
- 1《Python编程从入门到实践》day19
- 2Hadoop(2.6.0-cdh5.15.1)配置lzo压缩_hadoop-lzo包
- 3Node.js网络编程之WebSocket篇_node websocket
- 4机器人路径规划:基于改进型A*算法的机器人路径规划(提供Python代码)_a*算法多机器人路径规划
- 5搭建数据可视化工具:superset_sqlalchemy.exc.invalidrequesterror: can't determin
- 6RabbitMQ之二-Web管理界面_rabbitmq web查看数据
- 7git克隆及 配置ssh_git clone ssh://
- 8window环境安装kafka_kafka window
- 9mysql-sql-练习题-2
- 10Git进阶系列 | 7. Git中的Cherry-pick提交_git cherry
win10下安装Spark3.0和Hadoop3.1.3_window10安装spark3.2.4
赞
踩
1、spark win10安装
(1)解压文件到无空格的安装目录,安装到的目录为D:\Enviroment\Spark\spark-3.0.0-bin-hadoop3.2

(2)添加环境变量
- SPARK_HOME :D:\Enviroment\Spark\spark-3.0.0-bin-hadoop3.2
- %SPARK_HOME%\bin
- %SPARK_HOME%\sbin


(3)测试
cmd下输入spark-shell

2、Hadoop win10下安装
本安装用的是Linux下的hadoop3.1.3
(1)解压文件到无空格的安装目录
- 1
- 2
- 3

(2)配置环境变量:
- 1
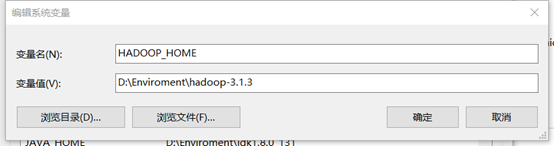
Hadoop环境变量要配置两个,一个bin,一个sbin
(3)修改Hadoop配置文件
修改D:\Enviroment\hadoop-3.1.3\sbin下的core-site.xml
- 1
- 2
- 3
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
修改D:\Enviroment\hadoop-3.1.3\sbin下的mapred-site.xml
- 1
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
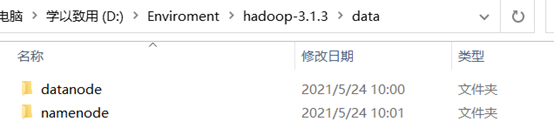
修改D:\Enviroment\hadoop-3.1.3\sbin下的hdfs-site.xml。因为在此指定了namenode和datanode,所以要在创建相关的文件夹。在D:\Enviroment\hadoop-3.1.3\data下创建namenode和datanode文件夹
- 1
<configuration> <!-- 这个参数设置为1,因为是单机版hadoop --> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/D:/hadoop-3.0.0/data/namenode</value> </property> <property> <name>fs.checkpoint.dir</name> <value>/D:/hadoop-3.0.0/data/snn</value> </property> <property> <name>fs.checkpoint.edits.dir</name> <value>/D:/hadoop-3.0.0/data/snn</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/D:/hadoop-3.0.0/data/datanode</value> </property> </configuration>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
修改D:\Enviroment\hadoop-3.1.3\sbin下的yarn-site.xml
- 1
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
修改 D:\Enviroment\hadoop-3.1.3\etc\hadoop下的hdfs-site.xml
指定对应的jdk环境

(4)bin目录替换。
因为Hadoop在linux和Windows下运行时的bin文件夹不同。主要体现为
windows下的 HADOOP_HOME\bin 有hadoop.dll 和 winutils.exe 这两个文件,
还有就是需要在C: windows\System32 里有hadoop.dll 文件 。
没有这个步骤会出现本地不满意链接错误
java.lang.UnsatisfiedLinkErrororg.apache.hadoop.io.nativeoNativeIO$Windows.access0(Ljava/lang/String;I)
(5)初始化namenode,启动Hadoop
在D:\Enviroment\hadoop-3.1.3\bin里进入 cmd 执行 hdfs namenode -format 命令初始化服务

在D:\Enviroment\hadoop-3.1.3\sbin里执行 start-all.cmd 命令启动hadoop服务,可以看到hadoop已经开始启动弹出来四个页面,分别对应着NameNode、DdataNode、ResourceManer、NodeManger。

(6)Hadoop Hdfs Web应用
1) http://127.0.0.1:8088/
查看集群所有节点状态:
- 1

2)http://localhost:9870/
可以查看到HDFS页面,在这个页面可以查看和操作各节点具体信息。
- 1
- 2

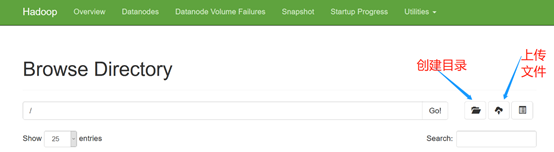
点击Utillities打开分布式文件系统,在这里不仅可以查看hdsf各级目录还可以创建删除目录,进行上传下载文件等操作,非常方便。
- 1
这两个按钮分别对应创建目录和上传文件
在这个页面还可以对上传的文件修改rwx读写执行权限、拥有者、所属组、文件副本数(这里可以看到是1,可以设置为10,但是具体情况还得看节点数是否满足,等有十个节点后会自动写够10个副本)
(7)Note:在之前的版本中文件管理的端口是50070
在3.0.0中替换为了9870端口,具体变更信息来源如下官方说明
http://hadoop.apache.org/docs/r3.0.0/hadoop-project-dist/hadoop-hdfs/HdfsUserGuide.html#Web_Interface
(8)cmd中的操作命令
这里和Linux有一点的是需要指定hdfs的uri路径,其余都一样。
hadoop fs -mkdir hdfs://localhost:9000/input

