
- 1ESXI低版本升级到ESXI6.7_esxi能跨版本升级吗
- 2Linux系统查询、端口是否开放_linux 如何测试端口开放了吗
- 3百度智能云千帆AppBuilder-SDK使用说明_千帆appbuilder 组件query改写
- 413.2k star, 高生产力的低代码开发平台 lowcode-engine
- 5Mac搭建Android10源码环境_mac编译android源码
- 6StartAI修图实例教程之海报修图
- 7如何选择合适的边缘计算机——将 AI 转移到 IIoT 边缘?
- 8DFS:floodfill算法解决矩阵联通块问题
- 9【Python】PyCharm中调用另一个文件的函数或类_pycharm调用其他py文件
- 10Gitee代码上传步骤详解(超详细)_gitee上传代码
Spark on YARN 部署搭建详细图文教程_spark on yarn安装配置
赞
踩
目录
一、引言
按照前面环境部署中所了解到的,如果我们想要一个稳定的生产 Spark 环境,那么最优的选择就是构建 HA StandAlone 集群。
不过在企业中,服务器的资源总是紧张的,许多企业不管做什么业务,都基本上会有 Hadoop 集群,也就是会有 YARN 集群。
对于企业来说,在已有 YARN 集群的前提下在单独准备 Spark StandAlone 集群,对资源的利用就不高,所以在企业中,多数场景下,会将 Spark 运行到 YARN 集群中。
YARN 本身是一个资源调度框架,负责对运行在内部的计算框架进行资源调度管理.。作为典型的计算框架,Spark 本身也是直接运行在 YARN 中,并接受 YARN 的调度的。所以,对于 Spark On YARN 无需部署 Spark 集群,只要找一台服务器,充当 Spark 的客户端,即可提交任务到 YARN 集群中运行。
二、SparkOnYarn 本质
2.1 Spark On Yarn 的本质?
- Master 角色由 YARN 的 ResourceManager 担任。
- Worker 角色由 YARN 的 NodeManager 担任。
- Driver 角色运行在 YARN 容器内或提交任务的客户端进程中。
- 真正干活的 Executor 运行在 YARN 提供的容器内。
2.2 Spark On Yarn 需要啥?
- 需要 Yarn 集群:已经安装了
- 需要 Spark 客户端工具,比如 spark-submit,可以将 Spark 程序提交到 YARN 中
- 需要被提交的代码程序:如 spark/examples/src/main/python/pi.py 此示例程序,或我们后续自己开发的 Spark 任务

三、配置 spark on yarn 环境
3.1 spark-env.sh
具体安装 spark 步骤:Spark-3.2.4 高可用集群安装部署详细图文教程_Stars.Sky的博客-CSDN博客
确保:HADOOP_CONF_DIR、YARN_CONF_DIR 在 spark-env.sh 以及环境变量配置文件中即可(其他的配置文件都不需要修改,切 spark 和 YARN 在同一机器上):
- (base) [root@hadoop01 /bigdata/spark-3.2.4]# vim conf/spark-env.sh
- ## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
- HADOOP_CONF_DIR=/bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop/
- YARN_CONF_DIR=/bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop/
3.2 连接到 YARN 中
3.2.1 bin/pyspark
- bin/pyspark --master yarn --deploy-mode client|cluster
-
- # --deploy-mode 选项是指定部署模式,默认是客户端模式
- # client 就是客户端模式
- # cluster 就是集群模式
- # --deploy-mode 仅可以用在 YARN 模式下
 注意:交互式环境 pyspark 和 spark-shell 无法运行 cluster 模式。
注意:交互式环境 pyspark 和 spark-shell 无法运行 cluster 模式。
3.2.2 bin/spark-shell
bin/spark-shell --master yarn --deploy-mode client|cluster注意:交互式环境 pyspark 和 spark-shell 无法运行 cluster 模式。
3.2.3 bin/spark-submit (PI)
bin/spark-submit --master yarn --deploy-mode client|cluster /xxx/xxx/xxx.py 参数四、部署模式 DeployMode
Spark On YARN 是有两种运行模式的,一种是 Cluster 模式,一种是 Client 模式。这两种模式的区别就是 Driver 运行的位置:
- Cluster 模式即:Driver 运行在 YARN 容器内部,和 ApplicationMaster 在同一个容器内。
- Client 模式即:Driver 运行在客户端进程中,比如 Driver 运行在 spark-submit 程序的进程中。
4.1 Cluster 模式
如图,此为 Cluster 模式 Driver运行在容器内部:

4.2 Client 模式
如图,此为Client 模式 Driver 运行在客户端程序进程中(以 spark-submit 为例) :

4.3 两种模式的区别

4.4 测试
4.4.1 client 模式测试
假设运行圆周率 PI 程序,采用 client 模式,命令如下:
(base) [root@hadoop01 /bigdata/spark-3.2.4]# bin/spark-submit --master yarn --deploy-mode client --driver-memory 512m --executor-memory 512m --num-executors 2 --total-executor-cores 2 /bigdata/spark-3.2.4/examples/src/main/python/pi.py 10-
bin/spark-submit: 这是用于提交 Spark 任务的脚本。 -
--master yarn: 指定 Spark 集群管理器为 YARN。 -
--deploy-mode client: 这意味着 Spark 任务的 driver 程序将在客户端机器(即你提交命令的机器)上运行。 -
--driver-memory 512m: 分配给 driver 的内存为 512 MB。 -
--executor-memory 512m: 每个 Spark executor 使用 512 MB 内存。 -
--num-executors 2: 指定 Spark 应使用 2 个 executor 进程。 -
--total-executor-cores 2: 指定所有 executors 合计可使用的 CPU 核心数为 2。 -
/bigdata/spark-3.2.4/examples/src/main/python/pi.py: 这是你要运行的 Python 程序的路径。 -
10: 这是传递给pi.py程序的一个参数。具体来说,这通常用于指定计算π值时的迭代次数或精度。
日志跟随客户端的标准输出流进行输出:

4.4.2 cluster 模式测试
假设运行圆周率 PI 程序,采用 cluster 模式,命令如下:
(base) [root@hadoop01 /bigdata/spark-3.2.4]# bin/spark-submit --master yarn --deploy-mode cluster --driver-memory 512m --executor-memory 512m --num-executors 2 --total-executor-cores 2 /bigdata/spark-3.2.4/examples/src/main/python/pi.py 10客户端是无日志信息和结果输出的:

4.5 两种模式总结
Client 模式和 Cluster 模式最最本质的区别是:Driver 程序运行在哪里。
Client 模式:学习测试时使用,生产不推荐(要用也可以,性能略低,稳定性略低)
- Driver 运行在 Client上,和集群的通信成本高
- Driver 输出结果会在客户端显示
Cluster模式:生产环境中使用该模式
- Driver 程序在 YARN 集群中,和集群的通信成本低
- Driver 输出结果不能在客户端显示
- 该模式下 Driver 运行 ApplicattionMaster 这个节点上,由 Yarn 管理,如果出现问题,yarn 会重启 ApplicattionMaster(Driver)
五、两种模式详细流程
5.1 Client 模式
在 YARN Client 模式下,Driver 在任务提交的本地机器上运行,示意图如下:
 具体流程步骤如下:
具体流程步骤如下:
- Driver 在任务提交的本地机器上运行,Driver 启动后会和 ResourceManager 通讯申请启动 ApplicationMaster;
- 随后 ResourceManager 分配 Container,在合适的 NodeManager 上启动ApplicationMaster,此时的 ApplicationMaster 的功能相当于一个 ExecutorLaucher,只负责向 ResourceManager 申请 Executor 内存;
- ResourceManager 接到 ApplicationMaster 的资源申请后会分配 Container,然后ApplicationMaster 在资源分配指定的 NodeManager 上启动 Executor 进程;
- Executor 进程启动后会向 Driver 反向注册,Executor 全部注册完成后 Driver 开始执行 main函数;
- 之后执行到 Action 算子时,触发一个 Job,并根据宽依赖开始划分 Stage,每个 Stage 生成对应的 TaskSet,之后将 Task 分发到各个 Executor 上执行。
5.2 Cluster 模式
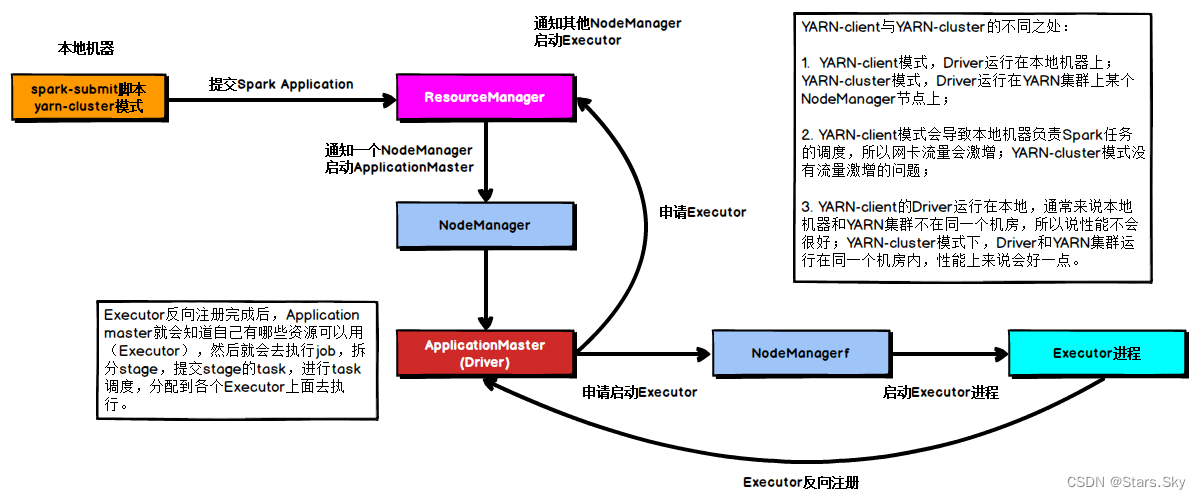
在 YARN Cluster 模式下,Driver 运行在 NodeManager Contanier 中,此时 Driver 与 AppMaster 合为一体,示意图如下:
具体流程步骤如下:
- 任务提交后会和 ResourceManager 通讯申请启动 ApplicationMaster;
- 随后 ResourceManager 分配 Container,在合适的 NodeManager 上启动 ApplicationMaster,此时的 ApplicationMaster 就是 Driver;
- Driver 启动后向 ResourceManager 申请 Executor 内存,ResourceManager 接到ApplicationMaster 的资源申请后会分配 Container,然后在合适的 NodeManager 上启动Executor 进程;
- Executor 进程启动后会向 Driver 反向注册;
- Executor 全部注册完成后 Driver 开始执行 main 函数,之后执行到 Action 算子时,触发一个 job,并根据宽依赖开始划分 stage,每个 stage 生成对应的 taskSet,之后将 task 分发到各个 Executor 上执行。

