
- 1智能加速:AI光模块助力数据中心迈向400G/800G超高速率的新境界
- 2Android Studio学习笔记(二)_android studio笔记(二)
- 3如何安装llvm的比较新的版本_lib库llvmjit.so 升级
- 4中文词向量:使用pytorch实现CBOW_怎样查看torch里有没有cbow
- 5通过 docker-compose 快速部署 DolphinScheduler 保姆级教程_dolphinscheduler docker
- 6java final 修饰变量_Java笔记:final修饰符
- 7Facebook广告投放技巧及思路、如何最大化发挥广告效益!_fb广告先投awareness获得数据再跟帖投转化
- 8安全计算环境(设备和技术注解)_当远程管理云计算平台中设备时,管理终端和云计算平台之间应建立双向身份验证机制
- 951单片机课程设计——基于单片机的AD模数转换设计_51单片机ad是什么
- 10飞桨自然语言处理框架 paddlenlp的 trainer_paddlenlp.trainer中train
LASSO回归
赞
踩
LASSO回归
LASSO(Least Absolute Shrinkage and Selection Operator,最小绝对值收敛和选择算子算法)是一种回归分析技术,用于变量选择和正则化。它由Robert Tibshirani于1996年提出,作为传统最小二乘回归方法的替代品。
损失函数
1.线性回归
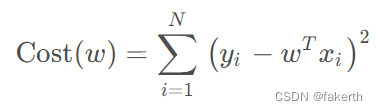
2.岭回归
岭回归的损失函数,在标准线性回归损失函数的基础上,增加了对权重的控制,作为正则化项,惩罚系λ乘以w向量的L2-范数的平方。
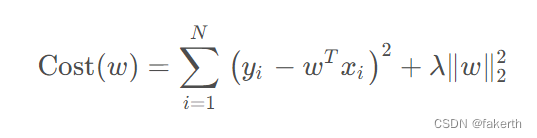
3.LASSO回归
LASSO回归的损失函数,同样在标准线性回归损失函数的基础上,增加了正则化项,正则化项改为惩罚系数λ乘以w向量的L1-范数的平方。
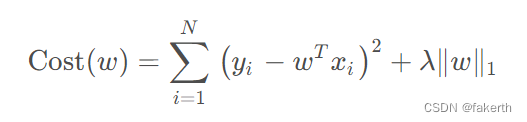
岭回归和LASSO回归通过调节λ的值来控制正则化的强度。λ的值越大,收缩效果越明显,越多的预测变量系数被设为零。相反,λ的值越小,模型越不稀疏,允许更多的预测变量具有非零系数。较小的λ值会接近于普通最小二乘回归。
在LASSO回归中,由于L1范数的几何特性,导致某些参数估计值为零,从而实现了变量的稀疏性。而岭回归通常会使得参数估计值接近于零,但不会精确地将某些参数收缩到零。
由于LASSO损失函数存在绝对值,所以并不是处处可导的,所以没办法通过直接求导的方式来直接得到w。
坐标下降法
坐标下降法(Coordinate Descent)是一种优化算法,用于求解无约束优化问题。它适用于目标函数可分解为各个变量的子问题的情况,即目标函数可以表示为各个变量的函数的和。
坐标下降法的基本思想是,在每次迭代中,固定除一个变量以外的其他变量,通过求解仅关于该变量的子问题来更新该变量的值。然后依次对每个变量进行更新,直到满足停止准则或达到最大迭代次数。坐标下降法的迭代步骤如下:
-
1.初始化变量的初始值。
-
2.选择一个变量wi。
-
3.将除变量wi以外的其他变量固定,将目标函数表示为只关于变量wi的函数。
-
4.求解子问题,更新变量wi的值,使得目标函数最小化。
-
5.重复步骤2-4,对下一个变量进行更新,直到所有变量都被更新一遍。
-
6.检查停止准则(当所有权重系数的变化不大或者到达最大迭代次数时,结束迭代
),如果满足停止准则,则停止迭代;否则返回步骤2。
在第k次迭代时,更新权重系数的方法如下:

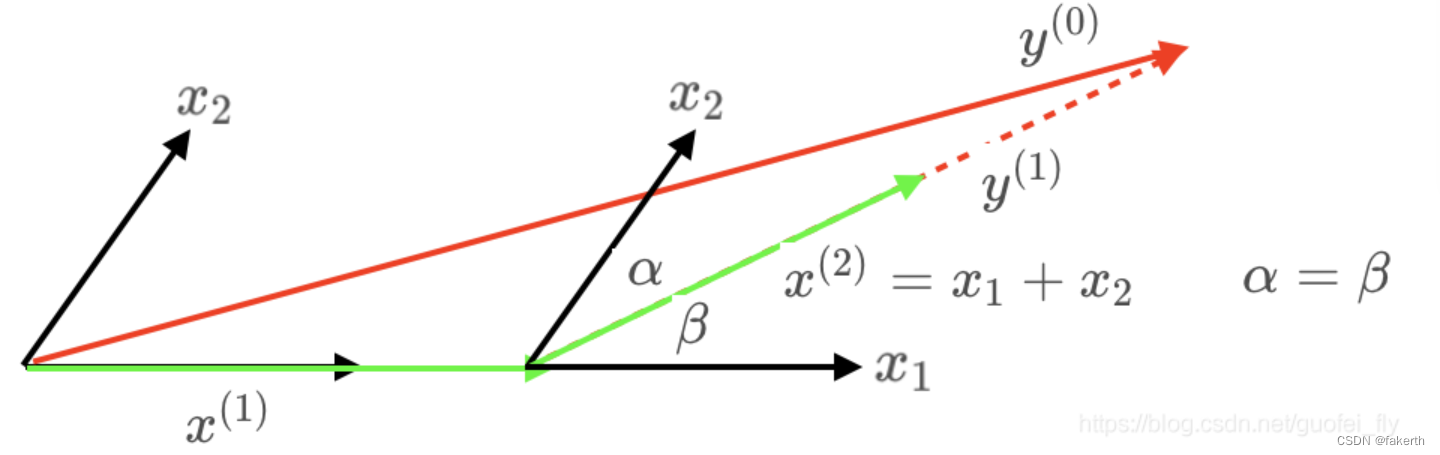
最小角回归
-
1.初始化:将所有自变量的系数设为零。
-
2.计算残差:计算当前模型的残差向量,表示目标变量与当前模型预测之间的差异。
-
3.选择自变量:选择与残差向量具有最大相关性的自变量。可以使用内积或相关系数来度量相关性。在初始阶段,与残差具有最大相关性的自变量将被选为第一个加入模型的自变量。
-
4.移动向量:将当前自变量的系数朝着它与残差向量之间的夹角最小的方向移动。这可以通过计算自变量与残差向量的内积来实现。
-
5.跟踪相关性:跟踪已选定自变量与其他自变量之间的相关性变化。为此,计算每个自变量与残差向量之间的相关系数。
-
6.更新系数:根据相关性的变化,更新自变量的系数。具体而言,增加具有最大相关系数的自变量的系数,使其逐渐接近其最终值。
-
7.跟踪变量:在更新系数后,重新计算已选定自变量与其他自变量之间的相关系数,以跟踪相关性的变化。
-
8.重复步骤4-7:重复移动向量、跟踪相关性和更新系数的步骤,直到选择的自变量数达到预设的阈值或满足其他停止准则。停止准则可以是预先确定的自变量数目,也可以是基于交叉验证或信息准则的模型选择方法。
sklearn实现
1.坐标下降法
from sklearn.linear_model import Lasso
# 初始化Lasso回归器,默认使用坐标下降法
reg = Lasso(alpha=0.1, fit_intercept=False)
# 拟合线性模型
reg.fit(X, y)
# 权重系数
w = reg.coef_
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.最小角回归法
from sklearn.linear_model import LassoLars
# 初始化Lasso回归器,使用最小角回归法
reg = LassoLars(alpha=0.1, fit_intercept=False)
# 拟合线性模型
reg.fit(X, y)
# 权重系数
w = reg.coef_
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

