
- 1灰度图恢复(100%用例)C卷(Java&&Python&&C++&&Node.js&&C语言)
- 2Apache Velocity漏洞CVE-2020-13936修复记录
- 3idea docker 内网应用实践
- 4error C2099: initializer is not a constant 或者error C2099:初始值设定项不是常量_error c2099: 初始值设定项不是常量
- 5机器学习-聚类算法Kmeans【手撕】
- 6【Linux operation 11】 - Linux 查看系统及内核信息
- 7JDK 各版本汇总表_jdk版本
- 8关于Spring cloud Gateway集成nacos 实现路由到指定微服务的方式总结_spring cloud gateway简写版路由配置无法转到对应微服务问题解决
- 9第四章 字符串_python实现将用户输入的十进制整数转换为指定进制的功能
- 10一文详解docker compose
Zookeeper深度解析(概念、原理机制、应用场景)_一致性协调服务
赞
踩
一、什么是Zookeeper?
Zookeeper是一个高效的分布式一致性协调服务,可以提供配置信息管理、命名、分布式同步、集群管理、数据库切换等服务。它不适合用来存储大量信息,可以用来存储一些配置、发布与订阅等少量信息。(Zookeeper 作为 Hadoop 项目中的一个子项目,是 Hadoop 集群管理的一个必不可少的模块,它主要用来控制集群中的数据,如它管理 Hadoop 集群中的 NameNode,还有 Hbase 中 Master Election、Server 之间状态同步等。)
二、Zookeeper设计目的
- 最终一致性:client不论连接到哪个Server,展示给它都是同一个视图,这是zookeeper最重要的性能。
- 可靠性:具有简单、健壮、良好的性能,如果消息m被到一台服务器接受,那么它将被所有的服务器接受。
- 实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
- 等待无关(wait-free):慢的或者失效的client不得干预快速的client的请求,使得每个client都能有效的等待。
- 原子性:更新只能成功或者失败,没有中间状态。
- 顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
三、Zookeeper的安装
- 前置环境:已安装好jdk
- 下载zookeeper的安装包:官网下载,下载和解压到/usr/local中
- 创建数据、日志文件夹:
- mkdir /usr/local/zookeeper/data
- mkdir /usr/local/zookeeper/log
- 设置核心配置文件:
- #打开核心配置
- mv /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg
- #设置核心配置文件
- vim /usr/local/zookeeper/conf/zoo.cfg
- #填入如下配置
- dataDir=/usr/local/zookeeper/data
- dataLogDir=/usr/local/zookeeper/log
- 启动zookeeper
- cd /usr/local/zookeeper/bin
- #启动zookeeper
- ./zkServer.sh start
三、Zookeeper的文件系统
文件系统的数据结构
zookeeper是用一个树形结构来进行数据存储管理的。它不适合用来存储大量信息,可以用来存储一些配置、发布与订阅等少量信息。如下图所示:
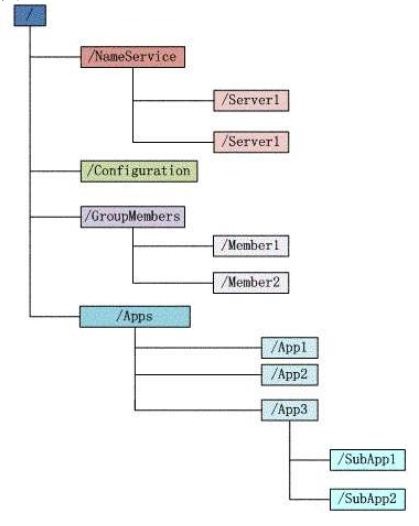
文件系统的节点(znode)
什么是znode?
每个子目录项如 NameService 都被称作为znode,和文件系统一样,我们能够自由的增加、删除znode,在一个znode下增加、删除子znode,每个znode都是可以存储数据的。
znode的分类
- persistent-持久化目录节点:持久节点就是节点被创建后会一直存在服务器,直到删除操作主动清除,这种节点也是最常见的类型。
- persistent_sequential-持久化顺序编号目录节点:持久顺序节点就是有顺序的持久节点,节点特性和持久节点是一样的,只是额外特性表现在顺序上。顺序特性实质是在创建节点的时候,会在节点名后面加上一个数字后缀,来表示其顺序。
- ephemeral-临时目录节点:临时节点就是会被自动清理掉的节点,它的生命周期和客户端会话绑在一起,客户端会话结束,节点会被删除掉。与持久性节点不同的是,临时节点不能创建子节点。
- ephemeral_sequential-临时顺序编号目录节点:临时顺序节点就是有顺序的临时节点,和持久顺序节点相同,在其创建的时候会在名字后面加上数字后缀。
文件系统的操作命令
运行zkCli.sh –server <ip:port>进入命令行工具,注意连接信息应该为zoo.cfg中配置的主机名或者ip
ls path命令
命令来查看当前znode下所包含的子节点
create [-s] [-e] path data acl 命令
创建节点命令,[-s] 顺序节点,[-e] 临时性节点,path 路径,data 数据内容,acl 权限
例如:create -s -e /newnode1 mydata
get path 命令
获取znode 信息
例如:get /app1
- 整个 ZNode 节点内容包括两部分:节点数据内容和节点状态信息。
- cZxid 就是 Create ZXID,表示节点被创建时的事务 ID。
- mZxid 就是 Modified ZXID,表示节点最后一次被修改时的事务 ID。
- ctime 就是 Create Time,表示节点创建时间。
- mtime 就是 Modified Time,表示节点最后一次被修改的时间。
- pZxid 表示该节点的子节点列表最后一次被修改时的事务 ID。只有子节点列表变更才会更新 pZxid,子节点内容变更不会更新。
- cversion 表示子节点的版本号。
- dataVersion 表示内容版本号。
- dataLength 表示数据长度。
- numChildren 表示子节点数。
- ephemeralOwner 表示创建该临时节点时的会话 sessionID,如果是持久性节点那么值为 0。
set path data [version] 命令
修改节点数据。path 是路径 data 是数据内容 [version] 是版本号,我们可以通过 set /app1 newapp1 来更新节点 /app1的内容,也可以自己设置版本号
例如: set /newnode1 updatedata
delete path [version] 命令
删除节点。
Java程序调用zookeeper的API操作节点
springboot整合zookeeper博客(转载链接)
zookeeper简便工具ZKclient的使用(转载链接)
引入依赖
- <dependency>
- <groupId>org.apache.zookeeper</groupId>
- <artifactId>zookeeper</artifactId>
- <version>3.4.10</version>
- </dependency>
连接zookeeper
- String hostPort = "192.168.137.88:2181";
- String rootPath = "/";
- ZooKeeper zooKeeper = new ZooKeeper(hostPort, 1000, null);
创建节点
- // 创建一个目录节点
- zookeeper.create("/mynode", "world".getBytes(), Ids.OPEN_ACL_UNSAFE,
- CreateMode.PERSISTENT);
获取节点状态信息
Stat falg = zooKeeper.exists("/mynode", false);获取节点数据内容
byte[] data2 = zooKeeper.getData("/mynode", false, null);修改节点数据
zooKeeper.setData("/mynode", "hello world!!!".getBytes(), -1);删除节点
zooKeeper.delete("/mynode", -1);关闭连接
zooKeeper.close();四、zookeeper的通知(Watch)机制
什么是zookeeper的通知机制?
Znode发生变化(Znode本身的增加,删除,修改,以及子Znode的变化)可以通过Watch机制通知到客户端。那么要实现Watch,就必须实现org.apache.zookeeper.Watcher接口,并且将实现类的对象传入到可以Watch的方法中。Zookeeper中所有读操作(getData(),getChildren(),exists())都可以设置Watch选项。Watch事件具有one-time trigger(一次性触发)的特性,如果Watch监视的Znode有变化,那么就会通知设置该Watch的客户端。
watch类型
数据watch(data watches):getData和exists负责设置数据watch
孩子watch(child watches):getChildren负责设置孩子watch
注意:
- exists操作上的watch,在被监视的Znode创建、删除或数据更新时被触发。
- getData操作上的watch,在被监视的Znode删除或数据更新时被触发。在被创建时不能被触发,因为只有Znode一定存在,getData操作才会成功。
- getChildren操作上的watch,在被监视的Znode的子节点创建或删除,或是这个Znode自身被删除时被触发。可以通过查看watch事件类型来区分是Znode,还是他的子节点被删除:NodeDelete表示Znode被删除,NodeDeletedChanged表示子节点被删除。
Java API设置Watch机制
创建自定义Watch监听类
- /**
- * 自定义watch
- */
- public class MyWatch implements Watcher {
-
- public void process(WatchedEvent watchedEvent) {
- System.out.println("监控的节点:" + watchedEvent.getPath());
- System.out.println("监控的类型:" + watchedEvent.getType());
- }
- }
设置Watch监听
- ZooKeeper zooKeeper = new ZooKeeper(hostPort, 1000, null);
- zooKeeper.getChildren(rootPath, new MyWatch());
事件类型
None:在客户端与Zookeeper集群中的服务器断开连接的时候,客户端会收到这个事件
NodeCreated:Znode创建事件
NodeDeleted:Znode删除事件
NodeDataChanged:Znode数据内容更新事件。其实本质上该事件只关注dataVersion版本号,但是只要调用了更新接口 dataVersion就会有变更
NodeChildrenChanged:Znode子节点改变事件,只关注子节点的个数变更,子节点内容有变更是不会通知的
五、zookeeper应用场景
1、配置文件管理
(1) 什么是配置文件管理?
程序通常会需要进行一些配置文件进行配置的管理。但是如果对于分布式项目来说,可能会部署在不同的服务器上,这样每台服务都会有自己的一套配置,如果需要对某些配置进行调整,则需要逐一的对各个服务器进行修改。zookeeper能够实现统一的配置文件管理。
(2) 如何管理配置文件?
将需要统一管理的配置全部放到zookeeper上去,保存在 Zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中就好

2、集群管理
(1) 什么是集群管理?
所谓集群管理无在乎两点:是否有机器退出和加入、选举master。
(2) 如何管理集群?
对于第一点,所有机器约定在父目录GroupMembers下创建临时目录节点,然后监听父目录节点的子节点变化消息。一旦有机器挂掉,该机器与 zookeeper的连接断开,其所创建的临时目录节点被删除,所有其他机器都收到通知:某个兄弟目录被删除。新机器加入也是类似,所有机器收到通知:新兄弟目录加入,highcount又有了。
对于第二点,我们稍微改变一下,所有机器创建临时顺序编号目录节点,每次选取编号最小的机器作为master就好。
3、分布式锁
(1) 分布式锁的实现方式
保持独占
我们将zookeeper上的一个znode看作是一把锁,通过createznode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。用完删除掉自己创建的distribute_lock 节点就释放出锁
控制时序
/distribute_lock 已经预先存在,所有客户端在它下面创建临时顺序编号目录节点,和选master一样,编号最小的获得锁,用完删除,依次方便

4、命名服务
在日常开发中,我们会遇到这样的场景:服务A需要访问服务B,但是服务B还在开发过程中(未完成),那么服务A(此时已完成)就不知道如何获取服务B的访问路径了,使用zookeeper的服务就可以简单解决:服务B部署成功后,可以先到zookeeper注册服务(即在zookeeper添加节点/service/B和节点数据)。服务A开发结束后,部署到服务器,然后服务A监控zookeeper服务节点/service/B,如果发现节点数据了,那么服务A就可以访问服务B了。
六、zookeeper集群
1、zookeeper的集群搭建
伪集群模式
什么是伪集群模式?
所谓伪集群, 是指在单台机器中启动多个zookeeper进程, 并组成一个集群.
步骤:
- 将单机安装的zookeeper文件夹复制2份
- 在每份zookeeper文件夹中的data目录下创建一个myid文件,并且写入一个编号(每个zookeeper服务的编号必须不同,1、2、3)
- 配置核心配置文件
- 依次启动每个zookeeper服务
- 查看每个zookeeper服务的状态
集群模式
集群模式的配置和伪集群基本一致.由于集群模式下, 各server部署在不同的机器上, 因此各server的conf/zoo.cfg文件可以完全一样.
zookeeper集群的“过半数存活”原则
什么是“过半数存活”原则?
“半数存活”原则,即集群中存活的服务器数量必须为总服务器数量的一半以上。
注意:
由于zookeeper过半数存活机制,因此在集群搭建的时候,我们通常都是搭建奇数台服务器。因为2N+1台服务器和2N+2 台服务器的容灾能力都是一样的,都是允许挂掉N台服务器(3台允许挂1台,4台也允许挂1台,依次类推)。所以基于成本考虑,2N+1台的选择方案更优。
zookeeper集群的角色

zookeeper集群的核心
- ZAB协议
ZooKeeper作为高可用的一致性协调框架,自然的ZooKeeper也有着一致性算法的实现,ZooKeeper使用的是ZAB协议作为数据一致性的算法,ZAB(ZooKeeper Atomic Broadcast )全称为:原子消息广播协议 - ZAB协议的基础
Leader选举:
在ZooKeeper中所有的事务请求都由一个主服务器也就是Leader来处理,其他服务器为Follower,Leader将客户端的事务请求转换为事务Proposal,并且将Proposal分发给集群中其他所有的Follower,然后Leader等待Follwer反馈,当有过半数(>=N/2+1)的Follower反馈信息后,Leader将再次向集群内Follower广播Commit信息,Commit为将之前的Proposal提交 - ZAB协议的状态
每个ZAB协议中,每个节点都属于以下三种中的一种
Looking:系统刚启动时或者Leader崩溃后正处于选举状态
Following:Follower节点所处的状态,Follower与Leader处于数据同步阶段
Leading:Leader所处状态,当前集群中有一个Leader为主进程
七、zookeeper配置详解
tickTime:心跳间隔时间。zookeeper中使用的基本时间单位, 毫秒值。
dataDir:数据目录。修改为zookeeper安装目录下的data目录,data目录自己创建,当然也可以指定为别的目录。
clientPort:客户端连接端口。客户端通过该端口连接Zookeeper。
initLimit:Follower初始化连接时和Leader连接的超时时间。zookeeper集群中的包含多台server,其中一台为leader,集群中其 余的server为follower。initLimit参数配置初始化连接时,follower和leader之间的最长心跳时间。此时该参数设置为5,说明时间限制为5倍tickTime,即5*2000=10000ms=10s
syncLimit:该参数配置leader和follower之间发送消息,请求和应答的最大时间长度。此时该参数设置为2,说明时间限制为2倍tickTime,即4000ms
集群配置:
server.serverid=serverhost:leader_listent_port:quorum_port
serverid:是当前zookeeper服务器的id(myid文件中写的编号)。
leader_listen_port:通常叫做原子广播端口,是该服务器一旦成为leader之后需要监听的端口,用于接收来自follower的请求。
quorum_port:通常叫做选举端口,是集群中的每一个服务器在最开始选举leader时监听的端口,用于服务器互相之间通信选举leader。

