
- 1【EI会议征稿】2024年第四届消费电子与计算机工程国际学术会议(ICCECE 2024)_ei会议ec4
- 2云计算面试总结_云计算运维面试
- 3Maven高级(二)--继承与版本锁定【案例:微服务备忘录的搭建】_maven 版本锁定
- 4java算法——盛最多水的容器(LeetCode第11题)_有 n 条垂线,长度存储在列表height 中,每相邻两条垂线间距离为1(垂线宽度不计)。
- 51391: 水仙花数(函数专题)_1391水仙花树
- 6OpenVINO主要工作流程_openvivo
- 7基于Spring Boot的ERP仓储管理信息系统设计与实现 毕业设计-附源码150958_货物仓储和运输调度管理原型系统的设计与实现
- 8故障:登录时不能选择 Administrator 账户登录_window7 admin设置的密码为admin登录不了
- 9Zabbix - 实现对磁盘动态监控
- 10技术淘宝
pytorch 实现yolo3详细理解(五)训练自己数据集和csv数据集标签处理_pytorch读取xml标签
赞
踩
摘要
前面基本已经将yolo3的大致细节都分析了,那么现在就要训练自己下载的数据集来看下效果,进行迁移学习,首先我会先对github本身自定义的custom数据集进行训练,只有一张照片,一个标签签,之后训练自己的数据集是要从xml文件先提取标签,完全按照custom中的格式进行布局,然后修改一下cfg文件就可以运行。dataset源码是对txt文件的处理,在实际运行中对数据进行分析是利用panda,所以直接利用panda生成csv文件进行读取更加方便。代码https://github.com/eriklindernoren/PyTorch-YOLOv3
custom数据集文件
在data文件夹下,这里一种有二个文件夹,三个文件,这里主要是一个模板,用于将自己的数据集处理成这种形式方便训练,这里也可以直接训练custom数据集,现在先来操作一下训练custom
训练custom数据集
在config文件夹下,如果是linux系统就可以直接运行.sh文件产生custom的cfg文件,这个文件的作用是darknet的网络部分,由于数据集的类别变化,输出的信息是由变化的,window系统可以直接复制yolo3.cfg文件 然后修改里面的参数,从新命名为yolo3-custom.cfg文件。具体修改如下(打开文件在最下面)

custom 中只有一个分类的train,所以类别为1,还有filters=3*(5+1)=18,3是yolo3中每个预测大小都有三种,5是框的坐标和置信度,1是我们需要训练的类别,
这里只写个一处位置的修改,上面还有二处,找到【yolo】的位置,修改classes,和上一层的filters=18就行,
开始训练
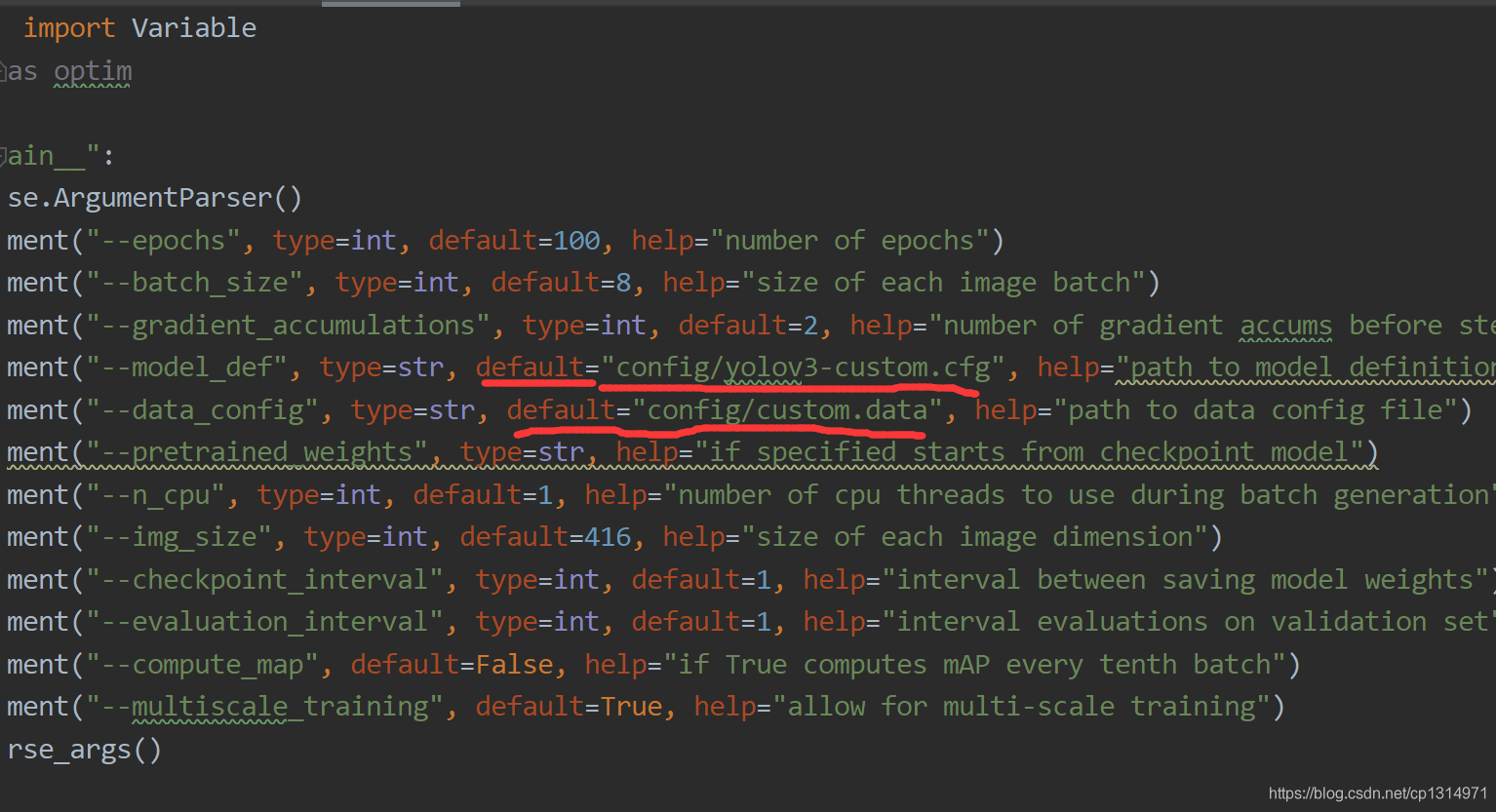
打开train.py文件,修改这二个地方,改成custom的数据集即可。到这里是可以运行的,当然你的电脑配置可能到不到设置的要求,在按照下面的修改一下batch 和num,主要看你的电脑配置了,
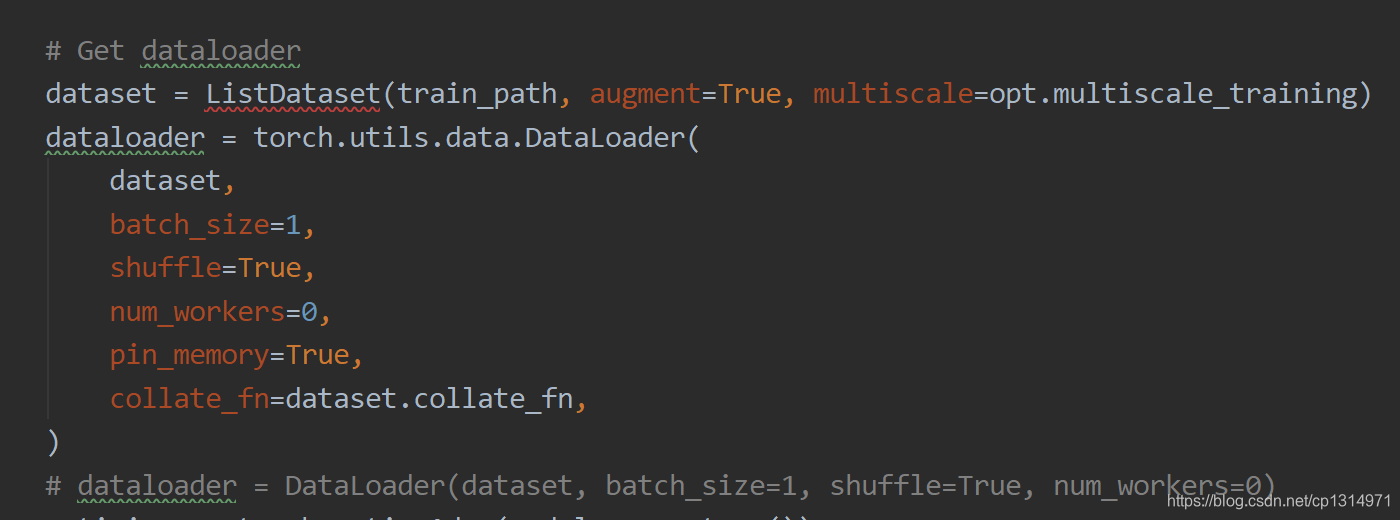
到目前为止,应该可以正常训练,如果不行,就是包的问题,

注意这里的tensorflow是cpu版本,cpu和gpu不能同时安装,主要是利用tensorboard,如果是这里有问题的话,可以将train.py利用tensorboard的代码全部注释掉,如下
自定义数据处理成custom格式
首先看下我下载数据

二个文件夹,一个放xml文件,一个是照片,
这里我们需要读取每一个xml文件来生成label,一个xml文件生成一个label,名字也是对应照片上的名字。这里还有一个小细节,就是在生成之前label,我们需要全部的分类,比如这里有五个分类目标,这五个分类目标是遍历每一个xml物体的名称,去掉重复的部分,就是分类了,这部分代码我没有展示,可以需要自己写(比较简单),下面放的这个代码是遍历全部的xml文件生成每一个对应的label,而且这里的框的位置是xywh形式。

生成lable的代码
import os,shutil import numpy as np import xml.etree.ElementTree as ET import os # 海胆 全息 扇贝 海星 海草 _classes = ('echinus', 'holothurian', 'scallop', 'starfish', 'waterweeds') from PIL import Image import torchvision.transforms as transforms _class_to_ind = dict(zip(_classes, range(5))) _ind_to_class = dict(zip(range(5), _classes)) a='E:\pytorch\JPEGImages/train/box/' e='E:\pytorch\JPEGImages/train/label/' d = 'E:\pytorch\JPEGImages/train/image/' b=os.listdir(a) xml = [] txt = [] img = [] for i in range(len(b)): xml.append(a + b[i]) path,filename = os.path.split(xml[i]) name = os.path.splitext(filename) txt.append(e+name[0]+'.txt') img.append(d+name[0]+'.jpg') for j in range(len(b)): xml_list = [] nn = [] d = img[j] image = transforms.ToTensor()(Image.open(d).convert('RGB')) _, height, weight = image.shape a = xml[j] tree = ET.parse(a) root = tree.getroot() for member in root.findall('object'): a = member[0].text b = _class_to_ind[a] value = (b, int(member[1][0].text), int(member[1][1].text), int(member[1][2].text), int(member[1][3].text) ) xml_list.append(value) for ii in range(len(xml_list)): tt = int(xml_list[ii][0]) x1 = float(xml_list[ii][1]) y1 = float(xml_list[ii][2]) x2 = float(xml_list[ii][3]) y2 = float(xml_list[ii][4]) x = ((x2+x1)/2)/weight y = ((y2+y1)/2)/height w = (x2-x1)/weight h = (y2-y1)/height x = round(x,8) y = round(y,8) w = round(w,8) h = round(h,8) sum = (tt,x,y,w,h) nn.append(sum) e = txt[j] file = open(e, 'w') for p in range(len(nn)): label = str(nn[p][0]) x = str(nn[p][1]) y = str(nn[p][2]) w = str(nn[p][3]) h = str(nn[p][4]) file.write(label + ' ') file.write(x + ' ') file.write(y + ' ') file.write(w + ' ') file.write(h + '\n') file.close()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
代码对应每一个不同的xml可能不同,主要是你需要学会读取xml文件的信息,在我之前的博客有讲解ET的使用。生成效果如下


这里边处理好全部的label了,还需要在整理二个txt文件保存路径即可,自己创建train.txt文件,保存训练照片的路径,在创建valid.txt保存验证数据集的路径,还需要穿件一个classes.names文件,保存类整体如下,对比custom还是很容易实现这一步的。

之后就是修改cfg文件了,一共有二个位置修改网络yolo3中的【yolo】层calsses修改自己分类和fitlers=3*(5+分类数)和创建custom.data用来数据集读取,具体如下之后再train.py再一次修改一下就可以了。

csv保存标签,重写dataset类
import os import glob import pandas as pd import xml.etree.ElementTree as ET _classes = ('echinus', 'holothurian', 'scallop', 'starfish', 'waterweeds') from PIL import Image import torchvision.transforms as transforms _class_to_ind = dict(zip(_classes, range(5))) _ind_to_class = dict(zip(range(5), _classes)) d = 'E:\pytorch\JPEGImages/train/image/' def xml_to_csv(path): xml_list = [] for xml_file in glob.glob(path + '/*.xml'): print(xml_file) path, filename = os.path.split(xml_file) name = os.path.splitext(filename) num = int(name[0]) img=(d + name[0] + '.jpg') image = transforms.ToTensor()(Image.open(img).convert('RGB')) _, height, weight = image.shape tree = ET.parse(xml_file) root = tree.getroot() for member in root.findall('object'): a = member[0].text classes = _class_to_ind[a] value = (num, img, weight, height, classes, int(member[1][0].text), int(member[1][1].text), int(member[1][2].text), int(member[1][3].text) ) xml_list.append(value) column_name = ['num','filename','width','height','class','xmin','ymin','xmax','ymax'] xml_df = pd.DataFrame(xml_list,columns=column_name) return xml_df def main(): image_path = os.path.join(os.getcwd(),'E:\pytorch\JPEGImages/train/box') xml_df = xml_to_csv(image_path) xml_df.to_csv('E:\pytorch\JPEGImages/train/labes2.csv',index=None) #带路径 'E://' print('finish') main()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
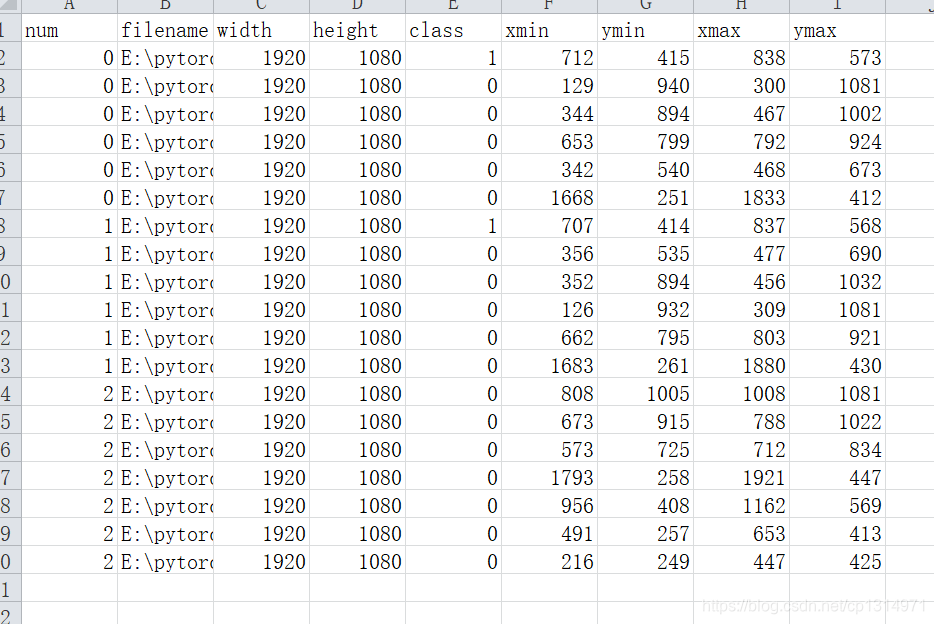
这一步是生成csv文件, 这里方便讲解就放了一点数据,如下图所示,我写num的目的是为了标记,比如全部是0的时候,说明这些信息全是一张照片的信息,一个照片可能有多个框,所以这里是为了一张照片的信息。
from PIL import Image import pandas as pd import numpy as np import torchvision.transforms as transforms from torch.utils.data import Dataset, DataLoader import torch import torch.nn.functional as F import random # 定义读取文件的格式 def pad_to_square(img, pad_value): c, h, w = img.shape dim_diff = np.abs(h - w) # (upper / left) padding and (lower / right) padding pad1, pad2 = dim_diff // 2, dim_diff - dim_diff // 2 # Determine padding pad = (0, 0, pad1, pad2) if h <= w else (pad1, pad2, 0, 0) # Add padding img = F.pad(img, pad, "constant", value=pad_value) return img, pad def resize(image, size): image = F.interpolate(image.unsqueeze(0), size=size, mode="nearest").squeeze(0) return image def random_resize(images, min_size=288, max_size=448): new_size = random.sample(list(range(min_size, max_size + 1, 32)), 1)[0] images = F.interpolate(images, size=new_size, mode="nearest") return images def horisontal_flip(images, targets): images = torch.flip(images, [-1]) targets[:, 2] = 1 - targets[:, 2] return images, targets class Mydataset(Dataset): def __init__(self,csv,transform=None, target_transform=None,): super(Mydataset,self).__init__() self.path = [] self.df=pd.read_csv(csv) for i in range(3): a = self.df[self.df['num'] == i] n = a['filename'].index[0] self.path.append(a['filename'][n]) self.transform = transform self.target_transform = target_transform def __getitem__(self, index): path=self.path[index] img = transforms.ToTensor()(Image.open(path).convert('RGB')) a = self.df[self.df['num'] == index] d = a.iloc[:, 4:9] e = np.array(d) targets = np.zeros((len(a), 6)) targets[:, 1:] = e img, pad = pad_to_square(img, 0) _, padded_h, padded_w = img.shape x1 = targets[:, 2] y1 = targets[:, 3] x2 = targets[:, 4] y2 = targets[:, 5] x1 += pad[0] y1 += pad[2] x2 += pad[1] y2 += pad[3] targets[:, 2] = ((x1 + x2) / 2) / padded_w targets[:, 3] = ((y1 + y2) / 2) / padded_h targets[:, 4] = (x2 - x1) / padded_w targets[:, 5] = (y2 - y1) / padded_h if np.random.random() < 0.5: img, targets = horisontal_flip(img, targets) return path,img,targets def collate_fn(self, batch): paths, imgs, targets = list(zip(*batch)) targets = [boxes for boxes in targets if boxes is not None] # Add sample index to targets for i, boxes in enumerate(targets): boxes[:, 0] = i targets = torch.cat(targets, 0) # Selects new image size every tenth batch if self.multiscale and self.batch_count % 10 == 0: self.img_size = random.choice(range(self.min_size, self.max_size + 1, 32)) # Resize images to input shape imgs = torch.stack([resize(img, self.img_size) for img in imgs]) self.batch_count += 1 return paths, imgs, targets def __len__(self): return len(self.path) val_data=Mydataset(csv='E:\pytorch\JPEGImages/train/22.csv', transform=transforms.ToTensor()) print(len(val_data)) trainloader = DataLoader(val_data, batch_size=1,shuffle=True, num_workers=0) for i,(p,img,e) in enumerate(trainloader): print(img.shape) print(e)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
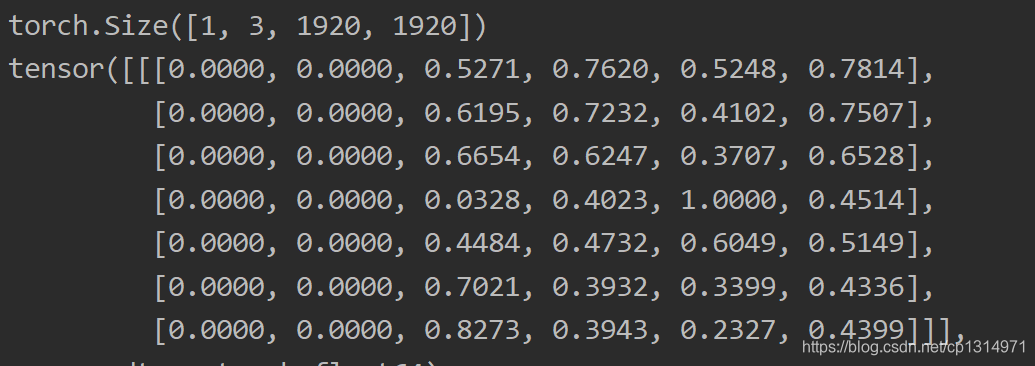
重写dataset的核心就是要让输出值有img和targets,代码细节不做过多讲解了,主要说明这里的 len(self):这个函数决定这__getitem__(self, index): index,这一步是读取csv文件的关键点。利用csv文件可以进行数据分析,比如各个大小形式的照片比例是多少,框的大小,都影响着yolo3的效果,


