
- 1git/github学习笔记-阅读笔记二_error: unable to create '/home/stormyjack/recon/de
- 2一、环境准备(Python、Anaconda、Git)最新版安装教程_anaconda git
- 3裁员?内卷?拿不到offer?这份阿里高工整理的Java核心知识点一定能帮到你!_精通java核心
- 4【DL】循环神经网络RNN、长短期记忆网络LSTM、门控循环单元网络GRU_循环神经网络(rnn),长短期记忆网络(lstm),门控循环单元(gru)网络结构
- 5GitHubDesktop:学习:三:(第一次操作)GitHubDesktop进行创建分支+合并分支:成功_github桌面版怎么合并分支
- 6基于蚁群算法的二维路径规划算法_基于蚁群算法的路径规划
- 7iPhone真机运行App提示“不再可用“(No Longer Available)的原因及解决_app is no longer available
- 8命名实体识别(NER)_命名实体识别ner
- 9python中复数用法_Python中的复数?
- 10数据结构 单链表 C语言实现_数据结构单链表c语言
大数据技术原理与应用-林子雨课后(部分习题答案)_大数据技术原理与应用第三版课后答案
赞
踩
第一章
2.试述数据产生经历的几个阶段
答:3个阶段
1.运营式系统阶段
人类社会最早大规模管理和使用数据,是从数据库的诞生开始的。大型零售超市销售系统、银行交韩系统、股市交易系统、医院医疗系统、企业客户管理系统等大量运营式系统,都是建立在数据库基础之上的,数据库中保存了大量结构化的企业关键信息,用来满足企业各种业务需求,在这个阶段,数据的产生方式是被动的,只有当实际的企业业务发生时,才会产生新的记录并存人数据库。比如,对于股市交易系统而言,只有当发生一笔股票交易时,才会有相关记录生成。
2. 用户原创内容阶段
互联网的出现,使得数据传播更加快捷,不需要借助于磁盘、磁带等物理存储介质传播数据,网页的出现进一步加速了大量网络内容的产生,从而使得人类社会数据量开始呈现“井喷式”增长。但是,互联网真正的数据爆发产生于以“用户原创内容"为特征的Web 2.0时代。Web 1.0时代主要以门户网站为代表,强调内容的组织与提供,大量上网用户本身并不参与内容的产生。而Web 2.0技术以Wiki.博客、微博、微信等自服务模式为主,强调自服务,大量上网用户本身就是内容的生成者,尤其是随着移动互联网和智能手机终端的普及,人们更是可以随时随地使用手机发微博、传照片,数据量开始急剧增加。
3.感知式系统阶段
物联网的发展最终导致了人类社会数据量的第三次跃升。 物联网中包含大量传感器,如温度作感烈。福度传感器、压力传感器、位移传感器、光电传感器等, 此外, 视频监控摄像头也是物联网的重要组成部分,物联网中的这些设备, 每时每刻都在自动产生大量数据,与Web 2.0时代数据,使得人类社会迅速步人“大数据时代”。的人工教据产生方式相比,物联网中的自动数据产生方式,将在超时间内生成更密集、更大量的数据,使得人类社会迅速进入“大数据时代”。
3.试述大数据的4个基本特征
答:数据量大、数据类型繁多、处理速度快和价值密度低。
5.数据研究经历了哪4个阶段?
答:人类自古以来在科学研究上先后历经了实验、理论、计算、和数据四种范式。
8.举例说明大数据的基本应用
答:
领域:大数据的应用
金融行业:大数据在高频交易、社区情绪分析和信贷风险分析三大金融创新领域发挥重要作用。
汽车行业:利用大数据和物联网技术的五人驾驶汽车,在不远的未来将走进我们的日常生活
互联网行业:借助于大数据技术,可以分析客户行为,进行商品推荐和有针对性广告投放
个人生活:大数据还可以应用于个人生活,利用与每个人相关联的“个人大数据”,分析个人生活行为习惯,为其提供更加周全的个性化服务。
9.举例说明大数据的关键技术
答:批处理计算,流计算,图计算,查询分析计算
11.定义并解释以下术语:云计算、物联网
答:
云计算:
云计算就是实现了通过网络提供可伸缩的、廉价的分布式计算机能力,用户只需要在具备网络接入条件的地方,就可以随时随地获得所需的各种IT资源。
物联网:
物物相连的互联网,是互联网的延伸,它利用局部网络或互联网等通信技术把传感器、控制器、机器、人类和物等通过新的方式连在一起,形成人与物、物与物相连,实现信息化和远程管理控制。
12.详细阐述大数据、云计算和物联网三者之间的区别与联系。
答:
大数据、云计算和物联网的区别:
大数据侧重于海量数据的存储、处理与分析,海量数据中发现价值,服务于生产和生活;云计算本质上皆在整合和优化各种IT资源并通过网络已服务的方法,廉价地提供给用户;物联网的发展目标是实现物物相连,应用创新是物联网的核心
大数据、云计算和物联网的联系:
从整体来看,大数据、云计算和物联网这三者是相辅相成的。大数据根植于云计算,大数据分析的很多技术都来自于云计算,云计算的分布式存储和管理系统提供了海量数据的存储和管理能力,没有这些云计算技术作为支撑,大数据分析就无从谈起。物联网的传感器源源不断的产生大量数据,构成了大数据的重要数据来源,物联网需要借助于云计算和大数据技术,实现物联网大数据的存储、分析和处理。
第二章
1.试述hadoop和谷歌的mapreduce、gfs等技术之间的关系
答:Hadoop的核心是分布式文件系统HDFS和MapReduce,HDFS是谷歌文件系统GFS的开源实现,MapReduces是针对谷歌MapReduce的开源实现。
2.试述Hadoop具有哪些特性。
答:高可靠性,高效性,高可扩展性,高容错性,成本低,运行在Linux平台,支持多种编程语言
4.试述Hadoop的项目结构以及每个部分的具体功能。
答:
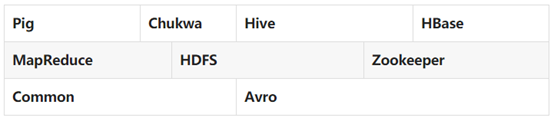
Commeon是为Hadoop其他子项目提供支持的常用工具,主要包括文件系统、RPC和串行化库。
Avro是为Hadoop的子项目,用于数据序列化的系统,提供了丰富的数据结构类型、快速可压缩的二进制数据格式、存储持续性数据的文件集、远程调用的功能和简单的动态语言集成功能。
HDFS是Hadoop项目的两个核心之一,它是针对谷歌文件系统的开源实现。
HBase是一个提高可靠性、高性能、可伸缩、实时读写、分布式的列式数据库,一般采用HDFS作为其底层数据存储。
MapReduce是针对谷歌MapReduce的开源实现,用于大规模数据集的并行运算。
Zoookepper是针对谷歌Chubby的一个开源实现,是高效和可靠的协同工作系统,提供分布式锁之类的基本服务,用于构建分布式应用,减轻分布式应用程序所承担的协调任务。
Hive是一个基于Hadoop的数据仓库工具,可以用于对Hadoop文件中的数据集进行数据整理、特殊查询和分布存储。
Pig是一种数据流语言和运行环境,适合于使用Hadoop和MapReducce平台上查询大型半结构化数据集。
Sqoop可以改进数据的互操作性,主要用来在hadoop配合关系数据库之间交换数据。
Chukwa是一个开源的、用于监控大型分布式系统的数据收集系统,可以将各种类型的数据收集成适合Hadoop处理的文件,并保存在HDFS中供Hadoop进行各种 MapReduce操作。
5.配置Hadoop时,java的路径JAVA_HOME是在哪一个配置文件中进行设置的
答:
hadoop目录下的etc/hadoop/hadoop-env.sh文件
6.所有节点的HDFS路径是通过fs.default.name来设置的,请问他是在哪个配置文件中设置的
答:core-site.xml
8.Hadoop伪分布式运行启动后所具有的进程都有哪些?
答:
1)NameNode它是hadoop中的主服务器,管理文件系统名称空间和对集群中存储的文件的访问,保存有metadate。
2)SecondaryNameNode它不是namenode的冗余守护进程,而是提供周期检查点和清理任务。帮助NN合并editslog,减少NN启动时间。
3)DataNode它负责管理连接到节点的存储(一个集群中可以有多个节点)。每个存储数据的节点运行一个datanode守护进程。
4)ResourceManager(JobTracker)JobTracker负责调度DataNode上的工作。每个DataNode有一个TaskTracker,它们执行实际工作。
5)NodeManager(TaskTracker)执行任务
6)DFSZKFailoverController高可用时它负责监控NN的状态,并及时的把状态信息写入ZK。它通过一个独立线程周期性的调用NN上的一个特定接口来获取NN的健康状态。FC也有选择谁作为Active NN的权利,因为最多只有两个节点,目前选择策略还比较简单(先到先得,轮换)。
7)JournalNode 高可用情况下存放namenode的editlog文件
第三章
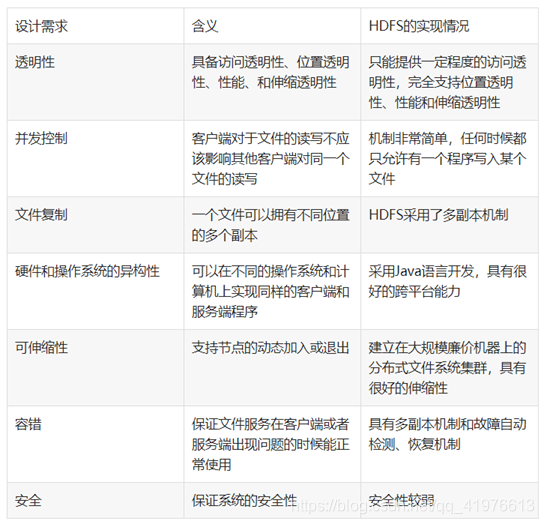
1.试述分布式文件系统设计的需求。
答:
4.试述HDFS中的名称节点和数据节点的具体功能。
答:
名称节点负责管理分布式文件系统系统的命名空间,记录分布式文件系统中的每个文件中各个块所在的数据节点的位置信息;
数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并向名称节点定期发送自己所存储的块的列表。
hadoop fs -ls
hadoop fs -cat
hadoop fs -mkdir
hadoop fs -get [-ignorecrc] [-crc] 复制指定的文件到本地文件系统指定的文件或文件夹。-ignorecrc选项复制CRC校验失败的文件。使用-crc选项复制文件以及CRC信息。
hadoop fs -put 从本地文件系统中复制指定的单个或多个源文件到指定的目标文件系统中。也支持从标准输入(stdin)中读取输入写入目标文件系统。
hadoop fs -rmr
6.HDFS只设置唯一一个名称节点,在简化系统设计的同时也带来了一些明显的局限性,请阐述局限性具体表现在那些方面。
答:
(1) 命名空间的限制:名称节点是保存在内存中的,因此,名称节点能够容纳的
对象(文件、块)的个数会受到内存空间大小的限制。
(2) 性能的瓶颈:整个分布式文件系统的吞吐量,受限于单个名称节点的吞吐量。
(3) 隔离问题:由于集群中只有一个名称节点,只有一个命名空间,因此,无法
对不同应用程序进行隔离。
(4) 集群的可用性:一旦这个唯一的名称节点发生故障,会导致整个集群变得不
可用。
7.试述HDFS的冗余数据保存策略。
答:
1).第一个副本:放置在上传文件的数据节点;如果是集群外提交,则随机挑选一台磁盘不太满、CPU不太忙的节点
2).第二个副本:放置在与第一个副本不同的机架的节点上
3).第三个副本:与第一个副本相同机架的其他节点上
4).更多副本:随机节点
9.试述HDFS是如何探测错误发生以及如何进行恢复的。
答:
- 名称节点出错
名称节点保存了所有的元数据信息,其中最核心的两大数据结构是Fslmage和EilLog,如果这两个文作发生根坏 那么管↑HOPS实例将失效Hap采用两种机制来确保名整节点的安全单门,把不称节点上的元数据信息同步存储到其他文件系统( 比如远程挂载的网络文件系统NFS)中:第二,运行 个第二名称节点,当名称节点宕机以后,可以把第名称节点作为一 种弥补措场利用站名称节点中的元数据信息进行系统恢复, 但是从前面对第二名称节点的介绍中可以看出,这样做仍然会丢失部分数据。因此,一般会把 上述两种方式结合使用,当名称节点发生宕机时首先到远程挂载的网络文件系统中获取备份的元数据信息,放到第二名称节点上进行恢复,并把第二名称节点作为名称节点来使用。
2.数据节点出错
每个数据节点会定期向名称节点发送“心跳”信息,向名称节点报告自己的状态。当数据节点发生故障,或者网络发生断网时,名称节点就无法收到来自一些数据节点的“心跳”信息,这时这些数据节点就会被标记为“宕机”,节点上面的所有数据都会被标记为“不可读”,名称节点不会再给它们发送任何IO请求。这时,有可能出现一种情形,即由于一些数据节点的不可用,会导致一此数据块的副本数量小于冗余因子。名称节点会定期检查这种情况,一旦发现某个数据块的副本数量小于冗余因子,就会启动数据冗余复制,为它生成新的副本。HDFS与其他分布式文件系统的最大区别就是可以调整冗余数据的位置。
3.数据出错
网络传输和磁盘错误尊因素都会造成数据错误。客户端在读取到数据后,会采用mds和shal对数据块进行校验,以确定读取到正确的数据。在文件被创建时,客户端就会对每- 个文件块进行信息摘录,并把这些信息写人同一个路径的隐藏文件里面。当客户端读取文件的时候,会先读取该信息文件,然后利用该信息文件对每个读取的数据块进行校验,如果校验出错,客户端就会请求到另外一个数据节点读取该文件块,并且向名称节点报告这个文件块有错误,名称节点会定期检查并且重新复制这个块。
10.请阐述HDFS在不发生故障的情况下读文件的过程。
答:
(1)客户端通过FlSysmeono打开文件相应地,在HIDFS文件系统中DitbuedFieSstess具体实现了FileSystem。 因此,调用open()方法后,DisribedFilSyste 会创建输人流FSDataInputStream.对于HDFS而言,具体的输人流就是DFSInputSteam
(2)在DFSInputStream的构造函数中,输人流通过ClientProtocal getBlockLocations0远程调用名称节点,获得文件开始部分数据块的保存位置。对于该数据块,名称节点返回保存该数据块的所有数据节点的地址,同时根据距离客户端的远近对数据节点进行排序:然后,DistributedFileSystem会利用DFSInputStream来实例化FSDataInputSteam.返回给客户端,同时返回了数据块的数据节点地址。
(3)获得输人流FDalnpulsreon后,客户端调用cao雨数开始读取数据。输人流根据响
面的排序结果,选择距离客户端最近的数据节点建立连接井读取数据。(4)数据从该数据节点读到客户端:当该数据块读取完毕时,FDsapulsrcor关闭和该数星节点的连接。
(5)输人流通过getBlockLocations()方法查找下一个数据块(如果客户端缓存中已经包含了数据块的位置信息,就不需要调用该方法)。
(6)找到该数据块的最佳数据节点,读取数据。
(7)当客户端读取完毕数据的时候,调用FSDataInputStream的close()函数,关闭输入流,需要注意的是,在读取数据的过程中,如果客户端与数据节点通信时出现错误,就会尝试连接包含此数据块的下一个数据节点。
第四章
3.请阐述HBase和传统关系数据库的区别
答:

- 分别解释HBase中行键、列键和时间戳的概念
答:
行键是唯一的,在一个表里只出现一次,否则就是在更新同一行,行键可以是任意的字节数组。
列族需要在创建表的时候就定义好,数量也不宜过多。列族名必须由可打印字符组成,创建表的时候不需要定义好列。
时间戳,默认由系统指定,用户也可以显示设置。使用不同的时间戳来区分不同的版本。
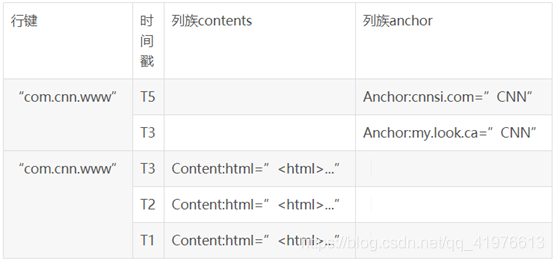
7.请举个实例来阐述HBase的概念视图和物理视图的不同
答:
HBase数据概念视图
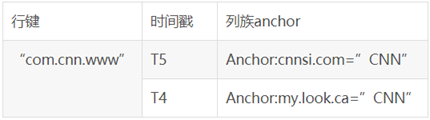
HBase数据物理视图

在HBase的概念视图中,一个表可以视为一个稀疏、多维的映射关系。
在物理视图中,一个表会按照属于同一列族的数据保存在一起
8.试述HBase各功能组建及其作用
(1)库函数:链接到每个客户端;
(2)一个Master主服务器:主服务器Master主要负责表和Region的管理工作;
(3)许多个Region服务器:Region服务器是HBase中最核心的模块,负责维护分配给自己的Region,并响应用户的读写请求
11.试述HBase的三层结构中各层次的名称和作用。

15.试述HStore的工作原理
答:每个Store对应了表中的一个列族的存储。每个Store包括一个MenStore缓存和若干个StoreFile文件。MenStore是排序的内存缓冲区,当用户写入数据时,系统首先把数据放入MenStore缓存,当MemStore缓存满时,就会刷新到磁盘中的一个StoreFile文件中,当单个StoreFile文件大小超过一定阈值时,就会触发文件分裂操作。
19.请列举几个HBase常用命令,并说明其使用方法
1.进入hbase shell console
$HBASE_HOME/bin/hbase shell
如果有kerberos认证,需要事先使用相应的keytab进行一下认证(使用kinit命令),认证成功之后再使用hbase shell进入可以使用whoami命令可查看当前用户
hbase(main)>
whoami
2.表的管理
1)查看有哪些表
hbase(main)>
list
2)创建表
#语法:create
#例如:创建表t1,有两个family name:f1,f2,且版本数均为2
hbase(main)>
create ‘t1’,{NAME
=> ‘f1’,
VERSIONS => 2},{NAME => ‘f2’,
VERSIONS => 2}
3)删除表
分两步:首先disable,然后drop
例如:删除表t1
hbase(main)>
disable ‘t1’
hbase(main)>
drop ‘t1’
4)查看表的结构
#语法:describe
#例如:查看表t1的结构
hbase(main)>
describe ‘t1’
5)修改表结构
修改表结构必须先disable
#语法:alter ‘t1’, {NAME => ‘f1’}, {NAME => ‘f2’, METHOD => ‘delete’}
#例如:修改表test1的cf的TTL为180天
hbase(main)>
disable ‘test1’
hbase(main)>
alter ‘test1’,{NAME=>‘body’,TTL=>‘15552000’},{NAME=>‘meta’,
TTL=>‘15552000’}
hbase(main)>
enable ‘test1’
3.权限管理
1)分配权限
#语法 : grant
#权限用五个字母表示: “RWXCA”.
#READ(‘R’), WRITE(‘W’), EXEC(‘X’), CREATE(‘C’), ADMIN(‘A’)
#例如,给用户‘test’分配对表t1有读写的权限,
hbase(main)>
grant ‘test’,‘RW’,‘t1’
2)查看权限
#语法:user_permission
#例如,查看表t1的权限列表
hbase(main)>
user_permission ‘t1’
3)收回权限
#与分配权限类似,语法:revoke
#例如,收回test用户在表t1上的权限
hbase(main)>
revoke ‘test’,‘t1’
4.表数据的增删改查
1)添加数据
#语法:put
#例如:给表t1的添加一行记录:rowkey是rowkey001,family name:f1,column name:col1,value:value01,timestamp:系统默认
hbase(main)>
put ‘t1’,‘rowkey001’,‘f1:col1’,‘value01’
用法比较单一。
2)查询数据
a)查询某行记录
#语法:get
#例如:查询表t1,rowkey001中的f1下的col1的值
hbase(main)>
get ‘t1’,‘rowkey001’,
‘f1:col1’
#或者:
hbase(main)>
get ‘t1’,‘rowkey001’,
{COLUMN=>‘f1:col1’}
#查询表t1,rowke002中的f1下的所有列值
hbase(main)>
get ‘t1’,‘rowkey001’
b)扫描表
#语法:scan
#另外,还可以添加STARTROW、TIMERANGE和FITLER等高级功能
#例如:扫描表t1的前5条数据
hbase(main)>
scan ‘t1’,{LIMIT=>5}
c)查询表中的数据行数
#语法:count
#INTERVAL设置多少行显示一次及对应的rowkey,默认1000;CACHE每次去取的缓存区大小,默认是10,调整该参数可提高查询速度
#例如,查询表t1中的行数,每100条显示一次,缓存区为500
hbase(main)>
count ‘t1’,
{INTERVAL => 100, CACHE => 500}
3)删除数据
a )删除行中的某个列值
#语法:delete
#例如:删除表t1,rowkey001中的f1:col1的数据
hbase(main)>
delete ‘t1’,‘rowkey001’,‘f1:col1’
注:将删除改行f1:col1列所有版本的数据
b )删除行
#语法:deleteall
#例如:删除表t1,rowk001的数据
hbase(main)>
deleteall ‘t1’,‘rowkey001’
c)删除表中的所有数据
#语法: truncate
#其具体过程是:disable table -> drop table -> create table
#例如:删除表t1的所有数据
hbase(main)>
truncate ‘t1’
5.Region管理
1)移动region
#语法:move ‘encodeRegionName’, ‘ServerName’
#encodeRegionName指的regioName后面的编码,ServerName指的是master-status的Region Servers列表
#示例
hbase(main)>move
‘4343995a58be8e5bbc739af1e91cd72d’,
‘db-41.xxx.xxx.org,60020,1390274516739’
2)开启/关闭region
#语法:balance_switch true|false
hbase(main)>
balance_switch
3)手动split
#语法:split ‘regionName’,‘splitKey’
4)手动触发major compaction
#语法:
#Compact
all regions in a table:
#hbase>
major_compact ‘t1’
#Compact
an entire region:
#hbase>
major_compact ‘r1’
#Compact
a single column family within a region:
#hbase>
major_compact ‘r1’, ‘c1’
#Compact
a single column family within a table:
#hbase>
major_compact ‘t1’, ‘c1’
6.配置管理及节点重启
1)修改hdfs配置
hdfs配置位置:/etc/hadoop/conf
#同步hdfs配置
cat /home/hadoop/slaves|xargs -i
-t scp /etc/hadoop/conf/hdfs-site.xml
hadoop@{}:/etc/hadoop/conf/hdfs-site.xml
#关闭:
cat /home/hadoop/slaves|xargs -i
-t ssh hadoop@{}
“sudo
/home/hadoop/cdh4/hadoop-2.0.0-cdh4.2.1/sbin/hadoop-daemon.sh --config /etc/hadoop/conf stop datanode”
#启动:
cat /home/hadoop/slaves|xargs -i
-t ssh hadoop@{}
“sudo
/home/hadoop/cdh4/hadoop-2.0.0-cdh4.2.1/sbin/hadoop-daemon.sh --config /etc/hadoop/conf start datanode”
2)修改hbase配置
hbase配置位置:
#同步hbase配置
cat /home/hadoop/hbase/conf/regionservers|xargs -i
-t scp /home/hadoop/hbase/conf/hbase-site.xml
hadoop@{}:/home/hadoop/hbase/conf/hbase-site.xml
#graceful重启
cd ~/hbase
bin/graceful_stop.sh
–restart --reload --debug inspurXXX.xxx.xxx.org
第五章
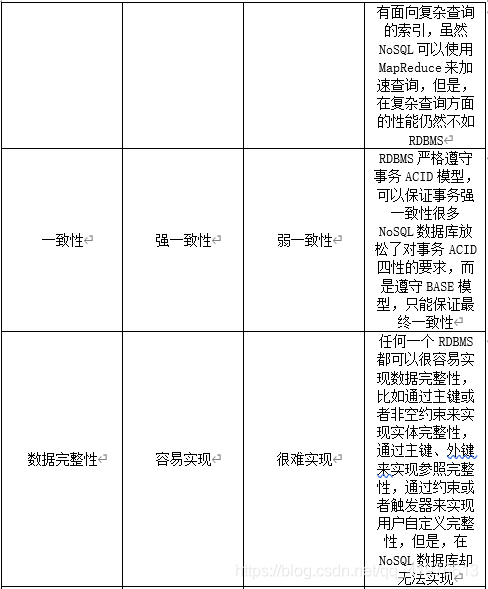
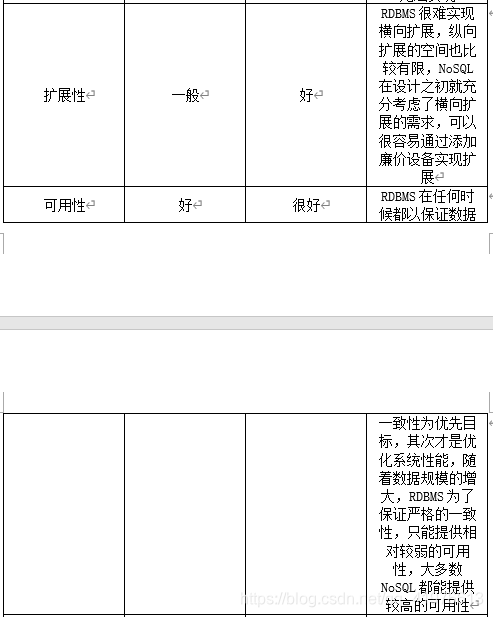
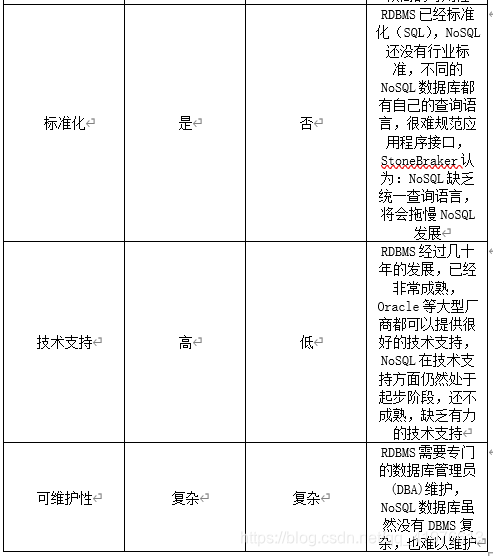
4.请比较NoSQL数据库和关系数据库的优缺点

5.试述NoSQL数据库的四大类型
答:键值数据库、列族数据库、文档数据库和图数据库
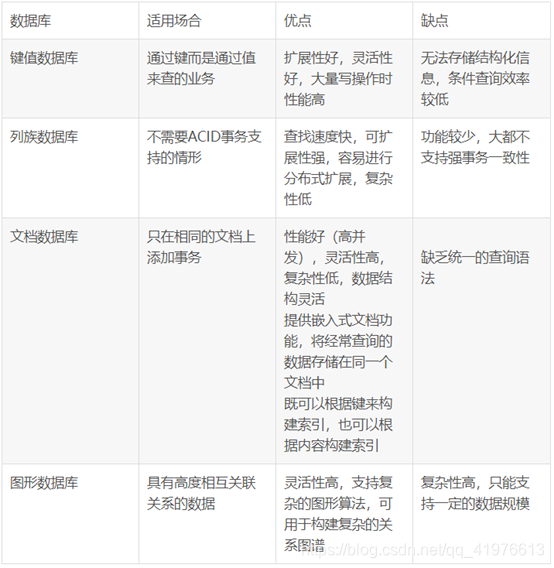
6.试述键值数据库、列族数据库、文档数据库和图数据库的适用场合和优缺点。
答:
7.试述CAP理论的具体含义。
答:所谓的CAP指的是:
C(Consistency):一致性,是指任何一个读操作总是能够读到之前完成的写操作的结果,也就是在分布式环境中,多点的数据是一致的,或者说,所有节点在同一时间具有相同的数据
A:(Availability):可用性,是指快速获取数据,可以在确定的时间内返回操作结果,保证每个请求不管成功或者失败都有响应;
P(Tolerance of Network Partition):分区容忍性,是指当出现网络分区的情况时(即系统中的一部分节点无法和其他节点进行通信),分离的系统也能够正常运行,也就是说,系统中任意信息的丢失或失败不会影响系统的继续运作。
11.请解释软状态、无状态、硬状态的具体含义。
答:“软状态(soft-state)”是与“硬状态(hard-state)”相对应的一种提法。数据库保存的数据是“硬状态”时,可以保证数据一致性,即保证数据一直是正确的。“软状态”是指状态可以有一段时间不同步,具有一定的滞后性。
12.什么是最终一致性?
答:
最终一致性根据更新数据后各进程访问到数据的时间和方式的不同,又可以区分为:
- 会话一致性:它把访问存储系统的进程放到会话(session)的上下文中,只要会话还存在,系统就保证“读己之所写”一致性。如果由于某些失败情形令会话终止,就要建立新的会话,而且系统保证不会延续到新的会话;
- 单调写一致性:系统保证来自同一个进程的写操作顺序执行。系统必须保证这种程度的一致性,否则就非常难以编程了
- 单调读一致性:如果进程已经看到过数据对象的某个值,那么任何后续访问都不会返回在那个值之前的值
- 因果一致性:如果进程A通知进程B它已更新了一个数据项,那么进程B的后续访问将获得A写入的最新值。而与进程A无因果关系的进程C的访问,仍然遵守一般的最终一致性规则
- “读己之所写”一致性:可以视为因果一致性的一个特例。当进程A自己执行一个更新操作之后,它自己总是可以访问到更新过的值,绝不会看到旧值

