
- 1Android Studio 连接夜神模拟器的方法_android studio连接夜神模拟器
- 2【访问网络资源出错】不允许一个用户使用一个以上用户名与服务器或共享资源的多重连接
- 3git clone报错:remote: Support for password authentication was removed on August 13, 2021._get clone remote: support for password authenticat
- 4idea使用Spring Initializer创建springboot项目的坑【保姆级教学】
- 5【大模型专区】Text2Video-Zero—零样本文本到视频生成(上)
- 6神经网络深度学习梯度下降算法优化
- 7最新chatGPT镜像网站入口
- 8BigDecimal类的加减乘除(解决double计算精度问题)_bigdecimal怎么和double相乘
- 9Zookeeper Zab 协议解析——算法整体描述(一)_解析整体描述
- 10海外版抖音怎么下载?如何快速完成下载并注册TikTok账号?
大数据学习1 - hadoop环境搭建及操作_hadoop环境搭建与使用
赞
踩
目录
目录
一、什么是大数据?
大数据(big data),或称巨量资料,指的是所涉及的资料量规模巨大到无法透过主流软件工具,在合理时间内达到撷取、管理、处理、并整理成为帮助企业经营决策更积极目的的资讯。 [19]
在维克托·迈尔-舍恩伯格及肯尼斯·库克耶编写的《大数据时代》 [1] 中大数据指不用随机分析法(抽样调查)这样捷径,而采用所有数据进行分析处理。大数据的5V特点(IBM提出):Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性)。
高速发展的信息时代,新一轮科技革命和变革正在加速推进,技术创新日益成为重塑经济发展模式和促进经济增长的重要驱动力量,而“大数据”无疑是核心推动力。那么,什么是“大数据”呢?如果从字面意思来看,大数据指的是巨量数据。那么可能有人会问,多大量级的数据才叫大数据?不同的机构或学者有不同的理解,难以有一个非常定量的定义,只能说,大数据的计量单位已经越过TB级别发展到PB、EB、ZB、YB甚至BB来衡量。
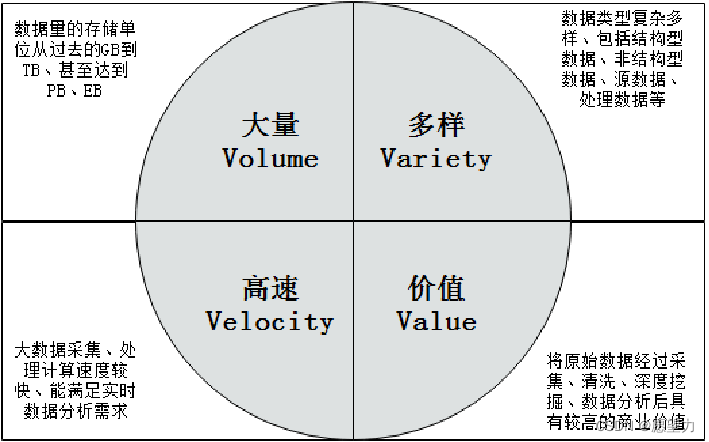
如何存储分析数据、对数据进行计算分析、怎么查询取出数据、根据数据进行价值预测都是大数据研究的方向。
二、什么是hadoop?
Hadoop是Apache基金会所开发的分布式系统基础架构,主要解决海量数据存储并分析计算的问题。
1.Hadoop核心组件
HDFS:分布式文件系统,是分布式计算中数据存储管理的基础。
MapReduce:用于大数据并行计算的一个计算模型。
Yarn:Hadoop中的资源管理器,可以为上层应用提供统一的资源管理和调度。
2.HDFS架构
1.HDFS采用主从架构(master/slave架构)。
2.HDFS集群是由一个NameNode和多个DataNode组成。
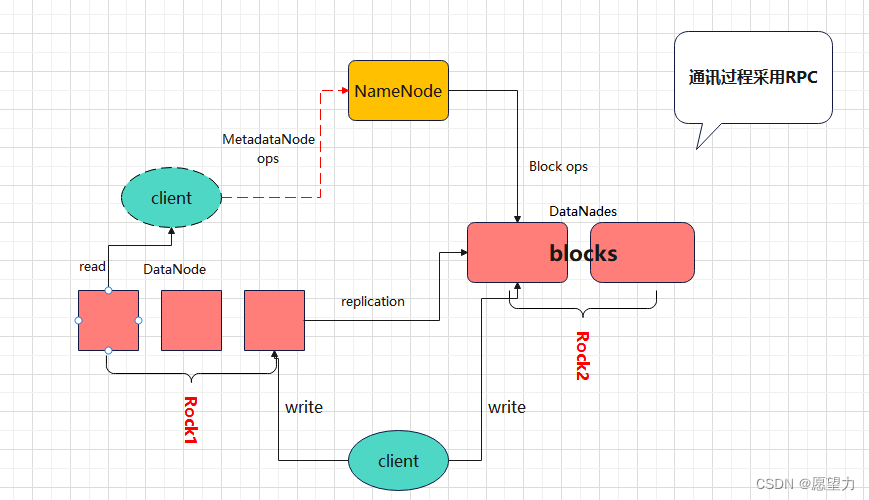
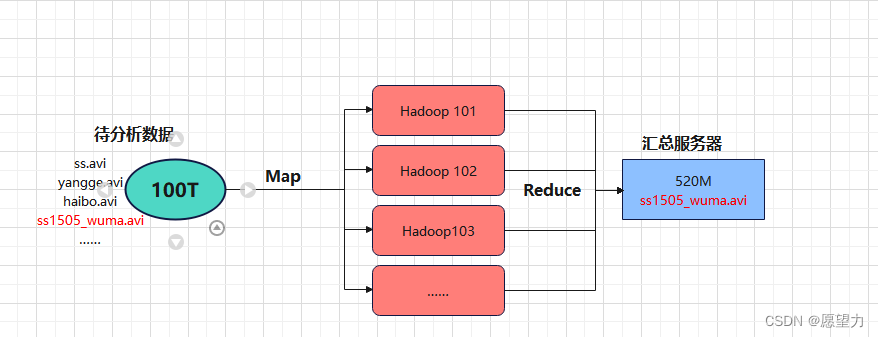
3.MapReduce
MapReduce是Hadoop中离线数据分析计算的模型,主要分为Map和Reduce两个阶段: 1.Map阶段并行处理输入数据
2.Reduce阶段对Map结果进行汇总
3.Yarn架构

三、Hadoop的集群模式
1.完全分布模式
在完全分布式模式下,Hadoop的守护进程分别运行在由多个主机搭建的集群上,不同节点担任不同的角色,在实际工作应用开发中,通常使用该模式构建企业级Hadoop系统。
2.伪分布模式
在伪分布式模式下, Hadoop程序的守护进程都运行在一台节点上,该模式主要用于调试Hadoop分布式程序的代码,以及程序执行是否正确。伪分布式模式是完全分布式模式的一个特例。(伪分布式是按照完全分布式搭建)
3.独立模式
在独立模式下,所有程序都在单个JVM上执行,调试Hadoop集群的MapReduce程序也非常方便。一般情况下,该模式常用于学习或开发阶段进行调试程序。
四、Hadoop创建伪分布式模式
1.获取安装Hadoop
Hadoop就是使用Java语言编写的,所以需要Java环境,如果没有请自行安装。
1.检查是否安装有Java,如果有使用【yum remove java -y】移除
2.在/opt里上传Java安装包,在该目录下创建java目录并将Java压缩包解压至java目录里
wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%2F; oraclelicense=accept-securebackup-cookie" "http://download.oracle.com/otn-pub/java/jdk/8u141-b15/336fa29ff2bb4ef291e347e091f7f4a7/jdk-8u141-linux-x64.tar.gz"3.【mv jdk1.8.0_161 jdk】重命名文件夹为jdk,方便查找
4.将Java环境变量配置到 /etc/profile 里
5.底线命令模式wq保存退出,【source /etc/profile】执行文件
6.使用【java】或者【javac】检查是否安装配置成功
1.下载Hadoop压缩包,并上传至 /opt/software 下。(Hadoop3.1下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/)
![]()
2.解压安装Hadoop
tar -zxvf hadoop-3.1.3.tar.gz
为了方便我们重名命一下
mv hadoop-3.1.3 hadoop
3.编辑 /etc/profile
vim /etc/profile配置以下路径
- HADOOP_HOME=/opt/software/hadoop
- PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
配置完成后wq退出,使用 【source /etc/profile】执行文件,然后使用【hadoop】或者【hadoop version】查看配置是否生效
到这里Hadoop的安装完成。
2.修改Hadoop配置文件
1.主要配置文件说明:
| 配置文件 | 功能描述 |
|---|---|
| hadoop-env.sh | 配置Hadoop运行所需的环境变量 |
| yarn-env.sh | 配置Yarn运行所需的环境变量 |
| core-site.xml | Hadoop核心全局配置文件,可在其他配置文件中引用 |
| hdfs-site.xml | HDFS配置文件,继承core-site.xml配置文件 |
| mapred-site.xml | MapReduce配置文件,继承core-site.xml配置文件 |
| yarn-site.xml | Yarn配置文件,继承core-site.xml配置文件 |
2.cd到 /opt/software/hadoop/etc/hadoop 可以找到这些文件 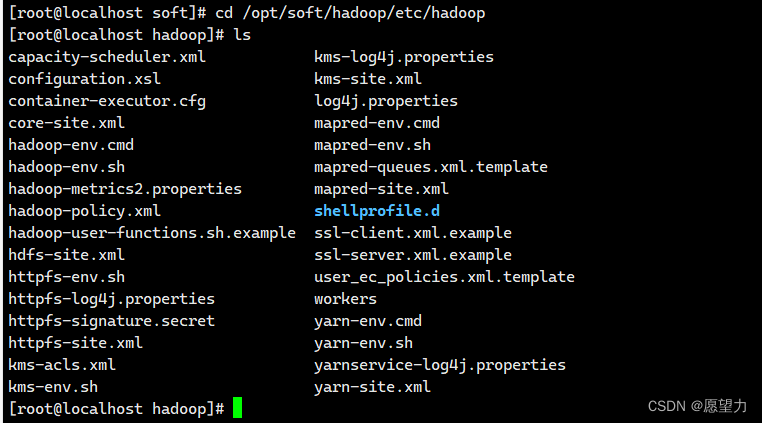
修改之前我们先手动把工作目录创建好
- mkdir -p /opt/hadoop-record/name
- mkdir -p /opt/hadoop-record/secondary
- mkdir -p /opt/hadoop-record/data
- mkdir -p /opt/hadoop-record/tmp

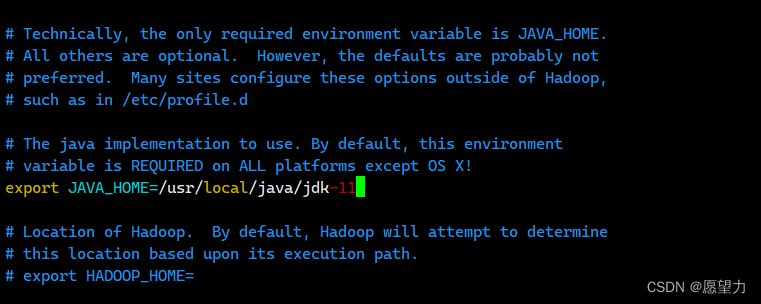
1)修改hadoop-env.sh文件,大概在开头处找到位置,将自己的jdk路径放进去,等号两边千万不要有空格。
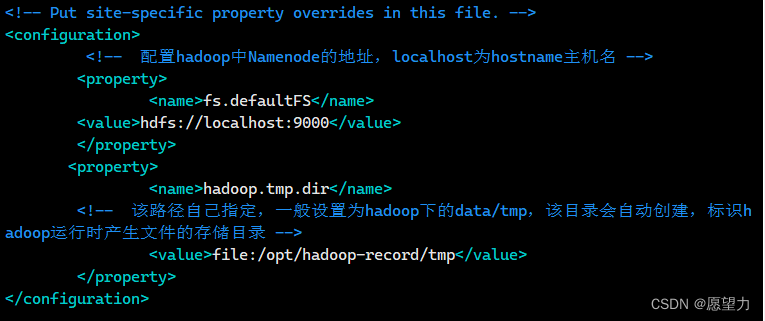
2)修改core-site.xml文件,在configuartion处添加内容
- <configuration>
- <!-- 配置hadoop中Namenode的地址,mymaster为hostname主机名 -->
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://localhost:9000</value>
- </property>
- <property>
- <name>hadoop.tmp.dir</name>
- <!-- 该路径自己指定,一般设置为hadoop下的data/tmp,该目录会自动创建,标识hadoop运行时产生文件的存储目录 -->
- <value>file:/opt/hadoop-record/tmp</value>
- </property>
- </configuration>
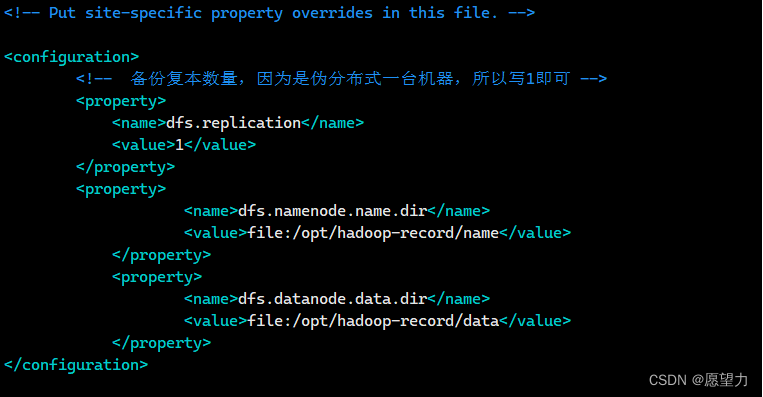
3)修改hdfs-site.xml文件,老样子在configuartion处添加内容
- <configuration>
- <!-- 备份复本数量,因为是伪分布式一台机器,所以写1即可 -->
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>file:/opt/hadoop-record/name</value>
- </property>
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>file:/opt/hadoop-record/data</value>
- </property>
- </configuration>
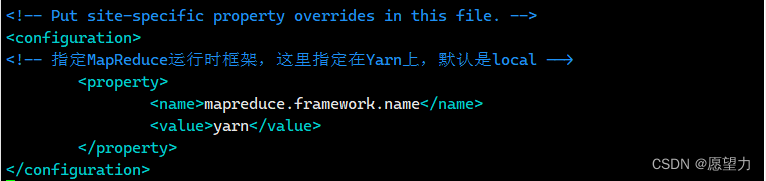
4)修改mapred-site.xml文件,添加以下内容
- <configuration>
- <!-- 指定MapReduce运行时框架,这里指定在Yarn上,默认是local -->
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- </configuration>
5)修改yarn-site.xml文件,添加以下内容
- <configuration>
- <!-- 指定yarn的resourceManager地址 -->
- <property>
- <name>yarn.resourcemanager.hostname</name>
- <value>localhost</value>
- </property>
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- </configuration>

3.启动hadoop
初次启动HDFS集群时,必须对主节点进行格式化处理,格式化文件系统指令如下(进入bin目录):格式化之前确保namenode和datanode进程结束。
./hdfs namenode -format也可以使用【hdfs namenode -format】直接格式化。
针对Hadoop集群的启动,需要启动内部包含的HDFS集群和YARN集群两个集群框架。启动方式有两种: 单节点逐个启动和使用脚本一键启动。

看到有successfully说明格式化成功
脚本一键启动和关闭:
(1)在主节点localhost上执行指令“start-dfs.sh”或“stop-dfs.sh”启动/关闭所有HDFS服务进程;
(2)在主节点localhost上执行指令“start-yarn.sh”或“stop-yarn.sh”启动/关闭所有YARN服务进程;
(3)在主节点localhost上执行“start-all.sh”或“stop-all.sh”指令,直接启动/关闭整个Hadoop集群服务(官方不建议使用,自己练习可以玩玩)。
如果启动遇到如下这几个参数的错误,说明是用户信息出现了错误
HDFS_NAMENODE_USER
HDFS_DATANODE_USER
HDFS_SECONDARYNAMENODE_USER
YARN_RESOURCEMANAGER_USER
YARN_NODEMANAGER_USER
可以将这参数添加到hadoop的 /sbin 目录里的这几个文件顶部中:
在【start-dfs.sh】【stop-dfs.sh】添加这几个参数:
- HDFS_DATANODE_USER=root
- HDFS_DATANODE_SECURE_USER=hdfs
- HDFS_NAMENODE_USER=root
- HDFS_SECONDARYNAMENODE_USER=root
在【start-yarn.sh】【stop-yarn.sh】添加这几个参数:
- YARN_RESOURCEMANAGER_USER=root
- HDFS_DATANODE_SECURE_USER=yarn
- YARN_NODEMANAGER_USER=root
或者添加新建一个环境变量文件【vim /etc/profile.d/myhadoop_env.sh】(推荐)
- export HDFS_NAMENODE_USER=root
- export HDFS_DATANODE_USER=root
- export HDFS_SECONDARYNAMENODE_USER=root
- export YARN_RESOURCEMANAGER_USER=root
- export YARN_NODEMANAGER_USER=root
里面加上以上参数,【source /etc/profile.d/myhadoop_env.sh】执行添加变量,然后再次启动。
全部启动后【jps】看到有6个进程

关闭防火墙或者开放指定端口,使用【IP+端口号:9870(此端口是hadoop3.0改过后的)】或者【IP+端口号:8088】浏览器访问。如果连接不上可以使用【netstat -anp | grep 端口号】查看端口的监控地址,网上查找解决办法。看到有页面说明hadoop成功启动。(3.0版本以下的端口默认为50070和8088,分别对应HDFS集群和YARN集群)
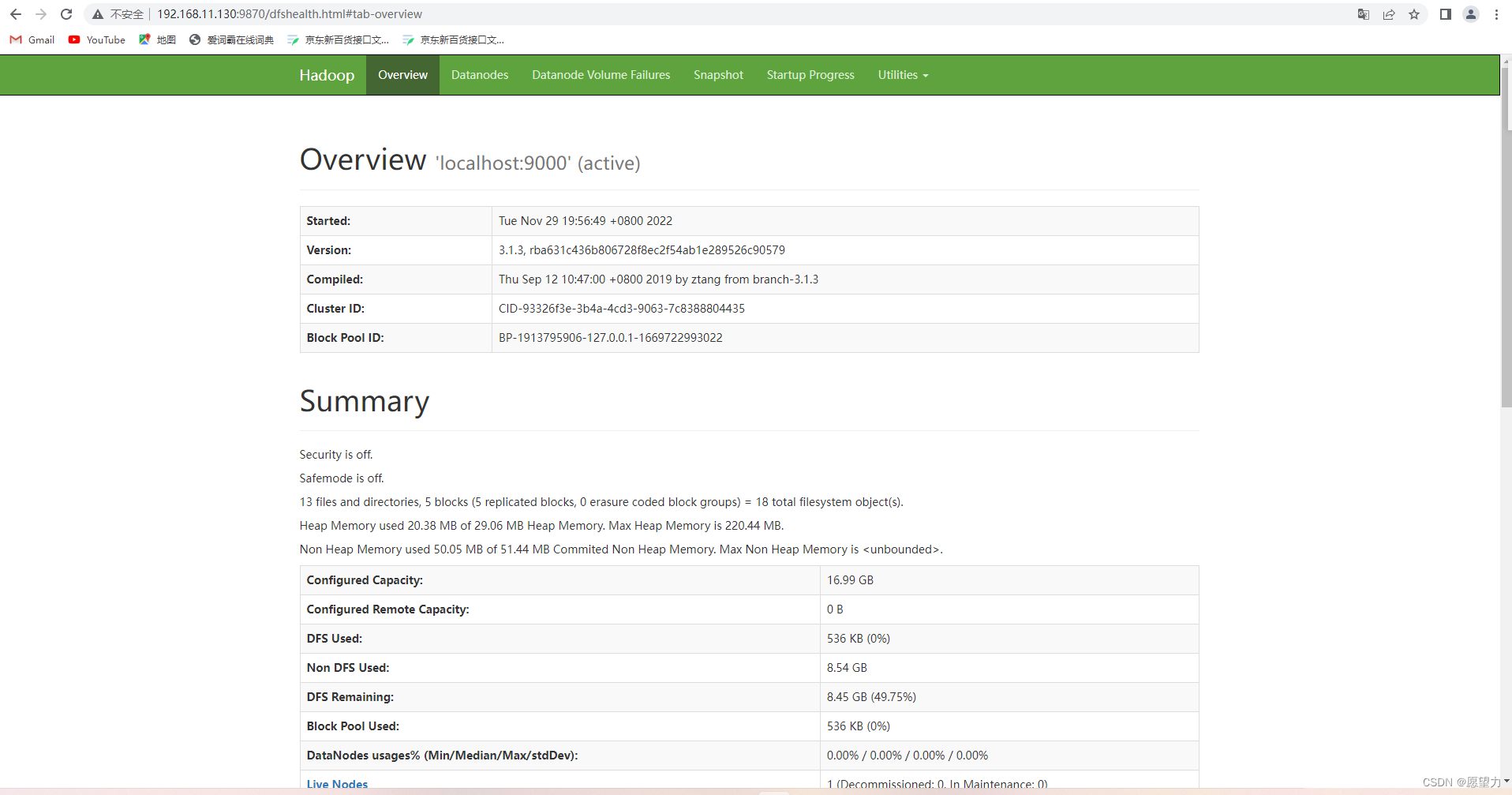

4.运行WerdCount测试
1.进入 /opt 目录下创建文件 hello.txt 并编辑文件,随意输入一些字母
![]()

2.将本地hello.txt上传至hdfs下
hadoop fs -put hello /hello
如果上传出现这个报错

可以在【hdfs-site.xml】中追加下面的内容
- <!-- appendToFile追加 -->
- <property>
- <name>dfs.support.append</name>
- <value>true</value>
- </property>
-
- <property>
- <name>dfs.client.block.write.replace-datanode-on-failure.policy</name>
- <value>NEVER</value>
- </property>
- <property>
- <name>dfs.client.block.write.replace-datanode-on-failure.enable</name>
- <value>true</value>
- </property>
3.进入/opt/software/hadoop/share/hadoop/mapreduce/ 并运行WordCount
- cd /opt/hadoop/share/hadoop/mapreduce/
- hadoop jar hadoop-mapreduce-examples-3.1.3.jar wordcount /hello /out
4.运行完成后打印查看结果
hadoop fs -cat /out/part-r-00000
可以看到打印结果是把每个单词出现的次数记录下来,英文中是以空格来区分单词的。
五、完全分布式(配置跟伪分布式有差别,可以直接替换)
1.准备工作
1)克隆2台空的linux机器,分别修改IP和主机名

2)修改hosts文件中的主机和IP映射
3)配置master到slaves1机器和slaves2机器上的ssh免密登录
master
slave1
slave2
HDFS
NameNode
DataNode
DataNode
SecondaryNameNode
DataNode
YARN
NodeManager
ResourceManager
NodeManager
NodeManager
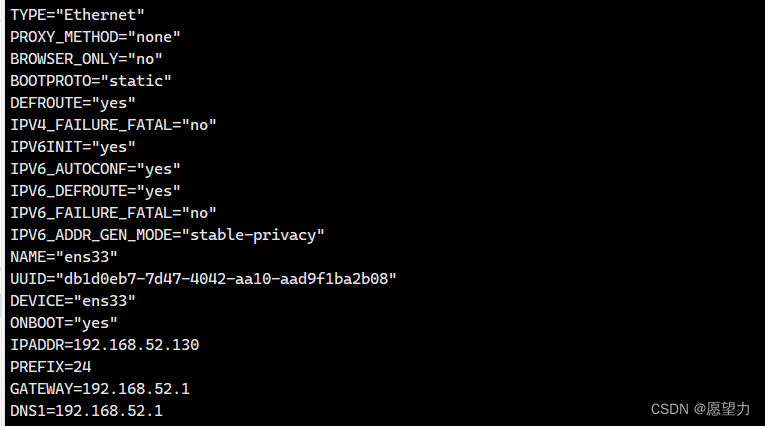
2.修改静态IP地址
vi /etc/sysconfig/network-scripts/ifcfg-ens33![]()
![]()
将BOOTPROTO参数改为static,将ONBOOT参数改为yes
然后追加上这些参数:
IPADDR=192.168.11.127 #静态IP
PREFIX=24 #子网掩码长度
GATEWAY=192.168.1.1 #默认网关
DNS1=192.168.1.1 #域名
wq保存退出,其余两台机器也需要配置同样的网络,配置好后每台机器都重启网卡
 重启网卡:
重启网卡:
service network restart然后分别修改主机和子机的名称
vi /etc/hostname下一步是配置【vi /etc/hosts】里IP地址和机器的关系,静态表
- master
- slaves1
- slaves2

将静态表远程拷贝到两个子机,过程中输入【yes】确认和密码
scp -r /etc/hosts slaves1:/etc/hosts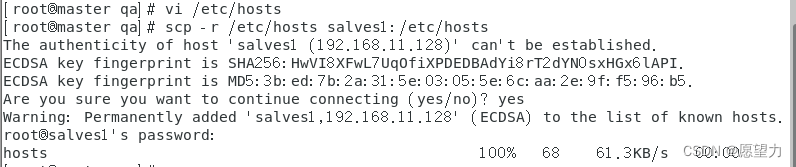
2台机器都拷贝完后重启所有机器,就可以看到主机名已经修改了
3.配置ssh免密
主机输入以下命令获取秘钥
ssh-keygen -t rsa直接回车跳过,将出现的秘钥拷贝至主机和2台子机
- ssh-copy-id -i root@master
- ssh-copy-id -i root@slaves1
- ssh-copy-id -i root@slaves2
输入root用户的密码,然后【ssh 'root@主机名'】验证
![]()
远程登录测试
![]()
登录成功!
4.修改主机hadoop配置
进入主机 /opt/software/hadoop/etc/hadoop 目录
1.修改【core-site.xml】文件
- <configuration>
- <!-- 指定NameNode的地址 -->
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://master:8020</value>
- </property>
- <!-- 指定hadoop数据的存储目录 -->
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/opt/software/hadoop/data</value>
- </property>
-
- <!-- 配置HDFS网页登录使用的静态用户为harry -->
- <property>
- <name>hadoop.http.staticuser.user</name>
- <value>harry</value>
- </property>
-
- <!-- 配置该harry(superUser)允许通过代理访问的主机节点 -->
- <property>
- <name>hadoop.proxyuser.harry.hosts</name>
- <value>*</value>
- </property>
- <!-- 配置该harry(superUser)允许通过代理用户所属组 -->
- <property>
- <name>hadoop.proxyuser.harry.groups</name>
- <value>*</value>
- </property>
- <!-- harry(superUser)允许通过代理的用户-->
- <property>
- <name>hadoop.proxyuser.harry.users</name>
- <value>*</value>
- </property>
- </configuration>

 localhost 改为主机当前的名称 master,保存退出
localhost 改为主机当前的名称 master,保存退出
2.进入【hdfs-site.xml】文件,数据备份数量改为3台
- <configuration>
- <!-- NameNode web端访问地址-->
- <property>
- <name>dfs.namenode.http-address</name>
- <value>master:9870</value>
- </property>
-
- <!-- SecondaryNameNode web端访问地址-->
- <property>
- <name>dfs.namenode.secondary.http-address</name>
- <value>slaves2:9868</value>
- </property>
-
- <!-- 测试环境指定HDFS副本的数量1 -->
- <property>
- <name>dfs.replication</name>
- <value>3</value>
- </property>
- </configuration>

3.编辑【yarn-site.xml】文件,修改主机名
- <configuration>
- <!-- 指定MR走shuffle -->
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
-
- <!-- 指定ResourceManager的地址-->
- <property>
- <name>yarn.resourcemanager.hostname</name>
- <value>master</value>
- </property>
-
- <!-- 环境变量的继承 -->
- <property>
- <name>yarn.nodemanager.env-whitelist</name>
- <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
- </property>
-
- <!--yarn单个容器允许分配的最大最小内存 -->
- <property>
- <name>yarn.scheduler.minimum-allocation-mb</name>
- <value>512</value>
- </property>
- <property>
- <name>yarn.scheduler.maximum-allocation-mb</name>
- <value>4096</value>
- </property>
-
- <!-- yarn容器允许管理的物理内存大小 -->
- <property>
- <name>yarn.nodemanager.resource.memory-mb</name>
- <value>4096</value>
- </property>
-
- <!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
- <property>
- <name>yarn.nodemanager.pmem-check-enabled</name>
- <value>true</value>
- </property>
- <property>
- <name>yarn.nodemanager.vmem-check-enabled</name>
- <value>false</value>
- </property>
- </configuration>
5.编辑【mapred-site.xml】文件
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
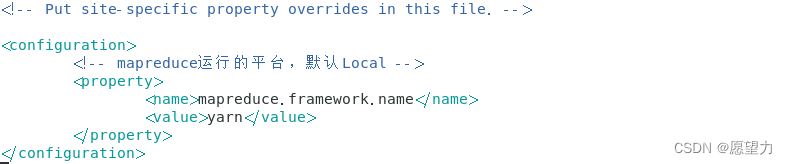
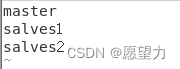
5.配置修改 workers 文件
vi workers- master
- slaves1
- slaves2
5.将jdk、hadoop、/etc/profile环境配置远程拷贝给2台子机器
拷贝jdk:
- scp -r /opt/software/jdk slaves1:/opt/software/jdk
- scp -r /opt/software/jdk slaves2:/opt/software/jdk
拷贝hadoop:
- scp -r /opt/software/hadoop slaves1:/opt/software/hadoop
- scp -r /opt/software/hadoop slaves2:/opt/software/hadoop
这个过程有点慢,请耐心等待……
拷贝环境:
- scp /etc/profile slaves1:/etc/profile
- scp /etc/profile slaves2:/etc/profile
6.启动测试
1.关闭3台机器的防火墙并禁止启动
- systemctl stop firewalld
- systemctl disable firewalld
2.3台机器执行 /etc/profile 环境变量文件
source /etc/profile3.主机master格式化,如果是在伪分布式上修改而来,则需要删除配置的hadoop.tmp.dir对应的目录(如/opt/hadoop-record/data/目录),然后执行格式化命令
hdfs namenode -format4.启动hadoop
start-all.sh停止:
stop-all.sh6.其他配置
1.配置历史服务器【mapred-site.xml】(可选)
- <!-- 历史服务器端地址 -->
- <property>
- <name>mapreduce.jobhistory.address</name>
- <value>master:10020</value>
- </property>
-
- <!-- 历史服务器web端地址 -->
- <property>
- <name>mapreduce.jobhistory.webapp.address</name>
- <value>master:19888</value>
- </property>
2.配置日志聚集【yarn-site.xml】(可选)
- <!-- 开启日志聚集功能 -->
- <property>
- <name>yarn.log-aggregation-enable</name>
- <value>true</value>
- </property>
-
- <!-- 设置日志聚集服务器地址 -->
- <property>
- <name>yarn.log.server.url</name>
- <value>http://master:19888/jobhistory/logs</value>
- </property>
-
- <!-- 设置日志保留时间为7天 -->
- <property>
- <name>yarn.log-aggregation.retain-seconds</name>
- <value>604800</value>
- </property>
(说明:文章里的slaves被我误写成了salves,但是无伤大雅,在可复制的代码里已改,如有没有修改的可以自己改掉。)
六、hadoop常用命令
HDFS命令使用时语法为: hdfs dfs –xxx –参数 ,如:
创建目录: hdfs dfs –mkdir /test
查看目录: hdfs dfs –ls /
查看文件: hdfs dfs –cat /test/output.part-r-00000
查看文件行数:hdfs dfs –cat /xxx.txt | wc –l
查看前几行数据:hdfs dfs –cat /xxx.txt | head -5
查看后几行数据:hdfs dfs –cat /xxx.txt | tail-5
本地文件上传到hdfs下的test目录: hdfs dfs –put /xxx.txt /test
从hdfs上把文件复制到本地:hdfs dfs -get /xxx.txt /opt/test
删除目录: hdfs dfs –rm –r /test/web.log
七、JavaAPI操作
Hadoop是使用Java语言编写的,因此可以使用Java API操作Hadoop文件系统。HDFS Shell本质上就是对Java API的应用,通过编程的形式操作HDFS,其核心是使用HDFS提供的Java API构造一个访问客户端对象,然后通过客户端对象对HDFS上的文件进行操作(增、删、改、查)。
1.说明
hadoop整合了许多文件系统,HDFS只是其中的一个实例。
| 包名 | 功能描述 |
| org.apache.hadoop.fs.FileSystem | 它是通用文件系统的抽象基类,可以被分布式文件系统继承,它具有许多实现类 |
| org.apache.hadoop.fs.FileStatus | 它用于向客户端展示系统中文件和目录的元数据 |
| org.apache.hadoop.fs.FSDataInputStream | 文件输入流,用于读取Hadoop文件 |
| org.apache.hadoop.fs.FSDataOutputStream | 文件输出流,用于写Hadoop文件 |
| org.apache.hadoop.conf.Configuration | 访问配置项,默认配置参数在core-site.xml中 |
| org.apache.hadoop.fs.Path | 表示Hadoop文件系统中的一个文件或者一个目录的路径 |
在Java中操作HDFS,创建一个客户端实例主要涉及以下两个类:
(1)Configuration:该类的对象封装了客户端或者服务器的配置,Configuration实例会自动加载HDFS的配置文件core-site.xml,从中获取Hadoop集群的配置信息。
(2)FileSystem:该类的对象是一个文件系统对象。
| 方法名 | 功能描述 |
| copyFromLocalFile(Path src,Path dst) | 类从本地磁盘复制文件到HDFS |
| copyToLocalFile(Path src,Path dst) | 从HDFS复制文件到本地磁盘 |
| mkdirs(Path f) | 建立子目录 |
| rename(Path src,Path dst) | 重命名文件或文件夹 |
| delete(Path f) | 删除指定文件 |
2.操作
1.使用idea或者eclipse创建一个maven项目,添加依赖【hadoop-client】
2.初始化客户端对象
(1)编写Java测试类,构建Configuration和FileSystem对象,初始化一个客户端实例进行相应的操作
(2)
- Configuration configuration = new Configuration();
-
- FileSystem fs= FileSystem.get(new URI("hdfs://192.168.11.130:9000"), configuration, "root");
3.在HDFS上创建目录
boolean bool = fs.mkdirs(new Path("/javaData"));4.上传文件到HDFS
fs.copyFromLocalFile(new Path("C:\\test.txt"), new Path("/javaData"));
5.从HDFS上下载文件到本地
fs.copyToLocalFile(new Path("/javaData/test.txt"), new Path("D:\\test.txt"));6.在HDFS上删除文件
boolean flag = fs.delete(new Path("/javaData/test.txt"));
7.获取HDFS所有节点内容
- DistributedFileSystem distributedFileSystem = (DistributedFileSystem) fs;
- try{
- DatanodeInfo[] datanodeInfos = distributedFileSystem.getDataNodeStats();
- for (DatanadeInfo di : datanodeInfos){
- System.out.println(di.getHostName());
- }
- }catch (Exception e){
- e.printStackTrace();
- }
8.获取HDFS文件列表
- RemoteIterator<LocatedFiledStatus> listFiles = fs.listFiles(new Path("/"),true);
- while(listFiles.hasNext()){
- LocatedFileStatus fileStatus = listFiles.next();
- String fname = fileStatus.getPath().getName();
- System.out.println("文件名字为:"+fname);
- long size = fileStatus.getBlockSize();
- System.out.println("文件大小为:"+size);
- FsPormission fp = fileStatus.getPormission();
- System.out.println(fp);
- long size1 = fileStatus.getLen();
- System.out.println("文件大小为:"+size1);
- }

