
- 1DH参数(Denavit-Hartenberg parameters)
- 2docker学习笔记7:centos docker安装mysql
- 3mysql设置主从数据库的同步_mysql 配置好主从同步后会先做全量同步嘛
- 4原生IP和住宅IP有什么区别?
- 5一、阿里外包面试题&解析_外派阿里面试题
- 61.43 财务测量指标——动态评价法(利息与折现)
- 7大脑与AI的认知差异:解码人类思维
- 8从git或者svn上下载下来的前端代码应该如何运行起来_svn拉下来的前端项目怎么运行
- 9python sklearn knn快速实现,保姆级教学_本关任务:学会如何使用sklearn构建knn模型。
- 10基于TensorRT的BERT实时自然语言理解(下)_bert 在python tensorrt 预测
使用 ClickHouse 构建通用日志系统_clickhouse日志处理
赞
踩
使用 ClickHouse 构建通用日志系统
序言
ClickHouse 是一款常用于大数据分析的数据库,因为其压缩存储,高性能,丰富的函数等特性,近期有很多尝试 ClickHouse 做日志系统的案例。本文将分享如何用 ClickHouse 做出好用的通用日志系统。
日志系统简述
在聊为什么 ClickHouse 适合做日志系统之前,我们先谈谈日志系统的特点。
-
大数据量。对开发者来说日志最方便的观测手段,而且很多情况下会直接打印 HTTP、RPC 的请求响应日志,这基本上就是把网络流量复制了一份。
-
非固定检索模式。用户有可能使用日志中的任意关键字任意字段来查询。
-
成本要低。日志系统不宜在 IT 成本中占比过高。
-
即席查询。日志对时效性要求普遍较高。
数据量大,检索模式不固定,既要快,还得便宜。所以日志是一道难解的题,它的需求几乎违反了计算机的基本原则,不过幸好它还留了一扇窗,就是对并发要求不高。大部分查询是人为即兴的,即使做一些定时查询,所检索的范围也一定有限。
现有日志方案
ElasticSearch
ES 一定是最深入人心的日志系统了,它可以满足大数据量、全文检索的需求,但在成本与查询效率上很难平衡。ES 对成本过于敏感,配置低了查询速度会下降得非常厉害,保障查询速度又会大幅提高成本。
Loki
Grafana 推出的日志系统。理念上比较符合日志系统的需求,但现在还只是个玩具而已。
三方日志服务
国内比较杰出的有阿里云日志服务,国外的 Humio、DataDog 等,都是抛弃了 ES 技术体系,从存储上重做。国内还有观测云,只不过其存储还是 ES,没什么技术突破。
值得一提的是阿里云日志服务,它对接了诸如 OpenTracing、OpenTelemetry 等标准,可以接入监控、链路数据。因为链路数据与日志具有很高的相似性,完全可以用同一套技术栈搞定。
三方服务优点是日志摄入方式、查询性能、数据分析、监控告警、冷热分离、数据备份等功能齐备,不需要用户自行开发维护。
缺点是贵,虽然都说比 ES 便宜,但那是在相同性能下,正常人不会堆这么多机器追求高性能。最后是要把日志数据交给别人,怎么想都不太放心。
ClickHouse 适合做日志吗?
从第一性原则来分析,看看 ClickHouse 与日志场景是否契合。
大数据量,ClickHouse 作为大数据产品显然是符合的。
非固定模式检索,其本身就是张表,如果只输入关键字没有列名的话,搜索所有列对 ClickHouse 来说显然是效率低下的。但此问题也有解,后文会提到。
成本低,ClickHouse 的压缩存储可将磁盘需求减少一个数量级,并能提高检索速度。与之相比,ES 还需要大量空间维护索引。
即席查询,即席有两个方面,一个是数据可见时间,ClickHouse 写入的能力较 ES 更强,且写入完成即可见,而ES 需要 refresh_interval 配置最少 30s 来保证写入性能;另一方面是查询速度,通常单台 ClickHouse 每秒钟可扫描数百万行数据。
ClickHouse 日志方案对比
很多公司如京东、唯品会、携程等等都在尝试,也写了很多文章,但是大部分都不是「通用日志系统」,只是针对一种固定类型的日志,如 APP 日志,访问日志。所以这类方案不具备普适性,没有效仿实施的必要,在我看来他们只是传达了一个信息,就是 ClickHouse 可以做日志,并且成本确实有降低。
只有 Uber 的 日志方案 真正值得参考,他们将原本基于 ELK 的日志系统全面替换成了 ClickHouse,并承接了系统内的所有日志。
我们的日志方案也是从 Uber 出发,使用 ClickHouse 作为存储,同时参考了三方日志服务中的优秀功能,从前到后构建了一套通用日志系统。ClickHouse 就像一块璞玉,像 ELK 日志系统中的 Lucene,虽然它底子不错,但想用好还需要大量的工作。
设计
存储设计
存储是最核心的部分,存储的设计也会限制最终可以实现哪些功能,在此借鉴了 Uber 的设计并进一步改进。建表语句如下:
create table if not exists log.unified_log ( -- 项目名称 `project` LowCardinality(String), -- DoubleDelta 相比默认可以减少 80% 的空间并加速查询 `dt` DateTime64(3) CODEC(DoubleDelta, LZ4), -- 日志级别 `level` LowCardinality(String), -- 键值使用一对 Array,查询效率相比 Map 会有很大提升 `string.keys` Array(String), `string.values` Array(String), `number.keys` Array(String), `number.values` Array(Float64), `unIndex.keys` Array(String), -- 非索引字段单独保存,提高压缩率 `unIndex.values` Array(String) CODEC (ZSTD(15)), `rawLog` String, -- 建立索引加速低命中率内容的查询 INDEX idx_string_values `string.values` TYPE tokenbf_v1(4096, 2, 0) GRANULARITY 2, INDEX idx_rawLog rawLog TYPE tokenbf_v1(30720, 2, 0) GRANULARITY 1, -- 使用 Projection 记录 project 的数量,时间范围,列名等信息 PROJECTION p_projects_usually (SELECT project, count(), min(dt), max(dt), groupUniqArrayArray(string.keys), groupUniqArrayArray(number.keys), groupUniqArrayArray(unIndex.keys) GROUP BY project) ) ENGINE = MergeTree PARTITION BY toYYYYMMDD(dt) ORDER BY (project, dt) TTL toDateTime(dt) + toIntervalDay(30);

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
表中的基本元素如下
-
project: 项目名称
-
dt: 日志的时间
-
level: 日志级别
-
[string|number|unIndex].[keys|values]: 记录日志中的结构化数据
-
rawLog: JSON 格式,记录日志的正文,以及冗余了 string.keys、string.values
一条日志一定符合这些基本元素,即日志的来源,时间,级别,正文。结构化字段可以为空,都输出到正文。
表数据排序使用了 ORDER BY (project, dt),order by 是数据在物理上的存储顺序,将 project 放在前边,可以避免不同 project 之间相互干扰。典型的反例是 ElasticSearch,通常在我们会将所有后端服务放在一个索引上,通过字段标识来区分。于是查询服务日志时,会受整体日志量的影响,即使你的服务没几条日志,查起来还是很慢。
也就是不公平,90% 的服务受到 10% 服务的影响,因为这 10% 消耗了最多的存储资源,拖累了所有服务。如果将 project 放在前边,数据量小的查询快,数据量大的查询慢,彼此不会相互影响。
但是 PARTITION BY toYYYYMMDD(dt) 中却没有 project,因为 project 的数量可能会非常大,会导致 partition 数量不受控制。
架构设计
解决了核心问题后,我们设计了一整套架构,使之能够成为通用日志系统。整体架构如下:
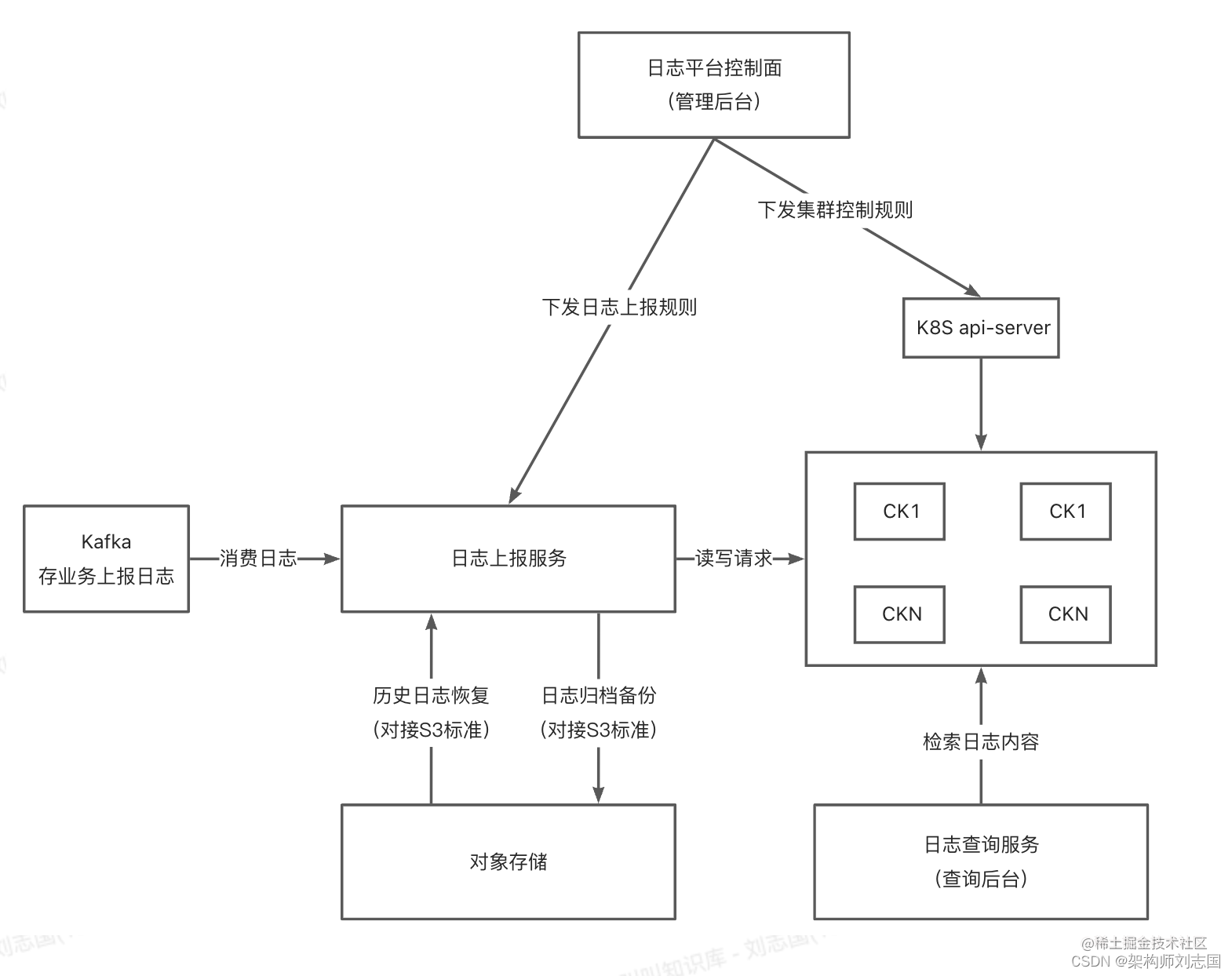
在系统中有如下角色:
- 日志上报服务
- 从 Kafka 中获取日志,解析后投递到 ClickHouse 中
- 备份日志到对象存储
- 日志控制面
- 负责与 Kubernetes 交互,初始化、部署、运维 ClickHouse 节点
- 提供内部 API 给日志系统内其他服务使用
- 管理日志数据生命周期
- 日志查询服务
- 将用户输入的类 Lucene 语法,转换成 SQL 到 ClickHouse 中查询
- 给前端提供服务
- 提供 API 给公司内部服务
- 监控告警功能
- 日志前端
ClickHouse 部署架构
ClickHouse 的集群管理功能比较孱弱,很容易出现集群状态不统一,集群命令卡住的情况,很多情况下不得不被迫重启节点。结合之前的运维经验以及参考 Uber 的做法,我们将 ClickHouse 分为读取节点(ReadNode)与数据节点(DataNode):
- ReadNode: 不存储数据。存储集群信息,负责转发所有查询。目前 2C 8G 的单节点也没有任何压力。
- DataNode: 存储数据。不关心集群信息,不连接 ZooKeeper,每个 DataNode 节点相互都是独立的。线上每个节点规格为 32C 128G。
由于 ReadNode 不涉及具体查询,只在集群拓扑信息变更时重载配置文件或重启。由于不存储什么数据,重启速度也非常快。DataNode 则通常没有理由重启,可以保持非常稳定的状态提供服务。
扩缩容问题
ReadNode 拉起节点即可提供服务,扩缩容不成问题,但很难遇到需要扩容的场景。
DataNode 扩缩容后有数据不均衡的问题。缩容比较好解决,在日志控制面标记为待下线,停止日志写入,随后通过在其他节点 insert into log.unified_log SELECT * FROM remote('ip', log.unified_log, 'user', 'password') where dt between '2022-01-01 00:00' and '2022-01-01 00:10' 以 10 分钟为单位,将数据均匀搬运到剩余的节点后,下线并释放存储即可。
扩容想要数据均衡则比较难,数据写入新节点容易,在旧节点删除掉难。由于 ClickHouse 的机制,删除操作是非常昂贵的,尤其是删除少量数据时。所以最好是提前扩容,或者是存算分离防止原节点存储被打满。
日志摄入
日志上报服务通过 Kafka 来获取日志,除了标准格式外,还可以配置不同的 Topic 有不同的解析规则。例如对接 Nginx 日志时,通过 filebeat 监听日志文件并发送到 kafka,日志上报服务进行格式解析后投递到 ClickHouse。
日志从发送到 Kakfa、读取、写入到 ClickHouse 全程都是压缩的,仅在日志上报服务中短暂解压,且解压后马上写入 Gzip Stream,内存中不保留日志原文。
而选择 Kafka 而不是直接提供接口,因为 Kafka 可以提供数据暂存,重放等。这些对数据的可靠性,系统灵活性有很大的帮助,之后在冷数据恢复的时候也会提到。
在 Java 服务上,我们提供了非常高效的 Log4j2 的 Kafka Appender,支持动态更换 kafka 地址,可以从 MDC 获取用户自定义列,并提供工具类给用户。
先说成果
ClickHouse 日志系统对接了 Java 服务端日志、客户端日志、Nginx 日志等,与云平台相比,日志方面的总成本减少了 ~85%,多存储了 ~80% 的日志量,平均查询速度降低了 ~80%。
平台仅用了三台服务器,存储了几百 TB 原始日志,高峰期摄入 500MB/s 的原始日志。
成本只是次要,好用才是第一位的,如何才能做出让开发赞不绝口,恨不得天天躺在日志里打滚的日志系统。
查询
查询语法
在查询上参考了 Lucene、各种云厂商,得出在日志查询场景,类 Lucene 语法是最为简洁易上手的。想象当你有一张千亿条数据的表,且字段的数量不确定,使用 SQL 语法筛选数据无疑是非常困难的。而 Lucene 的语法天然支持高效的筛选、反筛选。
但原生 Lucene 语法又有一定的复杂性,简化后的语法可支持如下功能:
- 关键词查询
- 使用任意日志内容进行全文查询,如
ERROR/api/user/list
- 使用任意日志内容进行全文查询,如
- 指定列查询
trace_id: xxxxuser_id: 12345key:*表示筛选存在该列的日志
- 短语查询
- 匹配一段完整文字,如
message: "userId not exists" - 查询内容含有保留字的情况,如
message: "userId:123456"
- 匹配一段完整文字,如
- 模糊查询
*Exception*、logger: org.apache.*
- 多值查询
user_id: 1,2,3等价于user_id: 1 OR user_id: 2 OR user_id: 3,在复杂查询下很方便,如level:warn AND (user_id: 1 OR user_id: 2 OR user_id: 3)即可简写为level:warn AND user_id:1,2,3
- 数字查询
- 支持 > = < ,如
http.elapsed > 100 - 一条日志中的两个列也可互相比较,如
http.elapsed > http.expect_elapsed
- 支持 > = < ,如
- 连接符
- AND、OR、NOT
- 用小括号表示优先级,如
a AND (b OR c)
日志查询服务会将用户输入的类 Lucene 语法转换为实际的 SQL。
全文查询
该功能可谓是 ElasticSearch 的杀手锏,难以想象无法全文检索的日志系统会是什么体验,而很多公司就这么做了,如果查询必须指定字段,体验上想来不会怎么愉悦。
我们通过将结构化列冗余到 rawLog 中实现了全文查询,同时对 rawLog 配置了跳数索引 tokenbf_v1 解决大数据量必须遍历的问题。一条 rawLog 的内容如下:
{ "project": "xxx-server", "dt": 1658160000058, "level": "INFO", "string$keys": [ "trace_ext.endpoint_name", "trace_id", "trace_type" ], "string$values": [ "/api/getUserInfo", "b7f7ae4a-f9ed-403a-b06c-ed46b84ba2a6", "SpringMVC" ], "unIndex$keys": [ "http.header" ], "message": "HTTP requestLog" }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
当用户查询 b7f7ae4a 时,则使用 multiSearchAny(rawLog, ['b7f7ae4a']) 查询 rawLog 字段;
当用户查询 trace_id: b7f7ae4a 时,则使用 has(string.values, 'b7f7ae4a') AND string.values[indexOf(string.keys, 'trace_id')] = 'b7f7ae4a' 同时在 rawLog 字段与字符串列中查询。因为实际使用中发现 rawLog 的索引足够大,很多情况下过滤效果更好。
查询字段为 select rawLog, unIndex.keys, unIndex.values ,这三个字段构成了一条完整的日志。这样 where 条件中使用列进行过滤,select 的列则基本收敛到 rawLog 上,可大大提高查询性能。
跳数索引
虽然 ClickHouse 的性能比较强,如果只靠遍历数据量太大依然比较吃力。
在实际使用中,使用链路ID、用户ID搜索的场景比较多,这类搜索的特点是时间范围可能不确定,关键词的区分度很高。如果能针对这部分查询加速,就能很大程度上解决问题。
ClickHouse 提供了三种字符串可用的跳数索引,均为布隆过滤器,分别如下:
- bloom_filter 不对字符串拆分,直接使用整个值。
- ngrambf_v1 会将每 N 个字符进行拆分。如果 N 太小,会导致总结果集太小,没有任何过滤效果。如果 N 太大,比如 10,则长度低于 10 的查询不会用到索引,这个度非常难拿捏。而且按每 N 字符拆分开销未免过大,当 N 为 10,字符串长度为 100 时,会拆出来 90 个字符串用于布隆过滤器索引。
- tokenbf_v1 按非字母数字字符(non-alphanumeric)拆分。相当于按符号分词,而通常日志中会有大量符号。
只有 tokenbf_v1 是最适合的,但也因此带来了一些限制,如中文不能分词,只能整段当做关键词或使用模糊搜索。或者遇到中文符号(全角符号)搜不出来,因为不属于 non-alphanumeric 的范围,所以类似 订单ID:1234 不能用 订单ID、1234 来进行搜索,因为这里的冒号是全角的。
但 tokenbf_v1 确实是现阶段唯一可用的了,于是我们建了一个很大的跳数索引 INDEX idx_rawLog rawLog TYPE tokenbf_v1(30720, 2, 0) GRANULARITY 1,大约会多使用 4% 的存储才能达到比较好的筛选效果。以下是使用索引前后的对比,用 trace_id 查询 1 天的日志:
-- 不使用索引,耗时 61s
16 rows in set. Elapsed: 61.128 sec. Processed 225.35 million rows, 751.11 GB (3.69 million rows/s., 12.29 GB/s.)
-- 使用索引,耗时不到 1s
16 rows in set. Elapsed: 0.917 sec. Processed 2.27 thousand rows, 7.00 MB (2.48 thousand rows/s., 7.63 MB/s.)
-- 使用 set send_logs_level='debug' 可以看到索引过滤掉了 99.99% 的块
<Debug> log.unified_log ... (SelectExecutor): Index `idx_rawLog` has dropped 97484/97485 granules.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
继续增加时间跨度差距会更加明显,不使用索引需要几百秒才能查到,使用索引仍然在数秒内即可查到。
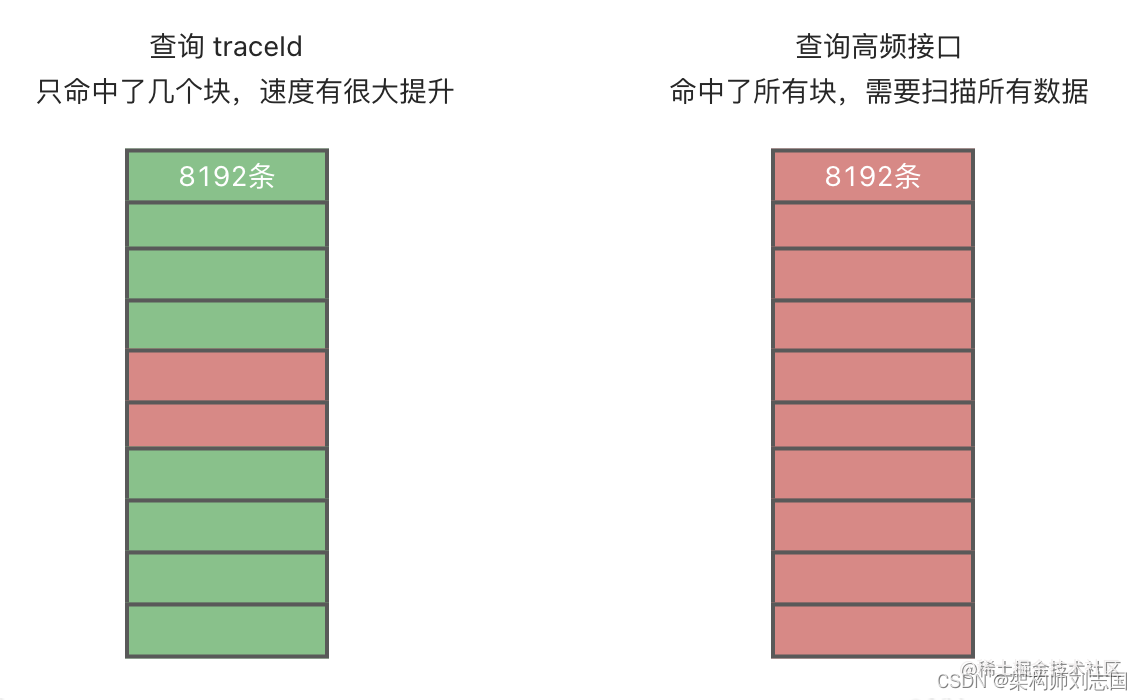
跳数索引的原理和稀疏索引类似,由于在 ClickHouse 中数据已经被压缩成块,所以跳数索引是针对整个块的数据,在查询时筛选出有可能在的块,再进入到块中遍历查询。如果搜索的关键词普遍存在,使用索引反而会减速,如下图所示:
字段类型问题
ElasticSearch 在使用时会遇到字段类型推断问题,一个字段有可能第一次以 Long 形式出现,但后续多了小数点成了 Float,一旦字段类型不兼容,后续的数据在写入时会被丢弃。于是我们大部分时候都被迫选择预先创建固定类型的列,限制服务打印日志时不能随意自定义列。
在日志系统中,我们首先创建了 number.keys, number.values 来保存数字列,并将这些字段在 string.keys, string.values 里冗余了一份,这样在查询的时候不用考虑列对应的类型,以及类型变化等复杂场景,只需要知道用户的搜索方式。
如查询 responseTime > 1000 时,就到 number 列中查询,如果查询 responseTime: 1000,就到 string 列中查询。
一切都为了给用户一种无需思考的查询方式,不用考虑它是不是数字,当它看起来像数字时,就可以用数字的方式搜索。同时也不需要预先创建日志库,创建日志列,创建解析模式等。当你开始打印,日志就出现了。
非索引字段
我们也提供了 unIndex 字段,配合 SDK 的实现用户可以将部分日志输出到非索引字段。在 unIndex 中的内容会被更有效地压缩,不占用 rawLog 字段可大幅加速全文查询,只在查询结果中展示。
日志分析
如果仅仅是浏览,人眼能看到的日志只占总量的极少部分。尤其在动辄上亿的量级下,我们往往只关注异常日志,偶尔查查某条链路日志。这种情况下数据的检索率,或许只有百万分之一。
而业务上使用的数据库,某张表只有几千万条数据,一天却要查上亿次的情况屡见不鲜。
大量日志写入后直到过期,也没有被检索过。通过分析日志来提高检索率,提高数据价值,很多时候不是不想,而是难度太高。比如有很多实践是用 hdfs 存储日志,flink 做分析,技术栈和工程复杂不说,添加新的分析模式不灵活,甚至无法发现新的模式。
ClickHouse 最强大的地方,正是其强悍到令人发指的分析功能。如果只是用来存放、检索日志,无疑大材小用。如果做到存储分析一体,不仅架构上会简化,分析能力也可以大大提高,做到让死日志活起来。
于是我们通过一系列功能,让用户能够有效利用 ClickHouse 的分析能力,去挖掘发现有价值的模式。
快速分析
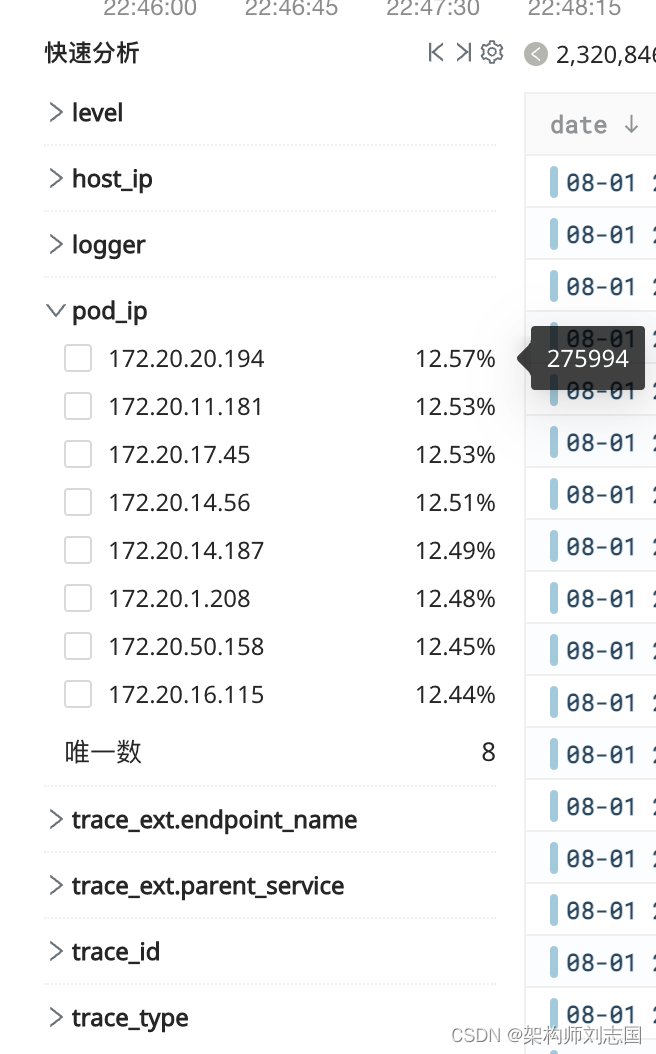
统计列的 TopN、占比、唯一数。
这个功能不算稀罕,在各种三方日志服务中算是标配。不过这里的快速分析列不用事先配置,一旦日志中出现这个列,就马上在快速分析中可用。
为了这个功能,在日志表中创建了一个 Projection:
PROJECTION p_projects_usually (SELECT project, count(), min(dt), max(dt), groupUniqArrayArray(string.keys), groupUniqArrayArray(number.keys), groupUniqArrayArray(unIndex.keys) GROUP BY project)
这样一来实时查询项目的所有列变得非常快,不用考虑在查询服务中做缓存,同时这些列名也帮助用户查询时自动补全:
但快速查询最麻烦的是难以对资源进行控制,日志数量较多时或查询条件复杂时,快速分析很容易超时变成慢速分析。所以我们控制最多扫描 1000w 行,并利用 over() 在一条 SQL 中就能同时查出聚合与明细结果:
select logger,
count() as cnt,
sum(cnt) over() as sum,
uniq(logger) over() as uniq from
(
select string.values[indexOf(string.keys, 'logger')] as logger
from unified_log where project= 'xx-api-server' and dt between '2022-08-01' and '2022-08-01' and rawLog like '%abc%'
limit 1000000
)
group by logger order by cnt desc limit 100;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
高级直方图

直方图用来指示时间与数量的关系,在此之上我们又加了一个维度,列统计。
即直方图是由日志级别堆叠而成的,不同日志级别定义了灰蓝橙红等不同颜色,不需要搜索也能让用户一眼看到是不是出现了异常日志:
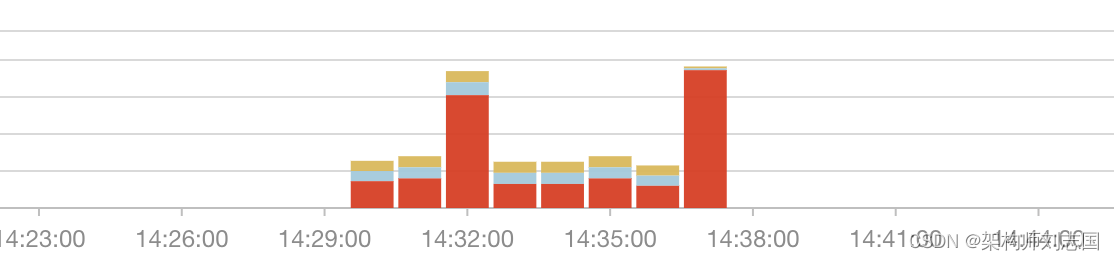
同时它还可以和快速分析结合,让直方图可使用任意列进行统计:
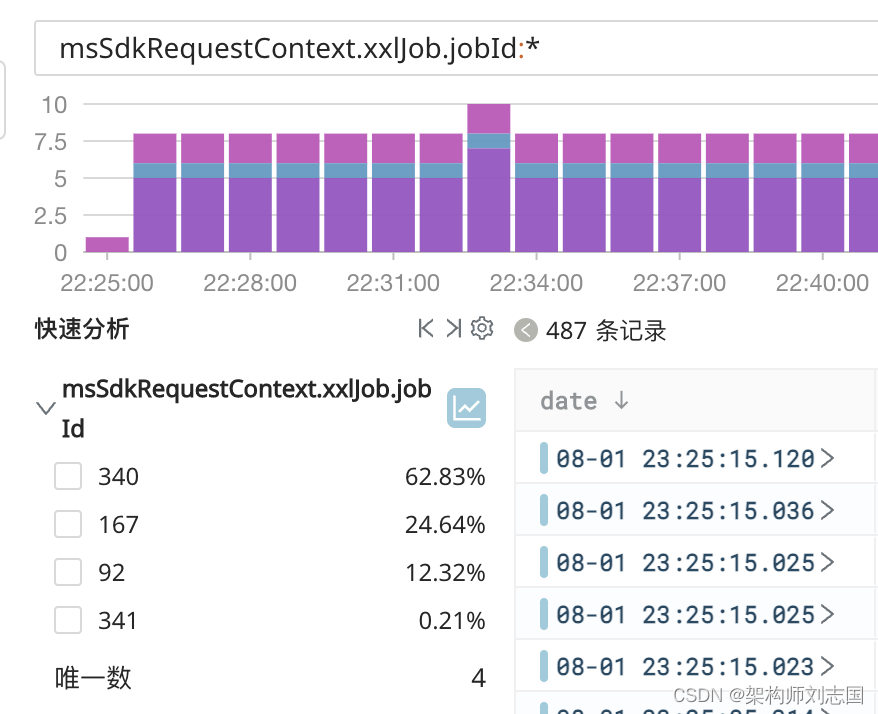
曾经业务方发现 MQ 消费堆积,因为有时候只有个别线程在进行消费,而在平时每个线程消费数量都很均匀,通过 thread_name 字段看直方图就一目了然了。
杀手锏 - 高级查询
很多日志都是没有结构化的内容,如果能现场抽取这些内容并分析,则对挖掘日志数据大有帮助。现在我们已经有了一套语法来检索日志,但这套语法无论如何也不适合分析。SQL 非常适合用来分析,大部分开发者对 SQL 也并不陌生,说来也巧,ClickHouse 本身就是 SQL 语法。
于是我们参考了阿里云日志服务,将语法通过管道符 | 一分为二,管道符前为日志查询语法,管道符后为 SQL 语法。管道符也可以有多个,前者是后者的子查询。
为了方便使用,我们也对 SQL 进行了一定简化,否则用户就要用 string.values[indexOf(string.keys, 'logger')] as logger 来获取字段,未免啰嗦。而 ClickHouse 中有 Map 类型,可以稍稍简化下用 string['logger'] as logger 。
语法结构:

下面用个完整的例子看下,在服务日志中看到一些警告日志:
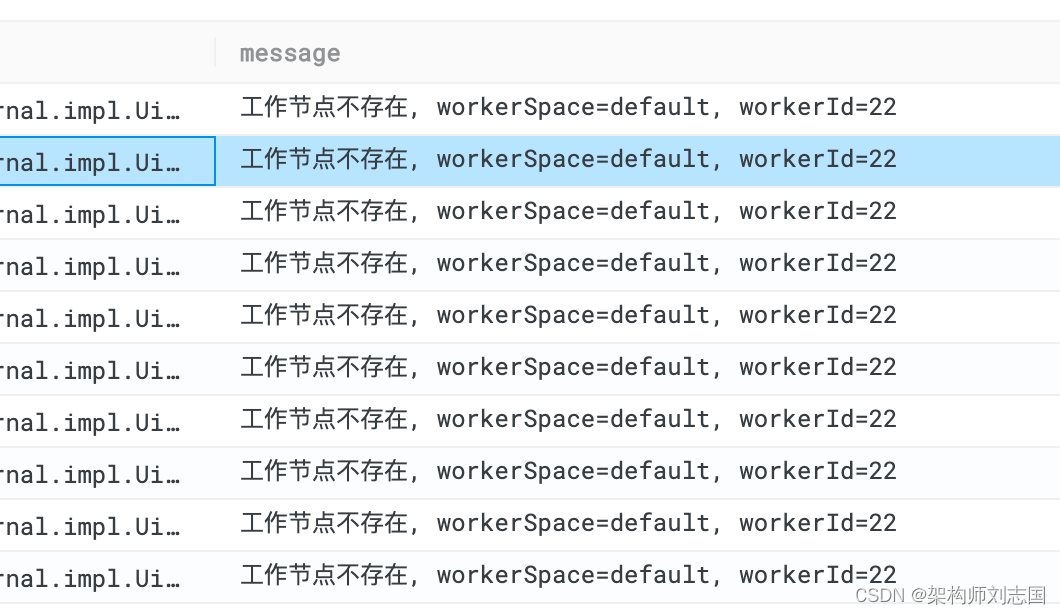
现在想统计有多少个不存在的工作节点,即「workerId=」后边的部分,查询语句如下:
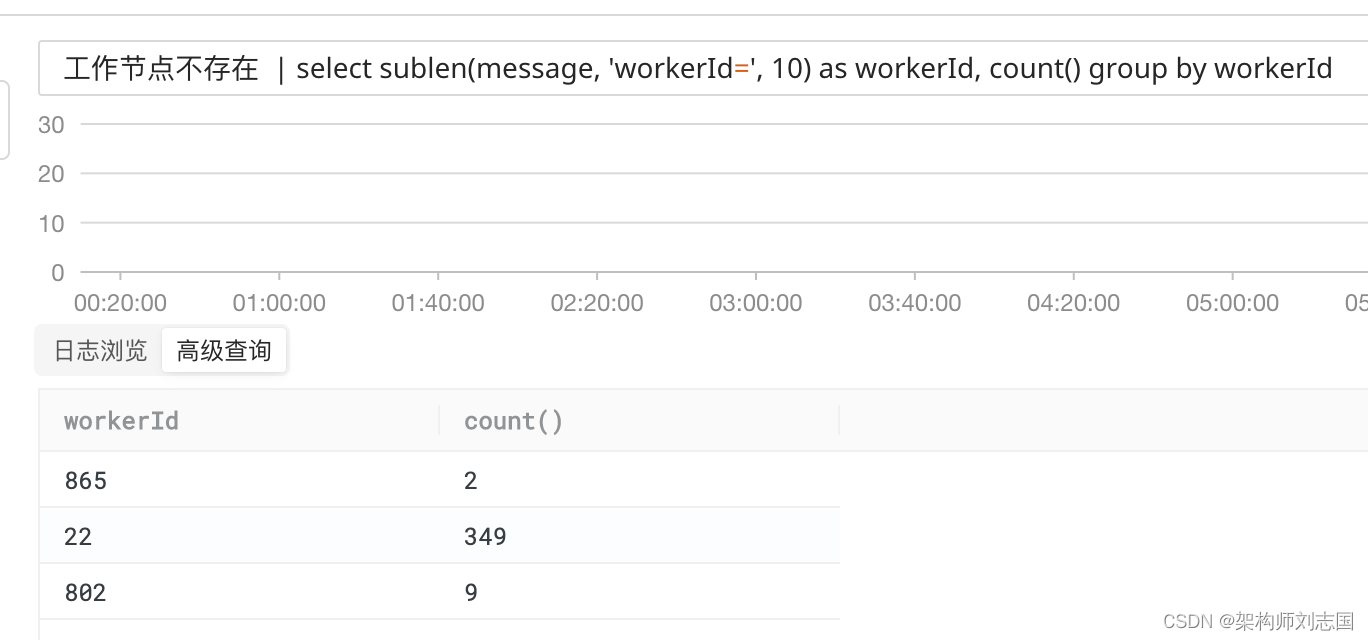
工作节点不存在 | select sublen(message, 'workerId=', 10) as workerId, count() group by workerId
首先通过「工作节点不存在」筛选日志,再通过字符串截取获取具体的 ID,最后 group 再 count() ,执行结果如下:
最终执行到 ClickHouse 的 SQL 则比较复杂,在该示例中是这样的:
SELECT sublen(message, 'workerId=', 10) AS workerId, COUNT() FROM ( SELECT dt, level, CAST((string.keys, string.values), 'Map(String,String)') AS string, CAST((number.keys, number.values), 'Map(String,Float64)') AS number, CAST((unIndex.keys, unIndex.values), 'Map(String,String)') AS unIndex, JSONExtractString(rawLog, 'message') AS message FROM log.unified_log_common_all WHERE project = 'xxx' AND dt BETWEEN '2022-08-09 21:19:12.099' AND '2022-08-09 22:19:12.099' AND (multiSearchAny(rawLog, [ '工作节点不存在' ])) ) GROUP BY workerId LIMIT 500
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
用户写的 SQL 当做父查询,我们在子查询中通过 CAST 方法将一对数组拼成了 Map 交给用户使用,这样也可以有效控制查询的范围。
而下面这个示例,则通过高级查询定位了受影响的用户。如下图日志,筛选条件为包含「活动不存在」,并导出 activityId、uid、inviteCode 字段
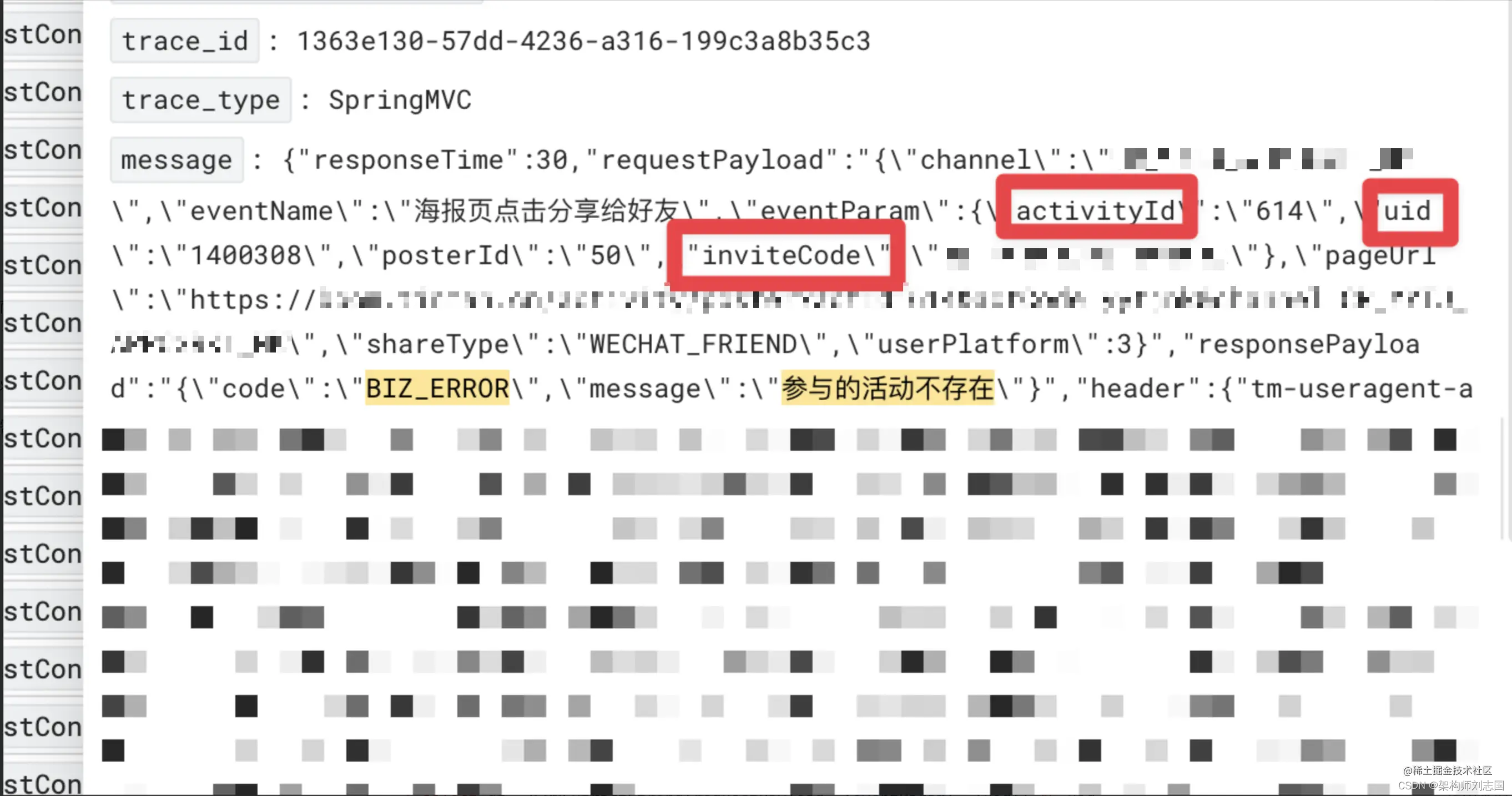
高级查询语句如下:
参与的活动不存在 and BIZ_ERROR
| select dt, JSONExtractString(message, 'requestPayload') AS requestPayload
| select dt, JSONExtractString(requestPayload, 'eventParam', 'uid') AS uid,
JSONExtractString(requestPayload, 'eventParam', 'activityId') AS activityId,
JSONExtractString(requestPayload, 'eventParam', 'inviteCode') AS inviteCode
- 1
- 2
- 3
- 4
- 5
结果如下:
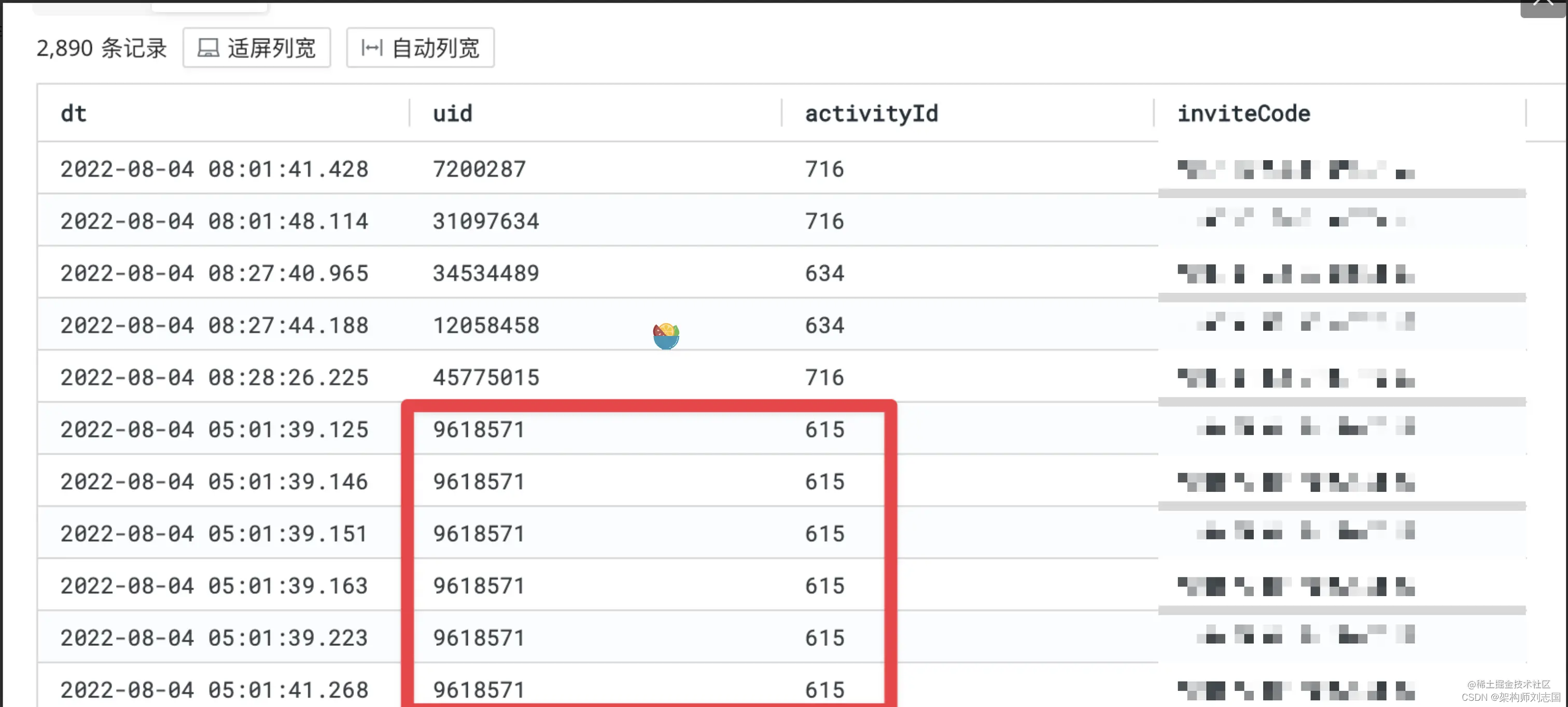
在结果中发现有重复的 uid、activityId 等,因为该日志是 HTTP 请求日志,用户会反复请求。所以还需要去重一下,在 ClickHouse 中有 limit by语法可以很方便地实现,现在高级查询如下:
参与的活动不存在 and BIZ_ERROR
| select dt, JSONExtractString(message, 'requestPayload') AS requestPayload
| select dt, JSONExtractString(requestPayload, 'eventParam', 'uid') AS uid,
JSONExtractString(requestPayload, 'eventParam', 'activityId') AS activityId,
JSONExtractString(requestPayload, 'eventParam', 'inviteCode') AS inviteCode
limit 1 by uid, activityId
- 1
- 2
- 3
- 4
- 5
- 6
查询结果中可见已经实现去重,结果数量也少了很多:
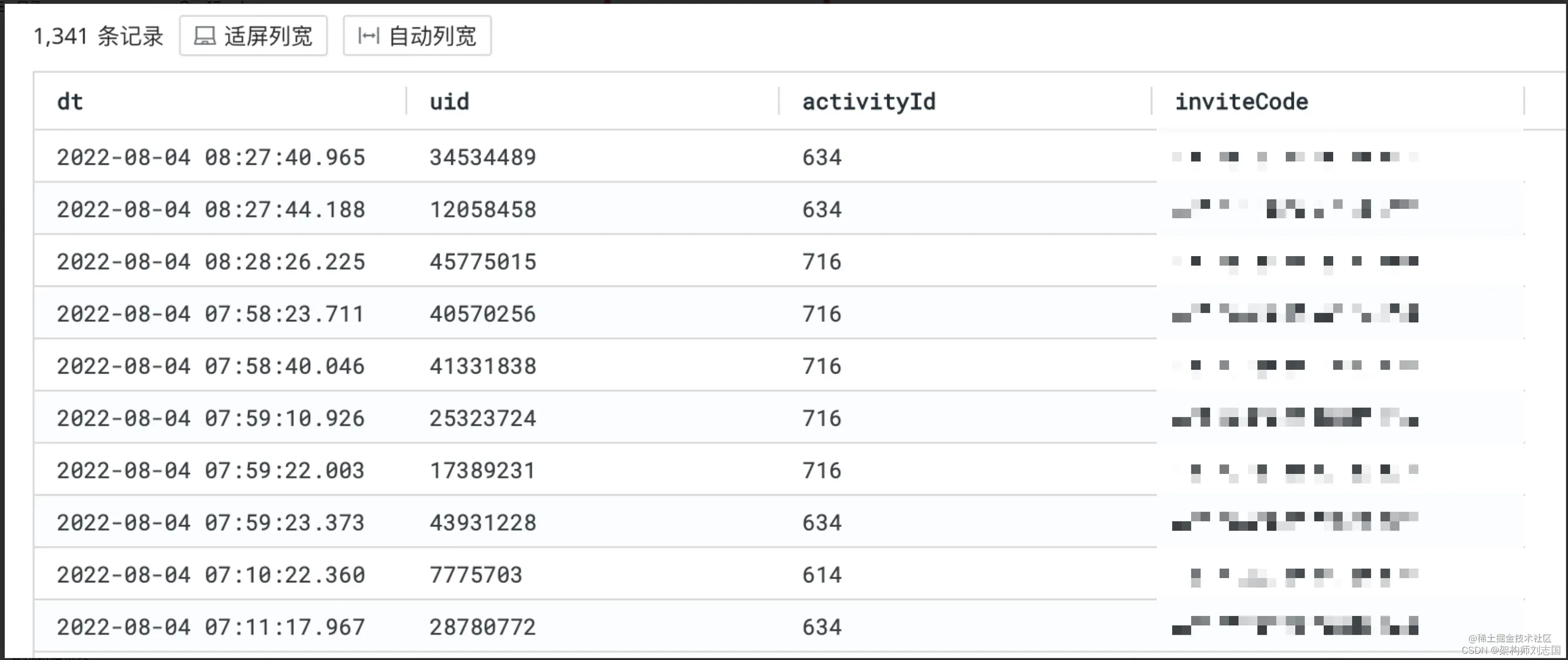
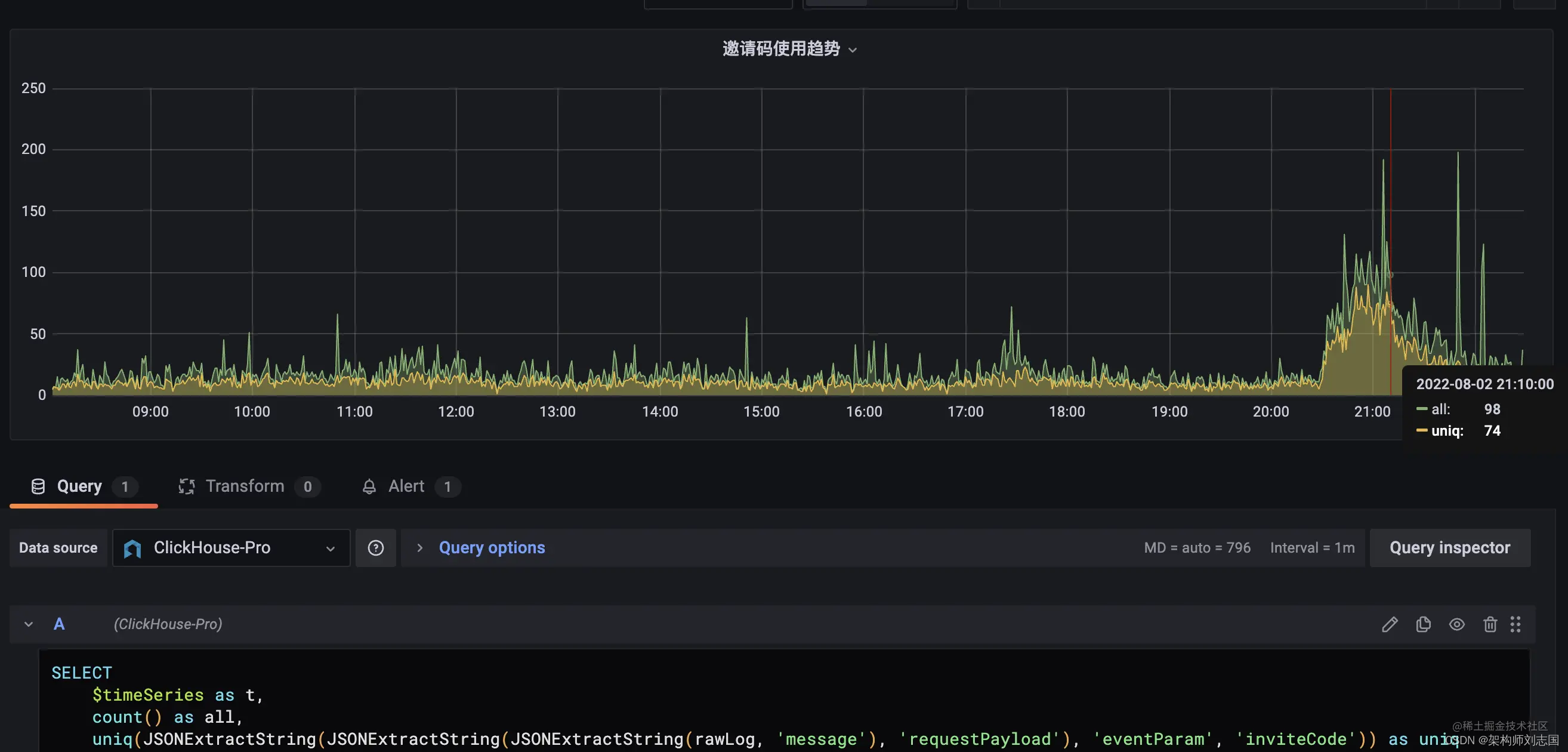
再进一步,也可以通过 inviteCode 邀请码在 Grafana 上创建面板,查看邀请码使用趋势并创建告警
自定义函数
ClickHouse 支持 UDF(User Defined Functions),于是也自定义了一些函数,方便使用。
- subend,截取两个字符串之间的内容
- sublen,截取字符串之后 N 位
- ip_to_country、ip_to_province、ip_to_city、ip_to_provider, IP 转城市、省份等
- JSONS、JSONI、JSONF: JSONExtractString、JSONExtractInt、JSONExtractFloat的简写
日志周期管理
日志备份
我们探索了很多种日志备份方式,最开始是在日志上报服务中,读 Kafka 时另写一份到 S3 中,但是遇到了很多困难。如果按照 project 的维度拆分,那么在 S3 上会产生非常多的文件。又尝试用 S3 的分片上传,但如果中间停机了,会丢失很大一部分分片数据,导致数据丢失严重;如果不按照 project 拆分,将所有服务的日志都放在一起,那么恢复日志的时候会很麻烦,即使只需要恢复 1GB 的日志,也要检索 1TB 的文件。
而 ClickHouse 本身的文件备份行不行呢,比如用 clickhouse-copier、ttl 等。首先问题还是无法按 project 区分,其次是这些在系统工程中,难以脱离人工执行。而如果使用 ttl,数据有可能没到 ttl 时间就因故丢失了。况且,我们还要求不同的 project 有不同的保存时间。
我们的最终方案是,通过 ClickHouse 的 S3 函数实现。ClickHouse 备份恢复语句如下:
-- 写入到 S3
INSERT INTO FUNCTION s3('%s','%s', '%s', 'JSONCompactEachRow', 'dt DateTime64(3), project String, level String, string$keys Array(String), string$values Array(String), number$keys Array(String), number$values Array(Float64), unIndex$keys Array(String), unIndex$values Array(String) ,rawLog String', 'gzip')
SELECT dt, project, level, string.keys, string.values, number.keys, number.values, unIndex.keys, unIndex.values, rawLog FROM log.unified_log where project = '%s' and dt between '%s' and '%s' order by dt desc limit 0,%d
-- 从 S3 恢复
insert into log.unified_log (dt, project, level, string.keys, string.values, number.keys, number.values, unIndex.keys, unIndex.values, rawLog)
select * from s3('%s','%s', '%s', 'JSONCompactEachRow', 'dt DateTime64(3), project String, level String, string$keys Array(String), string$values Array(String), number$keys Array(String), number$values Array(Float64), unIndex$keys Array(String), unIndex$values Array(String) ,rawLog String')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在日志上报服务中,每晚 1 点会跑定时任务,将前一天的日志数据逐步备份到 S3 中。
至于当天的日志,则有 Kafka 做备份,如果当天的日志丢了,则重置 kafka 的消费点位,从 0 点开始重新消费。
日志生命周期
在表的维度,有 ttl 设置。在日志控制面中可针对每个 project 配置保留时间,通过定时任务,对超时的日志执行 delete 操作: alter table unified_log delete where project = 'api-server' and dt < '2022-08-01'
由于 delete 操作负载较高,在配置生命周期时需要注意,最好对量级较大的服务独立配置生命周期。因为 delete 本质是将 Part 中的数据读出来重新写入一遍,在过程中排除符合 where 条件的数据。所以选择日志量较大的服务,才能降低 delete 操作的开销,不然没有删除的必要。
同时日志控制面也会定时监控磁盘使用量,一旦超过 95% 则启动强制措施,从最远一天日志开始执行 alter table unified_log drop partition xxx ,快速删除数据释放磁盘,避免磁盘彻底塞满影响使用。
冷数据恢复
用户选择好时间范围,指定过滤词后,执行数据恢复任务。
日志控制面会扫描 S3 上该服务的备份文件,并解冻文件(通常会对备份日志配置归档存储),等待文件解冻后,到 ClickHouse 中执行恢复。 此时用户在页面上可以看到日志恢复进度,并可以直接浏览已经恢复的日志了。
被恢复的日志会写入到一个新的虚拟集群中,具体实现为在 DataNode 中创建新的表,如 unified_log_0801,在 ReadNode 中创建新的分布式表,连接到新表中。查询时通过该分布式表查询即可。
在冷数据使用完后,删除之前创建出的表,避免长时间占用磁盘空间。
ClickHouse 性能浅谈
性能优化
ClickHouse 本身是一款非常高效且设计良好的软件,所以对它的优化也相对比较简单,纵向扩容服务器配置即可线性提高,而扩容最主要的地方就在 CPU 和存储。
在执行查询时观察 CPU 是否始终很高,在 SQL 后添加参数 settings max_threads=n 看是否明显影响查询速度。如果加了线程明显查询速度提高,则说明继续加 CPU 对提高性能是有效的。反之瓶颈则不在 CPU 。
存储上最好选择 SSD,尽量大的读写速度对查询速度帮助是极大的。而随机寻址速度好处有限,只要保证表设计合理,最终的 Part 文件数量不会太多,那么大部分的读取都是顺序的。
检查存储的瓶颈方式则很多,比如在查询时 Top 观察 CPU 的 wa 是否过高;通过 ClickHouse 命令行的查询速度结合列压缩比例,推断原始的读取速度;
而需要注意的是,如果列创建了很大的跳数索引,则可能在查询时会消耗一定量的时间。因为跳数索引是针对块的,一个 part 中可能包含几千几万个块,就有几千几万个布隆过滤器,匹配索引时需要循环挨个匹配。比如上文中跳数索引示例中,查询 trace_id 花费了 0.917s,实际上从 trace log可以看到,在索引匹配阶段花了 0.8s。
这个问题可能会在全文索引推出时得到缓解,因为布隆过滤器只能针对某几个块,布隆过滤器之间无法协作,数据的实际维度是 块 → 过滤器。而全文索引(倒排索引)正好将这个关系倒过来,过滤器→块,索引阶段不用循环匹配,速度则会提高很多。不过最终还是看官方怎么实现了,而且全文索引在数据写入时的开销也一定会比布隆过滤器高一些。
性能成本平衡
对我来说,日志自然是要充分满足即席查询的,所以优先保证查询速度,而不是成本和存储时长。而这套日志系统也可以根据不同的权衡,有不同的玩法。
性能优先型
在我们的实践中,使用了云平台的自带 SSD 型机器,CPU 基本够用,可以提供极高的读写性能,单盘可以达到 3GB/s。在使用时我们做了软 raid,来降低 ClickHouse 配置的复杂度。
这种部署成本也能做到很低,相比使用服务商的云盘要低 70% 左右。
存储分离型
存储使用服务商提供的云盘,优点是云盘可以随时扩容而且不丢数据。可以一定程度上单独扩容存储量和读写能力。
缺点是云盘通常不便宜,低等级的云盘提供的读写能力较差,而且读写会受限于服务器的网络带宽。高等级的云盘需要配合高规格的服务器才能完全发挥。
完全 S3 型
ClickHouse 的存储策略添加 S3 类型,并将表的 storage_policy 指定为S3。这样利用 S3 极低的存储价格,基本不用担心存储费用问题。
缺点是 S3 存储目前还不健全,可能会踩坑。S3 的性能当然也不算好,还会受限于单个 Bucket 的吞吐上限。不过用来承载低负载的场景还是很有价值的。另一种办法是使用 Minio 这类可以使用 S3 作为存储,对软件来说还是硬盘存储。
结语
基于 ClickHouse 构建的通用日志系统,有希望带领日志走向另一条道路,日志本就不应该是搜索引擎,而应该是大数据。未来日志的侧重点,应该更多从查询浏览,转向分析挖掘。
我们也在探索日志在定时分析,批分析上的能力,让日志能够发挥出更大的价值。这套日志系统也很快有公开的 demo 以供诸君把玩。

