
- 1C#中Winform使用OpenFileDialog选择文件打开并获取文件路径_通过openfiledialog选择文件路径
- 2react项目内存溢出,加大内存的方式之一 Ineffective mark-compacts near heap limit Allocation failed - JavaScript heap_vscode的react项目内存溢出
- 3Redis实现分布式锁的原理:常见问题解析及解决方案、源码解析Redisson的使用_分布式事务redis解决方案
- 42024永久免费版CrossOver软件下载及使用方法详细的步骤_crossover安装包
- 5guitar pro 8许可证忘记了怎么办 guitar pro8谱数字可以改吗
- 6基于微信学生新生报到小程序系统设计与实现
- 7ROS Motion Planning运动规划库安装方法及进阶使用方法详细介绍
- 8pom可视化idea_GitHub - haizlin-idea/rsbi-pom: 睿思BI-数据仪表盘,开源商业智能,数据可视化系统...
- 9在CDH集群安装Flink
- 10单片机学习笔记---独立按键控制LED亮灭_单片机按键控制led灯亮灭
基于Keras_bert模型的Bert使用与字词预测_keras-bert
赞
踩
基于Keras_bert模型的Bert使用与字词预测
学习参考杨老师的博客,请支持原文
一、Keras_bert 基础知识
1.1、kert_bert库安装
Kert_bert库是基于Keras库对Bert进行封装的Python库,可以实现直接对官方预训练权重的调用训练
但是该库在安装使用方面对于版本的兼容性要求比较高,python版本、tensorfolw版本、Keras版本、Kert_bert版本的相互之间需要相互的兼容。
本人由于习惯于使用Python3.6版本,基本都是在3.6版本上,安装tensoflow与keras库。tensorflow与keras的对应关系:
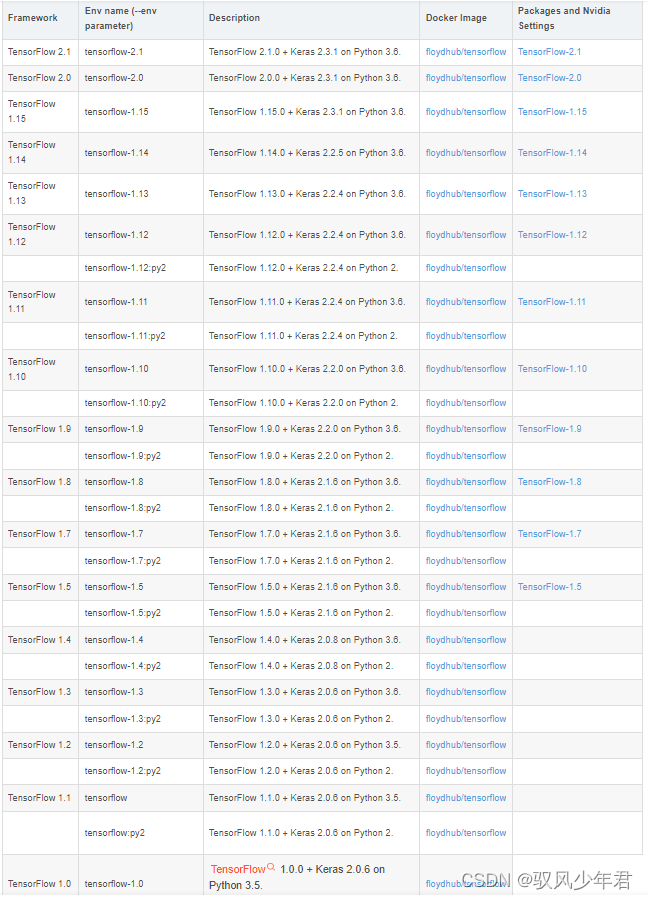
tensorflow2.0以上会出现和keras版本问题,在安装Kert_bert库出现很多次的Keras和keras_bert模型不兼容问题,多次搜索调试后选择版本如下:
tensorflow: 2.2.0
keras: 2.4.3
keras_bert: 0.89.0
Python 3.6.13
该版本,目前使用未出现问题。
1.2 Tokenizer文本拆分
keras_bert内嵌的Tokenizer可以实现对于字单位级别的拆分,并且生成相应的id,通过字典存放相应的token和id映射。
Tookenizer需要传入相应的字符所对应的id映射字典token_dict,其中[CLS]代表句子的起始,[SEP]代表句子的结束,[UNK]代表该该词未登录token_dict
from keras_bert import Tokenizer token_dict = { '[CLS]': 0, '[SEP]': 1, '今': 2, '天': 3, '气': 4, '很':5, '好':6, '[UNK]':7 , } #生成分词器-tokenizer对象 tokenizer = Tokenizer(token_dict) #用生成的分词器对象对句子拆分 print('拆分:',tokenizer.tokenize('今天天气很好')) #用生成的分词器对句子的字符进行ID映射编码 indices, segments = tokenizer.encode('今天天气很好') print('索引:',indices) #字对应索引 # -----------------------多句子训练------------------------------------ print('-----------传入两句话,max_len=10------------------------------') tokenizer.tokenize(first='今天天气很好', second='今天天蓝很不错') indices, segments = tokenizer.encode(first='今天天气很好', second='今天天蓝很不错', max_len=10) print(indices) #索引对应位置上字属于第一句话还是第二句话 print(segments) print('-------------传入两句话,max_len=20-------------------------') indices, segments = tokenizer.encode(first='今天天气很好', second='今天天蓝很不错', max_len=20) print(indices) #索引对应位置上字属于第一句话还是第二句话 print(segments)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
拆分: [‘[CLS]’, ‘今’, ‘天’, ‘天’, ‘气’, ‘很’, ‘好’, ‘[SEP]’]
索引: [0, 2, 3, 3, 4, 5, 6, 1]
-----------传入两句话,max_len=10------------------------------
[0, 2, 3, 3, 4, 1, 2, 3, 3, 1]
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1]
-------------传入两句话,max_len=20-------------------------
[0, 2, 3, 3, 4, 5, 6, 1, 2, 3, 3, 7, 5, 7, 7, 1, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
可以看出当出现token_dict未登录的词就转成了nuk,编码为7
当句子长度超过maxlen就都会被裁切掉
当句子长度不足maxlen,就会填充0
1.3 训练和使用
可见在使用之前需要先获取token_dict,才能进行下一步,用keras_bert中的,get_base_dict可以获取初始的tokendict,再对每个句子中的词进行编码
import keras from keras_bert import get_base_dict, get_model, compile_model, gen_batch_inputs #输入样本:toy玩具 sentence_pairs = [ [['all', 'work', 'and', 'no', 'play'], ['makes', 'jack', 'a', 'dull', 'boy']], [['from', 'the', 'day', 'forth'], ['my', 'arm', 'changed']], [['and', 'a', 'voice', 'echoed'], ['power', 'give', 'me', 'more', 'power']], ] #构建token词典 token_dict = get_base_dict() # A dict that contains some special tokens print('初始的tokendict:',token_dict) for pairs in sentence_pairs: print('pairs:',pairs) print('pairs[0] + pairs[1]:',pairs[0] + pairs[1]) for token in pairs[0] + pairs[1]: print('token:',token) if token not in token_dict: token_dict[token] = len(token_dict) token_list = list(token_dict.keys()) # Used for selecting a random word print('-----------------token_dict------------------') print(token_dict) print('-----------------token_list------------------') print('token_list:',token_list)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
初始的tokendict: {‘’: 0, ‘[UNK]’: 1, ‘[CLS]’: 2, ‘[SEP]’: 3, ‘[MASK]’: 4}
pairs: [[‘all’, ‘work’, ‘and’, ‘no’, ‘play’], [‘makes’, ‘jack’, ‘a’, ‘dull’, ‘boy’]]
pairs[0] + pairs[1]: [‘all’, ‘work’, ‘and’, ‘no’, ‘play’, ‘makes’, ‘jack’, ‘a’, ‘dull’, ‘boy’]
token: all
token: work
token: and
token: no
token: play
token: makes
token: jack
token: a
token: dull
token: boy
pairs: [[‘from’, ‘the’, ‘day’, ‘forth’], [‘my’, ‘arm’, ‘changed’]]
pairs[0] + pairs[1]: [‘from’, ‘the’, ‘day’, ‘forth’, ‘my’, ‘arm’, ‘changed’]
token: from
token: the
token: day
token: forth
token: my
token: arm
token: changed
pairs: [[‘and’, ‘a’, ‘voice’, ‘echoed’], [‘power’, ‘give’, ‘me’, ‘more’, ‘power’]]
pairs[0] + pairs[1]: [‘and’, ‘a’, ‘voice’, ‘echoed’, ‘power’, ‘give’, ‘me’, ‘more’, ‘power’]
token: and
token: a
token: voice
token: echoed
token: power
token: give
token: me
token: more
token: power
-----------------token_dict------------------
{‘’: 0, ‘[UNK]’: 1, ‘[CLS]’: 2, ‘[SEP]’: 3, ‘[MASK]’: 4, ‘all’: 5, ‘work’: 6, ‘and’: 7, ‘no’: 8, ‘play’: 9, ‘makes’: 10, ‘jack’: 11, ‘a’: 12, ‘dull’: 13, ‘boy’: 14, ‘from’: 15, ‘the’: 16, ‘day’: 17, ‘forth’: 18, ‘my’: 19, ‘arm’: 20, ‘changed’: 21, ‘voice’: 22, ‘echoed’: 23, ‘power’: 24, ‘give’: 25, ‘me’: 26, ‘more’: 27}
-----------------token_list------------------
token_list: [‘’, ‘[UNK]’, ‘[CLS]’, ‘[SEP]’, ‘[MASK]’, ‘all’, ‘work’, ‘and’, ‘no’, ‘play’, ‘makes’, ‘jack’, ‘a’, ‘dull’, ‘boy’, ‘from’, ‘the’, ‘day’, ‘forth’, ‘my’, ‘arm’, ‘changed’, ‘voice’, ‘echoed’, ‘power’, ‘give’, ‘me’, ‘more’]
构建模型
#构建训练模型
model = get_model(
token_num=len(token_dict),
head_num=5,
transformer_num=12,
embed_dim=25,
feed_forward_dim=100,
seq_len=20,
pos_num=20,
dropout_rate=0.05,
)
compile_model(model) #模型编译
model.summary() #模型简介
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
模型训练
def _generator(): while True: yield gen_batch_inputs( sentence_pairs, token_dict, #传入token_dict token_list, #传入token_list seq_len=20, mask_rate=0.3, swap_sentence_rate=1.0, ) #模型训练 model.fit_generator( generator=_generator(), #传入构建的函数 steps_per_epoch=1000, epochs=100, validation_data=_generator(), validation_steps=100, callbacks=[ keras.callbacks.EarlyStopping(monitor='val_loss', patience=5) ], )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
使用模型
#使用训练好的模型
inputs, output_layer = get_model(
token_num=len(token_dict),
head_num=5,
transformer_num=12,
embed_dim=25,
feed_forward_dim=100,
seq_len=20,
pos_num=20,
dropout_rate=0.05,
training=False, # The input layers and output layer will be returned if `training` is `False`
trainable=False, # Whether the model is trainable. The default value is the same with `training`
output_layer_num=4, # The number of layers whose outputs will be concatenated as a single output.
# Only available when `training` is `False`.
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
1.4 AdamWarmup
AdamWarmup优化器( optimizer )要用于预热( warmup )和衰减( decay)。学习率经过warmpup_ steps步后将达到Ir ,经过decay_ steps步后将衰减到min_ Ir。 中, calc_ train_ steps是 辅助函数,用于计算这两个步骤。
import numpy as np from keras_bert import AdamWarmup, calc_train_steps #生成随机数 train_x = np.random.standard_normal((1024, 100)) print(train_x) #分批训练 total_steps, warmup_steps = calc_train_steps( num_example=train_x.shape[0], batch_size=32, epochs=10, warmup_proportion=0.1, ) optimizer = AdamWarmup(total_steps, warmup_steps, lr=1e-3, min_lr=1e-5) print(optimizer)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
1.5 获取预先训练的检测点
用get_pretrained函数获取
from keras_bert import get_pretrained, PretrainedList, get_checkpoint_paths
#下载解压数据
model_path = get_pretrained(PretrainedList.multi_cased_base) #模型路径
paths = get_checkpoint_paths(model_path) #获取预训练地址
print('paths.config:',paths.config)
print('paths.checkpoint:',paths.checkpoint)
print('paths.vocab:', paths.vocab)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
paths.config: C:\Users\N.keras\datasets\multi_cased_L-12_H-768_A-12\bert_config.json
paths.checkpoint: C:\Users\N.keras\datasets\multi_cased_L-12_H-768_A-12\bert_model.ckpt
paths.vocab: C:\Users\N.keras\datasets\multi_cased_L-12_H-768_A-12\vocab.txt
1.6抽取特征
如果需要tokens或句子的特征,则可以使用辅助函数extract_ embeddings。 下面的代码能提取所有的tokens特征。
需要传入模型的上文获取的模型地址,和待抽取的句子文本
from keras_bert import extract_embeddings
# model_path = get_pretrained(PretrainedList.multi_cased_base)
texts = ['all work and no play', 'makes jack a dull boy~']
embeddings = extract_embeddings(model_path, texts)
print('------------------句子特征------------------')
print(embeddings)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
------------------句子特征------------------
[array([[ 0.07531555, -0.15103097, 0.16370851, …, 0.77671117,
0.02733378, -0.0297538 ],
[-0.12954001, -0.35776633, 0.02477884, …, 1.4055997 ,
0.16759634, -0.29797873],
[-0.26747486, -0.26116127, 0.11113451, …, 1.3588182 ,
0.10443275, -0.415785 ],
…,
[-0.34335068, -0.252737 , -0.68407285, …, 1.3278028 ,
-0.15623422, -0.4789365 ],
[-0.24592108, -0.12426493, -0.07056627, …, 1.3984789 ,
-0.03810839, -0.19883244],
[-0.02836535, -0.2510882 , 0.3347783 , …, 0.7883287 ,
0.05263783, -0.11937716]], dtype=float32), array([[ 0.30098903, -0.22291777, 0.6170633 , …, 0.5640485 ,
-0.03552696, 0.15263349],
[ 0.10523404, -0.2641968 , 0.6566459 , …, 1.0994014 ,
-0.13300316, 0.0962064 ],
[-0.2954503 , -0.35092717, 0.45172513, …, -0.24845225,
-0.4451233 , -0.0801053 ],
…,
[ 0.43035302, -0.31948596, 0.4378098 , …, 0.17429134,
-0.41476333, -0.09128644],
[ 0.47151148, -0.29935226, 0.6846881 , …, 0.34857082,
-0.11684854, -0.11591156],
[ 0.26193255, -0.16078277, 0.83464456, …, 0.53757495,
-0.04961903, 0.0441534 ]], dtype=float32)]
二、中文文本Bert预训练模型
2.1下载中文语料
首先,我们下载官方预训练模型chinese_L-12_H-768_A-12。
Google提供了多种预训练好的Bert模型,有针对不同语言的和不同模型大小。对于中文模型,我们使用Bert Base Chinese。
需要先下载好预训练的模型,解压到相应的位置,再读取相应文件夹的位置。
- Bert源代码: htps://github com/google-research/bert
- Bert预训练模型: https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip
import os
from keras_bert import load_vocabulary
from keras_bert import Tokenizer
from keras_bert import load_trained_model_from_checkpoint
#设置预训练模型的路径
pretrained_path = r'G:\chinese_L-12_H-768_A-12'
config_path = os.path.join(pretrained_path, 'bert_config.json')
checkpoint_path = os.path.join(pretrained_path, 'bert_model.ckpt')
vocab_path = os.path.join(pretrained_path, 'vocab.txt')
#构建中文字典ID映射
token_dict = load_vocabulary(vocab_path)
print(token_dict)
print('中文ID字典长度:',len(token_dict))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15

可以看到一共21128个词,同时也构建出来了相应的中文ID映射,就可以接着往下
#Tokenization
tokenizer = Tokenizer(token_dict)
print(tokenizer)
#加载预训练模型
model = load_trained_model_from_checkpoint(config_path, checkpoint_path)
print(model)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
<keras_bert.tokenizer.Tokenizer object at 0x000000006DE8CB38>
<tensorflow.python.keras.engine.training.Model object at 0x00000000E272B8D0>
2.2 从预加载模型中提取中文字特征
对自定义语料进行tokenizer处理,并使用预训练模型提取输入文本的特征。
仅提取出前5的位的向量值来查看
#-------------------------------第二步 特征提取--------------------------------- text = '语言模型' #先用分词器对象,将目标文本拆分,标准化 tokens = tokenizer.tokenize(text) print('标准化:',tokens) #获取对应字在字典中的ID映射 indices, segments = tokenizer.encode(first=text, max_len=512) print('----------------ID映射----------------') print(indices[:10]) print(segments[:10]) #根据ID提取模型中的字特征 print('---------------提取字特征-------------') predicts = model.predict([np.array([indices]), np.array([segments])])[0] #获取 for i, token in enumerate(tokens): #输出 print(token, predicts[i].tolist()[:5])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
标准化: [‘[CLS]’, ‘语’, ‘言’, ‘模’, ‘型’, ‘[SEP]’]
----------------ID映射----------------
[101, 6427, 6241, 3563, 1798, 102, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
---------------提取字特征-------------
[CLS] [-0.6339437961578369, 0.2029203623533249, 0.08105022460222244, -0.0326896607875824, 0.5675354599952698]
语 [-0.7589297890663147, 0.09625156223773956, 1.072314739227295, 0.006224252283573151, 0.6886608004570007]
言 [0.5497941970825195, -0.7931232452392578, 0.44259175658226013, -0.7123060822486877, 1.2053987979888916]
模 [-0.29216861724853516, 0.606366753578186, 0.4984245002269745, -0.42493146657943726, 0.426719069480896]
型 [-0.7458041906356812, 0.4949134290218353, 0.7189165353775024, -0.8728538155555725, 0.8354955911636353]
[SEP] [-0.8752526640892029, -0.21610988676548004, 1.339908480644226, -0.10673223435878754, 0.3961635231971741]
2.3 多句子特征提取
和前面一样,可以实现多个句子的特征提取
#----------------------------第三步 多句子特征提取------------------------------ text1 = '语言模型' text2 = "你好" tokens1 = tokenizer.tokenize(text1) print(tokens1) tokens2 = tokenizer.tokenize(text2) print(tokens2) indices_new, segments_new = tokenizer.encode(first=text1, second=text2 ,max_len=512) print(indices_new[:10]) #[101, 6427, 6241, 3563, 1798, 102, 0, 0, 0, 0] print(segments_new[:10]) #[0, 0, 0, 0, 0, 0, 0, 0, 0, 0] #提取特征 predicts_new = model.predict([np.array([indices_new]), np.array([segments_new])])[0] for i, token in enumerate(tokens1): print(token, predicts_new[i].tolist()[:5]) for i, token in enumerate(tokens2): print(token, predicts_new[i].tolist()[:5])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
[‘[CLS]’, ‘语’, ‘言’, ‘模’, ‘型’, ‘[SEP]’]
[‘[CLS]’, ‘你’, ‘好’, ‘[SEP]’]
[101, 6427, 6241, 3563, 1798, 102, 872, 1962, 102, 0]
[0, 0, 0, 0, 0, 0, 1, 1, 1, 0]
[CLS] [-0.3404940962791443, 0.5169003009796143, 0.8958081603050232, -0.5850763916969299, 0.1620779037475586]
语 [-0.6919717788696289, 0.37331458926200867, 1.3196662664413452, -0.0865214616060257, 0.5522887110710144]
言 [0.6706017851829529, -0.5946153402328491, 0.4751562178134918, -0.7590199112892151, 0.9860224723815918]
模 [-0.4227488040924072, 0.7286509871482849, 0.5555989742279053, -0.43479853868484497, 0.39219915866851807]
型 [-0.5974094271659851, 0.5976635217666626, 0.7734537124633789, -1.0439568758010864, 0.8142789006233215]
[SEP] [-1.1663365364074707, 0.541653037071228, 1.396380066871643, 0.014762230217456818, -0.20481276512145996]
[CLS] [-0.3404940962791443, 0.5169003009796143, 0.8958081603050232, -0.5850763916969299, 0.1620779037475586]
你 [-0.6919717788696289, 0.37331458926200867, 1.3196662664413452, -0.0865214616060257, 0.5522887110710144]
好 [0.6706017851829529, -0.5946153402328491, 0.4751562178134918, -0.7590199112892151, 0.9860224723815918]
[SEP] [-0.4227488040924072, 0.7286509871482849, 0.5555989742279053, -0.43479853868484497, 0.39219915866851807]
2.4 根据预训练的模型向量实现字词预测
可以根据相应字向量,实现对于未知词的预测。
将一句话中的某个字mask掉,再预测。
#------------------------------第四步 字词预测填充------------------------------ #加载语言模型 model = load_trained_model_from_checkpoint(config_path, checkpoint_path, training=True) token_dict_rev = {v: k for k, v in token_dict.items()} token_ids, segment_ids = tokenizer.encode( u'数学是利用符号语言研究数量、结构、变化以及空间等概念的一门学科', max_len=512) #mask掉“数学” print(token_ids[1],token_ids[2]) token_ids[1] = token_ids[2] = tokenizer._token_dict['[MASK]'] masks = np.array([[0, 1, 1] + [0] * (512 - 3)]) #模型预测被mask掉的部分 probas = model.predict([np.array([token_ids]), np.array([segment_ids]), masks])[0] pred_indice = probas[0][1:3].argmax(axis=1).tolist() print('Fill with: ', list(map(lambda x: token_dict_rev[x], pred_indice))) #Fill with: ['数', '学']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
3144 2110
Fill with: [‘数’, ‘学’]

