
- 1Ros结合科大讯飞linuxSDK进行离线语唤醒、命令识别_树莓派 科大讯飞离线语音唤醒
- 2为什么2024年Java 就业一地鸡毛,找工作这么难找?
- 31.3.2微信小程序 WXSS_at iolimit.runwithcb
- 4本地与远程的github取消关联_删除github本地项目和github的关联
- 5鸿蒙OS开发实战:【自动化测试框架】使用指南_鸿蒙测试
- 6emoji 乱码_emoji表情更新117名新成员,终于有珍珠奶茶啦!
- 7TCP的滑动窗口机制_滑动窗口机制是要提前设置一个窗口大小吗
- 8总结不同方案实现-LLM数据库查询-即Text2SQL
- 9生产RabbitMQ队列阻塞该如何处理?_rabbitmq unchecked阻塞
- 10window.URL.createObjectURL
使用 Docker 搭建 Hadoop 分布式环境_windows系统docker怎么搭建hadoop框架(1)
赞
踩
git clone https://github.com/big-data-europe/docker-hadoop.git
- 1
- 2
然后进入到 docker-hadoop 目录下运行
docker-compose up -d
- 1
- 2
下载 hadoop 镜像并创建容器。
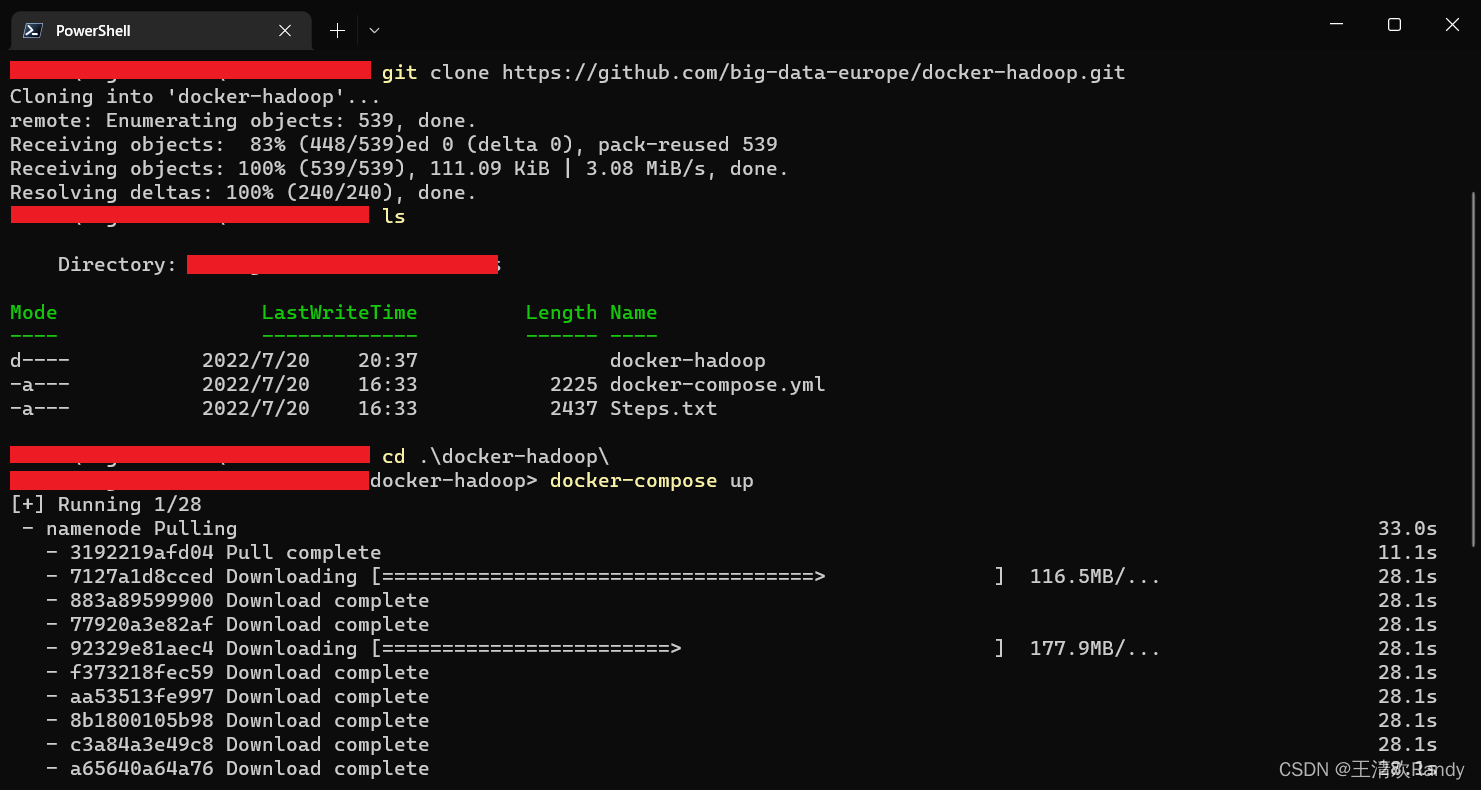
该命令执行完成之后使用 docker container ls 命令查看被启动的容器,我们可以看到如下 5 个节点

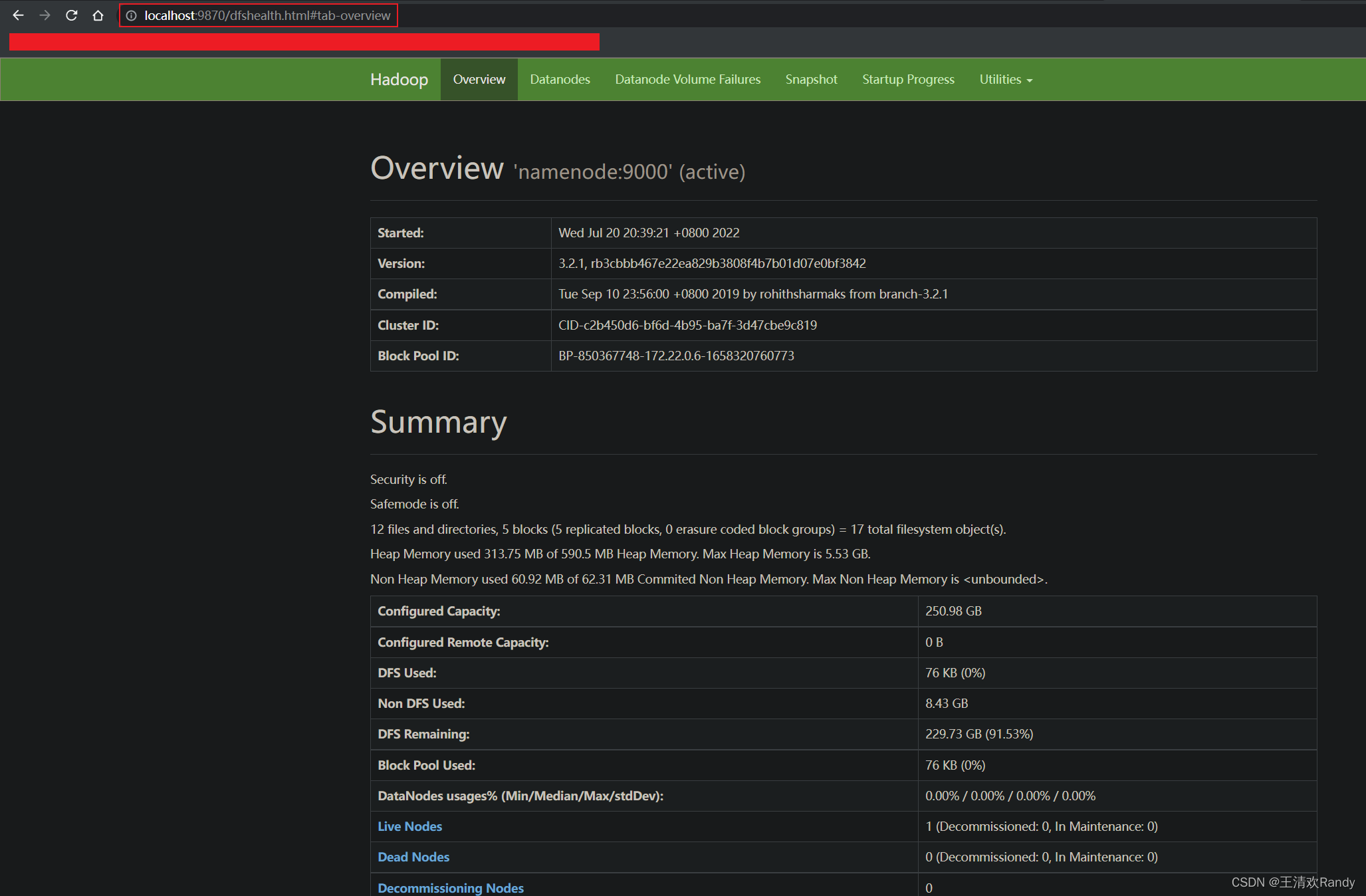
Hadoop 集群被成功启动后,可以通过如下 URL 访问各节点
Namenode: http://<dockerhadoop_IP_address>:9870/dfshealth.html#tab-overview
History server: http://<dockerhadoop_IP_address>:8188/applicationhistory
Datanode: http://<dockerhadoop_IP_address>:9864/
Nodemanager: http://<dockerhadoop_IP_address>:8042/node
Resource manager: http://<dockerhadoop_IP_address>:8088/
- 1
- 2
- 3
- 4
- 5
- 6
通过浏览器访问 Namenode 可以看到如下 Hadoop 集群管理页面
增加数据节点
到这里 Hadoop 集群已经创建完成了,如果想增加节点,可以通过修改 docker-hadoop 中的 docker-compose.yml 文件来实现。
例如,我们给当前集群增加两个数据节点 datanode 对 docker-compose.yml 文件修改如下:
datanode: image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8 container\_name: datanode restart: always volumes: - hadoop_datanode:/hadoop/dfs/data environment: SERVICE\_PRECONDITION: "namenode:9870" env\_file: - ./hadoop.env datanode2: image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8 container\_name: datanode2 restart: always volumes: - hadoop_datanode2:/hadoop/dfs/data environment: SERVICE\_PRECONDITION: "namenode:9870" env\_file: - ./hadoop.env datanode3: image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8 container\_name: datanode3 restart: always volumes: - hadoop_datanode3:/hadoop/dfs/data environment: SERVICE\_PRECONDITION: "namenode:9870" env\_file: - ./hadoop.env

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
然后重新执行 docker-compose up -d 增加节点
03 测试 Hadoop 集群
测试准备
我们使用简单的词频统计 mapreduce 任务来测试 Hadoop 集群
首先下载 hadoop-mapreduce-examples jar 包
然后使用如下命令将这个 jar 包拷贝到 namenode 节点
docker cp .\hadoop-mapreduce-examples-2.7.1.jar namenode:/tmp/
- 1
- 2
然后我们创建一个 input.txt 测试文件,并输入文字内容
We can only go faster, we can only aim higher, we can only become stronger by standing together — in solidarity.
然后也将这个输入文件拷贝到 namenode 节点中
docker cp .\input.txt namenode:/tmp/
- 1
- 2

开始测试
首先使用如下命令进入到 namenode 容器中,并进入到 tmp 目录
docker exec -it namenode /bin/bash
cd tmp/
- 1
- 2
- 3
然后使用如下命令在 HDFS 中创建一个 input 目录
hdfs dfs -mkdir -p /user/root/input
- 1
- 2
将输入文件 input.txt 存储到 HDFS 中
hdfs dfs -put input.txt /user/root/input
# 查看输入文件内容
hdfs dfs -cat /user/root/input/input.txt
- 1
- 2
- 3
- 4
Tips:可以将文件通过如下命令添加到指定的 Datanode 节点中
hdfs dfs -put Input.txt the-datanode-id

最后使用如下命令在 Hadoop 集群中运行 wordcount 词频统计 mapreduce 任务

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
深入研究,那么很难做到真正的技术提升。**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

