
- 1uniapp 如何嵌套H5 页面?_uniapp嵌套h5
- 2Hadoop专栏(十三)HIVE详解 下_nohup hive --service hiveserver2 & [1] 32072 [root
- 3iphone或安卓配置Charles抓包_charles iphone
- 4springboot呼伦贝尔旅游网站的设计与实现毕业设计源码091833_呼伦贝尔网站设计
- 512306抢票_java 12306抢票开源项目
- 6Unity的旋转实现一些方法总结(案例:通过输入,玩家进行旋转移动)_unity中如何如何获取transform.rotation.eulerangles.y的角度值和t
- 7谷歌(Google)技术面试概述
- 8【Unity3D】调整屏幕亮度、饱和度、对比度_unity亮度代码
- 9【leetcode基础题】刷题清单,刷完算法入门
- 10阿里云ECS流量计算_如何查看阿里云流量使用情况csdn
如何处理类别型特征?_类别型特征处理方式
赞
踩
目录:
- 问题描述
- 数据准备
- 标签编码
- 自定义二分类
- one-hot 编码
问题描述
一般特征可以分为两类特征,连续型和离散型特征,而离散型特征既有是数值型的,也有是类别型特征,也可以说是字符型,比如说性别,是男还是女;职业,可以是程序员,产品经理,教师等等。
本文将主要介绍一些处理这种类别型特征的方法,分别来自 pandas 和 sklearn 两个常用的 python 库给出的解决方法,这些方法也并非是处理这类特征的唯一答案,通常都需要具体问题具体分析。
数据准备
采用 UCI 机器学习库的一个汽车数据集,它包括类别型特征和连续型特征,首先是简单可视化这个数据集的部分样本,并简单进行处理。
首先导入这次需要用到的 python 库:
- import pandas as pd
- import numpy as np
- import pandas_profiling
- from sklearn.feature_extraction import DictVectorizer
- from sklearn.preprocessing import LabelEncoder, OneHotEncoder
接着加载数据:
- # 定义数据的列名称, 因为这个数据集没有包含列名称
- headers = ["symboling", "normalized_losses", "make", "fuel_type", "aspiration",
- "num_doors", "body_style", "drive_wheels", "engine_location",
- "wheel_base", "length", "width", "height", "curb_weight",
- "engine_type", "num_cylinders", "engine_size", "fuel_system",
- "bore", "stroke", "compression_ratio", "horsepower", "peak_rpm",
- "city_mpg", "highway_mpg", "price"]
-
- # 读取在线的数据集, 并将?转换为缺失NaN
- df = pd.read_csv("http://mlr.cs.umass.edu/ml/machine-learning-databases/autos/imports-85.data",
- header=None, names=headers, na_values="?" )
- df.head()[df.columns[:10]]
展示的前 10 列的 5 行数据结果如下:

这里介绍一个新的数据分析库--pandas_profiling,这个库可以帮我们先对数据集做一个数据分析报告,报告的内容包括说明数据集包含的列数量、样本数量,每列的缺失值数量,每列之间的相关性等等。
安装方法也很简单:
pip install pandas_profiling
使用方法也很简单,用 pandas读取数据后,直接输入下列代码:
df.profile_report()
显示的结果如下,概览如下所示,看右上角可以选择有 5 项内容,下面是概览的内容,主要展示数据集的样本数量,特征数量(列的数量)、占用内存、每列的数据类型统计、缺失值情况等:

这是一个很有用的工具,可以让我们对数据集有一个初步的了解,更多用法可以去查看其 github 上了解:
https://github.com/pandas-profiling/pandas-profiling
加载数据后,这里我们仅关注类别型特征,也就是 object 类型的特征,这里可以有两种方法来获取:
方法1:采用 pandas 提供的方法 select_dtypes:
- df2 = df.select_dtypes('object').copy()
- df2.head()
方法2: 通过 bool 型的 mask 获取 object 类型的列
- category_feature_mask = df.dtypes == object
- category_cols = df.columns[category_feature_mask].tolist()
- df3 = df[category_cols].copy()
- df3.head()
输出结果如下:

因为包含一些缺失值,这里非常简单的选择丢弃的方法,但实际上应该如何处理缺失值也是需要考虑很多因素,包括缺失值的数量等,但这里就不展开说明了:
- # 简单的处理缺失值--丢弃
- df2.dropna(inplace=True)
标签编码
第一种处理方法是标签编码,其实就是直接将类别型特征从字符串转换为数字,有两种处理方法:
- 直接替换字符串
- 转为
category类型后标签编码
直接替换字符串,算是手动处理,实现如下所示,这里用 body_style 这列特征做例子进行处理,它总共有 5 个取值方式,先通过 value_counts方法可以获取每个数值的分布情况,然后映射为数字,保存为一个字典,最后通过 replace 方法进行转换。

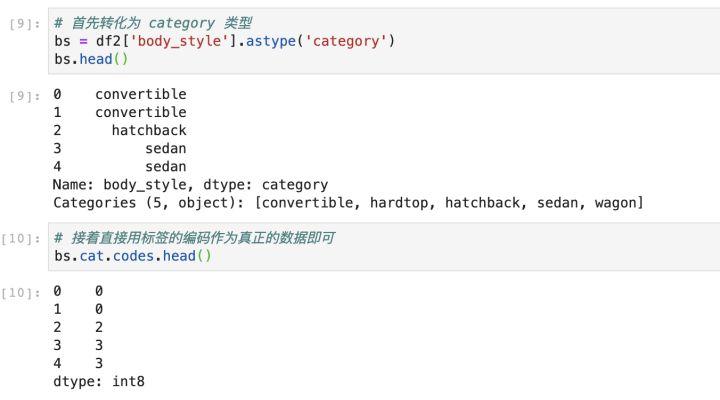
第二种,就是将该列特征转化为 category 特征,然后再用编码得到的作为数据即可:
自定义二分类
第二种方法比较特别,直接将所有的类别分为两个类别,这里用 engine_type 特征作为例子,假如我们仅关心该特征是否为 ohc ,那么我们就可以将其分为两类,包含 ohc 还是不包含,实现如下所示:

One-hot 编码
前面两种方法其实也都有各自的局限性
- 第一种标签编码的方式,类别型特征如果有3个以上取值,那么编码后的数值就是 0,1,2等,这里会给模型一个误导,就是这个特征存在大小的关系,但实际上并不存在,所以标签编码更适合只有两个取值的情况;
- 第二种自定义二分类的方式,局限性就更大了,必须是只需要关注某个取值的时候,但实际应用很少会这样处理。
因此,这里介绍最常用的处理方法--One-hot 编码。
实现 One-hot 编码有以下 3 种方法:
- Pandas 的
get_dummies - Sklearn 的
DictVectorizer - Sklearn 的
LabelEncoder+OneHotEncoder
Pandas 的 `get_dummies`
首先介绍第一种--Pandas 的 get_dummies,这个方法使用非常简单了:

Sklearn 的`DictVectorizer`
第二种方法--Sklearn 的 DictVectorizer,这首先需要将 dataframe 转化为 dict 类型,这可以通过 to_dict ,并设置参数 orient=records,实现代码如下所示:

Sklearn 的 `LabelEncoder`+`OneHotEncoder`
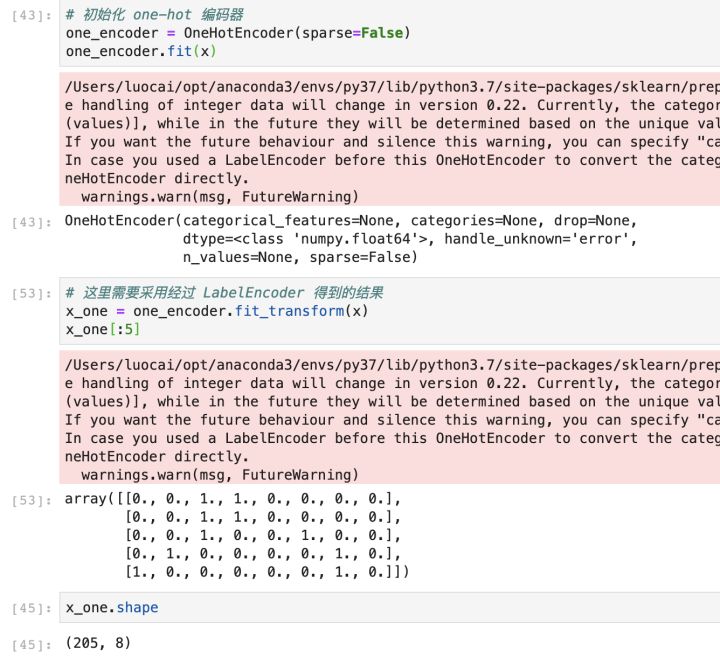
第三种方法--Sklearn 的 LabelEncoder+OneHotEncoder
首先是定义 LabelEncoder,实现代码如下,可以发现其实它就是将字符串进行了标签编码,将字符串转换为数值,这个操作很关键,因为 OneHotEncoder 是不能处理字符串类型的,所以需要先做这样的转换操作:

接着自然就是进行 one-hot 编码了,实现代码如下所示:
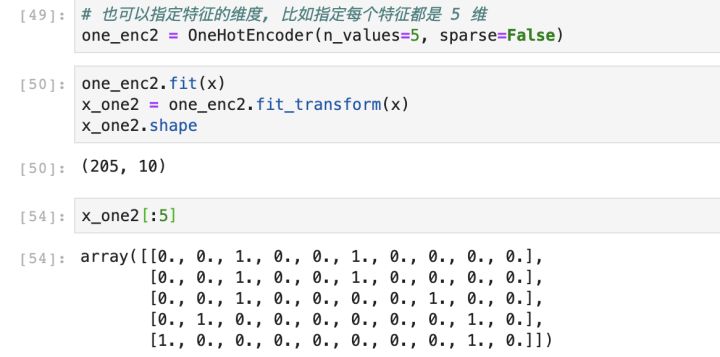
此外,采用 OneHotEncoder 的一个好处就是可以指定特征的维度,这种情况适用于,如果训练集和测试集的某个特征的取值数量不同的情况,比如训练集的样本包含这个特征的所有可能的取值,但测试集的样本缺少了其中一种可能,那么如果直接用 pandas 的get_dummies方法,会导致训练集和测试集的特征维度不一致了。
实现代码如下所示:
总结
对于类别型特征,最常用的还是 one-hot 编码,但很多问题都是需要具体问题具体分析,仅仅 one-hot 编码并不一定可以解决所有的类别型特征问题,需要多实践多总结经验。
参考
- https://mlln.cn/2018/09/18/pandas%E6%96%87%E6%9C%AC%E6%95%B0%E6%8D%AE%E8%BD%AC%E6%95%B4%E6%95%B0%E5%88%86%E7%B1%BB%E7%BC%96%E7%A0%81%E7%9A%84%E6%9C%80%E4%BD%B3%E5%AE%9E%E8%B7%B5/
- https://blog.csdn.net/selous/article/details/72457476
- https://towardsdatascience.com/encoding-categorical-features-21a2651a065c
- https://www.cnblogs.com/zhoukui/p/9159909.html

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

