
开源数据质量解决方案——Apache Griffin入门宝典_griffin 数据质量
赞
踩
提到格里芬—Griffin,大家想到更多的是篮球明星或者战队名,但在大数据领域Apache Griffin(以下简称Griffin)可是数据质量领域响当当的一哥。先说一句:Griffin是大数据质量监控领域唯一的Apache项目,懂了吧。
在不重视数据质量的大数据发展时期,Griffin并不能引起重视,但是随着数据治理在很多企业的全面开展与落地,数据质量的问题开始引起重视。
还是那句话,商用版的解决方案暂时不在本文的讨论范围内,目前大数据流动公众号对于数据治理工具的研究还是在开源方向,希望通过开源+二次开发结合的方式找到适合自己公司的数据治理工具箱。在未来有靠谱的商用方案,我们也会保持关注~
正文共: 12094字
预计阅读时间: 31分钟
本文将从数据质量,Griffin简介,Griffin架构,Griffin快速入门,Griffin批数据实战,Griffin流数据实战整合六个部分进行介绍,目的是带大家快速的入门数据质量管理工具的使用。
本文档版权属于公众号:大数据流动 所有。未经授权,请勿转载与商用!
考虑到抄袭问题,Griffin后续的高阶技术文章可能会付费,也希望大家能尽早加入数据治理、Griffin等相关技术群,我会将最新的文章与资料实时同步。
一、数据质量
数据质量管理(Data Quality Management),是指对数据从计划、获取、存储、共享、维护、应用、消亡生命周期的每个阶段里可能引发的各类数据质量问题,进行识别、度量、监控、预警等一系列管理活动,并通过改善和提高组织的管理水平使得数据质量获得进一步提高。
数据质量管理不是一时的数据治理手段,而是循环的管理过程。其终极目标是通过可靠的数据,提升数据在使用中的价值,并最终为企业赢得经济效益。
为什么会有数据质量管理呢?
大数据时代数据的核心不是“大”,而在于“有价值”,而有价值的关键在于“质量”。但现实是,数据往往存在很多问题:
- 数据无法匹配
- 数据不可识别
- 时效性不强
- 数据不一致
- 。。。。
那么,解决数据质量要达到什么目标呢?
总结来说就是可信和可用。
可信就是让数据具有实用性,准确性,及时性,完整性,有效性。
可用就是规范性和可读性。
数据质量可能不是数据治理的最核心部分,但可能会成为数据治理落地的做大障碍。
提高数据质量有多种方式,比如建立统一的数据标准、提高人员的意识与能力等等。
而一个提高数据质量的高生产力方式就是使用数据质量管理工具。
数据质量管理工具成熟的并不多,所以本文就不做无用的对比了,我们直接进入正题:Apache Griffin。
二、Griffin简介
Griffin是一个开源的大数据数据质量解决方案,由eBay开源,它支持批处理和流模式两种数据质量检测方式,是一个基于Hadoop和Spark建立的数据质量服务平台 (DQSP)。它提供了一个全面的框架来处理不同的任务,例如定义数据质量模型、执行数据质量测量、自动化数据分析和验证,以及跨多个数据系统的统一数据质量可视化。
Griffin于2016年12月进入Apache孵化器,Apache软件基金会2018年12月12日正式宣布Apache Griffin毕业成为Apache顶级项目。
Griffin官网地址:https://griffin.apache.org/
Github地址:https://github.com/apache/griffin
在eBay的数据质量管理实践中,需要花费很长时间去修复数据质量的问题,不管是批处理还是流处理,解决数据质量问题的时间都是巨大的,由此一个统一的数据质量系统就应运而生了。
在官网的定义中,Apache Griffin也早就更新为了批和流(Batch and Streaming)数据质量解决方案。Apache Griffin已经在朝着数据质量的统一管理平台而努力了。
Griffin主要有如下的功能特点:
- 度量:精确度、完整性、及时性、唯一性、有效性、一致性。
- 异常监测:利用预先设定的规则,检测出不符合预期的数据,提供不符合规则数据的下载。
- 异常告警:通过邮件或门户报告数据质量问题。
- 可视化监测:利用控制面板来展现数据质量的状态。
- 实时性:可以实时进行数据质量检测,能够及时发现问题。
- 可扩展性:可用于多个数据系统仓库的数据校验。
- 可伸缩性:工作在大数据量的环境中,目前运行的数据量约1.2PB(eBay环境)。
- 自助服务:Griffin提供了一个简洁易用的用户界面,可以管理数据资产和数据质量规则;同时用户可以通过控制面板查看数据质量结果和自定义显示内容。
Apache Giffin目前的数据源包括HIVE, CUSTOM, AVRO, KAFKA。Mysql和其他关系型数据库的扩展根据需要进行扩展。
当然Giffin也不是万能的,目前Griffin还是有很多的问题的,选择也要慎重:
Griffin的社区并不太活跃,可以共同讨论的人不多。
目前最新版本还是0.6,可能会有一些问题。
网上技术文档很少,当然这方面大数据流动也会不断的输出新的技术文档帮助大家。
三、Griffin架构
数据质量模块是大数据平台中必不可少的一个功能组件,以下Griffin作为一个开源的大数据数据质量解决方案,它支持批处理和流模式两种数据质量检测方式,可以从不同维度(比如离线任务执行完毕后检查源端和目标端的数据数量是否一致、源表的数据空值数量等)度量数据资产,从而提升数据的准确度、可信度。
在Griffin的架构中,主要分为Define、Measure和Analyze三个部分,如下图所示:
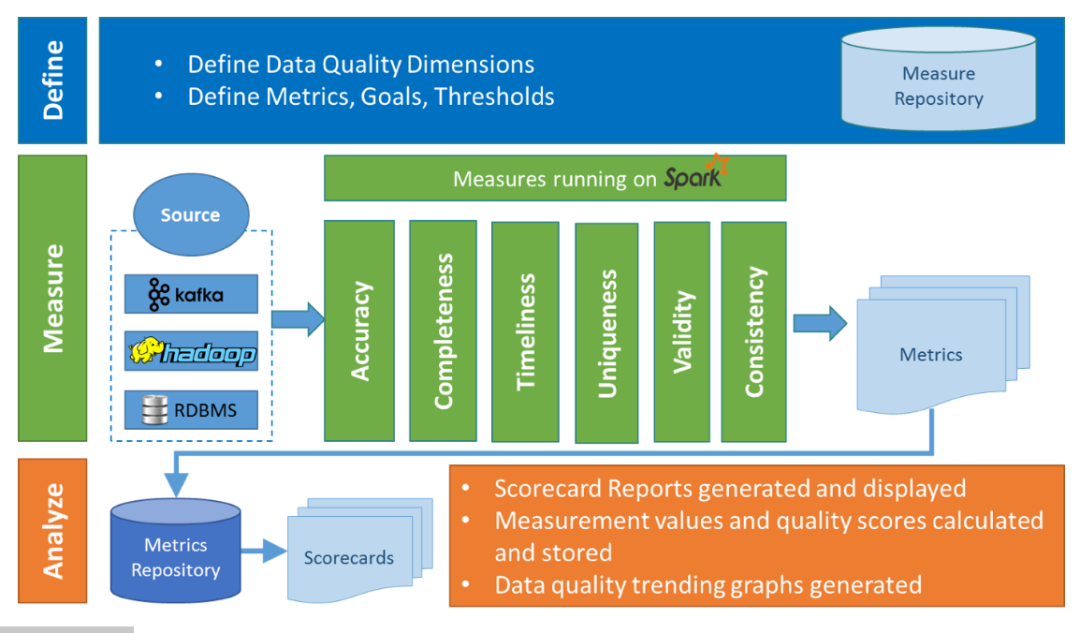
各部分的职责如下:
- Define:主要负责定义数据质量统计的维度,比如数据质量统计的时间跨度、统计的目标(源端和目标端的数据数量是否一致,数据源里某一字段的非空的数量、不重复值的数量、最大值、最小值、top5的值数量等)
- Measure:主要负责执行统计任务,生成统计结果
- Analyze:主要负责保存与展示统计结果
听起来有些晦涩,我们来看一下一个完整的Griffin任务的执行流程。
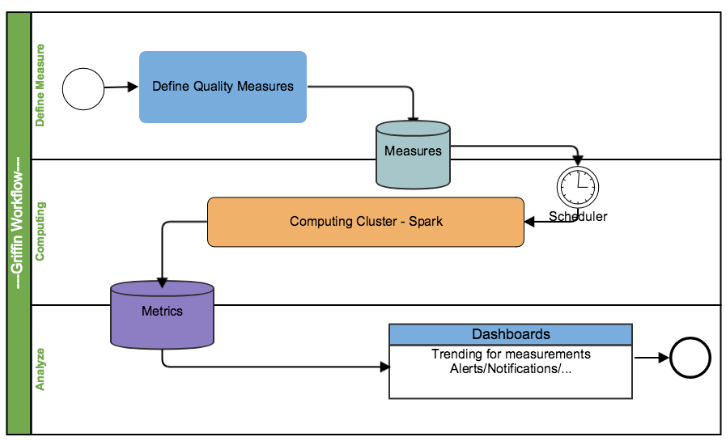
- 注册数据,把想要检测数据质量的数据源注册到griffin。
- 配置度量模型,可以从数据质量维度来定义模型,如:精确度、完整性、及时性、唯一性等。
- 配置定时任务提交spark集群,定时检查数据。
- 在门户界面上查看指标,分析数据质量校验结果。
Griffin 系统主要分为:数据收集处理层(Data Collection&Processing Layer)、后端服务层(Backend Service Layer)和用户界面(User Interface)

数据处理和存储层:
对于批量分析,数据质量模型将根据 hadoop 中的数据源计算 Spark 集群中的数据质量指标。
对于近实时分析,使用来自消息传递系统的数据,然后数据质量模型将基于 Spark 集群计算实时数据质量指标。对于数据存储,可以在后端使用Elasticsearch来满足前端请求。
Apache Griffin 服务:
项目有提供Restful 服务来完成 Apache Griffin 的所有功能,例如探索数据集、创建数据质量度量、发布指标、检索指标、添加订阅等。因此,开发人员可以基于这些 Web 开发自己的用户界面服务。
这种灵活性也让Griffin 得到了越来越多的应用。
四、Griffin快速入门
Griffin的最新版本为0.6.0,本文的安装部署也基于这个版本进行。
依赖准备
JDK (1.8 or later versions) MySQL(version 5.6及以上) Hadoop (2.6.0 or later) Hive (version 2.x) Spark (version 2.2.1) Livy(livy-0.5.0-incubating) ElasticSearch (5.0 or later versions)
大部分CDH已经自带,这里特别说一下Livy和ElasticSearch如何部署。
Livy是一个Spark的Rest服务器。
https://livy.apache.org/
准备livy安装包。
- 将livy安装包解压到/opt/目录下
- 创建livy用户、log目录并将livy的home目录属主修改为livy:hadoop
useradd livy -g hadoopmkdir /var/log/livymkdir /var/run/livychown livy:hadoop /var/log/livychown livy:hadoop /var/run/livychown -R livy:hadoop /opt/cloudera/apache-livy-0.6.0-incubating-bin/复制
3.进入livy home目录,在conf目录下创建livy.conf、livy-env.sh、spark-blacklist.conf配置文件
livy.conf、livy-env.sh、spark-blacklist.conf复制
4.修改配置文件livy.conf,添加如下内容
- livy.spark.master = yarn
- livy.spark.deployMode = cluster
- livy.environment = production
- livy.impersonation.enabled = truelivy.server.csrf_protection.enabled falselivy.server.port = 8998livy.server.session.timeout = 3600000livy.server.recovery.mode = recovery
- livy.server.recovery.state-store=filesystem
- livy.server.recovery.state-store.url=/tmp/livy
复制
5.修改配置文件livy-env.sh,增加hadoop和Spark的配置信息,如下
export JAVA_HOME=/usr/java/jdk1.8.0_181export HADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoopexport SPARK_CONF_DIR=/etc/spark2/confexport SPARK_HOME=/opt/cloudera/parcels/SPARK2-2.3.0.cloudera2-1.cdh6.3.2.p0.1041012/lib/spark2export HADOOP_CONF_DIR=/etc/hadoop/confexport LIVY_LOG_DIR=/var/log/livyexport LIVY_PID_DIR=/var/run/livyexport LIVY_SERVER_JAVA_OPTS="-Xmx2g"复制
6.修改配置文件spark-blacklist.conf
- # Configuration override / blacklist. Defines a list of properties that users are not allowed# to override when starting Spark sessions.## This file takes a list of property names (one per line). Empty lines and lines starting with "#"# are ignored.## Disallow overriding the master and the deploy mode.spark.master
- spark.submit.deployMode# Disallow overriding the location of Spark cached jars.spark.yarn.jarspark.yarn.jarsspark.yarn.archive# Don't allow users to override the RSC timeout.livy.rsc.server.idle-timeout
复制
core-site.xml 的群集范围高级配置代码段(安全阀)”配置项增加如下内容
- <property>
- <name>hadoop.proxyuser.livy.groups</name>
- <value>*</value></property><property>
- <name>hadoop.proxyuser.livy.hosts</name>
- <value>*</value></property>
复制
8.在HDFS上创建livy的home目录
- sudo -u hdfs hadoop fs -mkdir /user/livy
- sudo -u hdfs hadoop fs -chown livy:supergroup /user/livy
复制
9、启动livy服务
livy-server start复制
elasticsearch5安装,安装包也已下载在资料包中。
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.6.15.tar.gz# tar -zxvf elasticsearch-5.6.15# cd elasticsearch-5.6.15# sh ./bin/elasticsearch复制
配置准备
1、首先在mysql中初始化quartz数据库,这里需要用到脚本Init_quartz_mysql_innodb.sql。
脚本可以加griffin群,领取资料包下载。
mysql -u <username> -p <password> < Init_quartz_mysql_innodb.sql复制
2、Hadoop和Hive:
从Hadoop服务器拷贝配置文件到Livy服务器上,这里假设将配置文件放在/usr/data/conf目录下。
在Hadoop服务器上创建/home/spark_conf目录,并将Hive的配置文件hive-site.xml上传到该目录下:
#创建/home/spark_conf目录hadoop fs -mkdir -p /home/spark_conf#上传hive-site.xmlhadoop fs -put hive-site.xml /home/spark_conf/复制
3、设置环境变量:
#!/bin/bashexport JAVA_HOME=/data/jdk1.8.0_192#spark目录export SPARK_HOME=/usr/data/spark-2.1.1-bin-2.6.3#livy命令目录export LIVY_HOME=/usr/data/livy/bin#hadoop配置文件目录export HADOOP_CONF_DIR=/usr/data/conf复制
4、配置启动Livy
更新livy/conf下的livy.conf配置文件:
livy.server.host = 127.0.0.1livy.spark.master = yarnlivy.spark.deployMode = clusterlivy.repl.enable-hive-context = true复制
启动livy:
livy-server start复制
5、Elasticsearch配置:
在ES里创建griffin索引:
- curl -XPUT http://es:9200/griffin -d '{ "aliases": {}, "mappings": { "accuracy": { "properties": { "name": { "fields": { "keyword": { "ignore_above": 256, "type": "keyword"
- }
- }, "type": "text"
- }, "tmst": { "type": "date"
- }
- }
- }
- }, "settings": { "index": { "number_of_replicas": "2", "number_of_shards": "5"
- }
- }
- }
- '
复制
接下来进行源码编译打包。
Griffin的源码结构很清晰,主要包括griffin-doc、measure、service和ui四个模块,其中griffin-doc负责存放Griffin的文档,measure负责与spark交互,执行统计任务,service使用spring boot作为服务实现,负责给ui模块提供交互所需的restful api,保存统计任务,展示统计结果。
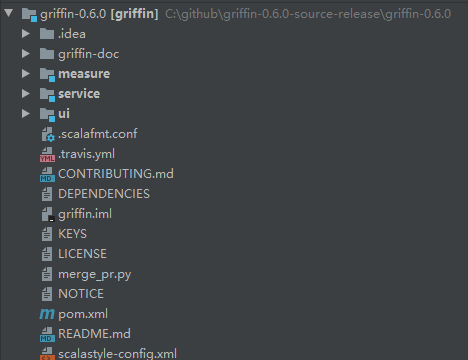
源码导入构建完毕后,需要修改配置文件,具体修改的配置文件如下:
application.properties:mysql,hive,es配置
quartz.properties
sparkProperties.json
配置文件修改好后,在idea里的terminal里执行如下maven命令进行编译打包:
mvn -Dmaven.test.skip=true clean install复制
命令执行完成后,会在service和measure模块的target目录下分别看到service-0.6.0.jar和measure-0.6.0.jar两个jar,将这两个jar分别拷贝到服务器目录下。
1、使用如下命令将measure-0.4.0.jar这个jar上传到HDFS的/griffin文件目录里:
#改变jar名称mv measure-0.6.0.jar griffin-measure.jar#上传griffin-measure.jar到HDFS文件目录里hadoop fs -put measure-0.6.0.jar /griffin/复制
2、运行service-0.6.0.jar,启动Griffin管理后台:
nohup java -jar service-0.6.0.jar>service.out 2>&1 &复制
几秒钟后,我们可以访问Apache Griffin的默认UI(默认情况下,spring boot的端口是8080)。
http://IP:8080复制
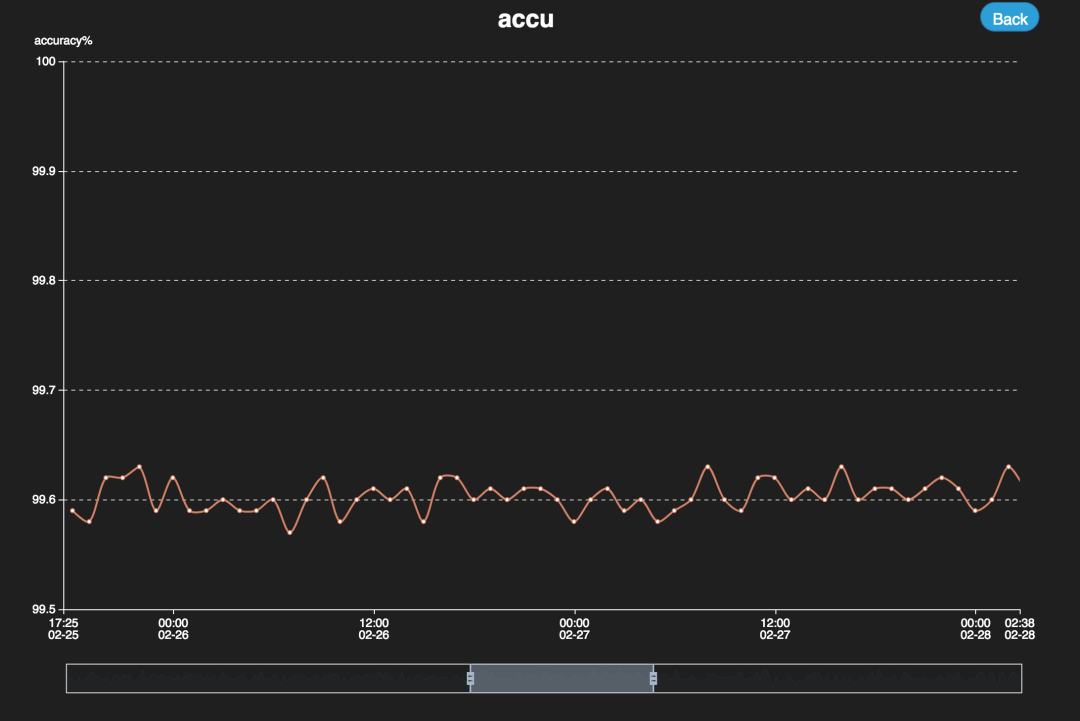
部分结果展示界面如下:
五、Griffin批数据实战
官网给出了批处理数据的例子。
1、在hive里创建表demo_src和demo_tgt:
- --create hive tables here. hql script--Note: replace hdfs location with your own pathCREATE EXTERNAL TABLE `demo_src`(
- `id` bigint,
- `age` int,
- `desc` string)
- PARTITIONED BY (
- `dt` string,
- `hour` string)ROW FORMAT DELIMITED
- FIELDS TERMINATED BY '|'LOCATION 'hdfs:///griffin/data/batch/demo_src';--Note: replace hdfs location with your own pathCREATE EXTERNAL TABLE `demo_tgt`(
- `id` bigint,
- `age` int,
- `desc` string)
- PARTITIONED BY (
- `dt` string,
- `hour` string)ROW FORMAT DELIMITED
- FIELDS TERMINATED BY '|'LOCATION 'hdfs:///griffin/data/batch/demo_tgt';
复制
2、生成测试数据:
从http://griffin.apache.org/data/batch/地址下载所有文件到Hadoop服务器上,然后使用如下命令执行gen-hive-data.sh脚本:
nohup ./gen-hive-data.sh>gen.out 2>&1 &复制
注意观察gen.out日志文件,如果有错误,视情况进行调整。这里我的测试环境Hadoop和Hive安装在同一台服务器上,因此直接运行脚本。
3、通过UI界面创建统计任务
选择DataAssets

在该页面可以看到数据资产展示

点击Measures,创建度量页面

通过下面的步骤来一步步创建

选择数据源
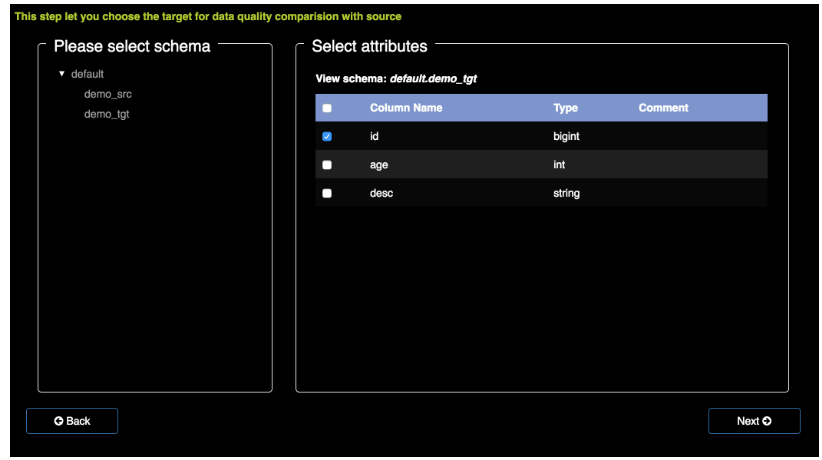
选择目标
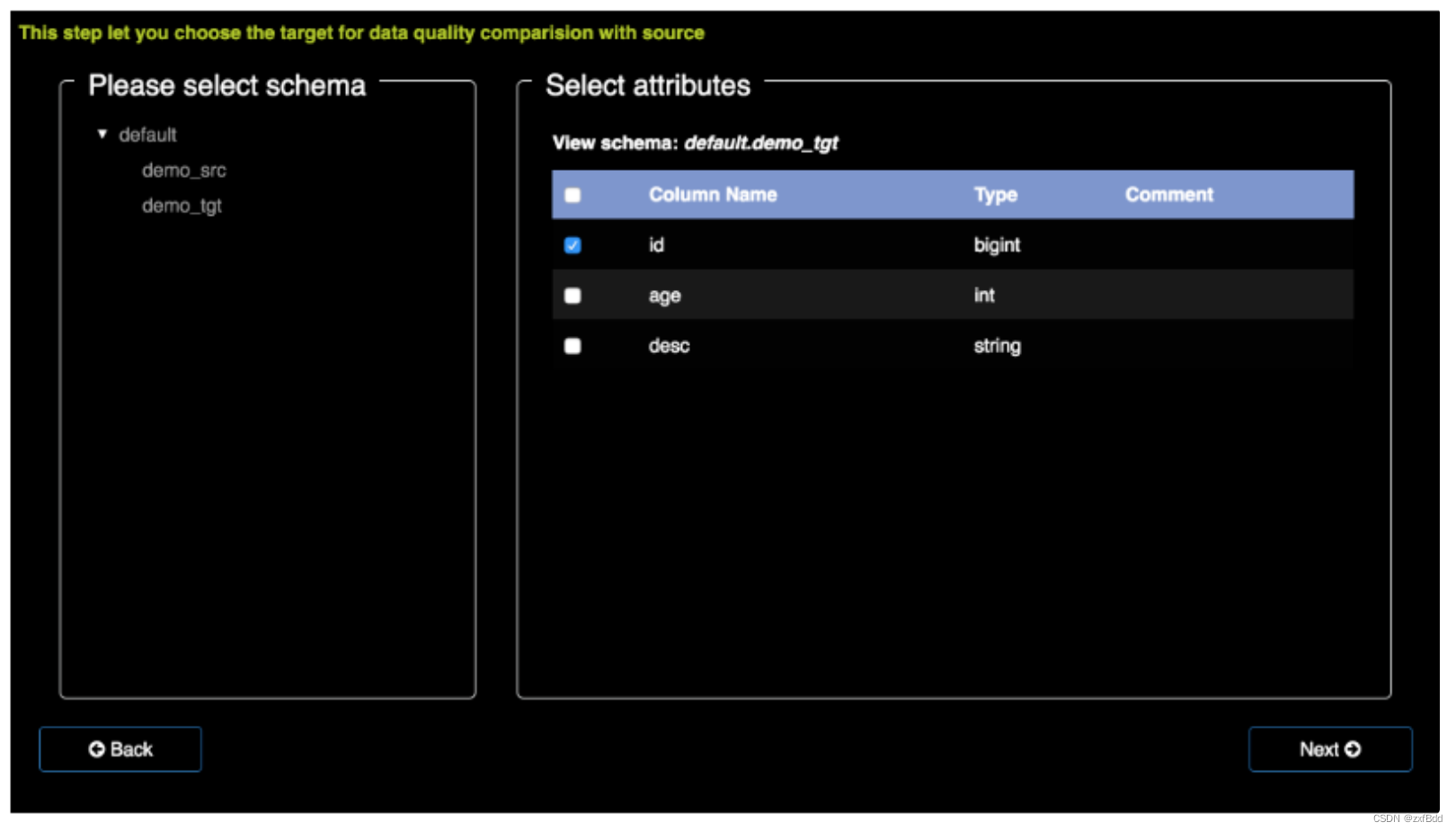
将两者关联
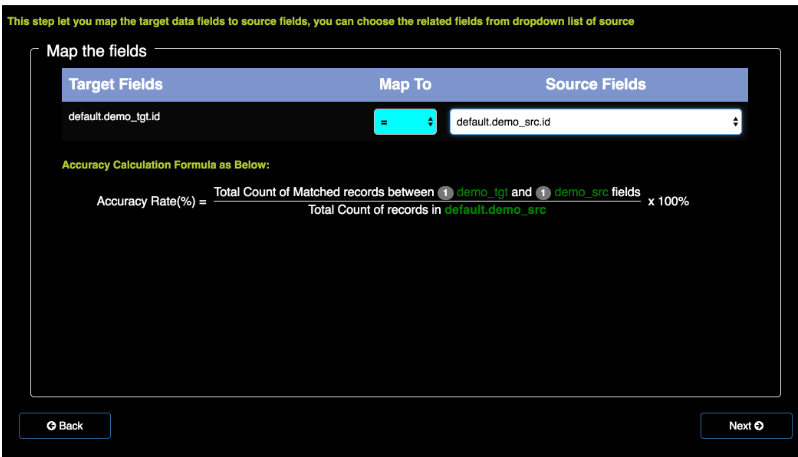
设置一些参数
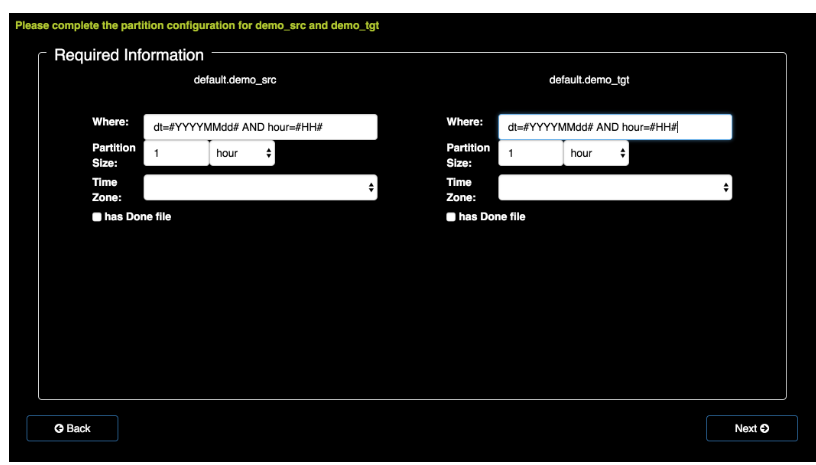
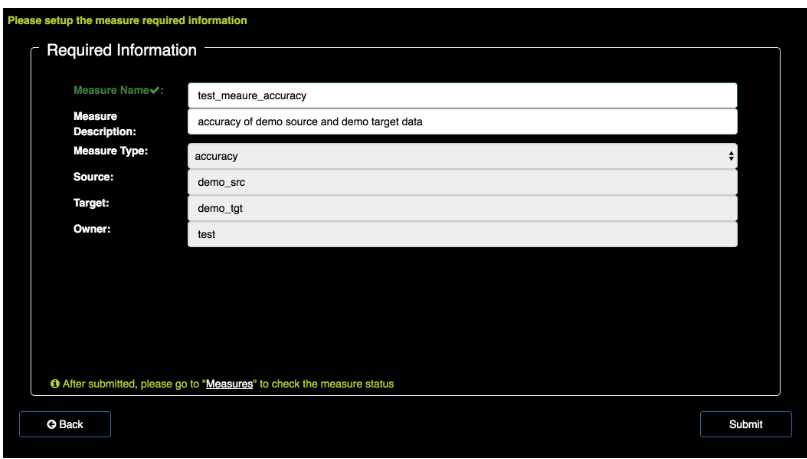
配置好提交
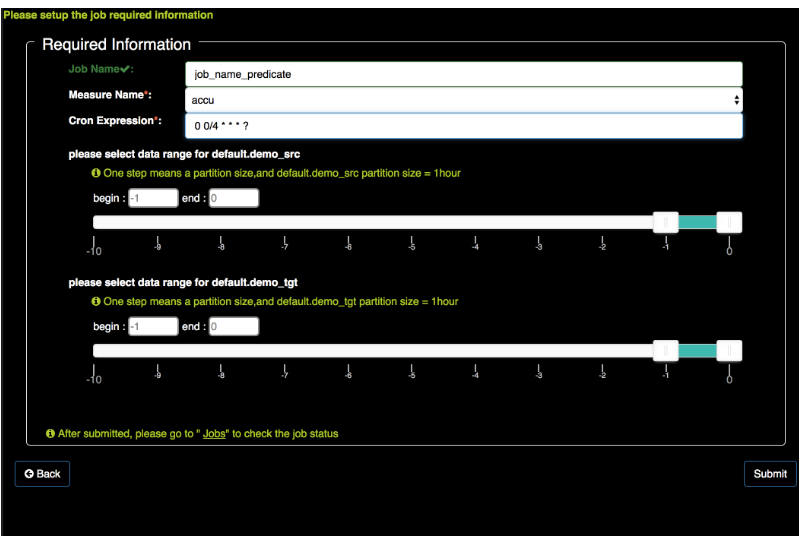
新增定时任务

用cron表达式建立任务
点击DQ Metrics,看到效果。
六、Griffin流数据实战
还会参考官网的例子。
示例流数据如下:
- {"id": 1, "name": "Apple", "color": "red", "time": "2018-09-12_06:00:00"}
- {"id": 2, "name": "Banana", "color": "yellow", "time": "2018-09-12_06:01:00"}
- ...
复制
官方也提供了测试数据的脚本https://griffin.apache.org/data/streaming/(已存资料包)
通过脚本可以源源不断将数据写入Kafka
- #!/bin/bash#create topicskafka-topics.sh --create --zookeeper hadoop101:2181 --replication-factor 1 --partitions 1 --topic sourcekafka-topics.sh --create --zookeeper hadoop101:2181 --replication-factor 1 --partitions 1 --topic target#every minuteset +ewhile truedo
- /opt/module/data/gen-data.sh sleep 90doneset -e
复制
Flink部分就是简单接收Kafka数据,然后再发向下游,部分代码片段如下:
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- FlinkKafkaConsumer010<String> kafkaconsumer = new FlinkKafkaConsumer010<String>(inputTopic, new SimpleStringSchema(), properties);
- DataStream<String> dataStream = env.addSource(kafkaconsumer);
-
- DataStream<String> target = dataStream.add...//具体处理逻辑target..addSink(new FlinkKafkaProducer010<String>( "hadoop101:9092", "target", new SimpleStringSchema()
- ));
- outMap.print();
- env.execute();
复制
配合env.json
- {
- "spark": {
- "log.level": "WARN",
- "checkpoint.dir": "hdfs:///griffin/checkpoint",
- "batch.interval": "20s",
- "process.interval": "1m",
- "init.clear": true,
- "config": {
- "spark.default.parallelism": 4,
- "spark.task.maxFailures": 5,
- "spark.streaming.kafkaMaxRatePerPartition": 1000,
- "spark.streaming.concurrentJobs": 4,
- "spark.yarn.maxAppAttempts": 5,
- "spark.yarn.am.attemptFailuresValidityInterval": "1h",
- "spark.yarn.max.executor.failures": 120,
- "spark.yarn.executor.failuresValidityInterval": "1h",
- "spark.hadoop.fs.hdfs.impl.disable.cache": true
- }
- },
- "sinks": [
- {
- "type": "console"
- },
- {
- "type": "hdfs",
- "config": {
- "path": "hdfs:///griffin/persist"
- }
- },
- {
- "type": "elasticsearch",
- "config": {
- "method": "post",
- "api": "http://es:9200/griffin/accuracy"
- }
- }
- ],
- "griffin.checkpoint": [
- {
- "type": "zk",
- "config": {
- "hosts": "zk:2181",
- "namespace": "griffin/infocache",
- "lock.path": "lock",
- "mode": "persist",
- "init.clear": true,
- "close.clear": false
- }
- }
- ]}

复制
dq.json
复制
提交任务
- spark-submit --class org.apache.griffin.measure.Application --master yarn --deploy-mode client --queue default \--driver-memory 1g --executor-memory 1g --num-executors 3 \
- <path>/griffin-measure.jar \
- <path>/env.json <path>/dq.json
复制
七、总结
数据管理工具目前来说还是非常匮乏的,Griffin提供的不仅仅是实现,还有数据质量管理的思路,这对于我们自研数据质量管理系统也是非常的宝贵的。
数据治理道路任重道远,欢迎加入相关交流群,我们共同学习进步~
最后提醒,文档版权为公众号 大数据流动 所有,请勿商用。相关技术问题以及安装包可以联系笔者独孤风加入相关技术交流群讨论获取。
文章分享自微信公众号:

大数据流动
复制公众号名称
本文参与 腾讯云自媒体分享计划 ,欢迎热爱写作的你一起参与!
作者:独孤风
原始发表时间:2022-07-15
如有侵权,请联系 cloudcommunity@tencent.com 删除。

