
- 1多线程之线程之间的通信_多线程交互方式
- 2网络性能测试工具 iperf3_iperf3下载
- 3SpringBoot学习之用ResponseEntity批量下载压缩文件(五)
- 4线程之间通信、进程之间通信_carlos guo 881230
- 5git学习笔记——移除文件和移动文件_.gitignore将编译后的文件,日志文件移出
- 6基于知识图谱的个性化智能教学推荐系统(论文+源码)_kaic_基于知识图谱的课程推荐
- 7YOLOv5进阶 | 利用PyQt搭建YOLOv5目标检测系统(附可视化界面+功能介绍+源代码)_yolo界面
- 8R语言中的execl数据转plink
- 9个人收集的网站,可以参考(程序员可收藏)_java 算法类题目网站
- 10十一:redis之布隆过滤器的使用与应用场景_布隆过滤器在redis中的应用
ChromaDB教程_chromadb.client
赞
踩
使用 Chroma DB,管理文本文档、将文本嵌入以及进行相似度搜索。
随着大型语言模型 (LLM) 及其应用的兴起,我们看到向量数据库越来越受欢迎。这是因为使用 LLM 需要一种与传统机器学习模型不同的方法。
LLM 的核心支持技术之一是向量嵌入。虽然计算机不能直接理解文本,但嵌入以数字表示文本。所有用户提供的文本都将转换为嵌入,用于生成响应。
将文本转换为嵌入是一个耗时的过程。为了避免这种情况,我们使用专门设计的矢量数据库,用于有效存储和检索矢量嵌入。在本教程中,我们将了解矢量存储和 Chroma DB,这是一个用于存储和管理嵌入的开源数据库。此外,我们将学习如何添加和删除文档、执行相似性搜索以及将文本转换为嵌入。
什么是矢量存储?
向量存储是专门为有效地存储和检索向量嵌入而设计的数据库。之所以需要它们,是因为像 SQL 这样的传统数据库没有针对存储和查询大型向量数据进行优化。
嵌入在高维空间中以数字向量格式表示数据(通常是非结构化数据,如文本)。传统的关系数据库不太适合存储和搜索这些向量表示。
向量存储可以使用相似性算法对相似的向量进行索引和快速搜索。它允许应用程序在给定目标向量查询的情况下查找相关向量。
在个性化聊天机器人的情况下,用户输入生成式 AI 模型的提示。然后,该模型使用相似性搜索算法在文档集合中搜索相似文本。然后,由此产生的信息用于生成高度个性化和准确的响应。这是通过在向量存储中嵌入和向量索引来实现的。
什么是ChromaDB?
Chroma DB![]() https://docs.trychroma.com/ChromaDB是一个开源矢量存储,用于存储和检索矢量嵌入。它的主要用途是保存嵌入和元数据,以便以后由大型语言模型使用。此外,它还可用于文本数据的语义搜索引擎。
https://docs.trychroma.com/ChromaDB是一个开源矢量存储,用于存储和检索矢量嵌入。它的主要用途是保存嵌入和元数据,以便以后由大型语言模型使用。此外,它还可用于文本数据的语义搜索引擎。
Chroma DB主要特点:
- 支持不同的底层存储选项,例如用于独立的 DuckDB 或用于可扩展性的 ClickHouse。
- 提供 Python 和 JavaScript/TypeScript 的 SDK。
- 专注于简单性、速度和支持性分析。
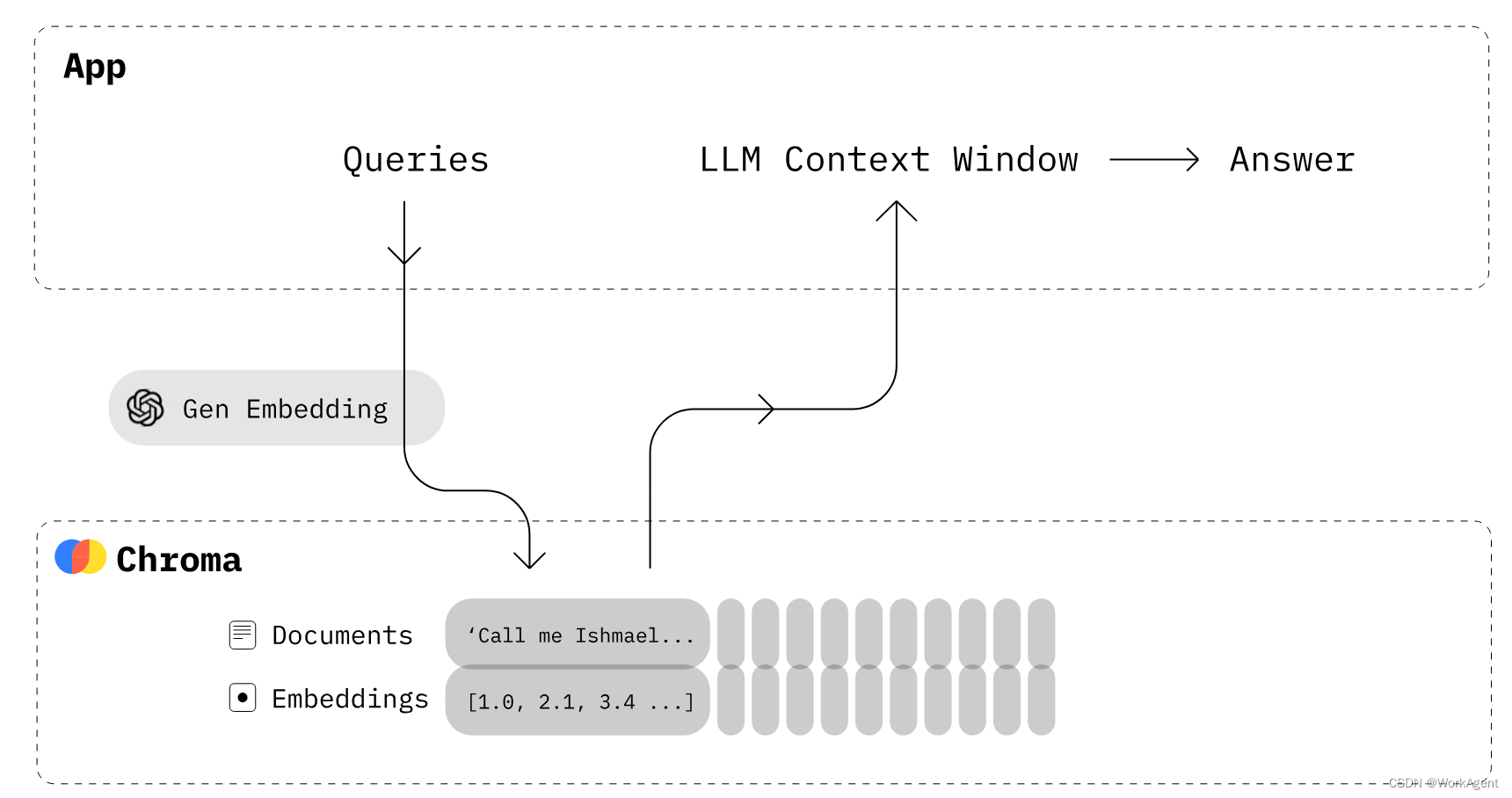
ChromaDB是如何工作的?
- 首先,必须创建一个类似于关系数据库中的表的集合。默认情况下,Chroma 使用 将文本转换为嵌入,但您可以修改集合以使用其他嵌入模型。
all-MiniLM-L6-v2 - 将具有元数据和唯一 ID 的文本文档添加到新创建的集合中。当您的收藏收到文本时,它会自动将其转换为嵌入。
- 通过文本或嵌入查询集合以接收相似的文档。您还可以根据元数据筛选出结果。
在下一部分中,我们将使用 Chroma 和 OpenAI API 来创建我们自己的矢量数据库。
ChromaDB入门
在本节中,将创建一个向量数据库,添加集合,向集合添加文本,并执行查询搜索。
首先,我们将为向量数据库和更好的嵌入模型安装。确保您已设置 OpenAI API 密钥。
注意:Chroma 需要 SQLite 3.35 或更高版本。如果遇到问题,请升级到 Python 3.11 或安装旧版本的Chroma
- # 环境安装
- !pip install chromadb openai
您可以通过创建不带设置的 Chroma DB 客户端来创建用于测试的内存数据库。
在我们的例子中,我们将创建一个持久数据库,该数据库将存储在“db/”目录中,并在后端使用 DuckDB。
- import chromadb
- from chromadb.config import Settings
-
- client = chromadb.Client(Settings(chroma_db_impl="duckdb+parquet",
- persist_directory="db/"
- ))
之后,我们将使用客户端创建一个集合对象。它类似于在传统数据库中创建表。
collection = client.create_collection(name="Students")为了将文本添加到我们的集合中,我们需要生成有关学生、俱乐部和大学的随机文本。您可以使用 ChatGPT 生成随机文本。这很简单。
- student_info = """
- Alexandra Thompson, a 19-year-old computer science sophomore with a 3.7 GPA,
- is a member of the programming and chess clubs who enjoys pizza, swimming, and hiking
- in her free time in hopes of working at a tech company after graduating from the University of Washington.
- """
-
- club_info = """
- The university chess club provides an outlet for students to come together and enjoy playing
- the classic strategy game of chess. Members of all skill levels are welcome, from beginners learning
- the rules to experienced tournament players. The club typically meets a few times per week to play casual games,
- participate in tournaments, analyze famous chess matches, and improve members' skills.
- """
-
- university_info = """
- The University of Washington, founded in 1861 in Seattle, is a public research university
- with over 45,000 students across three campuses in Seattle, Tacoma, and Bothell.
- As the flagship institution of the six public universities in Washington state,
- UW encompasses over 500 buildings and 20 million square feet of space,
- including one of the largest library systems in the world.

现在,我们将使用该函数添加带有元数据和唯一 ID 的文本数据。之后,Chroma 将自动下载模型以将文本转换为嵌入并将其存储在“Students”集合中。addall-MiniLM-L6-v2
- collection.add(
- documents = [student_info, club_info, university_info],
- metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
- ids = ["id1", "id2", "id3"]
- )
要运行相似性搜索,您可以使用该函数并以自然语言提问。它会将查询转换为嵌入,并使用相似性算法得出类似的结果。在我们的例子中,它返回了两个类似的结果。query
- results = collection.query(
- query_texts=["What is the student name?"],
- n_results=2
- )
-
- results

嵌入
使用其它模型
- from chromadb.utils import embedding_functions
- openai_ef = embedding_functions.OpenAIEmbeddingFunction(
- model_name="text-embedding-ada-002"
- )
- students_embeddings = openai_ef([student_info, club_info, university_info])
- print(students_embeddings)
更新和删除数据
就像关系数据库一样,您可以更新或删除集合中的值。为了更新文本和元数据,我们将提供记录和新文本的特定 ID。
- collection2.update(
- ids=["id1"],
- documents=["Kristiane Carina, a 19-year-old computer science sophomore with a 3.7 GPA"],
- metadatas=[{"source": "student info"}],
- )
运行一个简单的查询以检查是否已成功进行更改。
- results = collection2.query(
- query_texts=["What is the student name?"],
- n_results=2
- )
-
- results
验证结果
要从集合中删除记录,我们将使用“删除”功能并指定唯一 ID。
- collection2.delete(ids = ['id1'])
-
-
- results = collection2.query(
- query_texts=["What is the student name?"],
- n_results=2
- )
-
- results
学生信息文本已被删除;取而代之的是,我们得到了下一个最好的结果。

其它管理 操作
- # 创建客户端
- # client = chromadb.Client() 内存模式
- client = chromadb.PersistentClient(path="./chromac") # 数据保存在磁盘
- # chroma_client = chromadb.HttpClient(host="localhost", port=8000) docker客户端模式
- # 遍历集合
- client.list_collections()
- # 创建新集合
- collection = client.create_collection("testname")
- # 获取集合
- collection = client.get_collection("testname")
- # 创建或获取集合
- collection = client.get_or_create_collection("testname")
- # 删除集合
- client.delete_collection("testname")
- # 创建或获取集合
- collection = client.get_or_create_collection(name="my_collection2")
- # collection = client.create_collection(name="my_collection2")
- # collection = client.create_collection(name="my_collection", embedding_function=emb_fn)
- # collection = client.get_collection(name="my_collection", embedding_function=emb_fn)
- # Chroma集合创建时带有一个名称和一个可选的嵌入函数。如果提供了嵌入函数,则每次获取集合时都必须提供。
- # 获取集合中最新的5条数据
- collection.peek()
- # 添加数据
- collection.add(
- documents=["2022年2月2号,美国国防部宣布:将向欧洲增派部队,应对俄乌边境地区的紧张局势.", " 2月17号,乌克兰军方称:东部民间武装向政府军控制区发动炮击,而东部民间武装则指责乌政府军先动用了重型武器发动袭击,乌东地区紧张局势持续升级"],
- metadatas=[{"source": "my_source"}, {"source": "my_source"}],
- ids=["id1", "id2"]
- )
- # 如果 Chroma 收到一个文档列表,它会自动标记并使用集合的嵌入函数嵌入这些文档(如果在创建集合时没有提供嵌入函数,则使用默认值)。Chroma也会存储文档本身。如果文档过大,无法使用所选的嵌入函数嵌入,则会出现异常。
- # 每个文档必须有一个唯一的相关ID。尝试.添加相同的ID两次将导致错误。可以为每个文档提供一个可选的元数据字典列表,以存储附加信息并进行过滤。
- # 或者,您也可以直接提供文档相关嵌入的列表,Chroma将存储相关文档,而不会自行嵌入。
- # collection.add(
- # embeddings=[[1.2, 2.3, 4.5], [6.7, 8.2, 9.2]],
- # documents=["This is a document", "This is another document"],
- # metadatas=[{"source": "my_source"}, {"source": "my_source"}],
- # ids=["id1", "id2"]
- # )
- # 改数据
- # 更新所提供 id 的嵌入、元数据或文档。
- def update(ids: OneOrMany[ID],
- embeddings: Optional[OneOrMany[Embedding]] = None,
- metadatas: Optional[OneOrMany[Metadata]] = None,
- documents: Optional[OneOrMany[Document]] = None) -> None
- # 更新所提供 id 的嵌入、元数据或文档,如果不存在,则创建它们。
- def upsert(ids: OneOrMany[ID],
- embeddings: Optional[OneOrMany[Embedding]] = None,
- metadatas: Optional[OneOrMany[Metadata]] = None,
- documents: Optional[OneOrMany[Document]] = None) -> None
- # 删除数据
- # 根据 ID 和/或 where 过滤器删除嵌入数据
- def delete(ids: Optional[IDs] = None,
- where: Optional[Where] = None,
- where_document: Optional[WhereDocument] = None) -> None
- # collection.delete(ids=["3", "4", "5"])
- # 查询数据
- results = collection.query(
- query_embeddings=[[11.1, 12.1, 13.1],[1.1, 2.3, 3.2], ...],
- n_results=10,
- where={"metadata_field": "is_equal_to_this"},
- where_document={"$contains":"search_string"}
- )
- 或者:
- results = collection.query(
- query_texts=["俄乌战争发生在哪天?"],
- n_results=2
- )
- print(156, results)
- 156 {'ids': [['id1', 'id2']], 'embeddings': None, 'documents': [['2022年2月2号,美国国防部宣布:将向欧洲增派部队,应对俄乌边境地区的紧张局势.',
- ' 2月17号,乌克兰军方称:东部民间武装向政府军控制区发动炮击,而东部民间武装则指责乌政府军先动用了重型武器发动袭击,乌东地区紧张局势持续升级']],
- 'metadatas': [[{'source': 'my_source'}, {'source': 'my_source'}]], 'distances': [[1.2127416133880615, 1.3881784677505493]]}
LangChanWithChromaDB
接下来查看LangChain中结合ChromaDB使用
- # /home/knowqa/know_env/lib/python3.10/site-packages/langchain/vectorstores
- from langchain.vectorstores import Chroma
-
- # langchain 默认文档 collections [Collection(name=langchain)]
- # 持久化数据
- persist_directory = './chromadb'
- vectordb = Chroma.from_documents(documents=docs, embedding=embedding, persist_directory=persist_directory)
- vectordb.persist()
- # 直接加载数据
- vectordb = Chroma(persist_directory="./chromadb", embedding_function=embeddings)
- eg:
- from langchain.embeddings.openai import OpenAIEmbeddings
- from langchain.text_splitter import CharacterTextSplitter
- from langchain.vectorstores import Chroma
- from langchain.document_loaders import TextLoader
- import os
- os.environ["OPENAI_API_KEY"] = 'sk-xxxxxx'
- loader = TextLoader('./russia.txt', encoding='gbk') #中文必须带 encoding='gbk'
- documents = loader.load()
- text_splitter = CharacterTextSplitter(chunk_size=400, chunk_overlap=0)
- # chunk_size=1000表示每次读取或写入数据时,数据的大小为400个字节, 约200~400个汉字
- # 对于英文LangChain一般会使用RecursiveCharacterTextSplitter处理。由于中文的复杂性,会使用到jieba等处理工具预处理中文语句。
- docs = text_splitter.split_documents(documents)
- embedding = OpenAIEmbeddings()
- vectordb = Chroma.from_documents(docs, embeddings)
- query = "What did the president say about Ketanji Brown Jackson"
- docs = vectordb.similarity_search(query)
- print(docs[0].page_content) # 默认是返回4条数据, k=4
- # 直接加载数据库,然后查询相似度的文本
- vectordb = Chroma(persist_directory=persist_directory, embedding_function=embedding)
- query = "On what date did the war between Russia and Ukraine take place?"
- retriever = vectordb.as_retriever(search_type="mmr")
- s = retriever.get_relevant_documents(query)
- print(123, s)
- /
- 123 [Document(page_content='加意见和建议...乌克兰的战争”标语。', metadata={'source': './russiaX.pdf'}), Document(page_content='综合路透社、雅..导弹。', metadata={'source': './russiaX.pdf'}), Document(page_content='乌克兰东部问....
- print(556, s[0].page_content) # 选第一条的内容
- # 或者这样查询
- s = vectordb.similarity_search(query)
- # print(s[0].page_content)
- # 特别注意
- 在存入数据后有时不能立即查到新添加的数据,此时,关停后重启加载即可!
- # 直接用get获取数据
- res = vectordb.get(limit=2)
- print(266, res)
- //266 {'ids': ['e8661882-358c-11ee-a7f1-fb75c83274a1', 'e8661883-358c-11ee-a7f1-fb75c83274a1'], 'embeddings': None, 'metadatas': [{'source': './uploads/dazhihui.txt'}, {'source': './uploads/dazhihui.txt'}], 'documents': ['大智汇健康科技...', '二、团队介绍...']}
ChromaDB
像Chroma DB这样的向量存储正在成为大型语言模型系统的重要组成部分。通过提供专用的存储和向量嵌入的高效检索,它们能够快速访问相关的语义信息,从而为 LLM 提供支持。
在本色度数据库教程中,我们介绍了创建集合、添加文档、将文本转换为嵌入、查询语义相似性以及管理集合的基础知识。


