
- 1USP技术提升大语言模型的零样本学习能力
- 2大数据与机器学习:结合实践与技术
- 3update 还原到5分钟前_用好这3个公式,即兴演讲前那忐忑的5分钟,我再也不恐慌了...
- 4数据安全分类分级怎么搞?国家标准来了!(附全文)
- 5flink内存调优小记录_flink 内存
- 6机器学习之基于Python多种混合模型的糖尿病预测
- 7最新Ai写作创作系统源码+Ai绘画系统源码+搭建部署教程+支持GPT4.0+支持Prompt预设应用+思维导图生成_写作网 源码
- 8MySQL的卸载与安装(Linux)_linux卸载mysql
- 9hive 常用参数、参数优化_set hive(1)
- 10ARM Linux 下 编译 AWS SDK for C++ S3 连接minio及注意事项_交叉编译 aws sdk for c++ s3
IDEA开发Spark应用实战(Scala)
赞
踩
- 去spark官网下载spark安装包,里面有开发时所需的库,如下图,地址是:http://spark.apache.org/downloads.html
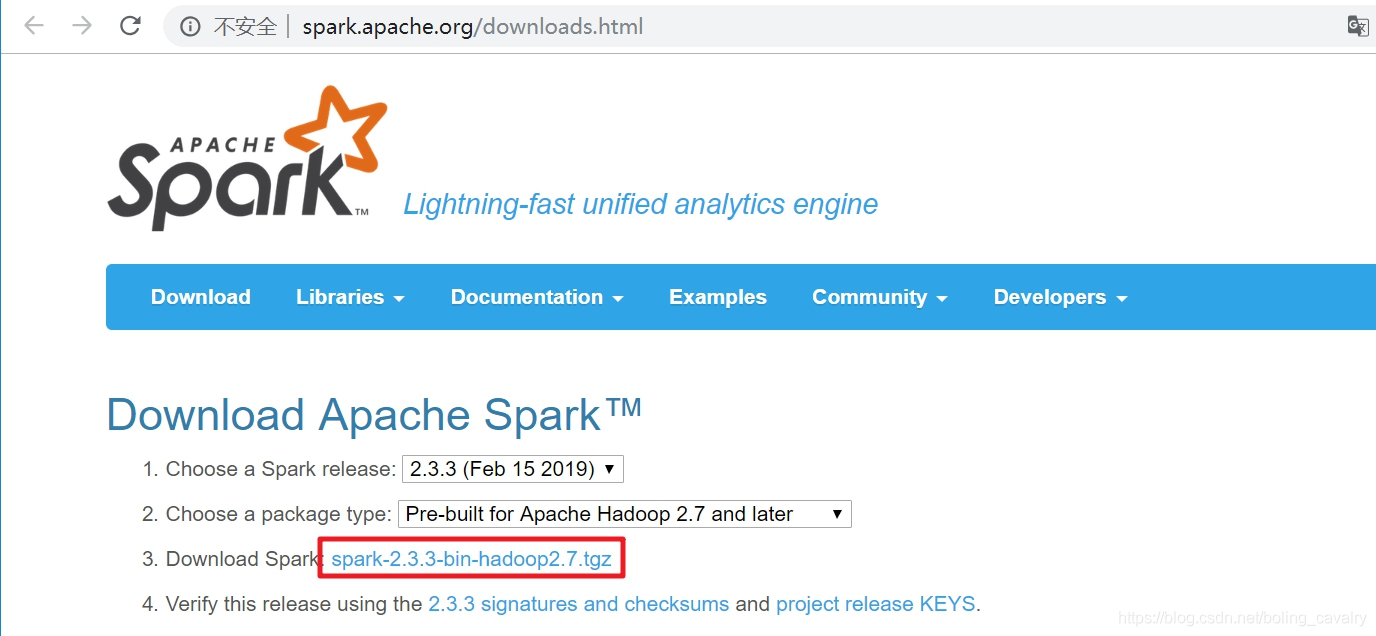
- 将下载好的文件解压,例如我这里解压后所在目录是:C:\software\spark-2.3.3-bin-hadoop2.7
IDEA安装scala插件
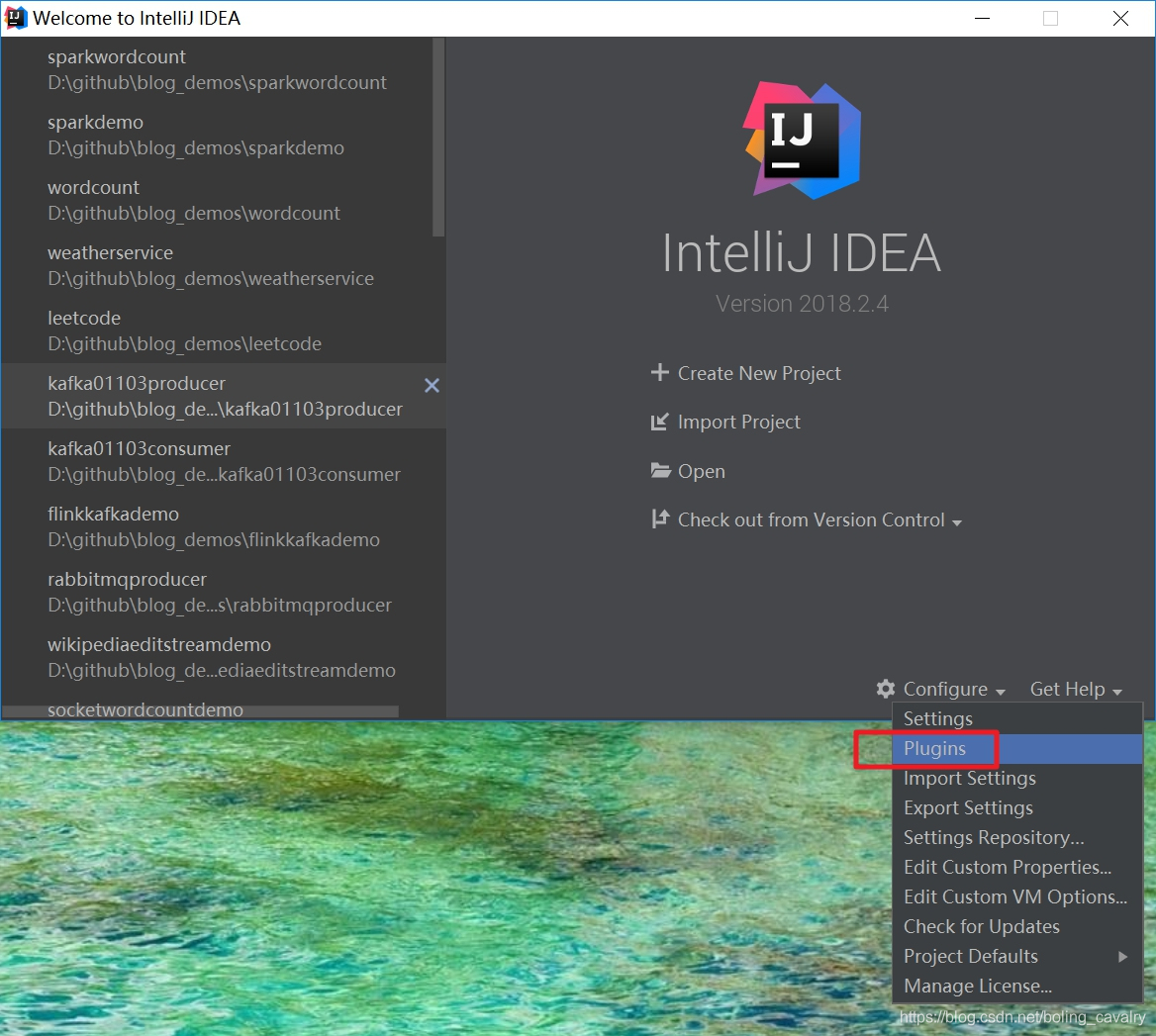
- 打开IDEA,选择"Configure"->“Plugins”,如下图:
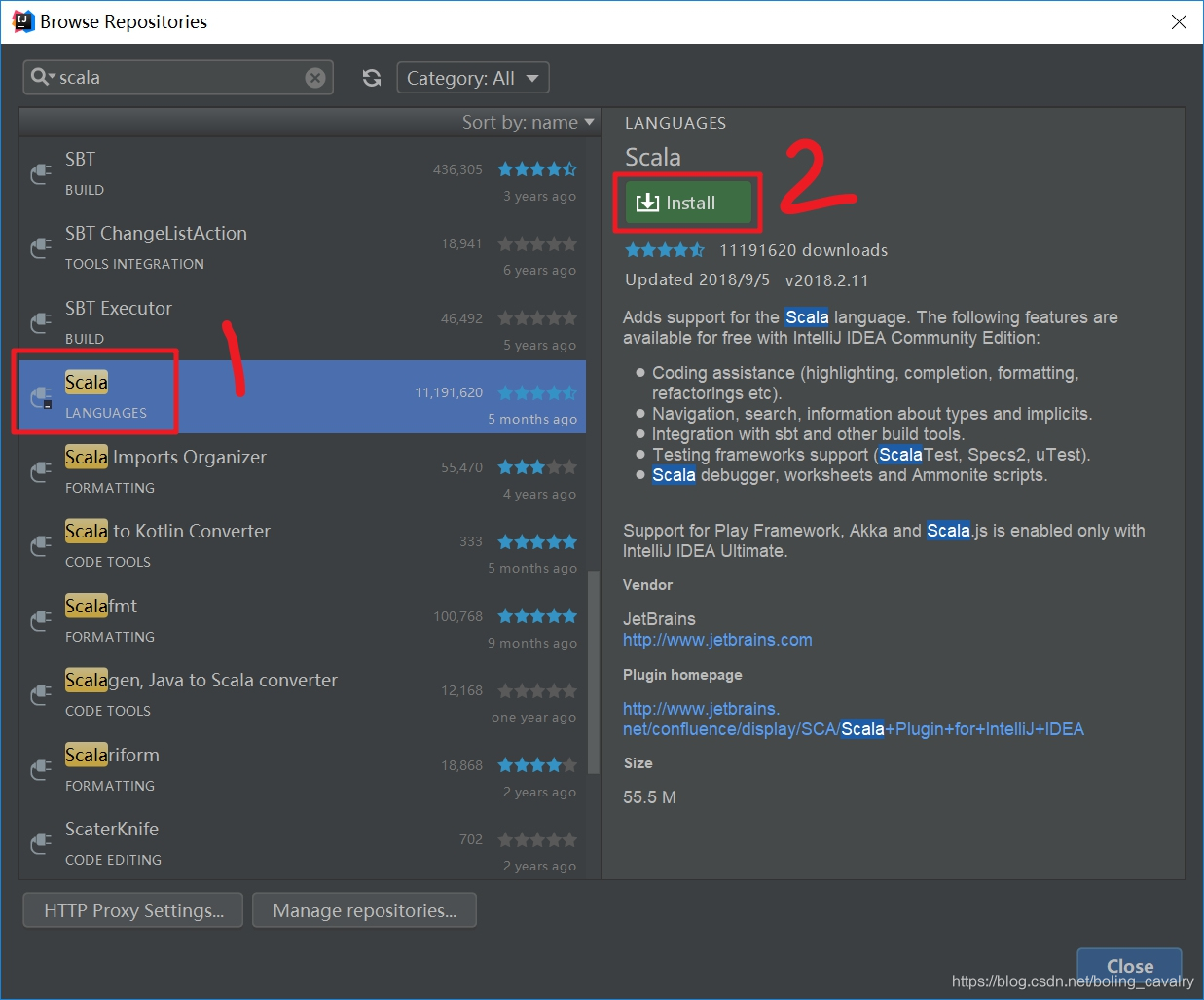
- 如下图,在红框1输入"scala",点击红框2,开始在中央仓库说搜索:

- 在搜索结果中选中"scala",再点击右侧的"Install",如下:
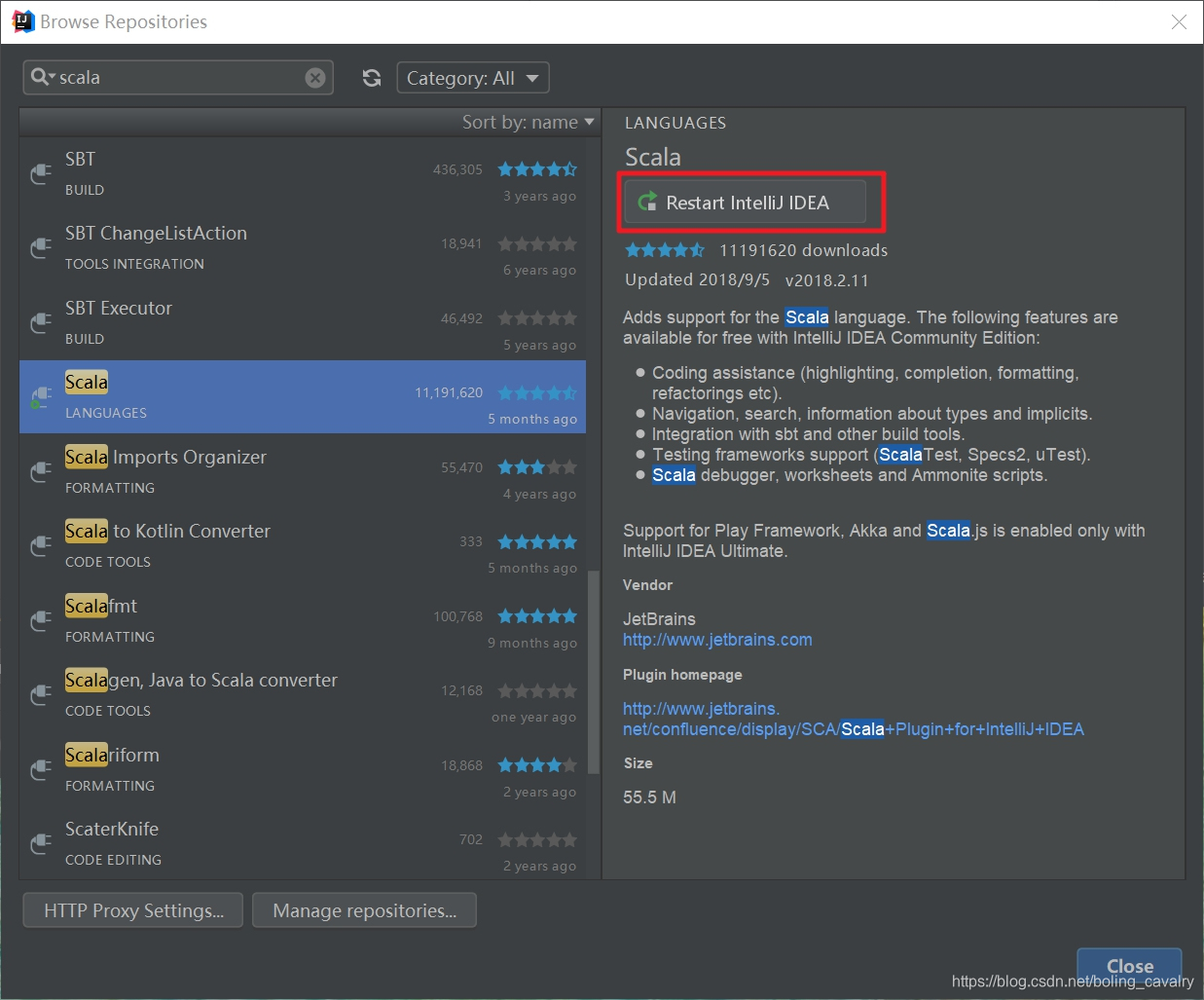
- 等待在线安装成功后,点击"Restart IntelliJ IDEA",如下:
新建scala工程
- 点击下图红框,创建一个新工程:
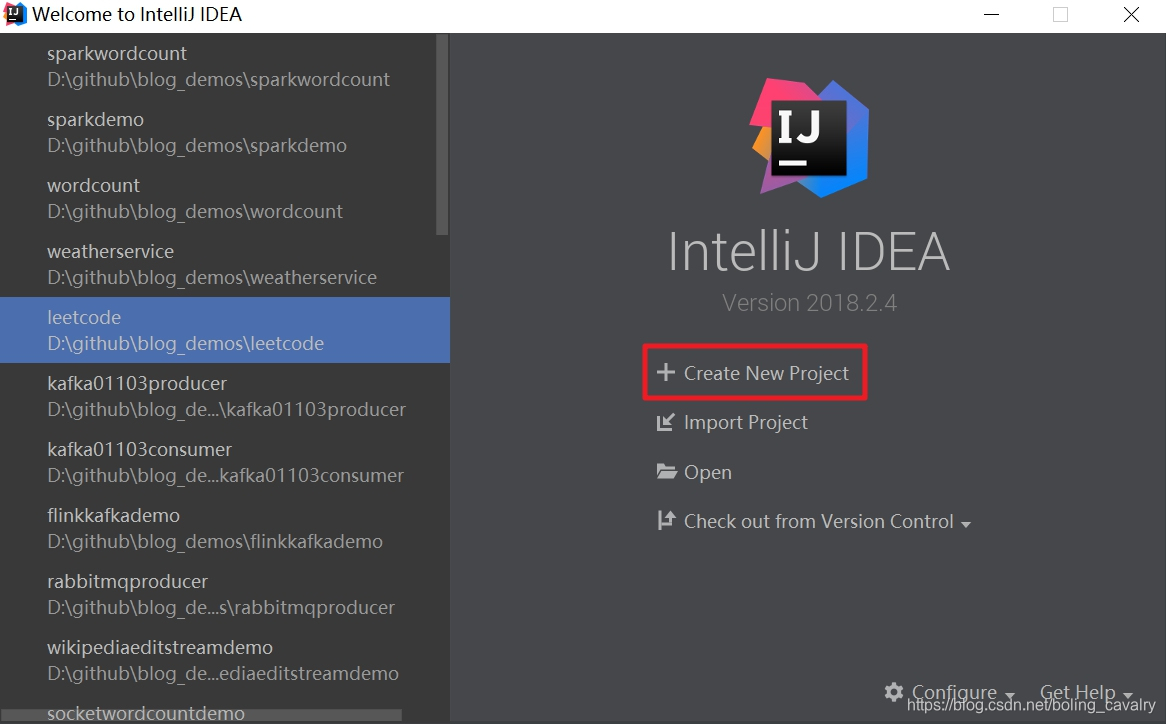
- 在弹出窗口中选择"Scala"->“IDEA”,如下图:
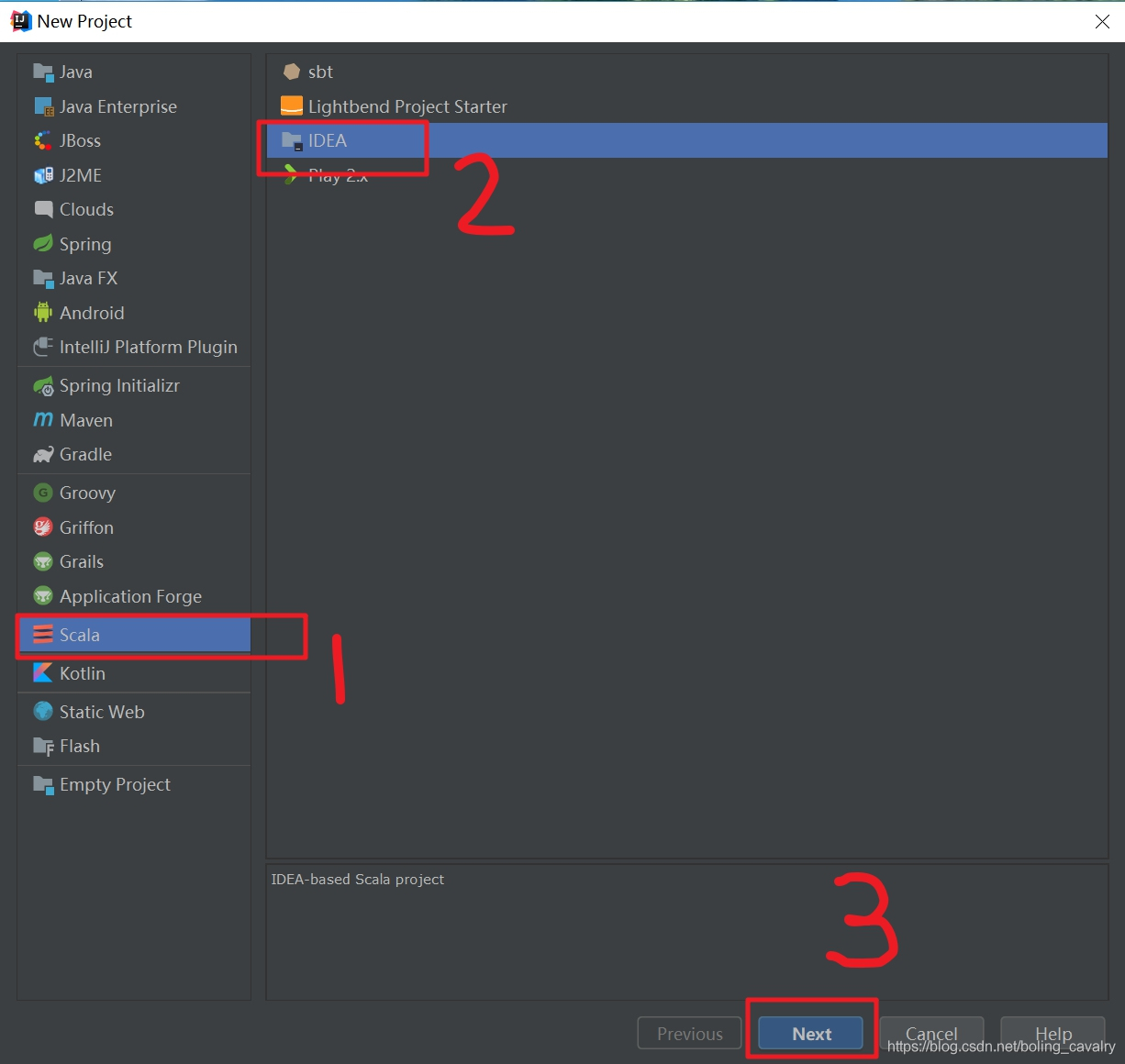
- 如下图,在红框1中输入项目名称,点击红框2,选择Scala SDK:

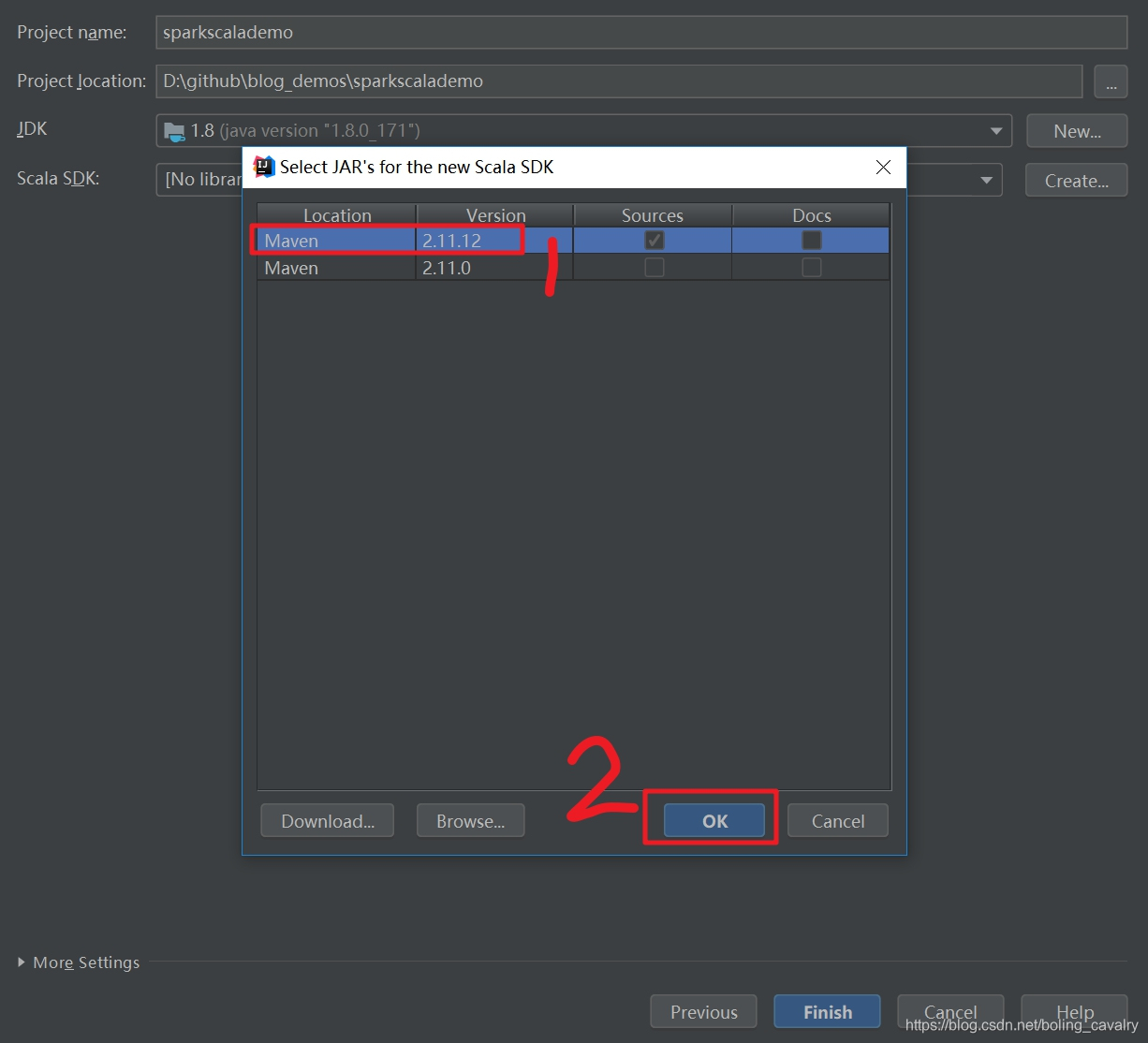
- 在弹出的窗口选择"2.11.12"版本,如下图:
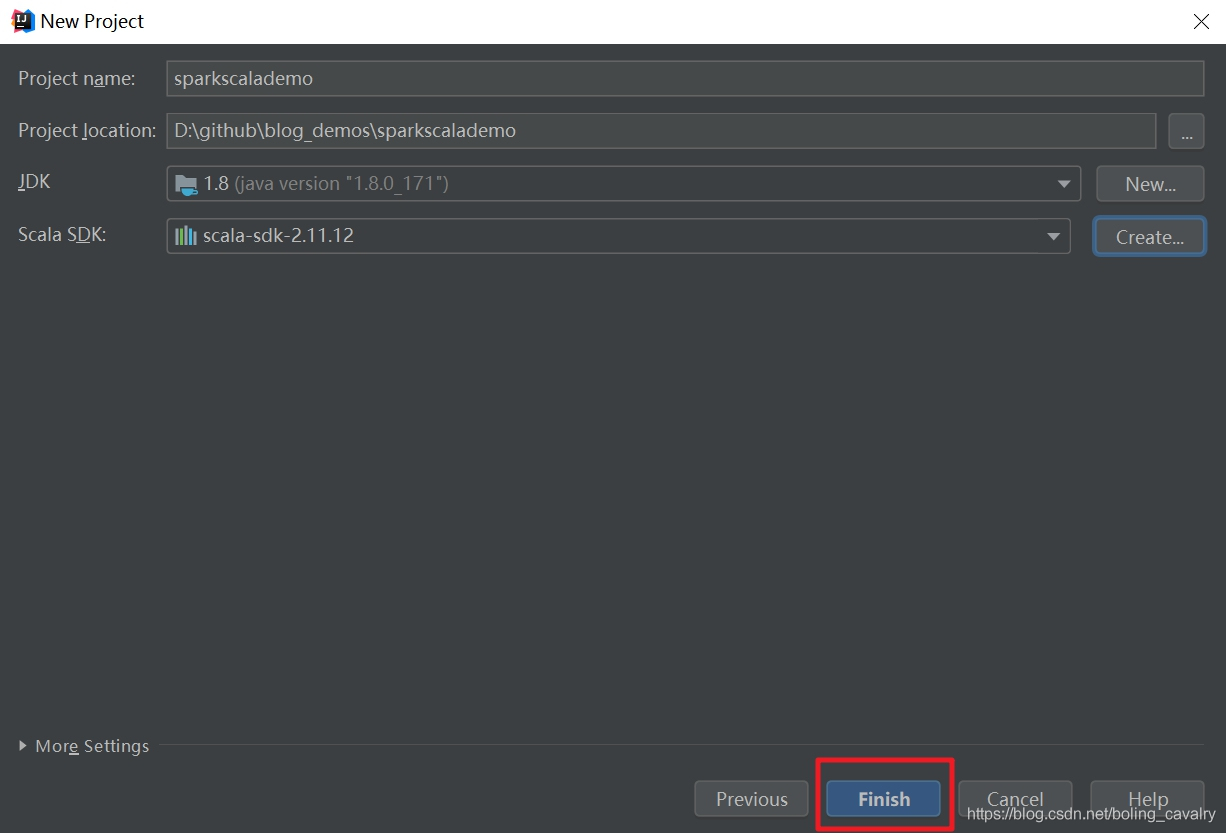
- 点击下图红中的"Finish",完成工程创建:
- 工程创建成功了,接下来是添加spark库,点击"File"->“Project Structure”,如下图:
- 在弹出窗口选择新增一个jar库,如下图:

- 在弹出窗口选择前面安装的spark-2.3.3-bin-hadoop2.7文件夹下面的jar文件夹,如下:

- 如下图,弹出的窗口用来选择模块,就选工程目录即可:
- 至此,整个spark开发环境已经设置好了,现在写一个demo试试,创建一个object,源码如下:
package com.bolingcavalry.sparkscalademo.app
import org.apache.spark.{SparkConf, SparkContext}
/**
-
@Description: 第一个scala语言的spark应用
-
@author: willzhao E-mail: zq2599@gmail.com
-
@date: 2019/2/16 20:23
*/
object FirstDemo {
def main(args: Array[String]): Unit={
val conf = new SparkConf()
.setAppName(“first spark app(scala)”)
.setMaster(“local[1]”);
new SparkContext(conf)
.parallelize(List(1,2,3,4,5,6))
.map(x=>x*x)
.filter(_>10)
.collect()
.foreach(println);
}
}
以上代码的功能很简单:创建用一个数组,将每个元素做平方运算,再丢弃小于10的元素,然后逐个打印出来;
11. 代码完成后,点击右键选择"Run FirstDemo",即可立即在本机运行,如下图:
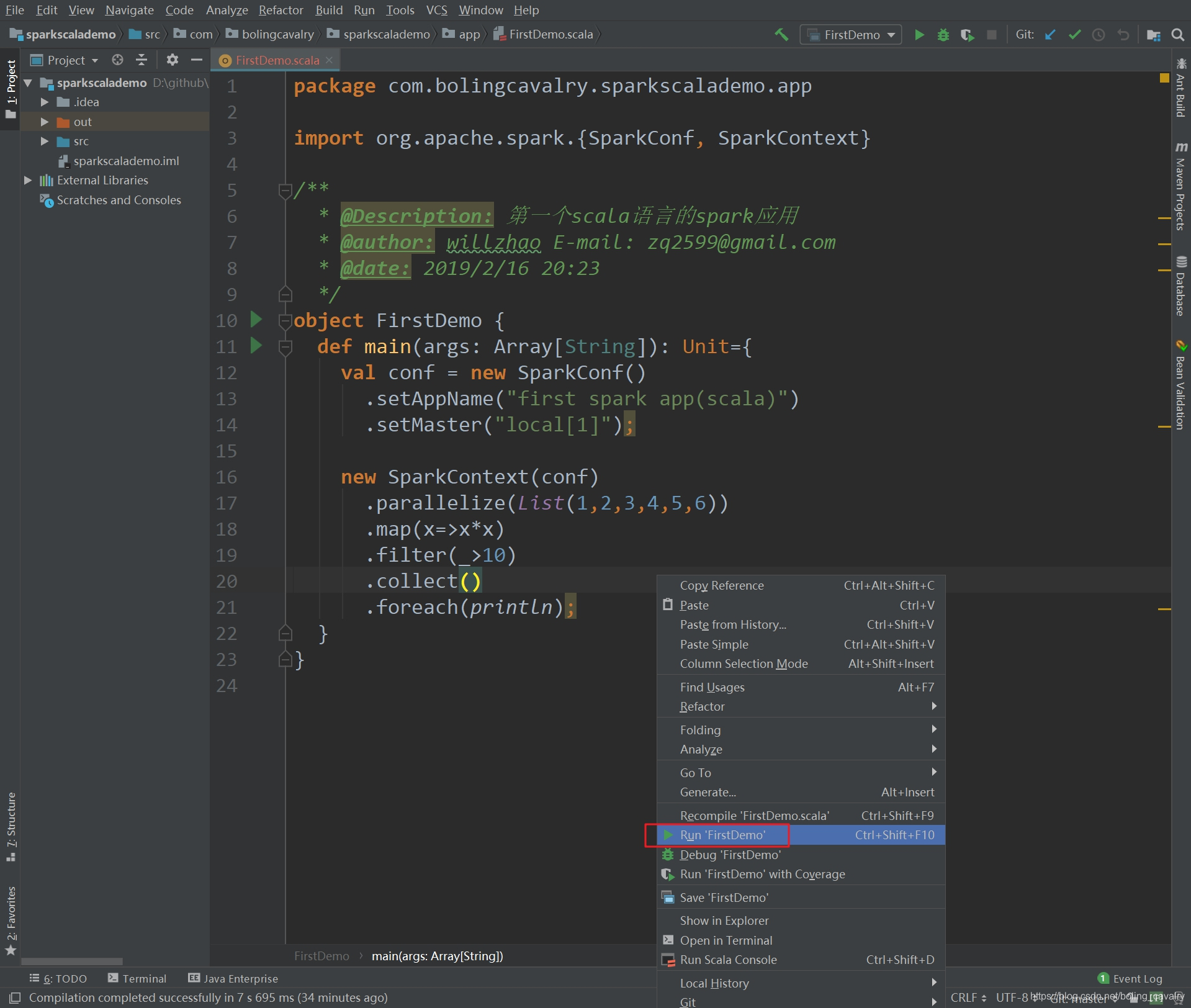
12. 由于windows环境并没有做hadoop相关配置,因此控制台上会有错误堆栈输出,但这些信息并不影响程序运行(本例没有用到hadoop),输出如下,可见结果已经被打印出来(16、25、36):
2019-02-17 09:04:21 INFO TaskSchedulerImpl:54 - Removed TaskSet 0.0, whose tasks have all completed, from pool
2019-02-17 09:04:21 INFO DAGScheduler:54 - ResultStage 0 (collect at FirstDemo.scala:20) finished in 0.276 s
2019-02-17 09:04:21 INFO DAGScheduler:54 - Job 0 finished: collect at FirstDemo.scala:20, took 0.328611 s
16
25
36
2019-02-17 09:04:21 INFO SparkContext:54 - Invoking stop() from shutdown hook
2019-02-17 09:04:21 INFO AbstractConnector:318 - Stopped Spark@452ba1db{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
2019-02-17 09:04:21 INFO SparkUI:54 - Stopped Spark web UI at http://DESKTOP-82CCEBN:4040
2019-02-17 09:04:21 INFO MapOutputTrackerMasterEndpoint:54 - MapOutputTrackerMasterEndpoint stopped!
2019-02-17 09:04:21 INFO MemoryStore:54 - MemoryStore cleared
2019-02-17 09:04:21 INFO BlockManager:54 - BlockManager stopped
2019-02-17 09:04:21 INFO BlockManagerMaster:54 - BlockManagerMaster stopped
2019-02-17 09:04:21 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint:54 - OutputCommitCoordinator stopped!
2019-02-17 09:04:21 INFO SparkContext:54 - Successfully stopped SparkContext
2019-02-17 09:04:21 INFO ShutdownHookManager:54 - Shutdown hook called
2019-02-17 09:04:21 INFO ShutdownHookManager:54 - Deleting directory C:\Users\12167\AppData\Local\Temp\spark-4bbb584a-c7c2-4dc8-9c7e-473de7f8c326
Process finished with exit code 0
构建打包,提交到spark环境运行
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注:Java)

最后
各位读者,由于本篇幅度过长,为了避免影响阅读体验,下面我就大概概括了整理了




《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
71716)]
[外链图片转存中…(img-bNEiEPLw-1713858471716)]
[外链图片转存中…(img-ZTLJlfKm-1713858471717)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!

