
- 1DES加密算法|密码学|网络空间安全_des密码
- 2Spring boot 项目(二十三)——用 Netty+Websocket实现聊天室
- 3【错误记录】GitHub 提交代码失败、获取代码失败、连接超时、权限错误、ping 请求连接超时 ( 查找域名对应 IP | 设置 host 文件 )_泛播github
- 4密码算法原理与实现:DES加密算法_在分组密码设计中用到扩散和混淆的理论。理想的扩散是
- 5python石头剪子布while循环_14.python之石头剪子布
- 6各大互联网公司都有哪些部门?核心部门又是什么?一文全知道!
- 7Mysql数据备份一(简易备份)_mysql 实例备份
- 8学历低能进大厂吗?专科学历我慌了,但是我还是顺利拿到了想要的大厂offer!这不美滋滋?!_专科网络技术能进大厂吗
- 9mac Navicat Premium 16 汉化_navicat16汉化包
- 10Windows 10版本更新指南:探索最新功能和优化_win10升级到20h2版本是质量更新还是功能更新
02-过拟合和欠拟合的表现与解决方法_过拟合的表现
赞
踩
1.过拟合
1.1 过拟合的表现
模型在训练集上面表现得非常好,而在测试集和验证集上面表现得非常差,损失曲线呈现一种高方差状态。(高方差指的是在训练集上面误差很低,而在测试集上面的误差相较于训练集大很多)
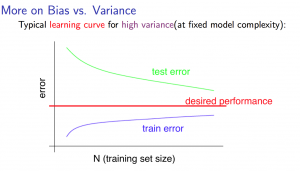
1.2 过拟合的原因
从两个角度区分析:
- 模型复杂度:模型过于复杂,参数量过多,导致模型拥有了可以记住训练数据集细节和噪声的能力,使得模型对新数据的泛化能力差。
- 数据集规模大小:若一个数据集的规模相较于模型复杂度来说太小,模型就会过度挖掘数据集中的特征,把一些不具备代表性的特征和噪声也学习到模型之中。例如一个数据集里面包含着N张黑熊的图片,模型可能就会把黑色与黑熊建立强关联,进而导致模型对于新数据集上像黑色皮毛动物的识别出现问题。当在新的数据集,遇到黑色的动物时,就会把它识别为黑熊。
1.3 过拟合的解决方法
- 获取更多的数据:数据规模增大,可以有效地解决过拟合问题。更多的数据可以让模型学习到更为全面和多样的特征,从而使模型学习到更为具普适性的特征,更好地刻画数据之间的真实联系,减少噪声或者偶然的异常点对模型的影响。此外,因为模型的学习能力是有限的,当训练数据较少的时候,模型会倾向于过多拟合训练集中的噪声信息,而当数据集足够大时,模型就会从大量的样本中筛选出真实的、有代表性的特征,进而增强模型对于未知数据的泛化能力,避免了过拟合的发生。因此,获得更多的训练数据是解决过拟合问题最有效的手段之一。
- 降低模型复杂度:在深度学习中我们可以减少网络的层数,改用参数量更少的模型;在机器学习的决策树模型中可以降低树的高度、进行剪枝等。
- 正则化方法:如 L2 将权值大小加入到损失函数中,根据奥卡姆剃刀原理,拟合效果差不多情况下,模型复杂度越低越好
- 添加BN层:在网络中每一层输入的数据进行归一化,从而使得输入数据具有更加标准的分布,增强了模型的稳定性和泛化性能。
- Early Stopping:Early stopping便是一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。
- 集成学习方法:集成学习是把多个模型集成在一起,来降低单一模型的过拟合风险,例如Bagging方法。
- 交叉检验:如S折交叉验证,通过交叉检验得到较优的模型参数,其实这个跟上面的Bagging方法比较类似,只不过S折交叉验证是随机将已给数据切分成S个互不相交的大小相同的自己,然后利用S-1个子集的数据训练模型,利用余下的子集测试模型;将这一过程对可能的S种选择重复进行;最后选出S次评测中平均测试误差最小的模型。
2.欠拟合
2.1欠拟合表现
模型无论是在训练集还是在测试集上的表现都很差,损失曲线呈现一种高偏差状态。(高偏差指的是训练集和验证集的误差都较高,但相差很少)
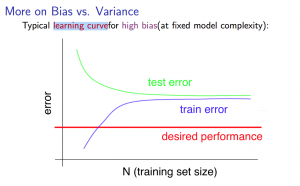
欠拟合的原因
从两个角度来分析:
- 模型过于简单:简单的模型学习能力比较差,无法学习到数据集中代表性的表征信息。
- 提取的特征不好:当特征不足或者现有特征与样本标签的相关性不强时,模型容易出现欠拟合
欠拟合的解决方法
-
增加模型复杂度:如线性模型增加高次项改为非线性模型、在神经网络模型中增加网络层数或者神经元个数、深度学习中改为使用参数量更多更先进的模型等等。
-
调整正则化项:可以增加L1正则项或L2正则项的权重,或者减少Dropout的权重,减少模型的过拟合风险。
-
使用更好的特征:在特征工程方面,可以选择更好的特征、更好的损失函数、更好的优化器等手段来提升模型的性能。
问题解答
答:当训练数据较少时,模型会基于训练数据中较小的样本空间进行学习,因此会更容易受到噪声的影响,从而更容易学习到与真实数据无关的关系或者偏离真实数据的信息。因为在数据中存在一些随机性或者异常值,这些数据在样本空间中的比例往往很小,但是当样本容量较小时,这些数据容易被模型误认为是具有代表性的特征,从而加大过拟合的风险。同时,模型的拟合能力是非常强的,如果只根据较少的数据进行训练,模型会专门追求拟合这些数据,而不是追求对整个数据集的更好的泛化能力,从而导致过度拟合。
正则化是一种常用的限制模型复杂度的方法,可以有效地防止过拟合。其主要思想是在损失函数中添加一个惩罚项,使得模型在训练的过程中不仅要拟合训练数据,还要尽量使得模型参数趋近于零或者较小的值,从而避免模型在训练数据集上拟合得过于复杂,无法很好地推广到未见过的数据集上。
常见的正则化方法包括:
-
L1正则化(Lasso):将模型的目标函数加上L1范数(绝对值)作为惩罚项,可以使得许多模型参数变为0,从而达到特征选择的效果。
-
L2正则化(Ridge):将模型的目标函数加上L2范数(平方和的开方)作为惩罚项,可以有效压缩模型参数,防止过拟合。
-
Dropout:在神经网络训练的过程中,按照一定的概率随机丢弃一些神经元的输出,从而使得不同部分之间的参数得到充分的训练,减轻神经网络的过拟合问题。
当模型的参数量很大时,正则化能够帮助减少模型复杂度,同时避免特别针对训练集的噪声和随机波动而过拟合。通过调整正则化参数的值,可以在训练集和测试集之间取得一个平衡,使得算法能够达到较好的泛化性能。
批量归一化(Batch Normalization,BN)是一种常见的神经网络技术,其主要作用是在网络中每一层输入的数据进行归一化,从而使得输入数据具有更加标准的分布,增强了模型的稳定性和泛化性能,在一定程度上可以抑制过拟合。
主要原因如下:
-
BN层减少了网络输入的内部协变量偏移的影响。内部协变量偏移是指在网络层数较多的过程中,前面层的输入的分布(特征分布)的变化会影响到后面层的学习效果。添加BN层使得输入分布更加稳定,解决了这个问题。
-
BN层可以将训练样本的数据进行归一化,使得输入的数据分布更加标准化,增强了模型对数据的鲁棒性,进而提升了泛化能力。
-
BN层增加了模型的随机性。在训练过程中,BN层会随机选择小批量输入进行归一化,增加了模型的多样性,从而可以减少过拟合的风险。
-
BN层允许增加较大的学习率。因为输入数据被归一化,最终的输出更加稳定,使得模型更容易收敛,从而可以使用更大的学习率,加速训练的过程。
综上所述,BN层对神经网络的性能提升有很大的帮助,并且能够有效地抑制过拟合的问题。
特征生成和特征变换方法一般适用于结构化数据,对于图像等高维数据,常见的特征提取方法可以使用卷积神经网络(CNN)等深度学习模型,将原始数据转化为更高效的特征表示。
CNN可以通过一系列的卷积核和池化操作,从原始图像中自动提取特征,这些特征通常包含不同层次的、非线性的、高维的特征信息,可以有效地提升模型的表达能力和泛化性能。
此外,也可以使用预训练的CNN模型(如Inception、ResNet、VGG等),对图像进行特征提取,然后将这些特征输入到后续的分类或回归模型中继续训练。这种方法可以有效地利用预训练模型的特征提取能力,同时减少数据集的大小和模型复杂度,提高模型的泛化性能。



