
- 1有什么职业入行时间短,薪资高?_工作时间少工资高的工作
- 2基于51单片机的十字路口交通灯系统_proteus红绿灯仿真元件名称
- 3Flutter: won‘t run without google play services, which are not supported by your device 解决办法
- 4spacy分词工具下载指南_spacy怎么下载
- 5【LeetCode】96. 不同的二叉搜索树(中等)——代码随想录算法训练营Day40
- 6java 3至5年常见面试题及答案_3-5年java面试题
- 7【数据结构】图
- 8C++:模版初阶 | STL简介_stl风格
- 9智慧树大数据分析的python_智慧树知到大数据分析的python基础搜题公众号
- 10Redis 面试指南:常见问题及最佳答案_redis面试
“Wav2lip在唇形合成与迁移中的深入应用:从语音驱动技术到精准唇形合成的全面解析“_wav2lip唇行同步
赞
踩
基于Wav2lip实现精准唇形合成
1. 项目概述
本项目基于飞桨PaddleGAN实现精准唇形合成,提供预训练模型,无需训练即可直接使用。通过唇形合成技术,可以让静态图像或动态视频中的人物进行唇形转换,输出与目标语音相匹配的视频,实现自制视频配音。

2. 解决方案
唇形合成模型Wav2lip通过采用唇形判别器来强制生成器产生准确而逼真的唇部运动,实现任务口型与输入语音同步。此外,考虑到时间相关性,Wav2Lip在判别器中使用了多个连续帧,并通过视觉质量损失来提升视觉质量。该模型适用于任意人脸、任意语言,对任意视频都能达到很好的效果。
3. 数据准备
项目提供了蒙娜丽莎的图片和一段新闻播报音频,保存在work文件夹下。你也可以准备自己的图片/视频以及音频文件。
4. 模型推理
首先,从GitHub/Gitee上下载PaddleGAN的代码,只需在第一次运行项目时下载即可。然后,使用PaddleGAN develop版本,安装所需包。具体操作如下: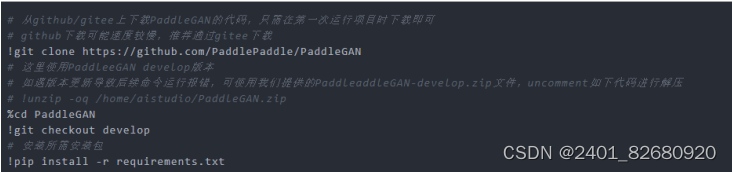
唇形动作合成
通过运行特定命令,您可以实现唇形合成,具体参数说明如下:
- face: 用于唇形合成的图片或视频文件。
- audio: 用于驱动唇形合成的音频文件。
- outfile: 指定生成的视频文件的保存路径及文件名。
本项目支持您上传自备的视频和音频文件,轻松合成您想要的配音视频。程序运行完成后,将生成您在 outfile 参数中指定的视频文件。
以下是一个示例命令,供您参考:
export PYTHONPATH=$PYTHONPATH:/home/aistudio/work/PaddleGAN && python applications/tools/wav2lip.py --face /home/aistudio/work/picture.jpeg --audio /home/aistudio/work/audio.m4a --outfile /home/aistudio/work/output.mp4
解读wav2lip:探究语音驱动唇部动作的技术原理

本文来自ACM 2020:A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild
一、现有方法不足
常见的语音驱动嘴唇运动方法在处理动态的和无约束的说话人脸视频时,通常无法准确地合成口型,导致生成的视频与音频不同步,主要原因包括两方面:
(1)传统的基于像素的人脸重建损失无法准约束音频-口型同步:因为面部重建损失是基于整个图像计算的,而唇部区域只占整个图像的很小一部分(不到4%),因而无法聚焦唇部细节。此外,在人脸重建的训练过程中,只有在训练的中后期才开始优化口型,导致前期监督信息缺乏。
(2)传统的基于GAN的判别器在音频-口型同步检测方面准确率较低:传统的GAN判别器只使用单帧图像来评估口型同步,缺乏时间上下文信息,无法评估口型动态变化质量。而且由于生成过程中存在伪影,GAN判别器更容易关注视觉伪影,从而忽略音频和口型的对应关系。
为了解决上述两个问题,wav2lip引入了一个在真实视频中预训练的专家口型同步判别器,且包含多帧信息,用于判断音频和口型是否同步。实验发现,相较于基于像素的人脸重建方法,这个专家判别器在口型同步判别任务上更精准。在训练阶段,将该专家判别器保持冻结状态,保证判断结果不受伪影的干扰。
二、 本文方法介绍
wav2lip模型的训练分为两个阶段,第一阶段是专家音频和口型同步判别器预训练;第二阶段是GAN网络训练。训练部分包括一个生成器和两个判别器,这里的两个判别器分别是专家音频和口型同步判别器和视觉质量判别器,前者预训练完毕后,在GAN训练过程中保持冻结。
具体来说,wav2lip的训练流程如下:首先,提取音频特征,将音频特征与人脸图像进行配对,形成一个音频-图像对,然后训练专家音频和口型同步判别器。接下来,wav2lip使用GAN来学习音频-图像对之间的映射关系。生成器网络负责生成逼真的嘴唇动作,而判别器网络则负责评估生成的嘴唇动作的一致性和真实性,通过不断的训练和反馈,生成器网络逐渐学习到如何根据音频特征生成与之匹配的嘴唇动作。
在训练完成后,wav2lip模型根据音频信息逐帧生成一个说话的人脸视频。
2.1 数据集处理
本文使用的LRS2数据集,来自BBC的唇语视频,包含4万多个口语句子,它的训练集、验证集和测试集是根据广播日期进行划分。用户也可以自行收集各种视频数据,提升目标场景的效果。
推荐使用视频帧率为25fps,音频采样率为16k,视频的一帧对应音频块的长度为16。
2.2 专家音频和口型同步判别器预训练
wav2lip专家音频和口型同步判别器用于评估生成的唇部动作与音频的同步性,它是由syncNet改进而来,关于syncNet只需要简单了解一下:
syncNet包含一个人脸编码器和一个音频编码器,两者都由一系列2D卷积层组成。人脸编码器的输入是一个大小为 Tv 的视频窗口 V ,包含连续的人脸帧,但这些帧仅保留人脸下半部分。音频编码器的输入是一个大小为 Ta×D 的语音片段 S ,其中 Tv 和 Ta 分别是视频和音频的时间步长。syncNet的两个 编码器分别计算音频嵌入和视频嵌入,然后使用最大间隔损失进行训练,最小化匹配的音频-口型对之间的嵌入距离。最大间隔损失的原理是基于最大间隔分类器的思想,通过最大化类别之间的间隔来提高分类器的鲁棒性和泛化能力。
wav2lip对SyncNet 进行了三个方面的修改,训练了更好的专家口型同步判别器:即使用RGB图像作为输入,增加模型的深度,使用余弦相似度二元交叉熵损失,即余弦相似度BCE损失。
wav2lip使用LRS2训练集对判别器进行训练,在训练过程中,每个样本的时间维度设置为5帧(Tv = 5),按通道维度拼接起来,这样能够获取视频帧的上下文信息。在测试集上评估,wav2lip的专家判别器的准确率达到了91%,而LipGAN中使用的判别器的准确率只有56%。
有了准确的口型同步判别器后,可以在训练过程中利用它来对生成器进行优化,提高生成器生成口型的准确性。
2.3 口型生成器
wav2lip的生成器负责生成包含目标口型的人脸图像,是一个2D-CNN编码器-解码器结构,包含三个由卷积网络组成的模块:Identity Encoder,Speech Encoder,Face Decoder。
其中,Identity Encoder用于编码身份特征,把随机参考帧与姿势先验帧按通道维度拼接起来作为输入。参考帧包含目标人脸的完整外观特征,如嘴唇的形状、颜色和纹理等,用于唇部形状和运动的合成。姿势先验帧的下半部分被掩蔽,但提供了目标人脸的姿势信息,比如头部和脸部的方向和角度等信息,确保合成的唇部动作与目标人脸的姿势一致。同时,姿势先验帧也作为重建目标。这两个图像共同作为输入,确保生成的人脸的外观、口型和姿态更加准确。
Speech Encoder 用于编码输入的语音片段,Face Decoder则通过反卷积进行上采样,用于重建人脸图像,它的输入是编码后的音频特征和身份特征的拼接。
生成器通过最小化生成帧与真实帧之间的L1重构损失来提高生成的帧的质量,重建目标函数为:
Lrecon =1N∑i=1N‖Lg−LG‖1
wav2lip生成器独立地生成每一帧,然后将连续生成的帧序列输入给预训练的专家音频和口型同步判别器。
具体来说,为了在训练过程中与专家判别器的配合,生成器需要生成 Tv=5 个连续帧,但只使用生成的人脸的下半部分进行判别,生成器通过最小化来自专家判别器的同步损失来提高生成的帧的口型同步质量,同步损失函数为余弦相似度二元交叉熵损失:
Psync=v⋅smax(‖v‖2⋅‖s‖2,ϵ)Lsync=1N∑i=1N−log(Psynci)
在生成器的训练过程中,专家判别器的权重保持不变,因为专家判别器是从真实视频中的口型数据训练的,无需改变。通过这种生成器的结构和专家判别器的共同作用,可以生成任意人脸对象,并且口型与语音的同步性较好。但由于LRS2清晰度偏低,生成图像脸部较模糊,而且牙齿部分还原度稍差,可以选择清晰度更高的数据集,或者利用超分模型提升脸部的清晰度。此外,当参考人脸图片侧脸时,脸部可能会不协调。
2.4 视觉质量判别器
实验观察到,使用专家口型同步判别器可以使生成器生成准确的口型形状,但有时候会导致生成区域出现模糊或者伪影。为了提高生成图像质量,wav2lip在生成器中使用了一个额外的的视觉质量判别器。
具体来讲,wav2lip有两个判别器,口型同步判别器和质量判别器,一个用于提高口型同步准确性,另一个用于提高生成图像视觉质量。口型同步判别器在GAN训练期间保持冻结,视觉质量判别器只对生成的人脸的质量进行监督,不负责口型同步。
视觉质量判别器 D 由多个卷积块组成,训练目标是最大化目标函数 Ldisc :
Lgen=Ex∼Lg[log(1−D(x)]∣Ldisc =Ex∼LG[log(D(x))]+Ex∼Lg[log(1−D(x)]
其中, Lg 对应于生成器 G 生成的图像, LG 对应于真实图像。
2.5 生成器训练
生成器的最终优化目标是重建损失、同步损失和对抗损失的加权和,用公式表示如下:
Ltotal =(1−sw−sg)⋅Lrecon +sw⋅Lsync +sg⋅Lgen
其中,sw 同步惩罚权重, sg 对抗损失权重。
重建损失衡量生成器生成的图像与原始图像之间的差异,同步损失衡量生成口型与目标口型之间的差异,对抗损失衡量生成的图像在对抗训练中与判别器的对抗表现。通过最小化这些损失函数的加权和,生成器可以生成口型同步的高质量人脸图像。
三、参考文献
LipGAN:Towards Automatic Face-to-Face Translation
SyncGAN: Using learnable class specific priors to generate synthetic data for improving classifier performance on cytological images
Wav2Lip唇形动作迁移实验
1. 实验介绍
1.1 实验目的
理解并掌握的基础知识点,包括:encoder、decoder;
掌握Wav2Lip唇形动作迁移算法的设计原理以及构建流程;
熟悉飞桨开源框架构建生成对抗网络Wav2Lip的方法。
1.2 实验内容
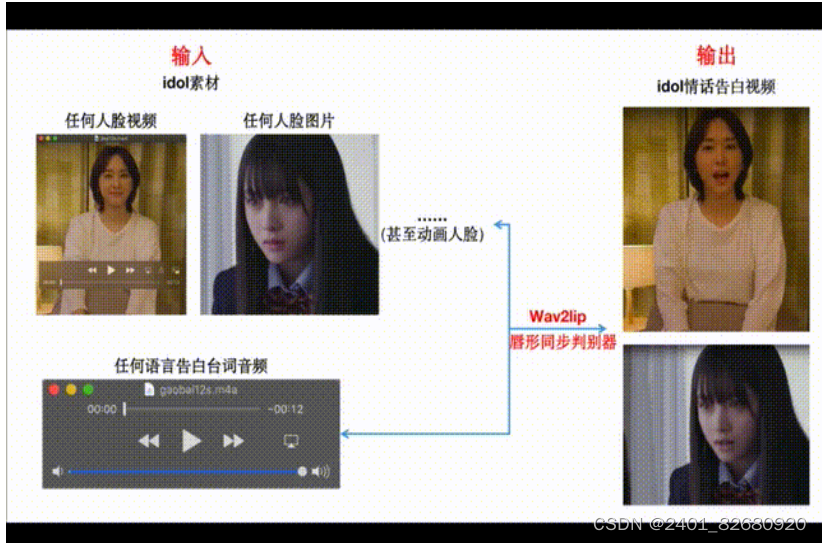
Wav2Lip[1]模型是一个基于GAN的唇形动作迁移算法,实现生成的视频人物口型与输入语音同步。Wav2Lip不仅可以基于静态图像来输出与目标语音匹配的唇形同步视频,还可以直接将动态的视频进行唇形转换,输出与输入语音匹配的视频,俗称「对口型」,如 图2 所示:
1.3 实验环境
本实验支持在实训平台或本地环境操作,建议您使用实训平台:
实训平台:如果您选择在实训平台上操作,无需安装实验环境。实训平台集成了实验必须的相关环境,代码可在线运行,同时还提供了免费算力,即使实践复杂模型也无算力之忧。
本地环境:如果您选择在本地环境上操作,需要安装Python3.7、飞桨开源框架2.0等实验必须的环境,具体要求及实现代码请参见《本地环境安装说明》
所有需要安装的环境统一存放在了 ~/work/requirements.txt 文件中,您可以通过如下代码安装必须的实验环境。
%cd ~/work/ !pip install -r requirements.txt
1.4 实验设计
本实验的实现方案如 图3 所示:
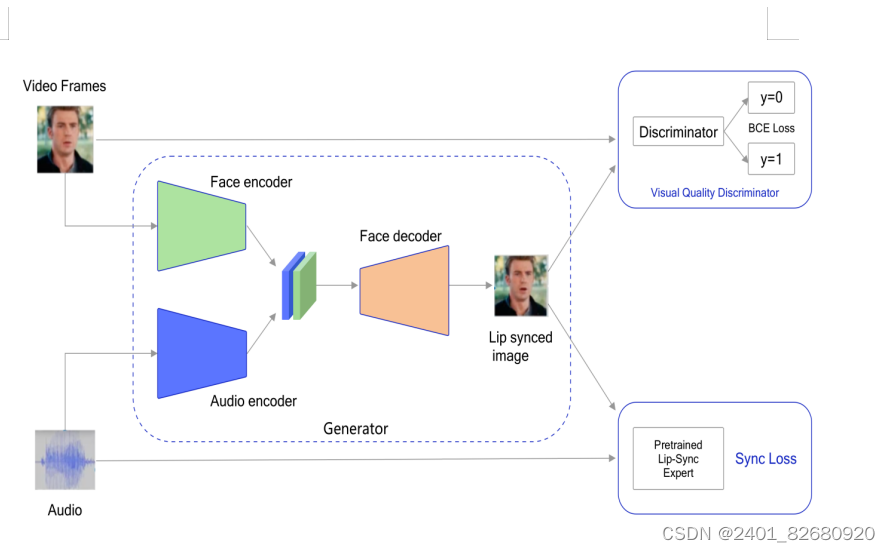
- 在训练阶段,生成器模型的输入包含两部分(视频帧序列和音频),分别通过Face encoder和Audio encoder得到特征信息,并进行融合;再通过Face decoder获得唇形和音频同步的图像帧。把原始视频帧和生成图像帧输入到视觉质量判别器中,二分类的结果表示是真实的图像、还是生成的图片,进而提高图像质量。把生成图像帧和音频输入到预先训练好的唇形同步判别器中,判断唇形是否生成的精准,在训练过程中,唇形同步判别器参数会一直被冻结,不参与训练和更新。
- 在推理阶段,提供一段音频和视频(或图像、动画)即可合成唇形同步视频。
2. 实验详细实现
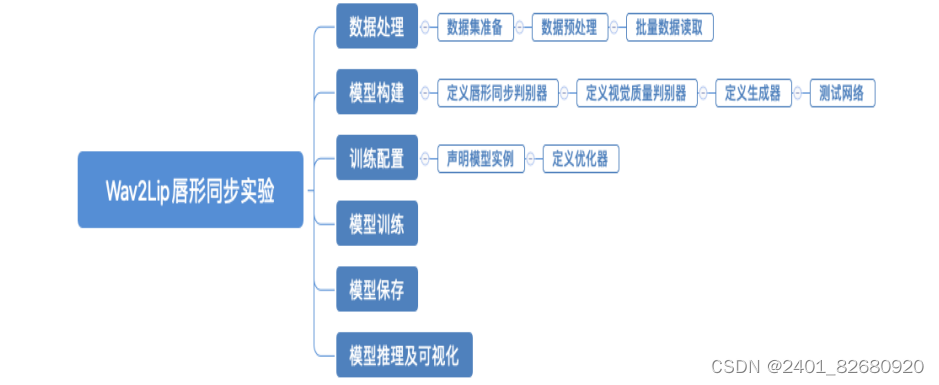
Wav2Lip生成唇形同步视频的实验流程如 图4 所示,主要包含6个步骤:
1.数据处理: 根据网络接收的数据格式,完成相应的预处理操作,保证模型正常读取;
2.模型构建: 设计Wav2Lip网络结构;
3.模型配置: 实例化模型,指定学习率和优化器;
4.模型训练: 执行多轮训练不断调整参数,以达到较好的效果;
5.模型保存: 将模型参数保存到指定位置,便于后续推理使用;
6.模型推理及可视化: 使用训练好的模型将视频人物的唇形和输入语音同步,并可视化推理结果。
2.1 数据处理
2.1.1 数据准备
LRS2 (Lip Reading Sentences 2) 数据集来自BBC电视节目中的数千个口语句子,每个句子的长度不超过100个字符。在使用本实验时,需要大家自行下载数据LRS2,本实验只使用了main部分,所以只下载Part A即可。然后上传到本项目(在项目的详情页面中, 点击"修改", 选择"创建数据集")。
上传数据集之后,默认保存在/home/aistudio/data/data82728/(根据实际情况修改)文件夹内,使用cat命令连接所有文件到lrs2_v1.tar,并解压。
# 仅初次下载数据时运行,如果已经解压过,不需要运行此段代码 # 修改为自己数据集目录 %cd /home/aistudio/data/data82728/ !cat lrs2_v1_parta* >lrs2_v1.tar !tar -xf lrs2_v1.tar !rm -rf lrs2_v1.tar !mv mvlrs_v1/ /home/aistudio/work/data/ print('Done...')
2.1.2 数据预处理
对下载的LRS2数据集做进一步处理(提取A视频帧进行人脸检测,提取B的音频),并保存在相应文件夹下。
导入相应的依赖库,代码实现如下。
运行lrs2_preprocess.py文件对数据集进行预处理以实现快速训练,感兴趣的可以详细阅读代码。

2.1.3 批量数据读取
我们选取一段连续的真实视频人脸序列,并只保留上半部分人脸(图5中下半部分被遮挡的目标人脸),另外再选取一段随机参考帧(通过视频随机移动5帧产生),然后将两段图片序列在通道的维度上concatenate起来;同时选取与真实帧同步的音频片段,一起输入到Generator中, 这些数据输入到生成器中后,生成器重建出与音频同步的唇形,即重建出被遮挡的人脸下半部分的同时,其唇形也已经是和音频同步的唇形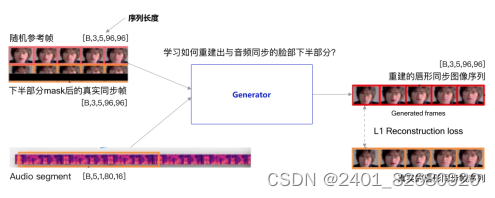
数据集加载使用飞桨Dataset(数据集定义) + DataLoader(多进程数据集加载)。
先定义数据集,主要是实现一个新的Dataset类,继承父类 paddle.io.Dataset ,并实现父类中如下两个抽象方法:
__getitem__:根据给定索引获取数据集中指定样本;
__len__:返回数据集样本个数。
读取数据列表(train.txt)的函数,获取所有视频的路径,具体实现代码如下:

2.2 模型构建
Wav2Lip模型结构如 图6 所示,包含一个生成器和两个判别器。为了根据音频生成与音频精准同步的唇形图像,首先模型的输入包含两个部分,一是一段视频帧序列,二是一段音频(Melspectrogram segment),这两部分数据按照特定的组织格式输入模型的生成器,生成器由两个编码器以及一个解码器组成,生成器中的脸部编码器接收视频图像帧,生成中间特征;生成器中的音频编码器接收音频信号生成音频中间特征;得到的脸部中间特征以及音频中间特征分别进行concat进行特征融合,融合后的特征再送入脸部解码器中进行解码,最终输出唇形与音频同步的图像帧(Generated frames)。在训练的时候,生成器生成的唇形同步的图像帧会输入到后面的判别器中,判别器也包含两部分,一是一个已经预训练好的唇形与音频同步的判别器SyncNet, 它接受音频信号以及生成的唇形同步的图像作为输入,来判别生成的唇形图像与音频是否同步,这个判别器需要提前预训练好,目的是增强唇形与音频同步判别的能力;二是唇形视觉质量的判别器(Visual Quality Discriminator),这个判别器接收生成器生成的唇形图像以及与音频同步真实同步的唇形图像,来判别其真假,驱动唇形质量更好地生成。
在Wav2Lip判别器和生成器网络中,重复使用conv+norm+ReLu+residual;conv+LeakyReLU;ConvBNRelu+norm+ReLU三个模块,所以在飞桨中使用Layer子类定义的方式来进行代码编写,方便复用,子类中包含两个函数:
- init 函数:声明Layer组网 ;
- forward 函数:使用声明的 Layer 变量进行前向计算。
在定义Layer子类时,需要使用paddle.nn.Conv2D API、paddle.nn.BatchNorm2D API、paddle.nn.Conv2DTranspose API。
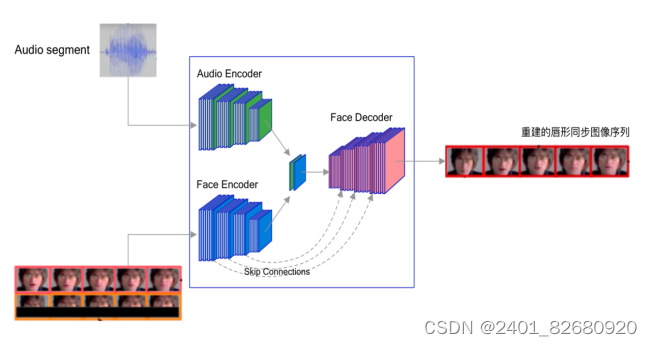
2.2.1 生成器
生成器包含如下3部分,如图7所示:
视频和人脸图像之间的映射能够从未标记的数据中进行端到端的训练,该网络由两个不对称的音频和视频流组成训练后的网络用于确定视频中的假同步错误
- Identity Encoder:由一堆残差卷积层组成,对随机参考帧R进行编码,并在通道维度与姿态先验P(下半部分遮住的目标脸部)相连接。
- Speech Encoder(Audio Encoder):由一堆2D卷积层组成,对输入语音片段S进行编码,然后与其对应脸部表示相连接。
- Face Decoder:由一堆卷积层组成,以及使用转置卷积进行上采样。通过对输入图像的遮挡目标脸部进行适当的出行修复,产生一个由视听融合产生的唇同步面孔。
-
图7:生成器结构图
生成器的训练目标是最小化生成帧LgL_gLg和真实帧 LGL_GLG 之间的L1损失,计算公式如下:

2.2.2 唇形同步判别器
研究者发现,之前方法由于仅使用重建损失或较弱的唇形同步判别器,没有对错误的唇形进行适当的惩罚。于是,采用预训练的专家唇形同步判别器,它已经相当准确地检测唇形同步错误。我们不在GAN设置中训练唇形同步判别器,即对于生成的帧,不再进行进一步微调唇形同步判别器。
基于SyncNet模型改进,用于训练唇形同步判别器,主要包含以下几点改进:
- 不以信道级联的方式输入灰度图,而是输入彩色图像;
- 使用跳跃连接的残差块,构建更深层的网络;
- 更换损失函数,使用余弦相似度的二值交叉熵损失值。
2.2.4 测试网络
测试生成网络Wav2Lip和质量判别网络Wav2LipDiscQual的前向计算结果,一个batch的数据,输出一张图片。

2.3 训练配置
2.3.1 声明定义好的判别器和生成器实例
定义一个生成器gen_model、唇形同步判别器dis_sync_model、质量判别器dis_qual_model:
2.3 训练配置
2.3.1 声明定义好的判别器和生成器实例
定义一个生成器gen_model、唇形同步判别器dis_sync_model、质量判别器dis_qual_model:

.
2.3.2 定义优化器对象
本实验使用Adam优化器,初始学习率learning_rate设置为0.0001。
在训练神经网络时,使用学习率控制参数的更新速度。学习率过小时,会大大降低参数的更新速度,收敛速度慢,一般在训练一定epoch之后使用;学习率较大时,容易发生震荡,导致参数在最优值附近来回摆动。为此,在训练过程中引入学习率衰减,使学习率随着训练的进行逐渐衰减。本案例采用线性衰减方法(如图11所示)设置学习率的策略,其通过 epoch 计算出一个因子,该因子会乘以初始学习率,用飞桨API paddle.optimizer.lr.LambdaDecay 实现。
2.3.3 唇形同步判别器损失函数
使用余弦相似度的二值交叉熵损失值,实现代码如下:
2.4 模型训练
训练模型并调整参数的过程,通过观察在训练过程中的检测指标(如损失函数、生成图片效果等)判断模型的训练状态,及时调整超参数等。本实验考虑到时长因素,只训练了20个epoch,每个epoch都需要在训练集上运行,并打印出相应的loss。
2.5 模型保存
训练完成后,可以将模型参数保存到磁盘,用于模型推理。
2.6 模型推理
加载保存好的生成器模型来进行模型推理,观察模型生成唇形同步视频的效果,推理流程: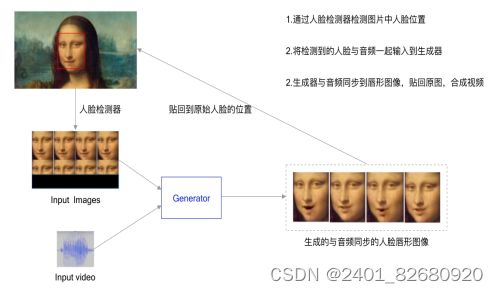
检测人脸后,可能一个人脸被多次检测,给出多个预测框(如图11左图),我们希望仅输出其中一个最好的检测框。这里使用非极大值抑制(Non-Maximum Suppression,NMS)的方法来消除多余的候选框:选出得分最高的预测框,然后看哪些预测框跟它的IoU大于阈值thresh,就把这些预测框给丢弃掉。这里IoU的阈值是超参数,需要提前设置,本实验设置0.3。经过NMS处理,最终保留的预测框如图14右图所示:

.使用上述定义好的人脸检测算法和NMS算法,获取一个batch的人脸数据,具体实现代码如下:


接下来就可以使用准备好的视频、音频来生成唇形同步视频,由于训练完整Wav2Lip数据集需要花费较多的时间和算力,这里提供一个训练好的模型进行预测(pretrained_models/wav2lip_hq.pdparams)。具体实现代码如下:



该wav2lip模型几乎是万能的,适用于任何人脸、任何语音、任何语言,对任意视频都能达到很高的准确率,可以无缝地与原始视频融合,还可以用于转换动画人脸,并且导入合成语音也是可行的。不仅可以让蒙娜丽莎像朱广权一样播报新闻,还可以让宋代诗人穿越千年念诗、让你的idol对你说出任何你想听的情话等等。大家可以上传自己准备的视频和音频, 合成任意想要的逼真的配音视频。
让图片会说话、视频花式配音的魔法--Wav2lip的使用只用两步:
- 在上述代码中的face参数和audio参数分别换成自己的视频和音频路径;
- 运行上述代码,并保存制作完成的对口型视频(outfile参数指定的视频文件)。
3 实验总结
本次实验使用飞桨框架构建了Wav2Lip的GAN网络,并在LRS2数据集上实现了唇形动作迁移任务。通过本次实验,您不但掌握了《人工智能导论:模型与算法》- 6.5深度生成学习(P231-P235)中介绍的相关原理的实践方法,还熟悉了通过开源框架实现深度学习任务的实验流程和代码实现。大家可以在此实验的基础上,尝试开发自己感兴趣的唇形动作迁移任务。
4 实验拓展
尝试调整学习率和训练轮数epoch等超参数,观察模型训练效果;
大家可以大开脑洞,自娱自乐,更换视频和音频生成新的视频。

