
热门标签
热门文章
- 1一文了解——大模型在金融行业的应用场景和落地路径_金融行业大模型应用
- 2Linux进程概念
- 3必备年终绩效工作总结模板
- 4绝对干货 | PMP考试知识体系精髓归纳,看完本文考试so easy_pmp体系
- 5Quartus II 15.0波形仿真解决方案_quartus ii15.0波形仿真
- 6[SQL系列] 从头开始学PostgreSQL Union Null 别名 触发器_plpgsql union all
- 7python将电视剧按收视率进行排序_2019电视剧收视率排行榜
- 8基于FPGA的DDS在Modelsim与TD的联合仿真(三)_modelsim怎么添加安路ip库
- 9【毕业设计】微信小程序校园跑腿系统_校园跑腿系统论文
- 102023年第十四届蓝桥杯大赛python组省赛真题(更新中)-最新的_给定 n 个数 ai,问能满足 m! 为∑ni=1(ai!) 的因数的最大的 m 是多少。其中 m!
当前位置: article > 正文
零基础入门NLP - 新闻文本分类比赛方案分享 nano- Rank1
作者:很楠不爱3 | 2024-04-13 18:09:26
赞
踩
零基础入门NLP - 新闻文本分类比赛方案分享 nano- Rank1
nano- 康一帅
简介
环境
Tensorflow== 1.14.0Keras== 2.3.1bert4keras== 0.8.4
文件说明
EDA:用于探索性数据分析。data_utils:用于预训练语料的构建。pretraining:用于Bert的预训练。train:用于新闻文本分类模型的训练。pred:用于新闻文本分类模型的预测。
其他
赛题分析
赛题背景
通过这道赛题可以引导大家走入自然语言处理的世界,带大家接触NLP的预处理、模型构建和模型训练等知识点。
任务目标
要求选手根据新闻文本字符对新闻的类别进行分类,这是一个经典文本分类问题。
数据示例

文本长度
- 训练集共200,000条新闻,每条新闻平均907个字符,最短的句子长度为2,最长的句子长度为57921,其中75%以下的数据长度在1131以下。
- 测试集共50,000条新闻,每条新闻平均909个字符,最短句子长度为14,最长句子41861,75%以下的数据长度在1133以下。
- 训练集和测试集就长度来说似乎是同一分布。

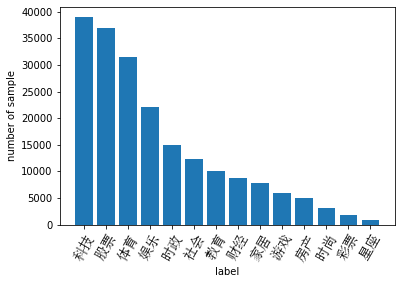
标签分布
- 赛题的数据集类别分布存在较为不均匀的情况。在训练集中科技类新闻最多,其次是股票类新闻,最少的新闻是星座新闻。
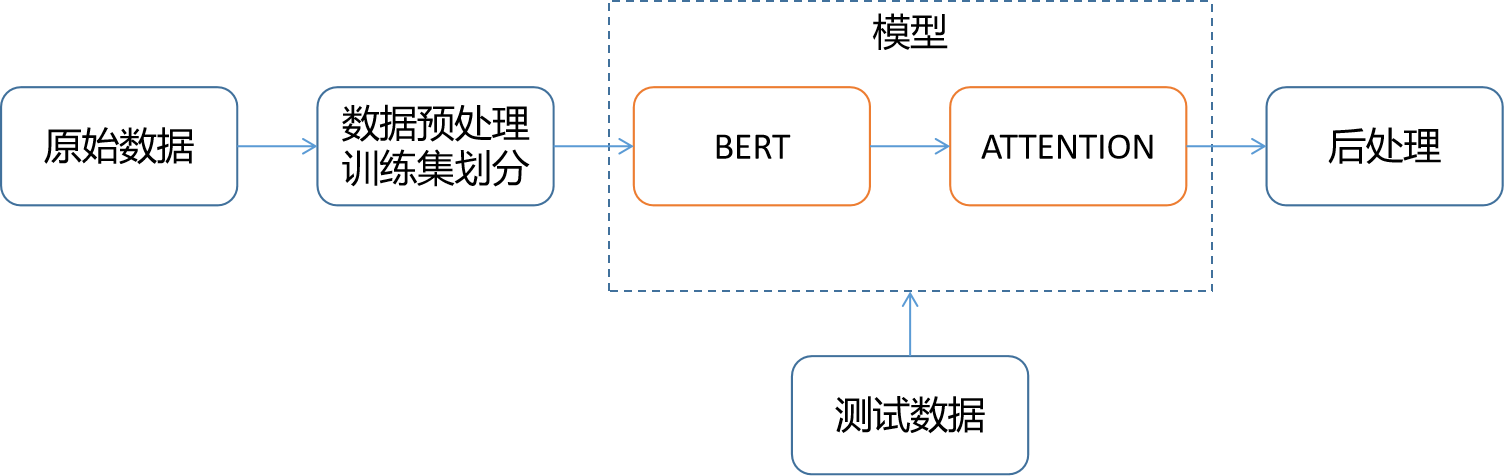
总体思路
数据划分
- 使用StratifiedKFold交叉验证。StratifiedKFold能够确保抽样后的训练集和验证集的样本分类比例和原原始数据集基本一致。
- 利用全部数据,获得更多信息。
- 降低方差,提高模型性能。
查看本文全部内容,欢迎访问天池技术圈官方地址:零基础入门NLP - 新闻文本分类比赛方案分享 nano- Rank1_天池技术圈-阿里云天池
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/很楠不爱3/article/detail/417802
推荐阅读

相关标签

