
- 1开发者实战 | 在英特尔® 开发者套件上使用 OpenVINOSharp 部署 YOLOv8 模型
- 2Proxmox VE进行磁盘分区并配置NFS服务器实现文件共享_pve共享存储
- 3基于Java+Vue+uniapp微信小程序国产动漫论坛系统设计和实现_小程序论坛界面
- 4java可变参数(详解+代码样例)_java非基本数据类型怎么实现可变参数
- 5适用于yolov5单类检测的coco数据集制作及训练_yolov5只训练coco其中的一类
- 6Pytorch与Tensorflow2相互转换,函数记录(持续更新中......)_tensorflow和pytorch模型之间转换
- 7vivado sdk debug生成参数曲线_Vivado之ILA详解
- 8HikariCP连接池分析-重启数据源_hikari 连接池是开源
- 9Kali Linux 2022下载_kali linux下载
- 10vue+element实现非常好看的鲜花网站商城,页面完整,样式美观_elementui商城页面布局
聊聊大模型浪潮下的时间序列预测_timegpt
赞
踩
今天跟大家聊一聊大模型在时间序列预测中的应用。随着大模型在NLP领域的发展,越来越多的工作尝试将大模型应用到时间序列预测领域中。这篇文章介绍了大模型应用到时间序列预测的主要方法,并汇总了近期相关的一些工作,帮助大家理解大模型时代时间序列预测的研究方法。
技术交流群
建了技术答疑、交流群!想要进交流群、资料的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
方式①、添加微信号:mlc2060,备注:技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:技术交流

1
大模型时间序列预测方法
最近三个月涌现了很多大模型做时间序列预测的工作,基本可以分为2种类型。
第一种是直接用NLP的大模型做时间序列预测。这类方法中,使用GPT、Llama等NLP大模型进行时间序列预测,重点是如何将时间序列数据转换成适合大模型的输入数据。
第二种是训练时间序列领域的大模型。这类方法中,使用大量的时间序列数据集,联合训练一个时间序列领域的GPT或者Llama等大模型,并用于下游时间序列任务。
针对上述两类方法,下面给大家分别介绍几篇相关的经典大模型时间序列代表工作。
2
NLP大模型应用到时间序列
这类方法是最早出现的一批大模型时间序列预测工作。
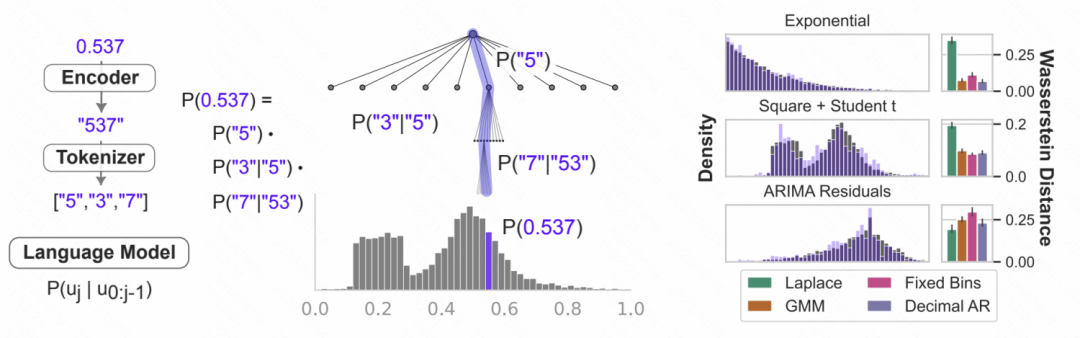
纽约大学和卡内基梅隆大学联合发表的文章_Large Language Models Are Zero-Shot Time Series Forecasters_中,对时间序列的数字表示进行了tokenize的设计,以此转换成GPT、LLaMa等大模型可以识别的输入。由于不同大模型对于数字的tokenize方式不一样,因此使用不同的大模型时,也需要个性化的进行处理。例如GPT会把一串数字分割成不同的子序列,影响模型学习,因此本文将数字之间强行加入一个空格来适配GPT的输入形式。而对于LLaMa等最近发布的大模型,一般对单独的数字都进行分割,因此不再需要加空格操作。同时,为了避免时间序列数值太大,使输入序列太长,文中进行了一些缩放操作,将原始时间序列的值限定在一个比较合理的范围内。
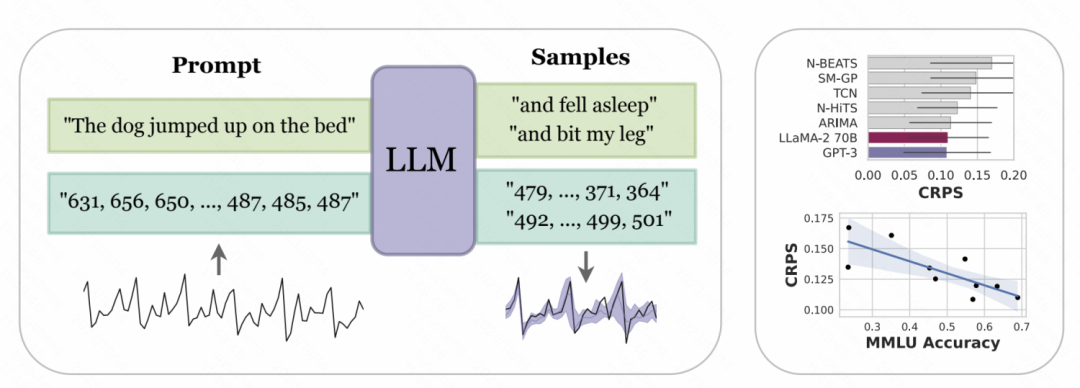
上述处理后的数字字符串,输入到大模型中,让大模型自回归的预测下一个数字,最后再将预测出的数字转换成相应的时间序列数值。下图中给出了一个示意图,利用语言模型的条件概率建模数字,就是根据前面的数字预测下一位为各个数字的概率,是一种迭代的层次softmax结构,加上大模型的表征能力,可以适配各种各样的分布类型,这也是大模型可以以这种方式用于时间序列预测的原因。同时,模型对于下一个数字预测的概率,也可以转换成对不确定性的预测,实现时间序列的不确定性预估。
另一篇文章**TIME-LLM: TIME SERIES FORECASTING BY REPROGRAMMING LARGE LANGUAGE MODELS**提出了一种reprogramming方法,将时间序列映射到文本,实现时间序列和文本这两种模态之间的对齐。
具体实现方法为,首先将时间序列分成多个patch,每个patch通过MLP得到一个embedding。然后,将patch embedding映射到语言模型中的词向量上,实现时间序列片段和文本的映射和跨模态对齐。文中提出了一种text prototype的思路,将多个词映射到一个prototype,以此来表示一段时间序列patch的语义。例如下图例子中,shot和up两个词映射到红色三角,对应时间序列中短期上升形式子序列的patch。

3
时间序列大模型
另一个研究思路是,借鉴NLP领域大模型的思路,直接构建一个时间序列预测领域的大模型。
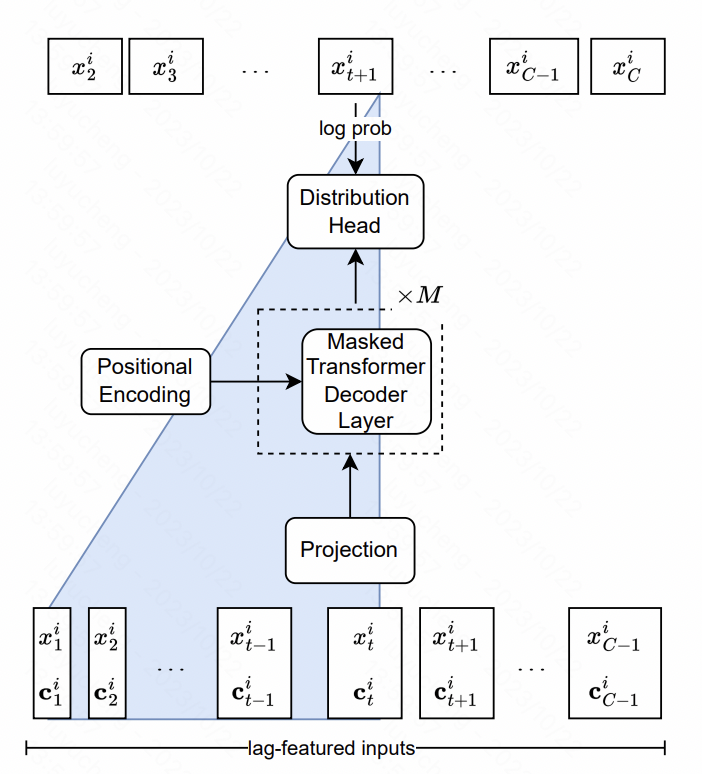
_Lag-Llama: Towards Foundation Models for Time Series Forecasting_这篇文章搭建了时间序列中的Llama模型。核心包括特征层面和模型结构层面的设计。
在特征方面,文中提取了多尺度多类型的lag feature,主要是原始时间序列不同时间窗口的历史序列统计值。这些序列作为额外的特征输入到模型中。在模型结构方面,NLP中的LlaMA结构,核心是Transformer,对其中的normalization方式和position encoding部分做了优化。最后的输出层,使用多个head拟合概率分布的参数,例如高斯分布就拟合均值方差,文中采用的是student-t分布,输出freedom、mean、scale三个对应参数,最后得到每个时间点的预测概率分布结果。
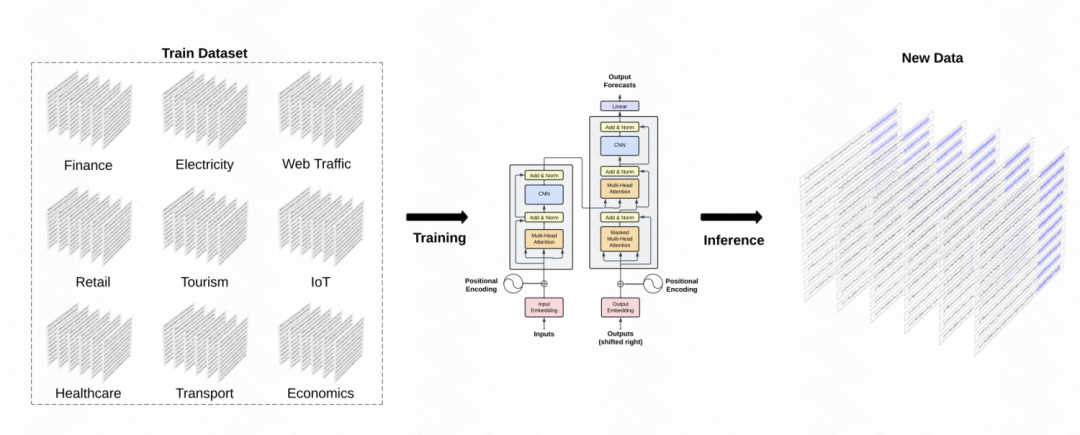
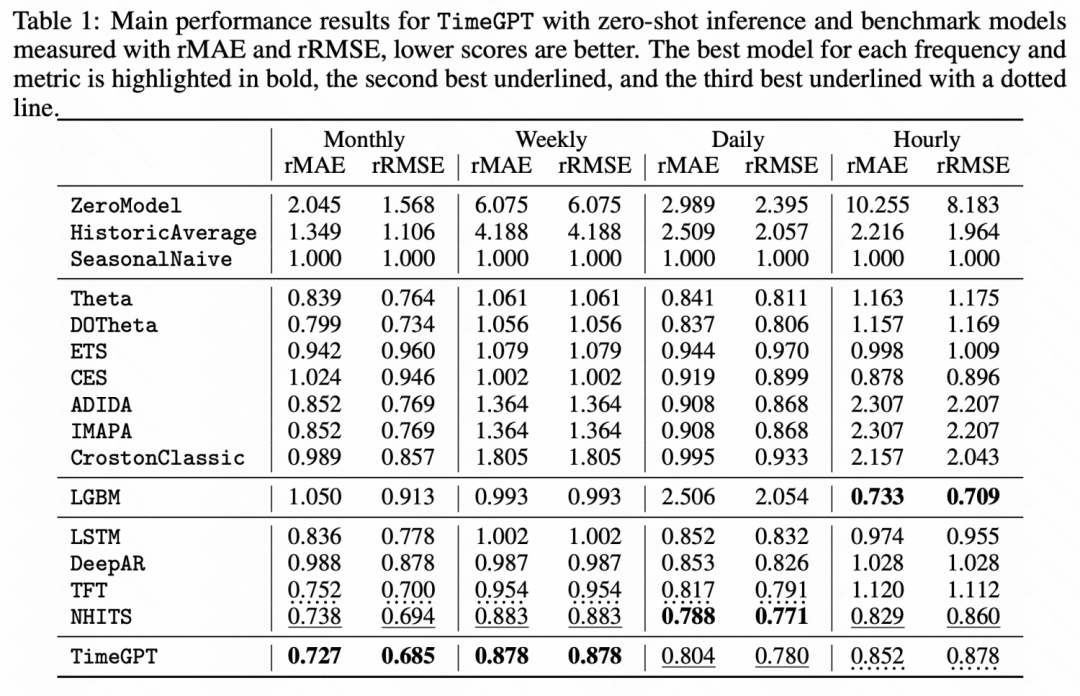
另一篇类似的工作是_TimeGPT-1_,构建了时间序列领域的GPT模型。在训练数据方面,TimeGPT应用了海量的时间序列数据,总计100billion的数据样本点,涉及多种类型的domain数据。在训练过程中,使用更大的batch size和更小的学习率来提升训练的鲁棒性。模型主体结构为经典的GPT模型。
通过下面的实验结果也可以看出,在一些零样本学习任务中,这种时间序列预训练大模型相比基础的模型都取得了显著的效果提升。
4
总结
这篇文章介绍了大模型浪潮下的时间序列预测研究思路,整体包括直接利用NLP大模型做时间序列预测,以及训练时间序列领域的大模型。无论哪种方法,都向我们展现了大模型+时间序列的潜力,是一个值得深入研究的方向。

