
- 1区块链行业名词解释大全_区块链 miner
- 2Python中很常用的函数map(),一起来看看用法_map()函数
- 3Anaconda python版本降级_anaconda降级python
- 4AI程序员时代的到来:探索其对程序员行业的深远影响_ai程序员的出现将给整个行业带来以下新变化
- 5【独家源码】ssm更美个人美妆穿搭分享微信小程序95827应对计算机毕业设计困难的解决方案_微信小程序 换装 源码
- 6linux:磁盘管理和文件系统_linux文件系统管理和磁盘管理的区别
- 7如何在 GitHub 的项目中创建一个分支呢?_github创建分支
- 8【django】django中使用jinja2模板_django jinja2
- 92024届计算机专业大学生,该何去何从?_2024计算机专业就业形势分析报告
- 1013_51单片机应用_AT24C02&IIC_7【判断题】at24co2芯片有写操作时间,即执行写操作(芯片内部需要将数据烧写至存储
完全解析分布式存储,带你了解HDFS的块_hdfs中块的概念
赞
踩
在大数据的学习过程中,我们经常会听到“分布式”这三个字,那个所谓的“分布式”到底是什么意思?我们看到一些古装电视剧电影,在古代,生产力比较低下,没有现在的各种便捷的交通工具。人们需要运输一些货物的时候,最常见的方式就是套马车,用马来拉动车。如果需要拉的货物比较多,一匹马拉不动呢?人们的做法并不是训练一匹更加强壮的马,而是会使用多匹马同时来拉动这辆马车。这就是分布式的思想!
那么在程序世界中,单台服务器的能力是有限的,虽然我们可以堆配置来构建一台性能非常强悍的服务器,但是上限还是容易达到的,且成本会非常的高。为了解决这样的问题,我们就可以使用多台服务器协同工作,共同来完成指定的任务,组成一个服务器集群,而这样的集群我们通常也就称为--分布式集群。
分布式集群可以提供数据的存储、计算等操作。今天我们就来聊一聊分布式存储,也就是一个分布式文件系统。其实在HDFS之前,也有一些其他的分布式文件系统,笼统的来说,只要是实现了将数据分散的存储在多个节点上进行存储,并且可以实现数据的读取就可以称为是“分布式文件系统”。
传统的分布式文件系统的缺点
现在想象一下这种情况:有四个文件 0.5TB的file1,1.2TB的file2,50GB的file3,100GB的file4;有7个服务器,每个服务器上有10个1TB的硬盘。
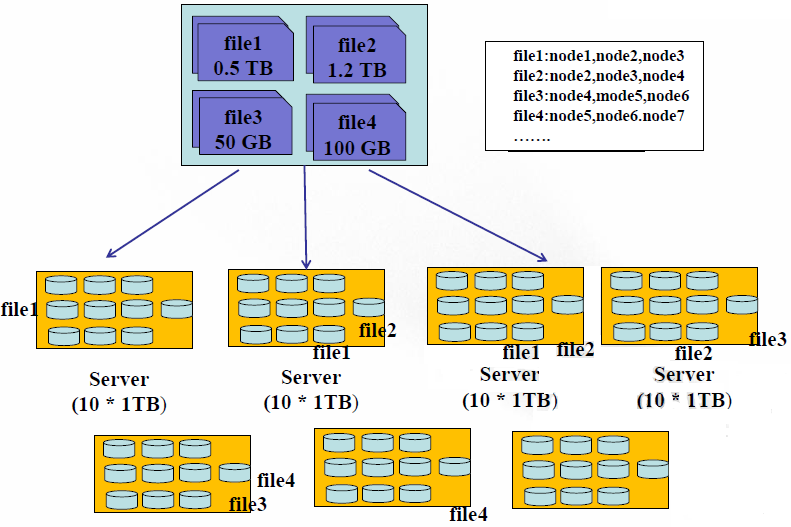
在存储方式上,我们可以将这四个文件存储在同一个服务器上(当然大于1TB的文件需要切分),我们需要使用一个文件来记录这种存储的映射关系吧。用户是可以通过这种映射关系来找到节点硬盘相应的文件的。那么缺点也就暴露了出来:
第一、负载不均衡。
因为文件大小不一致,势必会导致有的节点磁盘的利用率高,有的节点磁盘利用率低。
第二、网络瓶颈问题。
一个过大的文件存储在一个节点磁盘上,当有并行处理时,每个线程都需要从这个节点磁盘上读取这个文件的内容,那么就会出现网络瓶颈,不利于分布式的数据处理。
HDFS的块结构
HDFS与其他普通文件系统一样,同样引入了块(Block)的概念,并且块的大小是固定的。但是不像普通文件系统那样小,而是根据实际需求可以自定义的。块是HDFS系统当中的最小存储单位,在hadoop2.0中默认大小为128MB(hadoop1.x中的块大小为64M)。在HDFS上的文件会被拆分成多个块,每个块作为独立的单元进行存储。多个块存放在不同的DataNode上,整个过程中 HDFS系统会保证一个块存储在一个数据节点上 。但值得注意的是,如果某文件大小或者文件的最后一个块没有到达128M,则不会占据整个块空间 。
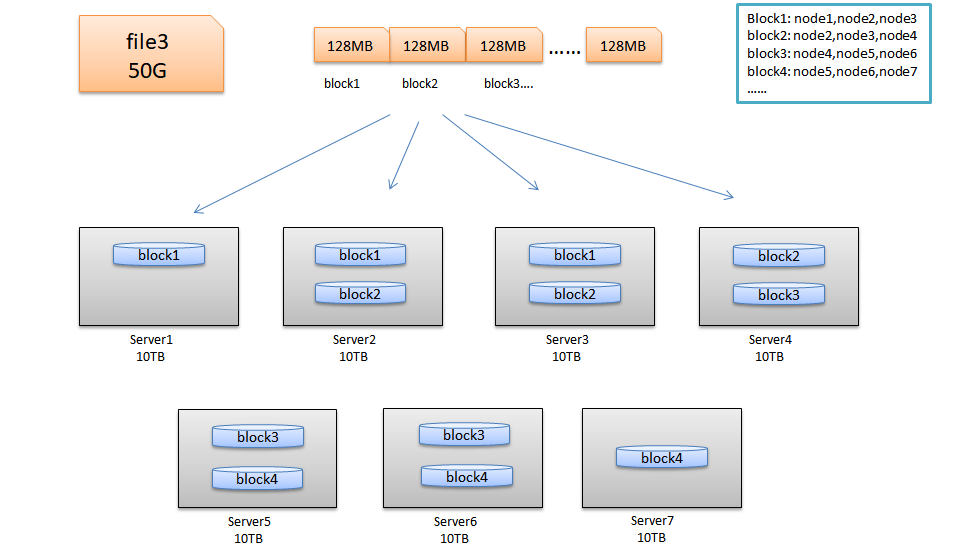
块的存储位置
在hdfs-site.xml中我们配置过下面这个属性,这个属性的值就是块在linux系统上的存储位置
<!-- 确定DFS数据节点应该将其块存储在本地文件系统的何处-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>

HDFS的优点
1. 高容错性(硬件故障是常态):数据自动保存多个副本,副本丢失后,会自动恢复
2. 适合大数据集:GB、TB、甚至PB级数据、千万规模以上的文件数量,1000以上节点规模。
3. 数据访问: 一次性写入,多次读取;保证数据一致性,安全性
4. 构建成本低:可以构建在廉价机器上。
5. 多种软硬件平台中的可移植性
6. 高效性:Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
7. 高可靠性:Hadoop的存储和处理数据的能力值得人们信赖.
HDFS的缺点
1. 不适合做低延迟数据访问:
HDFS的设计目标有一点是:处理大型数据集,高吞吐率。这一点势必要以高延迟为代价的。因此HDFS不适合处理用户要求的毫秒级的低延迟应用请求
2. 不适合小文件存取:
1. 从存储能力出发(固定内存)
因为HDFS的文件是以块为单位存储的,且如果文件大小不到128M的时候,是不会占用整个块的空间的。但是,这个块依然会在内存中占用150个字节的元数据。因此,同样的内存占用的情况下,大量的小文件会导致集群的存储能力不足。
例如: 同样是128G的内存,最多可存储9.2亿个块。如果都是小文件,例如1M,则集群存储的数据大小为9.2亿*1M = 877TB的数据。但是如果存储的都是128M的文件,则集群存储的数据大小为109.6PB的数据。存储能力大不相同。
2. 从内存占用出发(固定存储能力)
同样假设存储1M和128M的文件对比,同样存储1PB的数据,如果是1M的小文件存储,占用的内存空间为1PB/1Mb*150Byte = 150G的内存。如果存储的是128M的文件存储,占用的内存空间为1PB/128M*150Byte = 1.17G的内存占用。可以看到,同样存储1PB的数据,小文件的存储比起大文件占用更多的内存。
3. 不适合并发写入,文件随机修改:
HDFS上的文件只能拥有一个写者,仅仅支持append操作。不支持多用户对同一个文件的写操作,以及在文件任意位置进行修改。
帮助到你的话就点个关注吧~

