
- 1【中间件】RocketMQ与Kafka的异同_rocketmq的offset和kafka的offset的区别
- 2产品的运营方法
- 3spring boot学习第十七篇:OAuth2概述及使用GitHub登录第三方网站
- 4使用nvidia-ml-py实时监控GPU状态_nvidia-ml-py>=375.53是什么意思
- 5问题 Cannot run program /etc/spark/conf.cloudera.spark_on_yarn/yarn-conf/topology.py No such file
- 6如何有效提升软件测试质量?_如何提高软件测试的质量
- 7【Jenkins】【Jenkins 使用】Jenkins 与 Git_jenkins git
- 8Visual Studio Code(VS Code)启动React项目报错?(附解决方法)_react项目启动报错问题及解决方法
- 9二进制安全找实习记录,网络安全程序员架构之路该如何继续学习
- 10Java基于SpringBoot+Vue的高校招生管理系统,附源码
CVPR 2023 | 港中文联合微软研究院推出基于级联分组注意力模块的全新实时网络架构模型 EfficientViT_级联组注意力的优点
赞
踩
本文首发于微信公众号 CVHub,未经授权不得以任何形式售卖或私自转载到其它平台,仅供学习,违者必究!

Title: EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention
Paper: https://arxiv.org/pdf/2305.07027v1.pdf
Code: https://github.com/microsoft/Cream/tree/main/EfficientViT
导读
本文介绍了一种名为EfficientViT的高效视觉Transformer模型,旨在解决传统Vision Transformer模型在计算成本方面存在的问题,使其适用于实时应用。
众所周知,传统Transformer模型的速度通常受限于内存效率低下的操作,尤其是在多头自注意力机制(MHSA)中的张量重塑和逐元素函数。为了提高内存效率并增强通道间的通信,本文设计了一种新的构建块,采用了"三明治布局(sandwich layout)"策略,即在高效的前馈神经网络FFN层之间使用了一个受内存限制的MHSA。
此外,作者还发现在自注意力机制中,不同头部之间的注意力图具有高度的相似性,导致计算冗余。为了解决这个问题,文章提出了级联分组注意力(cascaded group attention)模块,将完整特征的不同切分输入到不同的注意力头部,从而既节省了计算成本,又提高了注意力的多样性。

最后,通过全面的实验证明了EfficientViT在速度和准确性之间取得了良好的平衡,并超越了现有的高效模型。例如:
EfficientViT-M5在准确性上超过了MobileNetV3-Large1.9%;- 在
Nvidia V100 GPU和Intel Xeon CPU上的吞吐量分别提高了 40.4% 和 45.2%: - 与最近的高效模型
MobileViT-XXS相比,EfficientViT-M2在准确性上优于 1.8%,在GPU/CPU上的运行速度分别提高了 5.8 倍/ 3.7 倍,并且在转换为ONNX格式后的速度提高了7.4 倍;
动机
在这一部分,本文分别从内存访问、计算冗余和参数效率三个方面探讨如何提高视觉Transformer的效率,并通过实证研究来确定速度瓶颈,并总结出有用的设计准则。
内存访问
首先,我们讨论下如何通过减少内存效率低下的层来节省内存访问成本。许多工作提到过,内存效率低下的操作主要位于MHSA层而不是FFN层,如下图所示:

然而,大多数现有的ViT模型在这两个层之间使用了相同数量的层,这可能无法实现最佳的效率。因此,本文探索在小型模型中以快速推理为目标的 MHSA 和 FFN 层的最佳分配。具体来说,作者将 Swin-T 和 DeiT-T 模型缩小,形成几个具有更高推理吞吐量的小型子网络,并比较具有不同比例 MHSA 层的子网络的性能。
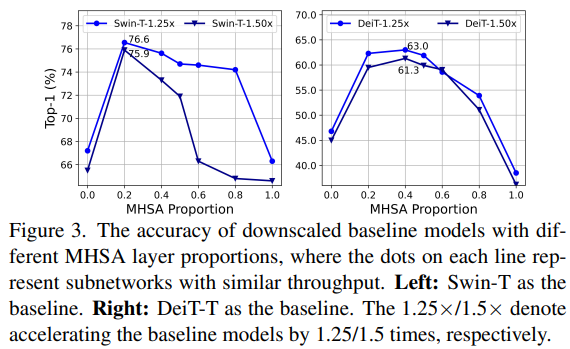
如上图所示,具有 20% 至 40% MHSA 层的子网络倾向于获得更好的准确性。这种比例远小于通常采用 50% MHSA 层的典型 ViT 模型。此外,本文还通过测量内存限制操作的时间消耗来比较内存访问效率,包括重塑、逐元素相加、复制和归一化等操作。结果显示,在具有 20% MHSA层的 Swin-T-1.25× 模型中,内存限制操作的时间消耗仅占总运行时间的 44.26%。这一观察结果也适用于 DeiT 和具有 1.5× 加速的更小模型。因此,适当减少 MHSA 层的利用率完全可以提高内存效率并改善模型性能。
计算冗余
多头自注意力机制是将输入序列嵌入到多个子空间(头部)中,并分别计算注意力图,这之前就被论证过是可以有效提高性能。不过,大家都明白,注意力图的计算成本很高,况且这种多重子空间的表达如何设置数量其实也不好定,这必将导致存在冗余现象。
为了节省计算成本,本文继续探索如何在小型 ViT 模型中减少冗余的注意力。具体来说,作者训练了缩减宽度的 Swin-T 和 DeiT-T 模型,使其推理加速倍数为 1.25 倍,并测量了每个块中每个注意力头部与其他头部之间的最大余弦相似度。

从上图中我们可以观察到,在注意力头部之间存在较高的相似性,尤其是在最后的块中。这种现象表明,许多头部学习了相同完整特征的类似投影,并产生了大量的计算冗余。为了明确地鼓励不同头部学习不同的模式,我们采用了一种直观的解决方案,即将每个头部只用完整特征的一个切分进行输入,这类似于组卷积的思想。通过使用修改后的 MHSA 训练了缩减模型的变体,并在如上图中计算了注意力的相似度。结果显示,在不同的头部中使用特征的不同通道切分,而不是像 MHSA 一样对所有头部使用相同的完整特征,可以有效减少注意力计算的冗余。
参数效率
最后,我们再分析下 QKV 的设置。典型的 ViT 模型主要继承了 NLP Transformer 的设计策略,例如,在 Q、K、V 的投影中使用相等的通道数、在不同阶段增加注意力头数,并将 FFN 的扩展比设置为4。对于轻量级模型,这些组件的配置需要进行仔细的重新设计。因此,EfficientViT 中沿用了 Taylor 结构剪枝方法来自动找到 Swin-T 和 DeiT-T 模型中的重要组件,并探索参数分配的基本原则。剪枝方法在一定的资源约束下移除不重要的通道,并保留最关键的通道以尽可能保持准确性。它使用梯度和权重的乘积作为通道的重要性指标,这近似于移除通道时损失的波动性。
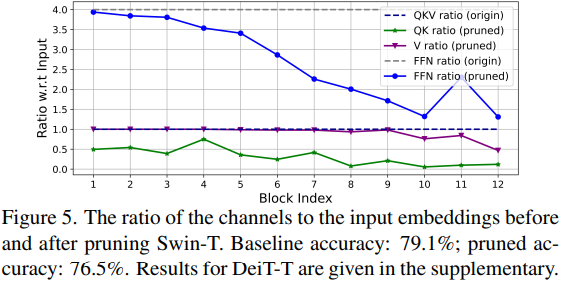
上图展示了输出通道与输入通道之间的比例,并提供了未剪枝模型的原始比例作为参考。观察到以下现象:
- 前两个阶段保留了更多的维度,而最后一个阶段则保留得较少;
- Query、Key 和 FFN 的维度被大幅减小,而 Value 的维度几乎保持不变,只在最后几个块中减少。
这些现象表明:
- 典型的通道配置,即在每个阶段之后加倍通道数或在所有块中使用相同的通道数,可能在最后几个块中产生大量的冗余;
- 当 Q、K 具有相同维度时,Q、K 中的冗余要大得多,而 V 则偏好相对较大的通道数,接近输入嵌入维度。
基于以上分析,下面我们一起看看 EfficientViT 是如何构建的。
方法

图中上半部分为 EfficientViT 的网络架构图,分别由Sandwich Layout block和Cascaded Group Attention等核心模块构成。
EfficientViT Building Blocks
Sandwich Layout
为了构建一个内存高效的块,本文首先提出了一种三明治布局,它使用了较少的受内存限制的自注意力层和更具内存效率的 FFN 层来进行通道通信,抽象公式如下:

该块包含了 N 个 FFN 层,在单个自注意力层之前和之后。这种设计减少了模型中自注意力层引起的内存时间消耗,并应用更多的 FFN 层,以实现不同特征通道之间的高效通信。此外,作者还在每个 FFN 之前应用了一个额外的令牌交互层,使用了深度卷积(DWConv),从而引入有利于局部结构信息的归纳偏差,增强了模型的能力。
Cascaded Group Attention
在 MHSA 中,注意力头的冗余是一个严重的问题,导致计算效率低下。受高效 CNN 中的组卷积启发,本文提出了一种名为级联组注意力的新颖注意力模块,用于视觉 transformer。它将每个头部与完整特征的不同切分进行输入,从而明确地将注意力计算分解到不同的头部中。形式上,这个注意力可以表示为:

尽管使用特征切分而不是完整特征对每个头部进行输入更加高效,可以节省计算开销,但我们可以继续改进其容量,通过鼓励 Q、K、V 层在具有丰富信息的特征上学习投影。最后,通过以级联的方式计算每个头部的注意力图,如上图(c)所示,它将每个头部的输出添加到后续头部中,逐步优化特征表示。
这种级联设计具有两个优势。首先,将不同的特征切分输入到每个头部可以提高注意力图的多样性。类似于组卷积,级联组注意力可以通过 h× 减少 Flops 和参数,因为 QKV 层中的输入和输出通道数减少了 h×。其次,级联注意力头允许增加网络的深度,从而进一步提高模型的容量,而不引入任何额外的参数。它只会带来轻微的延迟开销,因为每个头部中的注意力图计算使用了更小的 QK 通道维度。
Parameter Reallocation
为了提高参数效率,可通过扩展关键模块的通道宽度并缩小不重要的模块来重新分配网络中的参数。具体而言,基于上面提到的 Taylor 重要性分析,本文为每个阶段中每个头部的 Q 和 K 投影设置较小的通道维度。对于 V 投影,作者允许其与输入嵌入的维度相同。由于 FFN 中存在参数冗余,作者还将扩展比从 4 减少到 2。通过提出的重新分配策略,重要模块具有更多的通道数,在高维空间中学习表示,以防止特征信息的丢失。与此同时,不重要模块中的冗余参数被删除,以加速推理过程并增强模型的效率。
EfficientViT Network Architectures
这里我们再简单说下该网络架构的一些具体情况。首先,输入部分采用重叠的图块嵌入将 16×16 的图块嵌入到具有 C1 维度的标记中,这增强了模型在低级视觉表示学习方面的能力。该架构包含三个stage。每个阶段堆叠了提出的 EfficientViT 构建块,并且每个子采样层(分辨率的2×子采样)将标记数量减少了4×。为了实现高效的子采样,作者进一步提出了 EfficientViT 子采样块,它也具有三明治布局,不同之处在于将自注意力层替换为反向残差块,以减少子采样过程中的信息损失。
值得注意的是,本文方法在整个模型中采用批归一化(BN)而不是大多数 ViT 模型都默认采用的层归一化(LN)。作者认为, BN 可以折叠到前置的卷积或线性层中,这在运行时比 LN 具有优势。我们还使用 ReLU 作为激活函数,因为常用的 GELU 或 HardSwish 等激活函数响应速度较慢,有时在某些推理部署平台上不受良好支持。(来自 CNN 组件的反击?)

如上表所示,本文使用六种不同的宽度和深度规模构建了一系列的模型,并为每个阶段设置了不同数量的注意力头。
实验
- 数据集和框架:在ImageNet-1K数据集上进行图像分类实验,使用PyTorch 1.11.0和Timm 0.5.4。
- 训练参数:在8个Nvidia V100 GPU上从头开始训练300个epochs,使用AdamW优化器和余弦学习率调度器。总批量大小为2048。输入图像大小调整为224x224,并进行随机裁剪。初始学习率为1x10-3,权重衰减为2.5x10-2。使用Mixup、自动增强和随机擦除等数据增强方法。
- 吞吐量评估:在Nvidia V100 GPU上测量吞吐量,对于CPU和ONNX,在Intel Xeon E5-2690 v4 @ 2.60 GHz处理器上以批量大小16的单线程运行模型。对于GPU,使用内存容纳的最大2的幂批量大小。对于CPU和ONNX,模型以批量大小16的单线程运行。
- 迁移性:测试EfficientViT在下游任务上的迁移性能,包括图像分类、在COCO上使用RetinaNet进行目标检测以及实例分割。对于图像分类和目标检测,使用AdamW进行300个epochs的微调,批量大小为256,学习率为1x10-3,权重衰减为1x10-8。


总结
本文提出了EfficientViT模型,通过优化内存效率和注意力计算冗余,实现了高速且内存高效的视觉Transformer模型,并在实验中展示了它在速度和准确性方面的优越性能。此外,本文代码已开源,同时提供了转 onnx 等示例,提速非常明显,欢迎大家踊跃尝试!
关注我们
CVHub是一家专注于计算机视觉领域的高质量知识分享平台:
- 全站技术文章原创率达99%!
- 每日为您呈献全方位、多领域、有深度的前沿AI论文解决及配套的行业级应用解决方案,提供科研 | 技术 | 就业一站式服务!
- 涵盖有监督/半监督/无监督/自监督的各类2D/3D的检测/分类/分割/跟踪/姿态/超分/重建等全栈领域以及最新的AIGC等生成式模型!
关注微信公众号,欢迎参与实时的学术&技术互动交流,领取学习大礼包,及时订阅最新的国内外大厂校招&社招资讯!
即日起,CVHub 正式开通知识星球,首期提供以下服务:
- 本星球主打知识问答服务,包括但不仅限于算法原理、项目实战、职业规划、科研思想等。
- 本星球秉持高质量AI技术分享,涵盖:每日优质论文速递,优质论文解读与知识点总结等。
- 本星球力邀各行业AI大佬,提供各行业经验分享,星球内部成员可深度了解各行业学术/产业最新进展。
- 本星球不定期分享学术论文思路,包括但不限于
Challenge分析,创新点挖掘,实验配置,写作经验等。 - 本星球提供大量 AI 岗位就业招聘资源,包括但不限于
CV,NLP,AIGC等;同时不定期分享各类实用工具、干货资料等。


