- 1解决:Microsoft Visual C++ 14.0 is required. Get it with “Microsoft Visual C++ Build Tools“
- 2TransReID | 首次将transformer应用于行人重识别
- 3基于matlab的汽车牌照识别程序详细教程_matleb写一个图像识别照片中汽车车牌的程序
- 4记录Ubuntu20.04安装、NVIDIA显卡驱动安装和cuda安装_nvidia ubuntu ai 20.04
- 5Win10 使用VMware等虚拟机启动虚拟机蓝屏报错SYSTEM_SERVICE_EXCEPTION解决方案_联想电脑安装虚拟机的时候报错 system service exception
- 6【炼丹手册】炼丹环境上等马之WSL2-Ubuntu20.04+CUDA11.3+cuDNN8.9.0.131-1+PyTorch1.20.0搭建手册+查tGPT API使用踩坑_wsl cuda 11.3 cudnn
- 7计算机毕业设计之java+springboot基于vue的社区医院管理服务系统_在internet高速发展的今天,我们生活的各个领域都涉及到计算机的应用,其中包括社区
- 8基于Springboot汽车租赁租车系统设计与实现 开题报告参考
- 9[LeetCode解题报告] 127. 单词接龙_单词接龙 最低时间复杂度
- 10Python练习题答案: 我更喜欢SQL ...【难度:2级】--景越Python编程实例训练营,1000道上机题等你来挑战_cur.executemany("insert into book(id,price,name) v
Python可视化在量化交易中的应用(17)_Seaborn核密度曲线图_sns.kdeplot 返回核密度数值
赞
踩
Seaborn中核密度图的绘制方法
seaborn中绘制核密度图使用的是sns.kdeplot()函数:
sns.kdeplot(x,y,shade,vertical,kernel,bw,gridsize=200,cut=3,clip,legend,cumulative,shade_lowest,cbar,cbar_ax,cbar_kws,ax,weights,hue,palette,hue_order,hue_norm,multiple=‘layer’,common_norm,common_grid,levels=10,thresh=0.05,bw_method=‘scott’,bw_adjust=1,log_scale,color,fill,data,data2,**kwargs,)
关键参数说明:
x:用于绘制核密度估计图的一维数据,可以是列表、数组或Series。
y:用于绘制二维核密度估计图的第二维数据,可以是列表、数组或Series。
shade:指定是否填充核密度曲线下的区域,默认为True。
vertical:指定是否绘制垂直核密度估计图,默认为False。
kernel:指定核函数的类型,默认为’gau’,即高斯核函数。
bw:指定核密度估计的带宽。可以是标量,也可以是一个字符串,用于选择自动确定带宽的方法。
gridsize:指定绘制核密度估计图时的网格大小,默认为200。
cut:指定在绘制二维核密度估计图时剪切数据的值,默认为3。
clip:指定是否对估计的密度进行裁剪,默认为False。
legend:指定是否显示图例,默认为False。
cumulative:指定是否绘制累积密度函数图,默认为False。
shade_lowest:指定是否填充最低密度区域,默认为False。
cbar:指定是否显示颜色条,默认为False。
cbar_ax:指定颜色条的轴对象。
cbar_kws:传递给颜色条绘图函数的其他关键字参数。
ax:指定绘图的轴对象。
weights:指定数据点的权重。
hue:用于对数据进行分组的变量名,根据该变量的不同取值,会以不同的颜色显示在图中。
palette:用于指定颜色调色板的名称或颜色列表。
hue_order:用于指定hue变量取值的顺序。
hue_norm:用于对hue变量进行归一化的对象。
multiple:指定多个核密度估计图的绘制方式,默认为’layer’,表示在同一轴上绘制多个核密度估计图。
common_norm:指定是否使用共同的密度估计规范,默认为False。
common_grid:指定是否使用共同的网格规范,默认为False。
levels:指定绘制等高线的数量,默认为10。
thresh:指定绘制等高线时的阈值,默认为0.05。
bw_method:指定带宽选择方法的名称或标量,默认为’scott’。
bw_adjust:指定带宽的调整因子,默认为1。
log_scale:指定是否使用对数刻度,默认为False。
color:指定绘图的颜色。
fill:指定是否填充核密度曲线下的区域,默认为True。
data:用于绘图的数据集,可以是DataFrame或数组。
data2:用于绘制二维核密度估计图的第二个数据集,可以是DataFrame或数组。
**kwargs:其他可选参数,用于传递给底层绘图函数。
案例展示:
使用seaborn绘制平安银行股票交易开盘价、收盘价、最高价、最低价的核密度图形。通过观察核密度图形,可以帮助投资者了解价格或收益等数据的分布情况,有助于了解数据的中心趋势、峰度和偏度等统计特征,以及是否存在异常值或离群点,为投资决策提供依据。
代码如下:
import numpy as np import pandas as pd import matplotlib.pyplot as plt from matplotlib.font_manager import FontProperties # 设置为默认字体 plt.rcParams['font.family'] = 'SimHei' # 显示负数 plt.rcParams['axes.unicode_minus'] = False # 导入数据 df = pd.read_excel("2023年一季度A股日线行情.xlsx") # 将日期列转化为日期格式 df["trade_date"] = df["trade_date"].astype("str").apply(lambda x:x[:4]+"-"+x[4:6]+"-"+x[6:]) # 将日期列转换为日期类型,并设置为索引列 df['trade_date'] = pd.to_datetime(df['trade_date']) df.set_index('trade_date', inplace=True) # 筛选2023年3月的行情数据 start_date = '2023-03-01' end_date = '2023-03-31' df = df.loc[start_date:end_date] # 筛选中国平安的3月股票交易数据 stock = df[df['ts_code']=='000001.SZ'] # 筛选出开盘价、收盘价、最高价、最低价 stock = stock[['open','close','high','low']] # 设置图形大小 fig, ax = plt.subplots(figsize=(10, 6)) # 绘制核密度曲线图 sns.kdeplot(data=stock, ax=ax, fill='coolwarm', shade=True) plt.xlabel('Price') # 设置y轴标签 plt.ylabel('Frequency') # 设置图标题 plt.title('Stock Price Fluctuation') # 显示图形 plt.show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
代码运行效果如下图所示:
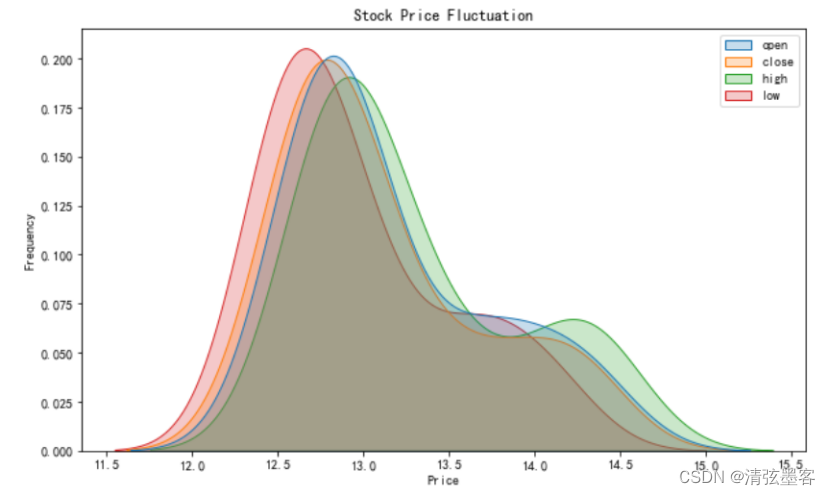
图5.3.9 开盘价、收盘价、最高价、最低价核密度图形展示
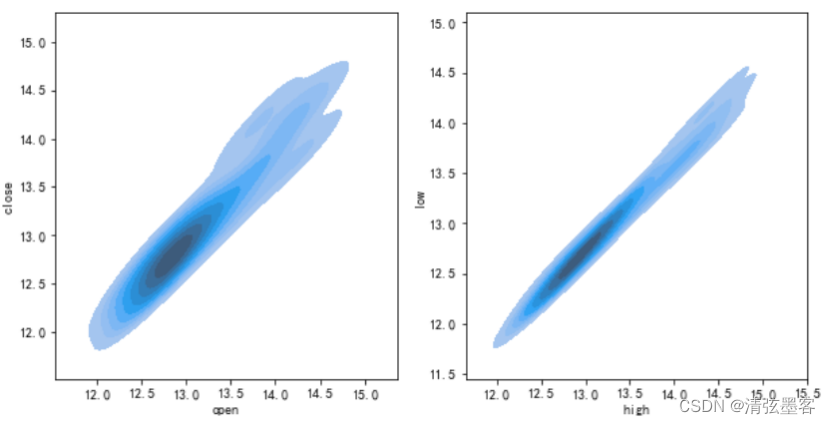
同时,我们也可以使用核密度图形观察特征值与特征值之间的分布情况,比如,可以分别观察开盘价与收盘价、最高价与最低价之间的关系。
在上述代码的基础上补充以下代码:
# 创建一个2x2的子图布局
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
# 使用Seaborn绘制等高线图
sns.kdeplot(stock['open'],stock['close'], shade=True,fill = True, ax = ax[0])
sns.kdeplot(stock['high'],stock['low'], shade=True,fill = True, ax = ax[1])
# 显示图形
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
代码运行效果如下图所示: