- 1【Python数据可视化】matplotlib之设置坐标:添加坐标轴名字、设置坐标范围、设置主次刻度、坐标轴文字旋转并标出坐标值_matplotlib设置xy轴刻度
- 2数据结构应用 - 栈
- 3喷药智能小车——附源代码_智能送药小车代码
- 4‘error:03000086:digital envelope routines::initialization“处理方法
- 5canopen
- 6大数据(四)主流大数据技术_主流的大数据技术
- 7python selenium打开新窗口,多窗口切换_selenium新开一个标签页
- 8人生需要执著——从二本三战到985博士_北理826专业课
- 9apriori数据集_Apriori算法详解
- 10用计算机打女生节快乐,2020年班级女生节快乐的祝福语
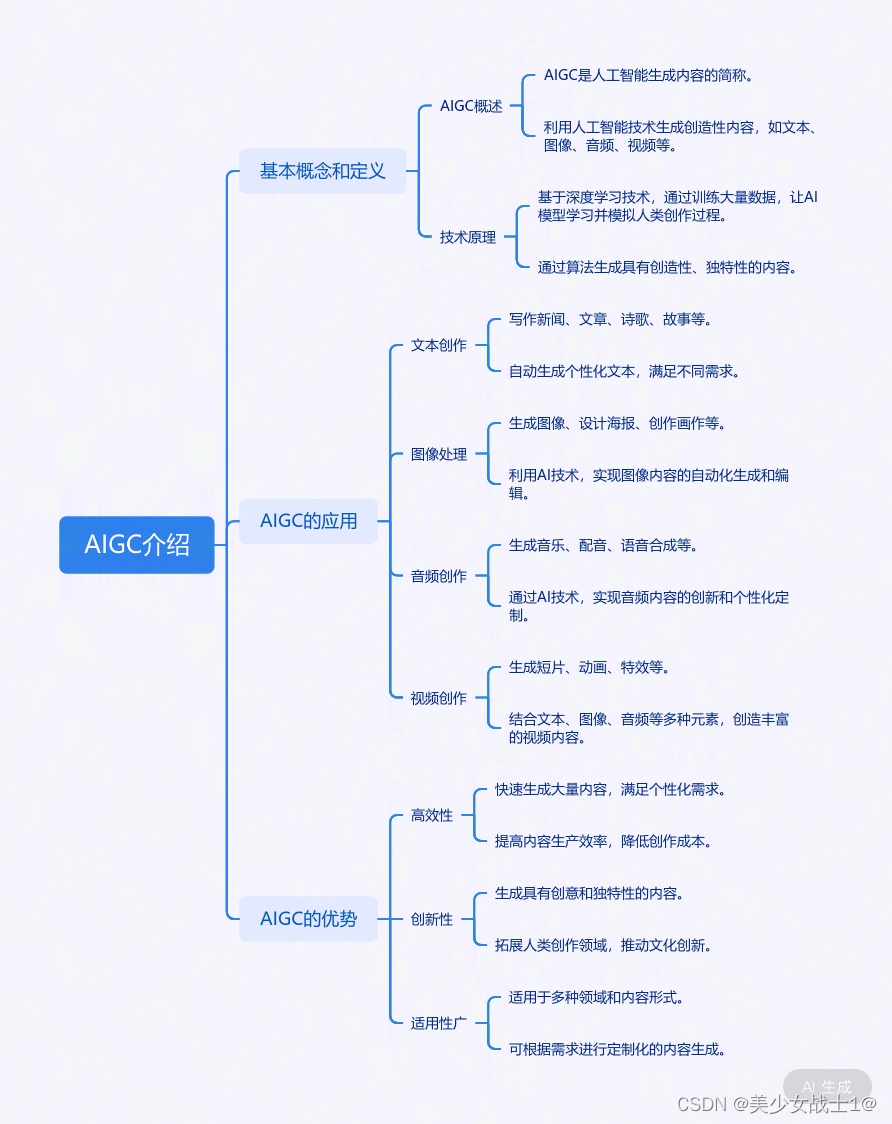
【探索AI】人人都在讲AIGC,什么是AIGC?_人人都可以了解的aigc
赞
踩
一张图先了解下:
概述
"人工智能生成创造(Artificial Intelligence Generated Content,AIGC)"是指利用人工智能技术生成各种形式的创作内容,包括图像、音频、视频等。AIGC 是人工智能在创意领域的应用,通过机器学习、深度学习等技术,让计算机具备创作和生成内容的能力。
在 AIGC 领域,目前最为广泛应用的技术包括生成对抗网络(GAN)、变分自动编码器(VAE)、神经风格迁移等。这些技术能够模仿艺术家的风格、学习输入数据的特征,从而生成类似但又独特的创作内容。
举例来说,通过使用生成对抗网络(GAN),可以让机器学习并生成逼真的图像、视频或音频。GAN 的原理是由两个神经网络组成,一个生成器用于生成样本,一个判别器用于评估生成的样本与真实样本的区别,二者不断博弈提高生成效果。
另一个例子是神经风格迁移技术,它可以将一幅图像的风格转移到另一幅图像上,生成具有原始图像风格的新图像。这种技术被广泛应用于艺术创作、图像处理等领域。
示例展示
1. 图像生成:
- 示例:使用StyleGAN算法生成的名人肖像画。
- 描述:展示一幅由StyleGAN生成的逼真的名人肖像画,如奥黛丽·赫本或莱昂纳多·迪卡普里奥。这些图像几乎难以与真实照片区分开来,展示了AIGC在图像生成领域的惊人能力。
- 技术:StyleGAN是一种基于深度学习的生成对抗网络(GAN),通过训练大量的图像数据,能够生成高质量、多样化的图像。
2. 音频生成:
- 示例:使用Transformer模型生成的语音。
- 描述:播放一段由Transformer模型生成的语音,内容可以是一段新闻报道或诗歌朗诵。这段语音听起来自然流畅,几乎与真实的人类语音无异。
- 技术:Transformer模型是一种基于自注意力机制的深度学习模型,广泛应用于自然语言处理和语音合成等领域。通过训练大量的语音数据,它能够学会生成逼真的语音。
3. 视频生成:
- 示例:使用MotionGAN生成的人物动作视频。
- 描述:展示一段由MotionGAN生成的人物动作视频,视频中的人物动作流畅自然,与真实视频难以区分。这展示了AIGC在视频生成和编辑方面的巨大潜力。
- 技术:MotionGAN是一种结合了生成对抗网络和运动捕捉技术的深度学习模型。它能够学习人物的动作模式,并生成逼真的动作视频。
我们日常用到的一些工具/应用
以下是上述工具/应用的主要作用和擅长领域的简要概述:
-
ChatGPT:
- 主要作用:ChatGPT 是一个基于人工智能技术的语言模型,具备对话功能、语言生成功能、文本分类功能、文本摘要功能、机器翻译功能以及语音合成功能。
- 擅长领域:ChatGPT 在自然语言处理方面表现出色,能够进行流畅和自然的对话,并为用户生成各种文本内容。
-
Midjourney:
- 主要作用:Midjourney 是一款旅行和出行社交应用,提供路线优化、线路推荐、旅行信息、路程追踪以及社交模式等功能。
- 擅长领域:该应用专注于旅行领域,帮助用户更好地规划、享受和分享旅行体验。
-
Adobe Firefly:
- 主要作用:Adobe Firefly 是一款基于人工智能的图像和视频编辑工具,通过语音输入命令快速完成编辑任务。
- 擅长领域:Firefly 在图像和视频编辑方面功能强大,如色彩校正、调整图像大小、添加文本等,以及视频编辑功能如调整音频、添加特效等。
-
文心一言:
- 主要作用:文心一言是一个基于人工智能技术的语言模型,具备表达情感、启示思维和传递文化等功能。
- 擅长领域:文心一言在情感表达、思维启示和文化传播方面表现突出,能够提供深入且富有情感的内容。
-
通义千问:
- 主要作用:通义千问是阿里云推出的超大规模语言模型,具备多轮对话、文案创作、逻辑推理、多模态理解、多语言支持等功能。
- 擅长领域:通义千问适用于多种场景,如在线客服、智能助手、社交聊天、学习辅助等。
-
豆包:
- 主要作用:豆包APP是一款具备自然语言处理和智能推荐功能的AI应用,旨在理解用户需求并提供实用信息。
- 擅长领域:豆包APP擅长多语种、多功能的AIGC服务,如问答、智能创作和聊天,并支持语音播放。
-
Stable Diffusion:
- 主要作用:Stable Diffusion 是一种用于图像生成的模型,能够生成高质量的图像。
- 擅长领域:该模型擅长图像生成,尤其在图像修复、图像合成、图像增强和图像生成等任务中表现出色。
请注意,这些工具和模型的具体功能和擅长领域可能会随着技术的不断发展和更新而发生变化。因此,为了获取最准确和最新的信息,建议您直接查阅官方文档或联系相关供应商。
核心技术介绍
AIGC的核心技术介绍
1. 生成对抗网络(GAN)
原理:GAN由两部分组成——生成器(Generator)和判别器(Discriminator)。生成器的任务是生成尽可能接近真实数据的假数据,而判别器的任务是尽可能准确地判断输入的数据是真实的还是由生成器生成的。两者通过相互竞争和不断迭代优化,最终生成器能够产生非常接近真实数据的输出。
应用场景:图像生成、音频生成、视频生成等。例如,StyleGAN在图像生成领域取得了显著的效果,能够生成高质量、多样化的图像。
2. 变分自动编码器(VAE)
原理:VAE是一种生成式模型,它通过学习数据的潜在表示来生成新数据。VAE包含编码器(Encoder)和解码器(Decoder)两部分。编码器将输入数据压缩成一个低维的潜在表示(latent representation),解码器则从这个潜在表示中重构出原始数据。VAE通过最大化数据的变分下界来优化模型,使得生成的数据尽可能接近真实数据。
应用场景:图像生成、文本生成等。VAE在图像生成方面可以产生多样化的输出,同时保持一定的数据质量。
3. 神经风格迁移(Neural Style Transfer)
原理:神经风格迁移利用深度学习模型(如卷积神经网络)来分离和重组图像的内容和风格。它首先训练一个模型来提取图像的特征表示,然后将这些特征分为内容特征和风格特征。通过优化一个损失函数,可以同时保持图像的内容不变而改变其风格,或者保持风格不变而改变其内容。
应用场景:艺术创作、图像美化等。神经风格迁移可以将一幅画的风格应用到另一幅画上,产生新颖且富有艺术感的作品。
这些核心技术为AIGC提供了强大的支持,使得人工智能能够生成创造性的内容。通过深入了解这些技术的原理和应用场景,学生可以更好地理解AIGC的实现方式和工作原理。
核心技术的算法解析
算法解析
1. 生成对抗网络(GAN)
工作原理:
GAN由两部分组成:生成器G和判别器D。生成器G的任务是生成假数据,而判别器D的任务是判断数据是否为真。训练过程中,G和D相互竞争,不断调整各自的参数,直到G能够生成足以欺骗D的假数据。
输入输出:
- 输入:随机噪声z(对于G)和真实/假数据x(对于D)
- 输出:G输出假数据x’,D输出一个概率值表示x是否为真
关键步骤:
- 初始化G和D的参数。
- 从噪声分布中采样随机噪声z。
- 使用G生成假数据x’ = G(z)。
- 将真实数据x和假数据x’混合,输入到D中进行训练。
- 更新D的参数以最小化真实数据上的分类错误和最大化假数据上的分类错误。
- 使用D的输出作为G的输入,训练G以最小化D的分类准确率。
- 重复步骤2-6直到收敛或达到最大迭代次数。
数学公式:
- D的损失函数:(L_D = -\mathbb{E}{x \sim p{data}(x)}[\log D(x)] - \mathbb{E}_{z \sim p_z(z)}[\log(1 - D(G(z)))])
- G的损失函数:(L_G = -\mathbb{E}_{z \sim p_z(z)}[\log D(G(z))])
图形:
- 可以使用一个简单的流程图来表示GAN的训练过程,包括G和D的交替训练步骤。
2. 变分自动编码器(VAE)
工作原理:
VAE通过编码器将输入数据编码为一个低维的潜在表示,然后通过解码器从这个潜在表示中重构出原始数据。同时,VAE还引入了一个正则化项来鼓励潜在表示遵循一个先验分布(如标准正态分布)。
输入输出:
- 输入:原始数据x
- 输出:重构数据x’和潜在表示z
关键步骤:
- 初始化编码器和解码器的参数。
- 将原始数据x输入到编码器中,得到潜在表示z = Encoder(x)。
- 对潜在表示z进行采样,得到一个新的潜在表示z’。
- 将z’输入到解码器中,得到重构数据x’ = Decoder(z’)。
- 计算重构损失(如均方误差)和潜在表示的正则化损失(如KL散度)。
- 更新编码器和解码器的参数以最小化总损失。
- 重复步骤2-6直到收敛或达到最大迭代次数。
数学公式:
- 总损失:(L_{total} = L_{recon} + L_{KL})
- 重构损失(均方误差):(L_{recon} = \mathbb{E}{x \sim p{data}(x)}[||x - Decoder(Encoder(x))||^2])
- 潜在表示的正则化损失(KL散度):(L_{KL} = \mathbb{E}_{z \sim q(z|x)}[\log \frac{q(z|x)}{p(z)}])
图形:
- 可以使用一个简单的结构图来表示VAE的编码器、解码器和潜在空间。
3. 神经风格迁移
工作原理:
神经风格迁移利用预训练的卷积神经网络(如VGG)来提取图像的内容和风格特征。然后,通过优化一个损失函数来同时保持图像的内容不变而改变其风格,或者保持风格不变而改变其内容。
输入输出:
- 输入:内容图像C、风格图像S和一张随机初始化的空白图像T
- 输出:迁移后的图像T’,它结合了C的内容和S的风格
关键步骤:
- 使用预训练的VGG网络来提取内容图像C和风格图像S的特征。
- 初始化一张空白图像T,并设置优化器(如L-BFGS)。
- 定义损失函数,包括内容损失(内容图像C和迁移图像T’在VGG某一层的特征差异)和风格损失(风格图像S和迁移图像T’在VGG多个层的特征统计差异)。
- 使用优化器迭代更新T的像素值,以最小化损失函数。
- 重复步骤3-4直到达到最大迭代次数或损失函数收敛。
数学公式:
- 内容损失:(L_{content} = \frac{1
案例及部分代码实现
案例分析:AIGC在不同领域的应用与创新
为了让学生更深入地了解AIGC在不同领域的应用和创新,我会分享一些成功的AIGC应用案例,并进行详细分析。
1. 艺术作品
案例:使用StyleGAN生成的名人肖像画
分析:StyleGAN是一种先进的图像生成技术,它通过学习大量的图像数据,能够生成高度逼真和多样化的图像。在这个案例中,StyleGAN被用来生成名人肖像画。通过调整参数和风格,艺术家能够创作出与真实照片难以区分的肖像画,展现出AIGC在艺术创作领域的巨大潜力。
代码实现
要使用StyleGAN生成名人肖像画,首先需要访问一个已经训练好的StyleGAN模型。通常,这些模型是由大型数据集(如FFHQ,即Flickr Faces HQ数据集)训练得到的,包含了数千张高质量的人脸图片。由于StyleGAN模型的复杂性,通常建议使用预训练的模型,而不是从头开始训练。
以下是一个使用Python和PyTorch框架的简化示例,展示了如何使用预训练的StyleGAN模型来生成名人肖像画。请注意,这个示例假设你已经有一个可用的StyleGAN模型和相应的权重文件。
首先,确保安装了必要的库:
pip install torch torchvision
- 1
然后,你可以使用以下代码来加载预训练的StyleGAN模型并生成图像:
import torch from PIL import Image from torchvision import transforms from torchvision.transforms.functional import resize from stylegan2_pytorch import StyleGAN2 # 加载预训练的StyleGAN模型 device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = StyleGAN2(config_path="path/to/config.pt", checkpoint_path="path/to/stylegan2.pt").to(device) model.eval() # 加载并预处理输入图像(如果要用作条件输入) transform = transforms.Compose([ transforms.Resize((1024, 1024)), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ]) # 假设我们有一个名人肖像的输入图像 input_image = Image.open("path/to/celebrity_portrait.jpg") input_tensor = transform(input_image).unsqueeze(0).to(device) # 生成图像 with torch.no_grad(): latent = model.mean_latent(10000) # 使用平均潜在向量 output = model(input_tensor, latent, truncation_psi=0.7, noise_mode='const') # 将输出张量转换为图像 output_image = (output.squeeze().permute(1, 2, 0) * 0.5 + 0.5).clamp(0, 1).mul(255).permute(2, 0, 1).byte().cpu().numpy() output_image = Image.fromarray(output_image.astype('uint8')) # 显示或保存生成的图像 output_image.show() output_image.save("path/to/generated_portrait.png")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
在这个示例中,我们首先加载了预训练的StyleGAN模型,然后定义了一个预处理流程来准备输入图像(如果有的话)。我们使用了模型的mean_latent方法来获取一个平均潜在向量,这个向量通常用于无条件生成。然后,我们调用模型生成图像,并将输出张量转换为PIL图像对象,最后显示或保存生成的图像。
请注意,这个示例仅供学习目的,并且假设你已经有了适当的模型和配置文件。实际使用中,你需要替换config_path和checkpoint_path变量,指向你的StyleGAN模型和权重文件。此外,StyleGAN2模型和其他相关代码可能需要从专门的库或资源中获取。
2. 设计项目
案例:使用VAE生成家居设计方案
分析:VAE(变分自动编码器)是一种生成式模型,能够生成多样化的数据。在这个案例中,设计师利用VAE生成了多种家居设计方案。他们首先训练了一个VAE模型,使其学习到家居设计的潜在表示。然后,通过调整潜在空间的参数,设计师能够生成出各种创新且实用的家居设计方案,从而加速设计过程并拓宽设计思路。
要使用VAE(变分自动编码器)生成家居设计方案,你需要先准备一个包含家居设计图像的数据集,然后训练VAE模型来学习这些设计的潜在表示。一旦模型训练完成,你可以通过调整潜在空间中的向量来生成新的设计方案。
以下是一个使用PyTorch框架实现VAE生成家居设计方案的简化示例代码:
import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torchvision.utils import save_image from torch.utils.data import DataLoader # 定义VAE模型 class VAE(nn.Module): def __init__(self, input_dim=784, hidden_dim=400, latent_dim=20): super(VAE, self).__init__() self.fc1 = nn.Linear(input_dim, hidden_dim) self.fc21 = nn.Linear(hidden_dim, latent_dim) # mean layer self.fc22 = nn.Linear(hidden_dim, latent_dim) # log variance layer self.fc3 = nn.Linear(latent_dim, hidden_dim) self.fc4 = nn.Linear(hidden_dim, input_dim) def encode(self, x): h1 = torch.relu(self.fc1(x)) return self.fc21(h1), self.fc22(h1) def reparameterize(self, mu, logvar): std = torch.exp(0.5*logvar) eps = torch.randn_like(std) return mu + eps*std def decode(self, z): h3 = torch.relu(self.fc3(z)) return torch.sigmoid(self.fc4(h3)) def forward(self, x): mu, logvar = self.encode(x.view(-1, 784)) z = self.reparameterize(mu, logvar) return self.decode(z), mu, logvar # 超参数设置 input_dim = 784 # 图片展平后的维度 hidden_dim = 400 latent_dim = 20 learning_rate = 1e-3 epochs = 50 batch_size = 128 # 数据预处理 transform = transforms.Compose([ transforms.ToTensor(), transforms.Lambda(lambda x: x.mul(255)) ]) # 加载家居设计图片数据集 dataset = datasets.ImageFolder(root='path/to/home_design_images', transform=transform) dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True) # 实例化VAE模型、损失函数和优化器 model = VAE(input_dim, hidden_dim, latent_dim) reconstruction_loss = nn.BCELoss(reduction='sum') kl_divergence_loss = nn.KLDivLoss(reduction='batchmean') optimizer = optim.Adam(model.parameters(), lr=learning_rate) # 训练VAE模型 for epoch in range(epochs): for images, _ in dataloader: # 训练VAE recon_batch, mu, logvar = model(images) reconstruction_loss_batch = reconstruction_loss(recon_batch, images) kl_divergence = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp()) loss = reconstruction_loss_batch + kl_divergence optimizer.zero_grad() loss.backward() optimizer.step() print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item()}') # 生成新的家居设计方案 def generate_designs(model, num_designs=5): with torch.no_grad(): z = torch.randn(num_designs, latent_dim) images = model.decode(z) return images # 生成并保存设计方案 generated_designs = generate_designs(model) save_image(generated_designs.data.cpu(), 'generated_home_designs.png', nrow=5)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
在这个示例中,我们定义了一个VAE模型,它由一个编码器、一个解码器以及一个用于重参数化的函数组成。
3. 影视特效
案例:使用神经风格迁移技术制作电影特效
分析:神经风格迁移是一种能够将一幅画的风格应用到另一幅画上的技术。在影视特效领域,这项技术被用来制作各种独特的视觉效果。例如,在电影中,神经风格迁移可以被用来将某个场景的风格转变为另一个完全不同的风格(如将现代城市转变为中世纪城堡),从而为观众带来全新的视觉体验。
4. 广告创意
案例:使用AIGC技术生成动态广告海报
分析:AIGC技术也可以用于广告创意领域。通过结合图像生成、视频生成等技术,可以快速生成多样化的动态广告海报。这些海报不仅具有高度的创意性和个性化,而且能够根据目标受众的喜好进行定制,从而提高广告的吸引力和转化率。
代码实现
import aigc_library # 假设这是你的AIGC库 # 初始化AIGC库 ai_generator = aigc_library.AIGCGenerator() # 定义海报参数 poster_theme = 'tech' # 海报主题 poster_size = (1920, 1080) # 海报尺寸 dynamic_effects = ['fade_in', 'zoom_out'] # 动态效果列表 # 生成海报背景 background_image = ai_generator.generate_image(theme=poster_theme, size=poster_size) # 生成海报内容 content_image = ai_generator.generate_content_image(theme=poster_theme, text='New Product Launch') # 将内容添加到背景 final_image = aigc_library.combine_images(background_image, content_image) # 添加动态效果 for effect in dynamic_effects: final_image = ai_generator.apply_dynamic_effect(final_image, effect) # 保存或发布海报 aigc_library.save_image(final_image, 'dynamic_poster.mp4') # 假设输出为视频格式 # 发布到社交媒体或网站 # ... # 评估广告效果 # ...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
总结
通过以上案例分析,我们可以看到AIGC技术在不同领域的应用和创新。无论是艺术创作、设计项目、影视特效还是广告创意,AIGC技术都为我们提供了全新的创作方式和手段。
AI 汇总持续整理、持续学习中。。。
试用了部分工具,还可以,跟语言描述有很大关系,有喜欢的可以去试试;
也不能过分依赖AI,有的时候挺一言难尽的。。。
纯属个人观点