
- 1Java三种程序基本结构_java程序的三种基本结构
- 2关于FPGA的BUFG的问答
- 3openGauss知识分享 #openGauss_opengauss知识点文档
- 4centos7.9系统rabbitmq3.8.5升级为3.8.35版本
- 5岭南师范C语言程序设计真题_2021南京师范大学现代教育技术考研经验分享
- 6(已解决)windows系统卸载office2013(安装程序包语言不受系统支持)_setupprodoffscrub打不开
- 7kotlin字符串操作_kotlin 字符串替换
- 8基于llama模型进行增量预训练
- 9华为手机如何升级鸿蒙系统_怎么把华为手机升级到鸿蒙系统,又怎么回退为EMUI?...
- 10【最全】PS各个版本下载安装及小试牛刀教程(PhotoShop CS3 ~~ PhotoShop 2022)_photoshop下载csdn
10分钟了解数据质量管理-奥斯汀格里芬 Apache Griffin
赞
踩
在不重视数据质量的大数据发展时期,Griffin并不能引起重视,但是随着数据治理在很多企业的全面开展与落地,数据质量的问题开始引起重视。
1.Griffin简介
Griffin是一个开源的大数据数据质量解决方案,由eBay开源,它支持批处理和流模式两种数据质量检测方式,是一个基于Hadoop和Spark建立的数据质量服务平台 (DQSP)。它提供了一个全面的框架来处理不同的任务,例如定义数据质量模型、执行数据质量测量、自动化数据分析和验证,以及跨多个数据系统的统一数据质量可视化。
Griffin于2016年12月进入Apache孵化器,Apache软件基金会2018年12月12日正式宣布Apache Griffin毕业成为Apache顶级项目。
Griffin官网地址:https://griffin.apache.org/
Github地址:https://github.com/apache/griffin

Apache Giffin目前的数据源包括HIVE, CUSTOM, AVRO, KAFKA。Mysql和其他关系型数据库的扩展根据需要进行扩展。
各部分的职责如下:
Define:主要负责定义数据质量统计的维度,比如数据质量统计的时间跨度、统计的目标(源端和目标端的数据数量是否一致,数据源里某一字段的非空的数量、不重复值的数量、最大值、最小值、top5的值数量等)
Measure:主要负责执行统计任务,生成统计结果
Analyze:主要负责保存与展示统计结果
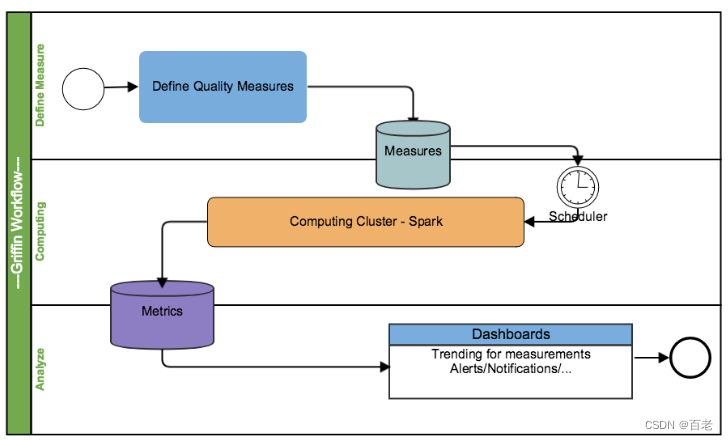
注册数据,把想要检测数据质量的数据源注册到griffin。
配置度量模型,可以从数据质量维度来定义模型,如:精确度、完整性、及时性、唯一性等。
配置定时任务提交spark集群,定时检查数据。
在门户界面上查看指标,分析数据质量校验结果
项目有提供Restful 服务来完成 Apache Griffin 的所有功能,例如探索数据集、创建数据质量度量、发布指标、检索指标、添加订阅等。因此,开发人员可以基于这些 Web 开发自己的用户界面服务。
Griffin 系统分为:数据收集处理层(Data Collection&Processing Layer)、后端服务层(Backend Service Layer)和用户界面(User Interface)
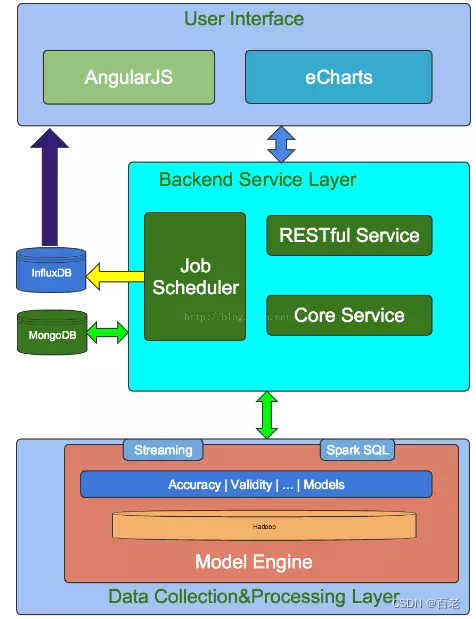
数据收集处理层
模型引擎(Model Engine)是核心,Griffin 是模型驱动的解决方案。基于目标数据集,可以选择不同的数据质量维度执行目标数据质量验证。
内置的程序库能 batch 和 streaming 两种类型的数据源:
- 对于 batch 数据,通过数据连接器从 Hadoop 平台收集数据。
- 对于 streaming 数据,可以连接到消息系统(kafka)做近似实时数据分析。
在拿到数据之后,模型引擎将在 spark 集群中计算数据质量。
后端服务层
服务层有三个关键组件:
- 核心服务:管理元数据,如:模型定义、订阅管理和用户定制等
- 作业调度:根据模型的定义创建并调度作业,触发模型引擎的运行并取得度量值结果,然后存储度量值,在检测到数据质量问题时发送电子邮件通知。
- 接口服务:提供 REST 接口服务,如:注册数据资产,创建数据质量模型,度量发布,度量检索,添加订阅等等。可以基于这些接口服务开发自己的用户界面。
用户界面
Griffin 有一个内置的可视化工具,基于 AngularJS 和 eCharts 开发的。
Griffin 代码结构,可对照上面的三层划分
- griffin-doc 管理文档
- measure 执行统计任务,通过 Livy 提交任务到 Spark。模型定义。
- service 服务层,提供管理接口
- ui 内置的展示层

