
- 1时序图中if else画法_时序图 if else
- 2桌面运维岗面试三十问
- 3brew mysql 失败_Mac mysql安装失败解决方法
- 4FPGA设计之时序约束---常用指令与流程_input_delay_max
- 5【实战】TF-IDF,WORD2VEC,机器学习算法,深度学习算法在新浪新闻分类表现。_word2vec svm新闻文本分类
- 6【2022研电赛】兆易创新杯全国二等奖:自动驾驶汽车路面目标智能检测系统_电子大赛 智能识别
- 7git合并远程库并将代码合并完提交到自己的分支的流程_合并其他人的代码后提交自己的代码
- 8Gitlab设置中文
- 9some 术语 1
- 10SQL Server 中,删除表数据有以下几种方式_sqlserver删除表
mediapipe KNN 基于mediapipe和KNN的引体向上计数/深蹲计数/俯卧撑计数【mediapipe】【KNN】【BlazePose】【K邻近算法】【python】_python mediapipe knn
赞
踩
Mediapipe KNN引体向上计数/深蹲计数/俯卧撑计数
引言
Mediapipe在从视频中估计人体姿势的各种应用中发挥着关键作用,例如量化体育锻炼、手语识别和全身手势控制。例如,它可以构成瑜伽、舞蹈和健身应用的基础。它还可以在增强现实中将数字内容和信息叠加在物理世界之上。
MediaPipe Pose 是一种用于高保真身体姿势跟踪的 ML 解决方案,利用Google的BlazePose研究从 RGB 视频帧中推断出全身的 33 个 3D landmarks(图1)和背景分割蒙版。当前最先进的方法主要依赖于强大的桌面环境进行检测,而该框架在大多数现代手机、台式机/笔记本电脑、python开发环境甚至网络上实现了实时性能。

由于我们选择了简单易上手的k-最近邻算法(k-NN) 作为分类器(该算法根据训练集中最接近的样本确定对象的类别),而不是根据各运动的肢体之间的夹角特点作为分类依据,所以该方法具有良好的泛化通用能力,可以广泛应用在诸如深蹲(deep squat)、俯卧撑(push up)、引体向上(pull up)等健身运动的计数上(代码中的关键点距离对包含了这三种运动涉及到的关节,其他运动本人暂未研究过),您只需要输入这三种运动的视频即可(或者如果您想使用自己采集的样本,只需要将训练样本图片更换成对应的运动即可),而几乎不需要修改代码。

功能
本项目可以实现深蹲(deep squat)、俯卧撑(push up)、引体向上(pull up)的检测和计数,您只需要输入视频,就可以直接计数您的动作个数。到目前为止已经实现了深蹲(deep squat)和俯卧撑(push up)的检测和计数,引体向上由于没有找到合适的时间和地点拍摄训练样本图片,所以暂时没有生成csv文件,不过要自己生成也很简单,拍摄上下两个状态的训练样本图片并按以下结构把它放到fitness_poses_images_in(存放样本图片的文件夹最好取这个名字省得去改代码)文件夹中,然后运行程序即可。
引体向上训练样本图片文件夹结构
|---fitness_poses_images_in(建议名字起这个)
|---pull_down(建议名字起这个)
-001.jpg
-002.jpg
...
|---pull_up(建议名字起这个)
-001.jpg
-002.jpg
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
说明
本项目测试的运行环境为:win10,python3.7,pycharm,内存大于等于16G。
对于想要自己拍摄图片然后获取训练文件的同学,建议你的电脑内存配置至少要在16G及以上,否则你训练的时候可能会爆内存导致程序突然中断,对于这种情况,我遇到的pycharm报错通常是进程已结束,退出代码为-1073740940(0xC0000374)
使用的Mediapipe版本为0.8.10。
关于mediapipe的安装及可能遇到的问题,请参考:https://blog.csdn.net/m0_57110410/article/details/125538796
需要导入的库:
import io
from PIL import ImageFont
from PIL import ImageDraw
import csv
import cv2
from matplotlib import pyplot as plt
import numpy as np
import os
from PIL import Image
import sys
import tqdm
from mediapipe.python.solutions import drawing_utils as mp_drawing
from mediapipe.python.solutions import pose as mp_pose
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
步骤
- 收集目标练习的图像样本并对其进行姿势预测,
- 将获得的姿态标志转换为适合 k-NN 分类器的数据,并使用这些数据形成训练集,
- 执行分类本身,然后进行重复计数。
训练样本
为了建立一个好的分类器,应该为训练集收集适当的样本:理论上每个练习的每个最终状态大约有几百个样本(例如,俯卧撑和深蹲的“向上”和“向下”位置,图2和图3),收集的样本涵盖不同的摄像机角度、环境条件、身体形状和运动变化,这一点很重要,能做到这样最好。但实际中如果嫌麻烦的话每种状态15-25张左右都可以,然后拍摄角度要注意多样化,最好每隔15度拍摄一张。


训练样本图片的格式:
# Required structure of the images_in_folder:
#
# fitness_poses_images_in/
# squat_up/
# image_001.jpg
# image_002.jpg
# ...
# squat_down/
# image_001.jpg
# image_002.jpg
# ...
# ...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

当然,里面的图片的名字不需要如同image_001.jpg、image_002.jpg这样有序,可以随便命名
def show_image(img, figsize=(10, 10)): """Shows output PIL image.""" plt.figure(figsize=figsize) plt.imshow(img) plt.show() # 提取训练集关键点坐标 class BootstrapHelper(object): """Helps to bootstrap images and filter pose samples for classification.""" def __init__(self, images_in_folder, images_out_folder, csvs_out_folder): self._images_in_folder = images_in_folder self._images_out_folder = images_out_folder self._csvs_out_folder = csvs_out_folder # Get list of pose classes and print image statistics. # 获取姿势集合列表并打印图片统计信息 self._pose_class_names = sorted([n for n in os.listdir(self._images_in_folder) if not n.startswith('.')]) def bootstrap(self, per_pose_class_limit=None): """Bootstraps images in a given folder. Required image in folder (same use for image out folder): pushups_up/ image_001.jpg image_002.jpg ... pushups_down/ image_001.jpg image_002.jpg ... ... Produced CSVs out folder: pushups_up.csv pushups_down.csv Produced CSV structure with pose 3D landmarks: sample_00001,x1,y1,z1,x2,y2,z2,.... sample_00002,x1,y1,z1,x2,y2,z2,.... """ # Create output folder for CVSs. if not os.path.exists(self._csvs_out_folder): os.makedirs(self._csvs_out_folder) for pose_class_name in self._pose_class_names: print('Bootstrapping ', pose_class_name, file=sys.stderr) # Paths for the pose class. images_in_folder = os.path.join(self._images_in_folder, pose_class_name) images_out_folder = os.path.join(self._images_out_folder, pose_class_name) csv_out_path = os.path.join(self._csvs_out_folder, pose_class_name + '.csv') if not os.path.exists(images_out_folder): os.makedirs(images_out_folder) with open(csv_out_path, 'w', newline='') as csv_out_file: csv_out_writer = csv.writer(csv_out_file, delimiter=',', quoting=csv.QUOTE_MINIMAL) # Get list of images. image_names = sorted([n for n in os.listdir(images_in_folder) if not n.startswith('.')]) # print(image_names) if per_pose_class_limit is not None: image_names = image_names[:per_pose_class_limit] # Bootstrap every image. for image_name in tqdm.tqdm(image_names): # for image_name in image_names: # Load image. input_frame = cv2.imread(os.path.join(images_in_folder, image_name)) input_frame = cv2.cvtColor(input_frame, cv2.COLOR_BGR2RGB) # Initialize fresh pose tracker and run it. with mp_pose.Pose() as pose_tracker: result = pose_tracker.process(image=input_frame) pose_landmarks = result.pose_landmarks # Save image with pose prediction (if pose was detected). output_frame = input_frame.copy() if pose_landmarks is not None: mp_drawing.draw_landmarks( image=output_frame, landmark_list=pose_landmarks, connections=mp_pose.POSE_CONNECTIONS) output_frame = cv2.cvtColor(output_frame, cv2.COLOR_RGB2BGR) cv2.imwrite(os.path.join(images_out_folder, image_name), output_frame) # Save landmarks if pose was detected. if pose_landmarks is not None: # Get landmarks. frame_height, frame_width = output_frame.shape[0], output_frame.shape[1] pose_landmarks = np.array( [[lmk.x * frame_width, lmk.y * frame_height, lmk.z * frame_width] for lmk in pose_landmarks.landmark], dtype=np.float32) assert pose_landmarks.shape == (33, 3), 'Unexpected landmarks shape: {}'.format( pose_landmarks.shape) # print(image_name, pose_landmarks) csv_out_writer.writerow([image_name] + pose_landmarks.flatten().astype(np.str).tolist()) # Draw XZ projection and concatenate with the image. projection_xz = self._draw_xz_projection( output_frame=output_frame, pose_landmarks=pose_landmarks) output_frame = np.concatenate((output_frame, projection_xz), axis=1) csv_out_file.close() def _draw_xz_projection(self, output_frame, pose_landmarks, r=0.5, color='red'): frame_height, frame_width = output_frame.shape[0], output_frame.shape[1] img = Image.new('RGB', (frame_width, frame_height), color='white') if pose_landmarks is None: return np.asarray(img) # Scale radius according to the image width. r *= frame_width * 0.01 draw = ImageDraw.Draw(img) for idx_1, idx_2 in mp_pose.POSE_CONNECTIONS: # Flip Z and move hips center to the center of the image. x1, y1, z1 = pose_landmarks[idx_1] * [1, 1, -1] + [0, 0, frame_height * 0.5] x2, y2, z2 = pose_landmarks[idx_2] * [1, 1, -1] + [0, 0, frame_height * 0.5] draw.ellipse([x1 - r, z1 - r, x1 + r, z1 + r], fill=color) draw.ellipse([x2 - r, z2 - r, x2 + r, z2 + r], fill=color) draw.line([x1, z1, x2, z2], width=int(r), fill=color) return np.asarray(img) # 对齐图片和csv文件 def align_images_and_csvs(self, print_removed_items=False): """Makes sure that image folders and CSVs have the same sample. Leaves only intersetion of samples in both image folders and CSVs. """ for pose_class_name in self._pose_class_names: # Paths for the pose class. images_out_folder = os.path.join(self._images_out_folder, pose_class_name) csv_out_path = os.path.join(self._csvs_out_folder, pose_class_name + '.csv') # Read CSV into memory. rows = [] with open(csv_out_path, newline='') as csv_out_file: csv_out_reader = csv.reader(csv_out_file, delimiter=',') for row in csv_out_reader: rows.append(row) # Image names left in CSV. image_names_in_csv = [] # Re-write the CSV removing lines without corresponding images. with open(csv_out_path, 'w', newline='') as csv_out_file: csv_out_writer = csv.writer(csv_out_file, delimiter=',', quoting=csv.QUOTE_MINIMAL) for row in rows: # print(row) image_name = row[0] image_path = os.path.join(images_out_folder, image_name) if os.path.exists(image_path): image_names_in_csv.append(image_name) csv_out_writer.writerow(row) elif print_removed_items: print('Removed image from CSV: ', image_path) # Remove images without corresponding line in CSV. for image_name in os.listdir(images_out_folder): if image_name not in image_names_in_csv: image_path = os.path.join(images_out_folder, image_name) os.remove(image_path) if print_removed_items: print('Removed image from folder: ', image_path) # 分析异常的训练样本 def analyze_outliers(self, outliers): """Classifies each sample agains all other to find outliers. If sample is classified differrrently than the original class - it sould either be deleted or more similar samples should be aadded. """ for outlier in outliers: image_path = os.path.join(self._images_out_folder, outlier.sample.class_name, outlier.sample.name) print('Outlier') print(' sample path = ', image_path) print(' sample class = ', outlier.sample.class_name) print(' detected class = ', outlier.detected_class) print(' all classes = ', outlier.all_classes) img = cv2.imread(image_path) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) show_image(img, figsize=(20, 20)) def remove_outliers(self, outliers): """Removes outliers from the image folders.""" for outlier in outliers: image_path = os.path.join(self._images_out_folder, outlier.sample.class_name, outlier.sample.name) os.remove(image_path) def print_images_in_statistics(self): """Prints statistics from the input image folder.""" self._print_images_statistics(self._images_in_folder, self._pose_class_names) def print_images_out_statistics(self): """Prints statistics from the output image folder.""" self._print_images_statistics(self._images_out_folder, self._pose_class_names) def _print_images_statistics(self, images_folder, pose_class_names): print('Number of images per pose class:') for pose_class_name in pose_class_names: n_images = len([ n for n in os.listdir(os.path.join(images_folder, pose_class_name)) if not n.startswith('.')]) print(' {}: {}'.format(pose_class_name, n_images))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
获取归一化的landmarks
要将样本转换为 k-NN 分类器训练集,我们可以在给定图像上运行 BlazePose 模型,并将预测的landmarks转储到 CSV 文件中。此外,Pose Classification Colab (Extended)通过针对整个训练集对每个样本进行分类,提供了有用的工具来查找异常值(例如,错误预测的姿势)和代表性不足的类别(例如,不覆盖所有摄像机角度)。之后,您将能够在任意视频上测试该分类器。
# 人体姿态编码模块 class FullBodyPoseEmbedder(object): """Converts 3D pose landmarks into 3D embedding.""" def __init__(self, torso_size_multiplier=2.5): # Multiplier to apply to the torso to get minimal body size. self._torso_size_multiplier = torso_size_multiplier # Names of the landmarks as they appear in the prediction. self._landmark_names = [ 'nose', 'left_eye_inner', 'left_eye', 'left_eye_outer', 'right_eye_inner', 'right_eye', 'right_eye_outer', 'left_ear', 'right_ear', 'mouth_left', 'mouth_right', 'left_shoulder', 'right_shoulder', 'left_elbow', 'right_elbow', 'left_wrist', 'right_wrist', 'left_pinky_1', 'right_pinky_1', 'left_index_1', 'right_index_1', 'left_thumb_2', 'right_thumb_2', 'left_hip', 'right_hip', 'left_knee', 'right_knee', 'left_ankle', 'right_ankle', 'left_heel', 'right_heel', 'left_foot_index', 'right_foot_index', ] def __call__(self, landmarks): """Normalizes pose landmarks and converts to embedding Args: landmarks - NumPy array with 3D landmarks of shape (N, 3). Result: Numpy array with pose embedding of shape (M, 3) where `M` is the number of pairwise distances defined in `_get_pose_distance_embedding`. """ assert landmarks.shape[0] == len(self._landmark_names), 'Unexpected number of landmarks: {}'.format( landmarks.shape[0]) # Get pose landmarks. landmarks = np.copy(landmarks) # Normalize landmarks. landmarks = self._normalize_pose_landmarks(landmarks) # Get embedding. embedding = self._get_pose_distance_embedding(landmarks) return embedding def _normalize_pose_landmarks(self, landmarks): """Normalizes landmarks translation and scale.""" landmarks = np.copy(landmarks) # Normalize translation. pose_center = self._get_pose_center(landmarks) landmarks -= pose_center # Normalize scale. pose_size = self._get_pose_size(landmarks, self._torso_size_multiplier) landmarks /= pose_size # Multiplication by 100 is not required, but makes it eaasier to debug. landmarks *= 100 return landmarks # 计算中心点,mediapipe定义中心点为两个髋关节的中点 def _get_pose_center(self, landmarks): """Calculates pose center as point between hips.""" left_hip = landmarks[self._landmark_names.index('left_hip')] right_hip = landmarks[self._landmark_names.index('right_hip')] center = (left_hip + right_hip) * 0.5 return center def _get_pose_size(self, landmarks, torso_size_multiplier): """Calculates pose size. It is the maximum of two values: * Torso size multiplied by `torso_size_multiplier` * Maximum distance from pose center to any pose landmark """ # This approach uses only 2D landmarks to compute pose size. landmarks = landmarks[:, :2] # Hips center. left_hip = landmarks[self._landmark_names.index('left_hip')] right_hip = landmarks[self._landmark_names.index('right_hip')] hips = (left_hip + right_hip) * 0.5 # Shoulders center. left_shoulder = landmarks[self._landmark_names.index('left_shoulder')] right_shoulder = landmarks[self._landmark_names.index('right_shoulder')] shoulders = (left_shoulder + right_shoulder) * 0.5 # Torso size as the minimum body size. torso_size = np.linalg.norm(shoulders - hips) # Max dist to pose center. pose_center = self._get_pose_center(landmarks) max_dist = np.max(np.linalg.norm(landmarks - pose_center, axis=1)) return max(torso_size * torso_size_multiplier, max_dist) def _get_pose_distance_embedding(self, landmarks): """Converts pose landmarks into 3D embedding. We use several pairwise 3D distances to form pose embedding. All distances include X and Y components with sign. We differnt types of pairs to cover different pose classes. Feel free to remove some or add new. Args: landmarks - NumPy array with 3D landmarks of shape (N, 3). Result: Numpy array with pose embedding of shape (M, 3) where `M` is the number of pairwise distances. """ embedding = np.array([ # One joint. self._get_distance( self._get_average_by_names(landmarks, 'left_hip', 'right_hip'), self._get_average_by_names(landmarks, 'left_shoulder', 'right_shoulder')), self._get_distance_by_names(landmarks, 'left_shoulder', 'left_elbow'), self._get_distance_by_names(landmarks, 'right_shoulder', 'right_elbow'), self._get_distance_by_names(landmarks, 'left_elbow', 'left_wrist'), self._get_distance_by_names(landmarks, 'right_elbow', 'right_wrist'), self._get_distance_by_names(landmarks, 'left_hip', 'left_knee'), self._get_distance_by_names(landmarks, 'right_hip', 'right_knee'), self._get_distance_by_names(landmarks, 'left_knee', 'left_ankle'), self._get_distance_by_names(landmarks, 'right_knee', 'right_ankle'), # Two joints. self._get_distance_by_names(landmarks, 'left_shoulder', 'left_wrist'), self._get_distance_by_names(landmarks, 'right_shoulder', 'right_wrist'), self._get_distance_by_names(landmarks, 'left_hip', 'left_ankle'), self._get_distance_by_names(landmarks, 'right_hip', 'right_ankle'), # Four joints. self._get_distance_by_names(landmarks, 'left_hip', 'left_wrist'), self._get_distance_by_names(landmarks, 'right_hip', 'right_wrist'), # Five joints. self._get_distance_by_names(landmarks, 'left_shoulder', 'left_ankle'), self._get_distance_by_names(landmarks, 'right_shoulder', 'right_ankle'), self._get_distance_by_names(landmarks, 'left_hip', 'left_wrist'), self._get_distance_by_names(landmarks, 'right_hip', 'right_wrist'), # Cross body. self._get_distance_by_names(landmarks, 'left_elbow', 'right_elbow'), self._get_distance_by_names(landmarks, 'left_knee', 'right_knee'), self._get_distance_by_names(landmarks, 'left_wrist', 'right_wrist'), self._get_distance_by_names(landmarks, 'left_ankle', 'right_ankle'), # Body bent direction. # self._get_distance( # self._get_average_by_names(landmarks, 'left_wrist', 'left_ankle'), # landmarks[self._landmark_names.index('left_hip')]), # self._get_distance( # self._get_average_by_names(landmarks, 'right_wrist', 'right_ankle'), # landmarks[self._landmark_names.index('right_hip')]), ]) return embedding def _get_average_by_names(self, landmarks, name_from, name_to): lmk_from = landmarks[self._landmark_names.index(name_from)] lmk_to = landmarks[self._landmark_names.index(name_to)] return (lmk_from + lmk_to) * 0.5 def _get_distance_by_names(self, landmarks, name_from, name_to): lmk_from = landmarks[self._landmark_names.index(name_from)] lmk_to = landmarks[self._landmark_names.index(name_to)] return self._get_distance(lmk_from, lmk_to) def _get_distance(self, lmk_from, lmk_to): return lmk_to - lmk_from
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
生成的csv文件

fitness_poses_csvs_out文件夹里面的csv文件就是使用拍摄的训练样本提取出来的深蹲和俯卧撑的训练集文件,有了该文件后就可以直接运行本项目。当然,如果你想体验自己动手的快乐,可以自己拍摄训练样本并把它放到fitness_poses_images_in(存放样本图片的文件夹最好取这个名字省得去改代码)文件夹中,然后删掉fitness_poses_csvs_out文件夹中对应运动的两个csv文件,这两个csv文件丢失后程序会自动加载样本图片进行特征提取然后重新生成csv文件。
使用KNN算法分类
用于姿势分类的 k-NN 算法需要每个样本的特征向量表示和一个度量来计算两个这样的向量之间的距离,以找到最接近目标的姿势样本。
为了将姿势标志转换为特征向量,我们使用预定义的姿势关节列表之间的成对距离,例如手腕和肩膀、脚踝和臀部以及两个手腕之间的距离。由于该算法依赖于距离,因此在转换之前所有姿势都被归一化以具有相同的躯干尺寸和垂直躯干方向。

可以根据运动的特点选择所要计算的距离对(例如,引体向上可能更加关注上半身的距离对)。
为了获得更好的分类结果,使用不同的距离度量调用了两次 k-NN 搜索:
- 首先,为了过滤掉与目标样本几乎相同但在特征向量中只有几个不同值的样本(这意味着不同的弯曲关节和其他姿势类),使用最小坐标距离作为距离度量,
- 然后使用平均坐标距离在第一次搜索中找到最近的姿势簇。
# 姿态分类 class PoseClassifier(object): """Classifies pose landmarks.""" def __init__(self, pose_samples_folder, pose_embedder, file_extension='csv', file_separator=',', n_landmarks=33, n_dimensions=3, top_n_by_max_distance=30, top_n_by_mean_distance=10, axes_weights=(1., 1., 0.2)): self._pose_embedder = pose_embedder self._n_landmarks = n_landmarks self._n_dimensions = n_dimensions self._top_n_by_max_distance = top_n_by_max_distance self._top_n_by_mean_distance = top_n_by_mean_distance self._axes_weights = axes_weights self._pose_samples = self._load_pose_samples(pose_samples_folder, file_extension, file_separator, n_landmarks, n_dimensions, pose_embedder) def _load_pose_samples(self, pose_samples_folder, file_extension, file_separator, n_landmarks, n_dimensions, pose_embedder): """Loads pose samples from a given folder. Required folder structure: neutral_standing.csv pushups_down.csv pushups_up.csv squats_down.csv ... Required CSV structure: sample_00001,x1,y1,z1,x2,y2,z2,.... sample_00002,x1,y1,z1,x2,y2,z2,.... ... """ # Each file in the folder represents one pose class. file_names = [name for name in os.listdir(pose_samples_folder) if name.endswith(file_extension)] pose_samples = [] for file_name in file_names: # Use file name as pose class name. class_name = file_name[:-(len(file_extension) + 1)] # Parse CSV. with open(os.path.join(pose_samples_folder, file_name)) as csv_file: csv_reader = csv.reader(csv_file, delimiter=file_separator) for row in csv_reader: assert len(row) == n_landmarks * n_dimensions + 1, 'Wrong number of values: {}'.format(len(row)) landmarks = np.array(row[1:], np.float32).reshape([n_landmarks, n_dimensions]) pose_samples.append(PoseSample( name=row[0], landmarks=landmarks, class_name=class_name, embedding=pose_embedder(landmarks), )) return pose_samples # 找到姿态异常的训练样本 def find_pose_sample_outliers(self): """Classifies each sample against the entire database.""" # Find outliers in target poses outliers = [] for sample in self._pose_samples: # Find nearest poses for the target one. pose_landmarks = sample.landmarks.copy() pose_classification = self.__call__(pose_landmarks) class_names = [class_name for class_name, count in pose_classification.items() if count == max(pose_classification.values())] # Sample is an outlier if nearest poses have different class or more than # one pose class is detected as nearest. if sample.class_name not in class_names or len(class_names) != 1: outliers.append(PoseSampleOutlier(sample, class_names, pose_classification)) return outliers def __call__(self, pose_landmarks): """Classifies given pose. Classification is done in two stages: * First we pick top-N samples by MAX distance. It allows to remove samples that are almost the same as given pose, but has few joints bent in the other direction. * Then we pick top-N samples by MEAN distance. After outliers are removed on a previous step, we can pick samples that are closes on average. Args: pose_landmarks: NumPy array with 3D landmarks of shape (N, 3). Returns: Dictionary with count of nearest pose samples from the database. Sample: { 'pushups_down': 8, 'pushups_up': 2, } """ # Check that provided and target poses have the same shape. assert pose_landmarks.shape == (self._n_landmarks, self._n_dimensions), 'Unexpected shape: {}'.format( pose_landmarks.shape) # Get given pose embedding. pose_embedding = self._pose_embedder(pose_landmarks) flipped_pose_embedding = self._pose_embedder(pose_landmarks * np.array([-1, 1, 1])) # Filter by max distance. # # That helps to remove outliers - poses that are almost the same as the # given one, but has one joint bent into another direction and actually # represnt a different pose class. max_dist_heap = [] for sample_idx, sample in enumerate(self._pose_samples): max_dist = min( np.max(np.abs(sample.embedding - pose_embedding) * self._axes_weights), np.max(np.abs(sample.embedding - flipped_pose_embedding) * self._axes_weights), ) max_dist_heap.append([max_dist, sample_idx]) max_dist_heap = sorted(max_dist_heap, key=lambda x: x[0]) max_dist_heap = max_dist_heap[:self._top_n_by_max_distance] # Filter by mean distance. # # After removing outliers we can find the nearest pose by mean distance. mean_dist_heap = [] for _, sample_idx in max_dist_heap: sample = self._pose_samples[sample_idx] mean_dist = min( np.mean(np.abs(sample.embedding - pose_embedding) * self._axes_weights), np.mean(np.abs(sample.embedding - flipped_pose_embedding) * self._axes_weights), ) mean_dist_heap.append([mean_dist, sample_idx]) mean_dist_heap = sorted(mean_dist_heap, key=lambda x: x[0]) mean_dist_heap = mean_dist_heap[:self._top_n_by_mean_distance] # Collect results into map: (class_name -> n_samples) class_names = [self._pose_samples[sample_idx].class_name for _, sample_idx in mean_dist_heap] result = {class_name: class_names.count(class_name) for class_name in set(class_names)} return result
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
最后,我们应用指数移动平均(EMA) 平滑来平衡来自姿势预测或分类的任何噪声。为此,我们不仅搜索最近的姿势簇,而且计算每个姿势簇的概率,并将其用于随着时间的推移进行平滑处理。
# 姿态分类结果平滑 class EMADictSmoothing(object): """Smoothes pose classification.""" def __init__(self, window_size=10, alpha=0.2): self._window_size = window_size self._alpha = alpha self._data_in_window = [] def __call__(self, data): """Smoothes given pose classification. Smoothing is done by computing Exponential Moving Average for every pose class observed in the given time window. Missed pose classes arre replaced with 0. Args: data: Dictionary with pose classification. Sample: { 'pushups_down': 8, 'pushups_up': 2, } Result: Dictionary in the same format but with smoothed and float instead of integer values. Sample: { 'pushups_down': 8.3, 'pushups_up': 1.7, } """ # Add new data to the beginning of the window for simpler code. self._data_in_window.insert(0, data) self._data_in_window = self._data_in_window[:self._window_size] # Get all keys. keys = set([key for data in self._data_in_window for key, _ in data.items()]) # Get smoothed values. smoothed_data = dict() for key in keys: factor = 1.0 top_sum = 0.0 bottom_sum = 0.0 for data in self._data_in_window: value = data[key] if key in data else 0.0 top_sum += factor * value bottom_sum += factor # Update factor. factor *= (1.0 - self._alpha) smoothed_data[key] = top_sum / bottom_sum return smoothed_data
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
计数器
为了计算重复次数,该算法监控目标姿势类别的概率。深蹲的“向上”和“向下”终端状态:
- 当“下”位姿类的概率第一次通过某个阈值时,算法标记进入“下”位姿类。
- 一旦概率下降到阈值以下(即起身超过一定高度),算法就会标记“向下”姿势类别,退出并增加计数器。
为了避免概率在阈值附近波动(例如,当用户在“向上”和“向下”状态之间暂停时)导致幻像计数的情况,用于检测何时退出状态的阈值实际上略低于用于检测状态退出的阈值。
阈值设置的地方如下图:
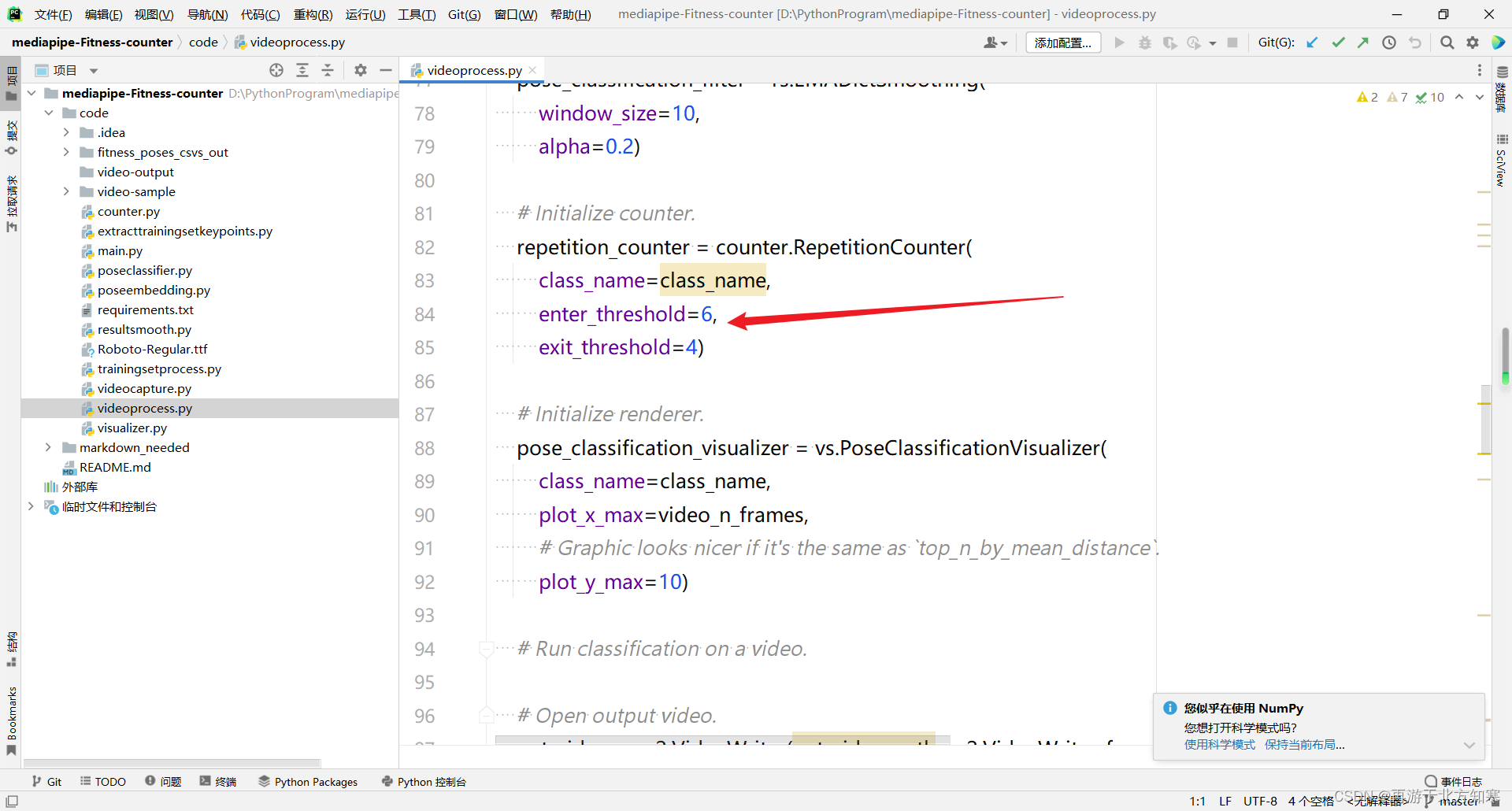
enter_threshold表示动作进入计数的阈值,exit_threshold表示动作退出计数的阈值,这两个阈值都满足计数器才会加一。
# 动作计数器 class RepetitionCounter(object): """Counts number of repetitions of given target pose class.""" def __init__(self, class_name, enter_threshold=6, exit_threshold=4): self._class_name = class_name # If pose counter passes given threshold, then we enter the pose. self._enter_threshold = enter_threshold self._exit_threshold = exit_threshold # Either we are in given pose or not. self._pose_entered = False # Number of times we exited the pose. self._n_repeats = 0 @property def n_repeats(self): return self._n_repeats def __call__(self, pose_classification): """Counts number of repetitions happend until given frame. We use two thresholds. First you need to go above the higher one to enter the pose, and then you need to go below the lower one to exit it. Difference between the thresholds makes it stable to prediction jittering (which will cause wrong counts in case of having only one threshold). Args: pose_classification: Pose classification dictionary on current frame. Sample: { 'pushups_down': 8.3, 'pushups_up': 1.7, } Returns: Integer counter of repetitions. """ # Get pose confidence. pose_confidence = 0.0 if self._class_name in pose_classification: pose_confidence = pose_classification[self._class_name] # On the very first frame or if we were out of the pose, just check if we # entered it on this frame and update the state. if not self._pose_entered: self._pose_entered = pose_confidence > self._enter_threshold return self._n_repeats # If we were in the pose and are exiting it, then increase the counter and # update the state. if pose_confidence < self._exit_threshold: self._n_repeats += 1 self._pose_entered = False return self._n_repeats
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
入口函数main
有两种选择模式,可以从本地上传视频进行检测,也可以调用摄像头进行实时检测
import videoprocess as vp import trainingsetprocess as tp import videocapture as vc if __name__ == '__main__': while True: menu = int(input("请输入检测模式(数字):1. 从本地导入视频检测\t2. 调用摄像头检测\t3. 退出\n")) if menu == 1: flag = int(input("请输入检测的运动类型(数字):1. 俯卧撑\t2. 深蹲\t3. 引体向上(暂未获得csv文件)\n")) video_path = input("请输入视频路径:") tp.trainset_process(flag) vp.video_process(video_path, flag) continue elif menu == 2: flag = int(input("请输入检测的运动类型(数字):1. 俯卧撑\t2. 深蹲\t3. 引体向上(暂未获得csv文件)\n")) print("\n按键q或esc退出摄像头采集") tp.trainset_process(flag) vc.process(flag) continue elif menu == 3: break else: print("输入错误,请重新输入!") continue
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
过程中遇到的问题
- csv文件读写问题
with open(csv_out_path, 'w', newline='') as csv_out_file:
csv_out_writer = csv.writer(csv_out_file, delimiter=',', quoting=csv.QUOTE_MINIMAL)
.......
csv_out_writer.writerow([image_name] + pose_landmarks.flatten().astype(np.str).tolist())
- 1
- 2
- 3
- 4
with open(csv_out_path, 'w', newline='')如果不加newline=''这个参数,那么writerow()写出来的csv会有空行。

with open(csv_out_path, newline='') as csv_out_file:
csv_out_reader = csv.reader(csv_out_file, delimiter=',')
- 1
- 2
with open(csv_out_path, 'w', newline='')如果不加newline=''这个参数,那么reafer()读出来的数据可能会缺失,例如csv中有25条数据,经过reader()读取之后csv中可能会只剩下一条数据,并且reader()也只读出那一条数据。我就在这个bug上花了很多时间才排查出来是csv读写文件的问题。根据python官方文档,不加newline=''参数读写csv文件可能会遇到各种奇奇怪怪的问题,也可能不会,反正加上总是没错的。
-
可视化模块的字体问题
它默认是去github上下载谷歌的一款字体,但因为某些原因,国内网络大部分时候上github是很卡的,可能会报连接超时的错误。
解决方法是我们可以把字体下载到本地,放到项目文件里,再把代码改成使用本地字体就OK了。 -
进度条一直换行
在使用tqdm.tqdm()显示进度条时出现如下现象:

出现这种情况的原因是在一个迭代过程中,如果迭代未完成就被中断,随后也没有从断点继续把剩余迭代完成,就会残存一个未能完成但参与显示的进度条,从而导致多行输出。
看警告提示:No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
我们可以定位到原来是plt.legend()这个函数出了问题,该函数是用来绘制图例的,要让该函数执行,必须在plt.plot()中传入label这个参数,比如:
plt.plot(x, y, label='男生')
plt.legend(loc='upper right') # loc 参数用来表示图例的位置
- 1
- 2
缺少这个参数,调用plt.legend()函数执行就会中断导致出现进度条多行打印的问题

我们的代码中果然没有该参数,我的方法是注释掉plt.legend(),简单粗暴,结果也没什么问题。反而加上label这个参数在这里不管用,不知道为什么。
检测结果
最终效果就是这样:
深蹲

俯卧撑

引体向上

源代码(github)
项目完整代码:https://github.com/MichistaLin/mediapipe-Fitness-counter
更新
5.15 增加了引体向上的文件,目前已经可以对引体向上进行计数了(感谢@2301_76798646贡献的图片样本)
补充
有的视频是竖版窄视频,可能会导致计数值超过两位之后只显示一位的情况(比如超过10之后的计数只显示十位上的1),可以自己调整数字显示的坐标,把它稍微向前移动就可以完整显示了。
效果演示
bilibili:https://www.bilibili.com/video/BV1NC4y1f7Jy/?vd_source=fe11f10f8ff610b1bda7d71b8fd07938


