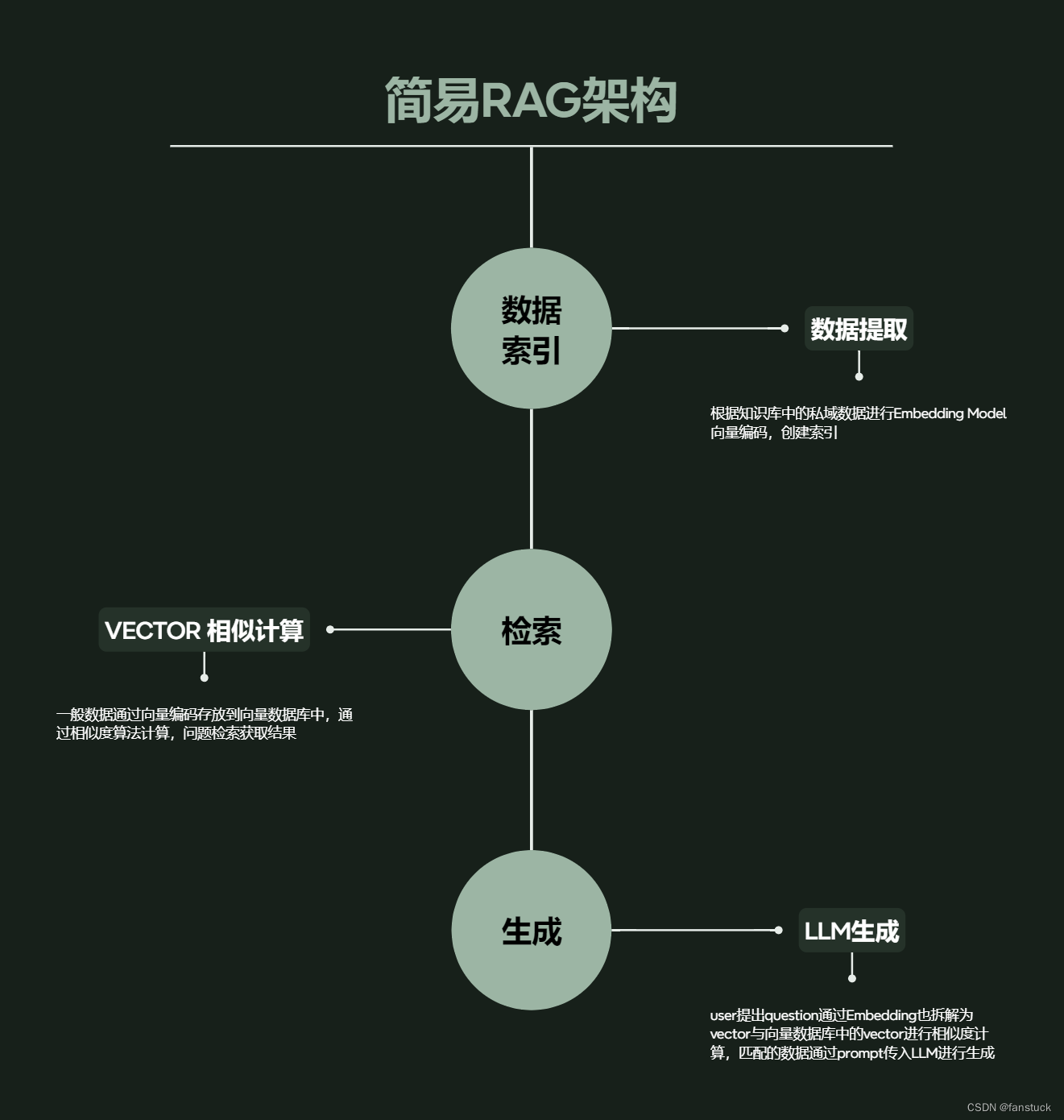 整体来看可以拆分为三个结构:数据索引——数据检索——LLM生成,整体架构如上述描述,我们先以整体视角看RGA的流程如上图所示。可以通俗的来讲
整体来看可以拆分为三个结构:数据索引——数据检索——LLM生成,整体架构如上述描述,我们先以整体视角看RGA的流程如上图所示。可以通俗的来讲
- 检索阶段:当用户提出一个问题时,RAG先将这个问题作为查询,搜索一个预先构建好的庞大数据库或知识库,寻找最相关的信息。这就像是当你在谷歌上输入查询一样,系统会返回与你的查询最匹配的结果。
- 生成阶段:一旦找到了最相关的信息,RAG会使用这些信息作为线索(或提示),通过一个语言生成模型来构造回答。这个过程就像是基于你从搜索引擎得到的资料撰写一篇报告或回答一个问题。
现在我们来拆分RGA的每一个阶段所做的工作。
RGA框架流程
数据储备
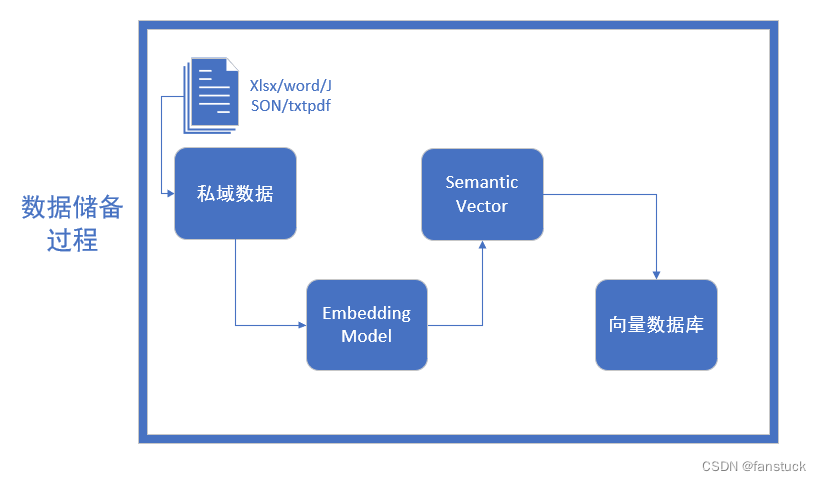
整个数据储备的过程可以分为四个步骤,首先是进行数据清洗。
数据清洗
需要转换为Embedding Model可以消化的格式,我们面对的知识源可能包括多种格式,如Word文档、TXT文件、CSV数据表、Excel表格,甚至是PDF文件、图片和视频等,都得转换为大语言模型可理解的纯文本数据。另外长本文还需要进行文本分割,需要考虑两个因素:1)embedding模型的Tokens限制情况;2)语义完整性对整体的检索效果的影响。
- 句分割:以”句”的粒度进行切分,保留一个句子的完整语义。常见切分符包括:句号、感叹号、问号、换行符等。
- 固定长度分割:根据embedding模型的token长度限制,将文本分割为固定长度(例如256/512个tokens),这种切分方式会损失很多语义信息,一般通过在头尾增加一定冗余量来缓解。
向量化(embedding)
我之前写过一篇基于向量数据库的推荐系统设计文章是有详细描述向量化这一过程的,在深度学习火热的当下,向量是一个无法逃避的概念,也就是每一种事物都可以通过人为给他编码,比如我们设计路段拥堵事件采用红黄绿是一个道理。物品可以通过Embedding模型映射到同一纬度:
之后再进行存储以后备用计算相似度用于推荐。Embedding模型市场上已经存在很多了:
| 模型名称 | 描述 | 获取地址 |
|---|---|---|
| ChatGPT-Embedding | ChatGPT-Embedding由OpenAI公司提供,以接口形式调用。 | https://platform.openai.com/docs/guides/embeddings/what-are-embeddings |
| ERNIE-Embedding V1 | ERNIE-Embedding V1由百度公司提供,依赖于文心大模型能力,以接口形式调用。 | https://cloud.baidu.com/doc/WENXINWORKSHOP/s/alj562vvu |
| M3E | M3E是一款功能强大的开源Embedding模型,包含m3e-small、m3e-base、m3e-large等多个版本,支持微调和本地部署。 | https://huggingface.co/moka-ai/m3e-base |
| BGE | BGE由北京智源人工智能研究院发布,同样是一款功能强大的开源Embedding模型,包含了支持中文和英文的多个版本,同样支持微调和本地部署。 | https://huggingface.co/BAAI/bge-base-en-v1.5 |
数据向量化后构建索引,并写入数据库的过程可以概述为数据入库过程,适用于RAG场景的数据库包括:FAISS、Chromadb、ES、milvus等。
数据检索
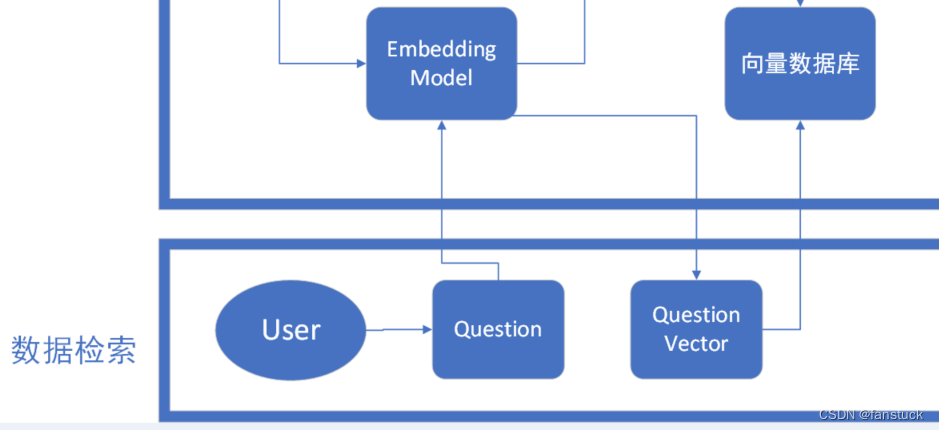
我们还需要对user提出的问题进行向量编码,和推荐系统设计的思路是一致的,其实推荐商品和给用户推荐回答二者的行为模式是一致的。推荐系统本质上是在用户需求不明确的情况下, 从海量的信息中为用户寻找其感兴趣的信息的技术手段。在博主写过的用户画像构建系统文章中有写到利用推荐系统作为下游服务,通过整合用户信息、物品信息和用户历史行为,推荐系统利用机器学习技术构建了个性化的用户兴趣模型。而给用户找答案的行为模式也是一样的,将用户提出的问题转换为向量,输入到向量数据库中进行数据检索。
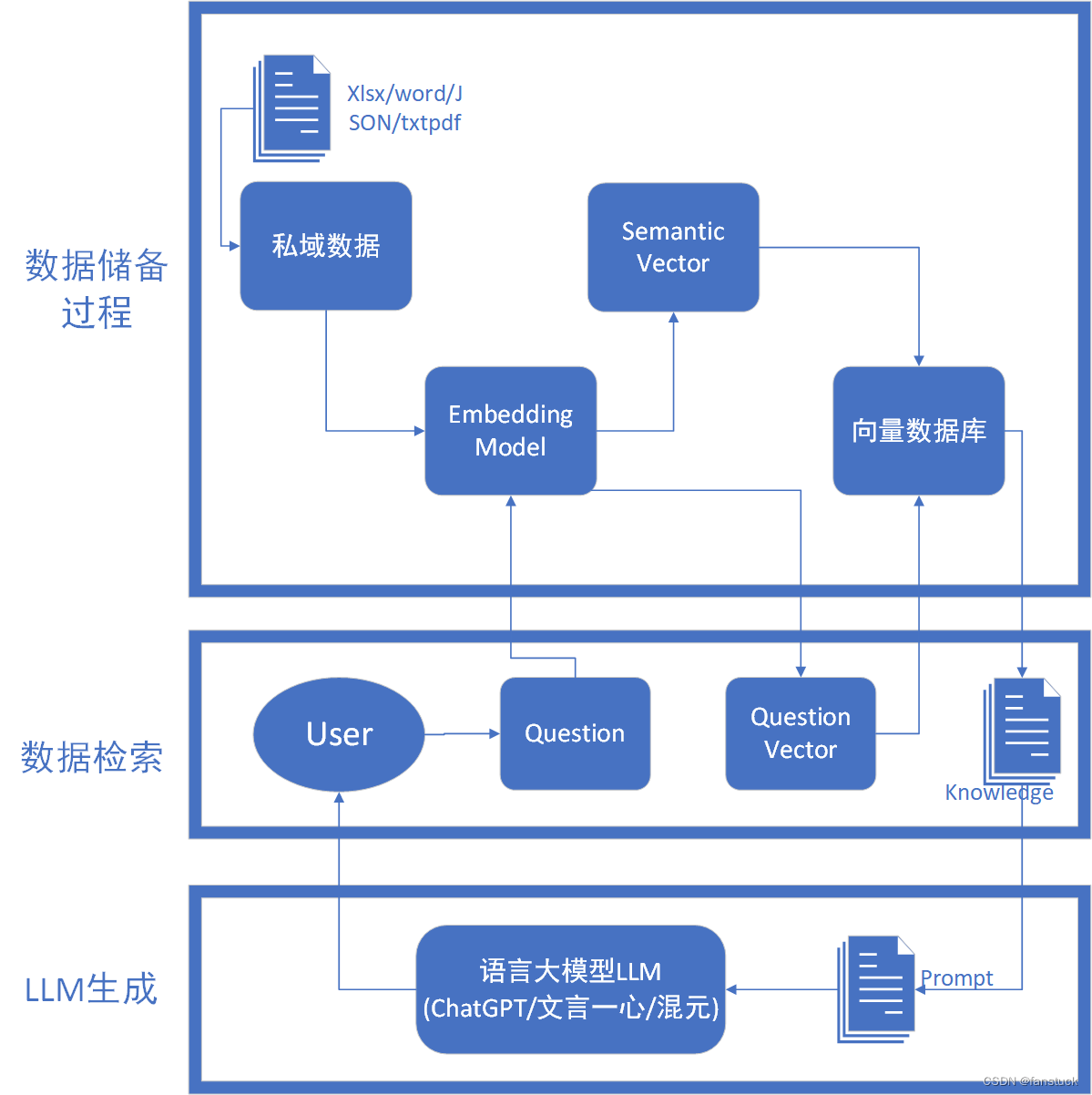
常见的数据检索方法包括:相似性检索、全文检索等,根据检索效果,一般可以选择多种检索方式融合,提升召回率。当接收到一个用户查询(如一个问题或关键词)时,RAG框架首先将这个查询转换为向量形式。这一步通常通过预训练的语言模型(如BERT、GPT等)完成,以确保查询向量能够有效地捕捉查询的语义。
有了查询向量后,RAG使用最近邻搜索算法在预构建的索引中找到与查询向量最相近的文档向量。这些最相近的向量代表了知识库中与查询最相关的信息。检索算法相当多种
 - 相似性检索:即计算查询向量与所有存储向量的相似性得分,返回得分高的记录。常见的相似性计算方法包括:余弦相似性、欧氏距离、曼哈顿距离等。
- 相似性检索:即计算查询向量与所有存储向量的相似性得分,返回得分高的记录。常见的相似性计算方法包括:余弦相似性、欧氏距离、曼哈顿距离等。
- 全文检索:全文检索是一种比较经典的检索方式,在数据存入时,通过关键词构建倒排索引;在检索时,通过关键词进行全文检索,找到对应的记录。
在RAG框架的实现中,常见的技术和工具包括Elasticsearch、FAISS(Facebook AI Similarity Search)、Annoy(Approximate Nearest Neighbors Oh Yeah)等,这些工具专门为大规模数据检索和最近邻搜索设计,能够有效支持RAG框架中的检索需求。
LLM生成

到了LLM生成这一步就比较简单了,因为通过相似度索引获取到了最高成绩的数据,接下来我们只需要通过返回的Knowledge生成出阶段性的Prompt就好了,然后再返回给LLM语言大模型,让LLM进行总结之后再返回给User。为了进一步提高检索的相关性和生成文本的准确度,一些RAG模型实现了动态Prompt生成技术。这种方法通过分析初步检索的结果,自动调整或生成新的Prompt,以优化后续的检索和生成过程。这种反馈循环可以显著提高模型的性能。而且RAG模型允许用户对初步生成的Prompt进行评价或修改,基于用户反馈进一步优化检索和生成的结果。
RAG 与微调
了解以上RAG框架以后,有一定的NLP或者大模型语言基础的情况下,我们不约而同会冒出一个新的想法:RAG 与微调到底哪个才是最优解决方案呢。这个问题的答案并非一成不变,它取决于多个因素,包括具体的应用场景、资源的可用性、以及对模型性能的具体要求。
应用场景的差异
- RAG框架特别适合于那些需要结合广泛知识库来生成答案或内容的场景。它通过检索与问题密切相关的信息,并基于这些信息生成回答,特别适用于信息检索、问答系统、内容推荐等领域。RAG的优势在于能够利用最新的、外部的信息源,提供更新、更准确的回答。
- 微调则适用于有大量标注数据的情况,可以根据具体任务对预训练模型进行个性化调整。这适用于各种NLP任务,如文本分类、情感分析、命名实体识别等。微调的优点是能够在特定的任务上达到很高的精度,尤其是当预训练模型和微调任务高度相关时。
资源的可用性
- RAG框架需要能够访问并处理大量的外部信息。这意味着它对计算资源和数据存储的要求相对较高。同时,实现高效的信息检索机制也是RAG成功应用的关键。
- 微调虽然也需要一定的计算资源,但通常情况下,资源的要求比RAG要低,因为一旦模型被微调,就不需要再实时检索外部信息。然而,微调需要大量的标注数据来训练模型,这在某些场景下可能是一个限制因素。
以实验来具体评测(摘Meta近期论文):使用三个流行的微调数据集: SQL, functional representation and GSM8K ,并发现在对样本进行 RAG 增强与zero-shot样本进行微调时,这三个数据集的精度都有多个百分点的提高。
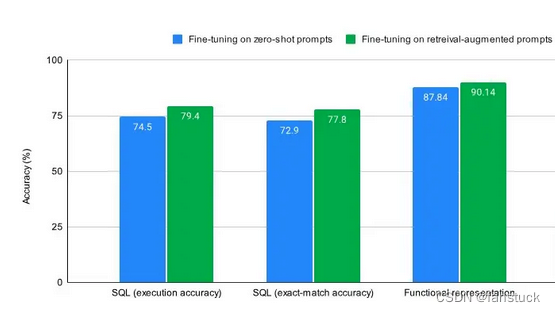
蓝色是针对zero-shot推理进行微调时的情况,绿色是针对检索增强提示进行微调时的情况(带有来自训练集的检索增强示例)。对于任何微调任务,无论是否是知识密集型任务,允许模型利用上下文学习和微调都会比仅仅微调零样本推理带来更好的性能。在一些情况下,结合使用RAG和微调可能是一个更好的策略。
总言
随着人工智能领域的快速发展,我们期待未来出现更多创新的技术,这些技术将进一步提高NLP任务的处理能力,为解决复杂的语言处理问题提供更多的可能性。同时,这也意味着AI工程师和研究人员需要不断地学习新的模型、技术和方法,以保持在这一动态发展的领域中的竞争力。我鼓励读者继续关注RAG、微调以及其他前沿的NLP技术和AI技术,通过实验和探索,找到最适合自己需求的解决方案。无论是在学术研究中,还是在实际应用开发中,不断地创新和尝试将是推动进步的重要动力。

