
- 1ADS-B数据站系统_ads-b数据网
- 2Edge和Chrome下载提示“无法安全下载”解决办法_一个接口浏览器下载 提示不安全
- 3交友拉新 单机50 操作简单 每天都可以做 轻松上手
- 4Win10—YOLOv5实战+TensorRT部署+VS2019编译(小白教程~易懂易上手)---超详细_vs tensort yolo
- 5OpenCV3入门教程(一)基础知识
- 6python 断言方法_Python 断言方法: assert
- 7Linux系统安全及应用(1)
- 8全球十大公司物联网战略,一个万物智能的世界即将到来_全球企业物联网布局
- 9windows电脑改造为linux
- 10web安全之点击劫持攻击(clickjack)_clickjacking attack 渗透
【NLP】bilstmCRF模型进行中文命名实体识别的实战_bilstm-crf模型的中文命名实体识别
赞
踩
写在前面
纵观接触到的NLP任务,我们发现了,绝大部分任务或多或少地依赖NER的能力。之前仓促地总结归纳了一篇关于命名实体识别的介绍性博客,但这只能非常有限的从前辈大神成熟的理论和我不成熟的思考中,得到如萤火之光般,稍纵即逝的短暂性感悟。而这之后,面对同样的问题和任务,依旧一头雾水,没有任何获得感让人内心焦躁,各位大兄弟,不知道你们是否也有同感呢?
不管怎样,实践出真知,决定还是自己跑一把bilstmCRF,来加深理解,认识算法的能力和缓解焦躁。同样的,由于水平有限,不足之处,还请大佬不吝赐教。
(关于NER的综述介绍,可以参考我的博客)
NER两句话
命名实体通常是指文本中指代性强的实体,NER问题的任务是从文本中抽取满足特定需求的文本片段。(这些片段可以是时间、人名、地名、组织机构名等)
NER解决方案
1、基于规则的方法
比如:正则表达式提取
这种方式方便,简单。但是随着语料的增加,规则越来越复杂,由于规则之间的冲突问题等,使得规则维护起来的成本也越来越高,适用性不强。
2、基于模型的方法
将NER问题看作是序列标注的问题,常用的HMM,CRF,RNN,RNN+CRF等
HMM简单训练快,但是马尔科夫假设会导致模型的准确率不佳
CRF理论上优于HMM,需要自己创建模板。
RNN解决了CRF特征模板的创建问题,尤其是LSTM等,由于记忆力机制,更好的利用了上下文信息,特征提取能力优秀。
基于BILSTMCRF 的NER系统
标注任务
希望从文本中抽取时间、人名、地名、组织机构名。
训练数据
我们人民日报1988人工标注语料库。可以在此处下载:
- 链接:https://pan.baidu.com/s/1gDGMSh6j2LGUeYeB8GZw4Q
- 提取码:lt4i
我们用到的bistmCRF模型可以参考:MAKING DYNAMIC DECISIONS AND THE BI-LSTM CRF
数据预处理
在人民日报中,时间、人名、地名、组织机构名分别被标注为:'t','nr','ns','nt'
{'t':'_TIME','nr':'_PERSON','ns':'_LOCATION','nt':'_ORGANIZATION'}做数据预处理时,主要从以下几个方面考虑:
全角字符转成半角字符
将分开标注的姓和名合并
将时间合并( 如 一九九八年/t 一月/t 一日/t 合并成 一九九八年一月一日/t)
标签体系
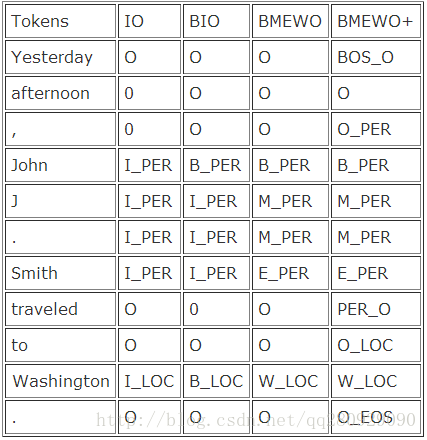
常见的标签体系有IO,BIO,BMEWO,BMWEO+
我们选用BMEWO,一般来讲,标签体系越复杂,准确性也越高,对应的训练时间也会更长。需要根据实际情况合理选择。
下图给出不同标签体系的标注示例:
训练数据生成
我们是基于字来训练model,所以训练时,输入是字的embedding。数据预处理脚本的输出如下图所示:

模型的结构
模型的结构同我的博客
相关参数:

平台
windows10 + CPU + pytorch +pycharm + anaconda
结果展示


代码地址
https://github.com/Bigmai-1234/BILSTMCRF
目前上传的,是实验性的代码。从目前来看,效果还是不错的。
当然,由于训练数据,个人能力(主要是个人能力)的问题,仍然存在诸如将不满足要求的词错标为实体和漏掉个别实体的情况,请知悉。
另外,我的代码中没有早停机制,数据预处理的过程中,也没有考虑特殊符号,在数据集的切分上,也只是简单的利用random.choice,希望有兴趣的大佬可以修正。
我此刻在想,bilstm 用Transformer 来代替的可能性,关于这个想法,不知道大佬您怎么看?
其他问题,也诚盼指教!

