
- 1触发器的创建_创建触发器
- 2笔记:FPGA上实现最小soc系统_quartus 实现fpga soc
- 3【银行测试】金融行业-银行测试类型分类,功能/业务/性能..._银行金融相关的应该怎么测试呢
- 4年度更新!统信UOS服务器版V20(1070)超越期待_统信 v20 1070 基于那个linux开发
- 5城市视频监控系统建设及设备选择指南
- 6Unity DOTS纯ECS写一个类似UGUI的EventSystem(实现IPointerDownHandler/IPointerUpHandler/IBeginDragHandler等)_unity ipointerdownhandler
- 7三万字长文 | 以架构视角解读银行数字化转型的两份重磅指导文件_金融数字化转型概念是哪个政策文件提出的e
- 8sklearn-svm对于红酒产地数据集进行分类_python基于svm的wine
- 9Linux Centos 7 压缩和解压缩命令_centos7压缩文件夹命令
- 10大数据技术11:Hadoop 原理与运行机制_hadoop原理及运行机制
AI大模型全解析:一文读懂其发展历程与未来趋势_ai大模型的发展
赞
踩
引言
近年来,随着深度学习技术的迅猛发展,AI大模型已经成为人工智能领域的重要研究方向和热点话题。AI大模型,指的是拥有巨大参数规模和强大学习能力的神经网络模型,如BERT、GPT等,这些模型在自然语言处理、计算机视觉等领域取得了令人瞩目的成果。
AI大模型的意义不仅在于其巨大的参数规模和学习能力,更在于它们对于解决现实世界复杂问题的潜力。这些模型可以通过大规模数据的学习,自动发现数据之间的关联性和特征,从而实现对文本、图像等数据的高效处理和理解。在自然语言处理领域,AI大模型已经在文本生成、语义理解等任务上取得了令人瞩目的成绩;在计算机视觉领域,它们也在图像分类、目标检测等任务上展现出了强大的能力。
随着科技的不断进步和数据的日益增长,AI大模型将在更多领域展现出其强大的潜力,为人类社会带来更多的创新和进步。本文将探讨AI大模型的发展历程、技术原理和应用前景,为读者提供一份全面了解和深入思考的参考资料。
一、背景与相关工作
AI大模型是指具有大规模参数和复杂结构的神经网络模型,通常由数十亿至数千亿个参数组成。这些模型使用深度学习技术,以大规模的数据为基础进行训练,并在各种任务和领域中展现出卓越的性能。
1、AI大模型的背景
AI大模型的背景可以追溯到深度学习的发展历程。深度学习是一种机器学习技术,通过构建多层神经网络来模拟人类大脑的工作原理,实现对复杂数据的学习和理解。在过去的几十年中,深度学习技术经历了多次重要突破,其中包括:
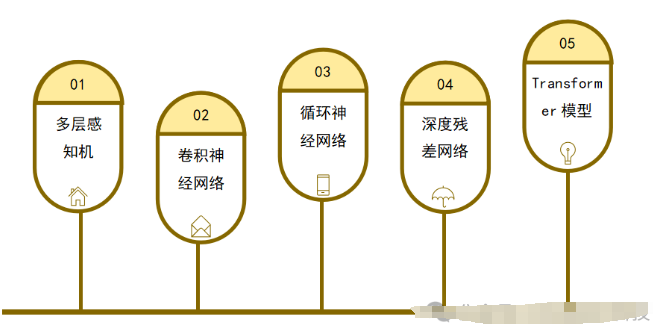
多层感知机(MLP):早期的神经网络模型,通过堆叠多层神经元来实现对复杂数据的非线性建模。
卷积神经网络(CNN):针对图像处理任务设计的神经网络结构,通过卷积层和池化层来提取图像的局部特征,并实现图像分类、目标检测等任务。
循环神经网络(RNN):适用于序列数据处理的神经网络结构,具有记忆功能,可应用于语言建模、机器翻译等任务。
深度残差网络(ResNet):通过引入残差连接解决了深度神经网络训练过程中的梯度消失和梯度爆炸问题,使得可以训练更深层次的网络结构。
Transformer模型:引入自注意力机制,用于处理序列数据,并在自然语言处理领域取得了显著成果。
随着数据量的不断增加和计算资源的增加,研究人员开始尝试构建更大规模、更复杂的神经网络模型,以提高模型的表征能力和泛化能力。这些大型模型包括BERT、GPT、T5等,其参数规模通常达到数十亿至数千亿级别。
AI大模型的兴起和发展,推动了人工智能领域的进步。它们在自然语言处理、计算机视觉、强化学习等领域取得了一系列重要的成果,使得人工智能技术在日常生活和工业生产中得到了广泛应用。然而,AI大模型也面临着训练成本高昂、参数规模爆炸、泛化能力有限等挑战,需要进一步的研究和优化。
2、AI大模型领域的研究成果和应用案例
AI大模型领域已经取得了许多重要的研究成果和应用案例,涵盖了自然语言处理、计算机视觉、强化学习等多个领域。以下是一些代表性的研究成果和应用案例:
(1)自然语言处理(NLP):
BERT(Bidirectional Encoder Representations from Transformers):BERT 是一种基于 Transformer 架构的预训练语言模型,通过双向编码器捕获文本中的双向上下文信息。BERT 在多个 NLP 任务上取得了 state-of-the-art 的结果,如文本分类、命名实体识别、文本相似度计算等。
GPT(Generative Pre-trained Transformer):GPT 系列模型是基于 Transformer 的生成式模型,可以生成连贯的自然语言文本。GPT 在文本生成、对话生成等任务上表现出色。
T5(Text-to-Text Transfer Transformer):T5 是一种通用的文本-文本转换模型,通过统一了输入和输出的形式,可以应用于多种 NLP 任务,如翻译、摘要、问答等。
(2)计算机视觉:
ViT(Vision Transformer):ViT 是一种将 Transformer 应用于图像处理的模型,将输入图像分割成图块,然后经过一系列的线性和 Transformer 编码层进行处理。ViT 在图像分类任务上表现出色,甚至超越了传统的 CNN 模型。
CLIP(Contrastive Language–Image Pre-training):CLIP 模型通过将自然语言和图像的表示空间联系起来,实现了跨模态的视觉理解。它能够在零样本学习和多模态任务中取得良好的表现,如图像分类、图像检索等。
(3)强化学习:
DQN(Deep Q-Network):DQN 是一种利用深度学习技术实现的强化学习算法,已被成功应用于玩 Atarti 游戏等任务。DQN 结合了深度学习的表征能力和强化学习的决策能力,实现了在复杂环境中的高效决策。
AlphaGo / AlphaZero:AlphaGo 是由 DeepMind 开发的围棋 AI,通过强化学习和深度神经网络技术,击败了世界顶级围棋选手。AlphaZero 是 AlphaGo 的进化版,不依赖于任何人类的专家知识,只通过自我对弈学习,成为了顶级围棋、象棋和将棋 AI。
这些研究成果和应用案例表明,AI大模型在不同领域展现出了强大的潜力,为实现更加智能的人工智能系统提供了重要的技术支持。随着技术的不断进步和应用场景的不断拓展,AI大模型将在未来发挥越来越重要的作用。
3、目前AI大模型面临的挑战和机遇
目前,AI大模型面临着一系列挑战和机遇,这些挑战和机遇相互交织,同时也是推动该领域发展的重要因素。
(1)挑战:
训练成本高昂: 训练大型神经网络模型需要大量的计算资源和时间,导致训练成本昂贵,这对于许多研究机构和企业来说是一个挑战。
参数规模爆炸: 随着模型规模的增大,模型的参数量呈指数级增长,导致模型的存储和计算复杂度急剧增加,同时也增加了训练和推理的时间和资源成本。
泛化能力限制: 尽管AI大模型在大规模数据上表现出色,但在少样本、小样本场景下的泛化能力仍有待提高。这意味着模型在真实世界中的应用可能会受到限制。
可解释性不足: AI大模型往往具有非常复杂的结构和大量的参数,导致其内部工作机制难以理解和解释,这给模型的可信度和可解释性带来了挑战。
数据隐私和安全性: 大型模型需要大量的数据进行训练,但数据的隐私和安全性问题仍然是一个严峻的挑战。泄露用户敏感信息可能会导致严重的后果。
(2)机遇:
数据增长和计算能力的提升: 随着数据量的不断增加和计算能力的提升,AI大模型在更多任务和领域上有望实现更好的性能。同时,新型的硬件和软件技术的出现也将进一步提高模型训练和推理的效率。
模型优化和压缩技术的发展: 针对AI大模型的挑战,模型优化和压缩技术的不断发展将有效缓解模型的存储和计算压力,降低训练成本,提高模型的效率和性能。
多模态融合: AI大模型将多模态数据(如文本、图像、音频等)进行有效融合,为更多复杂任务提供解决方案。多模态融合有望拓展AI大模型的应用场景,提高模型的智能水平。
迁移学习和自适应学习: 迁移学习和自适应学习等技术有望进一步提高AI大模型的泛化能力,使其在少样本和小样本场景下表现更加优异。
领域交叉和合作创新: AI大模型的发展需要跨学科的合作和创新,不同领域的知识和技术交叉融合,有望推动AI大模型的发展迈向更高层次。
综上所述,AI大模型面临的挑战和机遇并存,只有充分认识并应对这些挑战,才能更好地把握机遇,推动该领域持续发展。
二、理论基础
在AI大模型的研究和应用中,理论基础扮演着至关重要的角色。理论基础不仅提供了模型构建和优化的指导,也深刻影响了模型的性能和应用效果。
1、AI大模型的基本原理和核心技术
AI大模型的基本原理和核心技术主要包括以下几个方面:

(1)Transformer 架构:
Transformer 是一种基于自注意力机制的神经网络架构,由 Vaswani 等人在论文《Attention Is All You Need》中提出。它摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),完全采用了自注意力机制来实现序列到序列的学习。Transformer 架构包括编码器和解码器,其中编码器用于将输入序列编码成抽象表示,解码器用于根据编码器输出和上下文信息生成目标序列。Transformer 架构的出现为AI大模型的发展奠定了基础。
(2)自注意力机制:
自注意力机制是 Transformer 架构的核心,它允许模型在输入序列的所有位置上进行注意力计算,从而实现了对序列内部信息的全局建模。自注意力机制可以捕获输入序列中不同位置之间的依赖关系,并且能够有效处理长距离依赖关系,使得模型能够更好地理解和处理复杂的序列数据。
(3)预训练与微调:
AI大模型通常采用预训练和微调的策略进行训练。在预训练阶段,模型通过在大规模无标注数据上进行自监督学习或者有监督学习,学习得到通用的特征表示。在微调阶段,模型在特定任务的有标注数据上进行微调,以适应任务的特定要求。预训练和微调策略有效地提高了模型的泛化能力和适应性。
(4)多头注意力:
多头注意力机制是 Transformer 中的一种变体,它允许模型在不同的子空间中学习不同的特征表示。通过将注意力机制分为多个头部,模型能够同时捕获不同语义层次的信息,从而提高了模型的表达能力和学习效率。
(5)残差连接与层归一化:
残差连接和层归一化是提高深度神经网络性能的重要技术。残差连接允许模型在不同层次之间传递原始输入的信息,有助于缓解梯度消失和梯度爆炸问题。层归一化则有助于加速模型的训练收敛,提高模型的稳定性和泛化能力。
(6)优化和正则化技术:
AI大模型的训练通常采用各种优化算法和正则化技术来提高模型的性能和泛化能力。常用的优化算法包括随机梯度下降(SGD)、自适应学习率优化器(如Adam)、动量法等。正则化技术包括 L1 正则化、L2 正则化、Dropout 等,用于减少模型的过拟合风险。
通过这些基本原理和核心技术,AI大模型能够在大规模数据上进行训练,并在各种任务和领域中取得显著的成绩。
2、神经网络训练与优化的基本理论
神经网络训练与优化的基本理论涵盖了许多重要概念和技术,以下是其中的一些:
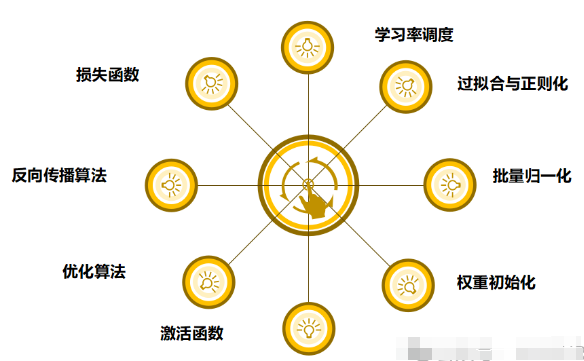
(1)损失函数(Loss Function):
损失函数是衡量模型预测输出与实际标签之间差异的函数。在监督学习中,通过最小化损失函数来调整模型参数,使得模型的预测结果尽可能接近实际标签。常见的损失函数包括均方误差(MSE)、交叉熵损失(Cross Entropy)、对数损失(Log Loss)等。
(2)反向传播算法(Backpropagation):
反向传播算法是神经网络训练的核心技术之一,用于计算损失函数关于模型参数的梯度。通过链式法则将输出层的误差反向传播到输入层,从而计算每个参数对损失函数的影响,然后使用梯度下降等优化算法更新模型参数。
(3)优化算法(Optimization Algorithms):
优化算法用于调整模型参数以最小化损失函数。常见的优化算法包括随机梯度下降(SGD)、动量法(Momentum)、AdaGrad、RMSProp、Adam 等。这些算法在梯度下降的基础上进行了改进,以提高收敛速度、稳定性和泛化能力。
(4)激活函数(Activation Functions):
激活函数是神经网络中的非线性变换,用于引入非线性因素以增加模型的表达能力。常见的激活函数包括 Sigmoid、ReLU(Rectified Linear Unit)、Tanh 等。选择合适的激活函数有助于提高模型的拟合能力和训练速度。
(5)权重初始化(Weight Initialization):
权重初始化是指初始化神经网络参数的过程,它对于训练的稳定性和收敛速度具有重要影响。常见的权重初始化方法包括随机初始化、Xavier 初始化、He 初始化等。
(6)批量归一化(Batch Normalization):
批量归一化是一种用于加速神经网络训练和提高模型稳定性的技术,通过在每个批次中对输入数据进行归一化处理,使得模型训练更加稳定且收敛速度更快。
(7)过拟合与正则化(Overfitting and Regularization):
过拟合是指模型在训练集上表现良好,但在测试集上泛化能力较差的现象。为了减少过拟合风险,可以采用正则化技术,如 L1 正则化、L2 正则化、Dropout 等,以限制模型的复杂度并增强泛化能力。
(8)学习率调度(Learning Rate Scheduling):
学习率调度是一种动态调整学习率的方法,可以根据训练过程中模型的表现来自适应地调整学习率。常见的学习率调度策略包括学习率衰减、余弦退火、指数衰减等。
以上这些基本理论构成了神经网络训练与优化的核心内容,通过合理地应用这些理论和技术,可以提高神经网络模型的性能和泛化能力。
3、与AI大模型相关的理论模型和概念
与AI大模型相关的理论模型和概念涵盖了多个领域的理论和方法,以下是一些与AI大模型密切相关的理论模型和概念:
(1)深度学习(Deep Learning):
深度学习是一种机器学习方法,通过构建多层神经网络来模拟人类大脑的工作原理,实现对复杂数据的学习和理解。AI大模型往往基于深度学习技术构建,利用大规模数据进行训练,具有强大的表征能力和泛化能力。
(2)神经网络(Neural Networks):
神经网络是深度学习模型的基础,它由多层神经元组成,通过学习输入数据的特征表示来实现对复杂任务的建模和预测。AI大模型往往是由数十甚至数百层的神经网络构成的。
(3)Transformer 架构:
Transformer 是一种基于自注意力机制的神经网络架构,由 Vaswani 等人提出。Transformer 架构被广泛应用于自然语言处理领域,是许多AI大模型的基础架构,如BERT、GPT、T5等。
(4)自注意力机制(Self-Attention Mechanism):
自注意力机制是一种用于捕捉序列数据中全局依赖关系的技术,它能够在输入序列的所有位置上进行注意力计算,从而有效地捕获长距离依赖关系。自注意力机制是Transformer 架构的核心组成部分。
(5)预训练与微调(Pre-training and Fine-tuning):
预训练和微调是AI大模型训练的常用策略。在预训练阶段,模型通过在大规模无标注数据上进行自监督学习或有监督学习来学习通用的特征表示;在微调阶段,模型在特定任务的有标注数据上进行微调,以适应任务的特定要求。
(6)多模态学习(Multi-Modal Learning):
多模态学习是一种将不同类型数据(如文本、图像、音频等)融合在一起进行联合建模的方法。AI大模型往往能够处理多模态数据,例如图文生成、图像问答等任务。
(7)元学习(Meta-Learning):
元学习是一种让模型学会如何学习的方法,通过在不同任务上学习通用的学习策略,使得模型能够快速适应新任务。元学习技术有助于提高AI大模型在小样本和少样本场景下的泛化能力。
这些理论模型和概念构成了AI大模型研究和发展的基础,通过不断地探索和优化,有助于推动AI大模型的进一步发展和应用。
三、技术方法
在研究和应用AI大模型时,技术方法的选择和运用至关重要。本节将介绍一系列用于训练、优化和压缩AI大模型的技术方法。这些方法涵盖了从分布式训练到模型压缩等各个方面,以应对复杂的模型训练和应用挑战。
1、训练大型模型的技术方法
训练大型模型涉及到许多技术方法和工程实践,以下是一些常用的训练大型模型的技术方法:
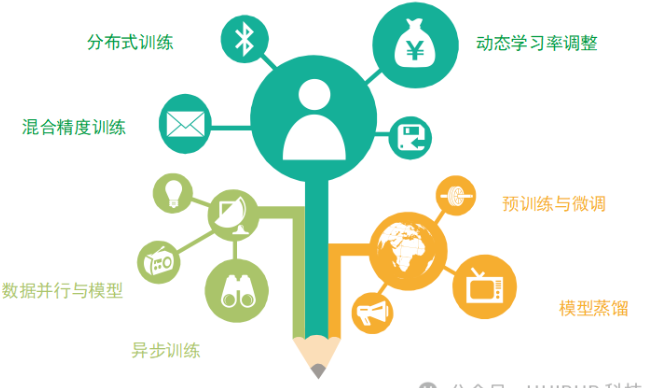
(1)分布式训练(Distributed Training):
分布式训练是将模型的训练过程分布在多个计算节点上进行,并通过消息传递或参数服务器等方式进行通信和同步。分布式训练可以显著加快训练速度,并处理大规模数据和大型模型带来的计算和存储压力。
(2)混合精度训练(Mixed Precision Training):
混合精度训练是将模型参数的计算过程中使用不同的数值精度,通常将参数和梯度计算采用低精度(如半精度浮点数),而梯度更新过程采用高精度(如单精度浮点数)。混合精度训练可以减少内存占用和计算量,加快训练速度。
(3)数据并行与模型并行(Data Parallelism vs Model Parallelism):
数据并行是将训练数据分成多个批次,在多个计算节点上并行处理,每个节点上的模型参数相同。模型并行是将模型的不同部分分布在不同的计算节点上进行训练,每个节点上的模型参数不同。数据并行和模型并行可以结合使用,以处理大型模型和大规模数据的训练。
(4)异步训练(Asynchronous Training):
异步训练是在分布式训练中使用的一种策略,允许不同计算节点之间的训练过程是异步的,即不需要等待所有节点完成计算才进行参数更新。异步训练可以提高训练效率,但可能会引入一定的收敛速度和稳定性问题。
(5)模型蒸馏(Model Distillation):
模型蒸馏是一种通过将一个大型复杂模型的知识转移到一个小型简单模型中来进行训练的方法。在训练大型模型之后,可以使用模型蒸馏技术将其知识压缩到一个小型模型中,从而减少模型的存储和计算开销。
(6)预训练与微调(Pre-training and Fine-tuning):
预训练是指在大规模无标注数据上进行的模型初始化过程,通常采用自监督学习或有监督学习的方式。微调是在特定任务的有标注数据上对预训练模型进行微调,以适应任务的特定要求。预训练和微调是训练大型模型的常用策略。
(7)动态学习率调整(Dynamic Learning Rate Adjustment):
动态学习率调整是一种根据训练过程中模型的性能动态调整学习率的方法,常见的技术包括学习率衰减、余弦退火、指数衰减等。动态学习率调整可以提高模型的收敛速度和泛化能力。
通过这些技术方法和工程实践,可以有效地训练大型模型,提高模型的性能和泛化能力,加速模型的收敛速度,从而实现在大规模数据和复杂任务上的应用。
2、大型模型的优化和压缩技术
针对大型模型的优化和压缩是提高模型效率、减少资源消耗、加速推理速度的重要手段。以下是一些常见的大型模型优化和压缩技术:
(1)模型剪枝(Model Pruning):
模型剪枝通过删除模型中冗余或不必要的参数和连接来减少模型的大小和计算量。常见的剪枝方法包括结构化剪枝、不结构化剪枝和稀疏化剪枝。模型剪枝可以显著减少模型的参数数量和存储空间,同时提高推理速度。
(2)量化(Quantization):
量化是将模型参数和激活值从浮点数表示转换为定点数或低位宽浮点数表示的过程。常见的量化方法包括定点量化、二值量化、三值量化等。量化技术可以大幅减少模型参数的存储需求和计算复杂度,提高模型在硬件上的执行效率。
(3)低秩近似(Low-Rank Approximation):
低秩近似是通过将模型参数矩阵分解为多个较低秩的矩阵来减少模型的参数数量和计算量。常见的低秩近似方法包括奇异值分解(Singular Value Decomposition,SVD)和张量分解(Tensor Decomposition)等。
(4)知识蒸馏(Knowledge Distillation):
知识蒸馏是一种通过将一个大型复杂模型的知识迁移到一个小型简单模型中来进行模型压缩的方法。通常,通过将大型模型的软标签(logits)作为小型模型的训练目标,以及利用温度参数来平滑目标概率分布,从而进行知识蒸馏。
(5)网络结构搜索(Neural Architecture Search,NAS):
网络结构搜索是一种自动化搜索适合特定任务的神经网络结构的方法。通过搜索和优化网络结构,可以设计出更加轻量化和高效的模型,以满足不同场景下的资源约束和性能需求。
(6)动态模型调整(Dynamic Model Adaptation):
动态模型调整是一种根据运行环境和输入数据的特性动态调整模型结构和参数的方法。例如,根据设备的计算资源和存储空间情况动态调整模型的大小和复杂度,或者根据实时输入数据的特征动态调整模型的参数。
这些优化和压缩技术可以在减少模型的存储和计算开销的同时,保持模型的性能和精度,从而实现在资源受限环境下的高效部署和应用。
3、大型模型在特定任务上的调参策略和实验技巧
针对大型模型在特定任务上的调参策略和实验技巧
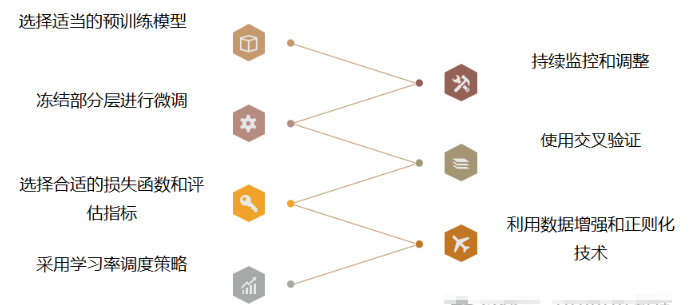
(1)选择适当的预训练模型:
在开始特定任务之前,选择一个适合的预训练模型作为基础。预训练模型的选择可以考虑该模型在相关领域的性能、规模大小、训练数据集的相似性等因素。
(2)冻结部分层进行微调:
对于大型预训练模型,可以冻结部分层(通常是底层或中间层)的参数,只微调模型的顶层或添加的新层。这样可以减少训练参数数量,加快训练速度,并降低过拟合的风险。
(3)选择合适的损失函数和评估指标:
选择与任务相匹配的损失函数和评估指标是至关重要的。根据任务的特性选择适当的损失函数,例如分类任务可以选择交叉熵损失,回归任务可以选择均方误差损失。评估指标可以是准确率、精确度、召回率、F1 分数等,具体根据任务需求而定。
(4)采用学习率调度策略:
使用合适的学习率调度策略有助于加速模型的收敛速度和提高性能。常见的学习率调度策略包括学习率衰减、余弦退火、指数衰减等。根据实验观察,动态调整学习率可能更有利于模型的优化。
(5)利用数据增强和正则化技术:
数据增强和正则化技术有助于提高模型的泛化能力和抗干扰能力。在训练过程中,可以采用各种数据增强技术如随机裁剪、旋转、翻转等来扩增训练数据,同时加入正则化技术如 Dropout、批量归一化等来减少过拟合的风险。
(6)使用交叉验证:
在模型调参过程中,使用交叉验证来评估模型的性能,有助于减少对单个验证集的依赖,提高模型评估的准确性和鲁棒性。交叉验证可以帮助确定最佳的超参数设置,例如学习率、批量大小、正则化参数等。
(7)持续监控和调整:
在模型训练过程中,持续监控模型的性能和指标变化,并根据实验结果调整模型的超参数和训练策略。通过反复迭代和实验,逐步优化模型并提高性能。
通过以上策略和技巧,可以有效地调优大型模型以适应特定任务的要求,提高模型的性能和泛化能力。
四、应用场景
在实际应用中,AI大模型在各个领域展现出了巨大的潜力。AI大模型在不同领域的应用场景,包括自然语言处理、计算机视觉、医疗健康等。通过深入了解这些应用场景,我们可以更好地理解AI大模型在解决现实问题中的作用和意义。
1、AI大模型在不同领域的应用案例
AI大模型在不同领域的应用案例非常丰富,以下是一些典型的例子:
(1)自然语言处理(NLP):
语言理解:使用AI大模型如BERT、GPT等进行语言理解任务,包括情感分析、命名实体识别、文本分类等。
语言生成:利用AI大模型生成文本,如基于GPT的文章生成、对话系统等。
机器翻译:利用AI大模型进行机器翻译任务,如使用Transformer架构的模型进行多语言翻译。
(2)计算机视觉(Computer Vision):
图像分类和目标检测:利用AI大模型进行图像分类、目标检测等任务,如使用CNN结构的模型进行图像分类和目标检测。
图像生成:使用生成对抗网络(GAN)和变分自编码器(VAE)等AI大模型进行图像生成任务,如图像超分辨率、风格迁移等。
(3)自动驾驶与智能交通:
自动驾驶:利用AI大模型处理传感器数据,进行环境感知、路径规划、行为预测等任务,如使用深度学习模型实现自动驾驶功能。
智能交通管理:利用AI大模型分析交通数据,进行交通流预测、拥堵管理等任务,如使用循环神经网络(RNN)模型进行交通流预测。
(4)医疗与生物信息学:
医学影像分析:利用AI大模型分析医学影像数据,进行疾病诊断、病灶检测等任务,如使用卷积神经网络进行医学影像分析。
药物设计与发现:利用AI大模型进行药物筛选、分子对接等任务,加速药物研发和发现过程。
(5)金融与风控:
信用评分:利用AI大模型分析客户数据,进行信用评分和风险管理,如使用深度学习模型进行信用评级。
欺诈检测:利用AI大模型分析交易数据,进行欺诈检测和风险预警,如使用逻辑回归模型进行欺诈检测。
(6)教育与辅助学习:
个性化教育:利用AI大模型分析学生数据,进行个性化教育和学习路径规划,如使用深度强化学习模型进行个性化推荐。
智能辅导:利用AI大模型进行学习过程监控和辅导,如使用聊天机器人进行答疑解惑。
这些应用案例展示了AI大模型在各个领域的广泛应用,并且在提高效率、改善用户体验、降低成本等方面发挥着重要作用。
2、AI大模型在应用中的优势和局限性
AI大模型在应用中具有许多优势,同时也存在一些局限性。以下是它们的一些主要特点:
(1)优势:
强大的表征能力:
AI大模型具有强大的表征学习能力,可以学习和理解复杂的数据模式和特征,从而在各种任务中取得良好的性能。
泛化能力强:
通过在大规模数据上进行预训练,AI大模型可以学习到通用的特征表示,具有较强的泛化能力,可以适应不同领域和任务的需求。
多模态融合:
AI大模型可以同时处理多种类型的数据,如文本、图像、语音等,能够进行多模态融合,从而实现更丰富的应用场景。
自动化特征提取:
AI大模型可以自动学习数据的特征表示,无需人工设计特征,减少了特征工程的工作量,提高了模型的效率和准确性。
持续迭代和优化:
AI大模型具有可迭代性,可以不断通过大规模数据进行迭代和优化,从而提高模型性能和精度。
(2)局限性:
计算和存储资源需求大:
AI大模型通常需要大量的计算资源和存储空间进行训练和推理,这对于硬件设备和成本带来了挑战。
可解释性差:
由于AI大模型的复杂性,其内部结构和决策过程通常难以解释和理解,这可能会限制其在一些对模型解释性要求较高的领域的应用。
数据隐私和安全风险:
AI大模型在训练过程中需要大量的数据,这可能涉及到数据隐私和安全风险,如数据泄露、隐私侵犯等问题。
过拟合和泛化能力不足:
在一些小样本和少样本场景下,AI大模型可能面临过拟合的问题,且泛化能力不足,需要针对性地进行调优和改进。
环境依赖性:
AI大模型的性能可能受到环境、数据分布和任务特性等因素的影响,需要在不同环境下进行适当的调整和优化。
综上所述,尽管AI大模型在各个领域都取得了巨大的成功,但在实际应用中仍然需要综合考虑其优势和局限性,针对性地进行应用和改进,以实现更好的性能和效果。
3、AI大模型在未来的发展趋势和可能的应用场景
未来AI大模型的发展趋势将会朝着以下几个方向发展:
模型规模持续增大:
随着硬件技术的进步和数据量的增加,AI大模型的规模将会不断增大,可能会出现更大规模、参数更多的模型,以进一步提升模型的性能和泛化能力。
跨模态融合:
未来的AI大模型可能会更加注重跨模态数据的融合和处理,例如将文本、图像、语音等多种类型的数据进行联合建模,实现更复杂、更丰富的应用场景。
可解释性和可控性增强:
针对AI大模型可解释性和可控性不足的问题,未来可能会加强对模型内部结构和决策过程的解释和理解,以提高模型的可解释性和可控性,满足对模型解释性要求较高的应用场景。
自适应学习能力:
未来的AI大模型可能会具备更强的自适应学习能力,能够根据环境和任务的变化自动调整模型结构和参数,实现持续迭代和优化。
个性化定制服务:
针对个性化需求的增加,未来的AI大模型可能会更加注重个性化定制服务,能够根据用户的特征和偏好提供个性化的服务和建议。
边缘计算和端到端解决方案:
随着边缘计算和物联网技术的发展,未来的AI大模型可能会更加注重在边缘设备上的部署和应用,提供端到端的智能解决方案。
多模态AI系统:
未来的AI大模型可能会更加注重多模态数据的处理和应用,能够实现不同模态数据之间的信息融合和交互,从而实现更加复杂和多样化的应用场景。
基于这些发展趋势,未来AI大模型可能会在医疗健康、智能交通、智能制造、智能教育、智能金融等领域发挥更加重要的作用。同时,AI大模型也将面临更多挑战,如数据隐私保护、可解释性问题、普适性问题等,需要继续探索和解决。
五、结论与展望
本文探讨了AI大模型的理论、技术和应用,总结如下:
1、主要观点和结论:
AI大模型具有强大的表征学习能力和泛化能力,在自然语言处理、计算机视觉、医疗健康、金融等领域取得了显著成就。
在训练大型模型方面,分布式训练、混合精度训练、模型并行等技术方法可以提高效率。
针对大型模型的优化和压缩技术包括模型剪枝、量化、知识蒸馏等,有助于减少模型的存储和计算开销。
在特定任务上,合理选择预训练模型、微调策略、损失函数等,可以提高模型的性能和效果。
2、未来研究和发展方向的建议:
加强AI大模型的可解释性和可控性研究,提高模型的透明度和可理解性,增强用户对模型的信任度。
深入研究跨模态融合技术,探索多种类型数据的融合和交互方式,实现更复杂、更丰富的应用场景。
加强对边缘计算和端到端解决方案的研究,实现在边缘设备上的智能应用和服务,满足不同场景下的需求。
3、对AI大模型技术的未来发展进行展望和预测:
AI大模型将继续发展壮大,规模和参数数量将不断增加,表征能力和泛化能力将进一步提升。
AI大模型将更加注重在边缘计算和物联网领域的应用,实现智能物联网和智能边缘设备。
AI大模型将更加注重多模态数据的处理和应用,实现不同模态数据之间的信息融合和交互,开拓更广阔的应用领域。
通过本文的探索,我们粗略了解了AI大模型的理论基础、技术方法以及在各个领域的应用场景。AI大模型作为当今人工智能领域的热点和前沿,展现出了巨大的潜力和发展空间。然而,我们也看到了AI大模型在实际应用中面临的挑战和局限性。
在未来的发展中,我们需要持续关注AI大模型的理论研究和技术创新,不断提高模型的性能和效率。同时,我们也需要探索更广泛的应用场景,将AI大模型应用于更多领域,实现人工智能技术的更大发展和应用。在这个过程中,我们需要充分发挥学术界、产业界和政府部门的力量,共同推动AI大模型技术的发展和应用,为人类社会的进步和发展做出贡献。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

