
- 1github下载指定分支_git如何只单独下载master
- 2分词Hanlp的介绍和在Java中基本使用_java hanlp
- 3使用Arduino开发ESP32(01):开发环境搭建_arduino esp32
- 4软考高项-计算题(2)
- 5Git命令、IntelliJ IDEA链接github和gitee_idea 查看git 提交的缓存区
- 6vue2,组件里有多个video, 但是我想同一时间只能有一个播放,怎么办
- 7实施要解决的_软件实施过程甲方不配合怎么处理问题
- 8在CentOS 7中搭建Git服务器_centos7搭建git服务器
- 9互联网面试八股文之Java基础_java八股文面试题
- 10ARINC818学习
二叉排序树(二叉查找树)_二叉排序树查找成功和不成功最大比较次数
赞
踩
一、引言
1、如果查找的数据集是普通的顺序存储,则插入操作可以将记录放在表的末端,给表记录数加一即可;对于删除操作可以是删除后,后面的记录向前移,也可以是把要删除的元素与最后一个元素互换位置,然后再删除最后一个元素,表记录数减一。因为整个数据集不要求有序,所以这样的数据集的存储结构对于插入和删除操作的效率还是不错的,但是正由于是无序的,所以会造成查找的效率很低。
2、如果查找的数据集是有序的线性表,并且是顺序存储的,则查找可以用折半、插值和斐波那契等查找算法来实现,但是因为有序,在插入和删除操作上,就需要耗费大量的时间了。
3、从以上两点可以看出分别采用无序的顺序存储结构和有序的顺序存储结构,它们本身对于删除、插入和查找操作是有利有弊的。那有没有一种可以使得插入和删除的效率不错,而且查找的效率还不错的存储结构和算法呢?答案是有的,把这种需要在查找时插入或删除的查找表称之为动态查找表,而一种称之为"二叉排序树"的数据结构就可以实现动态查找表的高效率。
二、二叉排序树
1、假如数据集是有序的且初始只有两个元素{62, 88},然后要插入元素58,如果是采用顺序存储结构,则元素62和88需要分别向后移动一个位置,然后在第一个元素位置插入元素58,保持有序。但是如果是采用二叉树结构,就可以避免移动元素,如下图:首先将第一个元素62定为二叉树的根结点(root),然后元素88因为比62大,所以让它成为根结点的右子树;接着元素58比62小,所以让它成为根结点的左子树。此时元素58的插入就并没有影响到原本是元素62和88。

如果数据元素有{62, 88, 58, 47, 35, 73, 51, 99, 37, 93},那么根据以上的规则来创建这棵二叉树如下图所示,当对这棵二叉树进行中序遍历时,得到的元素序列为{35, 37, 47, 51, 58, 62, 73, 88, 93, 99},可以发现它正好是一个从小到大排列的有序的序列。这样的一颗二叉树就叫做"二叉排序树"。

2、二叉排序树的定义
二叉排序树也叫做二叉查找树,它或者是一棵空树,或者是具有以下性质的二叉树:
- 若它的左子树不为空,则左子树上所有结点的值均小于它的根结点的值
- 若它的右子树不为空,则右子树上所有结点的值均大于它的根结点的值
- 它的左、右子树也分别为二叉排序树(递归的定义)
- 如果要删除的结点是二叉排序树中的叶子结点,可以直接删除,对整棵树来说不会影响到其它结点,如下图。

- 如果要删除的结点只有左子树或者只有右子树,则删除结点后,将它的左子树或者右子树整个移动到删除结点的位置即可,可以想象成独子继承父业,如下图。
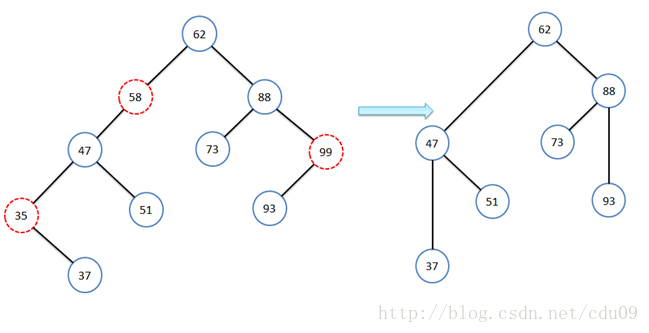
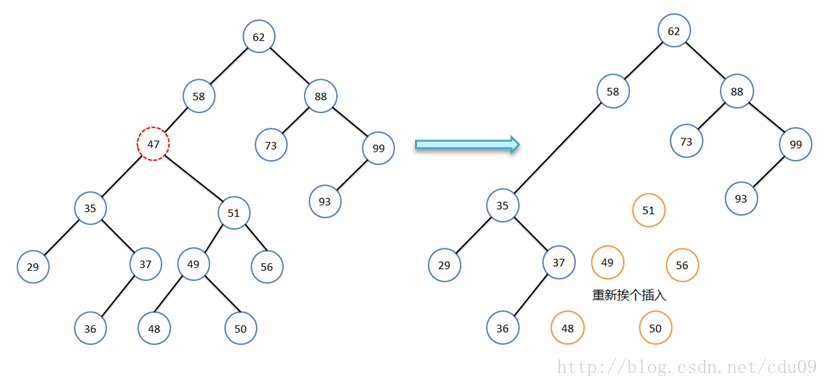
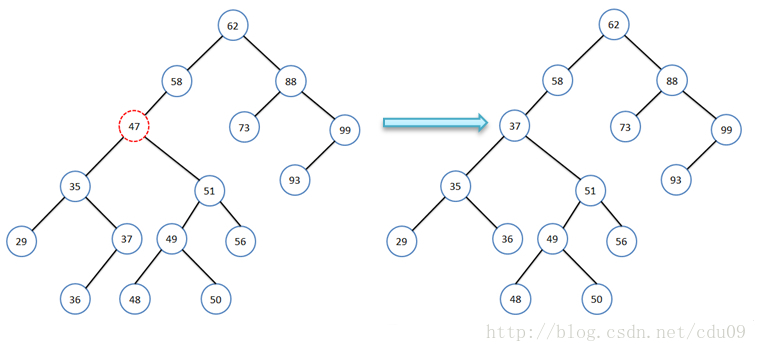
- 如果要删除的结点既有左子树又有右子树,可以先把该结点当成只有左子树,那么做法就如同第二种情况一样;然后再对要删除结点右子树的所有结点重新进行插入,如下图所示,但是这样一来,如果右子树的结点个数很多,效率就很低,而且还会导致整个二叉排序树结构发生很大的变化,有可能会增加树的高度,

- /**************************************************************/
- /** 二叉排序树 **/
- /**************************************************************/
-
- #include <stdio.h>
- #include <stdlib.h>
-
- #define FALSE 0
- #define TRUE 1
-
- typedef int Boolean;
- typedef int ElemType;
-
- // 二叉树的二叉链表结点结构定义
- typedef struct BiTNode
- {
- ElemType data;
- struct BiTNode *lchild, *rchild; // 左右孩子指针
- }BiTNode, *BiTree;
-
- /**
- * 递归查找二叉排序树tree中是否存在key
- * 指针front指向tree的双亲,其初始调用值为NULL
- * 若查找成功,则指针p指向该数据元素结点,并返回TRUE;否则指针p指向查找路径上访问的最后一个结点并返回FALSE
- */
- Boolean SearchBinarySortTree(BiTree tree, ElemType key, BiTree front, BiTree *p)
- {
- if (!tree) // 查找失败
- {
- *p = front;
- return FALSE;
- }
- else if (tree->data == key) // 查找成功
- {
- *p = tree;
- return TRUE;
- }
- else if (tree->data < key)
- {
- return SearchBinarySortTree(tree->rchild, key, tree, p); // 在该结点的右子树继续查找
- }
- else
- {
- return SearchBinarySortTree(tree->lchild, key, tree, p); // 在该结点的左子树继续查找
- }
- }
-
- /**
- * 当二叉树tree中不存在关键字等于key的数据元素时,插入key并返回TRUE,否则返回FALSE
- */
- Boolean InsertBinarySortTree(BiTree *tree, ElemType key)
- {
- BiTree p, s;
-
- if (!SearchBinarySortTree(*tree, key, NULL, &p)) // 不存在关键字为key的数据元素
- {
- s = (BiTree)malloc(sizeof(BiTNode));
- if (!s)
- {
- return FALSE;
- }
- s->data = key;
- s->lchild = s->rchild = NULL;
-
- if (!p) // p为空则说明二叉查找树为空
- {
- *tree = s; // 作为二叉排序树的根结点
- }
- else if (p->data > key)
- {
- p->lchild = s; // s结点作为左孩子
- }
- else
- {
- p->rchild = s; // s结点作为右孩子
- }
- return TRUE;
- }
- return FALSE; // 已经存在关键字为key的数据元素
- }
-
- /**
- * 从二叉排序树中删除结点p,并重接它的左或右子树
- */
- Boolean DoDelete(BiTree *p)
- {
- BiTree q, s;
-
- // 右子树为空,则只需要重接它的左子树
- if ((*p)->rchild == NULL)
- {
- q = *p;
- *p = (*p)->lchild;
- free(q);
- }
- else if ((*p)->lchild == NULL) // 左子树为空,则只需要重接它的右子树
- {
- q = *p;
- *p = (*p)->rchild;
- free(q);
- }
- else // 左右子树均不为空
- {
- q = *p;
- s = (*p)->lchild;
- while (s->rchild) // 转左,然后向右到尽头(找到待删除结点的前驱)
- {
- q = s;
- s = s->rchild;
- }
- (*p)->data = s->data; // s指向被删除结点的直接前驱
- if(q != *p) // 重接q的右子树
- {
- q->rchild = s->lchild; // 重接q的右子树
- }
- else
- {
- q->lchild = s->lchild; // 重接q的左子树
- }
- free(s);
- }
- return TRUE;
- }
-
- /**
- * 若二叉排序树tree中存在关键字等于key的数据元素时,则删除该元素结点,并返回TRUE,否则返回FALSE
- */
- Boolean DeleteBinarySortTree(BiTree *tree, ElemType key)
- {
- if (!tree) // 不存在关键字等于key的数据元素
- {
- return FALSE;
- }
- else
- {
- if (key == (*tree)->data) // 找到关键字等于key的数据元素
- {
- return DoDelete(tree);
- }
- else if (key < (*tree)->data)
- {
- return DeleteBinarySortTree(&(*tree)->lchild, key);
- }
- else
- {
- return DeleteBinarySortTree(&(*tree)->rchild, key);
- }
- }
- }
-
- int main()
- {
- int i;
- Boolean bole;
- ElemType data[10] = {62, 88, 58, 47, 35, 73, 51, 99, 37, 93};
-
- BiTree tree = NULL, p;
-
- for (i = 0; i < 10; i++)
- {
- InsertBinarySortTree(&tree, data[i]);
- }
-
- bole = SearchBinarySortTree(tree, 99, NULL, &p);
- if (bole == TRUE)
- {
- printf("查找成功\n");
- }
- else
- {
- printf("查找失败\n");
- }
-
- bole = DeleteBinarySortTree(&tree, 99);
- if (bole == TRUE)
- {
- printf("删除成功\n");
- }
- else
- {
- printf("删除失败\n");
- }
-
- return 0;
- }



