
- 1基于Python爬虫山西太原酒店数据可视化系统设计与实现(Django框架) 研究背景与意义、国内外研究现状
- 2bootstrap_bootstrap依赖
- 3批处理基本概念及编写方式_批处理是一个基本模块,它允许某些系统程序集在预定时间运行。它旨在帮助自动化一
- 4多元有序logistic回归分析_SPSS实例教程:有序多分类Logistic回归
- 5PyCharm 安装插件Vue_社区版pycharm 如何安装vue.js
- 6python分词词典_Python分词模块jieba (01)-jieba安装,分词,提取关键词,自定义分词,切换词库讲解...
- 7SVM(Python代码)_svm代码
- 8几种常见的开源协议介绍_常见的来源协议
- 9yum软件使用方法详解_yum如何使用
- 10Pytorch纯新手入门笔记_you may need to close and restart your shell afte
ECCV 2022 | 网易互娱AI Lab提出首个基于单幅图片的实时高分辨率人脸重演算法
赞
踩
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—> CV 微信技术交流群
转载自:机器之心 | 作者:网易互娱AI Lab
网易互娱 AI Lab 提出了一种基于单幅图片的实时高分辨率人脸重演算法,分别在台式机 GPU 和手机端 CPU 上支持以实时帧率生成 1440x1440 和 256×256 分辨率的人脸重演图像。
近年来,面部重演 (Face Reenactment) 技术因其在媒体、娱乐、虚拟现实等方面的应用前景而备受关注,其最直接的帮助就是能够帮助提升音视频的制作效率。
面部重演算法是一类以源人脸图像作为输入,可以将驱动人脸的面部表情和头部姿态迁移到源图像中,同时保证在迁移过程中源人脸的身份不变。相关技术在虚拟主播、视频会议等媒体和娱乐应用方面都具有巨大潜力。但现有算法往往计算复杂度较高,性能无法满足实时应用环境的要求。
针对这一痛点,网易互娱 AI Lab 提出了一种基于单幅图片的实时高分辨率人脸重演算法,与已有 SOTA 方法相比,算法可以在保证结果质量的同时,最高可将算法速度提升至原来的 9 倍,分别在台式机 GPU 和手机端 CPU 上支持以实时帧率生成 1440x1440 和 256×256 分辨率的人脸重演图像。
近日,网易互娱 AI Lab 与清华大学合作对该方案进行了系统性技术梳理,并撰写论文《 :Real-Time High-Resolution One-Shot Face Reenactment》,该文章已被 ECCV 2022 收录。
:Real-Time High-Resolution One-Shot Face Reenactment》,该文章已被 ECCV 2022 收录。

Face2Faceρ生成结果,左边:1440×1440 分辨率结果(帧率:25 fps,GPU:Nvidia GeForce RTX 2080Ti),右边:256×256 分辨率结果(帧率:25 fps,CPU:Qualcomm Kryo 680)
项目地址:https://github.com/NetEase-GameAI/Face2FaceRHO
技术背景
目前已经有不少关于面部重演 (Face Reenactment) 的相关研究。然而,无论是传统基于 CG 技术,基于图像的检索或 GAN 方法实现面部重演都需要源人脸大量的训练数据(几分钟到几小时),而这在实际应用场景中几乎是不可能满足的。
因此,近年来,一些学者提出了仅依赖几幅或者单幅人脸图像进行人脸重演的算法,这类方法主要思路是通过对人脸的外观和运动信息进行解耦和编码,而后通过在大量视频集中通过自监督方式学习得到各自的先验信息。根据对运动信息的编码方式不同,相关工作可以分为基于形变 (warp-based) 和直接合成 (direct synthesis) 两类。其中,基于形变的方法将运动信息显示的表示为运动场,而直接合成方法则将人脸的外观和运动信息分别编码在低维隐空间中,而后在解码得到合成结果。
虽然目前这两类方法都能取得不错的效果,但他们各自都有自己的优缺点。基于形变的方法仅适用与头部姿态变化较小的情况,在编辑前后头部姿态变化较大时则往往效果较差;直接合成的方法虽然可以应对较大的姿态变化,但其合成结果整体的保真度不如形变方法,例如,往往编辑后会造成源人脸身份的改变。另外,最重要的是已有方法复杂度往往较高,性能无法满足实时应用环境的要求。
针对已有两大类方法所存在的问题,项目组对这两类方法进行了创新性的融合,并且给出了一个能够支持实时人脸重演的最优框架。利用该框架,我们首次在不降低最终合成质量的前提下,实现了仅依赖 CPU 的手机端实时人脸重演。同时,如果利用台式机 GPU,则该框架可以支持 1440×1440 的高分辨率实时人脸重演。
技术思路
该方案的核心思路为将直接合成的方法融入到基于形变的算法流程中,主要包括两大模块:
1. 由于基于形变的算法不需要从无到有合成全部人脸信息,具备构建支持实时应用的网络结构潜力,因此该方案以基于形变的算法框架为主干,提出了一个轻量级的 U 型形变网络结构;同时,结合直接合成方法的姿态编码方法将驱动人脸的头部三维姿态进行编码并注入到该网络中,以提高其对大姿态的生成质量;
2. 为了进一步提高算法效率,该方案还提出了一个层次化的运动场预测网络用于估计源人脸到驱动人脸的像素运动,与已有的单尺度运动场估计算法不同,该方案可以基于不同尺度的特征点图像由粗到精的预测运动场,在保证计算精度的同时进一步降低了算法的复杂度。
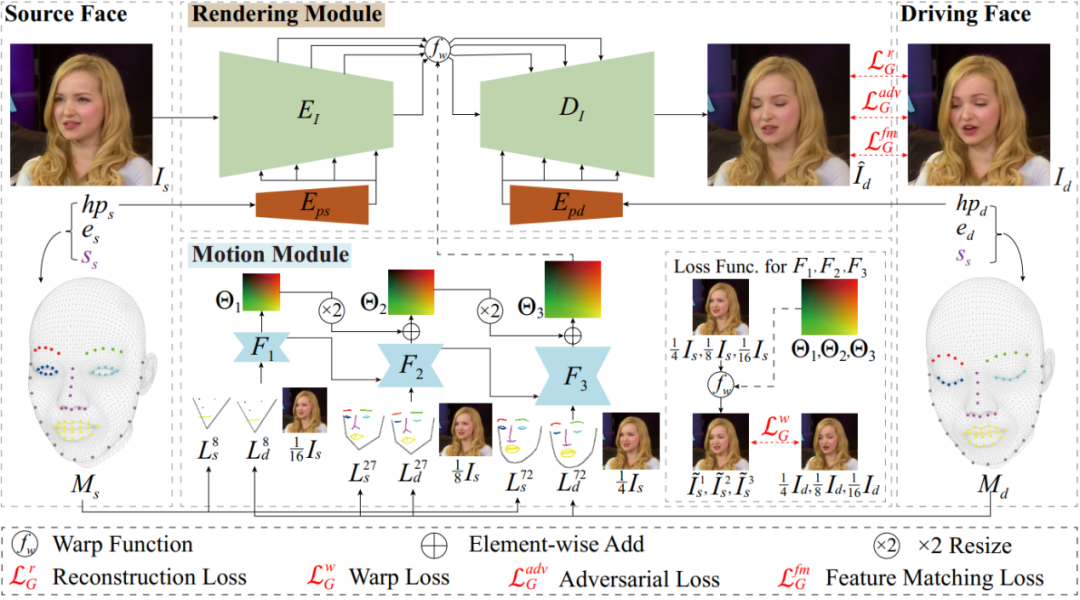
算法流程图
技术实现
本方法训练阶段以源图像和驱动图像对作为输入,首先采用 3DMM 算法拟合照片中人脸的形状、表情和头部姿态参数并计算相应的特征点图像。而后,渲染模块根据源图像、运动场以及源图像和驱动人脸的头部姿态合成面部重演结果。其中,运动场是由运动模块基于不同尺度的特征点图像采用由粗到精的方法预测得到。
3DMM 拟合
本方法首先采用网易互娱 AI Lab 自研的人脸 3DMM 重建算法计算得到输入的源图像和驱动图像的人脸参数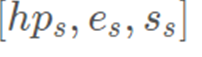 和
和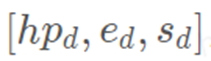 ,其中,
,其中, 为人脸形状参数,
为人脸形状参数, 为人脸表情参数,
为人脸表情参数,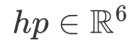 为头部姿态参数,s 和 d 分别代表源人脸和驱动人脸。与已有方法在应用 3DMM 重建结果时需要重建整个人脸不同的是,本方案仅需利用拟合得到的人脸信息重建部分关键点信息。在目前的方案中,我们基于 Face++ 的 106 点人脸特征点分布方案并从中选择了 72 个人脸关键点用于构建后续运动模块所需要的人脸特征点图。
为头部姿态参数,s 和 d 分别代表源人脸和驱动人脸。与已有方法在应用 3DMM 重建结果时需要重建整个人脸不同的是,本方案仅需利用拟合得到的人脸信息重建部分关键点信息。在目前的方案中,我们基于 Face++ 的 106 点人脸特征点分布方案并从中选择了 72 个人脸关键点用于构建后续运动模块所需要的人脸特征点图。
渲染模块
本方案渲染模块的主体框架采用基于形变的方法,然而传统的算法框架仅支持对于输入图片尺寸最多下采样到原尺度的 1/4,使用更多的下采样层则会导致图像合成质量明显降低,这就导致了整个网络不得不在较大的尺度上对图像进行处理,从而增加了算法的运行时间和内存占用。
为了解决这一问题,本方案提出了一个更有效率的渲染框架支持将输入图像下采样到原来的 1/16,并同时保证了最终的合成质量。网络结构如下图所示,主体结构由一个 U 型的编码器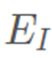 和解码器
和解码器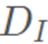 构成。由于每个下采样层都会造成图像细节的丢失,因此我们通过添加编码器与解码器之间的跳连来补偿这种信息损失。采用这种设计方案使得我们可以引入额外的 2 次下采样操作,在基本不改变生成质量的同时相比已有基于形变的算法框架提速至少 3 倍以上。
构成。由于每个下采样层都会造成图像细节的丢失,因此我们通过添加编码器与解码器之间的跳连来补偿这种信息损失。采用这种设计方案使得我们可以引入额外的 2 次下采样操作,在基本不改变生成质量的同时相比已有基于形变的算法框架提速至少 3 倍以上。
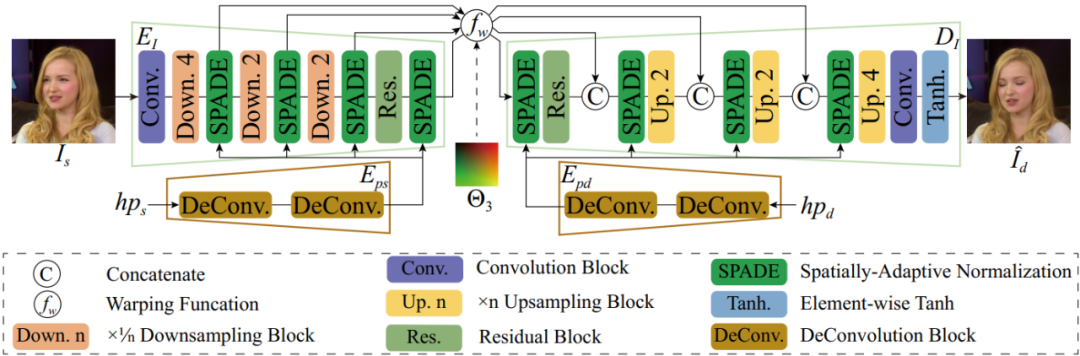
渲染模块网络结构图
传统基于形变的网络框架另一个显著的缺点是他们仅能处理有限范围内的姿态变化。因此,本文借鉴了直接合成方法中借助姿态信息来有效改善大姿态下的人脸合成质量的思路,对头部姿态信息进行编码并注入到编码器 E_I 和 D_I 中。其中,主流的头部姿态编码方式多是基于 2D 人脸特征点,3D 人脸特征点或者是点阵化后的 3DMM 人脸模型。然而,生成或者处理这些信息会引入不可忽略的计算代价。
因此,本方案直接使用 3DMM 拟合阶段所得到的头部姿态信息作为姿态编码注入渲染网络。具体的,6 维姿态信息首先通过反卷积网络 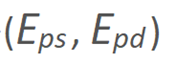 进行矩阵化编码,而后通过 SPADE 模块将其注入到渲染框架中。这里没有没有使用主流的 AdaIn 方法进行姿态信息的编码和注入的原因主要是出于时间效率上的考虑,测试发现 AdaIn 中使用的 MLP 结构时间消耗更大,且在最后的结果上与 SPADE 方法类似。
进行矩阵化编码,而后通过 SPADE 模块将其注入到渲染框架中。这里没有没有使用主流的 AdaIn 方法进行姿态信息的编码和注入的原因主要是出于时间效率上的考虑,测试发现 AdaIn 中使用的 MLP 结构时间消耗更大,且在最后的结果上与 SPADE 方法类似。
运动模块
准确的源图像到驱动图像人脸的运动信息估计对于基于形变方法的合成质量起着至关重要的作用。目前,采用人脸的 3DMM 网络作为运动场估计的指导信息是目前主流的也是效果比较好的方式。然而这种方式需要在预测时首先重构出整个人脸模型,而本文方法则仅需重建人脸网络上的稀疏特征点即可。通过将这些重构的特征投影到二维上并绘制得到人脸特征点图来作为预测运动场的指导信息,本方案可以避免对整个人脸网格的软渲染过程(往往非常耗时),使得即使在手机端 CPU 上也可以快速生成算法的输入数据。
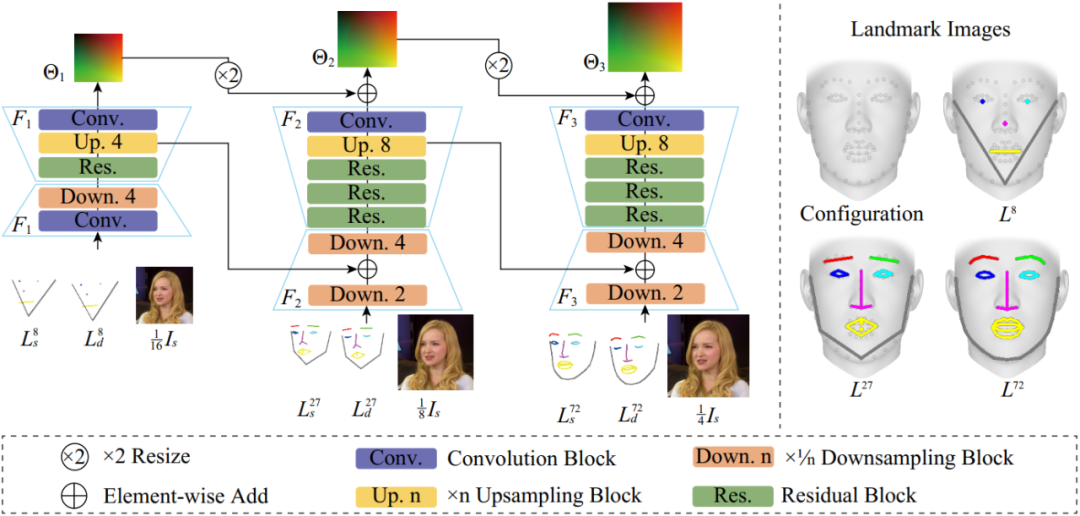
运动模块网络结构图
目前主流的运动场预测网络框架大多是基于单一尺度的 hourglass 网络,虽然效果较好但是效率较低。受最近光流场估计方法根据低分辨率预测结果渐进式生成高分辨率结果的启发,本文提出了一个类似的由粗到精的运动场估计策略,可以在不损失预测精度的前提下,相比传统单尺度算法提速 3.5 倍。如上图所示,运动模块分别采用三个子网络 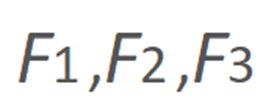 预测得到不同尺度下的运动场
预测得到不同尺度下的运动场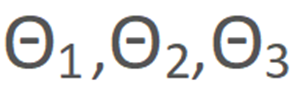 。每个子网络使用不同尺度的源图像和特征点图像作为输入,输出则为运动场的残差,用以在前一个网络的预测结果上添加细节。
。每个子网络使用不同尺度的源图像和特征点图像作为输入,输出则为运动场的残差,用以在前一个网络的预测结果上添加细节。
另外,每个子网络经过上采样后的特征图都会送入下一级网络用以加快网络训练时的收敛速度。需要注意的是,送入不同尺度子网络的特征点图所用的特征点数目也是逐渐增多的,如上图右侧所示,每层所用特征点是 72 个特征点的子集,数目分别为 8,27,72。
训练及预测细节
本文使用 VoxCeleb 数据集来进行训练,其中包含了大约 20k 的视频数据。训练过程采用自监督方式进行,从同一段视频中随机采样 2 张图像分别作为源图像和目标图像。另外,本文采用联合优化的方式在训练中同时更新渲染网路和运动网络的网络结构参数,损失函数包括以下几项:
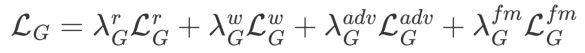
其中,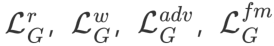 分别对应重建损失,形变损失,对抗损失和特征匹配损失,每个损失项的权重分别为 15,500,1,1。在本文实现中,
分别对应重建损失,形变损失,对抗损失和特征匹配损失,每个损失项的权重分别为 15,500,1,1。在本文实现中,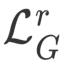 采用 VGG-19 网络计算生成结果和 ground-truth 之间的感知损失,
采用 VGG-19 网络计算生成结果和 ground-truth 之间的感知损失,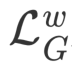 则计算了使用预测得到的运动场对源图进行形变的结果与 ground-truth 之间的 L_1损失用以约束运动模块生成正确的运动场,对抗损失
则计算了使用预测得到的运动场对源图进行形变的结果与 ground-truth 之间的 L_1损失用以约束运动模块生成正确的运动场,对抗损失 则采用对抗学习的方式进一步提高合成结果的质量,特征匹配损失
则采用对抗学习的方式进一步提高合成结果的质量,特征匹配损失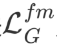 则用于稳定整个训练过程。
则用于稳定整个训练过程。
在预测过程中,对于给定的源图像,其人脸 3DMM 参数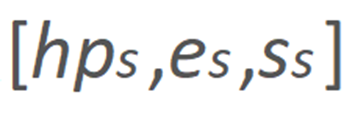 ,特征点图和渲染网络中的
,特征点图和渲染网络中的  和
和 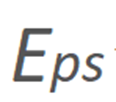 计算的特征编码都可以离线预先计算得到。而其余的步骤则是在线计算(例如,驱动人脸的 3DMM 参数
计算的特征编码都可以离线预先计算得到。而其余的步骤则是在线计算(例如,驱动人脸的 3DMM 参数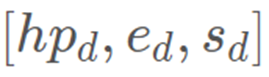 ,运动场
,运动场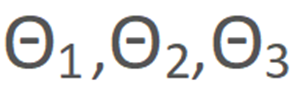 等)。
等)。
效果展示
项目组分别在人脸重演和人脸重建两个任务上对比了所提方案与已有 SOTA 方法 (FS-VID2VID, Bi-layer, LPD, FOMM, MRAA, HeadGAN) 的生成结果。从图中可以看出,所提方案无论在人脸身份的保持上或者对头部的大姿态编辑都能取得优于或与已有最优方法相似的结果,充分说明了算法的有效性。

人脸重演算法对比

人脸重建算法对比
另外,项目组还给出了手机端算法的运行效率,目前该算法支持手机端 CPU 下以 25 fps 的帧率实时生成 256x256 分辨率的人脸重演图片,而已有方案则均不支持手机端 CPU 下的实时运行。
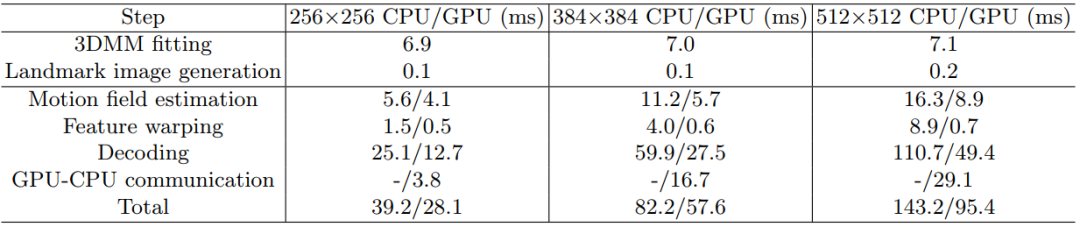
手机端运行时间
最后,项目组分别给出了算法在 PC 端和移动端的运行 demo 示例。
Mobile Demo
PC Demo
点击进入—> CV 微信技术交流群
CVPR 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
- 目标检测和Transformer交流群成立
- 扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
- 一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
-
- ▲扫码或加微信: CVer6666,进交流群
- CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
-
- ▲扫码进群
- ▲点击上方卡片,关注CVer公众号
- 整理不易,请点赞和在看

