
- 1SpringBoot GraalVM Native Image Support_springboot graalvm 编译 native
- 2OpenCV-Python系列(二)—— 图像处理(灰度图、二值化、边缘检测、高斯模糊、轮廓检测)_使用opencv将图片转化为灰度图像 把灰度图像转化为二值度图像 使用foundcontours
- 3tensorflow使用多个gpu训练
- 4深度学习与机器学习:发展融合之路
- 5eclipse操作git_eclipse unstaged changes好多没用的
- 6ESP8266 PWM输出控制_esp8266 控制360舵机
- 7编译原理——正规表达式与有限自动机(笔记)_确定的有限自动机是一个( ),通常表示为( )
- 8dockerfile CMD/ENTRYPOINT 指令,内部运行python文件,run的时候内部参数如何可配置_docker运行容器里py文件
- 9sc start service 1063 1053 错误原因_[sc] startservice 失败 1053:
- 10认识Tomcat (一)
kafka使用_使用Kafka Connect 同步Kafka数据到日志服务
赞
踩

简介
Kafka作为最流行的消息队列,在业界有这非常广泛的使用。不少用户把日志投递到Kafka之后,再使用其他的软件如ElasticSearch进行分析。Kafka Connect 是一个专门用于在Kafka 和其他数据系统直接进行数据搬运插件,如将Kafka数据写入到S3,数据库等。
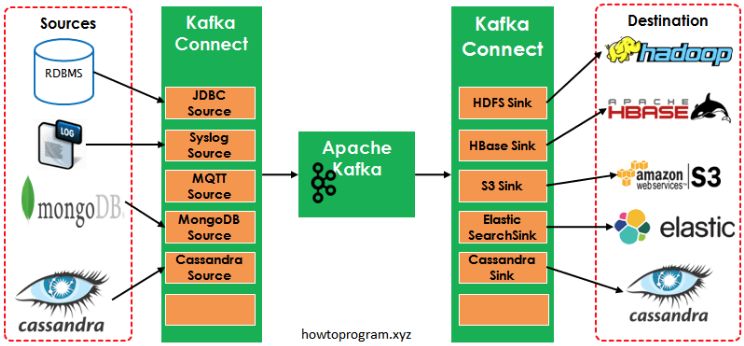
Kafka Connect
阿里云日志服务是一个日志采集,查询分析与可视化的平台,服务于阿里云上数十万用户。借助于日志服务提供的Kafka Connect插件,我们可以使用Kafka Connect 把Kafka里面的数据同步到阿里云日志服务,利用日志服务强大的查询能力与丰富的可视化图表类型,对数据进行分析与结果展示。
环境准备
如果还没有开通日志服务,前往 日志服务控制台开通。
准备测试用的 Kafka 集群。
创建用于访问阿里云日志服务的Access Key。
在日志服务控制台创建Project 和Logstore,并开启索引。
Kafka Connect安装
下载Kafka 日志服务connect 插件并打包:

打包之后,在项目根目录下,会生成一个压缩包 target/kafka-connect-logservice-1.0.0-jar-with-dependencies.jar 。这个文件包含了插件和所有依赖,把这个文件复制到Kafka运行的机器上。
Kafka connect的工作模式分为两种,分别是standalone模式和distributed模式。standalone模式可以简单理解为只有一个单独的worker,只需在启动时指定配置文件即可。而distributed模式可以启动多个worker,可以水平扩展和failover,插件本身的配置通过REST API的方式传递。这里我们为了演示方便仅演示standalone模式,在生产环境中建议使用distributed模式。
启动Connect
1)修改日志服务插件配置文件
在项目目录下config目录内有一个配置文件sink.properties,里面包含了日志服务插件运行所必须的配置信息:
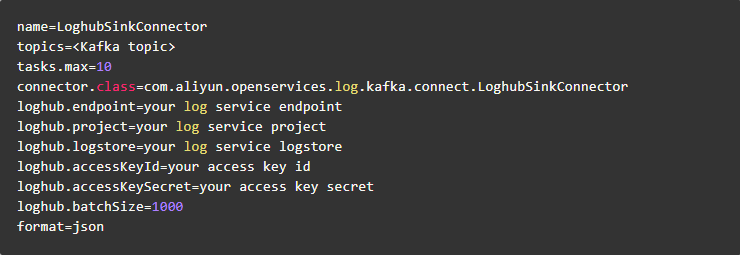
除了放日志服务必需的配置外,还可以指定数据格式。目前日志服务Connector只支持字符串类型的数据,format可以选择 json 或者 raw:
json:每条纪录的value作为一个JSON字符串解析,自动提取字段并写入日志服务。
raw:每条纪录的value作为一个字段,写入日志服务。
2)修改connect配置文件
在Kafka下载目录下,找到 config/connect-standalone.properties,修改如下配置:

plugin.path即为上文构建的jar 所在目录。在Kafka 下载目录内执行启动命令:

生成测试数据

替换其中的Kafka配置:
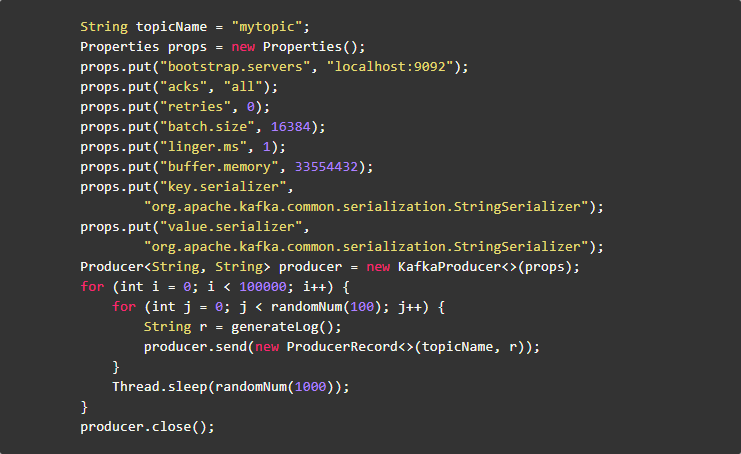
在IDE中运行产生测试数据的程序,会通过Kafka Producer往Kafka中写入一些模拟数据。
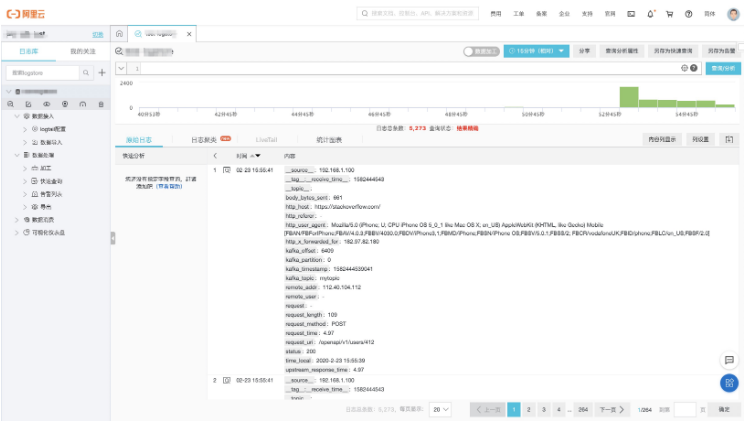
写入结果查询
日志服务控制台查看数据写入成功:
 更多精彩
更多精彩


 动动小手指 这里有
采购季最强攻略
!
动动小手指 这里有
采购季最强攻略
!

- swagger:swagger 引入
[详细] 赞
踩

