- 1如何自己的医疗图像分割数据集 使用NNunet进行训练_nnunet处理nii图像
- 2llama.cpp部署通义千问Qwen-14B_llama.cpp qwen
- 3轻松实现微信、QQ防撤回、多开工具_微信防撤回github
- 4napi系列学习基础篇——NAPI数据类型转换与同步调用
- 5用五一最简单的板做一个智能循迹小车_制作一个智能小车,前期有哪些检查工作
- 6干货:用好VSCode这13款插件,工作效率提升10倍_vscode design
- 7Sentence-Transformer的使用及fine-tune教程_distiluse-base-multilingual-cased
- 8一招解决从GItHub下载文件过慢问题_python下载github慢
- 9宇信科技:强势行业加速融入AIGC,同时做深做细
- 10用云手机运营TikTok有什么好处?
智能GDAI创作系统ChatGPT网站源码详细搭建部署教程文档_chatgptweb搭建
赞
踩
智能AI创作系统ChatGPT源码下载。智能GDAI创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型+国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说GDAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作ChatGPT小编这里写一个详细图文教程吧!本系统使用Nestjs+Vue+Typescript框架技术,持续集成AI能力到本系统。支持GPT-4-Turbo模型、支持DALL-E3文生图,支持最新GPT-4-Turbo模型、GPT-4-1106-Preview多模态模型。支持GPT-4图片对话能力上传图片并识图理解对话。
———————————————————————————————————————————
项目介绍
快速体验
-
系统用户端:
-
测试账号密码:admincs 123456
系统架构技术栈
-
前端:Vite4 + Vue3 + TS + Naive-UI
-
管理端:Vite4 + Vue3 + Element-Plus
-
服务端:Nodejs + NestJs
-
数据库:=Mysql5.7 + Redis
-
额外数据存储:阿里云oss | 腾讯云cos | chevereto图床 任选其一
交付及授权内容
因产品属于虚拟商品和技术服务,一经交付,概不退款,请知悉!
GDAI系统程序(内含用户端、管理端、服务后端三端为开源代码
前端编译后代码(打包后代码、但仍然支持可以修改部分内容以及替换掉部分静态资源文件)
私有化部署文档 (提供系统部署文档,不免费部署)
授权方式
服务器IP授权
不限量服务器ip换绑、随时换绑服务器
换绑为免费换绑
系统搭建部署所需准备内容
-
域名
-
云服务器:Linux服务器至少1核心2G内存
-
(根据必要软件安装情况增减配置,GDAI系统运行占用0.5G左右内存),建议2C4G配置起步
-
云服务器数量:AI系统部署国内国外服务器都可以,由于MJ绘画是海外服务需要中转,故海外服务器必需1台,用于搭建绘画API系统(推荐使用阿里香港轻量应用级服务器2C4G起,性价比高),国内服务器可有可无
-
存储服务(可选):为了更好的体验存储到 阿里云OSS对象存储、 腾讯云COS对象存储、Chevereto图床
-
邮箱服务(可选):用于系统用户邮箱注册验证模块、可使用 163邮箱、QQ邮箱、阿里云邮箱等具有SMTP发信的邮箱......
-
短信服务:本系统使用阿里云短信服务、当您配置并开启后则表示开启用户端手机号注册的行为
-
AI模型API:系统支持官方API和中转API(若无API不了解或者无中转API,提供中转API渠道)
-
Midjourney绘画功能模块: 使用官方订阅账户
-
微信登录(可选):需要一个官方的公众号【必须是服务号】不使用则不开启微信登录功能
-
支付模块(可选):系统支持4种支付接口(微信官方支付、易支付、码支付、虎皮椒支付)任选其一,建议使用微信官方支付
-
百度统计账号(可选):百度统计提供了免费的统计服务、我们只需要申请服务即可享受免费的流量统计,你可以自行前往百度统计官方平台申请、将用于首页的统计量访问图表展示、这是免费的服务、百度就可以找到很全面的教程、申请入口是这里:百度统计申请地址
-
其他准备内容:根据版本更新及自身所需
二、功能介绍
已支持 OpenAI GPT全模型 + 国内AI全模型 + 绘画池系统 + MJ局部编辑重绘功能+OpenAI TTS语音对话功能 + 文档对话总结功能 + Midjourney绘画动态全功能!
GDAi系统核心功能:
-
AI提问:程序已支持GPT3.5,GPT4.0提问、OpenAIGPT全模型+国内AI全模型、支持GPT联网提问
-
已支持OpenAIGPT全模型+国内AI全模型,已支持国内AI模型 百度文心一言、微软Azure、阿里云通义千问模型、清华智谱AIChatGLM、科大讯飞星火大模型、腾讯混元大模型等
-
ChatFile文档上传对话功能以及总结对话
-
新增知识库接入(对接百度千帆知识库),用户端动态显示知识库插件并通过插件的方式选择与知识库对话,可自定义训练内容回答和文档总结,上传文档作为知识库内容用于特定场景对话回答,比如企业文化规章制度、产品说明文档、客服等等各行业知识库等
-
新增支持MJ最新V6绘画模型(V6模型:能够处理更长的提示词,人物效果更加真实,构图、色调、光影更加细腻)
-
AI绘画:Midjourney绘画(全自定义调参)、Midjourney以图生图、Dall-E3绘画
-
Midjourney绘画动态全功能、绘画过程中实时预览缩略图以及同步实时进度显示
-
支持最新GPT-4多模态模型、OpenAI GPT-4-Turbo-With-Vision-128K模型
-
已支持GPT-4图片对话能力(上传图片并识图理解对话)可同时支持5张图同时上传对话
-
对话插件系统,后续逐步增加插件功能,扩展AI能力
-
新增KEY支持单独配置消耗费率,比如GPT4-32K比GPT4成本更高应该消耗更多的额度次数
-
微信公众号+邮箱+手机号注册登录
-
一键智能思维导图生成
-
应用广场,支持用户前台自定义添加私密或共享
-
AI绘画广场(画廊)
-
邀请+代理分销模式、用户每日签到功能、会话记录同步保存
-
支持对接微信官方支付、易支付、码支付、虎皮椒支付等,自定义聚合会员套餐
-
其他核心功能、后续其他免费版本功能更新
当前官方站点版本GDAi【V5.0.0】
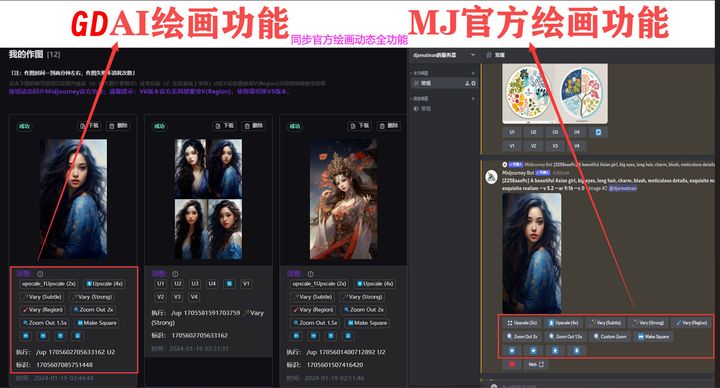
添加图片注释,不超过 140 字(可选)
三、GDAi系统更新日志
四、系统授权
GDAI系统源码授权
-
作者QQ:120758225、作者微信:jiqimeng ,添加请备注‘GDAi’
-
高级套餐包含低级套餐的全部内容,可以差价升级!远程:1小时内算一次。
-
因产品属于虚拟商品和技术服务,一经交付,概不退款,请知悉!
系统(私有化独立部署)授权价格
已支持 OpenAI GPT全模型 + 国内AI全模型 + 绘画池系统 + MJ局部编辑重绘功能+OpenAI TTS语音对话功能 + 文档对话总结功能 + Midjourney绘画动态全功能!
随着功能的不断开发新增和完善,价格会逐步提升,免费更新版本,已经购买的用户不受影响!
套餐一:【独立站账号开通】 :适合所有人员
限时优惠售价688,日常售价(988),【您将获得】,其中包含两个系统:
① + ②GDAi系统(永久使用,无需部署):
-
永久免费更新特权、后续的更新将不需要任何费用
-
不限量使用期限,无需部署,一个账号即可自由发挥
-
1对1客服解答
-
(自行按照教程搭建配置)
绘画API系统文档:1.Midjourney-Proxy-API部署文档
套餐二:【私有化独立部署搭建一条龙服务】
限时优惠售价2988【您将获得】,后续售价(3288)
-
套餐一系统源码授权包含套餐
-
一条龙搭建好,可永久后期帮系统更新
-
对接配置:服务器环境安装、系统部署、绘画池API系统搭建配置、后台支付、微信公众号、短信注册登录、MJ对接、COS存储桶、KEY池等等
-
作者vip服务、作者专属vip指导、保证您的服务稳定
-
适合不会任何技术但节省时间想使用此网站的人群。只需要管理和使用即可,搭建配置技术全包!
-
(自备服务器,域名,MJ会员,支付商户接口等):可协助申请指导!
套餐三:【系统授权+前端全开源源代码】
-
可二次开发任意界面UI
-
远程演示:基本使用教学(源码打包编译合并等教学)
-
价格等请加作者微信:jiqimeng 咨询
其他套餐:【GDAi系统全开源源代码】
-
包含前端、后端、服务端,三端源码
-
远程演示:基本使用教学(源码打包编译合并等教学)
-
多服务器分离部署教学
-
价格请加作者微信:jiqimeng 咨询
-
有开发能力个人或者公司可入
-
系统使用教程
-
分销商使用说明
-
1、首先在后台打开分销开关,及设置佣金比例 分销层级只能是二级,无法拿到第三层及以上层级的分佣 直推分佣比例:是第一级分销商的分佣比例 间推分佣比例:是第二级分销商的分佣比例
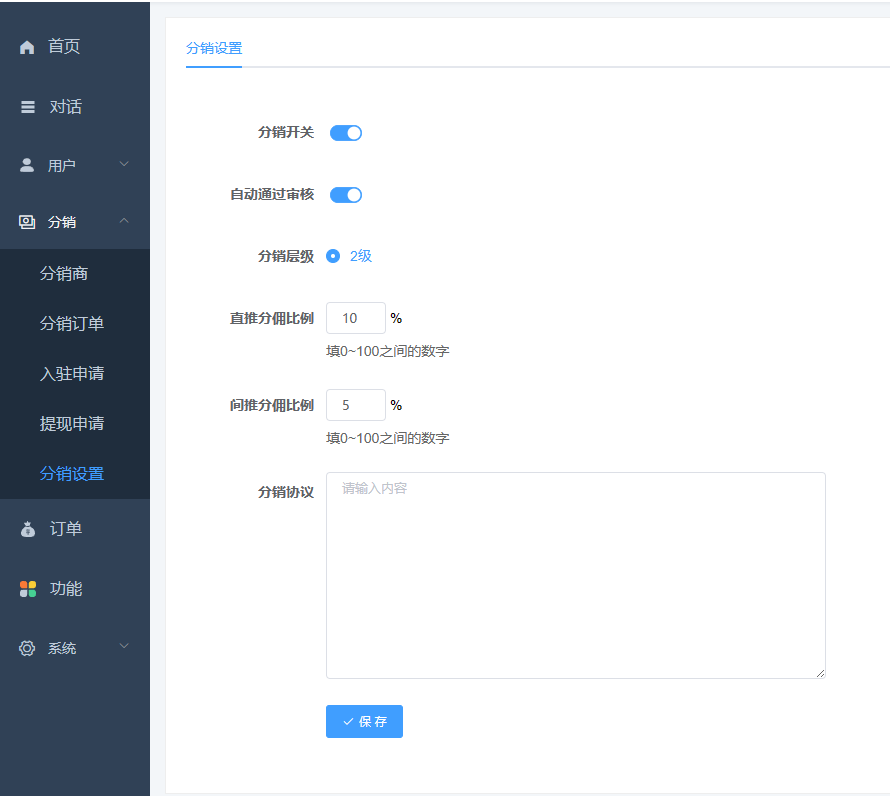
2、用户申请成为分销商 用户在小程序端、H5端申请成为分销商,后台可设置申请是否自动通过审核(见上一步) 通过申请之后,用户可进入分销中心。

3、申请提现 用户在分销中心申请提现,上传微信、支付宝收款码 后台看到申请以后,审核并给用户手动打款,并将状态置为已打款。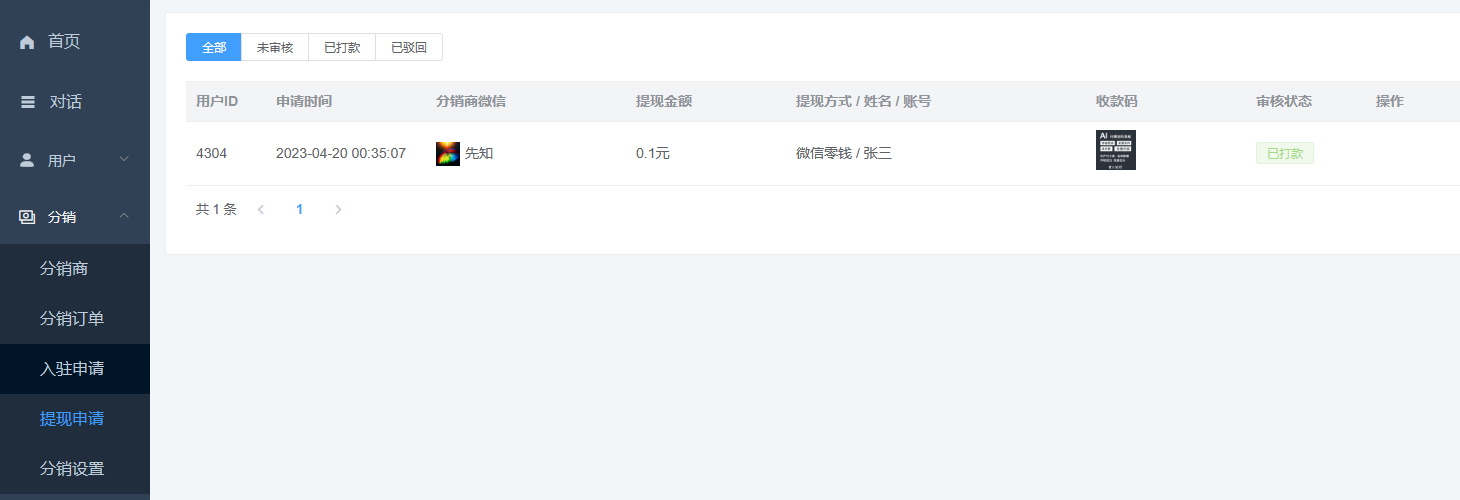
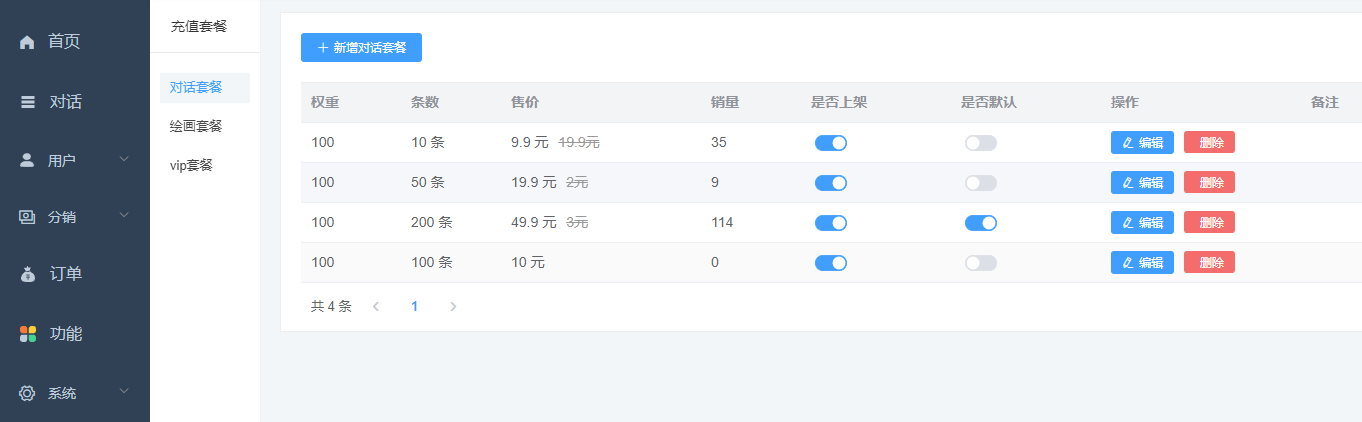
如何设置对话套餐、VIP套餐和绘画套餐?
1、设置对话套餐 站点后台->功能->充值套餐->新建对话套餐
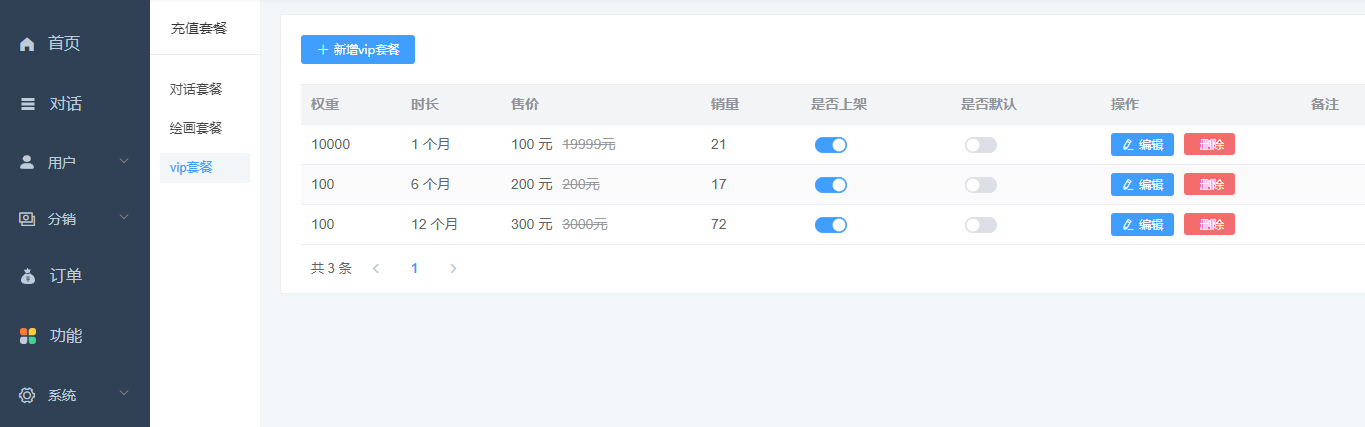
2、设置VIP套餐 站点后台->功能->充值套餐->新建vip套餐
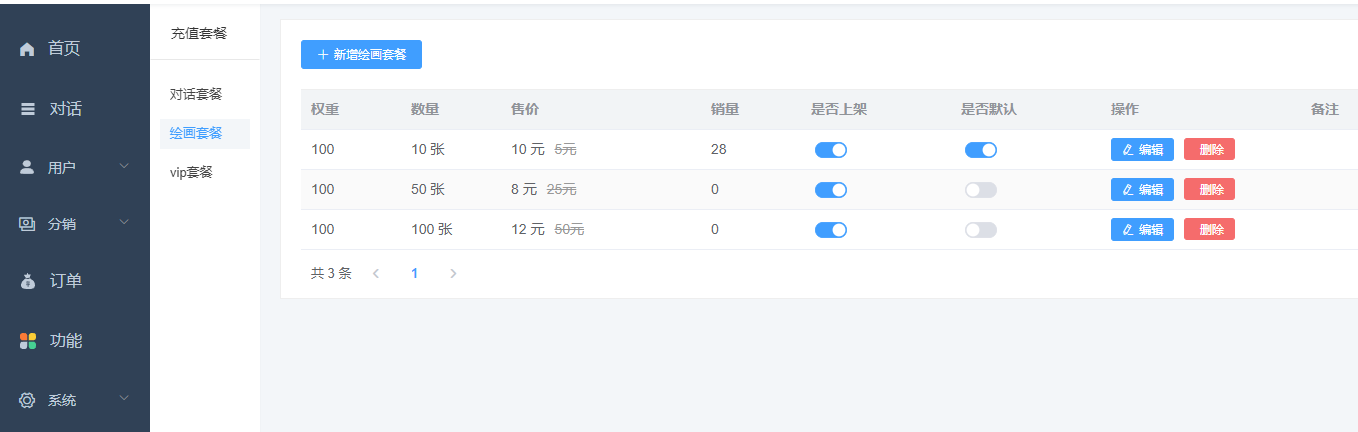
3、设置绘画套餐 站点后台->功能->充值套餐->新建绘画套餐
注:绘画和4.0对话不属于vip范畴,vip期间使用绘画也是消耗次数的。 前端小程序和H5展示效果如下图:

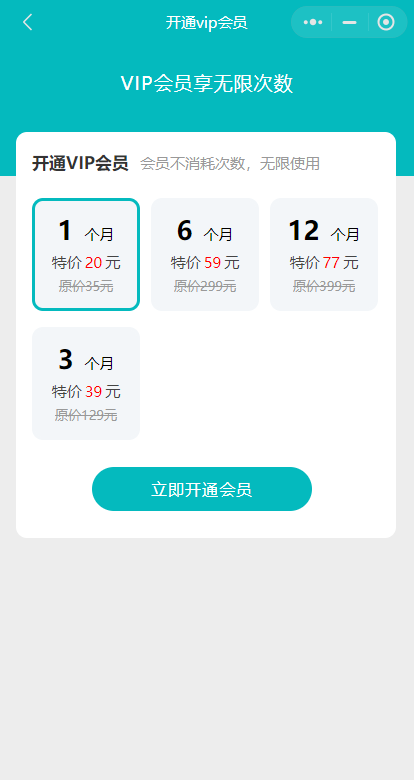
如何设置每日任务?
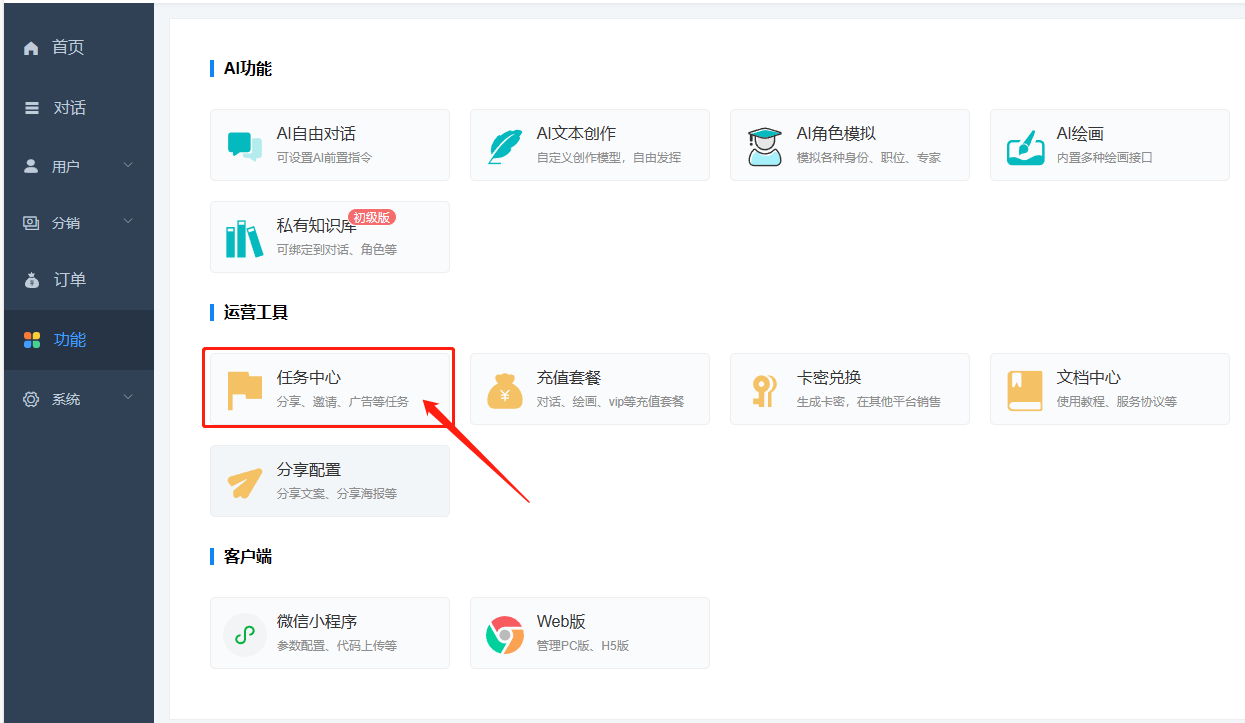
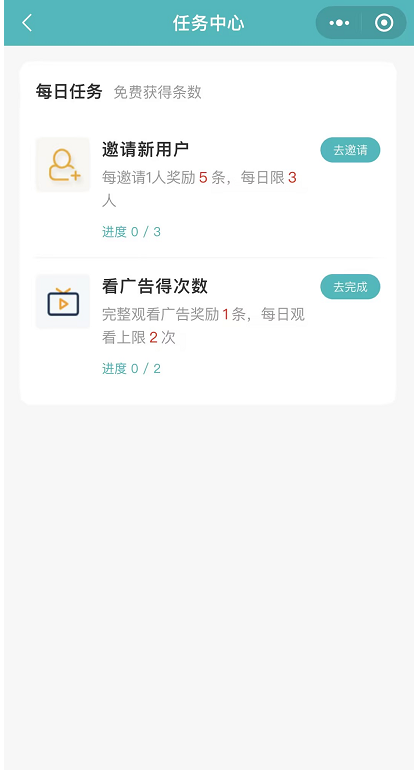
每日任务在站点后台-功能-任务中心设置,分为邀请奖励和激励广告(激励广告需要小程序开通流量主广告)。 站点后台可根据自己的需求来设定用户完成每日任务的奖励程度
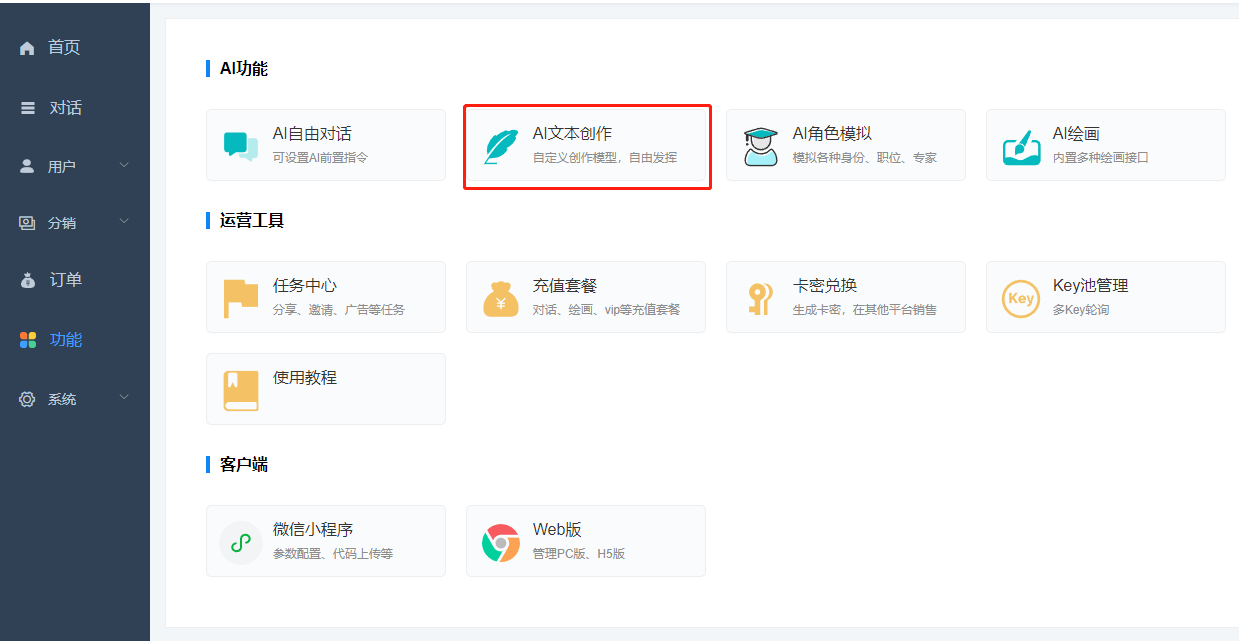
如何创建创作模型?
1、添加模型类别 首先创建类别,把模型归类在合适的类别,利于寻找
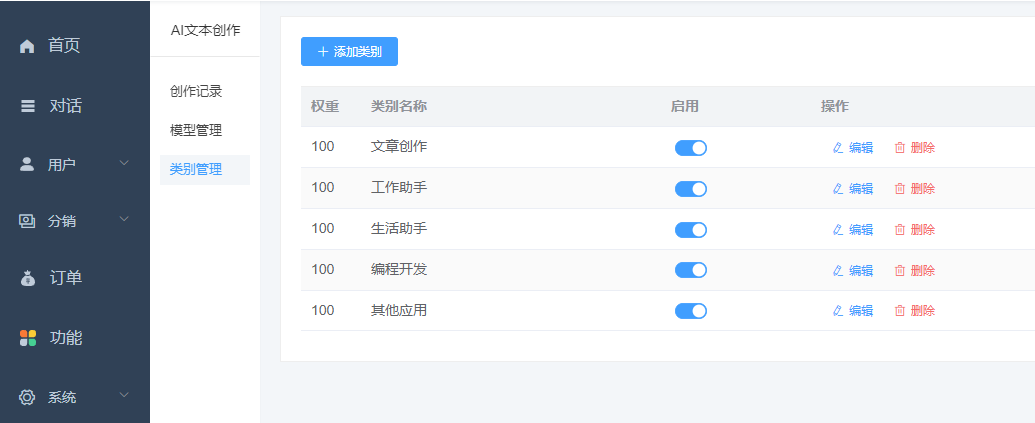
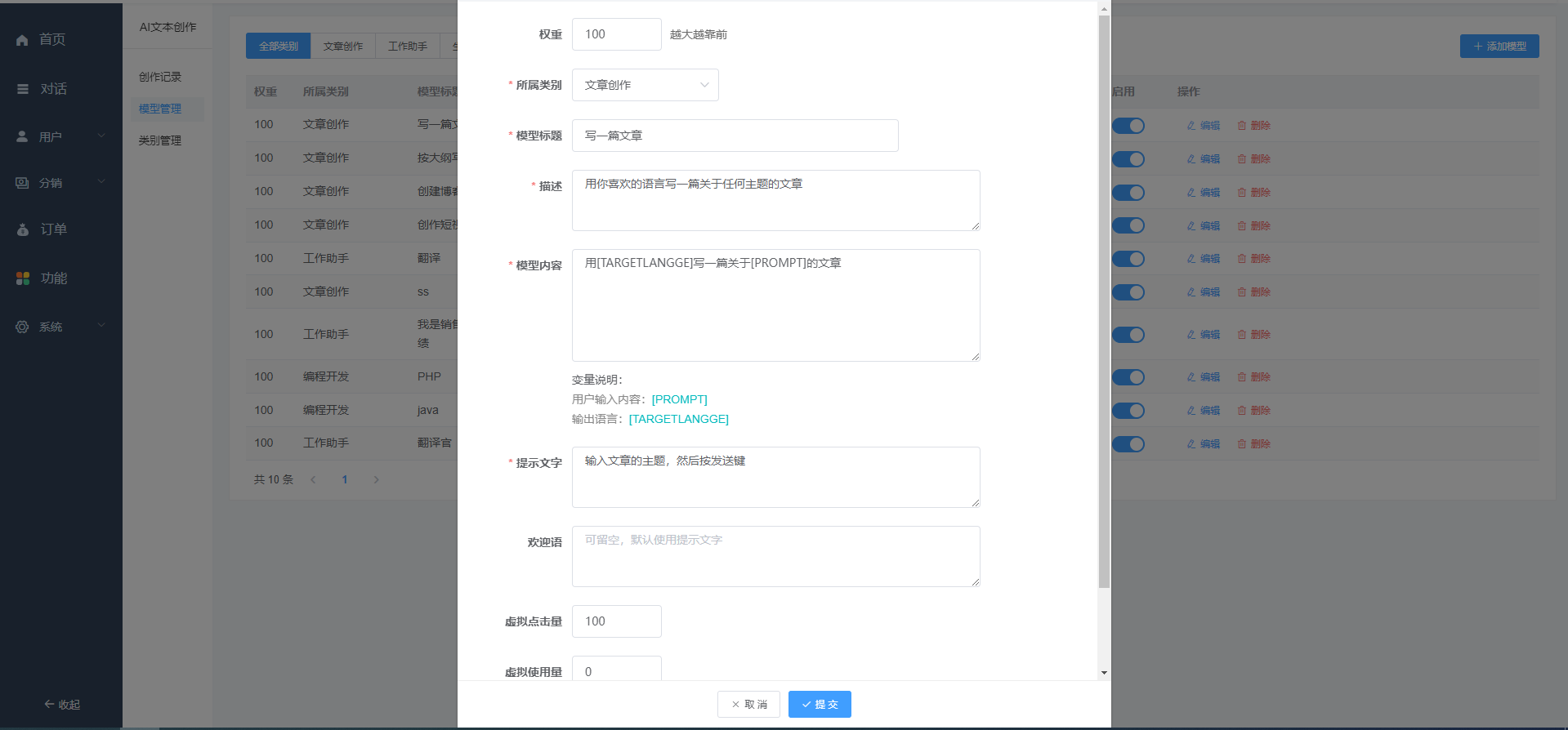
2、模型添加 参考系统内置的几个模型,添加自己的模型(我们也在整理更多的模型库,陆续开放参考) 填入模型标题、描述、内容、提示文字等

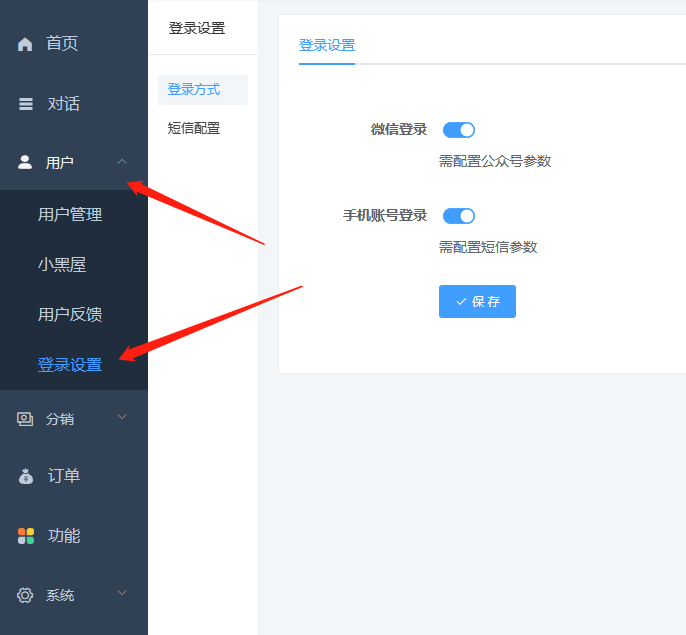
短信参数配置教程
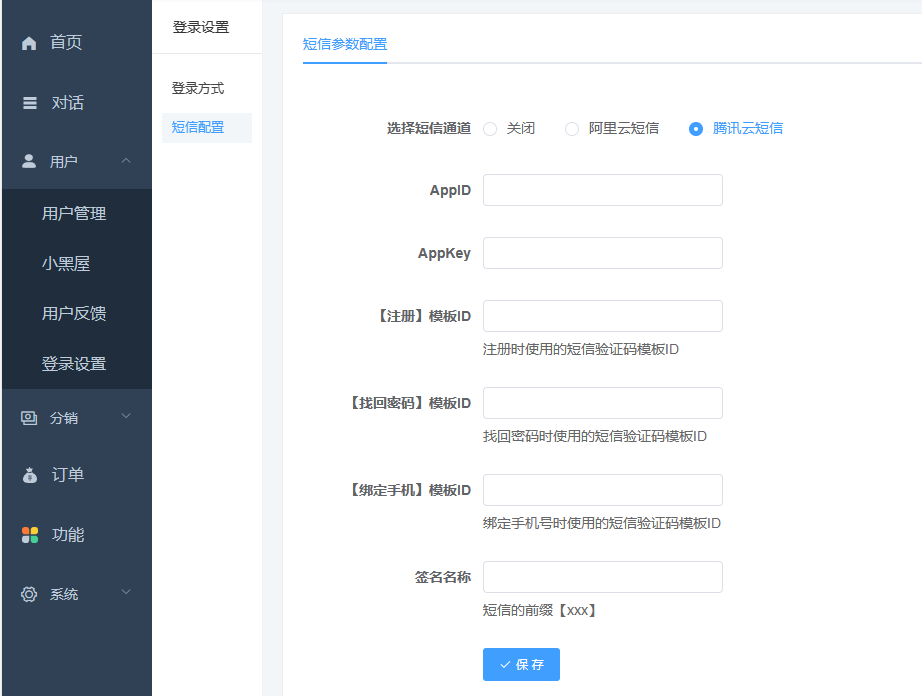
一、短信参数配置位置:站点后台-用户-登陆设置,打开手机账号登陆开关
二、购买短信套餐(阿里云或者腾讯云的选其一),进入短信配置参数。(以下分别有腾讯云和阿里云的短信配置) (一、)腾讯云短信配置
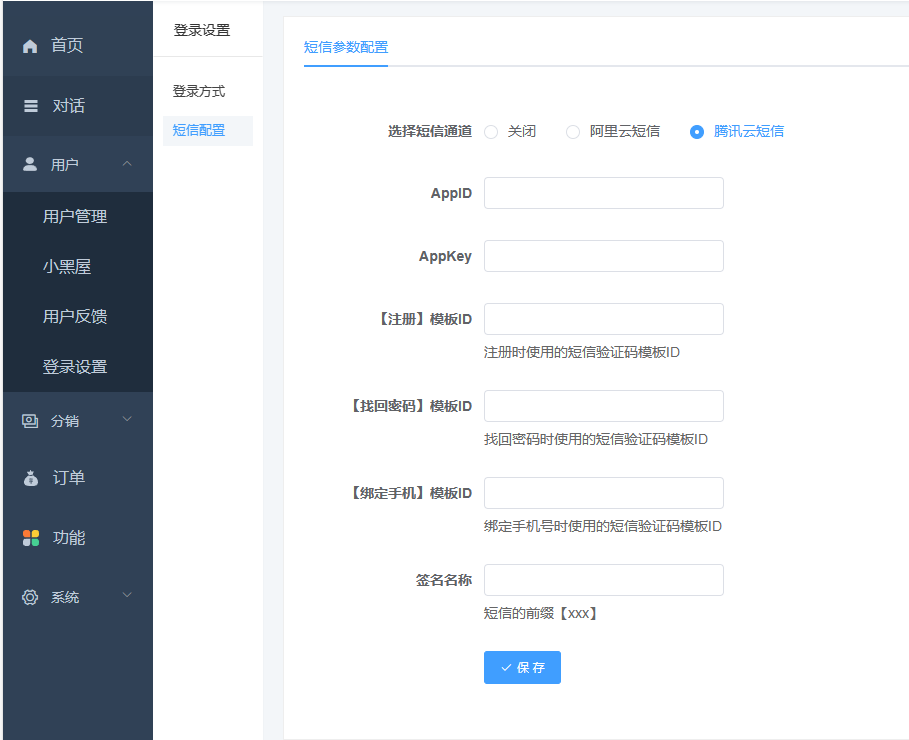
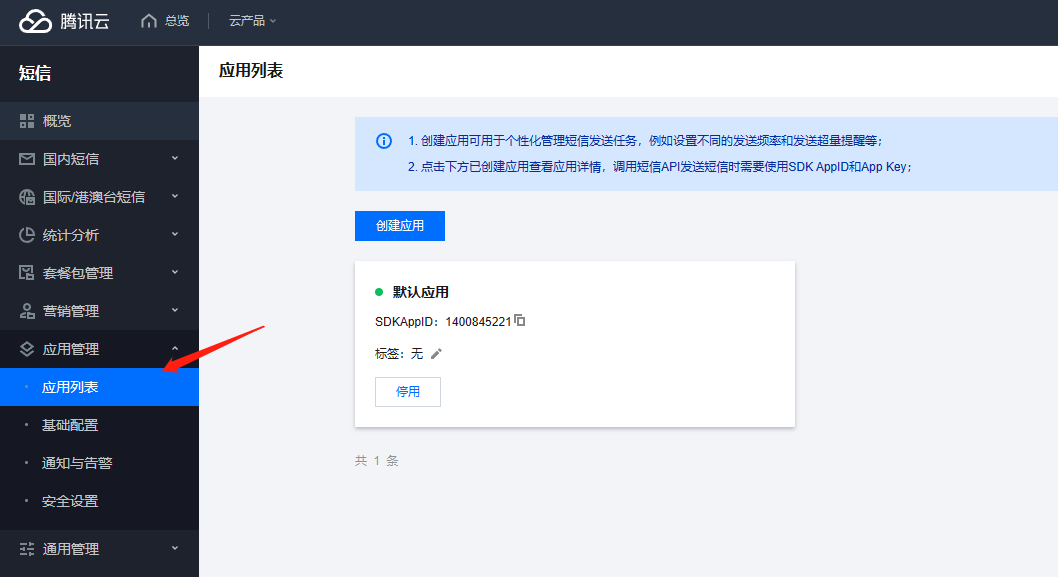
1、腾讯云短信的APPID和APPKEY,在短信后台的(应用管理)应用列表里,点进应用里找APPKEY
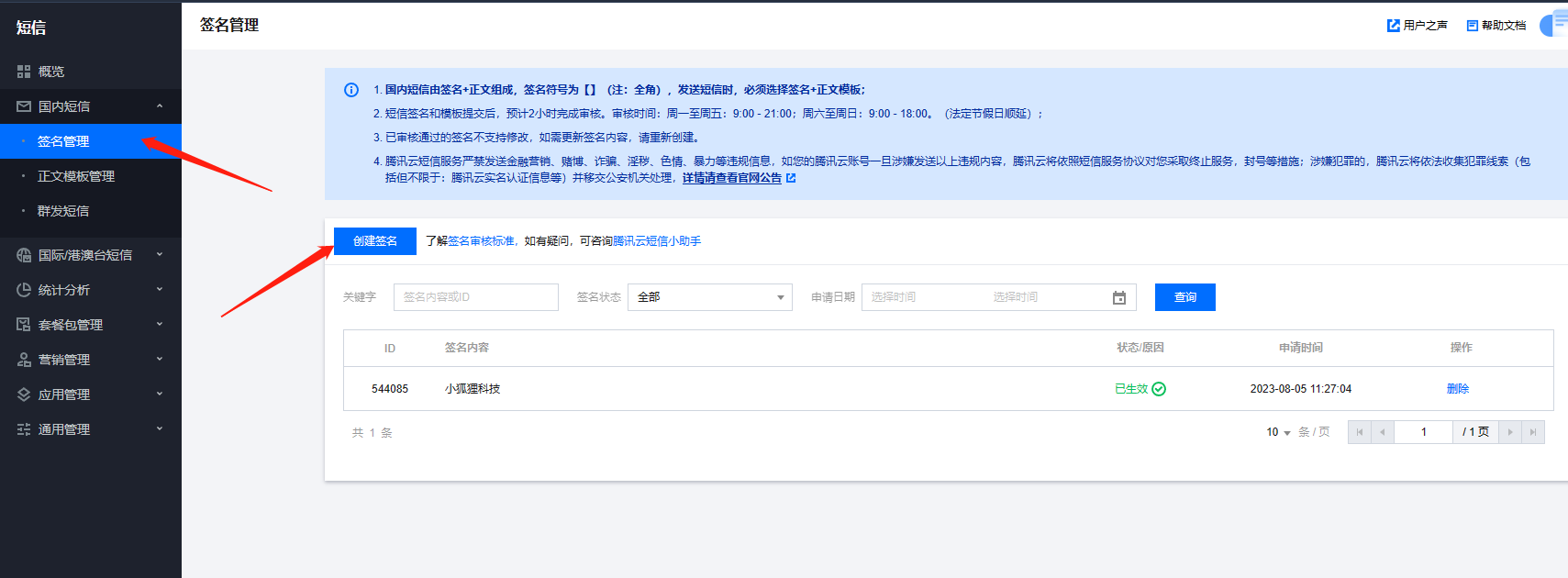
2、短信签名(位置:国内短信-签名管理)没有的话,需要先创建,然后提交审核,通过后才能使用
创建签名填写注意: 签名来源不要选测试或学习
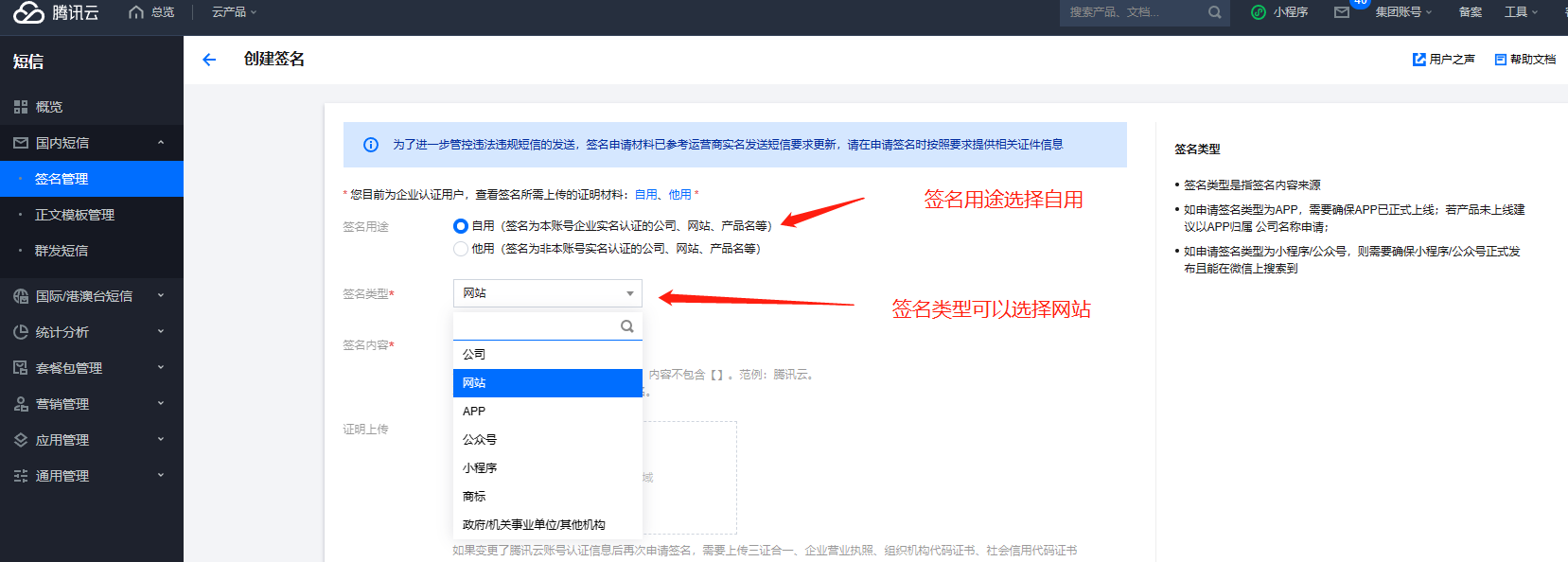
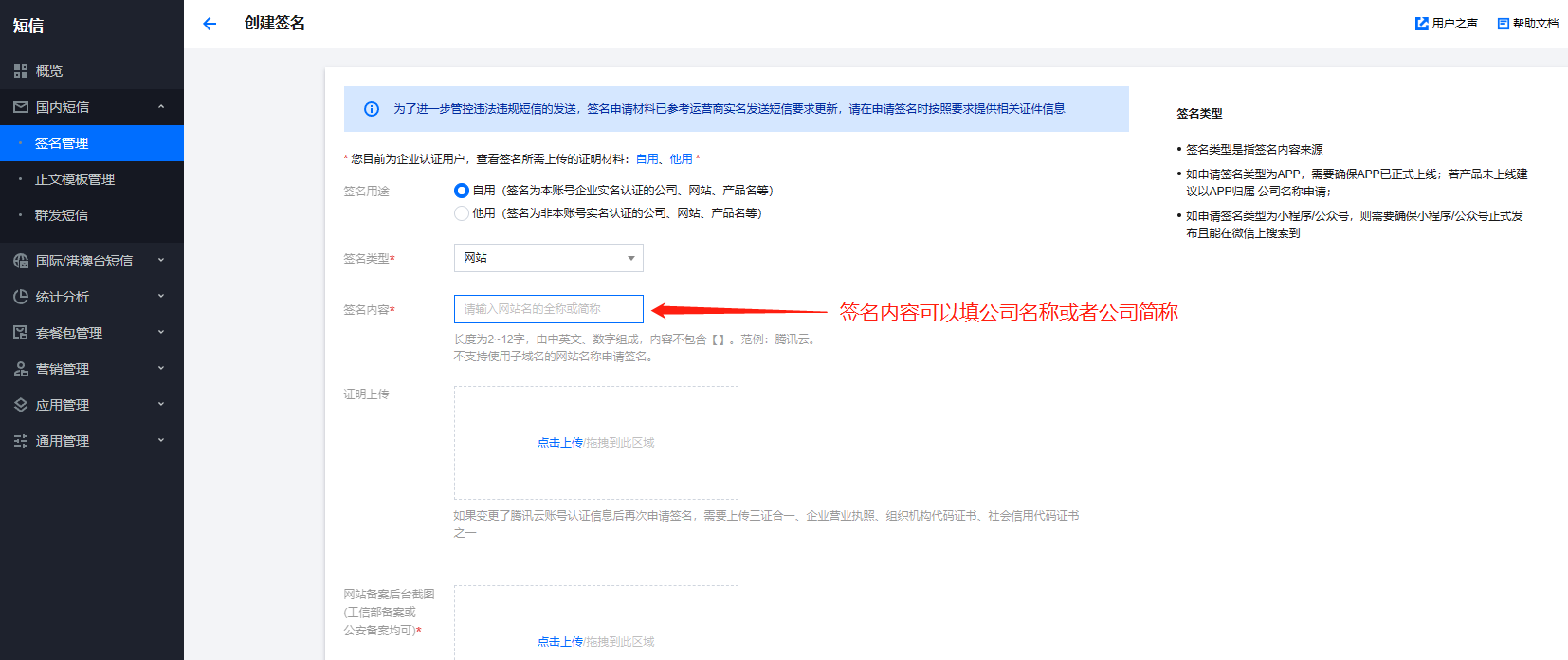
其他按照提示的创建要求填即可。 审核通过后,把签名内容填到站点后台短信参数的签名名称
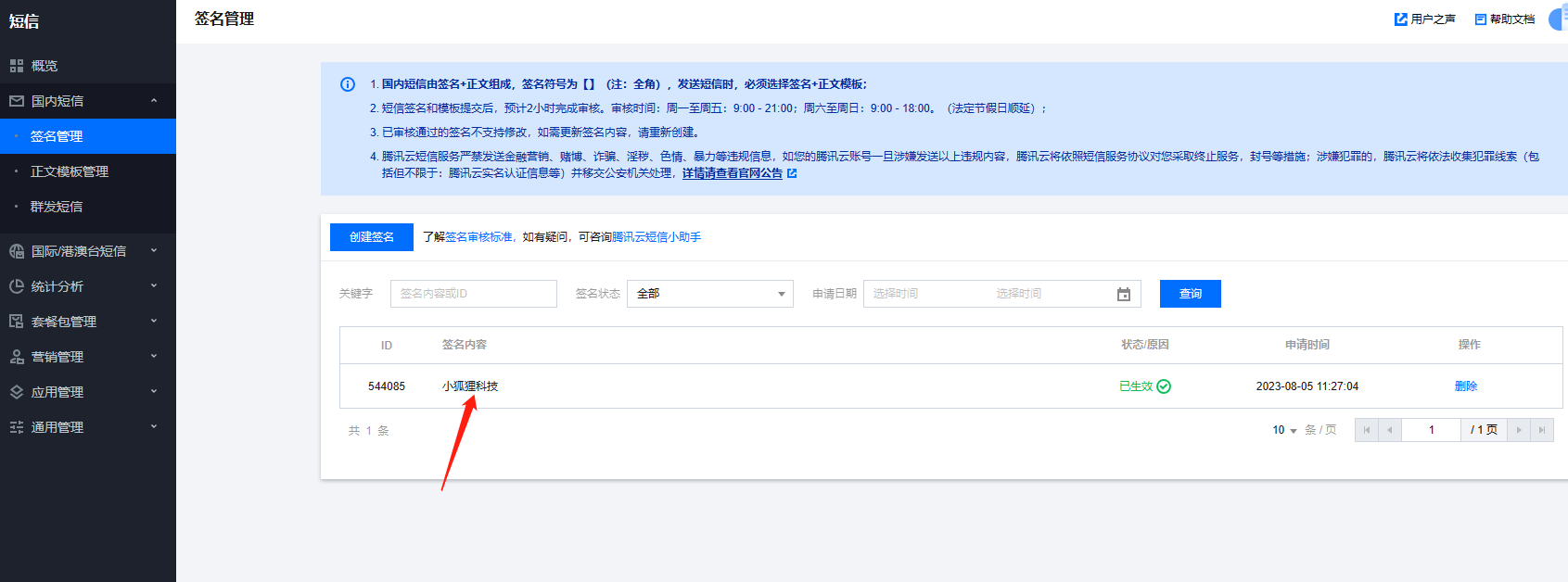
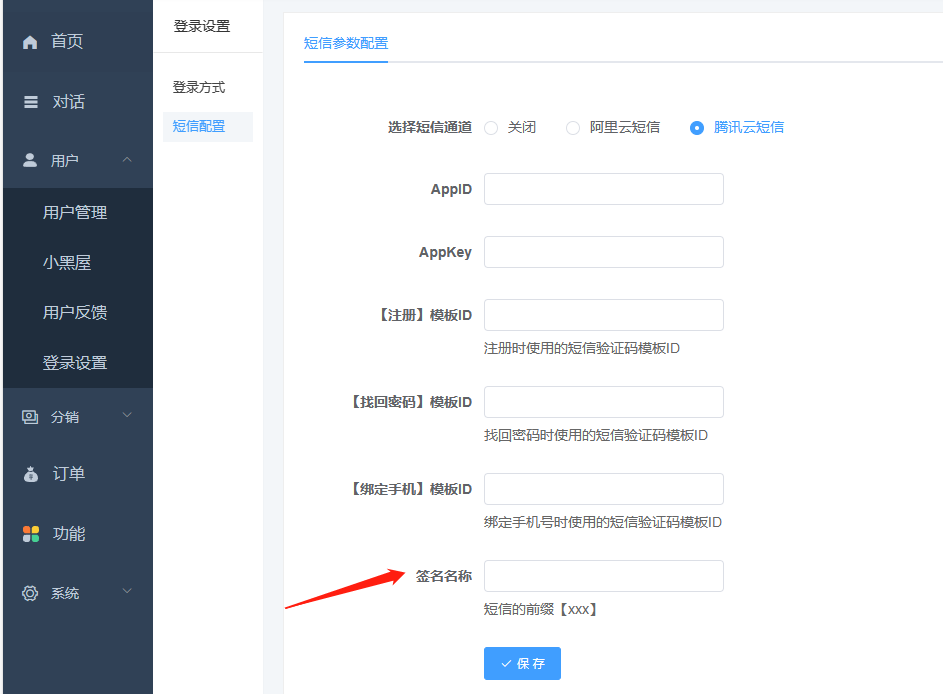
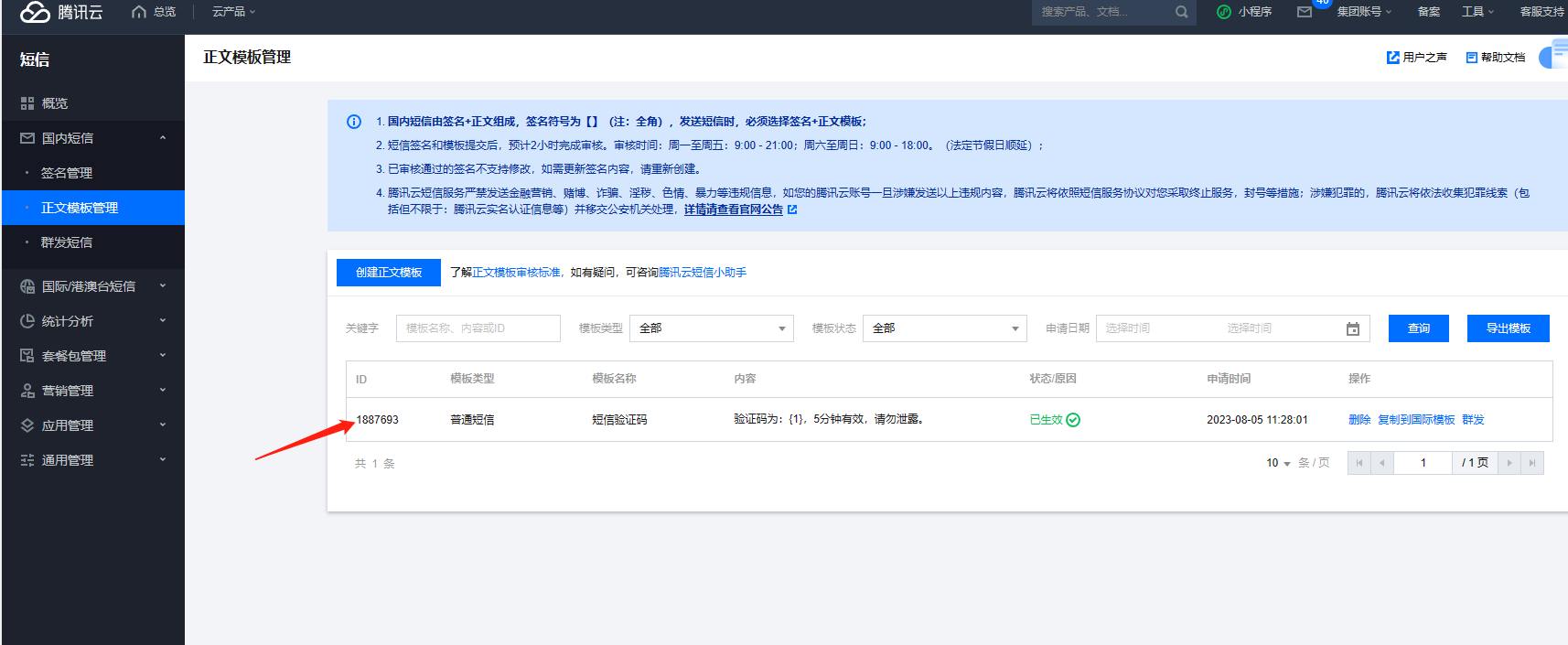
后台填签名名称一定不要加【】这个符号,要跟短信后台的签名完全一致 3、短信模板(位置:国内短信-正文模板管理)没有的话,需要先创建,然后提交审核,通过后才能使用
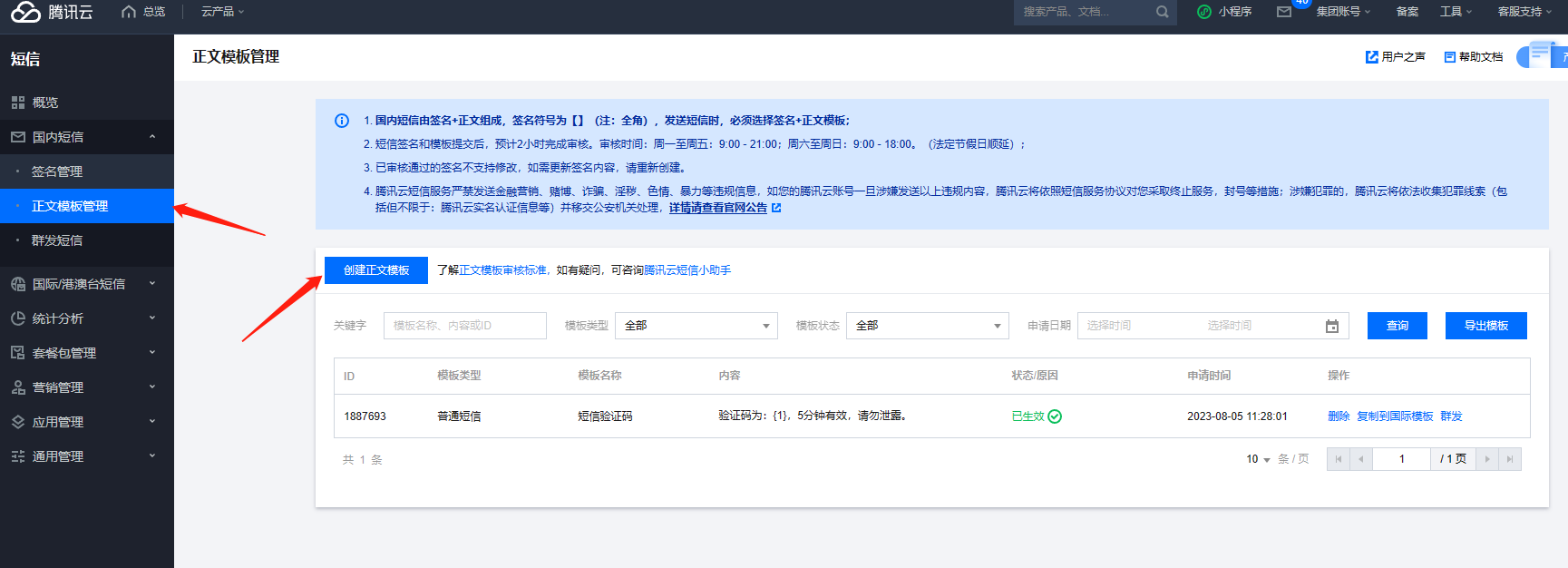
创建模板填写注意: 可以选择使用标准模板,注意模板内容里的变量只写一个验证码变量,不需要其他变量
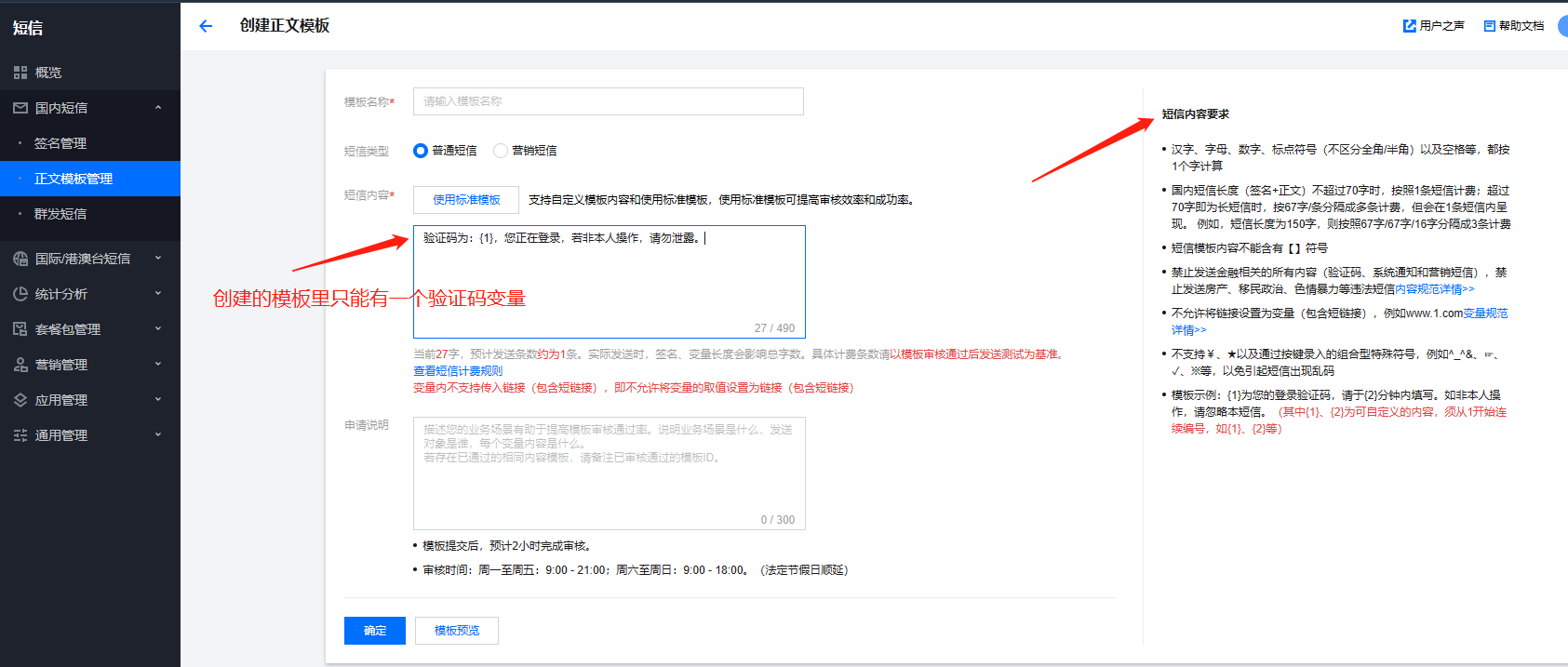
审核通过后,把模板id填到站点后台短信参数-模板ID
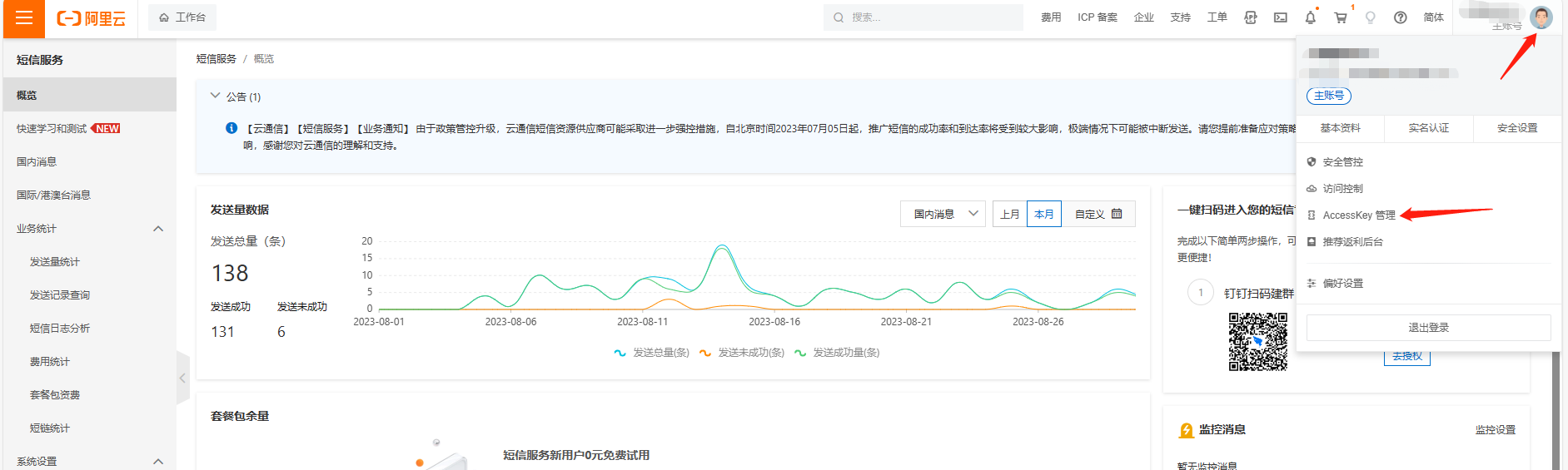
(二、)阿里云短信配置
1、阿里云短信的AccessKey ID和AccessKey Secret,在的AccessKey管理里查看
2、短信签名(位置:国内消息-签名管理)没有的话,需要先添加,然后提交审核,通过后才能使用
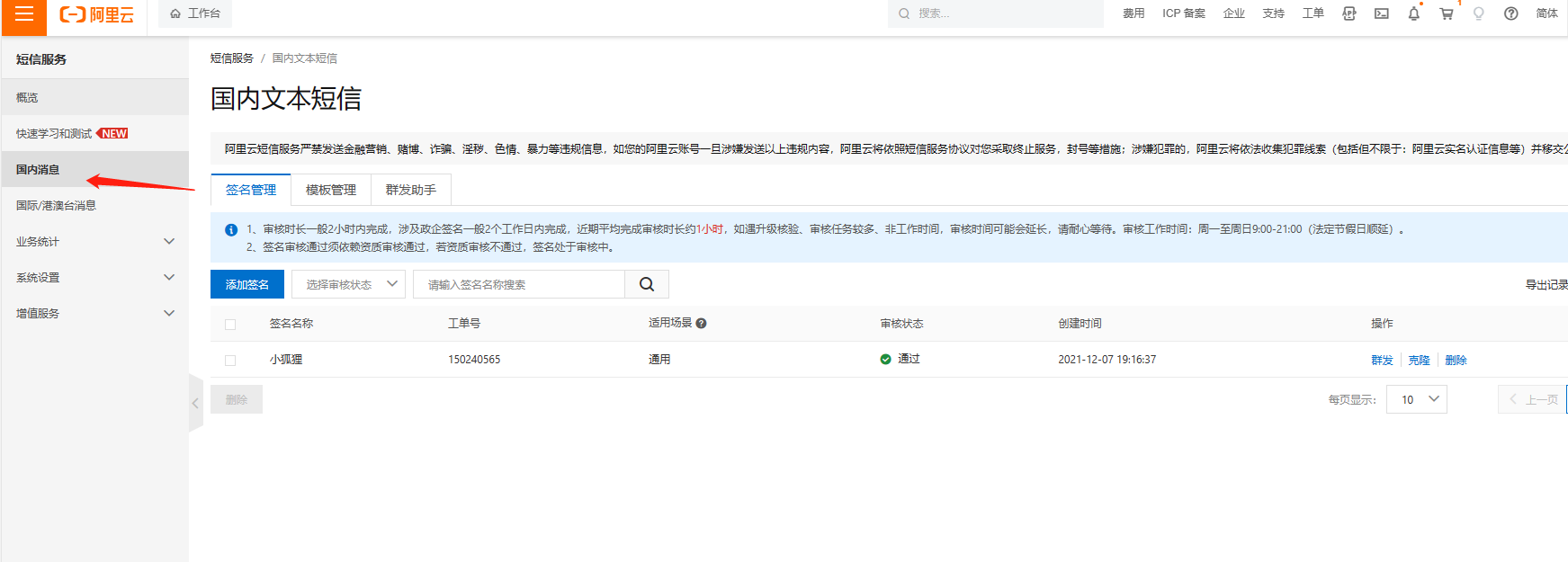
创建签名填写注意:
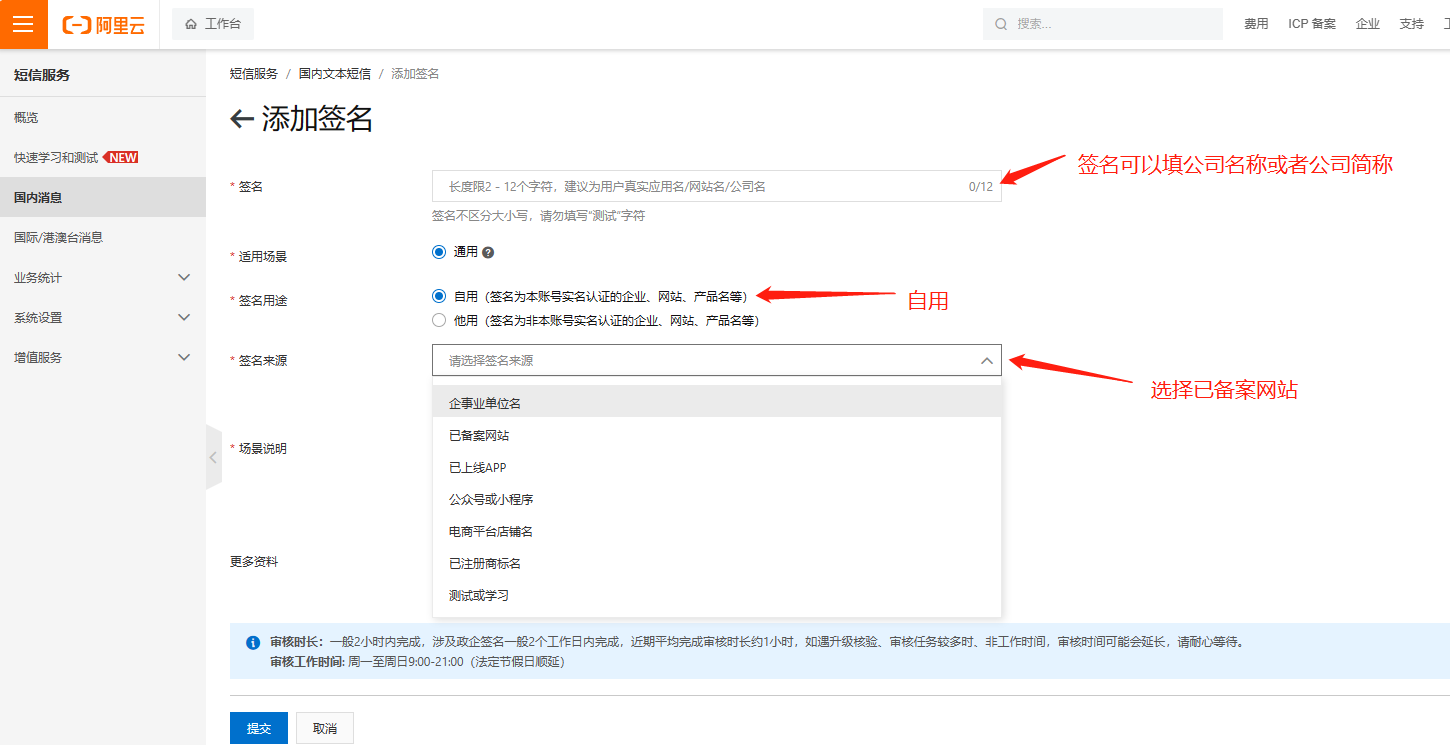
其他按照提示的创建要求填即可。 审核通过后,把签名内容填到站点后台短信参数的签名名称
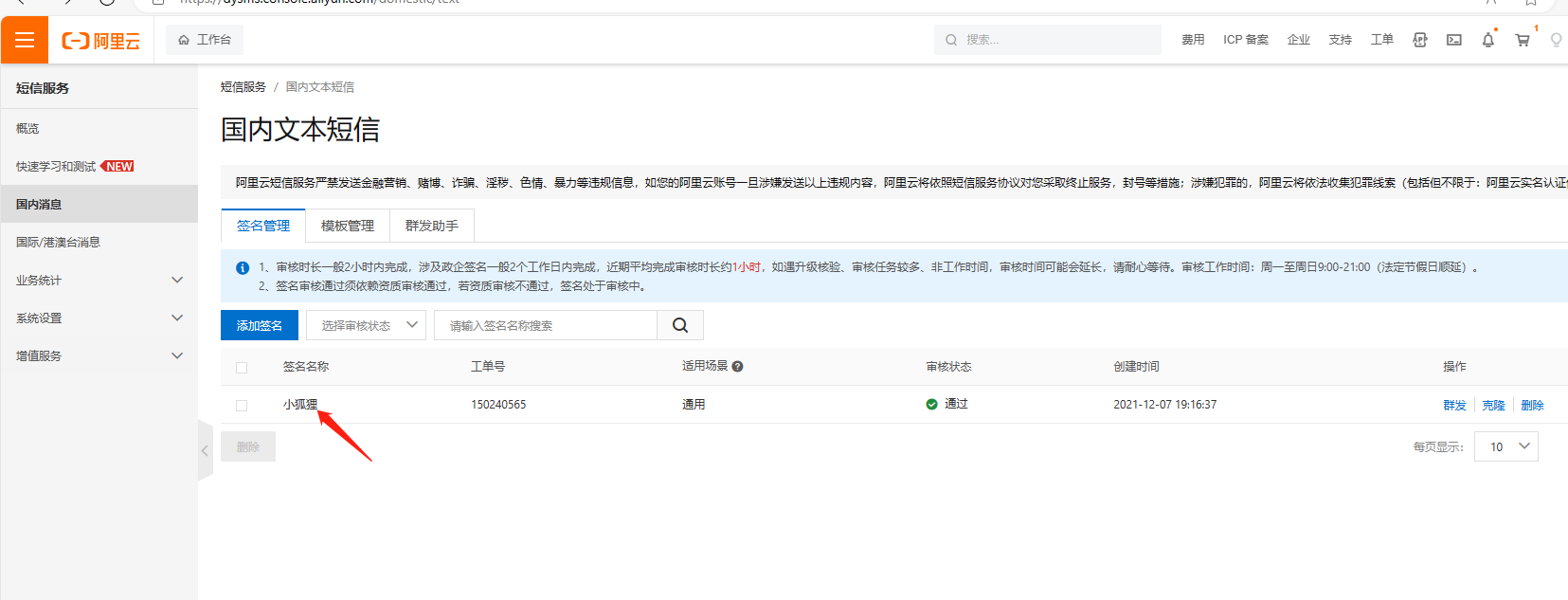
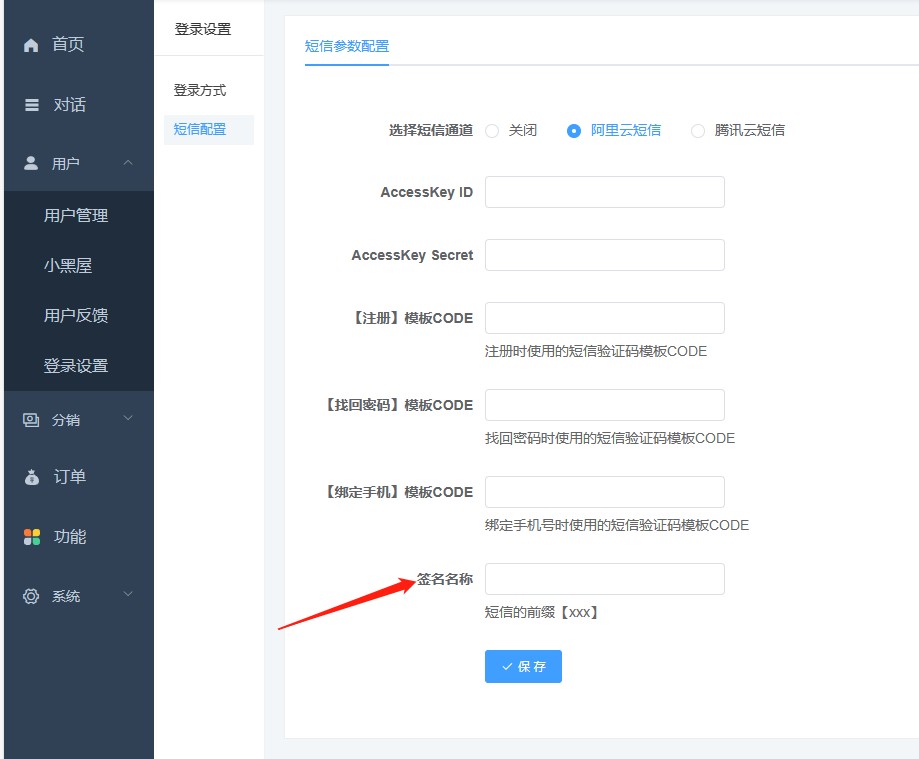
后台填签名名称一定不要加【】这个符号,要跟短信后台短信模板的关联签名完全一致。 3、短信模板(位置:国内消息-模板管理)没有的话,需要先添加,然后提交审核,通过后才能使用
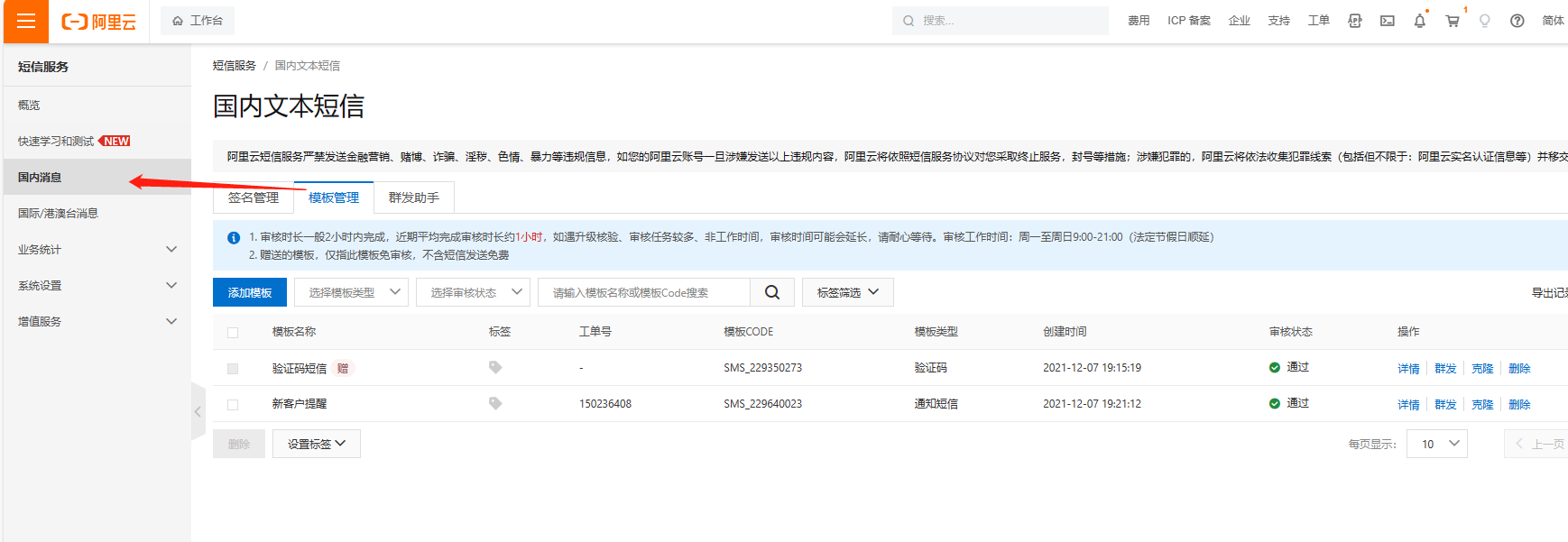
创建模板填写注意: 1、关联审核通过的签名 2、模板内容里的变量只写一个验证码变量,不需要其他变量
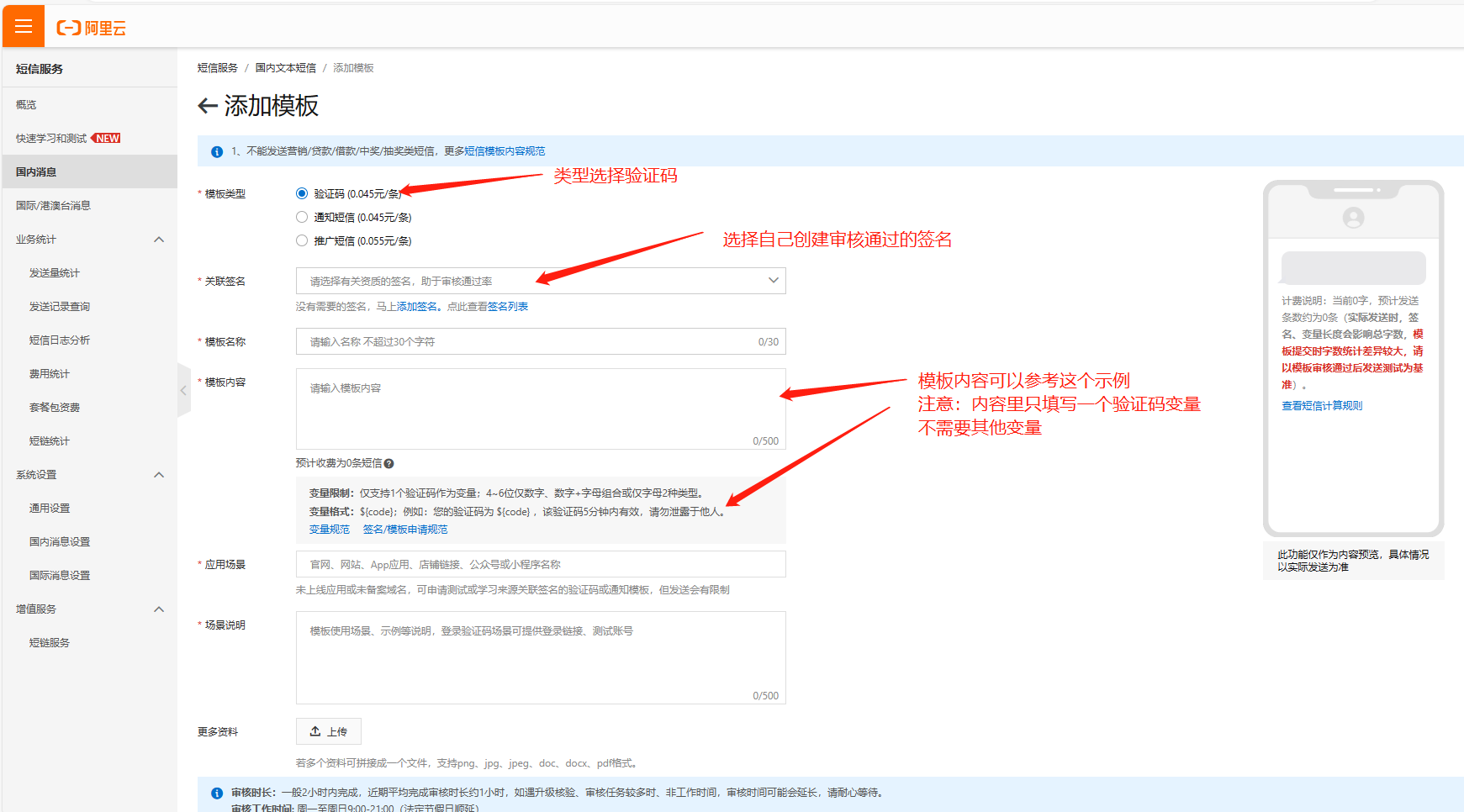
审核通过后,把模板CODE填到站点后台短信参数-模板CODE
公众号菜单配置教程
公众号启用了服务器配置以后,我们发现自定义菜单不能用了,应该如何启用呢?
见下图

将菜单“启用”就可以了
按照以上步骤我们发现公众号里的菜单已经出来了,
那么如何更换菜单内容呢?
1、先停用“服务器配置”
2、修改自定义菜单
3、启用“服务器配置”
4、再按前面步骤将自定义菜单开关开启
注意:停用“服务器配置”期间,影响PC端客户登录,尽量请选择人少的时候操作。
公众号参数配置教程
准备已认证的服务号
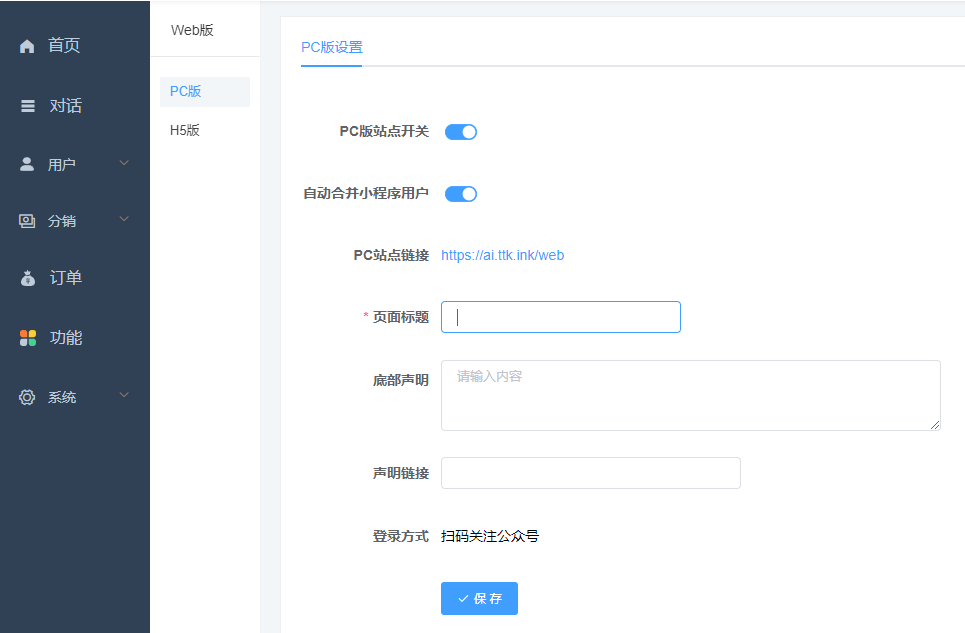
一、pc开关位置功能-web版
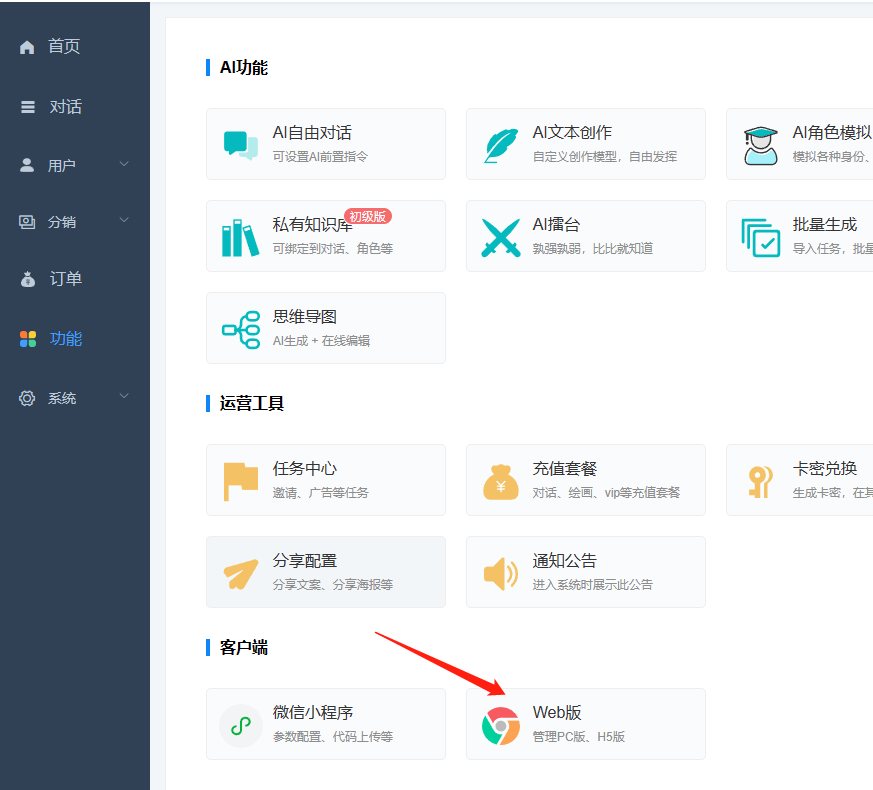
首先打开web站点开关、自动合并小程序用户开关(无小程序的忽略)
pc:
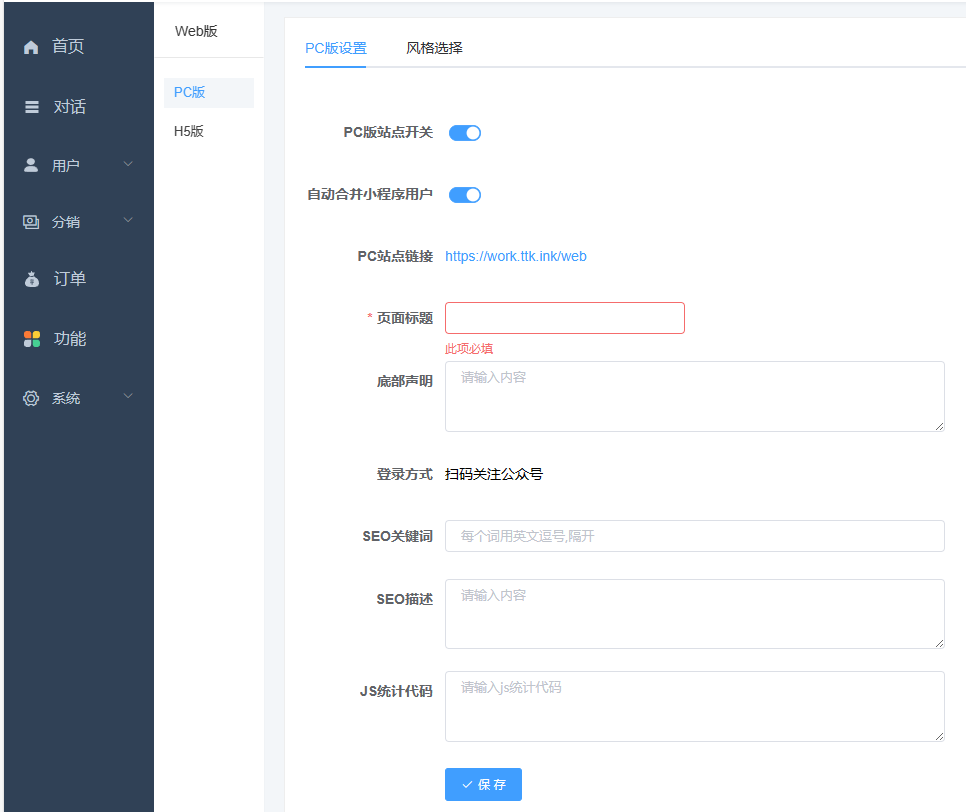
H5:参数必填,h5分享只转发链接形式不行,名片形式才会带参数。
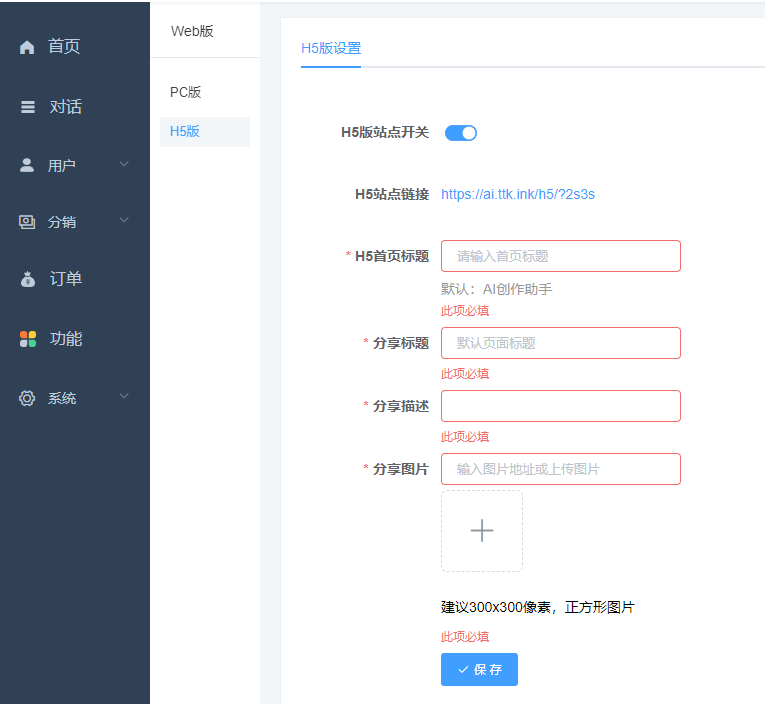
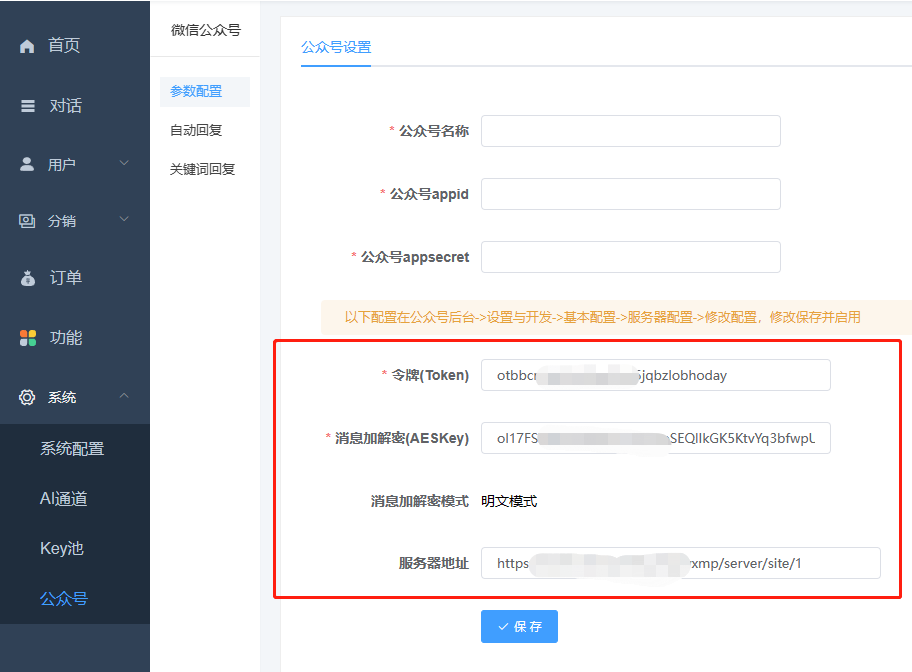
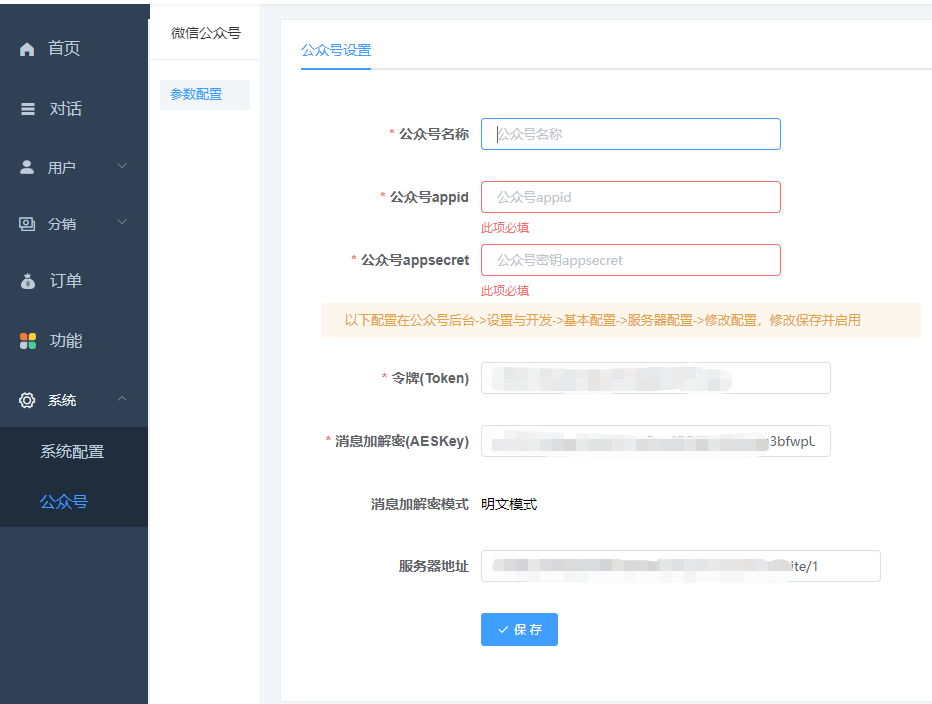
二、填入公众号参数名称、appid、appsecret
别忘了将国内服务器ip加入公众号白名单
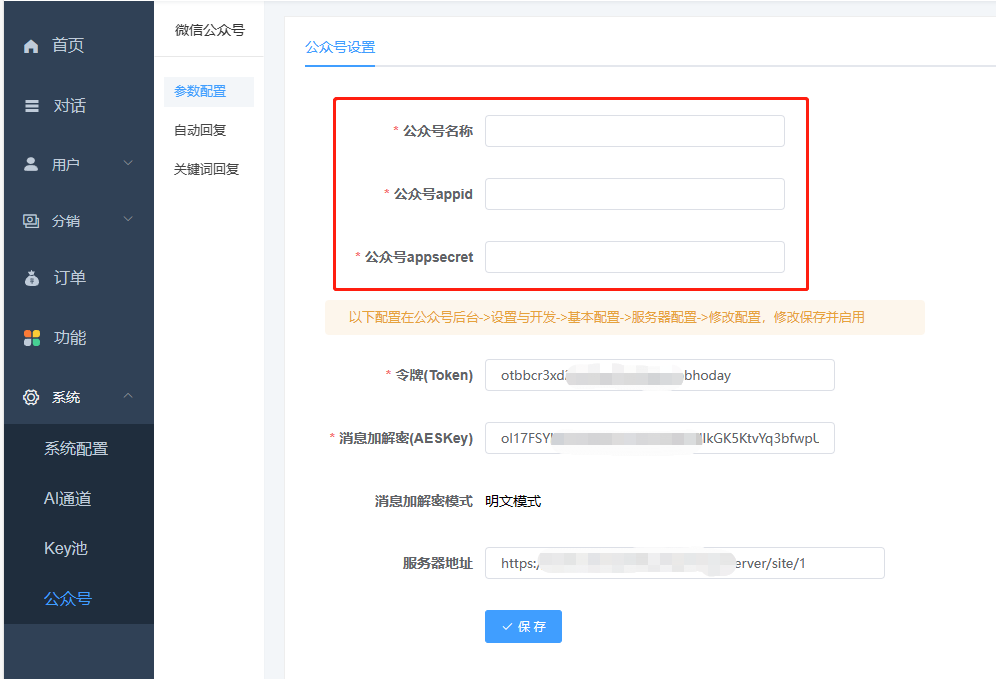
三、启用公众号“服务器配置”
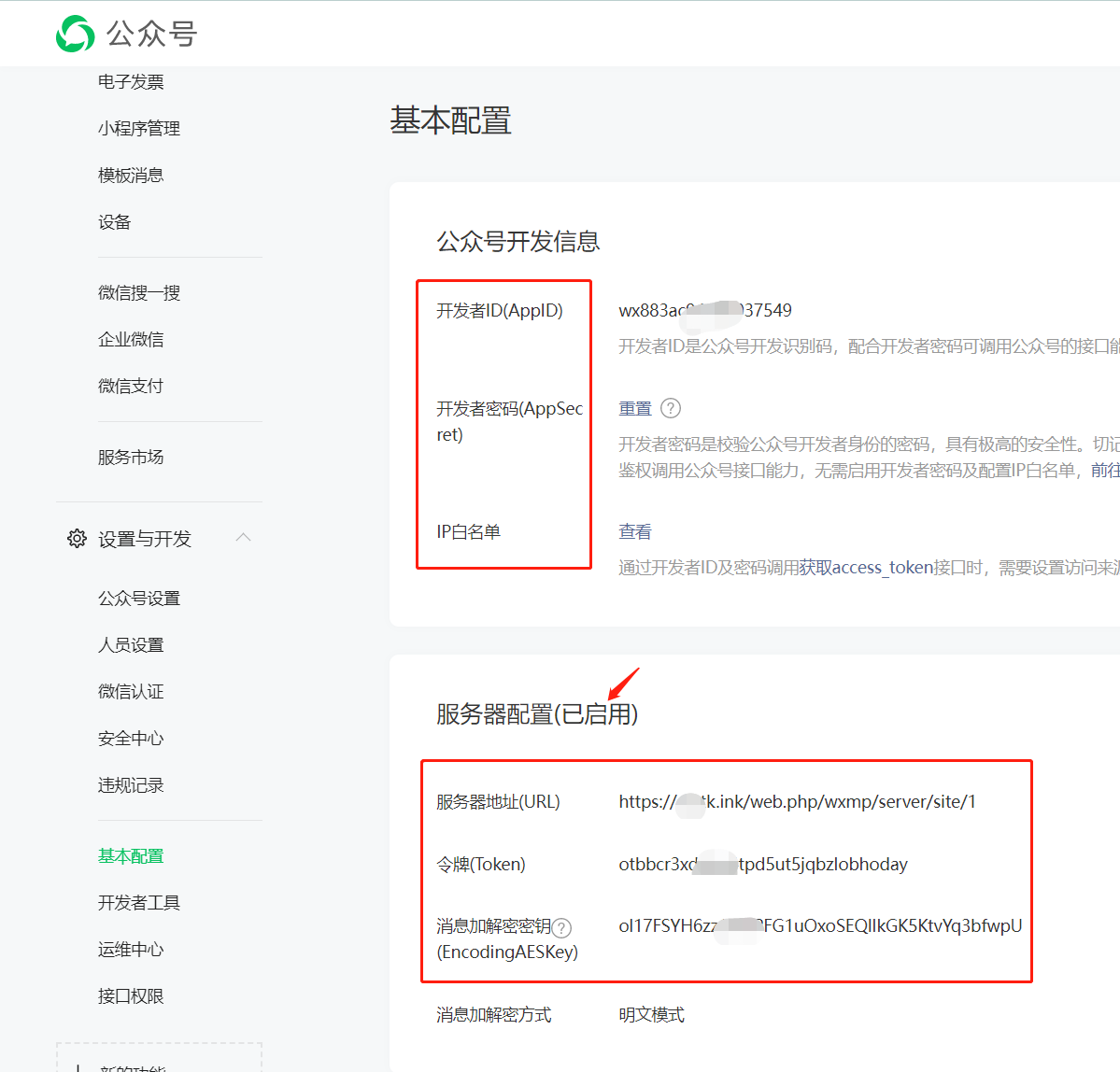
位置:公众号后台->设置与开发->基本配置->服务器配置->修改配置
填入后台生成的token、密钥、服务器地址
配置完成以后,别忘了启用
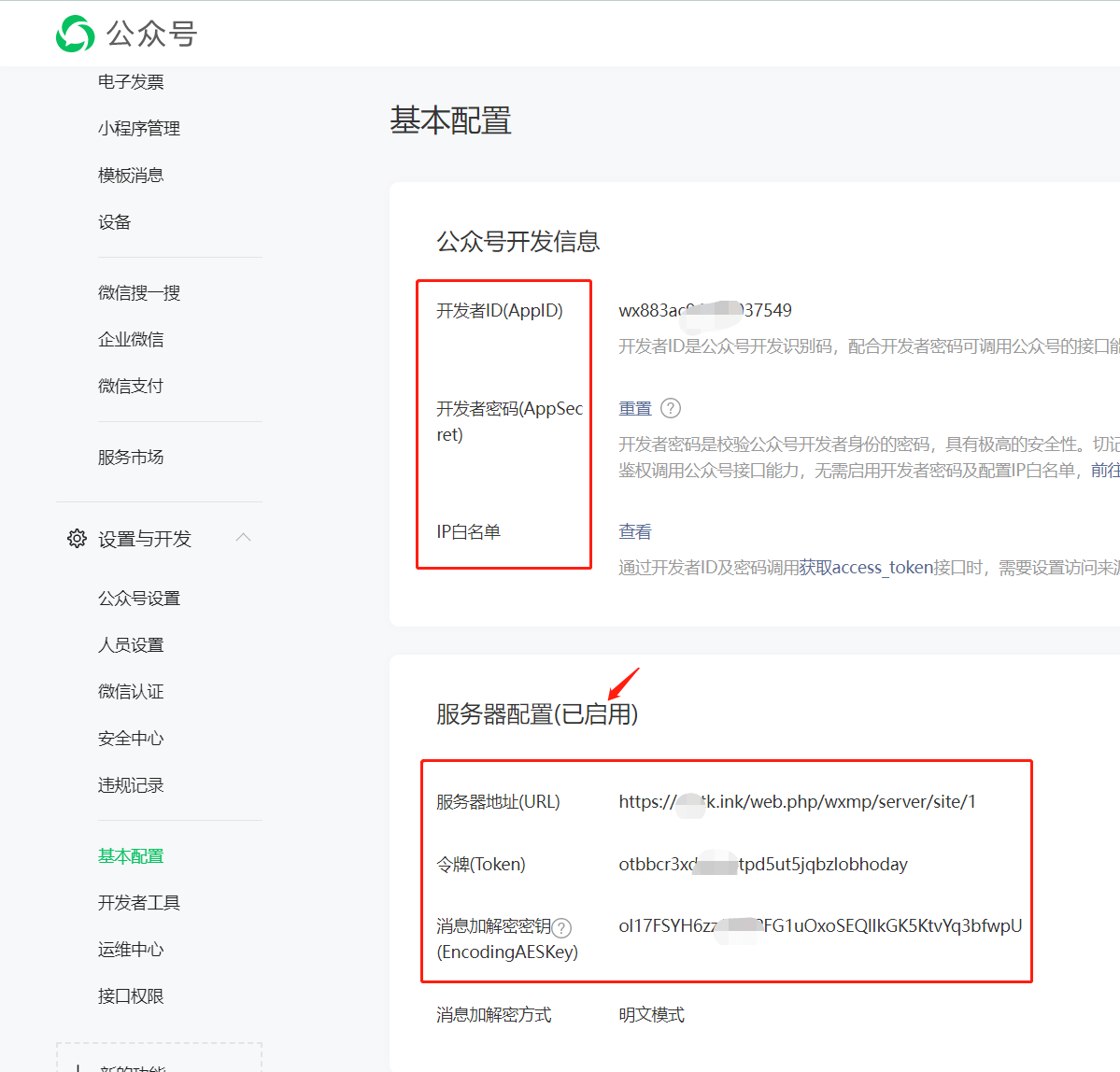
注意:启用“服务器配置”以后,如何启用自定义菜单,见下面教程
四、公众号添加网页授权域名、js安全域名、业务域名
位置在:开发 -> 接口权限 -> 网页授权

注意:验证文件放在站点public目录下,文件名称不要更改

H5分享注意:H5先打开链接,从右上角三个点加入收藏,然后再从收藏里打开,再分享就是卡片了,别人从卡片打开的再分享也是卡片,直接打开url链接分享的不是卡片,所以不要直接发url链接出去。
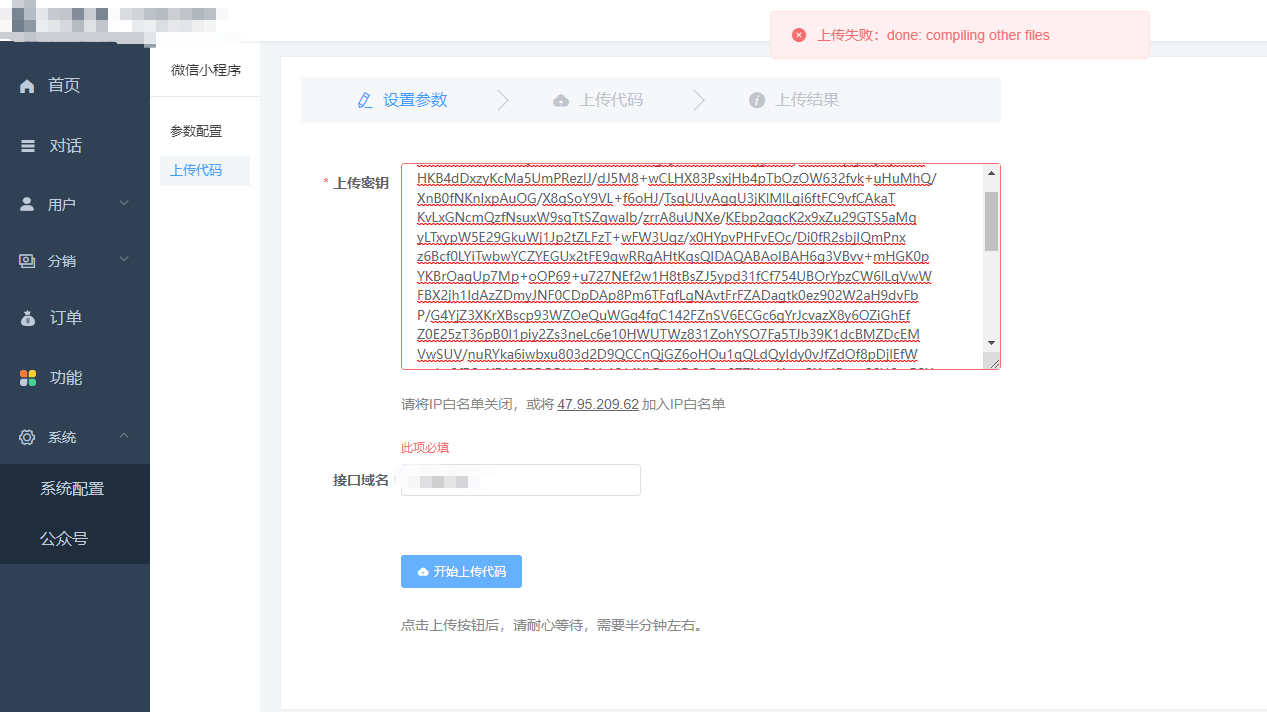
小程序参数配置、上传代码
准备注册好的小程序,并认证
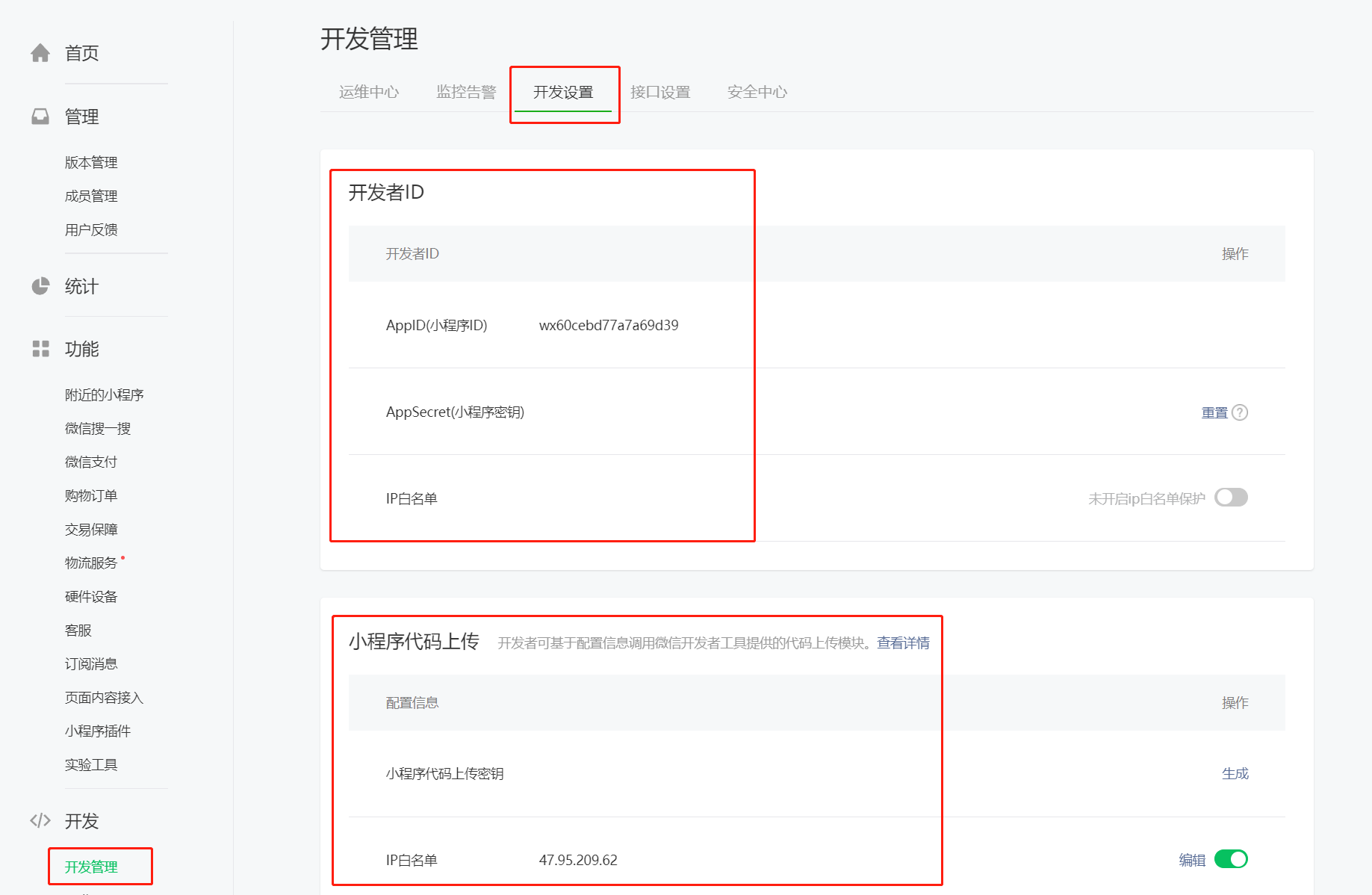
进入小程序后台(链接直达)->开发管理->开发设置
(以下参数的获取和配置均在此页面)
一、获取小程序appid、appsecret
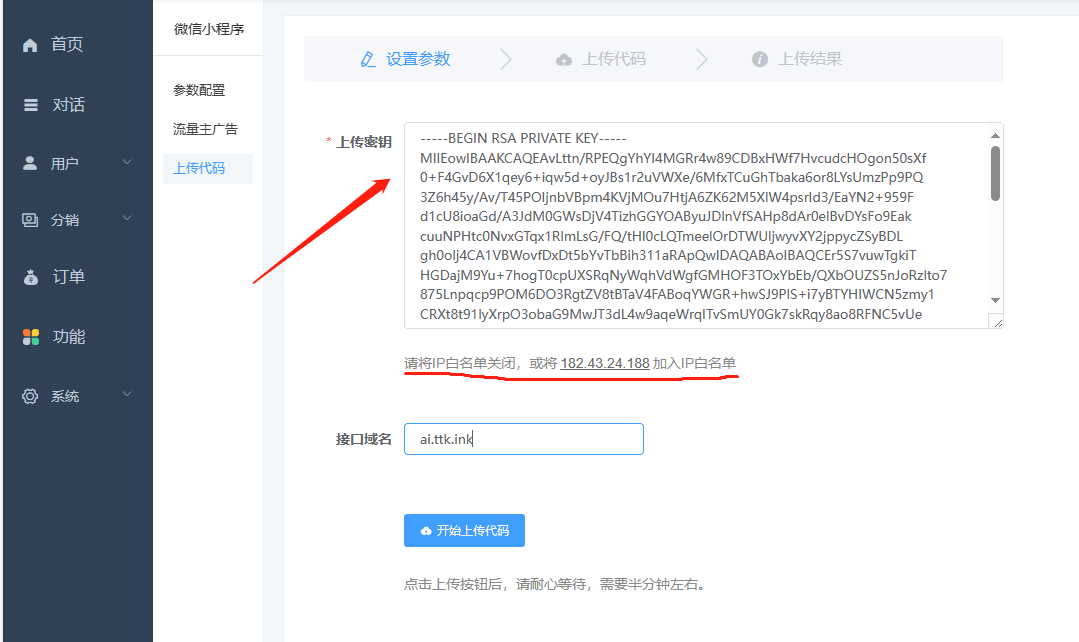
二、代码上传
获取上传密钥、设置上传ip白名单(如开启)
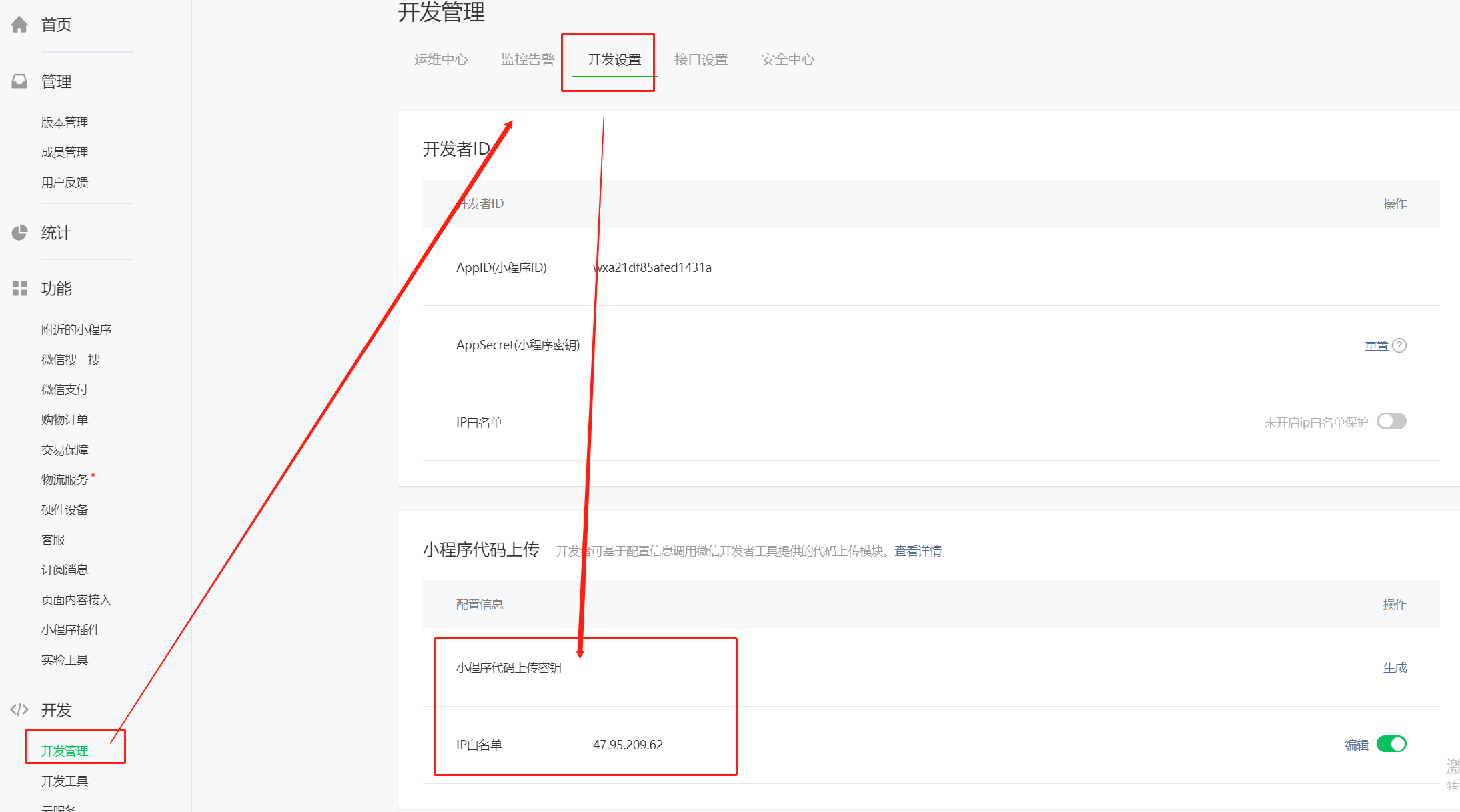
将上传密钥下载下来,完整填入到后台
后台上传位置:
位置:站点后台-功能-微信小程序
然后点击“开始上传代码”按钮
三、设置小程序request域名、uploadFile域名、downloadFile域名、业务域名等,见下图
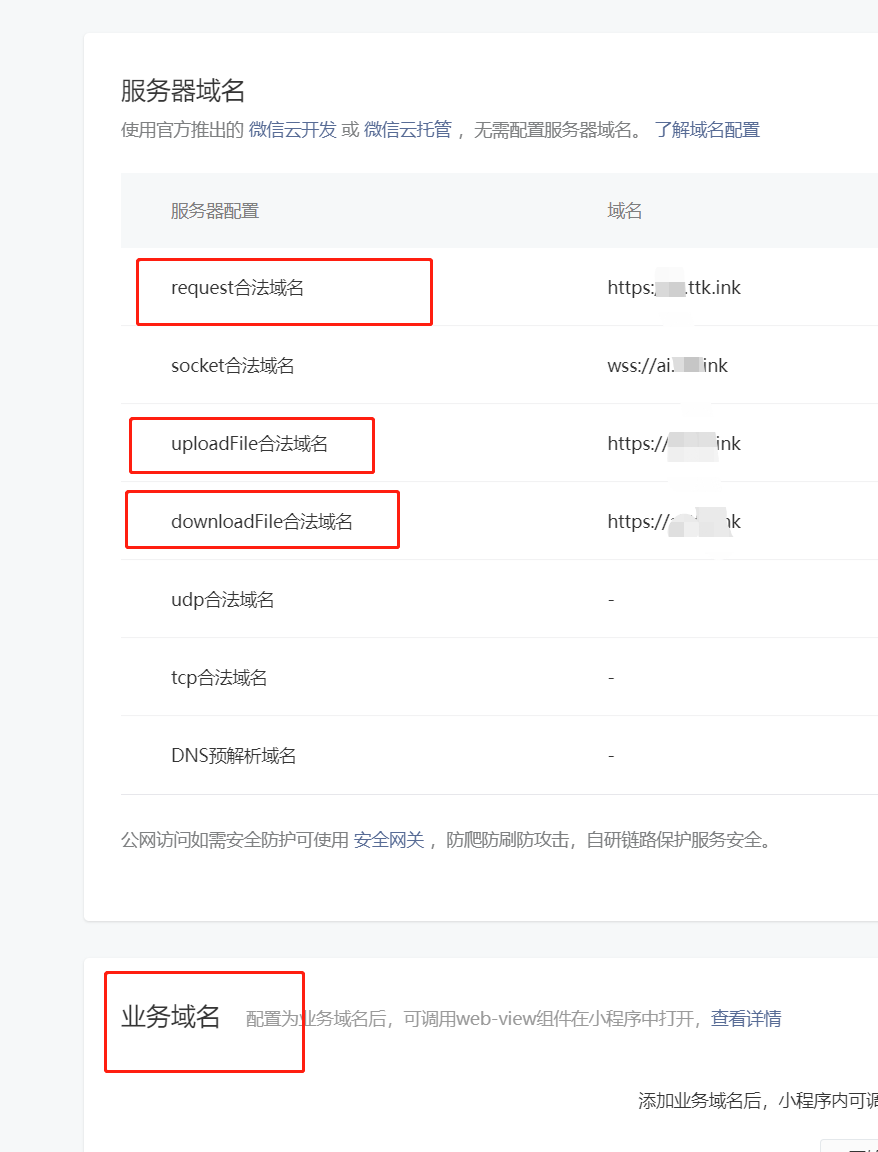
注:验证文件放到站点目录下的public目录下
四、提交小程序审核
注意:首先增加上小程序的"深度合成->ai问答"和"深度合成->ai绘画"两个类目
提交审核注意事项:
1、审核期间,后台打开小程序审核模式开关,审核通过以后再关闭
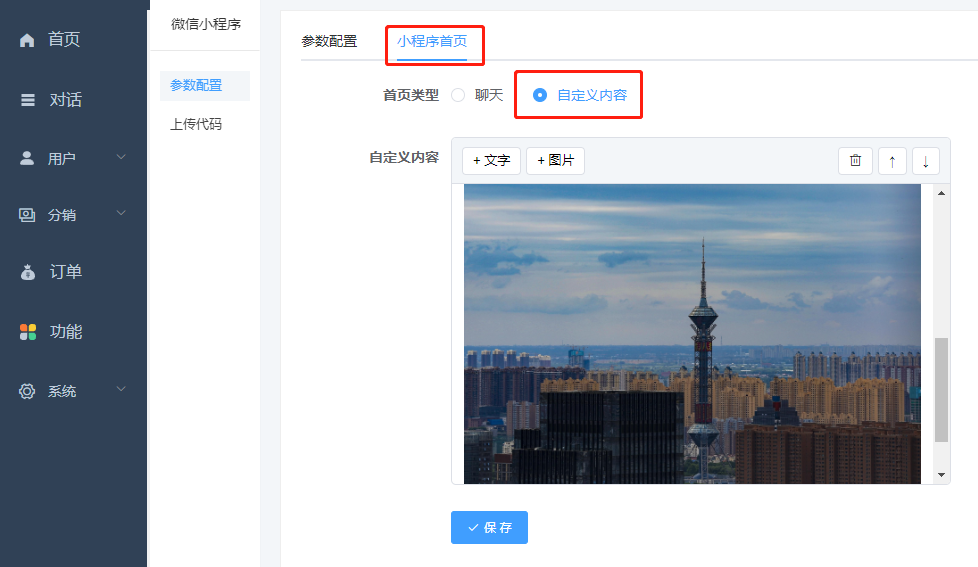
2、自定义一下小程序首页内容,如果小程序首页显示聊天窗,容易拒审,建议填入公司介绍或业务介绍,图文结合看起来丰富一点。
3、小程序需要增加ai类目,添加ai类目需要做算法备案,或者借用已经通过算法备案的合作协议。
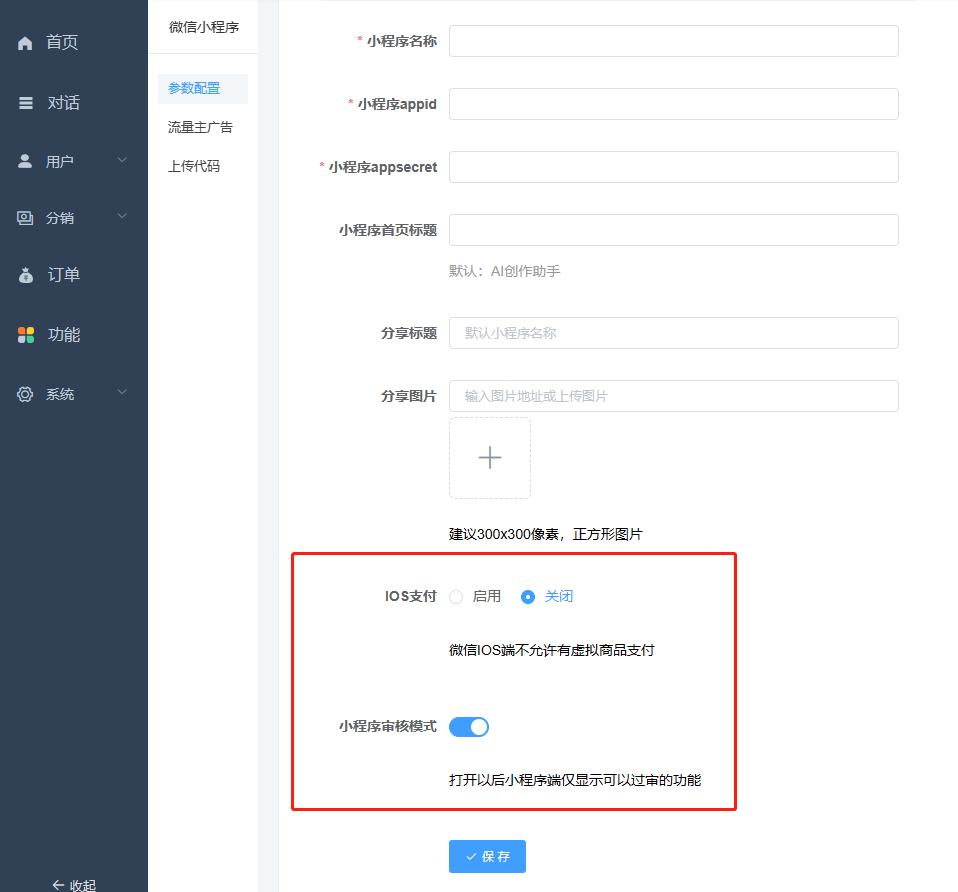
最后,在小程序后台提交审核即可
附:隐私协议设置参考
用户信息(微信头像昵称):补充会员资料
手机号:注册会员账号
相册(仅写入)权限:保存分享二维码
选中的照片或视频:设置会员头像
剪切板:一键复制内容
麦克风:AI语音对话
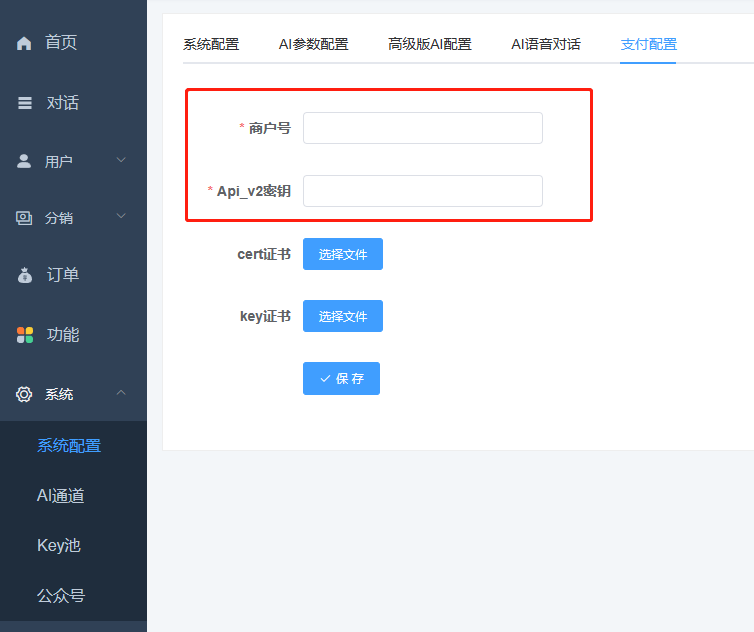
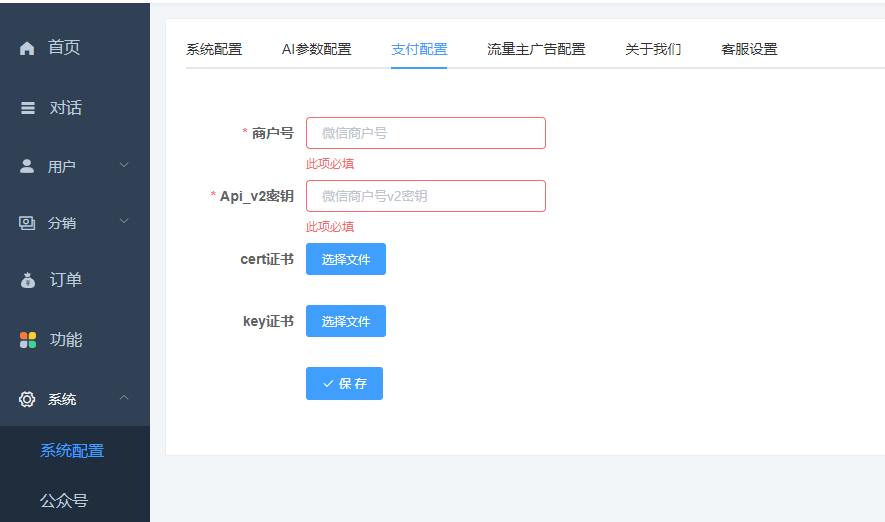
如何配置微信支付?
在站点后台->系统配置->支付配置,填入微信商户号、密钥_v2(证书可暂不上传,仅退款功能才用到证书)
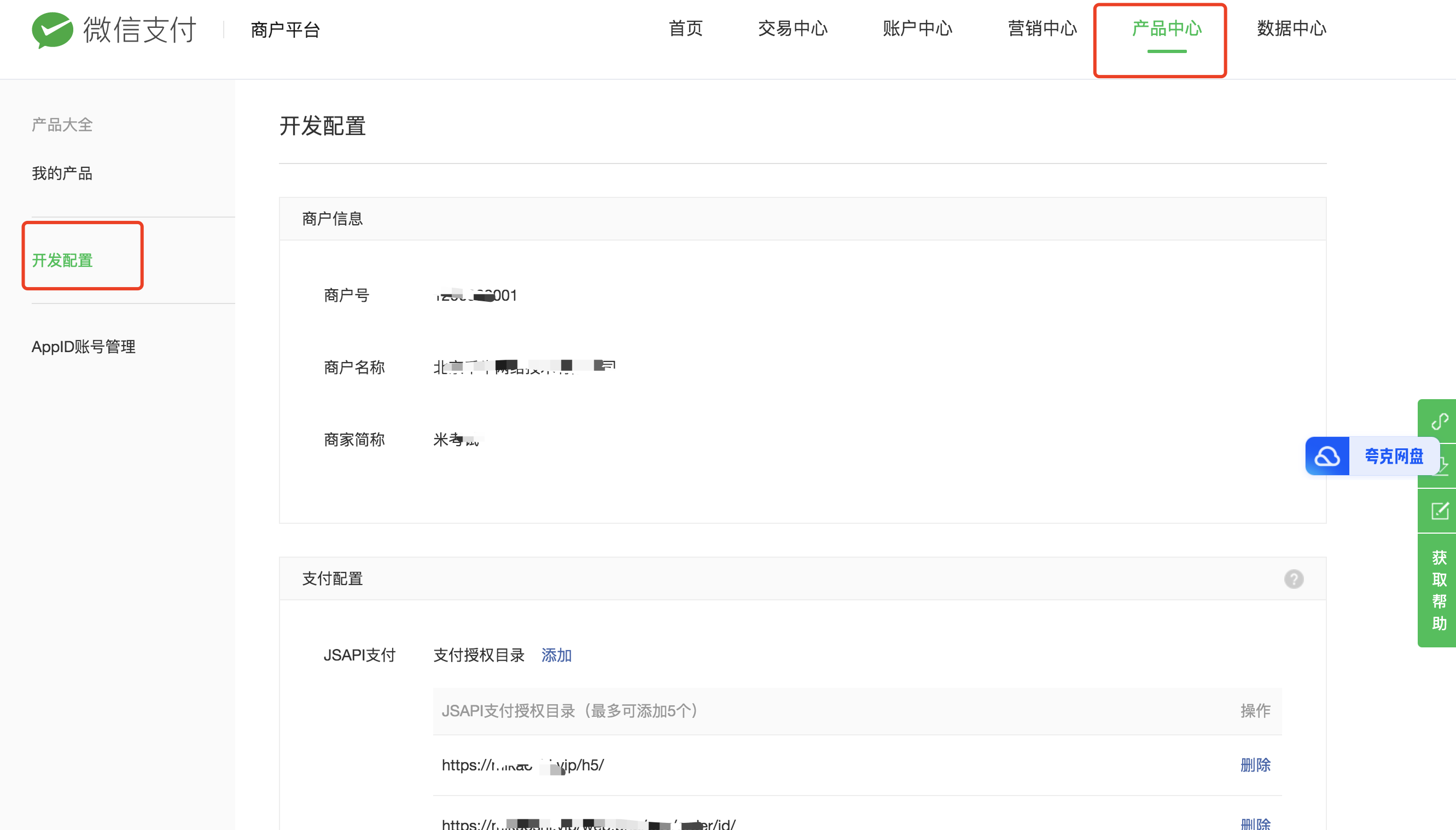
配置一下微信商户号的支付目录
位置在:微信商户号后台(链接)->产品中心->开发设置->jsapi支付目录
添加1个支付目录:
https://域名/
商户号开通一下native支付
路径:在商户平台>产品中心,找native支付,点击开通
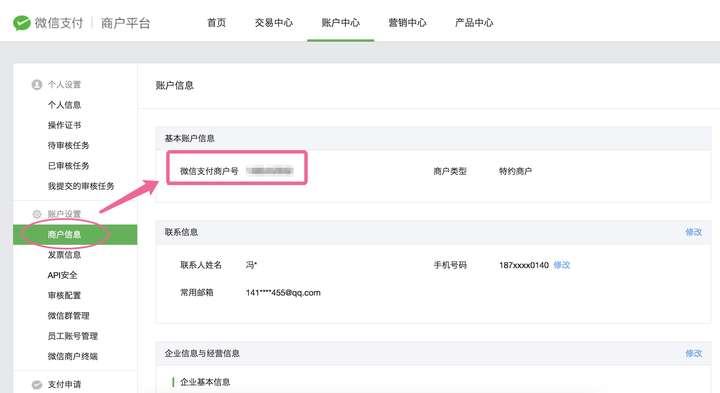
附:如何获取商户号和key ?
1、查看商户号
登录微信支付商户后台(微信商户平台) -> 账户中心 -> 账户设置 -> 商户信息 -> 微信支付商户号
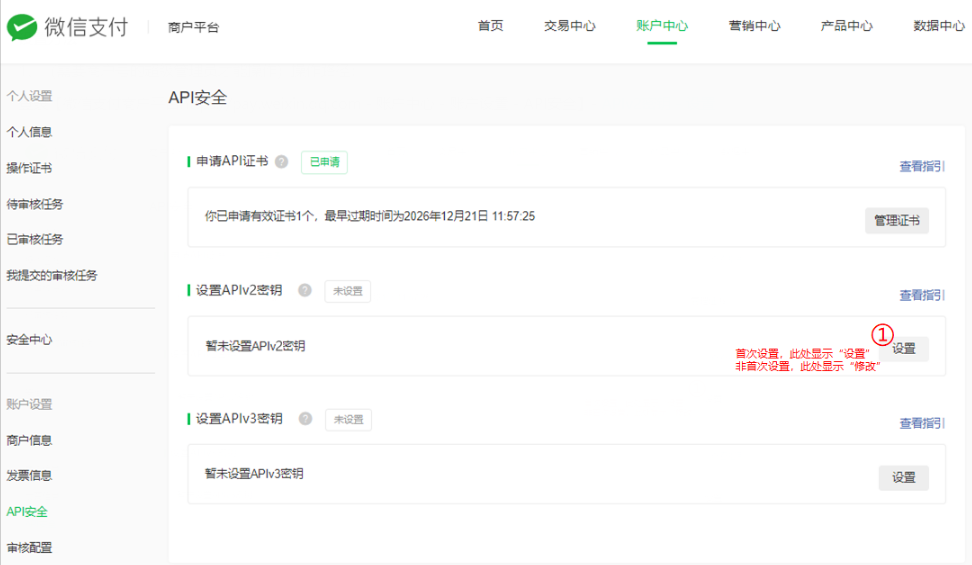
2、获取api_v2密钥
微信支付商户平台 -> 账户中心 -> 账户设置 -> API安全-> APIv2密钥
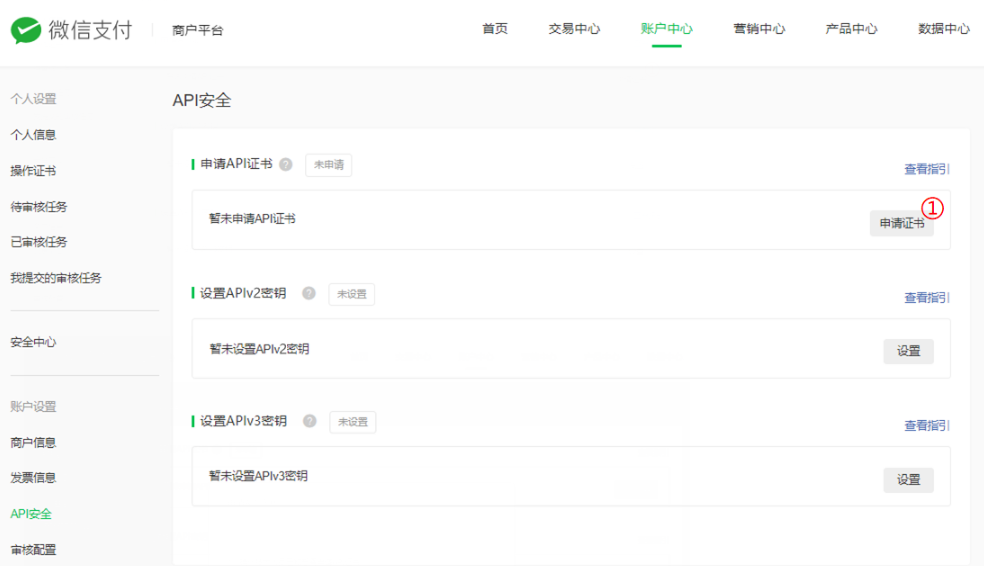
3、获取cert、key证书
微信支付商户平台 -> 账户中心 -> 账户设置 -> API安全 -> 申请API证书,按照提示生成证书即可
商户号绑定小程序和公众号appid
位置:产品中心->AppID账号管理->我关联的AppID账号->+关联AppID
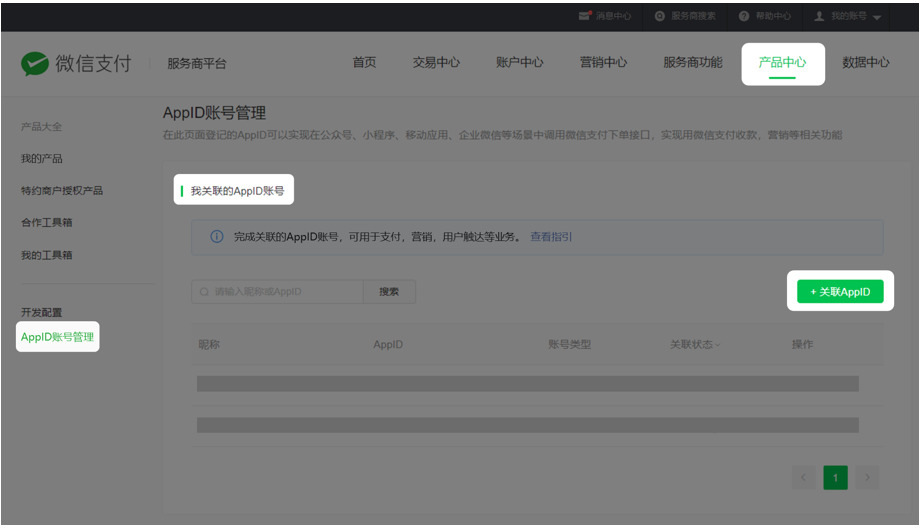
需要在进入公众号和小程序后台去确认。
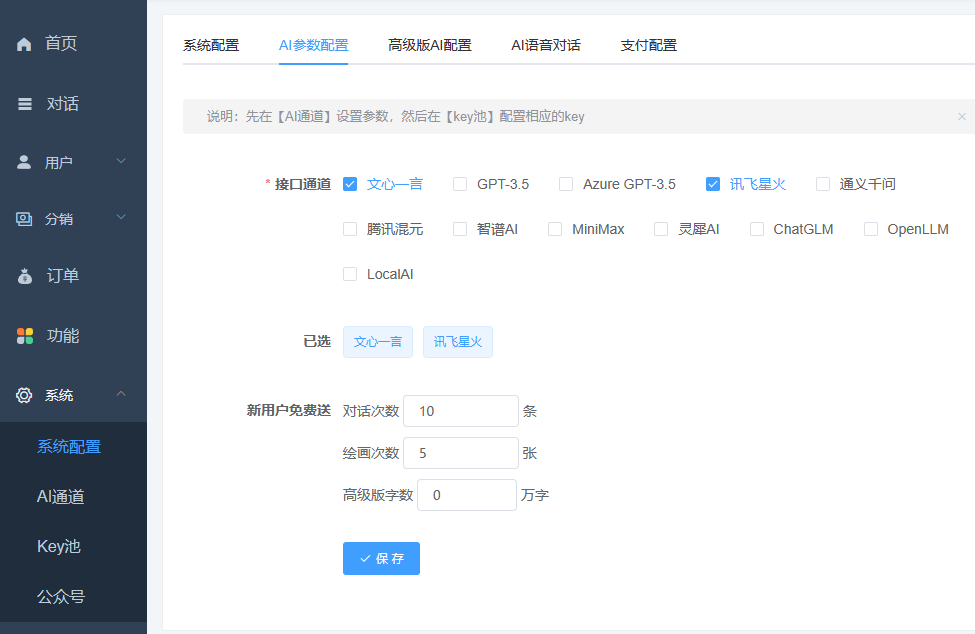
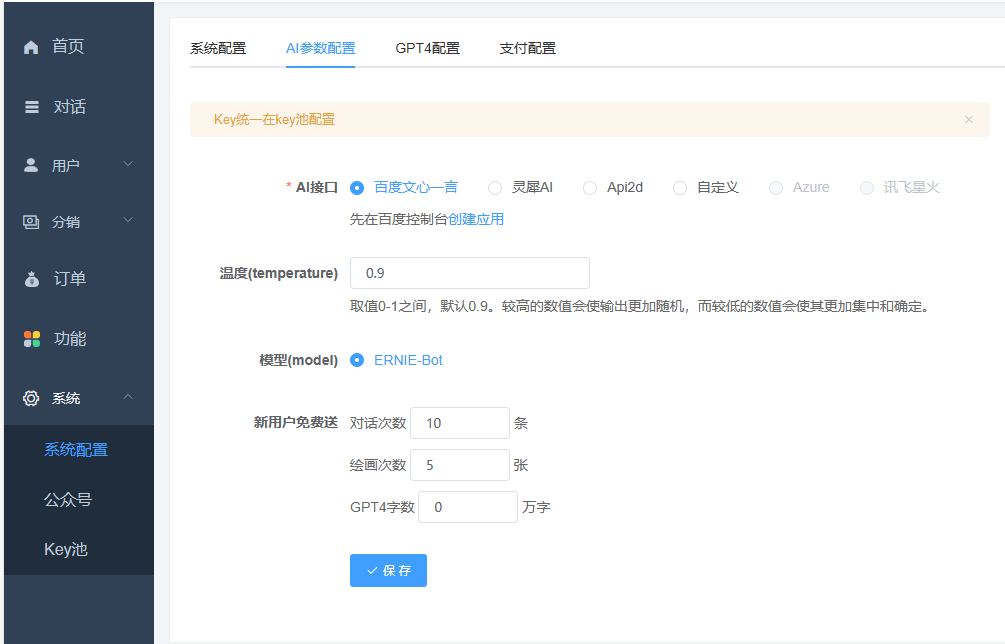
如何配置AI参数?
1、选择AI接口
接口选择:多个ai接口选择
百度文心一言:国内百度接口
灵犀接口:国内的AI接口
api2d接口:是一家提供openai接口的第三方平台(账号注册地址),无需自备GPT账号,无需反向代理,建议每次充值不要太多,不知道会不会关停跑路
自定义接口:如果使用openai接口的话,需自备GPT账号,需使用反向代理,请根据您当地的法规酌情选用。
2、最大回复长度(max_tokens)
GPT3.5接口最大长度是4096(问题+回复总长度),考虑到前置指令、创作模型、关联上下文等,建议设置不超过2000
3、模型:选择gpt-3.5-turbo
4、设置新用户免费送几条
5、其他保持默认即可。
绘画参数配置及使用
路径:站点后台-功能-AI绘画
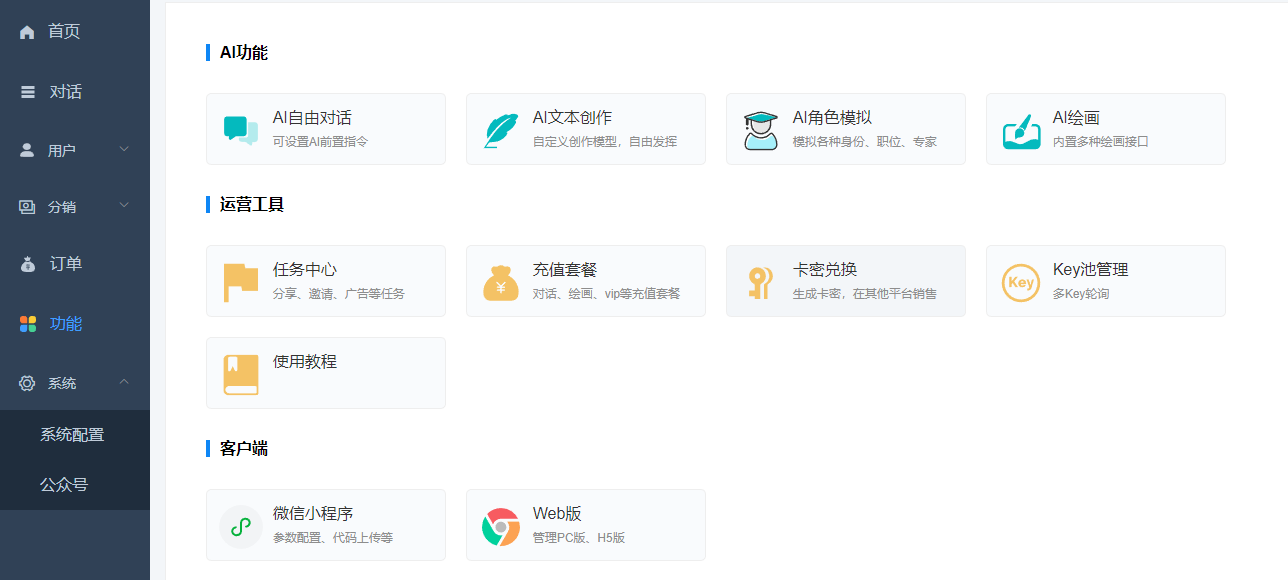
进入参数配置
接口选择:多种接口自主选择(需自己准备key),对应接口的key对话和绘画通用
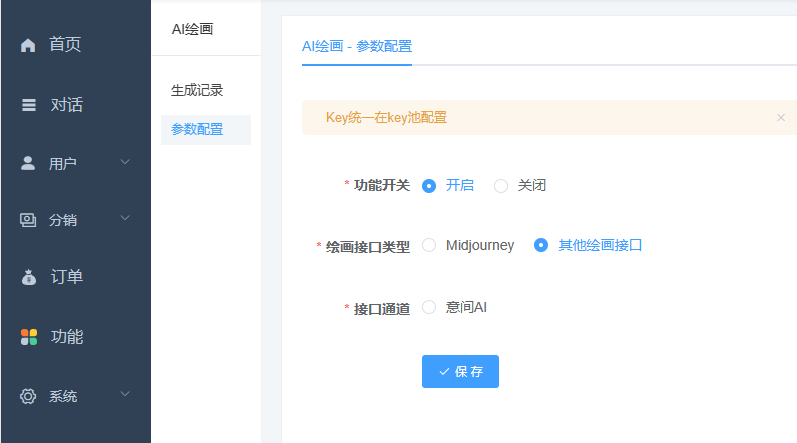
存储空间:
位置在超管后台-存储空间
自主选择存储(需自己准备),未配置存储空间(或配置错误)默认保存本地服务器。
使用:前端进入绘画模块,输入指令即可。
系统安装教程
需要准备的资料?
一、需要准备什么资料?
1、国内服务器、域名(已备案)、小程序(认证)、微信商户号、微信公众号(已认证的服务号)
如果使用国外openai接口,还需要准备以下资料:
2、海外服务器(做反向代理接口转发,按量或者按月付费都可以)
3、GPT账号(自备或者买一个)
国内服务器配置建议:
系统: Linux CentOS 7.9
cpu:2核及以上
内存:2G及以上
硬盘:20G及以上
带宽:5M及以上
海外服务器配置(建议购买阿里云海外服务器):
阿里云买美国服务器,买个2核1G的按月,带宽按量付费或者按月付费。5M及以上(不要一次买太长.
第一步:将主程序安装在国内服务器
运行环境要求:Nginx + PHP7.3或7.4 + MySQL5.6或5.7
1、解析一个域名到服务器ip(需已ICP备案)
2、服务器的宝塔面板里新建站点,mysql编码选utf8mb4,php版本7.3或7.4
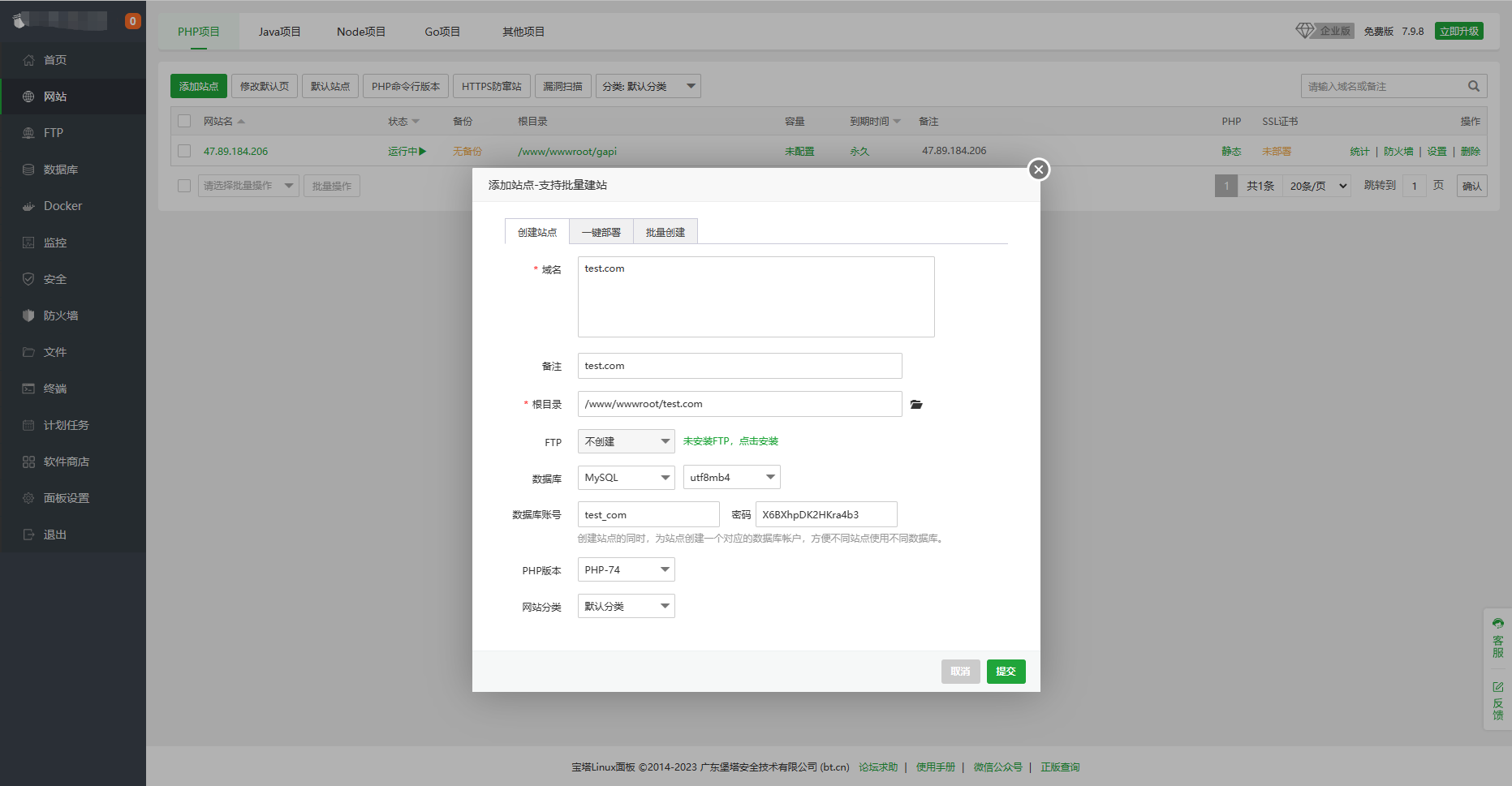
3、将源码包里的“server”文件夹内的文件上传到站点根目录
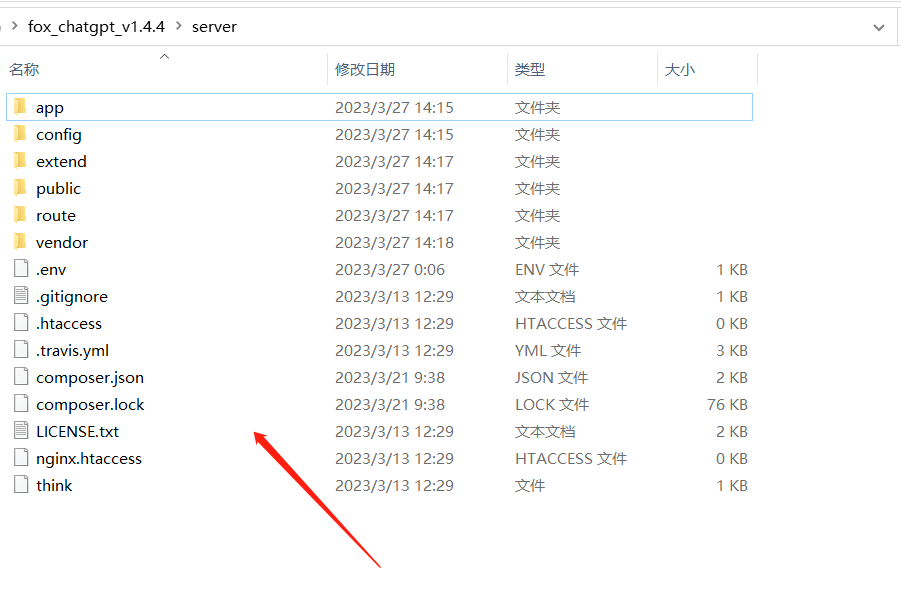
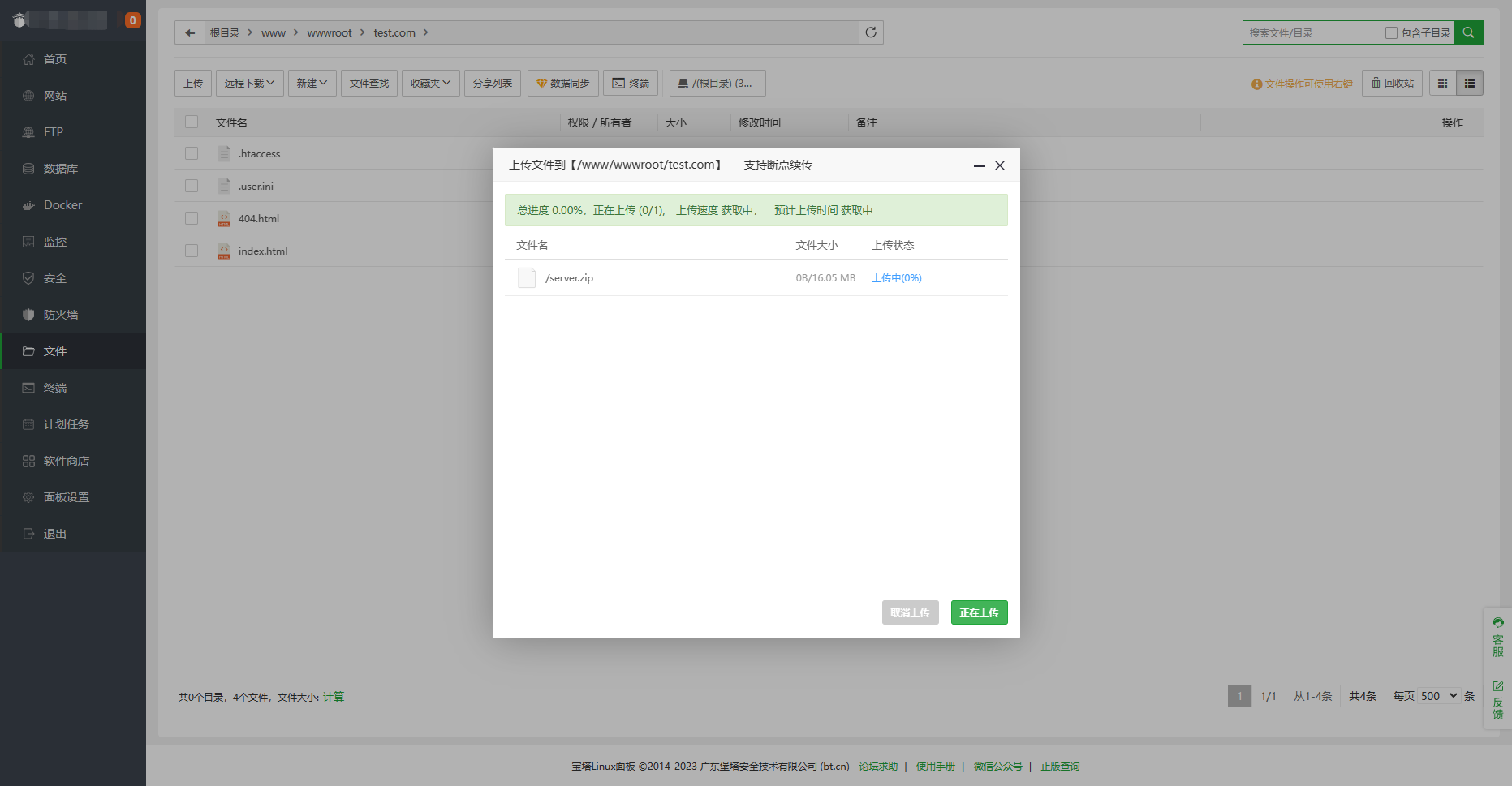
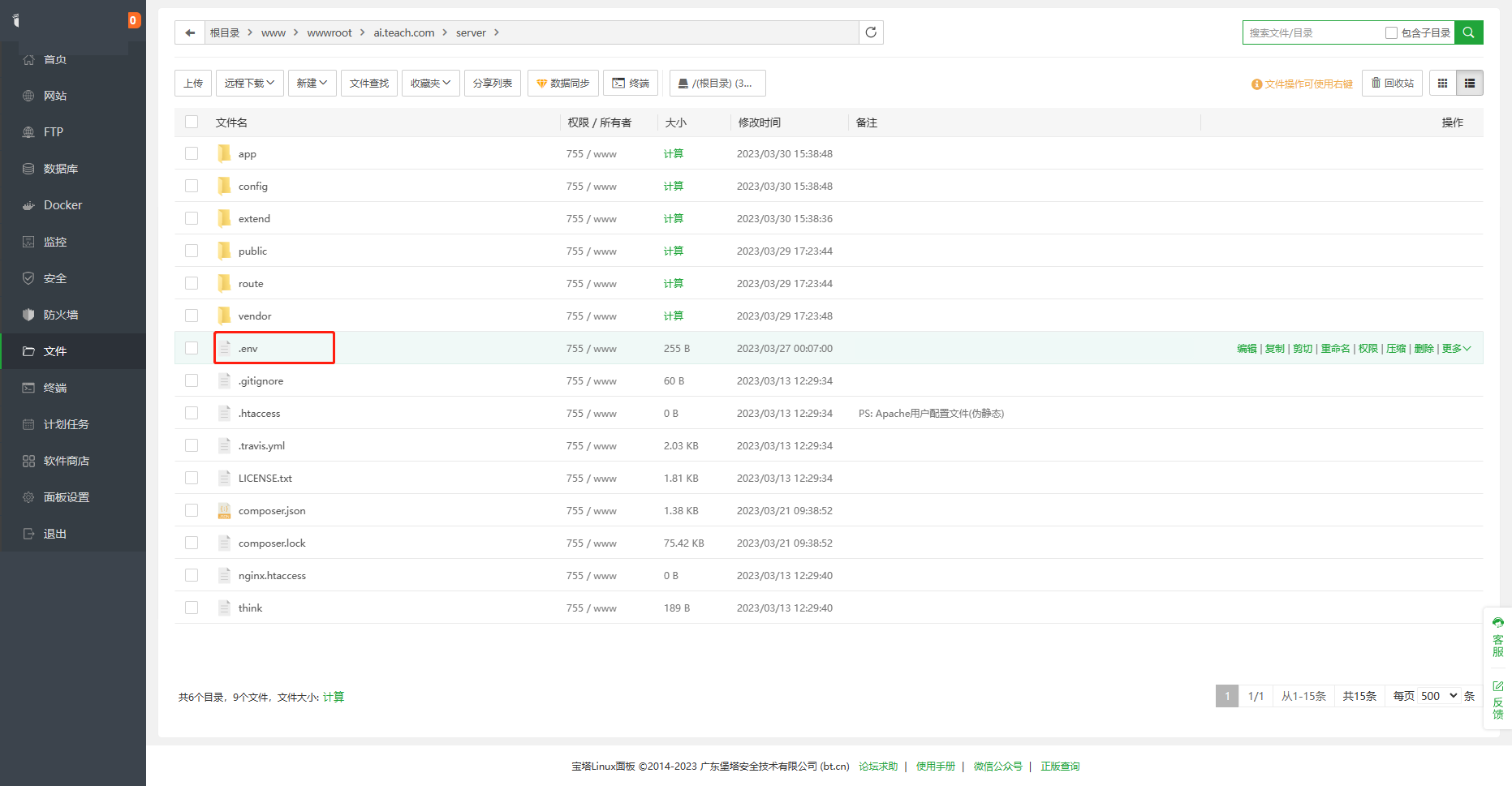
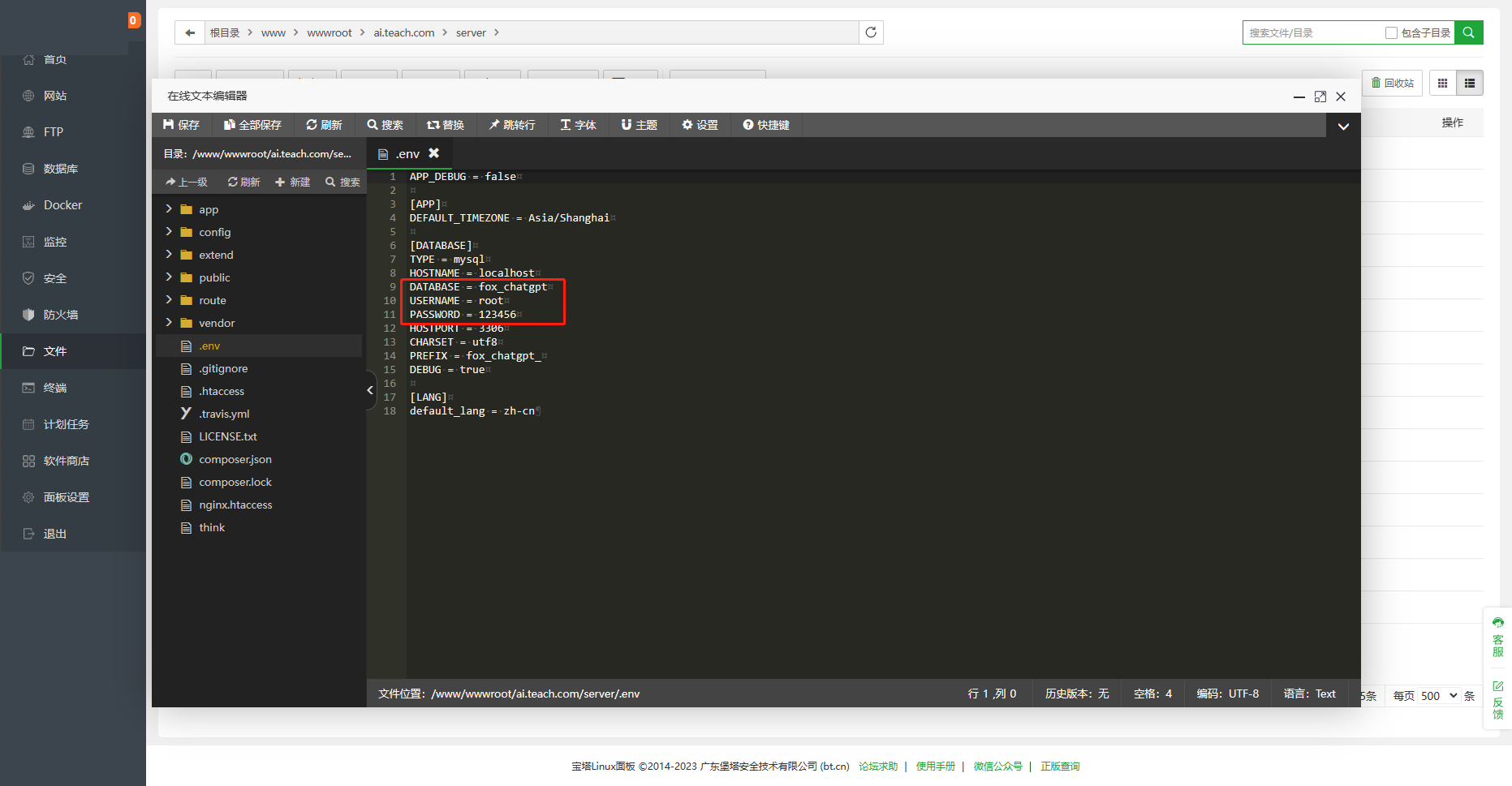
4、更改根目录.env文件里的数据库配置,改成自己新建站点的数据库 名称、账号、密码。
5、导入数据库,上传源码包里的db.sql文件,上传导入

上传完毕以后,点一下“导入”按钮
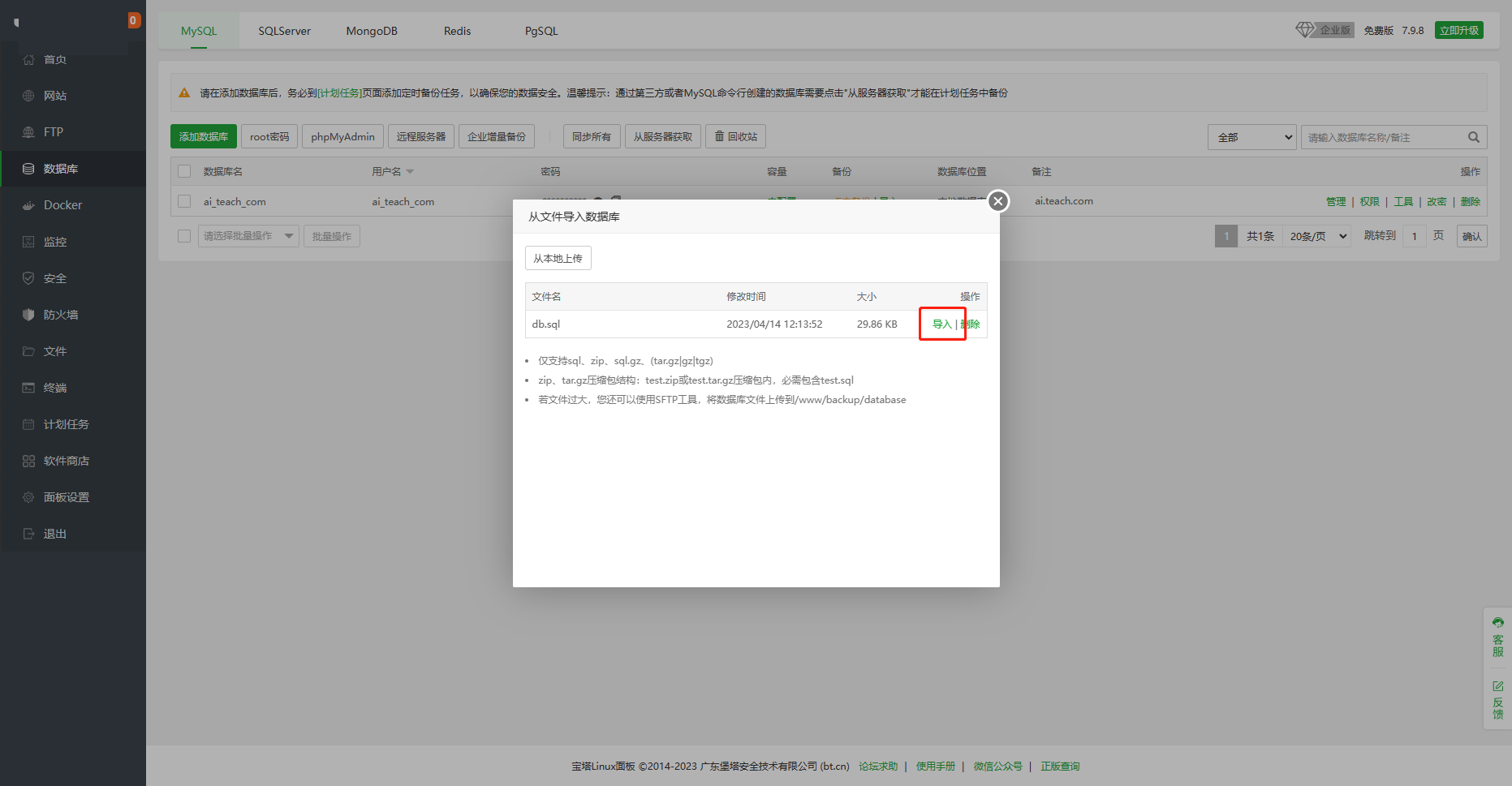
6、打开站点设置,点击网站目录,设置运行目录为/public,防跨站攻击一定要关掉
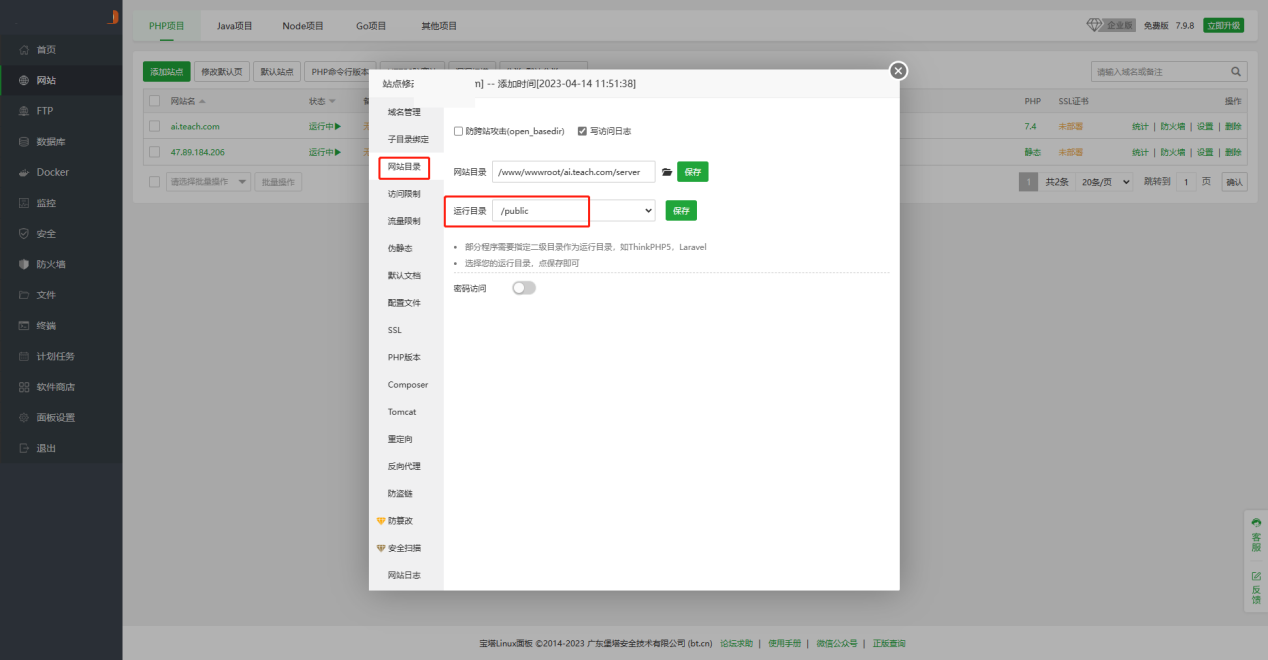
7、设置ssl证书(ssl证书可以使用宝塔免费证书,也可以去腾讯云/阿里云等平台申请),配置完成后打开“强制SSL”开关
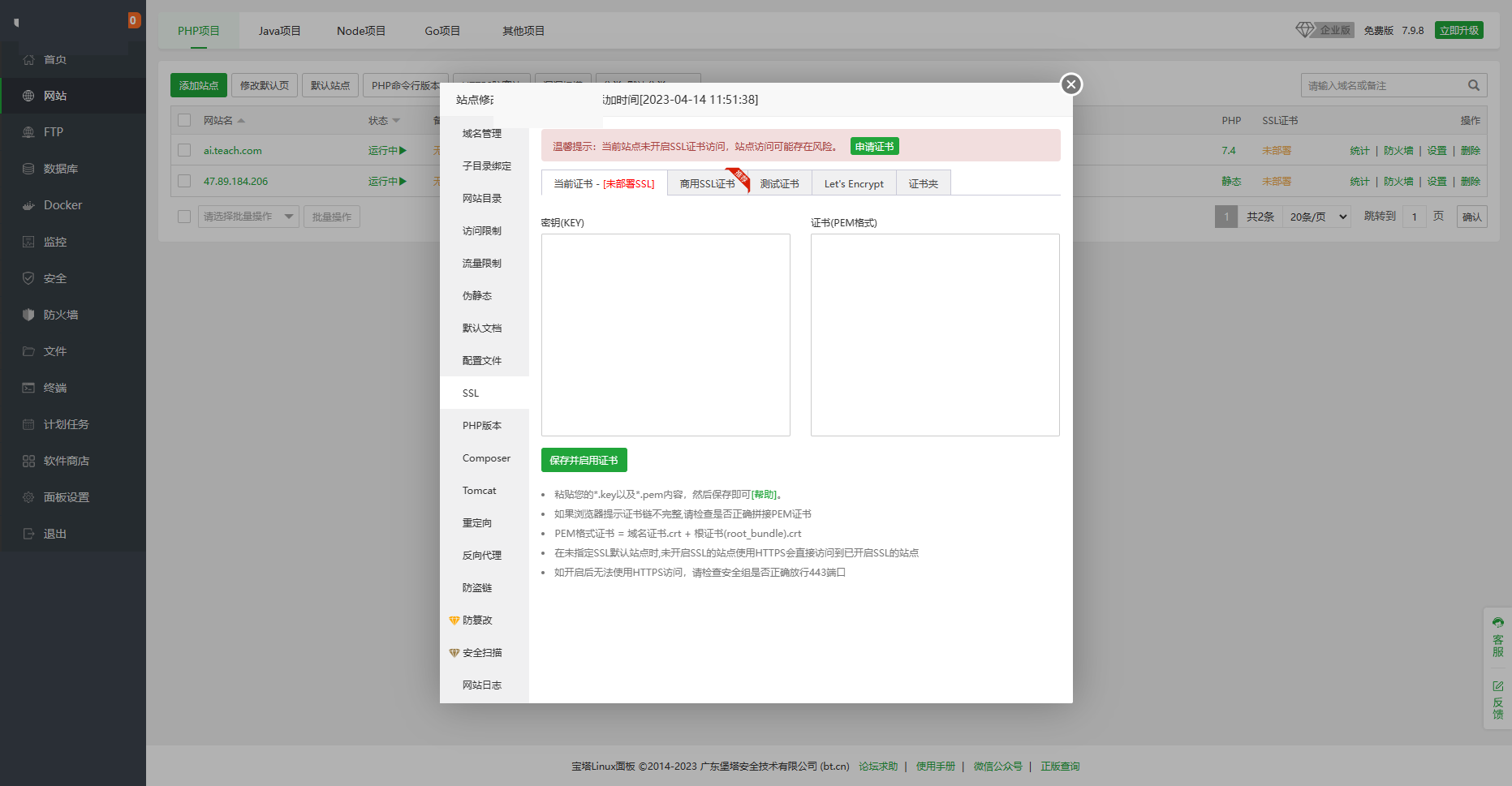
8、进入超管后台升级系统到最新版本
超管后台地址:https://域名/super
初始账号密码:super 123456 及时修改
-----
分站后台地址:https://域名/admin
初始账号密码:admin 123456 及时修改
后台必须用https访问,否则无法升级
9、首次直接打开域名会打不开网页
需要在 从 站点后台->功能->web版,打开PC版开关 即可
第二步:配置AI接口通道
《API接口通道我该如何选择?》
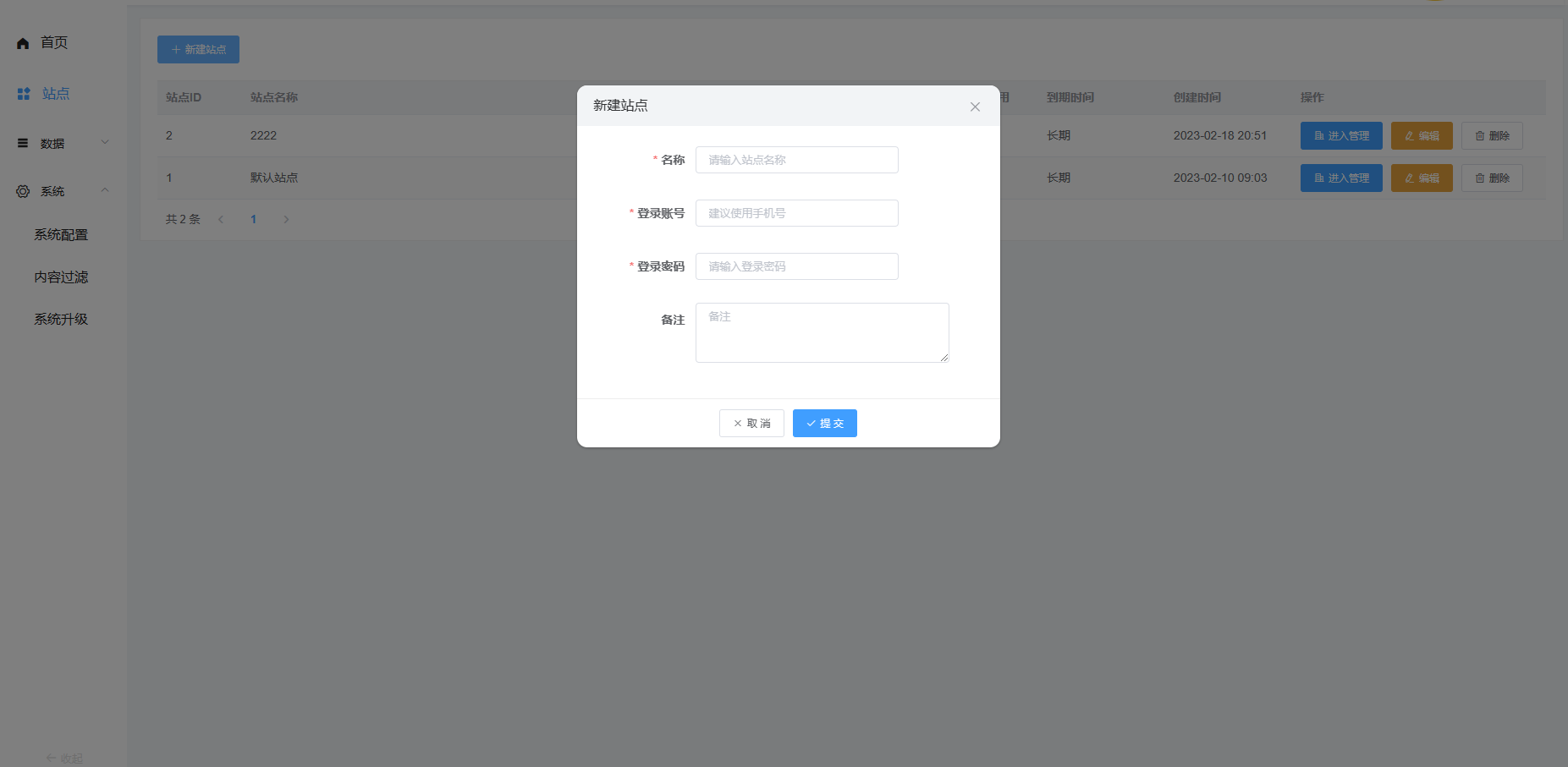
如何创建saas账号?
在超管后台添加新站点即可
如何升级系统?
进入超管后台->系统->系统升级 在更新前一定要查看更新内容,留意注意事项
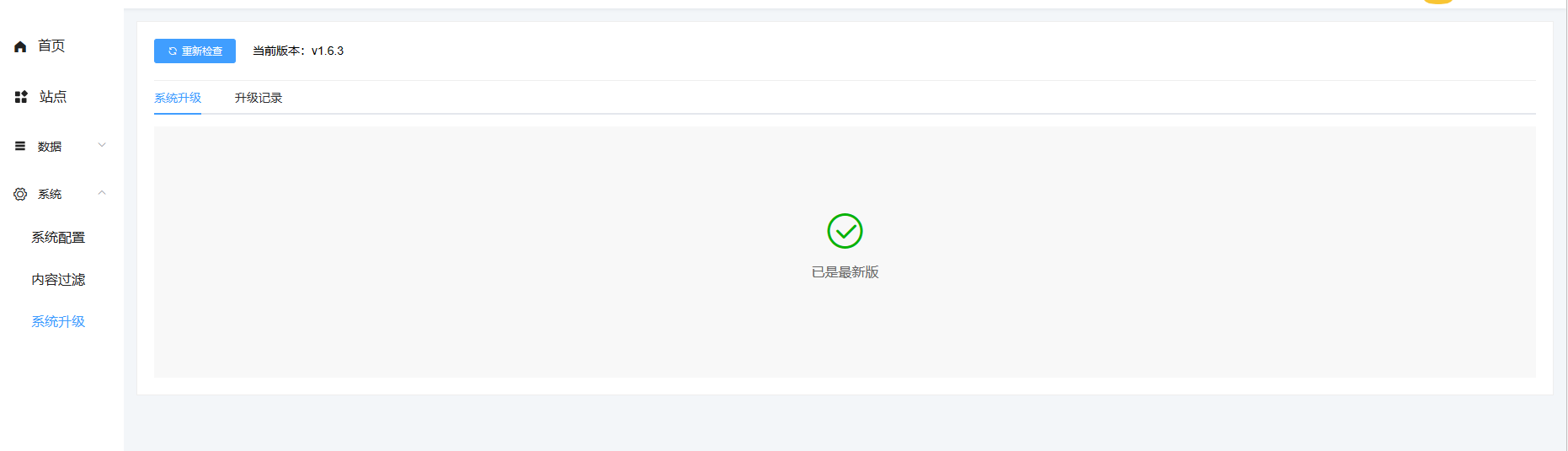
如果涉及小程序的更新,在分站点后台重新上传小程序代码,提交审核即可
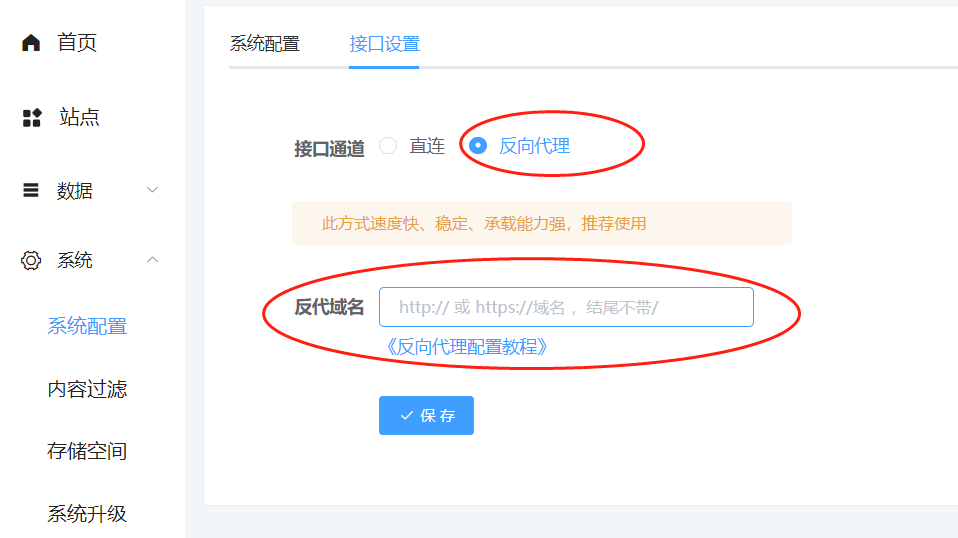
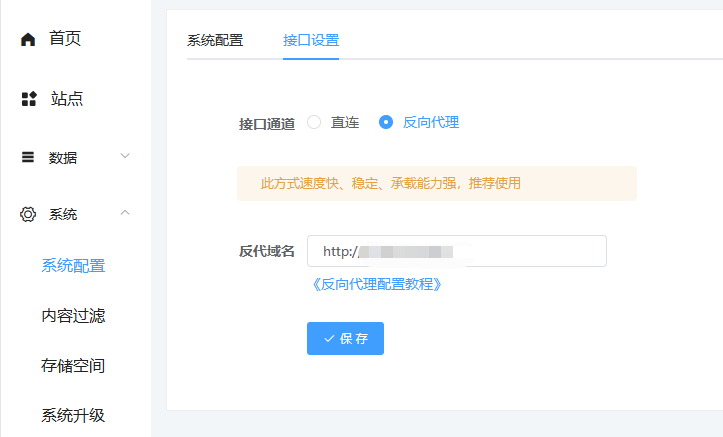
反向代理配置教程
注意,Openai和Gemini接口在国内直连不通,都需要配置反向代理 一、配置openai反向代理 1、超管后台选择接口通道为“反向代理”,填入自己海外服务器站点的域名。
2、在海外宝塔添加反向代理 将海外宝塔升级到最新,然后新建一个站点 -> 站点设置 -> 反向代理, 参数见下图:目标URL是 https://api.openai.com,发送域名是 api.openai.com
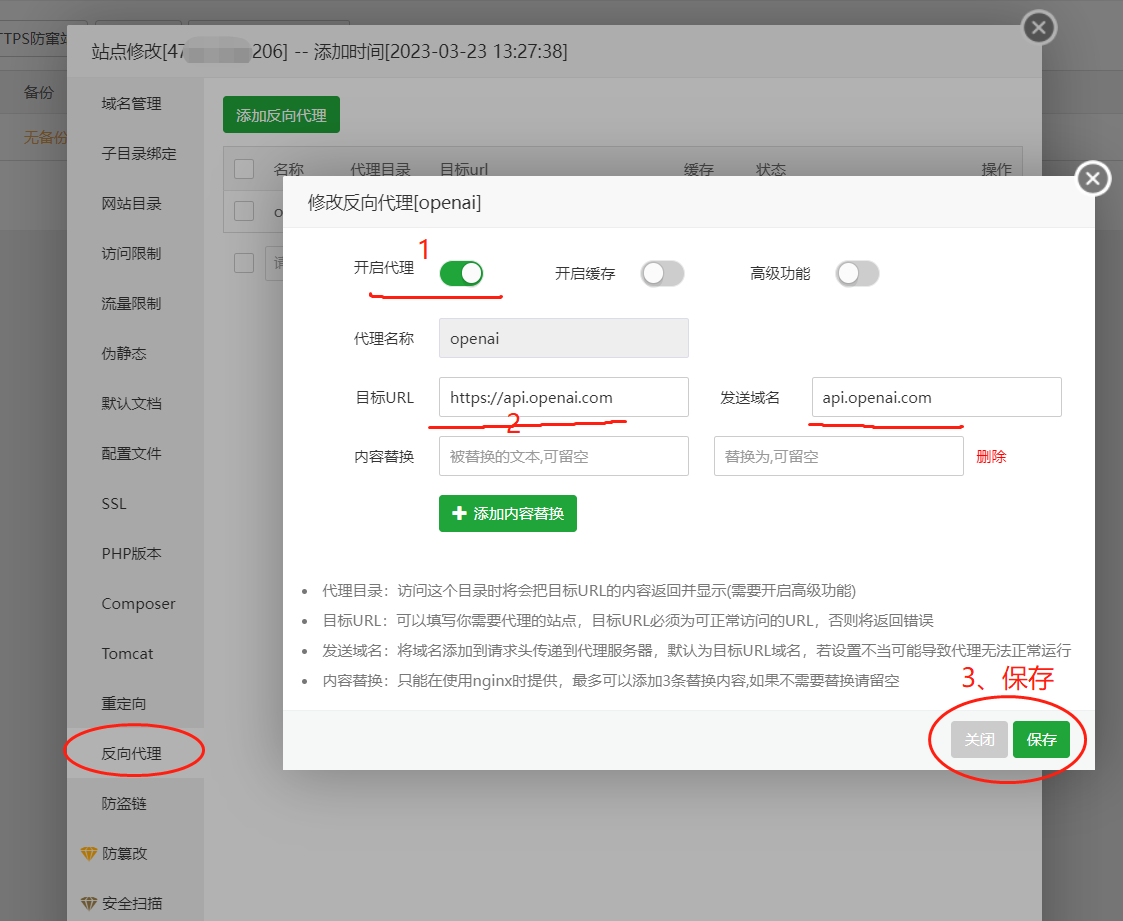
注意:配置完以后,将反代地址放浏览器打开,出现下图结果说明反向代理配置成功

如果出现502错误,则按下面方法解决: 打开海外宝塔面板 -> 站点设置 -> 反向代理 -> 配置文件
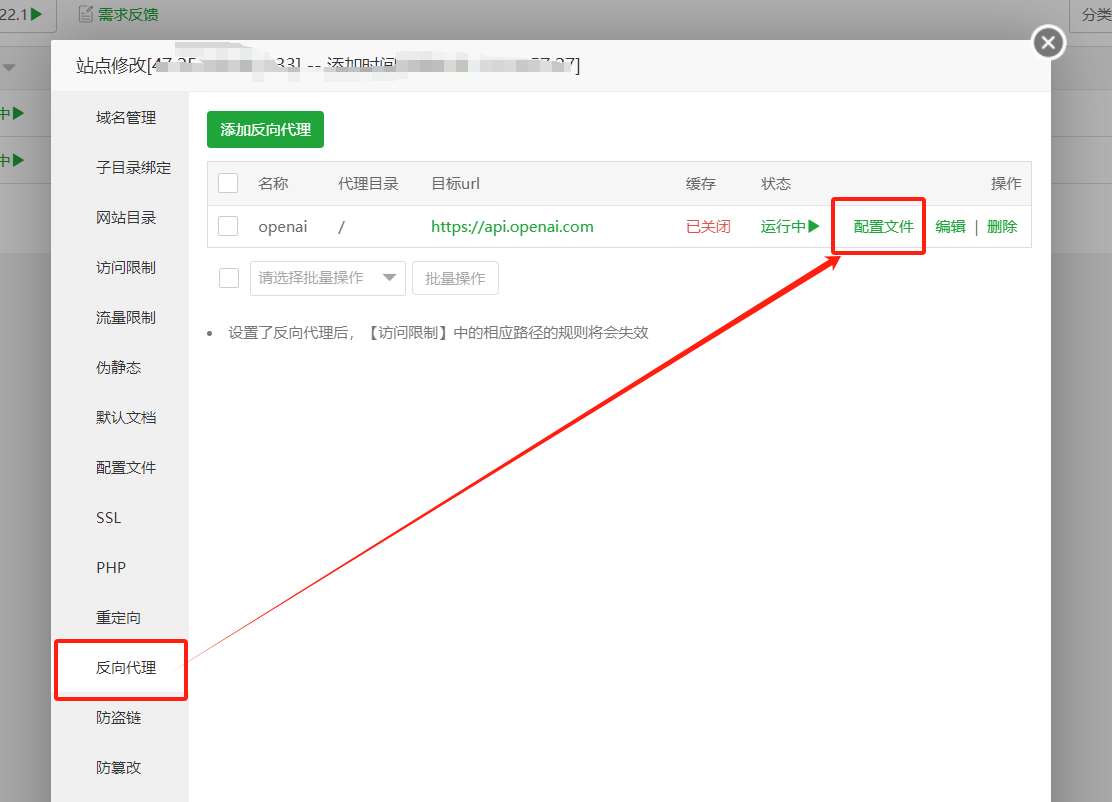
在 location / { proxy_pass https://api.openai.com; proxy_set_header Host api.openai.com; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header REMOTE-HOST $remote_addr; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection $connection_upgrade; proxy_http_version 1.1; # proxy_hide_header Upgrade; #这段代码下面,新增一句 proxy_ssl_server_name on; 即可,如下图
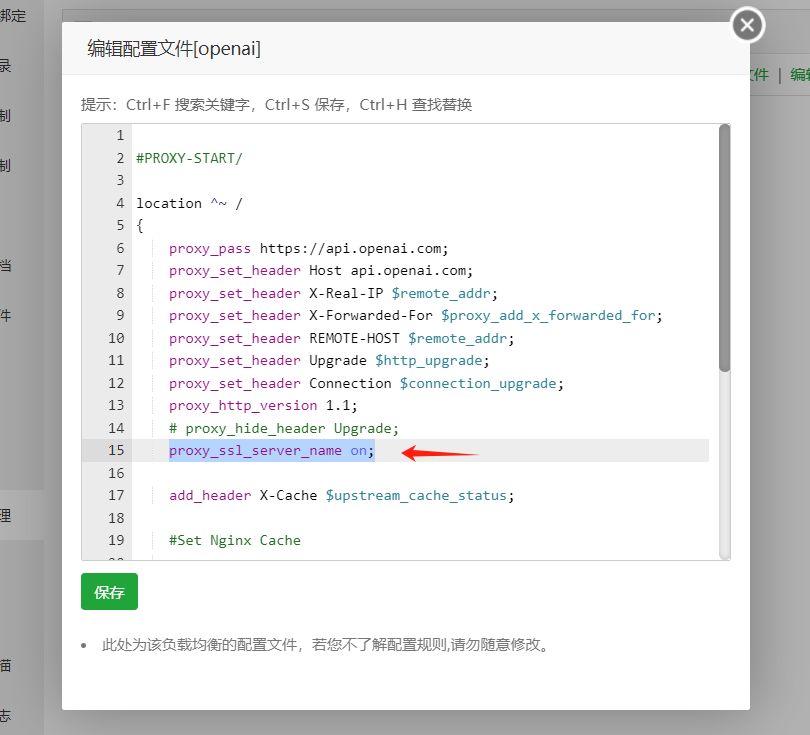
二、配置Gemini反向代理 另外在海外宝塔添加一个新站点(可以用域名,也可以用ip+端口形式),打开站点设置,添加反向代理 参数见下图:目标URL是 https://generativelanguage.googleapis.com,发送域名是 generativelanguage.googleapis.com
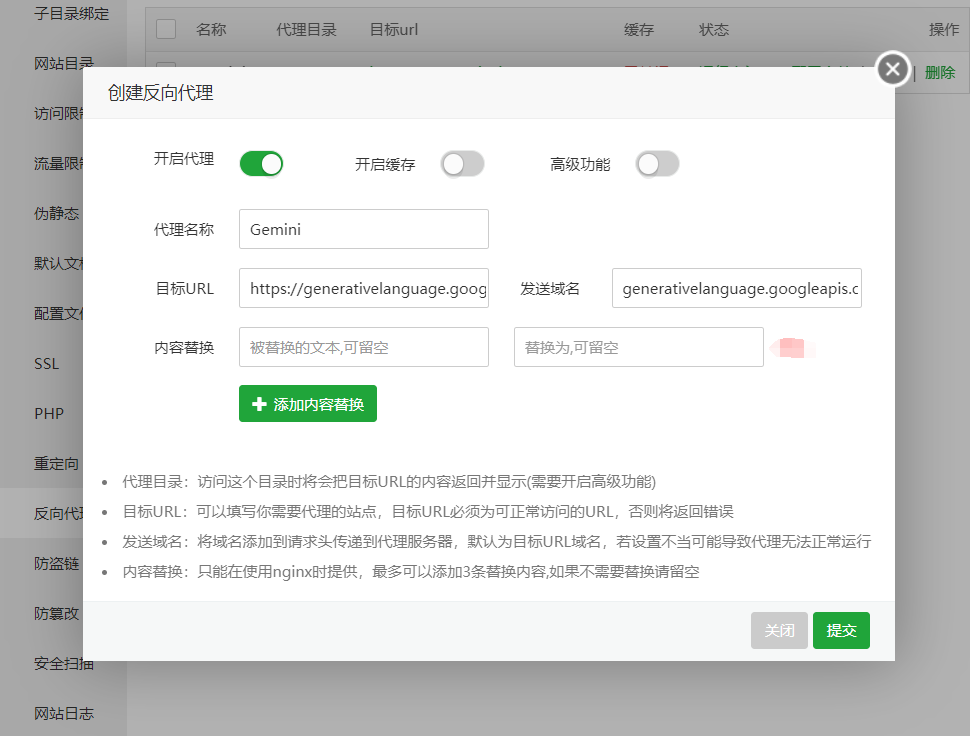
然后将站点地址填到后台Gemini通道的接口地址处:

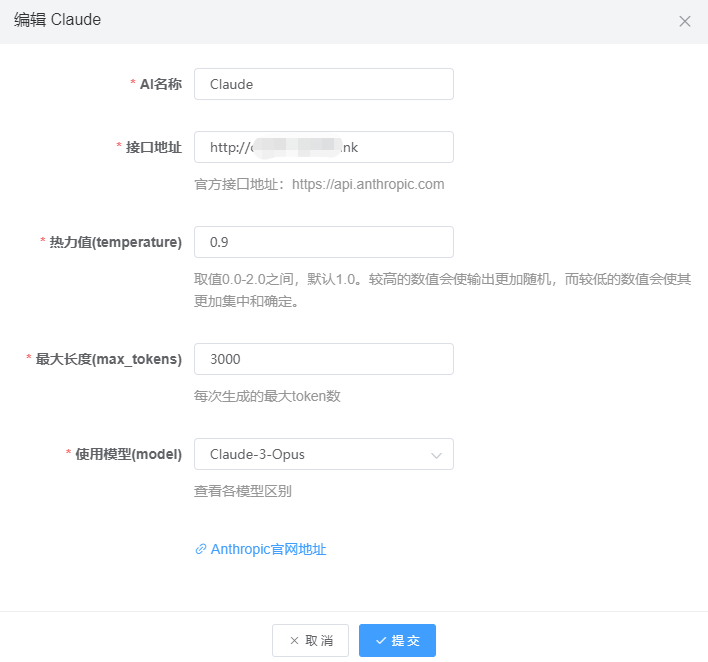
三、配置claude反向代理 在海外宝塔添加一个新站点(可以用域名,也可以用ip+端口形式),打开站点设置,添加反向代理 参数见下图:目标URL是 https://api.anthropic.com,发送域名是 anthropic.com

注意:配置完以后,将反代地址放浏览器打开,出现下图结果说明反向代理配置成功

如果出现502错误,则按下面方法解决: 打开海外宝塔面板 -> 站点设置 -> 反向代理 -> 配置文件

在 location / { proxy_pass https://api.openai.com; proxy_set_header Host api.openai.com; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header REMOTE-HOST $remote_addr; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection $connection_upgrade; proxy_http_version 1.1; # proxy_hide_header Upgrade; #这段代码下面,新增一句 proxy_ssl_server_name on; 即可,如下图 然后将站点地址填到后台claude通道的接口地址处:
API接口通道我该如何选择?
如果分站点的AI接口使用openai(站点后台->系统配置->AI参数配置->AI接口),则需要在超管后台配置接口通道,其他方式则无需在超管后台配置接口通道
1、进入超管后台选择接口通道: 直连:(1)主程序放在海外时选择此方式,无需配置反向代理 (2)直接使用国内接口,无需配置反向代理 反向代理:主程序放在国内时,选择此方式,需搭配海外服务器使用 使用接口文件转发:此方式已淘汰,新版本无法使用,仅暂时保留此配置给部分旧版本使用
其他文档
服务协议
在使用本网站提供的AI服务前,请您务必仔细阅读并理解本《免责声明》(以下简称“本声明”)。请您知悉,如果您选择继续访问本网站、或使用本网站提供的本服务以及通过各类方式利用本网站的行为(以下统称“本服务”),则视为接受并同意本声明全部内容。
1、您在从事与本服务相关的所有行为(包括但不限于访问浏览、利用、转载、宣传介绍)时,必须以善意且谨慎的态度行事;您确保不得利用本服务故意或者过失的从事危害国家安全和社会公共利益、扰乱经济秩序和社会秩序、侵犯他人合法权益等法律、行政法规禁止的活动,并确保自定义输入文本不包含以下违反法律法规、政治相关、侵害他人合法权益的内容:
- 反对宪法所确定的基本原则的;
- 危害国家安全,泄露国家秘密,颠覆国家政权,破坏国家统一的;
- 损害国家荣誉和利益的;
- 歪曲、丑化、亵渎、否定英雄烈士事迹和精神,以侮辱、诽谤或者其他方式侵害英雄烈士的姓名、肖像、名誉、荣誉的;
- 宣扬恐怖主义、极端主义或者煽动实施恐怖活动、极端主义活动的;
- 煽动民族仇恨、民族歧视,破坏民族团结的;
- 破坏国家宗教政策,宣扬邪教和封建迷信的;
- 散布谣言,扰乱经济秩序和社会秩序的;
- 散布淫秽、色情、赌博、暴力、凶杀、恐怖或者教唆犯罪的;
- 侮辱或者诽谤他人,侵害他人名誉、隐私和其他合法权益的;
- 含有虚假、有害、胁迫、侵害他人隐私、骚扰、侵害、中伤、粗俗、猥亵、或其它道德上令人反感的内容
- 中国法律、法规、规章、条例以及任何具有法律效力之规范所限制或禁止的其它内容。
2、您确认使用本服务时输入的内容将不包含您的个人信息。您同意并承诺,在使用本服务时,不会披露任何保密、敏感或个人信息。
3、本服务承诺不收集您的个人隐私数据,也不会与第三方共享您的个人信息。
4、禁止使用本服务算法编辑、加工、处理自己的或他人的个人信息、隐私数据等。
5、我们承诺不会使用您的输入内容、上传文件等训练AI模型。
3、您确认并知悉本服务生成的所有内容都是由人工智能模型生成,所以可能会出现意外和错误的情况,请确保检查事实。我们对其生成内容的准确性、完整性和功能性不做任何保证,并且其生成的内容不代表我们的态度或观点,仅为提供更多信息,也不构成任何建议或承诺。对于您根据本服务提供的信息所做出的一切行为,除非另有明确的书面承诺文件,否则我们不承担任何形式的责任。
4、本服务来自于法律法规允许的包括但不限于公开互联网等信息积累,因互联网的开放性属性,不排除其中部分信息具有瑕疵、不合理或引发不快。遇有此情形的,欢迎并感谢您随时通过 120758225@qq.com 邮箱举报。
5、不论在何种情况下,本网站均不对由于网络连接故障,电力故障,罢工,劳动争议,暴乱,起义,骚乱,火灾,洪水,风暴,爆炸,不可抗力,战争,政府行为,国际、国内法院的命令,黑客攻击,互联网病毒,网络运营商技术调整,政府临时管制或任何其他不能合理控制的原因而造成的本服务不能访问、服务中断、信息及数据的延误、停滞或错误,不能提供或延迟提供服务而承担责任。
6、当本服务以链接形式推荐其他网站内容时,我们并不对这些网站或资源的可用性负责,且不保证从这些网站获取的任何内容、产品、服务或其他材料的真实性、合法性。在法律允许的范围内,本网站不承担您就使用本服务所提供的信息或任何链接所引致的任何直接、间接、附带、从属、特殊、继发、惩罚性或惩戒性的损害赔偿。
如何更换域名
1、首先将原域名、新域名发给我们客服变更授权
2、在宝塔面板里,更换绑定的域名、重新生成SSL证书
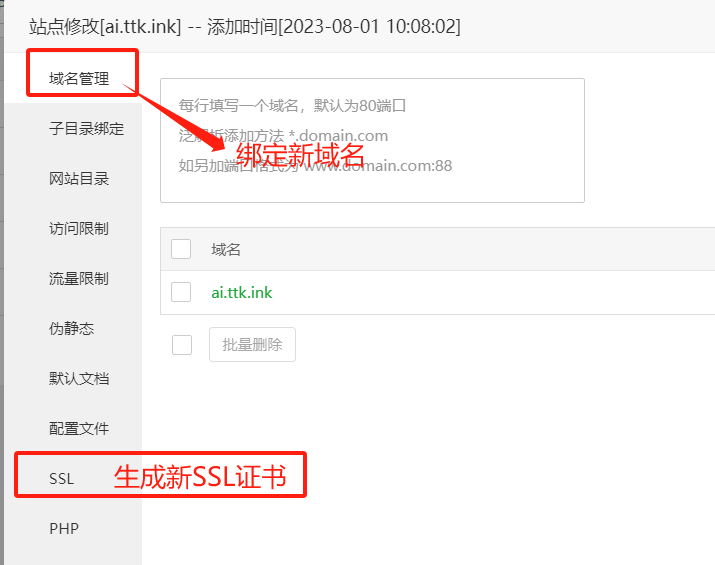
3、公众号:更换网页授权域名、JS安全域名、业务域名、服务器配置的服务器地址
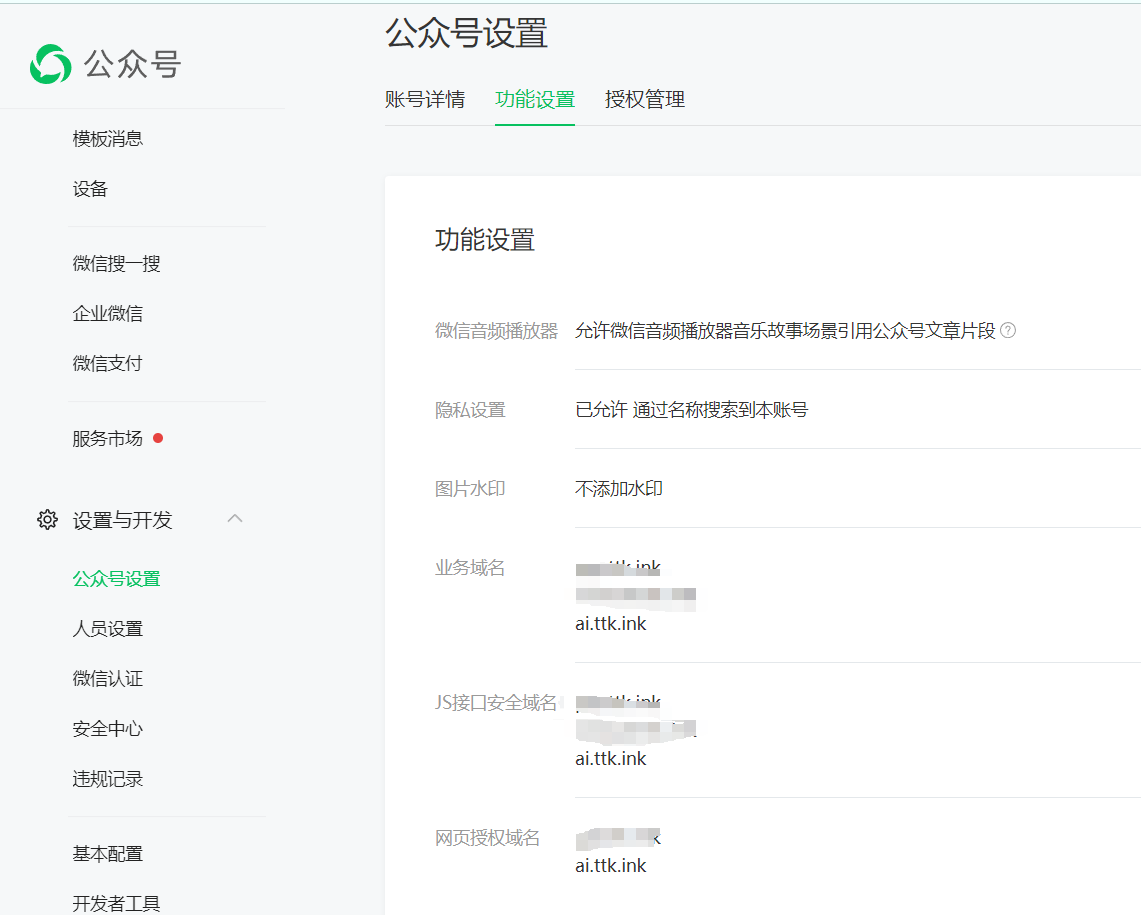
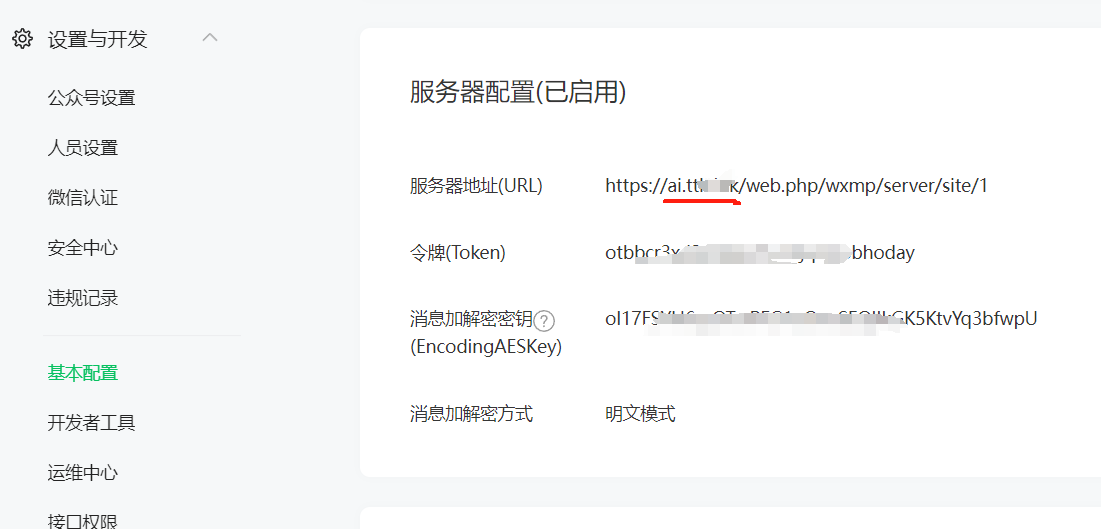
4、小程序:更换request合法域名、uploadFile合法域名、downloadFile合法域名、业务域名
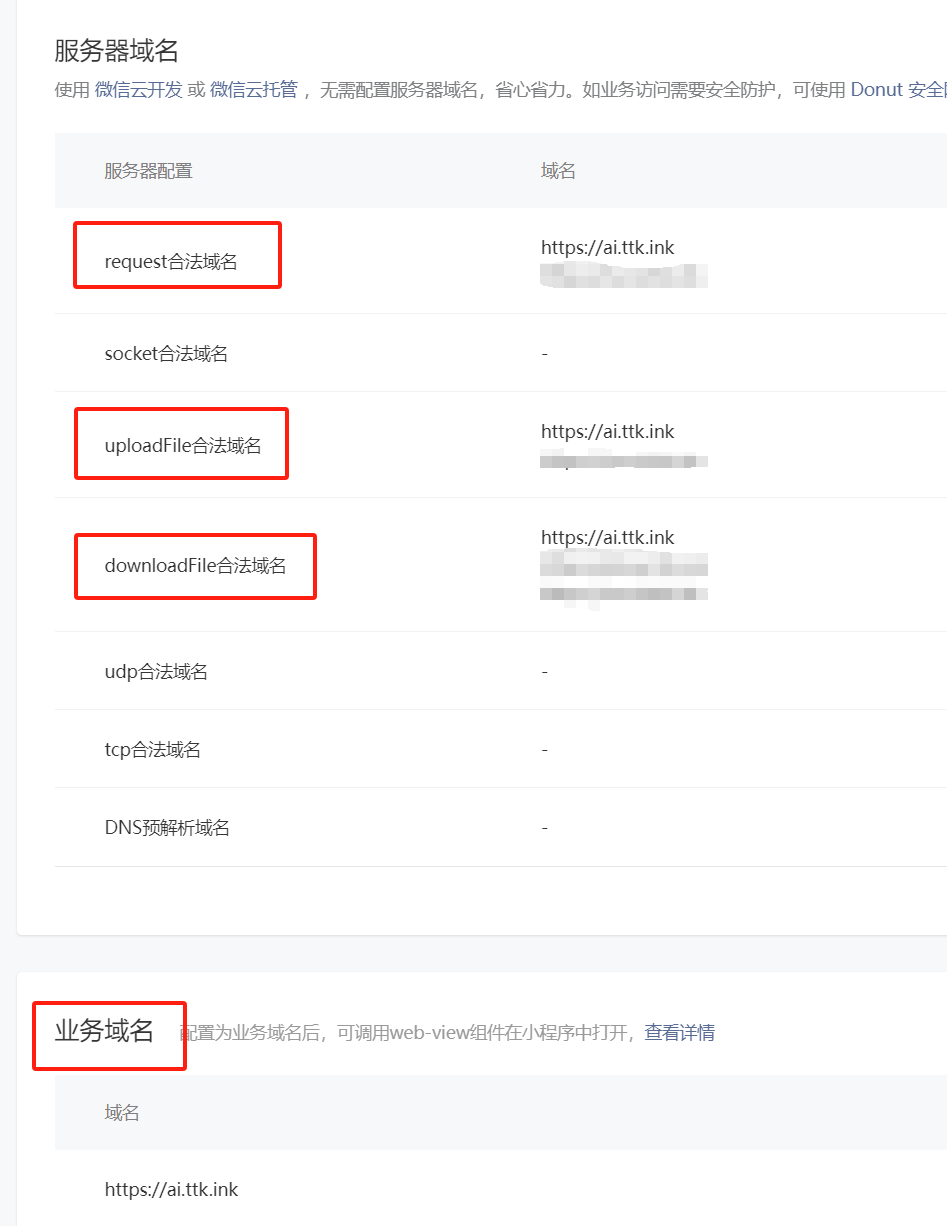
5、重新上传小程序提交审核
6、微信商户号:更换jsapi支付目录的域名
7、重新上传后台LOGO、分享海报图片
GPT 最佳实践
本指南分享了从 GPT 获得更好结果的策略和战术。有时可以结合使用此处描述的方法以获得更大的效果。我们鼓励进行实验以找到最适合您的方法。
此处演示的一些示例目前仅适用于我们功能最强大的模型gpt-4. 如果您还没有访问权限,gpt-4请考虑加入候补名单。一般来说,如果您发现 GPT 模型在某项任务中失败并且有更强大的模型可用,通常值得再次尝试使用更强大的模型。
获得更好结果的六种策略
写清楚说明
GPT 无法读懂您的想法。如果输出太长,要求简短的答复。如果输出太简单,请要求专家级的写作。如果您不喜欢这种格式,请展示您希望看到的格式。GPT 对您想要什么的猜测越少,您获得它的可能性就越大。
策略:
- 在您的查询中包含详细信息以获得更相关的答案
- 要求模特采用角色
- 使用定界符清楚地指示输入的不同部分
- 指定完成任务所需的步骤
- 提供例子
- 指定所需的输出长度
提供参考文本
GPT 可以自信地编造假答案,尤其是当被问及深奥的话题或引用和 URL 时。就像一张笔记可以帮助学生在考试中取得更好的成绩一样,为 GPT 提供参考文本可以帮助以更少的捏造来回答。
策略:
- 指示模型使用参考文本回答
- 指示模型使用参考文本中的引用来回答
将复杂任务拆分为更简单的子任务
正如在软件工程中将复杂系统分解为一组模块化组件是一种很好的做法一样,提交给 GPT 的任务也是如此。复杂的任务往往比简单的任务有更高的错误率。此外,复杂的任务通常可以重新定义为更简单任务的工作流,其中早期任务的输出用于构建后续任务的输入。
策略:
- 使用意图分类来识别与用户查询最相关的指令
- 对于需要很长对话的对话应用,总结或过滤之前的对话
- 分段总结长文档并递归构建完整摘要
给 GPT 时间“思考”
如果要求将 17 乘以 28,您可能不会立即知道,但随着时间的推移仍然可以计算出来。同样,GPT 在试图立即回答而不是花时间找出答案时会犯更多的推理错误。在回答之前询问一系列推理可以帮助 GPT 更可靠地推理出正确答案。
策略:
- 在匆忙下结论之前指示模型制定出自己的解决方案
- 使用内心独白或一系列查询来隐藏模型的推理过程
- 询问模型是否遗漏了之前传递的任何内容
使用外部工具
通过为 GPT 提供其他工具的输出来弥补它们的弱点。例如,文本检索系统可以将相关文档告知 GPT。代码执行引擎可以帮助 GPT 进行数学运算和运行代码。如果一项任务可以通过工具而不是 GPT 更可靠或更有效地完成,请卸载它以充分利用两者。
策略:
- 使用基于嵌入的搜索来实现高效的知识检索
- 使用代码执行来执行更准确的计算或调用外部 API
系统地测试更改
如果可以衡量,提高绩效会更容易。在某些情况下,对提示的修改会在一些孤立的示例上获得更好的性能,但会导致在更具代表性的示例集上的整体性能变差。因此,要确保更改对性能产生积极影响,可能有必要定义一个综合测试套件(也称为“评估”)。
战术:
- 参考黄金标准答案评估模型输出
策略
上面列出的每个策略都可以用特定的策略来实例化。这些策略旨在为尝试的事情提供想法。它们绝不是全面的,您可以随意尝试此处未展示的创意。
写清楚的说明
在查询中包含详细信息以获得更相关的答案
为了获得高度相关的响应,请确保请求提供任何重要的细节或上下文。否则,您将把它留给模型来猜测您的意思。
| 更差 | 更好的 |
| 如何在 Excel 中添加数字? | 如何在 Excel 中将一行美元金额相加?我想对整张行自动执行此操作,所有总计都在右侧的名为“总计”的列中结束。 |
| 谁是总统? | 谁是 2021 年的墨西哥总统,选举的频率如何? |
| 编写代码来计算斐波那契数列。 | 编写一个 TypeScript 函数来高效地计算斐波那契数列。自由地评论代码以解释每一部分的作用以及为什么这样写。 |
| 总结会议记录。 | 在一个段落中总结会议记录。然后写下演讲者的降价清单和他们的每个要点。最后,列出演讲者建议的后续步骤或行动项目(如果有)。 |
让模特采用角色
系统消息可用于指定模型在其回复中使用的角色。
system:当我请求帮助写东西时,你会回复一份文档,每个段落至少包含一个笑话或俏皮的评论。
user:给我的钢螺栓供应商写一封感谢信,感谢他在短时间内准时交货。这使我们能够交付重要订单。
使用定界符清楚地指示输入的不同部分
三重引号、XML 标记、章节标题等分隔符可以帮助区分要区别对待的文本部分。
user:用俳句总结由三重引号分隔的文本。"""在此插入文本"""
system:您将获得一对关于同一主题的文章(用 XML 标记分隔)。先总结一下每篇文章的论点。然后指出他们中的哪一个提出了更好的论点并解释原因。
user:<article>在这里插入第一篇文章</article> <article>在这里插入第二篇文章</article>
system:您将获得论文摘要和建议的标题。论文标题应该让读者对论文的主题有一个很好的了解,但也应该引人注目。如果标题不符合这些标准,建议 5 个备选方案。
user:摘要:此处插入摘要标题:此处插入标题
对于诸如此类的简单任务,使用定界符可能不会对输出质量产生影响。然而,任务越复杂,消除任务细节的歧义就越重要。不要让 GPT 工作以准确理解您对它们的要求。
指定完成任务所需的步骤
有些任务最好指定为一系列步骤。明确地写出步骤可以使模型更容易遵循它们。
system:使用以下分步说明响应用户输入。第 1 步 - 用户将用三重引号为您提供文本。在一个句子中总结这段文字,并加上一个前缀“Summary:”。第 2 步 - 将第 1 步中的摘要翻译成西班牙语,并加上前缀“Translation:”。
user:"""在此插入文本"""
提供示例
提供适用于所有示例的一般说明通常比通过示例演示任务的所有排列更有效,但在某些情况下提供示例可能更容易。例如,如果您打算让模型复制一种难以明确描述的特定样式来响应用户查询。这被称为“少量”提示。
系统:以一致的风格回答。
用户:教我耐心。
助手:开辟最深山谷的河流从温和的泉水流出;最伟大的交响乐源于一个音符;最复杂的挂毯始于一根单独的线。
用户:教我认识海洋。
指定输出的所需长度
您可以要求模型生成具有给定目标长度的输出。目标输出长度可以根据单词、句子、段落、要点等的计数来指定。但是请注意,指示模型生成特定数量的单词并不能实现高精度。该模型可以更可靠地生成具有特定数量的段落或要点的输出。
用户:用大约 50 个单词总结由三重引号分隔的文本。"""在此插入文本"""
用户:在 2 个段落中总结由三重引号分隔的文本。"""在此插入文本"""
用户:在 3 个要点中总结由三重引号分隔的文本。"""在此插入文本"""
提供参考文本
指示模型使用参考文本回答
如果我们可以为模型提供与当前查询相关的可信信息,那么我们可以指示模型使用提供的信息来编写其答案。
系统:使用由三重引号分隔的提供的文章来回答问题。如果在文章中找不到答案,写“我找不到答案”。
用户:<插入文章,每篇文章用三重引号分隔> 问题:<在此处插入问题>
鉴于 GPT 的上下文窗口有限,为了应用这种策略,我们需要一些方法来动态查找与所问问题相关的信息。嵌入可用于实现高效的知识检索。有关如何实现这一点的更多详细信息,请参阅策略“使用基于嵌入的搜索来实现高效的知识检索” 。
指示模型使用参考文本中的引文来回答
如果输入已补充相关知识,则可以直接要求模型通过引用所提供文档中的段落来为其答案添加引文。请注意,输出中的引用可以通过提供的文档中的字符串匹配以编程方式进行验证。
系统:您将获得一份由三重引号和一个问题分隔的文件。您的任务是仅使用提供的文件回答问题,并引用用于回答问题的文件中的段落。如果文档不包含回答此问题所需的信息,则只需写上:“信息不足”。如果提供了问题的答案,则必须用引文进行注释。使用以下格式引用相关段落 ({"citation": …})。
用户:"""<在此处插入文档>""" 问题:<在此处插入问题>
将复杂任务拆分为更简单的子任务
使用意图分类来识别与用户查询最相关的指令
对于需要大量独立指令集来处理不同情况的任务,首先对查询类型进行分类并使用该分类来确定需要哪些指令可能是有益的。这可以通过定义与处理给定类别中的任务相关的固定类别和硬编码指令来实现。这个过程也可以递归地应用于将任务分解为一系列阶段。这种方法的优点是每个查询将仅包含执行任务下一阶段所需的指令,与使用单个查询执行整个任务相比,这可以降低错误率。这也可以降低成本,因为更大的提示运行成本更高(参见定价信息)。
例如,假设对于客户服务应用程序,可以将查询分类如下:
系统:您将收到客户服务查询。将每个查询分为主要类别和次要类别。以 json 格式提供带有键的输出:primary 和 secondary。主要类别:计费、技术支持、账户管理或一般查询。计费次要类别: - 取消订阅或升级 - 添加付款方式 - 收费说明 - 对收费提出异议 技术支持次要类别: - 故障排除 - 设备兼容性 - 软件更新 账户管理次要类别: - 密码重置 - 更新个人信息 - 关闭帐户 -帐户安全 一般查询二级类别: - 产品信息 - 定价 - 反馈 - 与人交谈
用户:我需要让我的互联网重新工作。
基于客户查询的分类,可以向 GPT 模型提供一组更具体的指令来处理后续步骤。例如,假设客户需要“故障排除”方面的帮助。
系统:您将收到需要在技术支持环境中进行故障排除的客户服务查询。通过以下方式帮助用户: - 要求他们检查所有进出路由器的电缆是否已连接。请注意,电缆随时间松动是很常见的。- 如果所有电缆都已连接但问题仍然存在,请询问他们使用的是哪种路由器型号 - 现在您将建议他们如何重新启动他们的设备: -- 如果型号是 MTD-327J,建议他们按下红色按钮并按住它 5 秒钟,然后等待 5 分钟,然后再测试连接。-- 如果型号是 MTD-327S,建议他们拔下并重新插入,然后等待 5 分钟,然后再测试连接。- 如果客户的问题在重启设备并等待 5 分钟后仍然存在,请通过输出 {"IT support requested"} 将他们连接到 IT 支持。
用户:我需要让我的互联网重新工作。
请注意,已指示模型发出特殊字符串以指示对话状态何时发生变化。这使我们能够将我们的系统变成一个状态机,其中状态决定注入哪些指令。通过跟踪状态,哪些指令与该状态相关,以及可选地允许从该状态进行哪些状态转换,我们可以为用户体验设置护栏,而这很难通过结构化程度较低的方法实现。
Tactic:对于需要很长对话的对话应用,总结或过滤之前的对话
由于 GPT 具有固定的上下文长度,因此整个对话都包含在上下文窗口中的用户和助手之间的对话不能无限期地继续。
这个问题有多种解决方法,其中之一是总结对话中的先前回合。一旦输入的大小达到预定的阈值长度,这可能会触发一个查询,该查询总结了部分对话,并且先前对话的摘要可以作为系统消息的一部分包含在内。或者,可以在整个对话过程中在后台异步总结先前的对话。
另一种解决方案是动态选择与当前查询最相关的对话的先前部分。请参阅策略“使用基于嵌入的搜索来实现高效的知识检索”。
分段总结长文档并递归构建完整摘要
由于 GPT 具有固定的上下文长度,因此它们不能用于总结长度超过上下文长度减去单个查询中生成的摘要长度的文本。
要总结一个很长的文档,比如一本书,我们可以使用一系列查询来总结文档的每个部分。节摘要可以被连接和总结生成摘要的摘要。这个过程可以递归地进行,直到总结了整个文档。如果有必要使用有关前面部分的信息来理解后面的部分,那么另一个有用的技巧是在书中任何给定点之前包括文本的连续摘要,同时总结该点的内容。OpenAI在之前的研究中使用 GPT-3 的变体研究了这种用于总结书籍的程序的有效性。
给 GPT 时间“思考”
在匆忙下结论之前,指示模型自己制定解决方案
有时,当我们明确指示模型在得出结论之前根据第一原则进行推理时,我们会得到更好的结果。例如,假设我们想要一个模型来评估学生对数学问题的解决方案。解决这个问题的最明显方法是简单地询问模型学生的解决方案是否正确。
系统:判断学生的答案是否正确。
用户:问题陈述:我正在建造一个太阳能装置,我需要帮助来计算财务。- 土地成本 100 美元/平方英尺 - 我可以以 250 美元/平方英尺的价格购买太阳能电池板 - 我协商了一份维护合同,每年将花费我 10 万美元,外加 10 美元/平方英尺 的总成本是多少第一年的运营作为平方英尺数的函数。学生的解答:令 x 为以平方英尺为单位的安装尺寸。1.土地成本:100x 2.太阳能电池板成本:250x 3.维护成本:100,000 + 100x 总成本:100x + 250x + 100,000 + 100x = 450x + 100,000
助手:这位同学的答案是正确的。
但是这位同学的解法其实是不正确的!我们可以通过提示模型首先生成自己的解决方案来让模型成功注意到这一点。
系统:首先想出你自己解决问题的办法。然后将您的解决方案与学生的解决方案进行比较,并评估学生的解决方案是否正确。在您自己完成问题之前,不要判断学生的解决方案是否正确。
用户:问题陈述:我正在建造一个太阳能装置,我需要帮助来计算财务。- 土地成本 100 美元/平方英尺 - 我可以以 250 美元/平方英尺的价格购买太阳能电池板 - 我协商了一份维护合同,每年将花费我 10 万美元,外加 10 美元/平方英尺 的总成本是多少第一年的运营作为平方英尺数的函数。学生的解答:令 x 为以平方英尺为单位的安装尺寸。1.土地成本:100x 2.太阳能电池板成本:250x 3.维护成本:100,000 + 100x 总成本:100x + 250x + 100,000 + 100x = 450x + 100,000
助手:设 x 是以平方英尺为单位的安装尺寸。1.土地成本:100x 2.太阳能电池板成本:250x 3.维护成本:100,000 + 10x 总成本:100x + 250x + 100,000 + 10x = 360x + 100,000 学生的答案是错误的。他们在维护成本计算中犯了一个错误,使用 100x 而不是 10x。第一年运营的正确总成本是 360x + 100,000。
在操场上打开
使用内心独白或一系列查询来隐藏模型的推理过程
前面的策略表明,模型在回答特定问题之前详细推理问题有时很重要。对于某些应用程序,模型用于得出最终答案的推理过程不适合与用户共享。例如,在辅导应用程序中,我们可能希望鼓励学生自己找出答案,但模型对学生答案的推理过程可能会向学生揭示答案。
内心独白是一种可以用来缓解这种情况的策略。内心独白的想法是指示模型将本应对用户隐藏的输出部分放入结构化格式中,以便于解析它们。然后在将输出呈现给用户之前,对输出进行解析并仅使部分输出可见。
系统:按照以下步骤回答用户查询。第 1 步 - 首先找出您自己的问题解决方案。不要依赖学生的解决方案,因为它可能不正确。用三引号 (""") 将此步骤的所有作业括起来。第 2 步 - 将您的解决方案与学生的解决方案进行比较,并评估学生的解决方案是否正确。将此步骤的所有作业用三引号 ("") 括起来”)。第 3 步 - 如果学生犯了错误,请确定您可以在不给出答案的情况下给学生什么提示。将此步骤的所有工作用三重引号 (""") 括起来。第 4 步 - 如果学生犯了错误,请向学生提供上一步的提示(在三重引号之外)。而不是写“第 4 步 - ...”写“提示:”。
用户:问题陈述:<插入问题陈述> 学生解决方案:<插入学生解决方案>
或者,这可以通过一系列查询来实现,其中除最后一个之外的所有查询都对最终用户隐藏其输出。
首先,我们可以让模型自己解决问题。由于此初始查询不需要学生的解决方案,因此可以省略。这提供了额外的优势,即模型的解决方案不会因学生尝试的解决方案而产生偏差。
用户:<插入问题陈述>
接下来,我们可以让模型使用所有可用信息来评估学生解决方案的正确性。
系统:将您的解决方案与学生的解决方案进行比较,并评估学生的解决方案是否正确。
用户:问题陈述:"""<插入问题陈述>""" 您的解决方案:"""<插入模型生成的解决方案>""" 学生的解决方案:"""<插入学生的解决方案>"""
最后,我们可以让模型使用自己的分析来构建一个乐于助人的导师角色的回复。
系统:你是数学老师。如果学生犯了错误,请以不透露答案的方式向学生提供提示。如果学生没有犯错,只需给他们一个鼓励的评论。
用户:问题陈述:"""<插入问题陈述>""" 您的解决方案:"""<插入模型生成的解决方案>""" 学生的解决方案:"""<插入学生的解决方案>""" 分析:"""<插入模型从上一步生成的分析 >"""
询问模型是否遗漏了之前传递的任何内容
假设我们正在使用一个模型来列出与特定问题相关的来源的摘录。在列出每个摘录后,模型需要确定是否应该开始编写另一个摘录或是否应该停止。如果源文档很大,模型通常会过早停止并且无法列出所有相关摘录。在这种情况下,通常可以通过使用后续查询提示模型来查找它在先前传递中遗漏的任何摘录来获得更好的性能。
系统:您将获得一份由三重引号分隔的文件。你的任务是选择与以下问题相关的摘录:“人工智能历史上发生了哪些重大的范式转变。” 确保摘录包含解释它们所需的所有相关上下文——换句话说,不要提取缺少重要上下文的小片段。以 JSON 格式提供输出,如下所示:[{"excerpt": "..."}, ... {"excerpt": "..."}]
用户:"""<在此处插入文档>"""
助手:[{“摘录”:“模型在这里写了一个摘录”},... {“摘录”:“模型在这里写了另一个摘录”}]
用户:有更多相关的摘录吗?注意不要重复摘录。还要确保摘录包含解释它们所需的所有相关上下文——换句话说,不要提取缺少重要上下文的小片段。
使用外部工具
使用基于嵌入的搜索来实现高效的知识检索
如果作为输入的一部分提供,模型可以利用外部信息源。这可以帮助模型生成更明智和最新的响应。例如,如果用户询问有关特定电影的问题,将有关电影的高质量信息(例如演员、导演等)添加到模型的输入中可能会很有用。嵌入可用于实现高效的知识检索,以便在运行时将相关信息动态添加到模型输入中。
文本嵌入是一个向量,可以衡量文本字符串之间的相关性。相似或相关的字符串将比不相关的字符串靠得更近。这一事实以及快速向量搜索算法的存在意味着嵌入可用于实现高效的知识检索。特别是,一个文本语料库可以被分割成块,每个块都可以被嵌入和存储。然后可以嵌入给定的查询并执行向量搜索以从语料库中找到与查询最相关(即在嵌入空间中最接近)的嵌入文本块。
可以在OpenAI Cookbook中找到示例实现。有关如何使用知识检索来最小化模型编造错误事实的可能性的示例,请参阅策略“指示模型使用检索到的知识来回答查询”。
使用代码执行来执行更准确的计算或调用外部 API
不能依赖 GPT 自行准确地执行算术或长计算。在需要的情况下,可以指示模型编写和运行代码,而不是进行自己的计算。特别是,可以指示模型将要运行的代码放入指定的格式中,例如三重 backtics。生成输出后,可以提取并运行代码。最后,如果有必要,可以将代码执行引擎(即 Python 解释器)的输出作为输入提供给下一个查询的模型。
系统:您可以通过用三重反引号将其括起来来编写和执行 Python 代码,例如,```code goes here```。使用它来执行计算。
用户:找出以下多项式的所有实值根:3*x**5 - 5*x**4 - 3*x**3 - 7*x - 10。
代码执行的另一个好用例是调用外部 API。如果指导模型正确使用 API,则它可以编写使用它的代码。通过向模型提供说明如何使用 API 的文档和/或代码示例,可以指导模型如何使用 API。
系统:您可以通过用三重反引号括起来来编写和执行 Python 代码。另请注意,您可以访问以下模块以帮助用户向他们的朋友发送消息:```python import message message.write(to="John", message="嘿,下班后想见面吗?")`` `
警告:执行模型生成的代码本身并不安全,任何试图执行此操作的应用程序都应采取预防措施。特别是,需要一个沙盒代码执行环境来限制不受信任的代码可能造成的危害。
系统地测试变化
有时很难判断更改(例如,新指令或新设计)是否会使您的系统变得更好或更糟。查看几个示例可能会暗示哪个更好,但是样本量较小时,很难区分真正的改进还是随机的运气。也许这种变化有助于某些输入的性能,但会损害其他输入的性能。
评估程序(或“evals”)对于优化系统设计很有用。好的评价是:
- 代表现实世界的使用(或至少是多样化的)
- 包含许多测试用例以获得更大的统计能力(有关指南,请参见下表)
- 易于自动化或重复
| 要检测的差异 | 95% 置信度所需的样本量 |
| 30% | ~10 |
| 10% | ~100 |
| 3% | ~1,000 |
| 1% | ~10,000 |
输出的评估可以由计算机、人类或混合来完成。计算机可以使用客观标准(例如,具有单一正确答案的问题)以及一些主观或模糊标准来自动评估,其中模型输出由其他模型查询评估。OpenAI Evals是一个开源软件框架,提供用于创建自动评估的工具。
当存在一系列可能被认为质量相同的输出时(例如,对于答案很长的问题),基于模型的评估可能很有用。使用基于模型的评估可以实际评估的内容与需要人工评估的内容之间的界限是模糊的,并且随着模型变得更强大而不断变化。我们鼓励通过实验来弄清楚基于模型的评估对您的用例的适用程度。
参考黄金标准答案评估模型输出
假设已知问题的正确答案应该参考一组特定的已知事实。然后我们可以使用模型查询来计算答案中包含了多少所需事实。
例如,使用以下系统消息:
系统:您将获得由三重引号分隔的文本,这些文本应该是问题的答案。检查以下信息是否直接包含在答案中: - Neil Armstrong 是第一个在月球上行走的人。- 尼尔·阿姆斯特朗首次踏上月球的日期是 1969 年 7 月 21 日。对于这些要点中的每一个,请执行以下步骤: 1 - 重申要点。2 - 引用最接近这一点的答案。3 - 考虑阅读引文但不了解主题的人是否可以直接推断出这一点。在下定决心之前解释为什么或为什么不。4 - 如果对 3 的回答是“是”,则写“是”,否则写“否”。最后,提供有多少个“是”答案的计数。将此计数提供为 {"count": <insert count here>}。
这是一个满足两点的示例输入:
系统:<在上面插入系统消息>
用户:"""尼尔阿姆斯特朗因成为第一个踏上月球的人类而闻名。这一历史性事件发生在 1969 年 7 月 21 日,阿波罗 11 号任务期间。"""
这是一个示例输入,其中只有一个点得到满足:
系统:<在上面插入系统消息>
用户:"""尼尔·阿姆斯特朗走下登月舱,创造了历史,成为第一个踏上月球的人。"""
这是一个不满足的示例输入:
系统:<在上面插入系统消息>
用户:"""在 69 年的夏天,阿波罗 11 号的宏伟航行,像传说中的手一样大胆。阿姆斯特朗迈出了一步,历史展开了,"一小步,"他说,为了一个新世界。"""
这种基于模型的评估有很多可能的变体。考虑以下变体,它跟踪候选答案和黄金标准答案之间的重叠类型,并跟踪候选答案是否与黄金标准答案的任何部分相矛盾。
系统:使用以下步骤响应用户输入。在继续之前完全重述每个步骤。即“第 1 步:原因……”。第 1 步:逐步推理提交的答案中的信息与专家答案相比是否是:不相交、相等、子集、超集或重叠(即一些交集但不是子集/超集)。第 2 步:逐步推理提交的答案是否与专家答案的任何方面相矛盾。第 3 步:输出结构如下的 JSON 对象:{"type_of_overlap": "disjoint" or "equal" or "subset" or "superset" or "overlapping", "contradiction": true or false}
这是一个带有不合标准答案的示例输入,但与专家答案并不矛盾:
系统:<在上面插入系统消息>
用户:问题:“”“尼尔·阿姆斯特朗最著名的事件是什么?它发生在什么日期?假定 UTC 时间。”””提交的答案:“”“他不是在月球上行走吗?”“”专家回答: """尼尔·阿姆斯特朗最著名的是他是第一个在月球上行走的人。这一历史性事件发生在 1969 年 7 月 21 日。"""
这是一个示例输入,其答案直接与专家答案相矛盾:
系统:<在上面插入系统消息>
用户:问题:“”“尼尔·阿姆斯特朗最著名的事件是什么?它发生在什么日期?假定 UTC 时间。”””提交的答案:“”“1969 年 7 月 21 日,尼尔·阿姆斯特朗成为第二个走上这条路的人登月,继巴兹奥尔德林之后。""" 专家回答:"""尼尔阿姆斯特朗最著名的是他是第一个登上月球的人。这一历史性事件发生在 1969 年 7 月 21 日。"""
这是一个带有正确答案的示例输入,它还提供了比必要的更多的细节:
系统:<在上面插入系统消息>
用户:问题:“”“尼尔阿姆斯特朗最著名的事件是什么?它发生在什么日期?假定 UTC 时间。”“”提交的答案:“”“在 1969 年 7 月 21 日大约 02:56 UTC,尼尔阿姆斯特朗成为第一个人类踏上月球表面,标志着人类历史上的巨大成就。""" 专家解答:"""尼尔·阿姆斯特朗最著名的是他是第一个在月球上行走的人。这一历史性事件发生在 7 月 21 日, 1969."""
GPT各模型对比
openai接口
| 模型名称 | 资费(输入) | 资费(输出) | 字数上限 (含上下文) |
| gpt-3.5-turbo | $0.001 / K | $0.002 / k | 4K |
| gpt-3.5-turbo-0613 | $0.001 / K | $0.002 / k | 4K |
| gpt-3.5-turbo-1106 | $0.001 / K | $0.002 / k | 输入16K,输出4K |
| gpt-3.5-turbo-16k | $0.002 / k | $0.004 / k | 16K |
| gpt-3.5-turbo-16k-0613 | $0.002 / k | $0.004 / k | 16k |
| gpt-4 | $0.03 / k | $0.06 / k | 8K |
| gpt-4-0613 | $0.01 / k | $0.03 / k | 8K |
| gpt-4-1106-preview | $0.01 / K | $0.03 / k | 输入128k,输出4K |
| gpt-4-vision-preview | $0.01 / K | $0.03 / k | 输入128k,输出4K |
| gpt-4-32k | $0.01 / K | $0.12 / k | 32K |
| gpt-4-32k-0613 | $0.01 / K | $0.12 / k | 32K |
百度文心一言 注:1token 约等于 1个汉字 或者 1.3 个单词
| 模型名称 | 资费 |
| ERNIE-Bot | 0.012元/千tokens |
| ERNIE-Bot-turbo | 0.008元/千tokens |
| Llama-2-13B-Chat | 0.006元/千tokens |
| Llama-2-70B-Chat | 0.035元/千tokens |
| ChatGLM2-6B-32K | 0.004元/千tokens |
| ERNIE-Bot-4 | 0.12元/千tokens |
讯飞星火 1tokens 约等于1.5个中文汉字 或者 0.8个英文单词
| 服务引擎 | 单价 |
| 讯飞星火认知大模型V1.5 | 0.018元/千tokens |
| 讯飞星火认知大模型V2.0 | 0.036元/千tokens |
| 讯飞星火认知大模型V3.0 | 0.036元/千tokens |
通义千问 1token约等于1个中文汉字 或者 3至4个英文字母
| 模型名称 | 单价 |
| qwen-turbo | 0.008元/千tokens |
| qwen-plus | 0.02元/千tokens |
腾讯混元 1token 约等于1.8个中文汉字或3个英文字母
| 模型名称 | 单价 |
| 腾讯混元大模型标准版 | 0.01元 / 千tokens |
| 腾讯混元大模型高级版 | 0.1元 / 千tokens |
| 腾讯混元-Embedding | 0.0007元 / 千tokens |
通义千问 1token 约等于1.8个中文汉字或3个英文字母
| 模型名称 | 单价 |
| qwen-turbo | 0.008元 / 千tokens |
| qwen-plus | 0.02元 / 千tokens |
| qwen-max | 限时免费 |
| qwen-max-1201 | |
| qwen-max-longcontext |
智谱AI 1token 约等于1.8个中文汉字
| 模型 | 说明 | 上下文长度 | 单价 |
| GLM-4 | 提供了更强大的问答和文本生成能力。适合于复杂的对话交互和深度内容创作设计的场景。 | 128K | 0.1元 / 千tokens |
| GLM-3-Turbo | 适用于对知识量、推理能力、创造力要求较高的场景,比如广告文案、小说写作、知识类写作、代码生成等。 | 128K | 0.005元/千tokens |
MINIMAX 1000个token约对应750个字符文本(包括标点等字符)
| 模型名称 | 单价 |
| abab6 | 0.2元/千tokens |
| abab5.5 | 0.015元/千tokens |
| abab5.5s | 0.005元/千tokens |
Claude2
| 模型名称 | 单价(输入) | 单价(输出) |
| claude-1 | $0.0008/千tokens | $0.0024/千tokens |
| claude-2 | $0.008/千tokens | $0.024/千tokens |
| Claude 3 Opus | $0.015/千tokens | $0.075/千tokens |
| Claude 3 Sonnet | $0.003/千tokens | $0.015/千tokens |
| Claude 3 Haiku | $0.00025/千tokens | $0.00125/千tokens |
Gemini
| 模型名称 | 价格 |
| gemini-pro | 免费中 |
灵犀接口 计费规则与openai一致 api2d接口 最新价格请去他们官网查看
如何配置ai通道
1、首先进入站点后台选择ai通道
路径:系统-系统配置-AI参数配置
勾选想选择使用的ai通道(可多选,多选之后可以在前端选择接口使用)
勾选完要点保存
2、配置ai通道
路径:系统-ai通道
设置上一步已经勾选的ai通道
3、配置key
路径:系统-key池
进入key池之后把准备好的key放到对应名称的key池里、
自定义皮肤制作教程
PC版皮肤文件在: /public/static/skin/web
结构如下:
- web
-
- default(默认皮肤)
-
-
- config.json(配置文件)
- dark.css(夜间模式样式)
- light.css(日间模式样式)
- thumb.png(后台预览图)
-
-
- skin_02(皮肤2)
- skin_03(皮肤3)
- skin_04(皮肤4)
- ……
制作自定义皮肤步骤:
1、复制一份其它皮肤文件夹,并重命名(命名随意,但一定不要带“skin_”前缀,以免后边系统发布新的皮肤将你的皮肤覆盖)。里边包含以下四个文件:
config.json(配置文件,内容参考其他皮肤)
dark.css(夜间模式样式)
light.css(日间模式样式)
thumb.png(后台预览图)
PS:每个皮肤都是以上四个文件
2、在dark.css、light.css两个css文件里写你的css样式
3、从后台切换到这个皮肤,预览效果。
微信小程序AI类目添加指南
《微信小程序AI类目添加指南》
基于文心大模型开发的应用在应用商店/微信小程序上架指南 - 百度智能云千帆社区
MiniMax配置教程
首先登录MiniMax控制台:api.minimax.chat
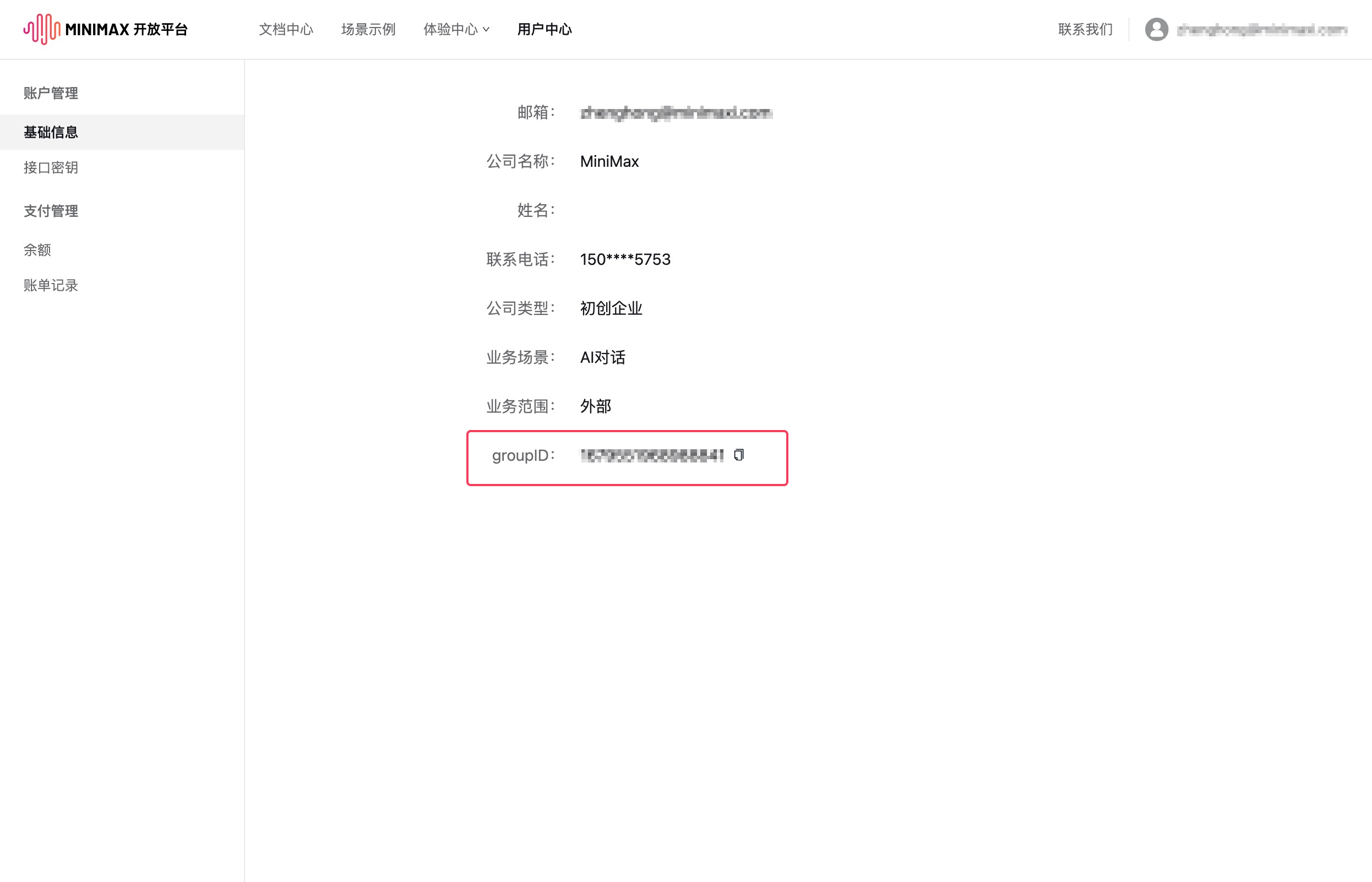
1、在【基础信息】获取group_id
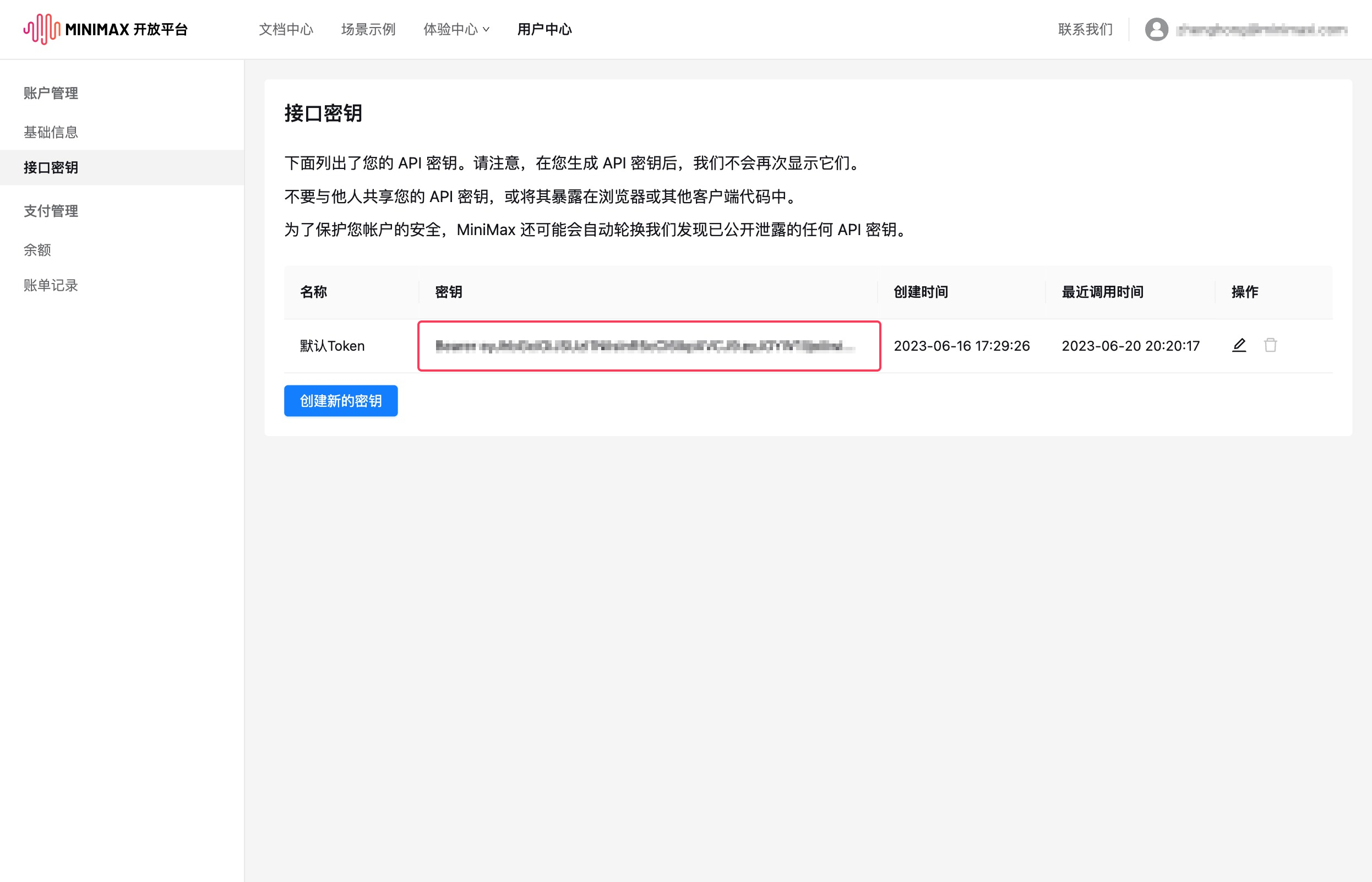
2、在【接口秘钥】获取 api key
3、将groupid和apikey填到后台key池。
Azure OpenAI申请和使用教程
一、申请使用Azure OpenAI服务 1、访问微软Azure平台进行申请:立即创建 Azure 免费帐户 | Microsoft Azure,如果有微软账号直接登录,没有则注册一个。

2、申请OpenAI API接口权限。 在Azure登录后,搜索关键词“OpenAI”,进入Azure OpenAI页面,在底部点击“创建Azure OpenAI”。
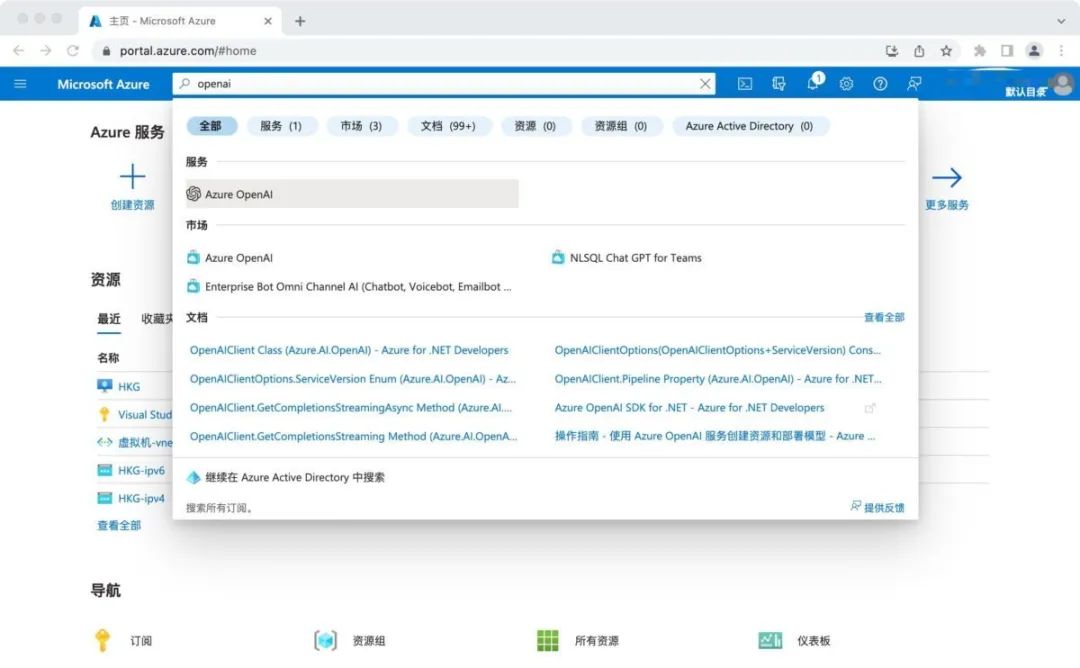
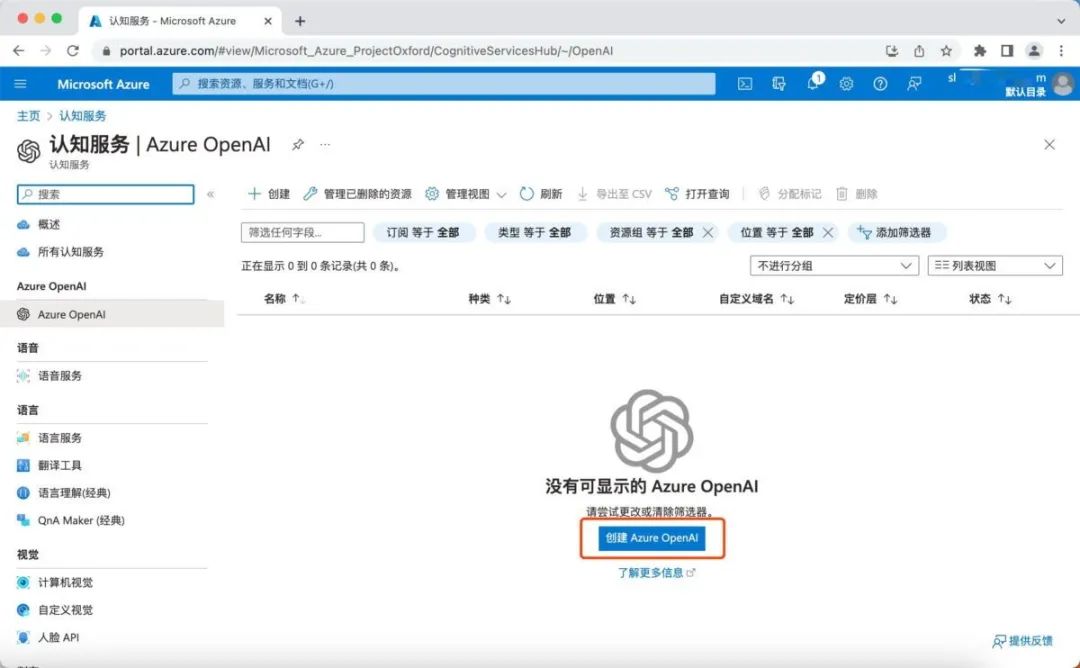
在此页面中,选择你的订阅(通常为免费试用订阅),然后创建一个名为“OpenAI”的资源组,当然你也可以命名为其它名字
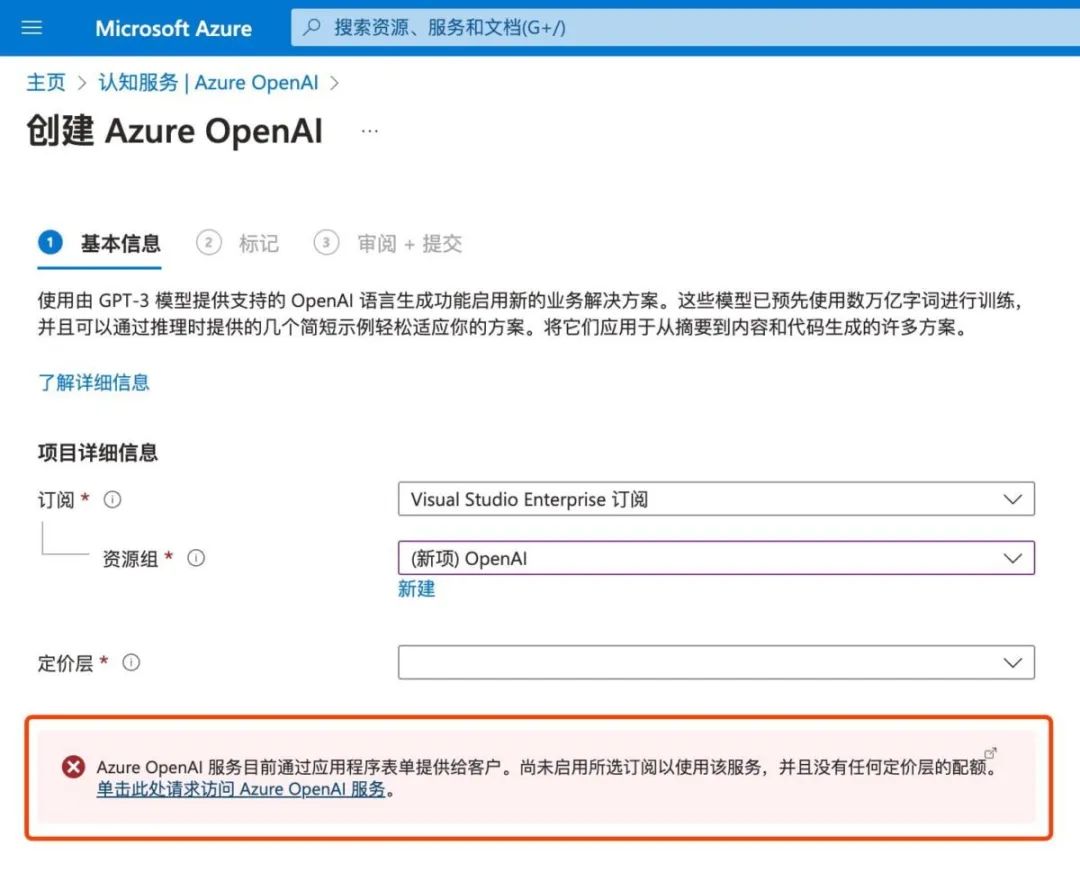
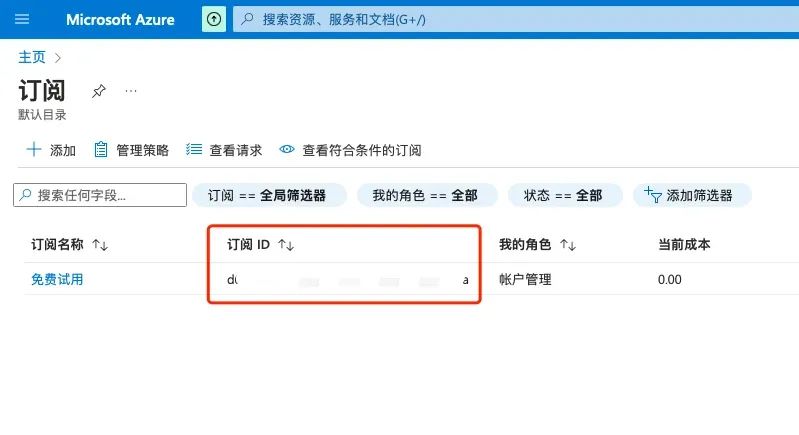
接着,点击红框位置申请,填写一个多达25道题的问卷,需要提供准确的订阅ID和公司信息。订阅ID不是目录ID(租户ID),在顶部搜索”订阅“,在打开的页面把订阅ID复制到问卷,具体请参考下图
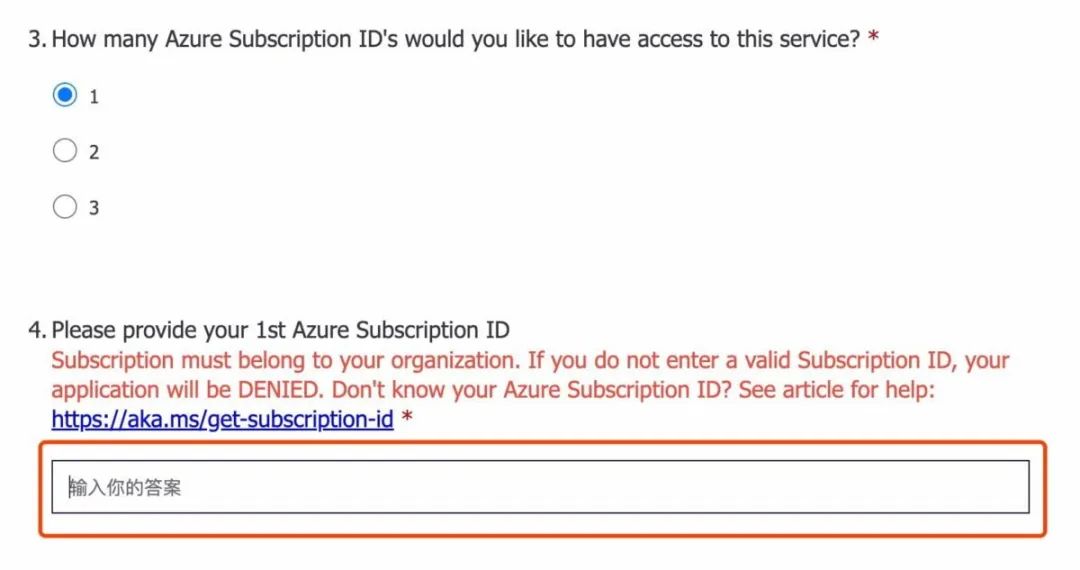
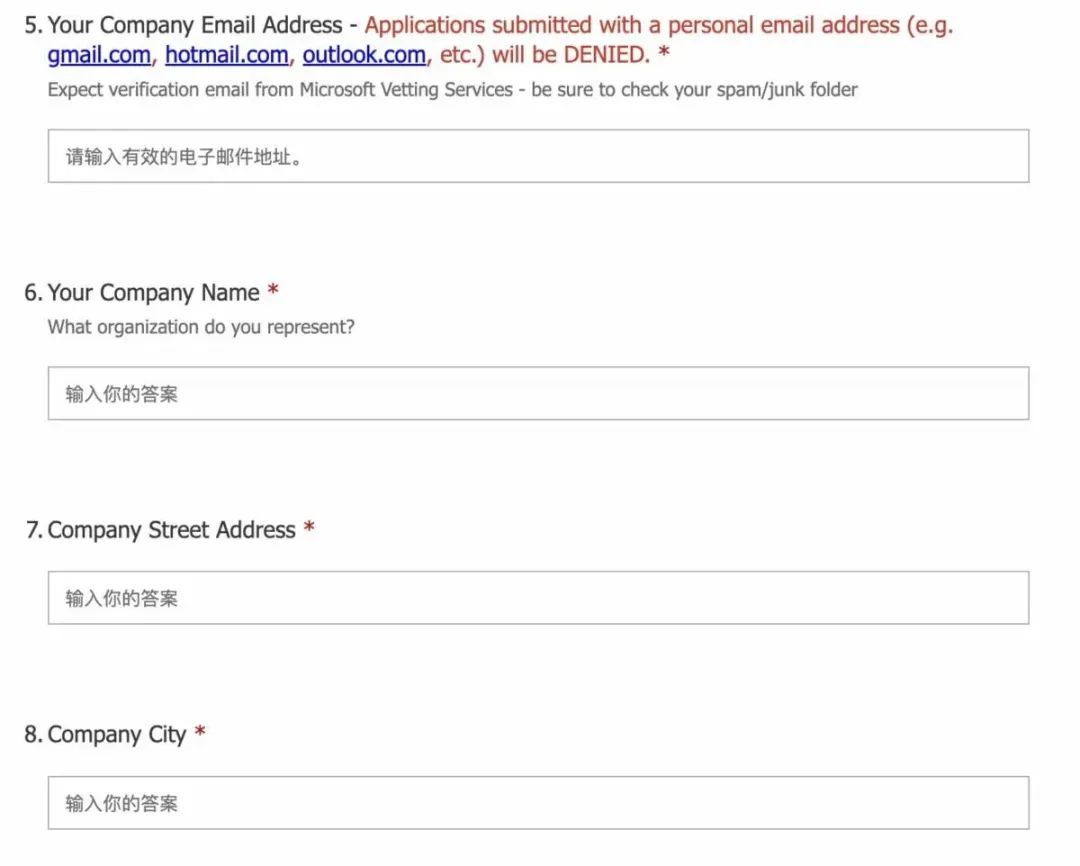
请注意,OpenAI只面向企业服务,因此需要填写公司信息和公司邮箱,而非私人邮箱。
申请完成后,等待审核,通常需要2-10天不等。审核通过后,你会收到一封验证邮件,复制链接到浏览器进行验证。通过验证后,你就获得了API接口权限,可以开始进行下一步配置。 二、配置Azure OpenAI 打开这个页面:Microsoft Azure 进入 Azure 后,直接搜索OpenAI

若是已经通过,这里即可选择订阅,否则会在下方提示让你申请
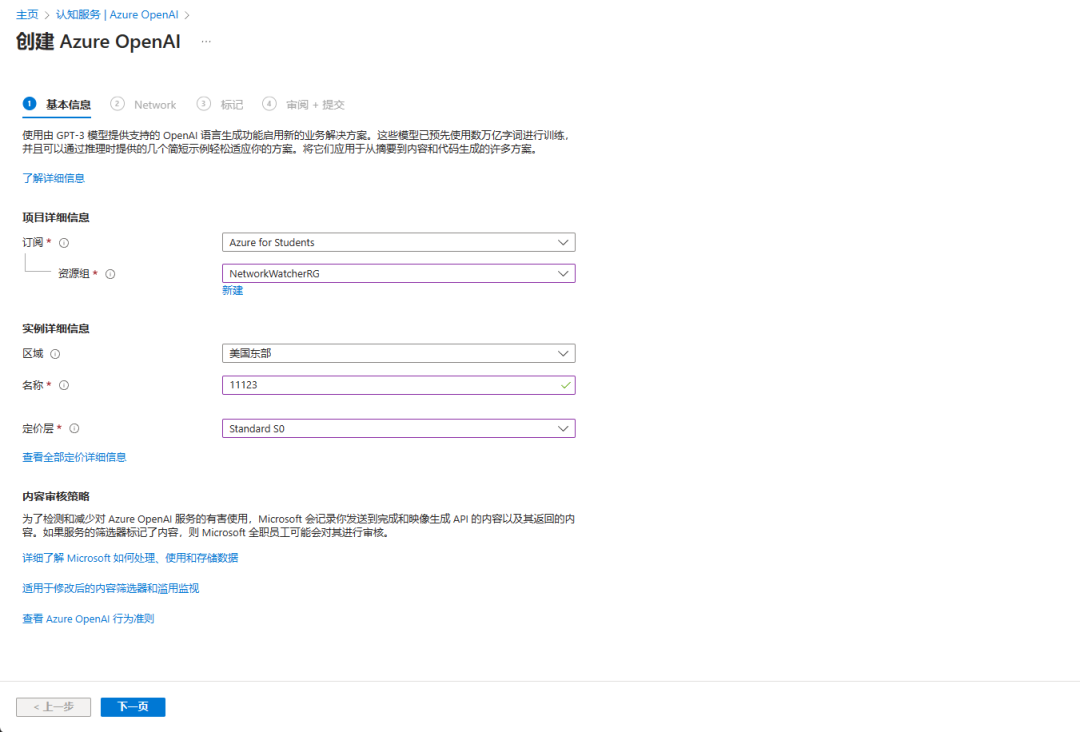
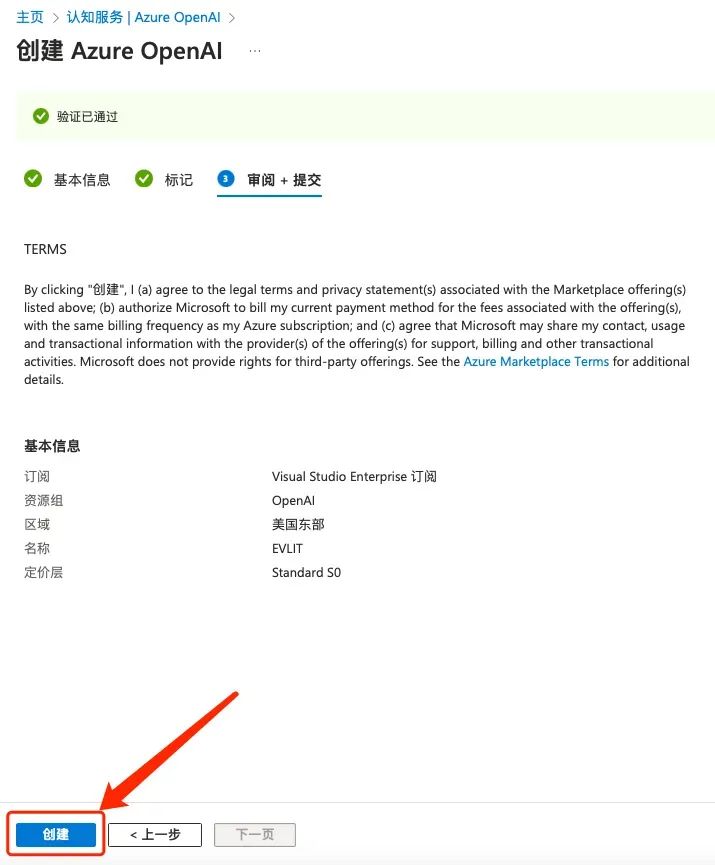
选完订阅、资源组,再选择好区域、名称、定价层(没有则去建一个),直接下一步就好了。
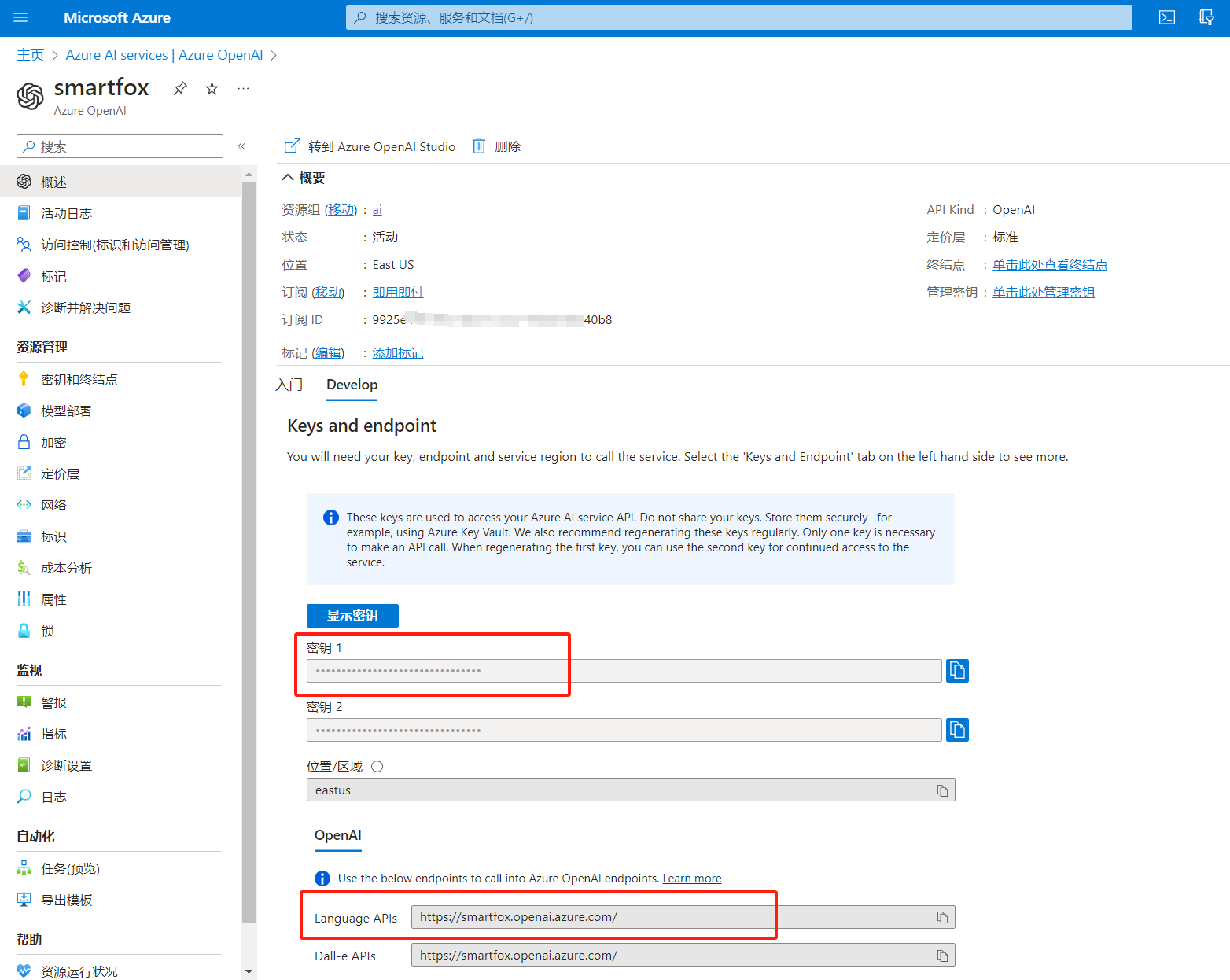
三、配置API参数到后台 1、将下图所示的 密钥1 和 Language APIs地址 填到后台key池
2、部署资源
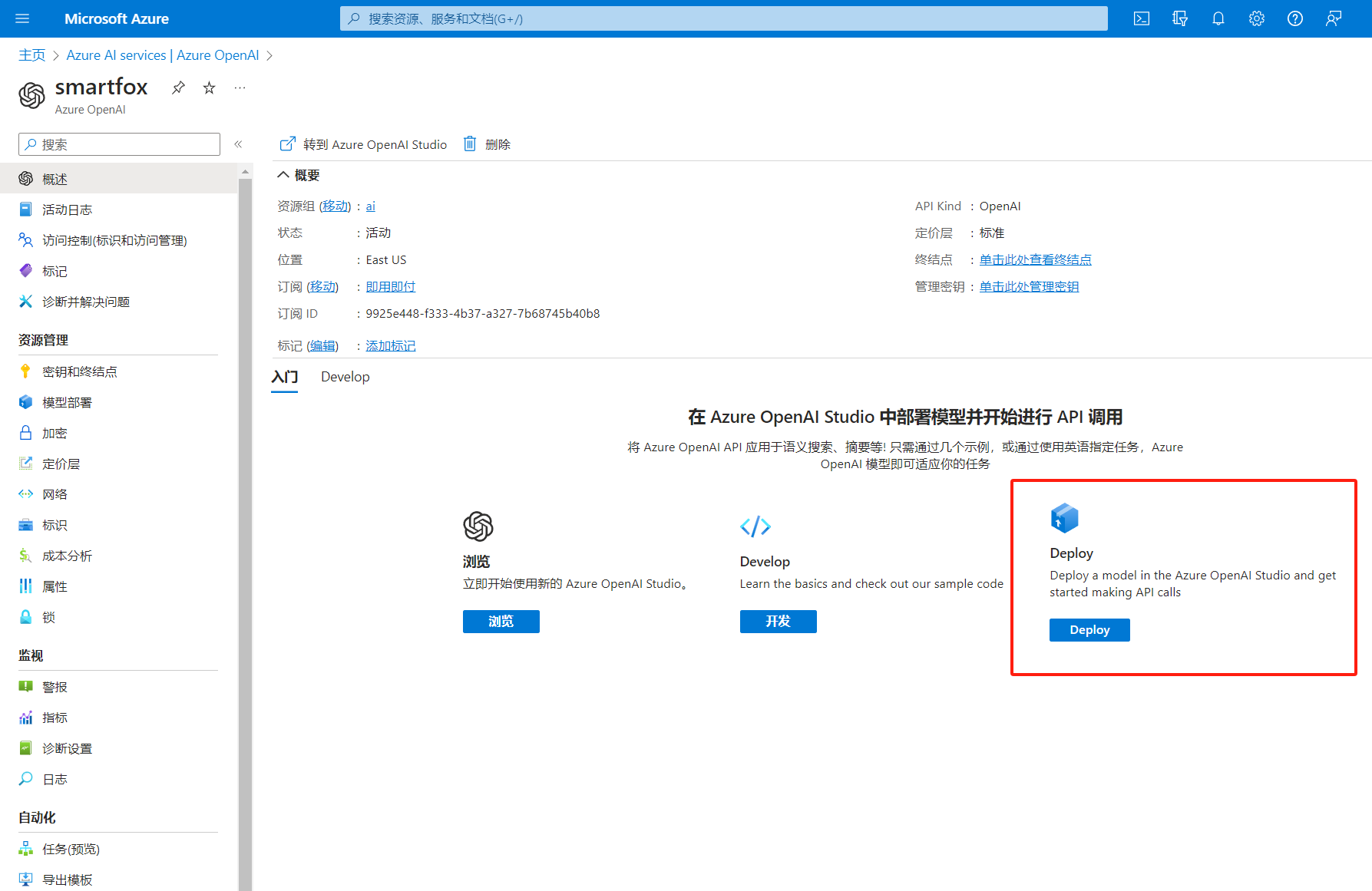
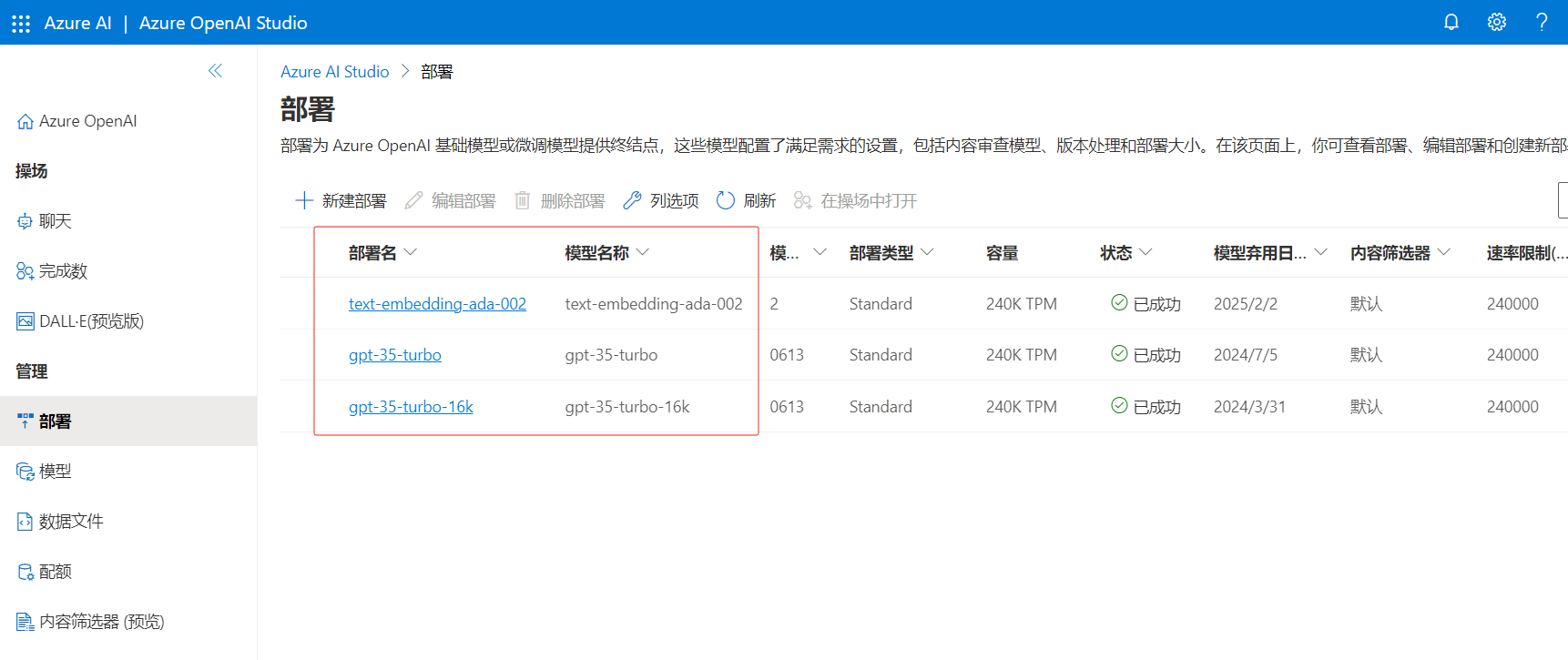
新建如下图所示三个部署。 部署名称和模型名称要一模一样,注意,很重要,名称要一模一样。 如果有GPT-4权限,也将GPT-4部署一下
腾讯混元申请和使用教程
腾讯混元管理地址:登录 - 腾讯云
1、登录后申请开通,申请审核通过后将会通过短信、邮箱和站内信通知您(预计5-15天)。
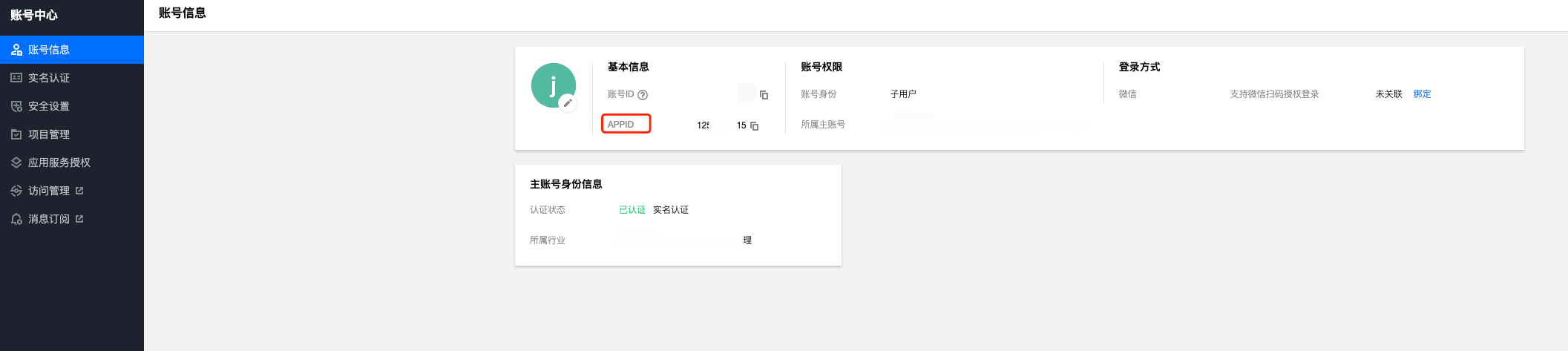
2.、在账号中心 > 账号信息获取 APPID。
3、在访问管理 > 访问密钥 > API 密钥管理获取 SecretId、SecretKey。
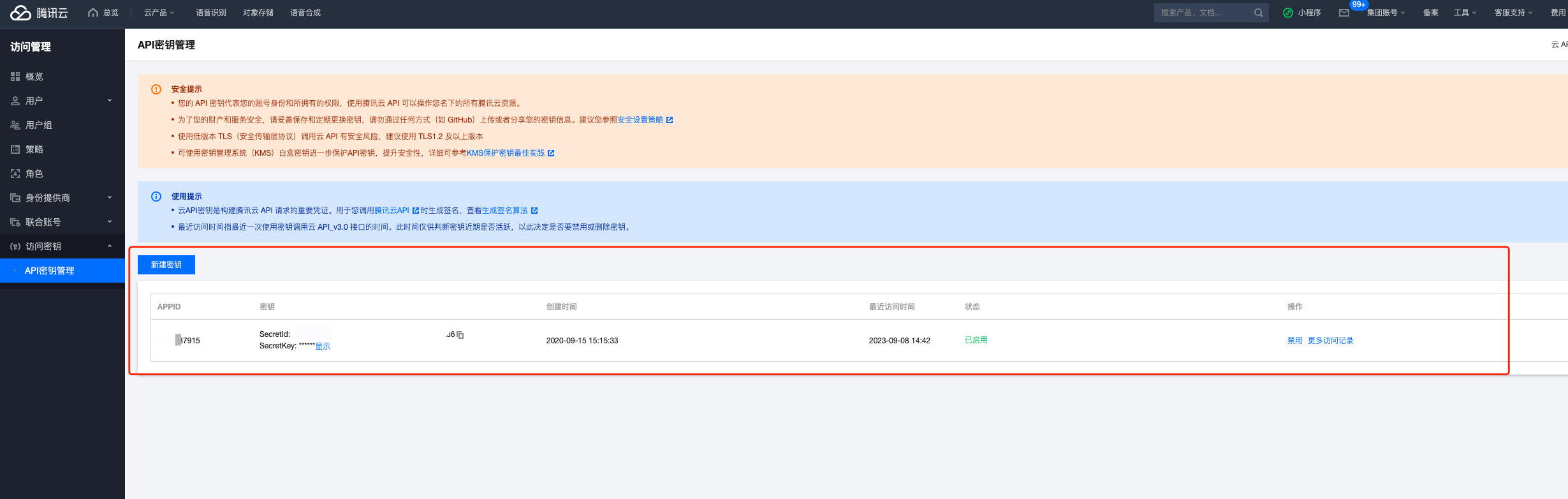
4、将APPID、SecretId、SecretKey填到后台key池。
阿里通义千问教程
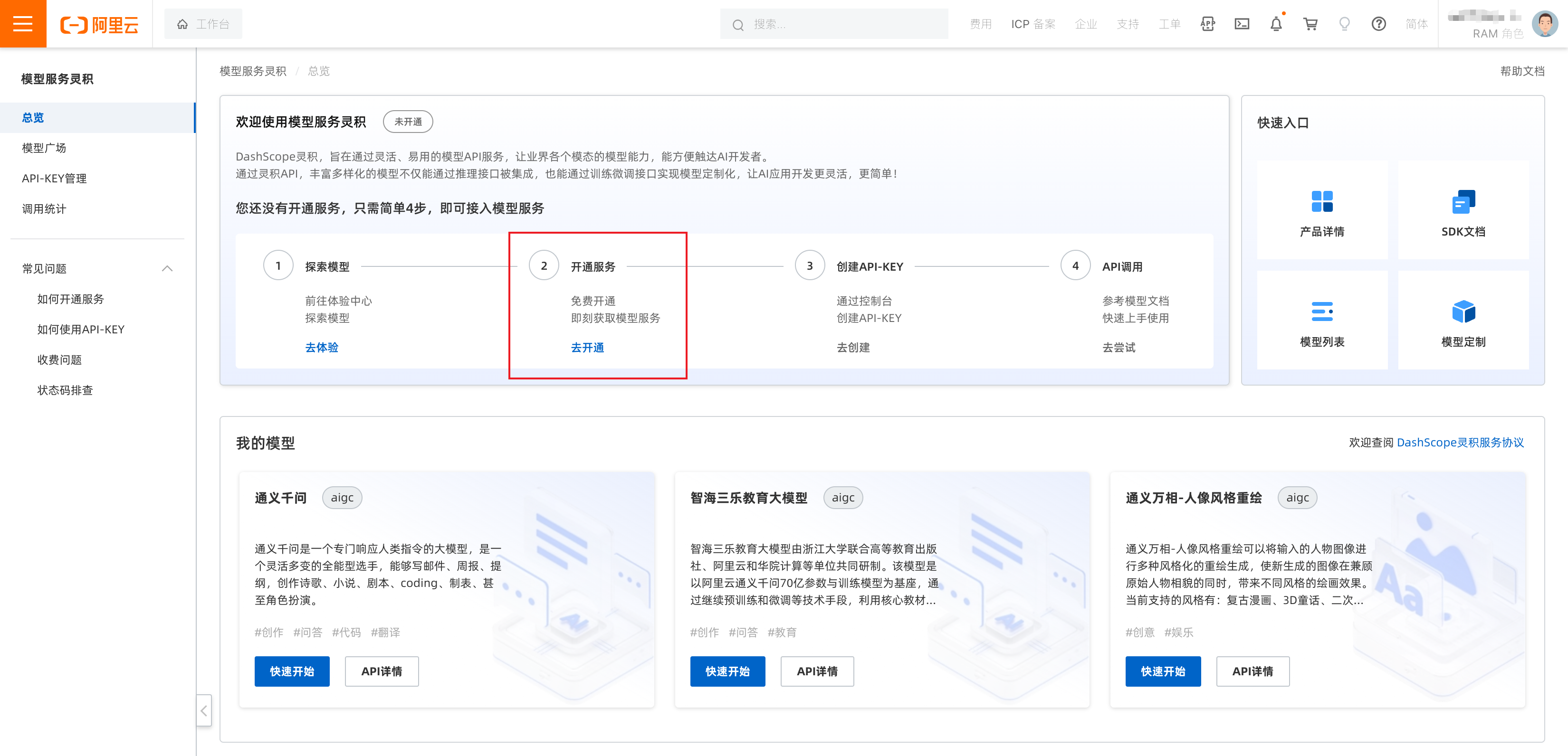
一、开通DashScope
访问DashScope控制台:https://dashscope.console.aliyun.com/overview

在“开通服务”项下,点击“去开通”。
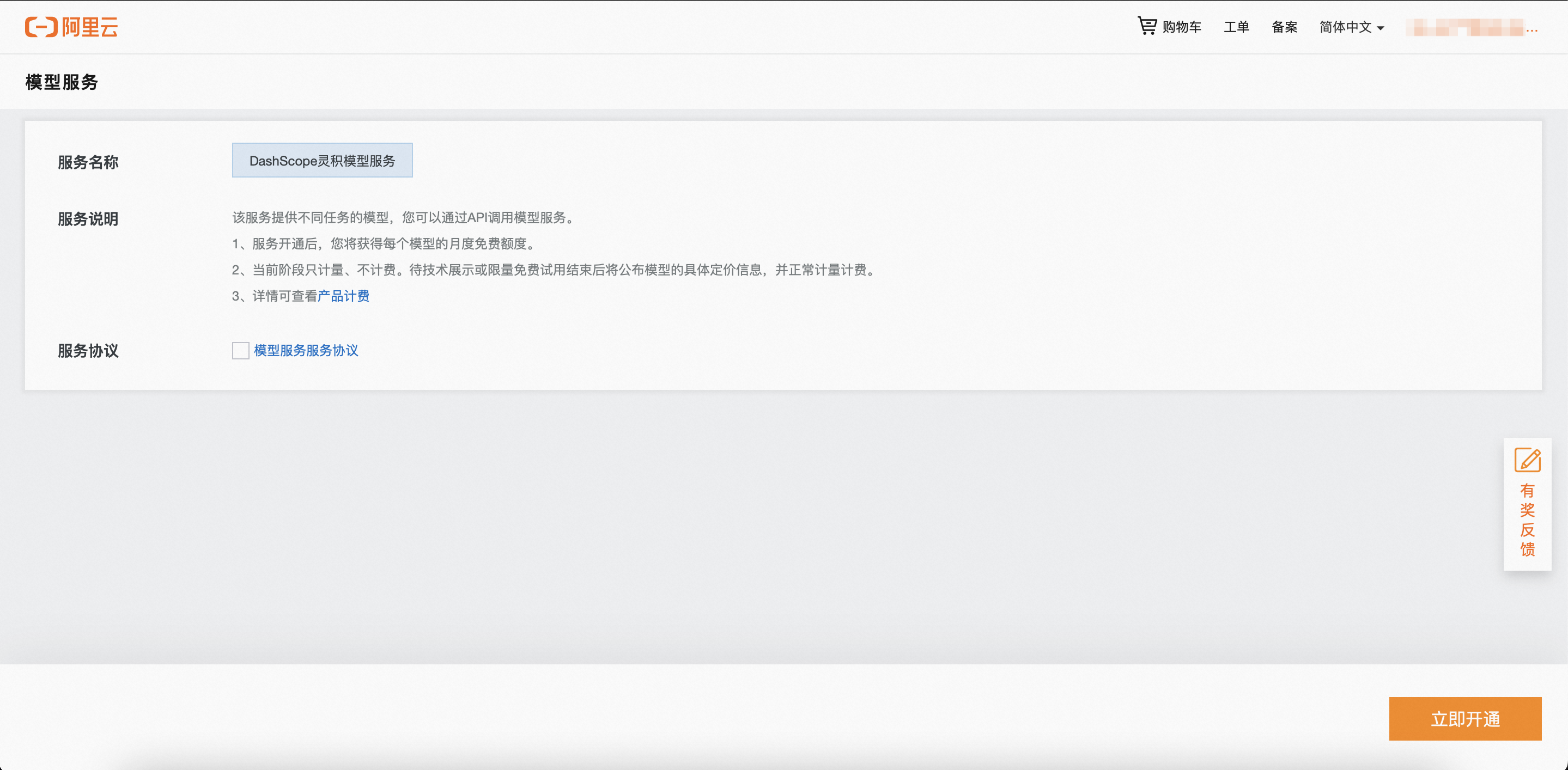
阅读服务协议,确认无误后点击“立即开通”。
二、创建API-KEY
1、访问DashScope管理控制台API-KEY管理页面:前往API-KEY管理,然后点击“创建新的API-KEY”。
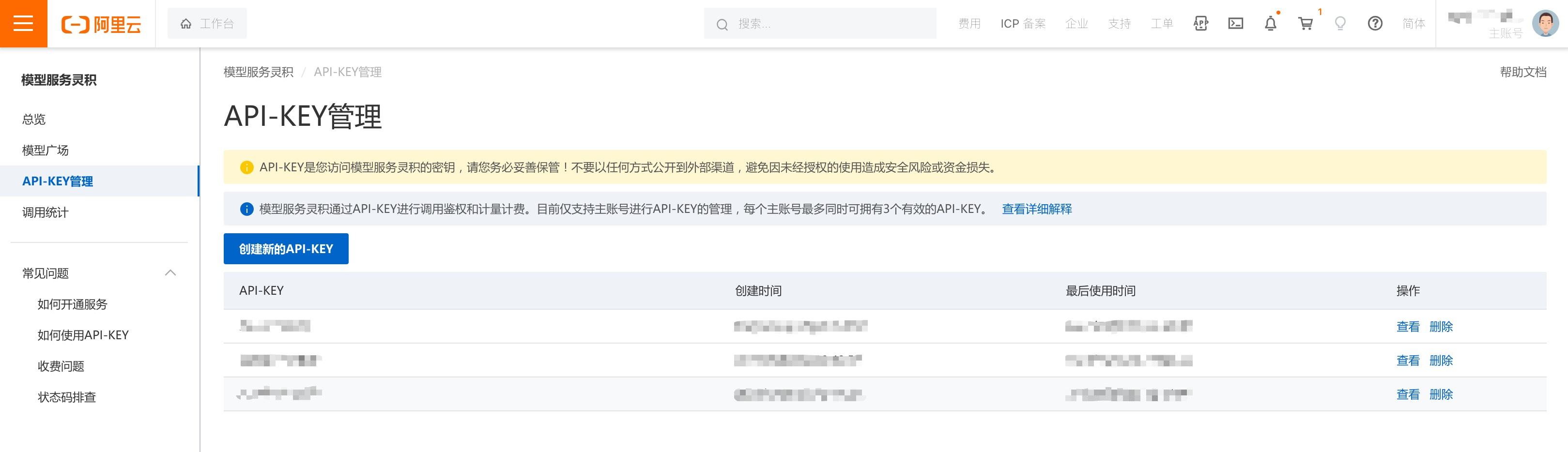
2、点击“创建新的API-KEY”后,系统会创建生成API-KEY,并在弹出的对话框中展示,此处客户可以点击复制按钮将API-KEY的内容复制保存。
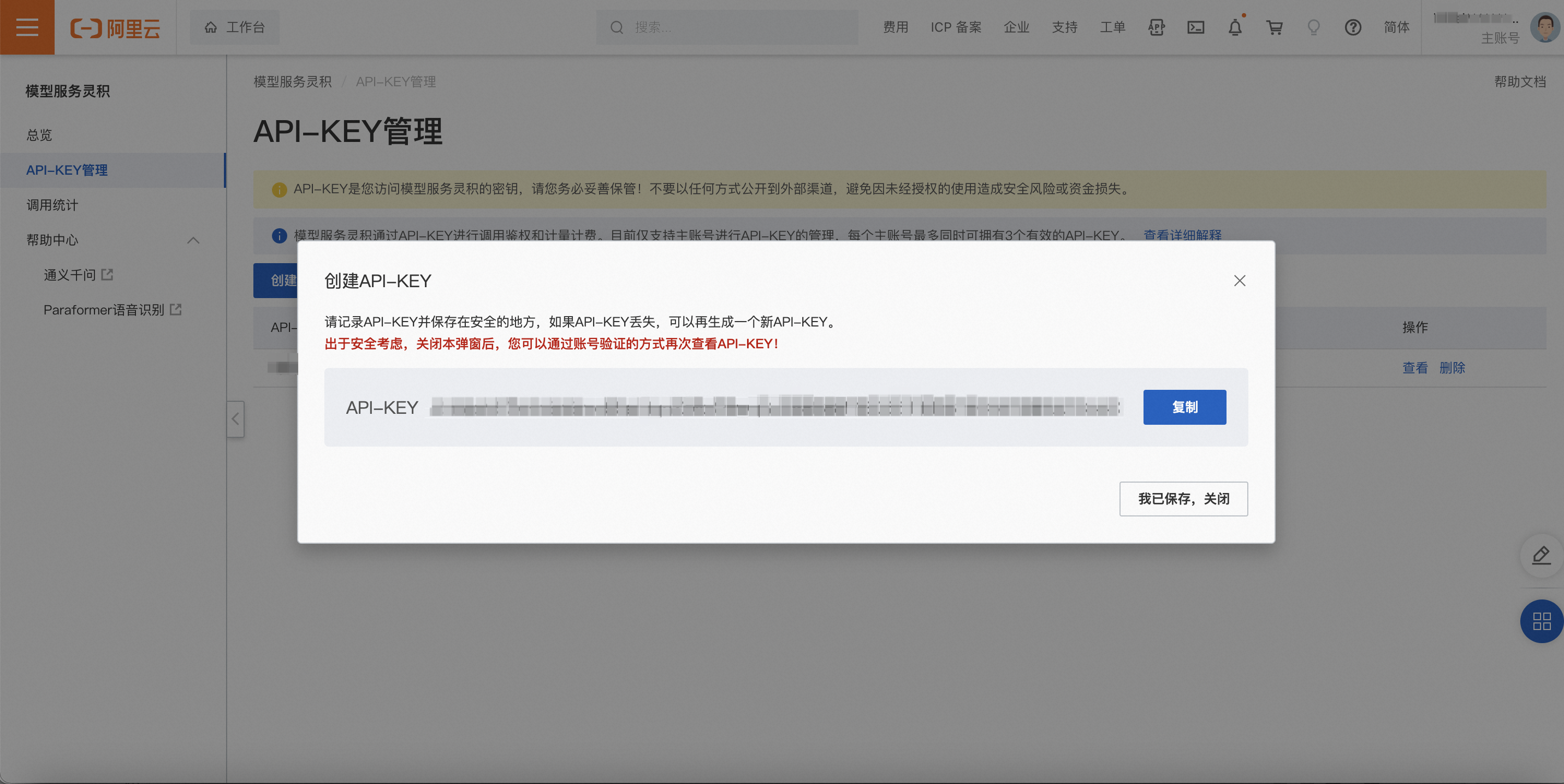
3、将上面获取到的API-KEY填到后台key池。
常见问题整理(编写中...)
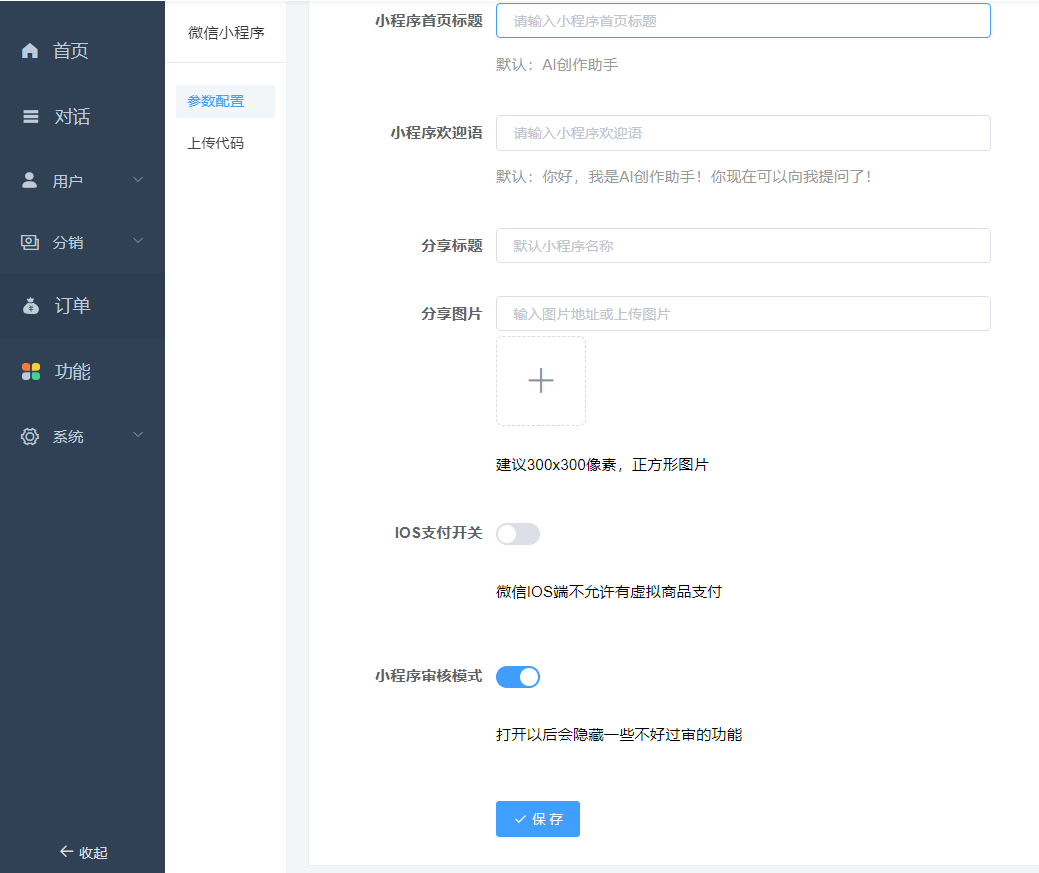
1、提交小程序审核失败 参数配置:ios开关关闭、审核模式打开、点击保存。
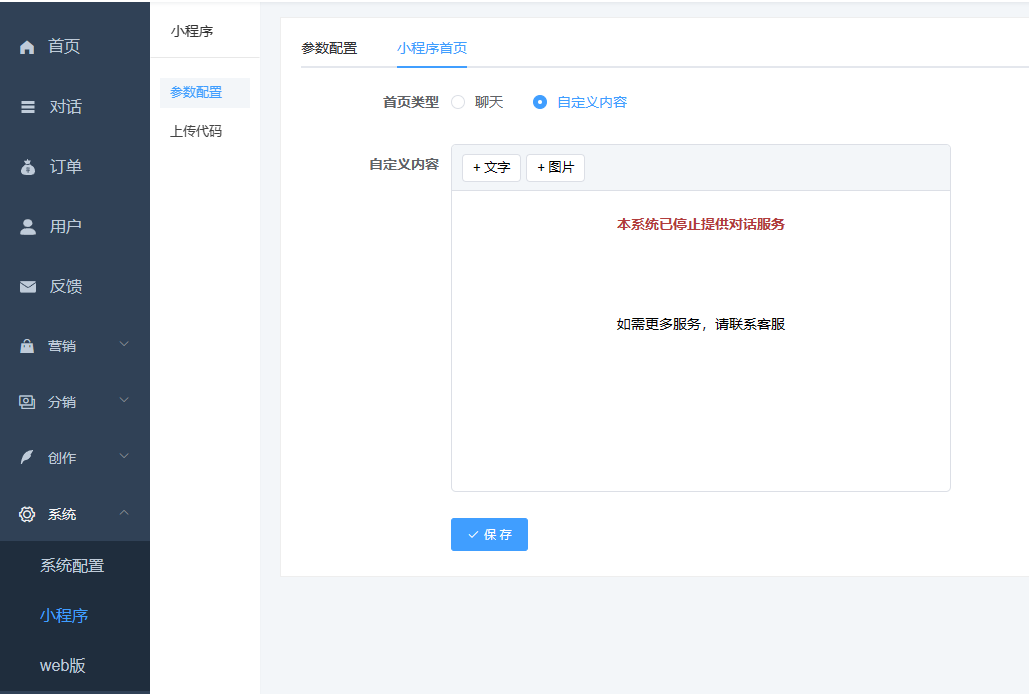
小程序首页 选择自定义首页;添加自定义图片或文字(两者都加也可)建议填写公司介绍和图片;点击保存。
注意:需先配置支付参数、AI参数,否则小程序会因为功能不正常而驳回审核
2、web站点打不开404错误 查看站点后台web站点开关是否打开

3、web打开出现500错误

查看web站点参数是否配置,配置是否正确,公众号服务器配置完成之后是否启用。
4、小程序打开报错'redirect_url域名与后台配置不一致' 登陆公众号后台查看公众号是否配置了网页授权域名 路径:开发→接口权限→网页授权

注意:添加网页授权域名需要下载的文件放在在运行目录public下,文件名称不要更改。

5、小程序上传代码出现下面错误 上传密钥错误,重新下载小程序代码上传密钥,文本打开全部复制到此处。