
- 1JetBrains 开发工具——免费教育许可申请流程_jetbrains教育
- 2springboot集成kafka多线程消费端的实现_springboot kafka多线程消费
- 3Python + Telnet基本使用_python telnet
- 4安装能调用GPU的pytorch版本_python安装pytorch gpu版本
- 5鸿蒙HarmonyOS4.0开发应用学习笔记_鸿蒙开发文档
- 6【项目实战】python影片数据爬取与数据分析django电影数据网络爬虫与分析系统(源码+答疑+文档报告PPT)
- 7WebSocket + Vue 简单聊天的实现_websocket+kafka+vue
- 8Scrapy_redis+scrapyd搭建分布式架构爬取知乎用户信息_scrapy-redis分布式局域网多台电脑之间怎么建立关联的
- 9基于STM32与FreeRTOS的四轴机械臂项目_基于stm32的机械臂项项目
- 10编写相亲交友源码,应该掌握的简写小技巧_相亲源代码
“自然”语言编程(NLC)的到来比你想象的要快
赞
踩

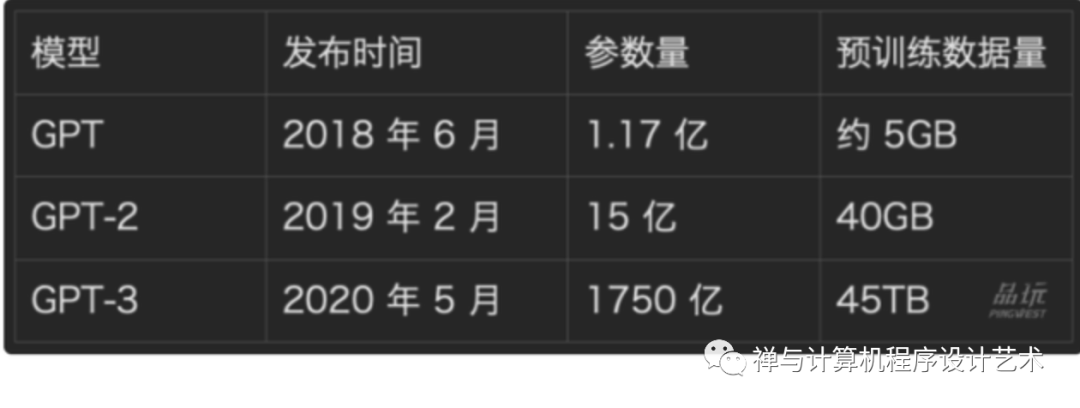
GPT-3
GPT-3 是一个训练集45TB、参数规模1750亿、预训练结果700G的AI模型,其一经问世就成为了万众瞩目的焦点。在其出现之后,使用GPT-3作诗、作曲甚至作画的应用纷至沓来。
AI 编程其实也并非是新鲜事了,之前的AI自动辅助编程工具Copilot也是一个。实际上,Codex更像是Copilot的一个全面升级。二者同样都是再GPT-3的基础上构建而成,不过Codex能够直接将英文需求描述直接转换为代码。
本质上,codex不能创造代码,仅仅是在不停地搬运代码而已。
代码智能
代码智能(code intelligence)的目的是让计算机具备理解和生成代码的能力,并利用编程语言知识和上下文进行推理,支持代码检索、补全、翻译、纠错、问答等场景。以深度学习为代表的人工智能算法,近年来在理解自然语言上取得了飞跃式的突破,代码智能也因此获得了越来越多的关注。该领域一旦有突破,将大幅度推动 AI 在软件开发场景的落地。
基准数据(Benchmark Dataset)对一个领域的发展至关重要。例如,ImageNet(斯坦福大学)极大地推动了计算机视觉领域的发展,类似包含多种任务的 GLUE(纽约大学)和 XGLUE(https://microsoft.github.io/XGLUE/,微软亚洲研究院自然语言计算组)数据集在自然语言处理领域也产生了非常深远的影响。近年来,统计机器学习算法,尤其是深度学习算法在很多代码智能任务(如代码检索、代码补全、代码纠错)上都取得了不错的进展,但是,代码智能领域仍缺少一个能覆盖多种任务的基准数据,以便从不同角度衡量模型的优劣。
微软 CodeXGLUE 项目
微软亚洲研究院(自然语言计算组)联合 Visual Studio 和必应搜索发布了代码智能领域首个大规模多任务的新基准——CodeXGLUE(https://github.com/microsoft/CodeXGLUE)。该基准可覆盖 code-code、code-text、text-code、text-text 四个类别,包含10个任务及14个数据集,具体有:代码克隆检测、代码缺陷检测、代码完形填空、代码补全、代码纠错、代码翻译、代码检索、代码生成、代码注释生成、代码文档翻译十项任务。其中,有自建数据集,也有在业界已有影响力的数据集。
CodeXGLUE 中包含如下十项任务:
代码克隆检测(Clone Detection)。该任务是为了检测代码与代码之间的语义相似度,包含两个外部公开数据集,但任务定义稍有不同。在第一个数据集中,给定两个代码作为输入,要求做0/1二元分类,1表示两段代码语义相同,0表示两段代码语义不同。在第二个数据集中,则给定一段代码作为输入,任务是从给定的代码库中检索与输入代码语义相同的代码。
代码缺陷检测(Defect Detection)。该任务是检测一段代码是否包含可以导致软件系统受到攻击的不可靠代码,例如资源泄露、UAF 漏洞和 DoS 攻击等。该任务中使用了外部公开数据集。
代码完形填空(Cloze Test)。先给定一段代码,但代码中的部分内容被掩盖住,该任务要求预测出被掩盖的代码。研究员们将该任务定义为多项选择题的形式,并构建了两个数据集。在第一个数据集中,被掩盖住的代码可以来自于代码中的任意字符;在第二个数据集中,则试图更有针对性地测试系统对代码 max、min 函数的理解能力。
代码补全(Code Completion),也就是给定已经写好的部分代码。该任务能够自动预测出后续的代码,具体包含两个设置,分别是词汇级别(Token-level)和行级别(Line-level)的补全。顾名思义,前者的任务是补全下一个词汇,而后者的任务是补全一整行代码。词汇级任务使用了两个被外部广泛使用的数据。行级别的任务则是在词汇级别任务的数据上自动构建的数据。
代码翻译(Code Translation)。该任务是把代码从一种编程语言翻译到另一种编程语言。研究员们构建了一个 Java 到 C# 的代码翻译数据集。
代码检索(Code Search)。该任务是为了检测自然语言与代码之间的语义相似度,包含两个数据集,具体定义稍有不同:在第一个数据集中,给定一个自然语言作为输入,任务是从给定代码库中检索与输入自然语言语义最相近的代码,研究人员为该数据新构建了一个测试集,用来更好地测试系统的深层语义理解能力。在第二个数据集中,给定自然语言-代码对作为输入,要求系统做0/1二元分类,1表示语义相似,0表示语义不相似,研究员们同样为该任务构造了新的测试数据集,测试数据的自然语言来自必应搜索引擎,可以更好地反应真实用户的查询习惯。
代码纠错(Code Refinement)。给定一段有 bug 或者复杂的代码作为输入,该任务要求生成被优化后的代码。该任务中使用了一个外部公开的数据集。8. 代码生成(Text-to-code Generation)。给定自然语言注释作为输入,该任务要求自动生成函数的源代码。该任务中使用了外部的公开数据集。
代码注释生成(Code Summarization)。给定一段函数代码作为输入,该任务要求自动生成对应的自然语言注释。该任务中使用了外部公开数据集。
文档翻译(Documentation Translation)。该任务的目的是自动将代码文档从一种自然语言翻译到另一种自然语言,如从英文翻译到中文。该任务中构建了新的数据集。CodeXGLUE 发布在 GitHub 上,参赛者可首先通过 Git Clone 命令下载全部资源。最外层目录对应了四个任务分类,即 Code-code、 Code-text、Text-code 和 Text-text。研究员们为每个任务和数据集都创建了子文件夹,其中包括数据、代码、评测脚本以及说明文档。对于来自外部的公开数据集,则提供了数据下载的脚本;同时,对于需要做预处理的部分数据,也提供了预处理的脚本。
IBM CodeNet 项目
2021年 5 月 5 日, IBM 宣布了 CodeNet 项目:https://developer.ibm.com/technologies/artificial-intelligence/data/project-codenet/ 。
CodeNet 是 ImageNet 的后续,ImageNet 是一个大规模的图像及其描述数据集;图片可免费用于非商业用途。ImageNet 现在是深度学习计算机视觉进程的核心。
CodeNet 是对人工智能 (AI) 编码的一次尝试,就像 ImageNet 对计算机视觉所做的那样:它是一个包含超过 1400 万个代码样本的数据集,涵盖 50 种编程语言,旨在解决 4000 个编码问题。该数据集还包含许多附加数据,例如软件运行所需的内存量和运行代码的日志输出。
谷歌Cloud AutoML

谷歌Cloud AutoML系统基于监督学习,所以需要提供一系列带有标签的数据。具体来说,开发者只需要上传一组图片,然后导入标签或者通过App创建,随后谷歌的系统就会自动生成一个定制化的机器学习模型。
据说,模型会在一天之内训练完成。
整个过程,从导入数据到打标签到训练模型,所有的操作都是通过拖拽完成。在这个模型生成以及训练的过程中,不需要任何人为的干预。
过去几个月里,有几家公司一直在测试Cloud AutoML。其中就包括迪士尼。这套系统让迪士尼在线商城的搜索功能更加强大。
所以,照这个势头发展下去,也许企业以后可能就不用雇佣机器学习和数据专家了。
Cloud AutoML,顾名思义就是云上的AutoML。谷歌去年5月发布AutoML,当时谷歌CEO劈柴哥说,现在设计神经网络非常耗时,对专业能力要求又高,只有一小撮科学家和工程师能做。为此,谷歌创造了一种新方法:AutoML,让神经网络去设计神经网络。
去年11月,谷歌对AutoML进行升级。之前的AutoML虽能设计出与人类设计的神经网络同等水平的小型神经网络,但始终被限制在CIFAR-10和Penn Treebank等小型数据集上。升级之后,AutoML也能应对ImageNet这种规模的数据集了。
总之,这个方法就是让AI设计AI。现在谷歌又把这个技能放到云上了。
加速机器学习
IBM 自己声明 CodeNet 的理由是,它旨在快速更新以过时代码编程的遗留系统,这是自20 多年前 Y2K 恐慌以来期待已久的发展,当时许多人认为未记录的遗留系统可能会失败并带来灾难性后果。
CodeNet 和类似项目最重要的影响是进一步靠近了自然语言编码 (NLC) 。
近年来,OpenAI和 Google 等公司一直在快速改进自然语言处理 (NLP) 技术。这些是机器学习驱动的程序,旨在更好地理解和模仿自然人类语言并在不同语言之间进行翻译。训练机器学习系统需要访问包含以所需人类语言编写的文本的大型数据集。NLC 也将所有这些应用于编码。
编码是一项很难学习的技能,更不用说掌握了,经验丰富的编码员应该精通多种编程语言。相比之下,NLC 利用 NLP 技术和 CodeNet 等庞大的数据库使任何人都可以使用英语,或者最终使用法语或中文或任何其他自然语言进行编码。它可以使设计网站之类的任务变得简单,只需键入“制作红色背景,上面有飞机图像,中间是我的公司徽标,下面是联系我按钮”,然后那个确切的网站就会出现,自然语言自动翻译成代码的结果。
很明显,IBM 的想法并不孤单。GPT-3 是 OpenAI 行业领先的 NLP 模型,已被用于通过编写您想要的描述来对网站或应用程序进行编码。在 IBM 消息传出后不久,微软宣布已获得 GPT-3 的专有权。
微软还拥有 GitHub——互联网上最大的开源代码集合——于 2018 年收购。该公司通过人工智能助手GitHub Copilot增加了 GitHub 的潜力。当程序员输入他们想要编码的操作时,Copilot 会生成一个可以实现他们指定的编码示例。然后,程序员可以接受 AI 生成的样本,对其进行编辑或拒绝,从而大大简化编码过程。Copilot 是向 NLC 迈出的一大步,但还没有实现。
自然语言编码的后果
尽管 NLC 尚不完全可行,但我们正在迅速迈向普通人更容易获得编码的未来。影响是巨大的。
首先,对研究和开发有影响。有人认为,潜在创新者的数量越多,创新率就越高。通过消除编码障碍,通过编程进行创新的潜力得以扩大。
此外,计算物理学和统计社会学等学科越来越依赖定制的计算机程序来处理数据。降低创建这些程序所需的技能将提高计算机科学以外专业领域的研究人员部署此类方法并做出新发现的能力。
然而,也有危险。具有讽刺意味的是,其中之一是编码的去民主化。目前,存在许多编码平台。其中一些平台提供了不同程序员喜欢的各种功能,但是没有一个提供竞争优势。一个新的程序员可以很容易地使用一个免费的、“简单的”编码终端,并且处于一点劣势。
然而,NLC 所需级别的 AI 开发或部署并不便宜,并且很可能被微软、谷歌或 IBM 等主要平台公司垄断。该服务可以收费提供,或者像大多数社交媒体服务一样,免费提供,但使用时有不利或剥削条件。
还有理由相信,由于机器学习的工作方式,此类技术将由平台公司主导。从理论上讲,像 Copilot 这样的程序在引入新数据时会有所改进:它们使用得越多,它们就会变得越好。这让新的竞争者更加困难,即使他们拥有更强大或更合乎道德的产品。
除非有严重的反击努力,否则大型资本主义企业集团似乎很可能成为下一次编码革命的守门人。
业内产品 Copilot、aiXcoder、Tabnine
说到根据自然语言生成代码这样的人工智能,大家可能会第一想到国外的 Copilot,的确,这是一个可以根据自然语言生成相应代码块的AI,一经推出,震惊世界。机智客看到不少地方流传人工智能写代码、取代程序员之类的描述。当然虽然是GitHub家的,不过也不可否认毕竟属于国外公司,而国内有没有Copilot呢?还真有,瞧,它娉娉婷婷一路走来了。
比如,智能编程机器人提供商 aiXcoder 宣布推出国内首个基于深度学习的支持方法级代码生成的智能编程模型——aiXcoder XL。这个对标国外Copilot的AI,也同时理解自然语言和编程代码,它的功能就是根据自然语言来生成相应的完整的代码功能片段。
这款AI,目前已经完成了在程序编写场景下的应用测试,并即将以IDE插件形态推出支持商业编程的产品。当然在XL之前,aiXcoder推出了意味着智能编程产品应用进入“大模型”时代的aiXcoder产品。aiXcoder XL显然是另一种进阶,是另一种超越。
在官方中文站点的演示页面,提供了一个演示性的一键生成代码应用。正因为是演示页,所以它只提供了Java编程语言的演示,也就是你用汉语输入要实现的功能(也就是描述函数功能的自然语言,中英文均可),该应用能给你生成一段实现代码。
Copilot:
https://github.com/features/copilot/
GitHub与Open AI一同合作,推出了一款名为“GitHub Copilot”的AI工具,Copilot可以根据上下文自动补全代码,包括文档字符串、注释、函数名称、代码,只要编程者给出一定提示,这款AI工具就可以补全出完整的函数。
Copilot虽然强大,但就和大部分人工智能工具一样,它仍是建立在OpenAI Codex算法的基础上,需要通过海量的代码来训练其智能程度。这对同样有着微软血统的OpenAI以及Github来说不是问题,微软在2018年斥资75亿美元收购了全球约有5000万用户的代码共享网站Github,这意味着Copilot所依托的Codex算法接受了数十亿行公共代码的训练。
事实早在Copilot诞生之前,OpenAI就推出1750亿参数的AI模型GPT-3,GPT-3耗费了千万美元对人类的诗歌、小说、新闻等海量自然语言进行训练(主要是英语),也因此GPT-3对自然语言具备了一定程度的理解能力。神经网络之父Geoffrey Hinton在GPT-3出现后,曾这样感慨:“生命、宇宙和万物的答案,其实只是4.398万亿个参数而已。”
当然,事物都是两面性的。也有网友表示“Copilot 一时爽,调试火葬场”,因为想要清楚、清晰的描述出目标函数想要实现的功能并不简单,同时在使用Copilot的过程中,需要不断去回顾检查AI生成的代码是否正确,这反而容易干扰到编程时的原有思路。
aiXcoder:
https://aixcoder.com/nl2code/
Tabnine:
https://hub.tabnine.com/v2/home?tabnineUrl=http%3A%2F%2F127.0.0.1%3A5555%2Fsec-eadaphkixnuxppapzzyg
人工智能生成代码,未来,真会成为我们日常开发的必备工具吧。毕竟,随着人工智能技术的成熟,AI势必和渗透到各个领域赋能所有行业和工种,而AI生成代码这事儿,倒不是说AI取代人这么简单粗暴,在数字化数据越来越庞大、工程和项目工作越来越复杂的今天,数据处理工作、计算工作远远超出以往我们能承受的极限了,用AI辅助实现一些功能,提升效率,跟得上日益突出的数据处理和分析工作的进展,是目前发展的一个趋势。
未来地选择应该是AI与人类程序员的配合,而非AI独立完成编码任务。而由此,ctrl+c/v的开发模式终有一天会被淘汰。因为AI最擅长的便是高度模仿过去存在的相似代码,复制粘贴+修补Bug的模式AI可能效率远远高于人类程序员。
未来,初级程序员的需求量将会减少,而信息安全方向将会变得更为吃香——因为,AI的模仿很有可能引用旧版的类库或是软件包,带来潜在的安全隐患。
参考资料
https://thenextweb.com/news/programming-natural-language-syndication
https://www.zhihu.com/question/60465374/answer/1499539780
https://readable.so/
https://openai.com/blog/openai-codex/

