- 1什么是PMP证书
- 2vue前后端分离单点登录,结合长token和短token进行登录_vue 单点登录
- 3github建立project
- 4CnOCR 使用教程
- 5打开MySQL数据库出现错误:ERROR 2003 (HY000): Can‘t connect to MySQL server on ‘localhost:3306‘ (10061)的解决办法_mysql hy000
- 6每周分享第 1 期_每周知识分享
- 7数学符号——指示函数(样子像空心的1的一个数学符号)
- 8android自动更新nitz,手机时间、夏令时及Android时间更新方式
- 9零成本使用Grass赚钱,简化教程,一学就会_grass插件下载
- 10用OpenCV唤醒你的摄像头——捕捉世界的美丽瞬间_opencv打开摄像头并捕捉图像
Scala及Spark安装及部署_安装spark2.11
赞
踩
在Linux下安装Scala
下载方式
1.百度网盘
链接:https://pan.baidu.com/s/1iWD6wVCHhDyohoqlP-ellA?pwd=1lg0
提取码:1lg0
2.官网下载
下载地址:https://www.scala-lang.org/download/2.11.8.html
解压安装
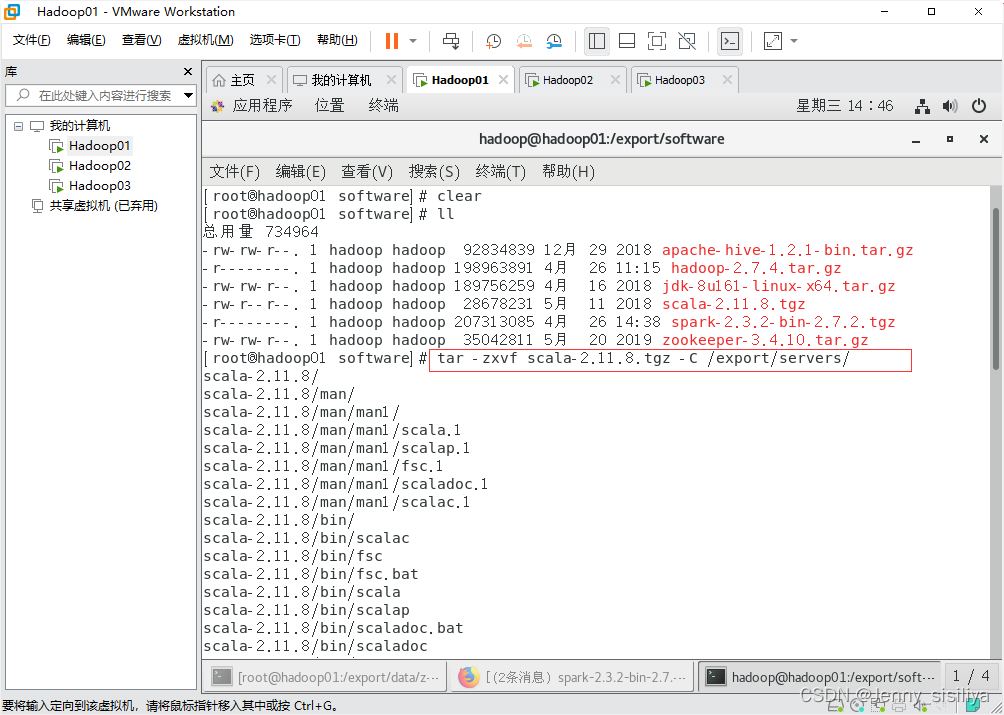
1.通过tar -zxvf 压缩包名称 -C 解压后文件所在位置命令将其文件解压到/export/servers/目录下。
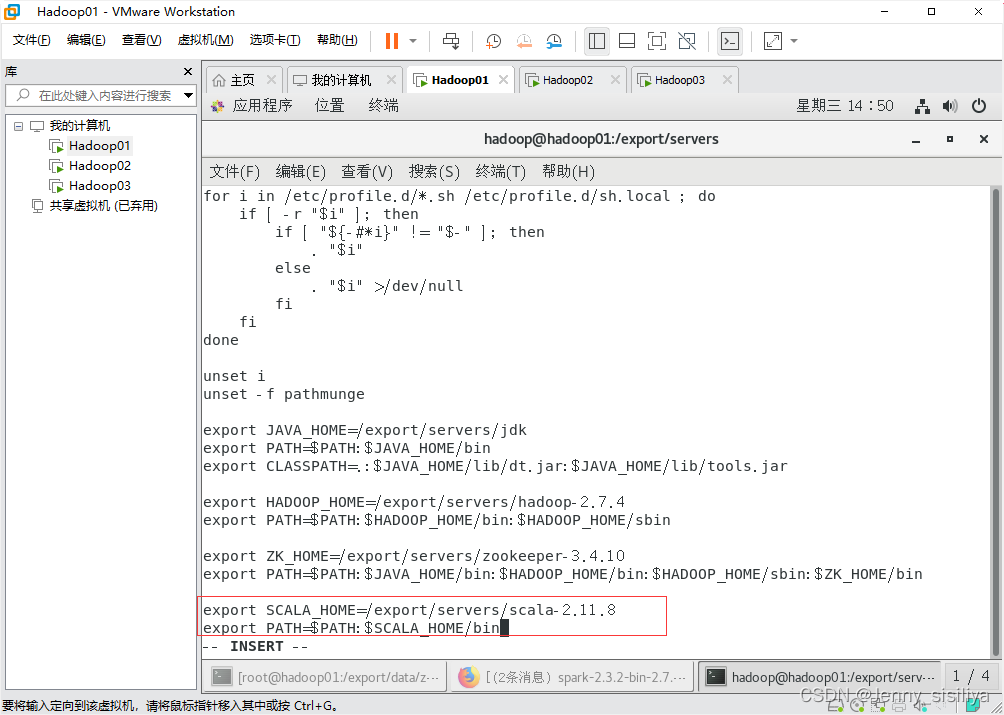
2.执行vi /etc/profile命令,进入Linux环境变量的配置文件中,添加scala环境变量,具体内容如下:
export SCALA_HOME=/export/servers/scala-2.11.8
export PATH=$PATH:$SCALA_HOME/bin
- 1
- 2
3.执行source /etc/profile命令生效环境变量。
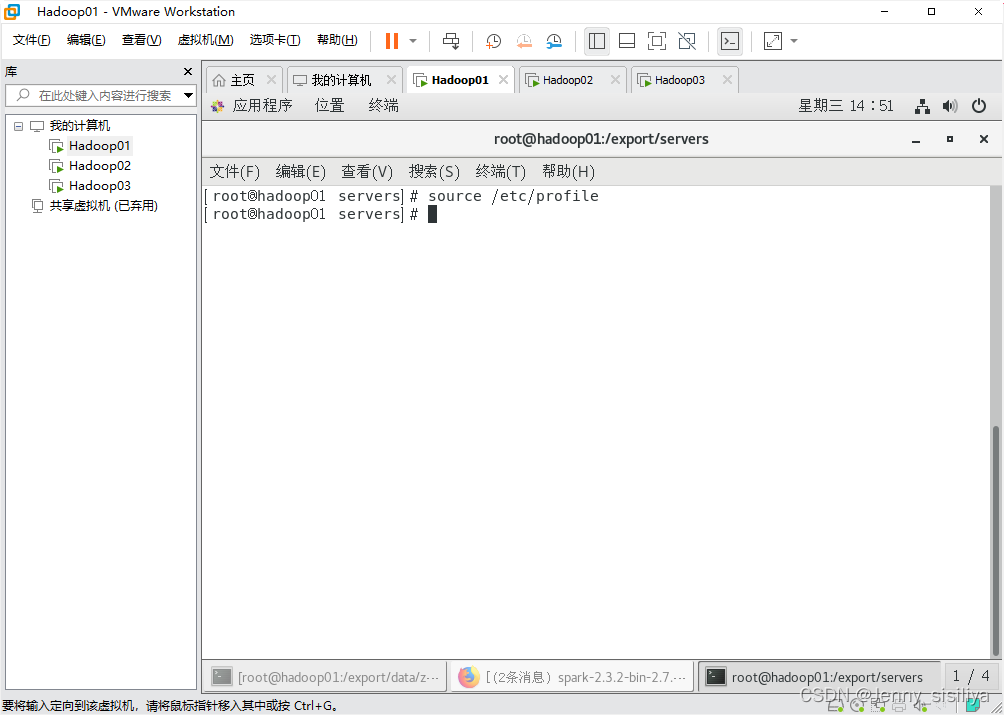
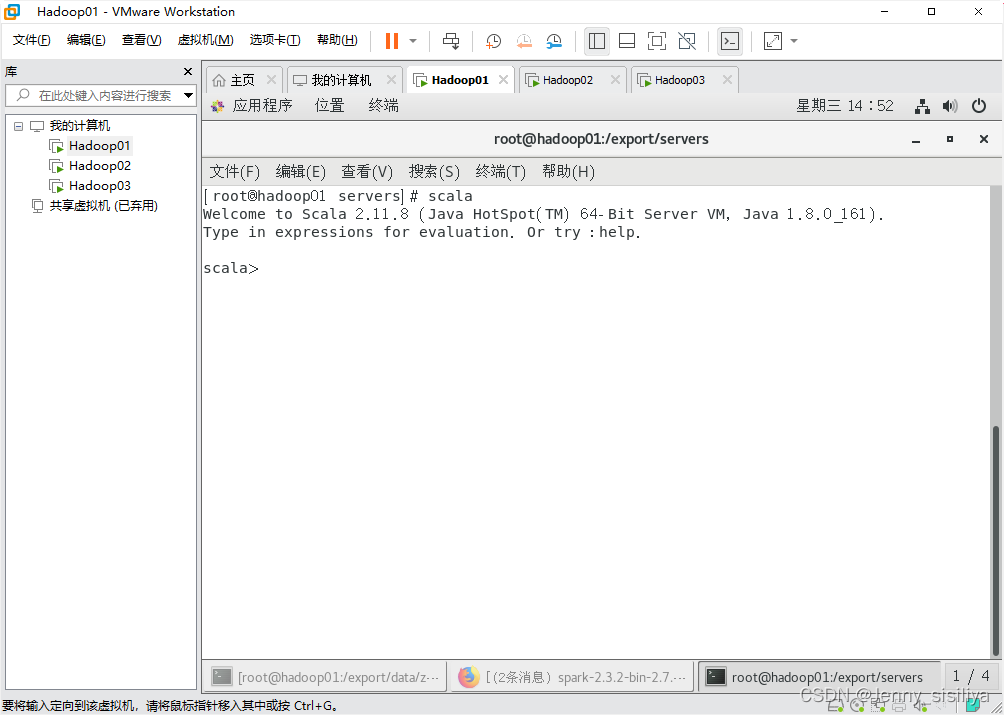
4.通过scala查看版本信息。
Spark集群安装部署
下载方式
1.百度网盘:
链接:https://pan.baidu.com/s/1uhvb41oQ0BKM1TujiozMZw?pwd=lsg5
提取码:lsg5
2.官网下载:
下载地址:https://spark.apache.org/downloads.html
解压Spark安装包
1.通过tar -zxvf 压缩包名称 -C 解压后文件所在位置命令将其文件解压到/export/servers/目录下。
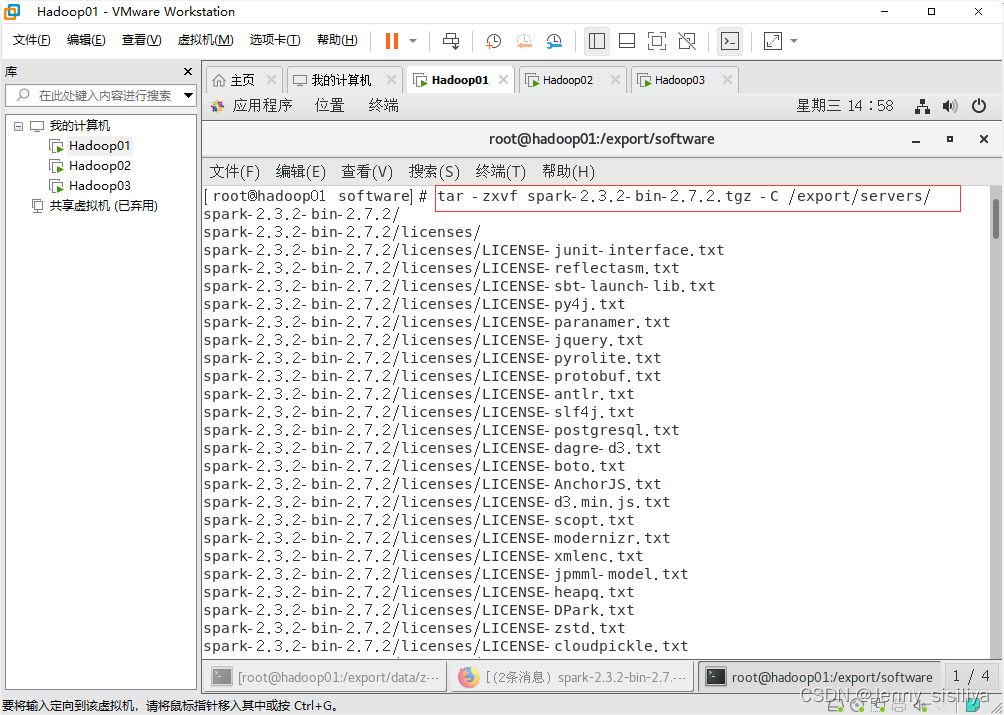
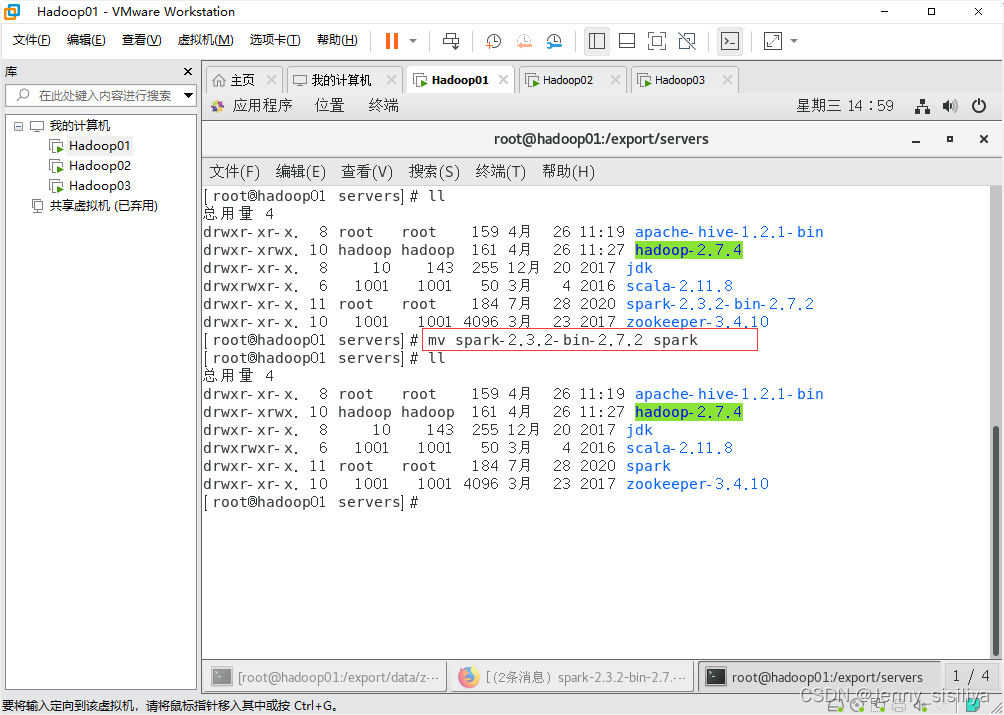
2.通过mv spark-2.3.2-bin-2.7.2 spark命令将spark的目录重命名为spark。
修改配置文件
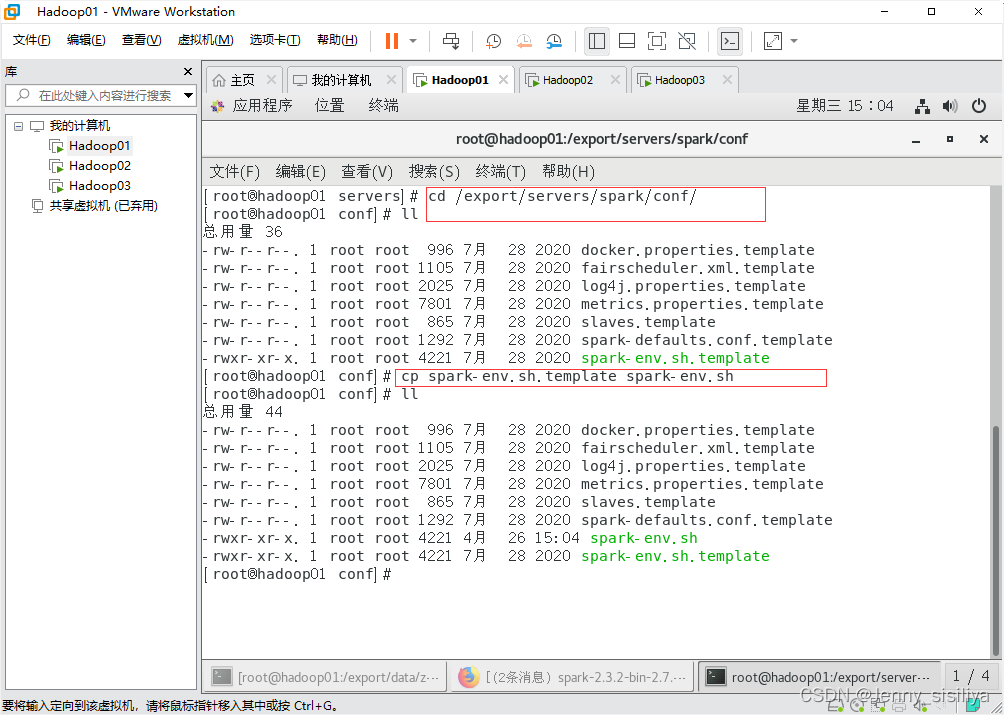
1.进入spark/conf目录修改spark的配置文件spark-env.sh,将spark-env.sh.template配置模板文件复制一份并重命名spark-env.sh,具体命令如下。
cd /export/servers/spark/conf/ --到spark/conf目录下
cp spark-env.sh.template spark-env.sh
- 1
- 2
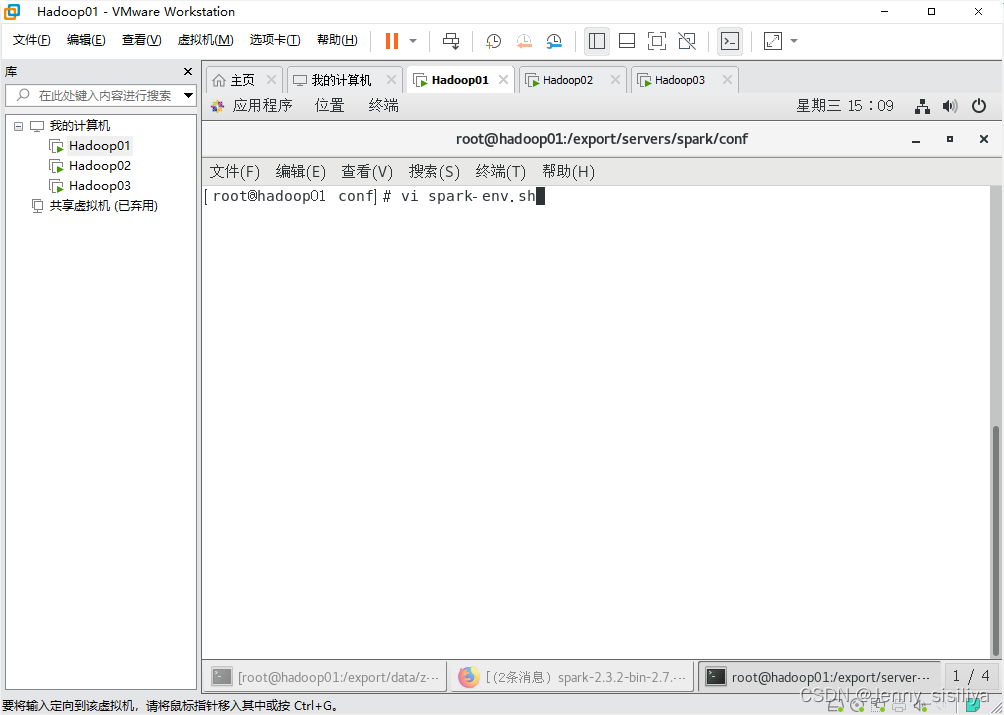
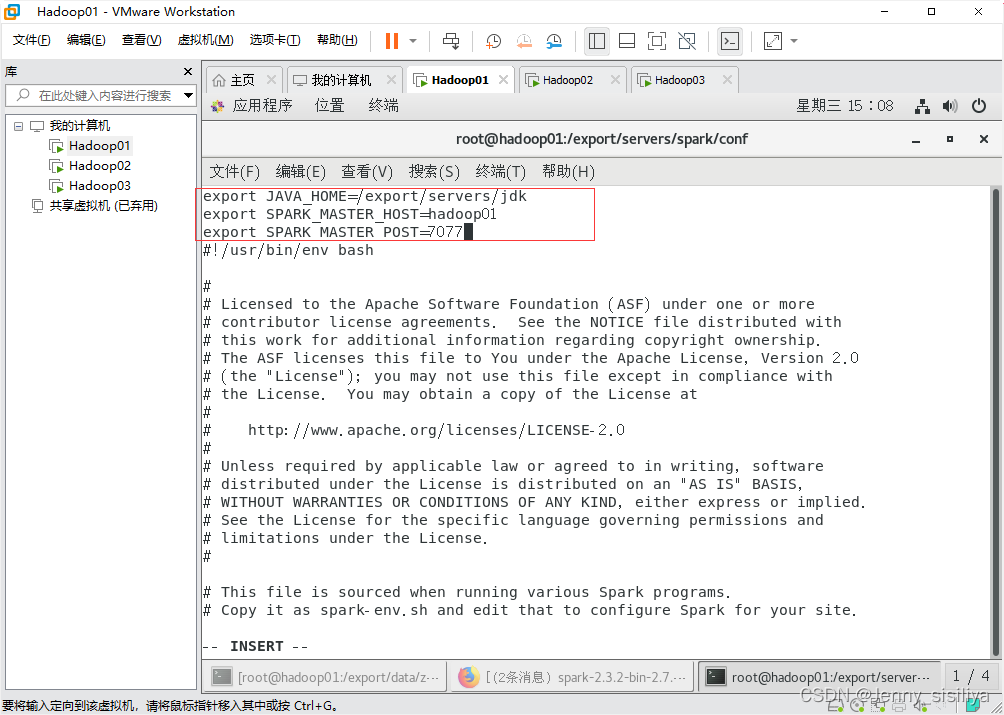
2.执行vi spark-env.sh命令,修改spark-env.sh文件,在该文件中添加以下内容:
export JAVA_HOME=/export/servers/jdk
export SPARK_MASTER_HOST=hadoop01
export SPARK_MASTER_POST=7077
- 1
- 2
- 3
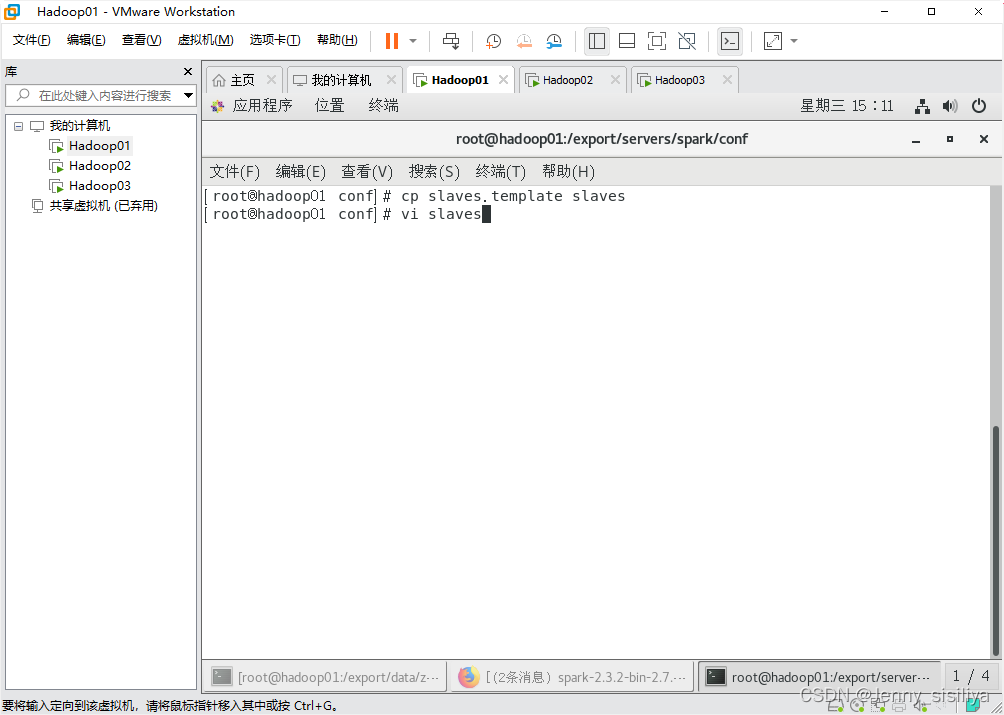
3.执行cp slaves.template slaves命令复制slaves.template文件,重命名为slaves,再通过vi slaves命令向其里面添加以下内容:
hadoop02
hadoop03
- 1
- 2
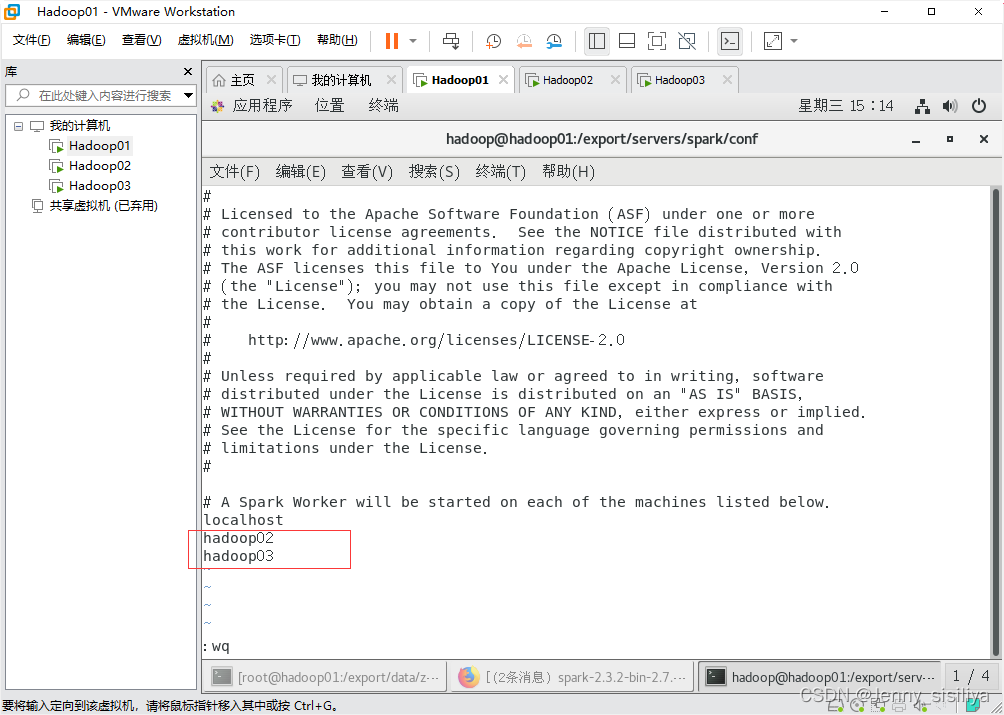
分发文件
修改完成配置文件后,将spark目录分发至hadoop02和hadoop03节点,具体命令如下:
scp -r /export/servers/spark/ hadoop02:/export/servers/
scp -r /export/servers/spark/ hadoop03:/export/servers/
- 1
- 2
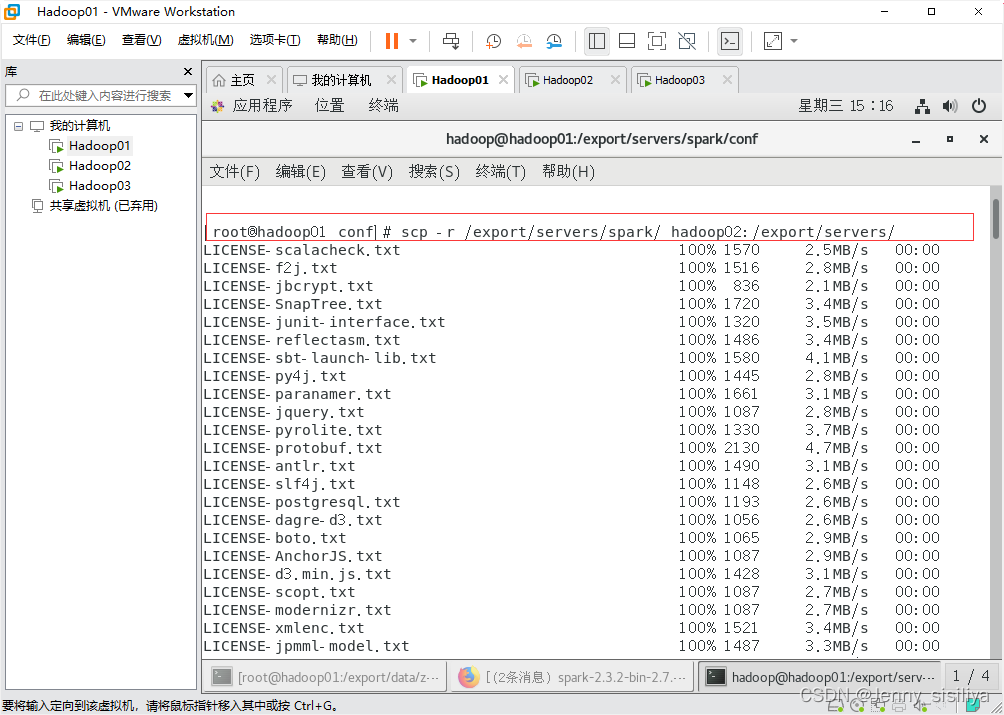
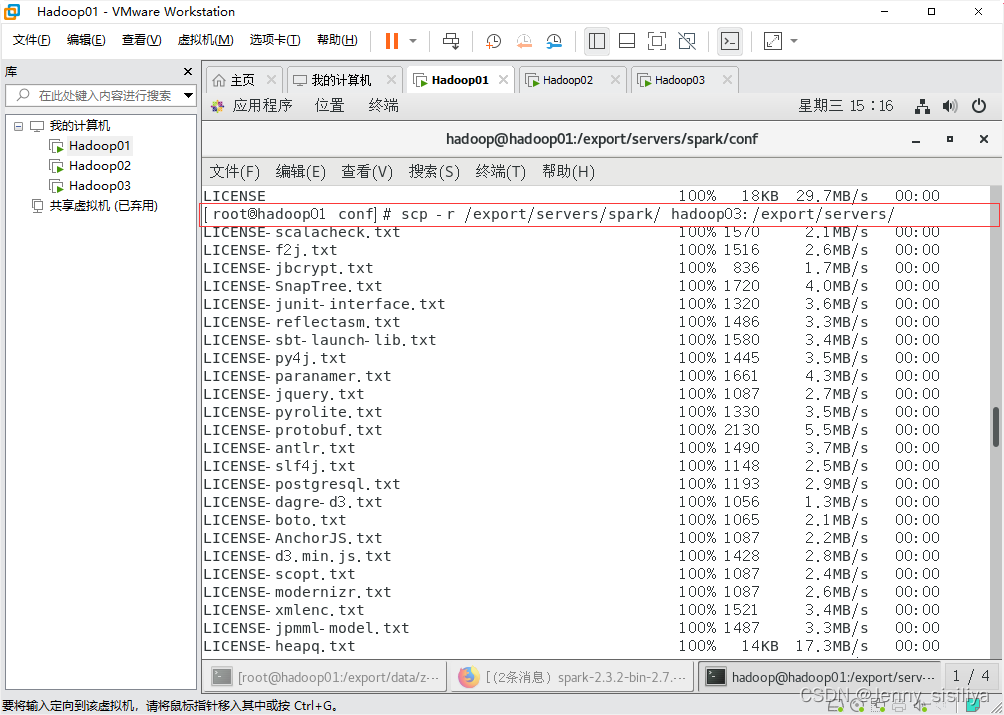
启动Spark集群
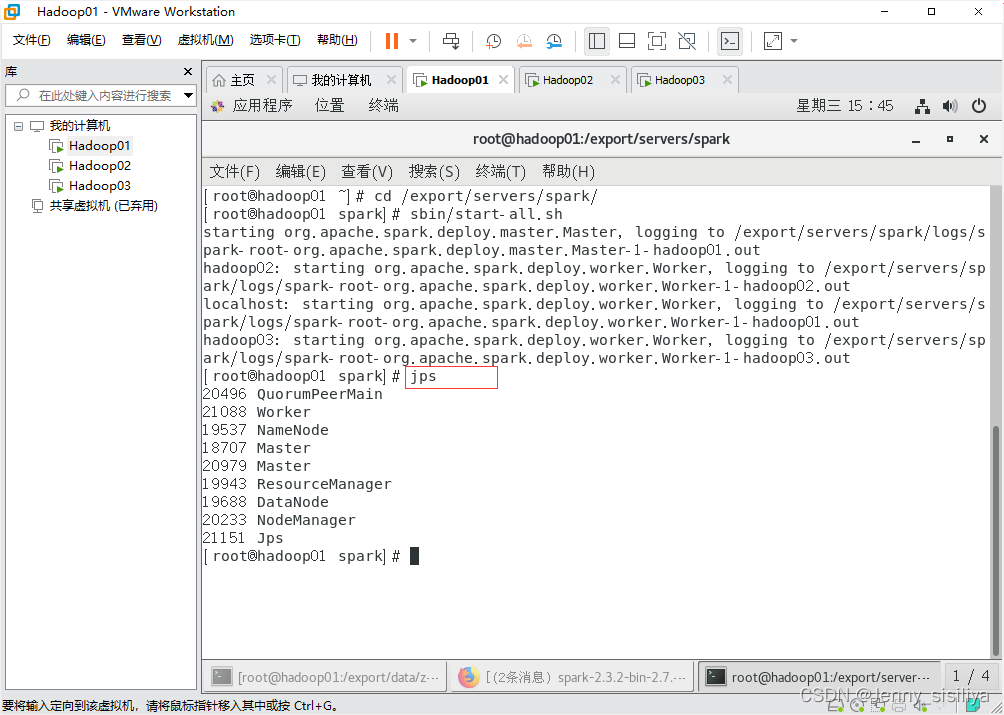
1.执行cd /export/servers/spark/命令进入Spark目录,通过sbin/start-all.sh命令启动Spark集群
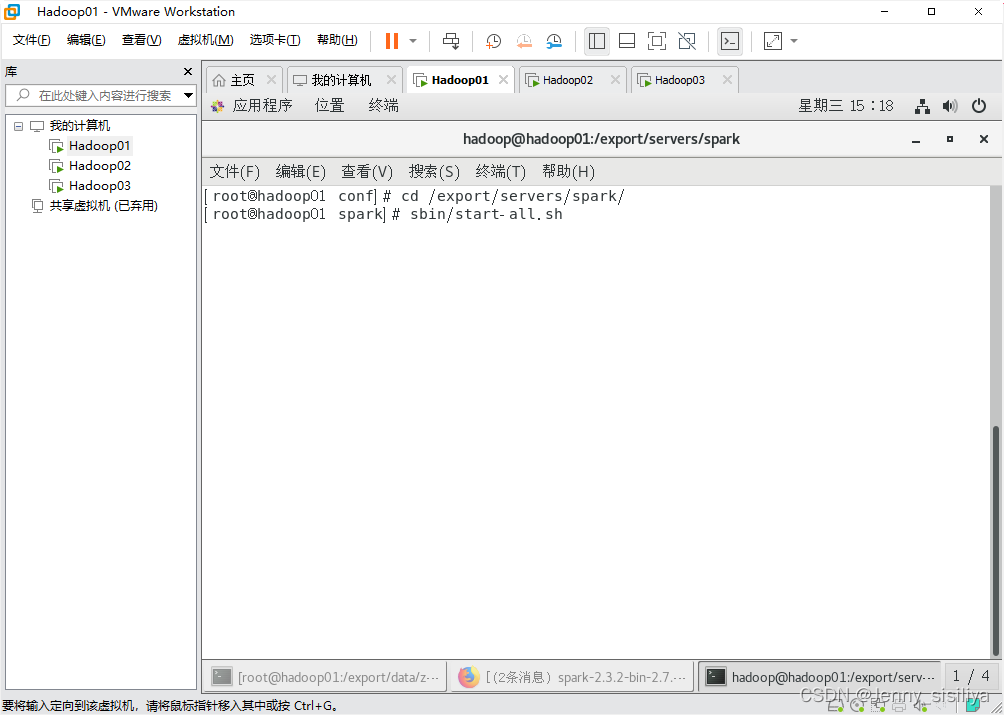
2.通过jps指令查看进程启动情况。
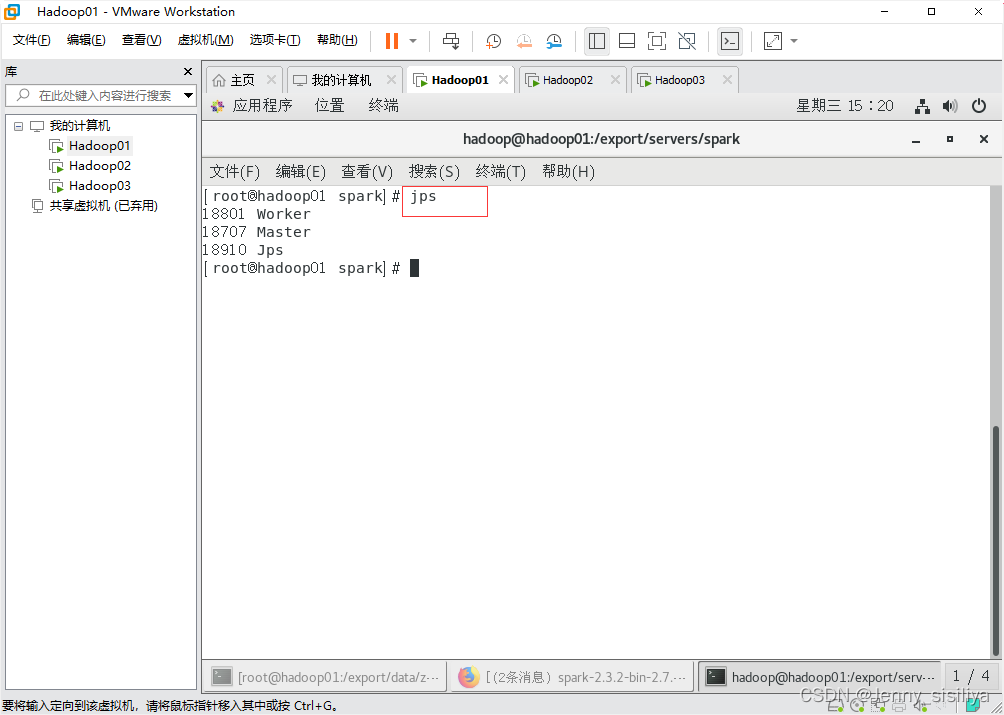
Spark HA集群部署
配置文件
1.首先,需要配置好zoo.cfg配置文件。
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/export/data/zookeeper/zkdata
clientPort=2181
server.1=hadoop01:2888:3888
server.2=hadoop02:2888:3888
server.3=hadoop03:2888:3888
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.修改spark-env.sh配置文件。
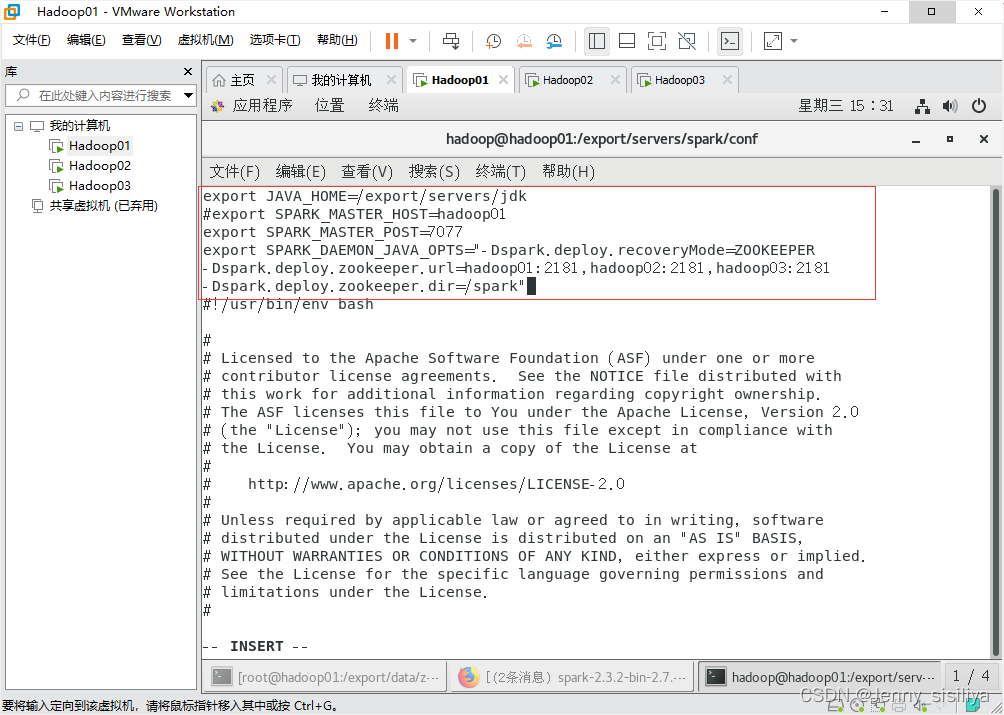
执行vi spark-env.sh命令,修改spark-env.sh文件,在该文件中添加以下内容:(注:将SPARK_MASTER_HOST配置参数前用#注释掉)
export JAVA_HOME=/export/servers/jdk
#export SPARK_MASTER_HOST=hadoop01
export SPARK_MASTER_POST=7077
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop01:2181,hadoop02:2181,hadoop03:2181
-Dspark.deploy.zookeeper.dir=/spark"
- 1
- 2
- 3
- 4
- 5
- 6
分发文件
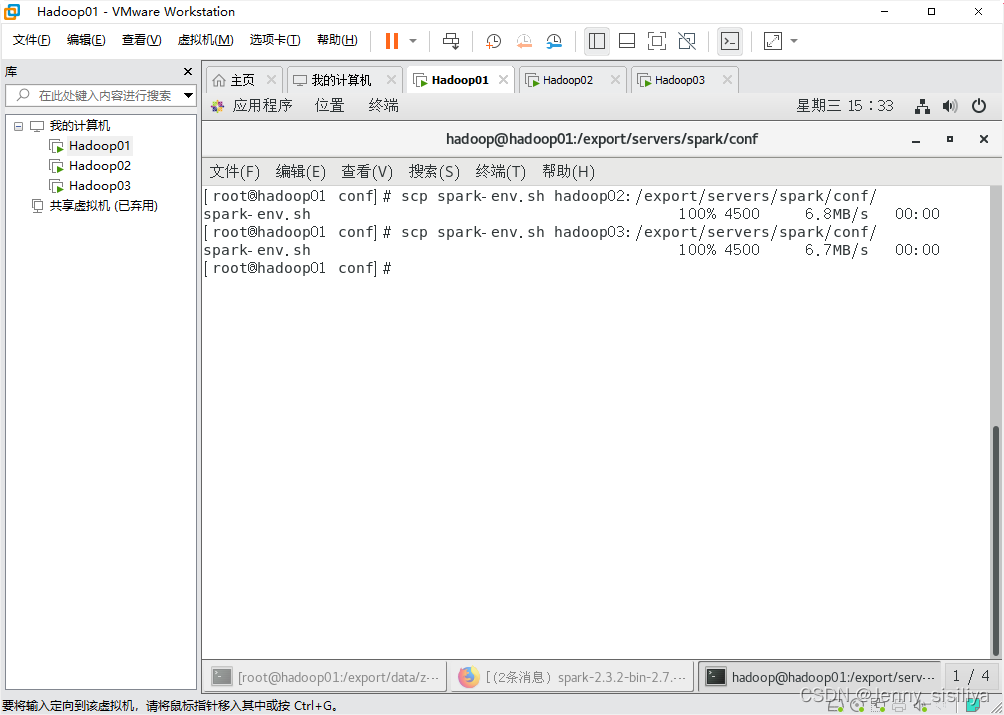
修改完成配置文件后,将spark-env.sh文件分发至hadoop02和hadoop03节点,具体命令如下:
scp spark-env.sh hadoop02:/export/servers/spark/conf/
scp spark-env.sh hadoop03:/export/servers/spark/conf/
- 1
- 2
启动Spark HA集群
1.执行zkServer.sh start命令依次启动Zookeeper服务。
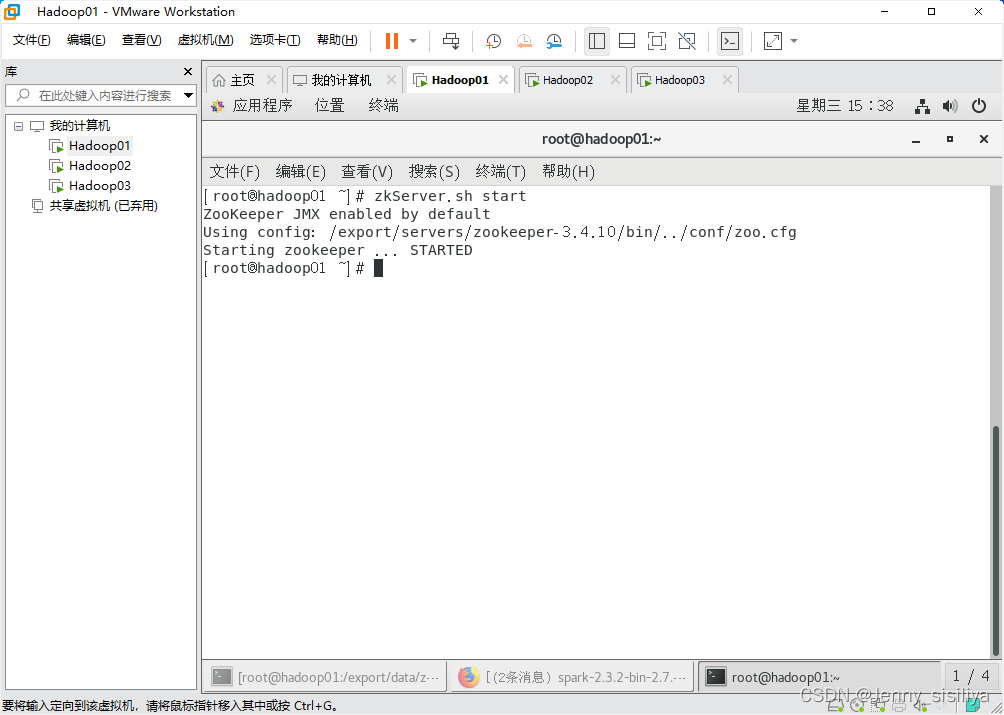
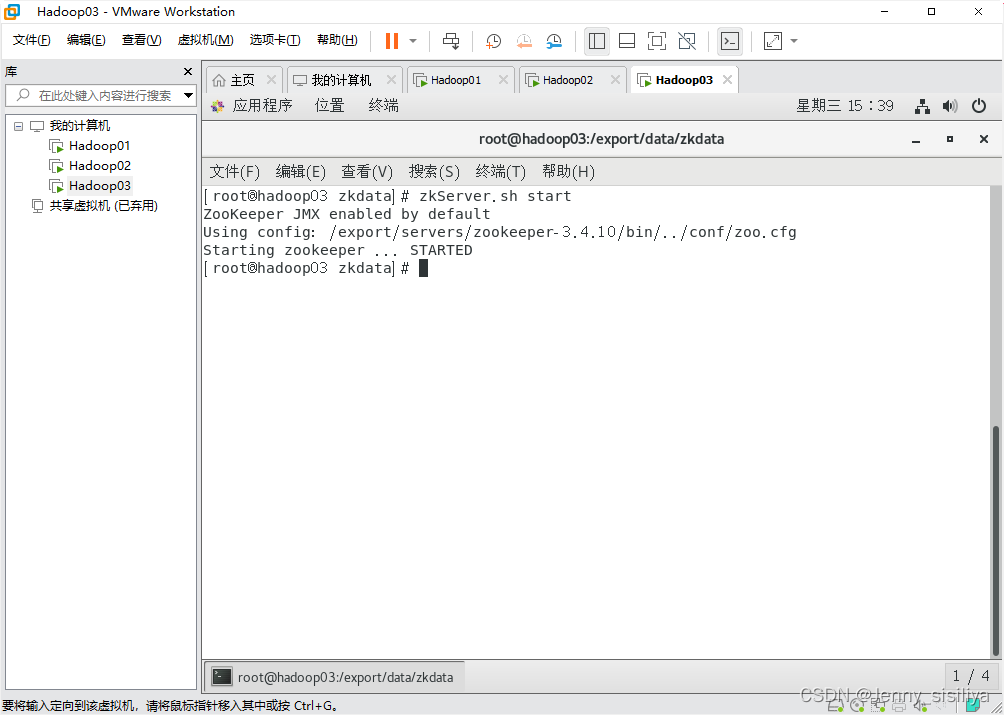
2.执行cd /export/servers/spark命令进入spark目录下通过sbin/start-all.sh命令启动Spark集群。
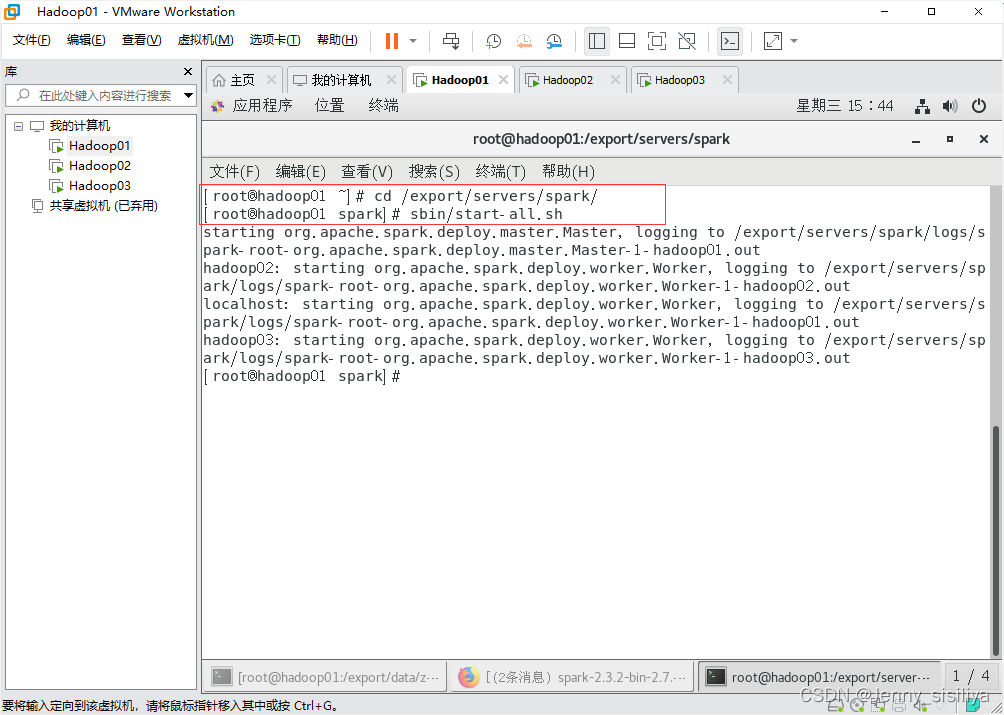
3.通过jps指令查看进程启动情况。