
热门标签
热门文章
- 1最新dataSophon1.1.2保姆级安装
- 2Ubuntu 24.04 Preview 版安装 libtinfo5
- 3Navicat mac 14天体验删除命令_navicat premium 14天试用
- 4MySQL的数据备份和恢复
- 5superset使用教程(2)_superset中文教程官网
- 6超强AI绘画Midjourney-关键词(示例)
- 7ADOP告诉您 2024年人工智能是什么?它的类型、趋势和未来?下篇
- 8前段json数据到后端接收_前端传入json 后端可以用@requestparm接受吗
- 9自己实现 SpringMVC 底层机制 系列之搭建 SpringMVC 底层机制开发环境和开发 WyxDispatcherServlet_如何将controller注入spring容器中
- 10rabbitmq_management_rabbitmq-management
当前位置: article > 正文
现代神经网络总结(AlexNet VGG GoogleNet ResNet的区别与改进)
作者:很楠不爱3 | 2024-04-29 07:13:44
赞
踩
现代神经网络总结(AlexNet VGG GoogleNet ResNet的区别与改进)
VGG NIN GoogleNet
1.VGG,NIN,GoogleNet的块结构图对比(注意:无AlexNet)
![![[1713922184273.png]]](https://img-blog.csdnimg.cn/direct/14d1d507839c4903b9f42d6187d8df1f.png)
这些块带来的区别与细节
AlexNet未使用块,主要对各个层进行了解: 卷积:捕捉特征 relu:增强非线性 池化层:减少计算量 norm:规范数据分布 全连接层:分类 VGG块的改善(对比AlexNet): 1.使用VGG块,更加的符合封装思想 2.VGG块使用更小的卷积核,可以捕捉更多细节 3.因为不断累加VGG块的原因,使得VGG可以比AlexNet更深 4.输入输出形状更加有规律 NIN块的改善(对比VGG): 1.训练的参数更少,且捕捉了更深的特征(使用了1x1卷积) 2.减少了模型中的参数数量(全局平均池化层) 原因:参数共享(可以查看参考视频,方便理解) Googlenet(对比VGG): 1.带来了多种卷积对应的多种特征(既不同尺度下的特征)(同一层内并行地应用多种卷积核尺寸和池化操作)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
3.7 特征图尺寸计算与参数共享_哔哩哔哩_bilibili
2.代码对比
AlexNet:
代码块:(卷积+最大池化层)
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2)
输出:(全连接分类)
nn.Flatten(),
nn.Linear(6400, 4096), nn.ReLU()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
VGG
代码块:(n层卷积层+1层最大池化层)
nn.Conv2d(in_channels, out_channels,kernel_size=3, padding=1)
nn.ReLU()
nn.MaxPool2d(kernel_size=2,stride=2)
输出:(全连接层)
nn.Flatten(),
nn.Linear(6400, 4096), nn.ReLU()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
NIN
代码块:(卷积层+2个1x1卷积核组成的卷积层)
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU()
输出:(NIN块+最大池化层+flatten)
nin_block(384, 10, kernel_size=3, strides=1, padding=1),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
GoogleNet
代码块:(线路1+线路2+线路3+线路4的结果横向拼接)
torch.cat((p1, p2, p3, p4), dim=1)
输出:(最后是全连接层)
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
- 1
- 2
- 3
- 4
- 5
- 6
7.4. 含并行连结的网络(GoogLeNet) — 动手学深度学习 2.0.0 documentation (d2l.ai)
注意:
以上所有得到的的都是分类映射,一般要再经过一次softmax才能得到分类结果,但softmax一般包含再网络定义的损失函数中了 既:
loss = nn.CrossEntropyLoss()时 softmax会被自动调用
- 1
- 2
ResNet
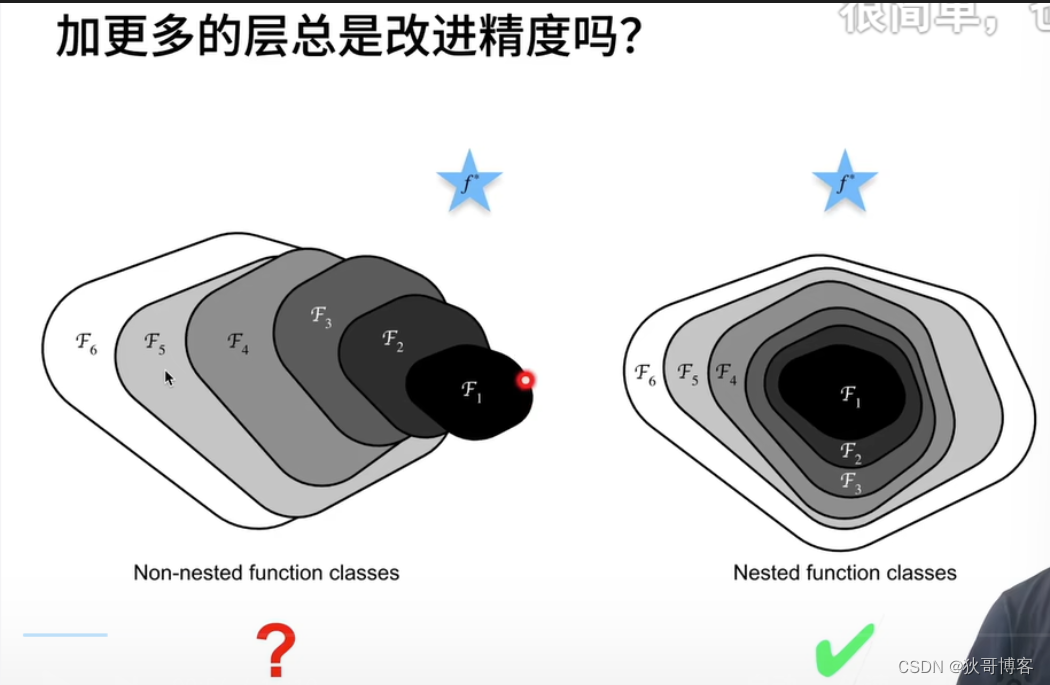
在上面三层神经网络之后得到的疑惑
->神经网络越深,越复杂总能改进精度吗?
如沐神的图,F1,F2的范围指的是对应网络的取值,f指的是真实值。
神经网络复杂度F1<F2,但是可以很明显看到F3没有F4复杂,但是F3离真实值更近。
所以答案是否定的
为了让神经网络越深,越复杂总能改进精度实现,如图2的思想就能满足,其实很简单:F2总是比F1取值范围大且F2包含F1就好了,既f(x)+x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
ResNet的表现是:
![![[1714099509490.png]]](https://img-blog.csdnimg.cn/direct/fe618c2f76ff4f4a81d218a171590a11.png)
注意:
1.如果f(x)与x的通道数不同 使用1X1卷积来改变通道数
2.如果f(x)与x的高宽不同 使用padding=0来扩充高宽
- 1
- 2
- 3
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/很楠不爱3/article/detail/506532
推荐阅读
相关标签

