
- 1git修改提交信息commit_修改commit信息会产生新的提交
- 2EasyARM_RT1052的BootLoader程序_rt1052 bootloader
- 3如果R是唯一析因整环,那么R[x]也是唯一析因整环
- 4七种编程语言的学习曲线
- 5银行软件测试岗位待遇怎么样,银行软件测试岗位职责
- 6计算机java项目|基于Web的网上购物系统的设计与实现_java网上购物系统
- 7Sqoop将hive处理的数据导出到MySQL_sqoop导出hive数据到mysql
- 82022Java最新面试-Bean的生命周期_bean的生命周期 面试
- 9mysql with 的用法 (含 with recursive)_mysql cast with
- 10Mysql中时间自动格式匹配date_format函数_mysql %y-%m
【博学谷学习记录】超强总结,用心分享|大数据之flinkCDC_flinkcdc和flink是一个吗
赞
踩
Flink CDC、Flink、CDC各有啥关系
Flink:流式计算框架,不包含Flink CDC,和Flink CDC没关系
CDC:是一种思想,理念,不涉及某一门具体的技术
Flink CDC:是CDC的一种实现而已,不属于Flink子版块
Flink CDC这个技术是阿里开发的。目的是为了丰富Flink的生态。
Flink CDC
历史
2020年7月,Flink CDC发布1.0版本。
2021年中旬,Flink CDC发布2.0版本。
目前最新版是Flink CDC2.3.0版本。
概述
Flink CDC 基于数据库日志的 Change Data Caputre 技术,实现了全量和增量的一体化读取能力,并借助 Flink 优秀的管道能力和丰富的
上下游生态,支持捕获多种数据库的变更,并将这些变更实时同步到下游存储。
jdbc Connectors和Flink CDC Connectors对比
JDBC Connectors连接器,确实可以读取外部的 数据库。比如:MySQL、Oracle、SqlServer等。
但是,JDBC连数据库,只是瞬时操作,没办法持续监听数据库的数据变化。
Flink CDC Connectors,可以实现数据库的变更捕获,能够持续不断地把变更数据同步到下游的系统中。
官网概述
官网链接:https://ververica.github.io/flink-cdc-connectors/
github链接:https://github.com/ververica/flink-cdc-connectors
在大数据组件中所处的位置
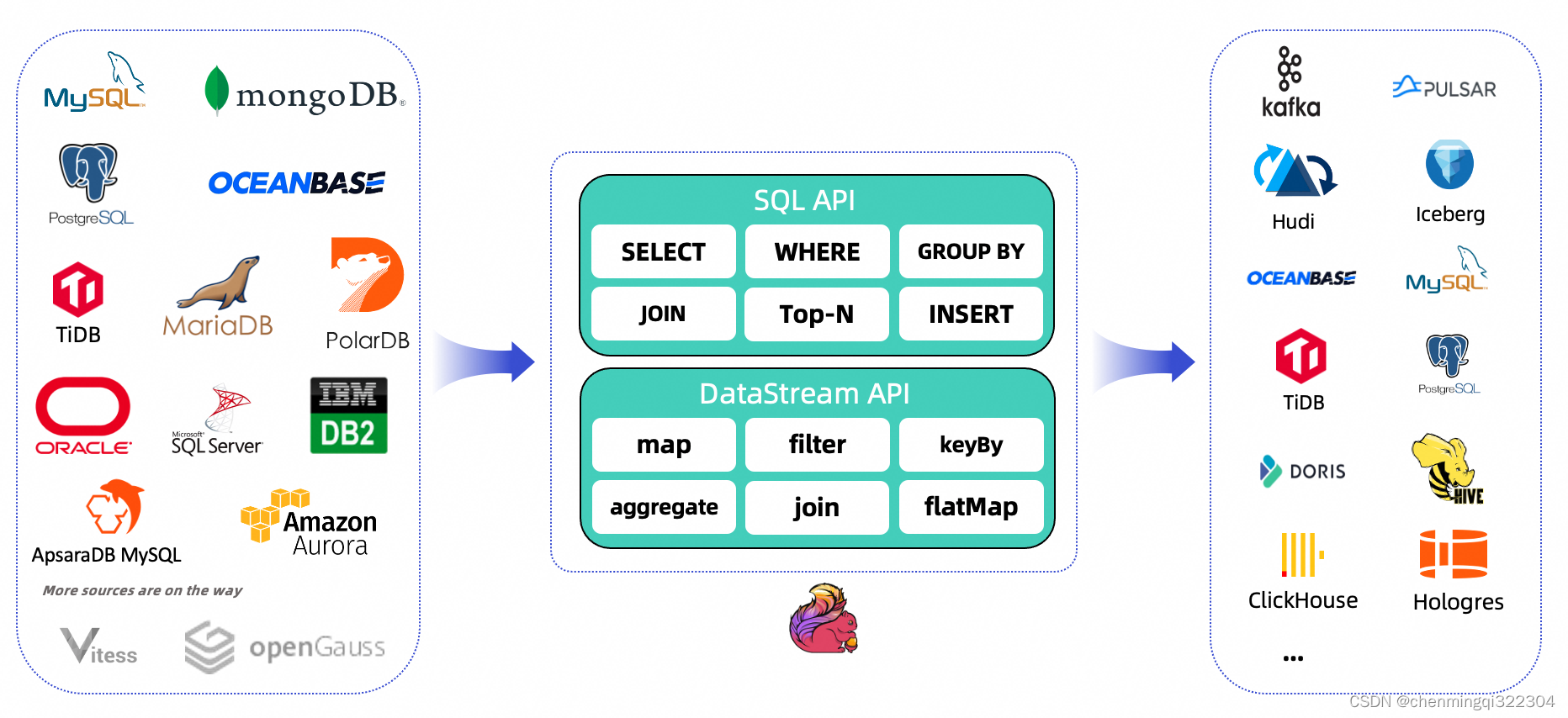
支持的连接器
| Connector | Database | Driver |
|---|---|---|
| mongodb-cdc | MongoDB: 3.6, 4.x, 5.0 | MongoDB Driver: 4.3.1 |
| mysql-cdc | MySQL: 5.6, 5.7, 8.0.xRDS MySQL: 5.6, 5.7, 8.0.xPolarDB MySQL: 5.6, 5.7, 8.0.xAurora MySQL: 5.6, 5.7, 8.0.xMariaDB: 10.xPolarDB X: 2.0.1 | JDBC Driver: 8.0.27 |
| oceanbase-cdc | OceanBase CE: 3.1.xOceanBase EE (MySQL mode): 2.x, 3.x | JDBC Driver: 5.1.4x |
| oracle-cdc | Oracle: 11, 12, 19 | Oracle Driver: 19.3.0.0 |
| postgres-cdc | PostgreSQL: 9.6, 10, 11, 12 | JDBC Driver: 42.2.12 |
| sqlserver-cdc | Sqlserver: 2012, 2014, 2016, 2017, 2019 | JDBC Driver: 7.2.2.jre8 |
| tidb-cdc | TiDB: 5.1.x, 5.2.x, 5.3.x, 5.4.x, 6.0.0 | JDBC Driver: 8.0.27 |
| db2-cdc | Db2: 11.5 | DB2 Driver: 11.5.0.0 |
支持的Flink版本
| Flink® CDC Version | Flink® Version |
|---|---|
| 1.0.0 | 1.11.* |
| 1.1.0 | 1.11.* |
| 1.2.0 | 1.12.* |
| 1.3.0 | 1.12.* |
| 1.4.0 | 1.13.* |
| 2.0.* | 1.13.* |
| 2.1.* | 1.13.* |
| 2.2.* | 1.13., 1.14. |
| 2.3.* | 1.13., 1.14., 1.15.*, 1.16.0 |
连接器参数选项
| Option | Required | Default | Type | Description |
|---|---|---|---|---|
| connector | required | (none) | String | 指定要使用的连接器, 这里应该是 'mysql-cdc'. |
| hostname | required | (none) | String | MySQL 数据库服务器的 IP 地址或主机名。 |
| username | required | (none) | String | 连接到 MySQL 数据库服务器时要使用的 MySQL 用户的名称。 |
| password | required | (none) | String | 连接 MySQL 数据库服务器时使用的密码。 |
| database-name | required | (none) | String | 要监视的 MySQL 服务器的数据库名称。数据库名称还支持正则表达式,以监视多个与正则表达式匹配的表。 |
| table-name | required | (none) | String | 要监视的 MySQL 数据库的表名。表名还支持正则表达式,以监视多个表与正则表达式匹配。 |
| port | optional | 3306 | Integer | MySQL 数据库服务器的整数端口号。 |
| server-id | optional | (none) | String | 读取数据使用的 server id,server id 可以是个整数或者一个整数范围,比如 ‘5400’ 或 ‘5400-5408’, 建议在 ‘scan.incremental.snapshot.enabled’ 参数为启用时,配置成整数范围。因为在当前 MySQL 集群中运行的所有 slave 节点,标记每个 salve 节点的 id 都必须是唯一的。 所以当连接器加入 MySQL 集群作为另一个 slave 节点(并且具有唯一 id 的情况下),它就可以读取 binlog。 默认情况下,连接器会在 5400 和 6400 之间生成一个随机数,但是我们建议用户明确指定 Server id。 |
| scan.incremental.snapshot.enabled | optional | true | Boolean | 增量快照是一种读取表快照的新机制,与旧的快照机制相比, 增量快照有许多优点,包括: (1)在快照读取期间,Source 支持并发读取, (2)在快照读取期间,Source 支持进行 chunk 粒度的 checkpoint, (3)在快照读取之前,Source 不需要数据库锁权限。 如果希望 Source 并行运行,则每个并行 Readers 都应该具有唯一的 Server id,所以 Server id 必须是类似 5400-6400 的范围,并且该范围必须大于并行度。 请查阅 增量快照读取 章节了解更多详细信息。 |
| scan.incremental.snapshot.chunk.size | optional | 8096 | Integer | 表快照的块大小(行数),读取表的快照时,捕获的表被拆分为多个块。 |
| scan.snapshot.fetch.size | optional | 1024 | Integer | 读取表快照时每次读取数据的最大条数。 |
| scan.startup.mode | optional | initial | String | MySQL CDC 消费者可选的启动模式, 合法的模式为 “initial”,“earliest-offset”,“latest-offset”,“specific-offset” 和 “timestamp”。 请查阅 启动模式 章节了解更多详细信息。 |
| scan.startup.specific-offset.file | optional | (none) | String | 在 “specific-offset” 启动模式下,启动位点的 binlog 文件名。 |
| scan.startup.specific-offset.pos | optional | (none) | Long | 在 “specific-offset” 启动模式下,启动位点的 binlog 文件位置。 |
| scan.startup.specific-offset.gtid-set | optional | (none) | String | 在 “specific-offset” 启动模式下,启动位点的 GTID 集合。 |
| scan.startup.specific-offset.skip-events | optional | (none) | Long | 在指定的启动位点后需要跳过的事件数量。 |
| scan.startup.specific-offset.skip-rows | optional | (none) | Long | 在指定的启动位点后需要跳过的数据行数量。 |
| server-time-zone | optional | (none) | String | 数据库服务器中的会话时区, 例如: “Asia/Shanghai”. 它控制 MYSQL 中的时间戳类型如何转换为字符串。 更多请参考 这里. 如果没有设置,则使用ZoneId.systemDefault()来确定服务器时区。 |
| debezium.min.row. count.to.stream.result | optional | 1000 | Integer | 在快照操作期间,连接器将查询每个包含的表,以生成该表中所有行的读取事件。 此参数确定 MySQL 连接是否将表的所有结果拉入内存(速度很快,但需要大量内存), 或者结果是否需要流式传输(传输速度可能较慢,但适用于非常大的表)。 该值指定了在连接器对结果进行流式处理之前,表必须包含的最小行数,默认值为1000。将此参数设置为0以跳过所有表大小检查,并始终在快照期间对所有结果进行流式处理。 |
| connect.timeout | optional | 30s | Duration | 连接器在尝试连接到 MySQL 数据库服务器后超时前应等待的最长时间。 |
| connect.max-retries | optional | 3 | Integer | 连接器应重试以建立 MySQL 数据库服务器连接的最大重试次数。 |
| connection.pool.size | optional | 20 | Integer | 连接池大小。 |
| jdbc.properties.* | optional | 20 | String | 传递自定义 JDBC URL 属性的选项。用户可以传递自定义属性,如 ‘jdbc.properties.useSSL’ = ‘false’. |
| heartbeat.interval | optional | 30s | Duration | 用于跟踪最新可用 binlog 偏移的发送心跳事件的间隔。 |
| debezium.* | optional | (none) | String | 将 Debezium 的属性传递给 Debezium 嵌入式引擎,该引擎用于从 MySQL 服务器捕获数据更改。 For example: 'debezium.snapshot.mode' = 'never'. 查看更多关于 Debezium 的 MySQL 连接器属性 |
MySQL和FlinkSQL列类型映射表
| MySQL type | Flink SQL type | NOTE |
|---|---|---|
| TINYINT | TINYINT | |
| SMALLINT TINYINT UNSIGNED TINYINT UNSIGNED ZEROFILL | SMALLINT | |
| INT MEDIUMINT SMALLINT UNSIGNED SMALLINT UNSIGNED ZEROFILL | INT | |
| BIGINT INT UNSIGNED INT UNSIGNED ZEROFILL MEDIUMINT UNSIGNED MEDIUMINT UNSIGNED ZEROFILL | BIGINT | |
| BIGINT UNSIGNED BIGINT UNSIGNED ZEROFILL SERIAL | DECIMAL(20, 0) | |
| FLOAT FLOAT UNSIGNED FLOAT UNSIGNED ZEROFILL | FLOAT | |
| REAL REAL UNSIGNED REAL UNSIGNED ZEROFILL DOUBLE DOUBLE UNSIGNED DOUBLE UNSIGNED ZEROFILL DOUBLE PRECISION DOUBLE PRECISION UNSIGNED DOUBLE PRECISION UNSIGNED ZEROFILL | DOUBLE | |
| NUMERIC(p, s) NUMERIC(p, s) UNSIGNED NUMERIC(p, s) UNSIGNED ZEROFILL DECIMAL(p, s) DECIMAL(p, s) UNSIGNED DECIMAL(p, s) UNSIGNED ZEROFILL FIXED(p, s) FIXED(p, s) UNSIGNED FIXED(p, s) UNSIGNED ZEROFILL where p <= 38 | DECIMAL(p, s) | |
| NUMERIC(p, s) NUMERIC(p, s) UNSIGNED NUMERIC(p, s) UNSIGNED ZEROFILL DECIMAL(p, s) DECIMAL(p, s) UNSIGNED DECIMAL(p, s) UNSIGNED ZEROFILL FIXED(p, s) FIXED(p, s) UNSIGNED FIXED(p, s) UNSIGNED ZEROFILL where 38 < p <= 65 | STRING | 在 MySQL 中,十进制数据类型的精度高达 65,但在 Flink 中,十进制数据类型的精度仅限于 38。所以,如果定义精度大于 38 的十进制列,则应将其映射到字符串以避免精度损失。在 MySQL 中,十进制数据类型的精度高达65,但在Flink中,十进制数据类型的精度仅限于38。所以,如果定义精度大于 38 的十进制列,则应将其映射到字符串以避免精度损失。 |
| BOOLEAN TINYINT(1) BIT(1) | BOOLEAN | |
| DATE | DATE | |
| TIME [§] | TIME [§] | |
| TIMESTAMP [§] DATETIME [§] | TIMESTAMP [§] | |
| CHAR(n) | CHAR(n) | |
| VARCHAR(n) | VARCHAR(n) | |
| BIT(n) | BINARY(⌈n/8⌉) | |
| BINARY(n) | BINARY(n) | |
| VARBINARY(N) | VARBINARY(N) | |
| TINYTEXT TEXT MEDIUMTEXT LONGTEXT | STRING | |
| TINYBLOB BLOB MEDIUMBLOB LONGBLOB | BYTES | 目前,对于 MySQL 中的 BLOB 数据类型,仅支持长度不大于 2147483647(2**31-1)的 blob。 |
| YEAR | INT | |
| ENUM | STRING | |
| JSON | STRING | JSON 数据类型将在 Flink 中转换为 JSON 格式的字符串。 |
| SET | ARRAY | 因为 MySQL 中的 SET 数据类型是一个字符串对象,可以有零个或多个值 它应该始终映射到字符串数组。 |
| GEOMETRY POINT LINESTRING POLYGON MULTIPOINT MULTILINESTRING MULTIPOLYGON GEOMETRYCOLLECTION | STRING | MySQL 中的空间数据类型将转换为具有固定 Json 格式的字符串。 请参考 MySQL 空间数据类型映射 章节了解更多详细信息。 |
Flink CDC消费数据的模式
FlinkCDC常用的消费数据的模式有两种:
-
initial:既能消费历史数据,又能消费增量数据,默认就是这种消费模式
-
latest-offset:只消费增量数据,历史数据不消费
编译源码
#0.基础目录
cd ~
#1.拉取源码
git clone https://github.com/ververica/flink-cdc-connectors.git
#2.进入Flink CDC源码目录
cd flink-cdc-connectors
#3.编译
mvn clean install -DskipTests
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
说明:
推荐去官网下载已经编译好的jar包。如果官网jar包不满足业务需求,才用这种方案。
官网下载链接:https://github.com/ververica/flink-cdc-connectors/releases
入门案例(掌握)
开启MySQL二进制日志功能
配置如下,把下面的配置信息粘贴到/etc/my.cnf文件中即可。
[mysqld]
server_id=1
log_bin = mysql-bin
binlog_format = ROW
expire_logs_days = 30
- 1
- 2
- 3
- 4
- 5
校验MySQL的binlog是否真正开启成功:
#1.登录MySQL
mysql -uroot -p123456
#2.执行一个命令
show variables like '%log%';
- 1
- 2
- 3
- 4
- 5
看到log_bin=ON,表示binlog日志开启成功。
Flink CDC安装部署
去官网下载Flink CDC的jar包,把jar包放置在$FLINK_HOME/lib目录下,重启Flink集群即可。
jar包名如下:
flink-sql-connector-mysql-cdc-2.2.1.jar
- 1
需求
从MySQL中使用Flink CDC同步全量数据。并且对数据进行增、删、改操作,看数据是否能够同步增量数据。
- 1
前期准备
#1.启动Flink集群
start-cluster.sh
#2.启动HDFS集群
start-dfs.sh
#3.进入FlinkSQL客户端
sql-client.sh
#3.进入MySQL客户端
mysql -uroot -p123456
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
操作步骤:
(1)在MySQL中创建数据库、表、插入数据(2张表)
(2)在FlinkSQL客户端中创建MySQL的映射表(2张表)
(3)在FlinkSQL中执行SQL操作,比如:select * from mysql_cdc_to_test_Student;
(4)在MySQL变更原表的数据(insert、update、delete),在FlinkSQL客户端中校验cdc的数据是否正常
- 1
- 2
- 3
- 4
- 5
演示
在MySQL中创建数据库、表、插入数据
#1.创建数据库 create database test character set utf8; #2.切换数据库 use test; #3.创建Student表 CREATE TABLE `Student`( `s_id` VARCHAR(20), `s_name` VARCHAR(20) NOT NULL DEFAULT '', `s_birth` VARCHAR(20) NOT NULL DEFAULT '', `s_sex` VARCHAR(10) NOT NULL DEFAULT '', PRIMARY KEY(`s_id`) ); #4.创建Score表 CREATE TABLE `Score`( `s_id` VARCHAR(20), `c_id` VARCHAR(20), `s_score` INT(3), PRIMARY KEY(`s_id`,`c_id`) ); #5.插入数据到Student表 insert into Student values('01' , '赵雷' , '1990-01-01' , '男'); insert into Student values('02' , '钱电' , '1990-12-21' , '男'); insert into Student values('03' , '孙风' , '1990-05-20' , '男'); insert into Student values('04' , '李云' , '1990-08-06' , '男'); insert into Student values('05' , '周梅' , '1991-12-01' , '女'); insert into Student values('06' , '吴兰' , '1992-03-01' , '女'); insert into Student values('07' , '郑竹' , '1989-07-01' , '女'); insert into Student values('08' , '王菊' , '1990-01-20' , '女'); #6.插入数据到Score表 insert into Score values('01' , '01' , 80); insert into Score values('01' , '02' , 90); insert into Score values('01' , '03' , 99); insert into Score values('02' , '01' , 70); insert into Score values('02' , '02' , 60); insert into Score values('02' , '03' , 80); insert into Score values('03' , '01' , 80); insert into Score values('03' , '02' , 80); insert into Score values('03' , '03' , 80); insert into Score values('04' , '01' , 50); insert into Score values('04' , '02' , 30); insert into Score values('04' , '03' , 20); insert into Score values('05' , '01' , 76); insert into Score values('05' , '02' , 87); insert into Score values('06' , '01' , 31); insert into Score values('06' , '03' , 34); insert into Score values('07' , '02' , 89); insert into Score values('07' , '03' , 98);

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
在FlinkSQL客户端中创建MySQL的映射表
映射表的建表要求:
(1)字段必须一样
(2)字段类型必须匹配。
#1.创建Student表的映射表 CREATE TABLE if not exists mysql_cdc_to_test_Student ( s_id STRING, s_name STRING, s_birth STRING, s_sex STRING, PRIMARY KEY (`s_id`) NOT ENFORCED ) WITH ( 'connector'= 'mysql-cdc', 'hostname'= '192.168.88.161', 'port'= '3306', 'username'= 'root', 'password'='123456', 'server-time-zone'= 'Asia/Shanghai', 'debezium.snapshot.mode'='initial', 'database-name'= 'test', 'table-name'= 'Student' ); #2.说明 database-name,指定来自于MySQL的哪个数据库。 table-name,指定使用Flink CDC同步这个数据库下的那张表的数据。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
执行SQL操作
select * from mysql_cdc_to_test_Student;
- 1
小结:
能看到FlinkSQL中的数据和MySQL中的数据一致,说明FlinkCDC成功映射到了源表,已经把历史数据都读取过来了。
继续执行SQL:
#1.新增
insert into Student values ('09','张三丰','2000-10-01','男');
#2.修改
update Student set s_name = '张无忌' where s_id = '09';
#3.删除
delete from Student where s_id = '09';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
继续执行SQL:
#1.需求 查询同时存在01课程和02课程的学生信息 #2.创建Score的映射表 CREATE TABLE if not exists mysql_cdc_to_test_Score ( `s_id` STRING, `c_id` STRING, `s_score` INT, PRIMARY KEY (`s_id`) NOT ENFORCED ) WITH ( 'connector'= 'mysql-cdc', 'hostname'= '192.168.88.161', 'port'= '3306', 'username'= 'root', 'password'='123456', 'server-time-zone'= 'Asia/Shanghai', 'debezium.snapshot.mode'='initial', 'database-name'= 'test', 'table-name'= 'Score' ); #3.实现 SELECT s.* FROM ( SELECT * FROM mysql_cdc_to_test_Score WHERE c_id = '01' ) AS t1 INNER JOIN (SELECT * FROM mysql_cdc_to_test_Score WHERE c_id = '02') AS t2 ON t1.s_id = t2.s_id INNER JOIN mysql_cdc_to_test_Student AS s ON t1.s_id = s.s_id; #4.新增 insert into Score values ('06','02',100); #5.修改 update Student set s_name = '李云龙' where s_id = '04'; #6.删除 delete from Score where s_id = '06' and c_id = '02';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
Flink CDC 2.0概述
整体流程可以概括为,首先通过主键对表进行 Snapshot Chunk 划分,再将 Snapshot Chunk 分发给多个 SourceReader,每个
Snapshot Chunk 读取时通过算法实现无锁条件下的一致性读, SourceReader 读取时支持 chunk 粒度的 checkpoint,在所有
Snapshot Chunk 读取完成后, 下发一个 binlog chunk 进行增量部分的 binlog 读取,这便是 Flink CDC 2.0 的整体流程。
官方测试效果:
用 TPC-DS 数据集中的 customer 表进行了测试,Flink 版本是 1.13.1,customer 表的数据量是 6500 万条,Source 并发为 8,全量读取
阶段:Flink CDC 2.0 用时 13 分钟;Flink CDC 1.4 用时 89 分钟;读取性能提升 6.8 倍。
晚上课程内容安排
- 生活中的湖
- 程序中的湖
- 常见的数据湖
- Delta Lake
- Iceberg
- Hudi
- Hudi概述
- 湖仓一体架构
- Hudi入门案例
- Hudi核心概念剖析
- Hudi综合案例
数据湖(理解)
数据湖是一种思想,一种理念。不涉及某一门具体的技术。
数据湖 VS 数据仓库
数仓:结构化的数据。
数据湖:结构化、半结构化、非结构化都可以。
数据湖和数据仓库优缺点,后面还会细说。
常见的数据湖框架
数据湖是一种思想,理念,围绕这种思想实现技术就是数据湖框架了。
目前市场上有如下数据湖框架:
- Delta Lake
- Apache Hudi
Delta Lake
Delta Lake是Spark的商业公司研发的,所以Delta Lake和Spark技术是强绑定的。
Hudi概述
Hudi,Hadoop Update Delete and Incremental。用来管理分布式文件系统的数据湖框架。
核心特性:
- 支持事务
- 支持行级别更新、删除功能
- 支持变更流
湖仓平台。基于数据湖,构建数据仓库。
历史
- 2015年出的论文
- 2016年由Uber公司研发
- 2017年开源
- 2018年捐赠给Apache
- 2019年从Apache孵化毕业,成为顶级项目
- 目前为止,最新版为0.13.0版本
湖仓一体架构
为什么会有湖仓一体的架构,就是因为单独拎出来数据仓库或者数据湖,都有自身的弊端。
数据仓库的特点
- 支持结构化数据分析
- 安全性还可以
- 方便管理
- 缺乏灵活性
- 不支持半结构、非结构化数据分析
- 专注于BI,而不是AI
数据湖的特点
- 支持结构化、半结构化、非结构化舒服分析
- 扩容较廉价
- 不方便管理,会快速沦为数据沼泽
- 安全性较弱
- 专注于AI,而不是BI
湖仓一体特点
Ø 湖仓一体是一种新的数据管理模式,将数据仓库和数据湖两者之间的差异进行融合,并将数据仓库构建在数据湖上,
从而有效简化了企业数据的基础架构,提升数据存储弹性和质量的同时还能降低成本,减小数据冗余。
- 支持结构化、半结构化、非常结构化数据分析
- 支持AI和BI
- 更好地管理
- 安全性也有了加强
说明:
至于如何实现湖仓一体,简单来说,就是一对配置而已。
Hudi快速入门(掌握)
Hudi安装部署
Flink官网的download只提供了源码包的下载,我们也可以去编译源码,得到编译后的bundled jar包。
但是,我们这里采用从maven官方仓库下载。
https://repo.maven.apache.org/maven2/org/apache/hudi/hudi-flink1.14-bundle_2.12/0.11.1/
- 1
从官网下载Flink和Hudi的bundled jar包,放置在$FLINK_HOME/lib目录下,即可。
hudi-flink1.14-bundle_2.12-0.11.1.jar
- 1
前提准备
#1.启动Flink集群
start-cluster.sh
#2.启动HDFS集群
start-dfs.sh
#3.进入FlinkSQL客户端
sql-client.sh
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
演示
#1.创建表 CREATE TABLE t1( uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED, name VARCHAR(10), age INT, ts TIMESTAMP(3), `partition` VARCHAR(20) ) PARTITIONED BY (`partition`) WITH ( 'connector' = 'hudi', -- 连接器指定hudi 'path' = 'hdfs://node1:8020/hudi/t1', -- 数据存储地址 'table.type' = 'MERGE_ON_READ' -- 表类型,默认COPY_ON_WRITE,可选MERGE_ON_READ ); #2.插入数据 INSERT INTO t1 VALUES ('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'), ('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'), ('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'), ('id4','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'), ('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'), ('id6','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'), ('id7','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'), ('id8','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4'); #3.读取数据 select * from t1; #4.更新数据 insert into t1 values ('id1','Danny',27,TIMESTAMP '1970-01-01 00:00:01','par1'); #5.流式数据更新 CREATE TABLE t2( uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED, name VARCHAR(10), age INT, ts TIMESTAMP(3), `partition` VARCHAR(20) ) PARTITIONED BY (`partition`) WITH ( 'connector' = 'hudi', 'path' = 'hdfs://node1:8020/hudi/t2', 'table.type' = 'MERGE_ON_READ', 'read.streaming.enabled' = 'true', -- 开启流式读取 'read.start-commit' = '20210316134557', -- 指定流式消费数据时间 'read.streaming.check-interval' = '4' -- 指定流式数据源检查间隔,默认是60s ); #6.往流式表中插入数据 INSERT INTO t2 VALUES ('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'), ('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'), ('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'), ('id4','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'), ('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'), ('id6','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'), ('id7','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'), ('id8','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4'); #7.查询数据 select * from t2; ~~
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73

