
- 1Pandas分组与排序_pandas分组排序
- 2苹果电脑批量生成准考证wps_wps批量制作准考证
- 3易语言tcp多线程服务端客户端_从TCP协议到TCP通信的各种异常现象和分析
- 4MySQL — 关联查询_mysql关联查询
- 5人工智能讲师咨询叶梓案例实战:人工智能在搜索引擎的应用目录信息自动抓取-2_智能咨询女
- 6【论文分享】基于微信小程序的快递取寄系统设计与实现_基于微信小程序的乡村快递代拿系统设计与实现
- 7劝人写码,千刀万剐——“前端已死”难道要成真了?
- 8PostgreSQL 中强大的全文搜索_postgresql 全文检索
- 9Centos的Filesystem中/dev/mapper/centos-root内存已满的解决办法_/dev/mapper/centos-root 满了
- 10MacBook IDEA 下载 安装 配置 使用_idea mac
图文解读:推荐算法架构——精排!
赞
踩

导语 | 精排是整个推荐算法中比较重要的一个模块,目前基本都是基于模型来实现,主要涉及样本、特征、模型三部分。本文将对其进行详细阐述,希望为更多的开发者提供经验和帮助。
一、整体架构
精排是整个推荐算法中比较重要的一个模块,目前基本都是基于模型来实现,涉及样本、特征、模型三部分。
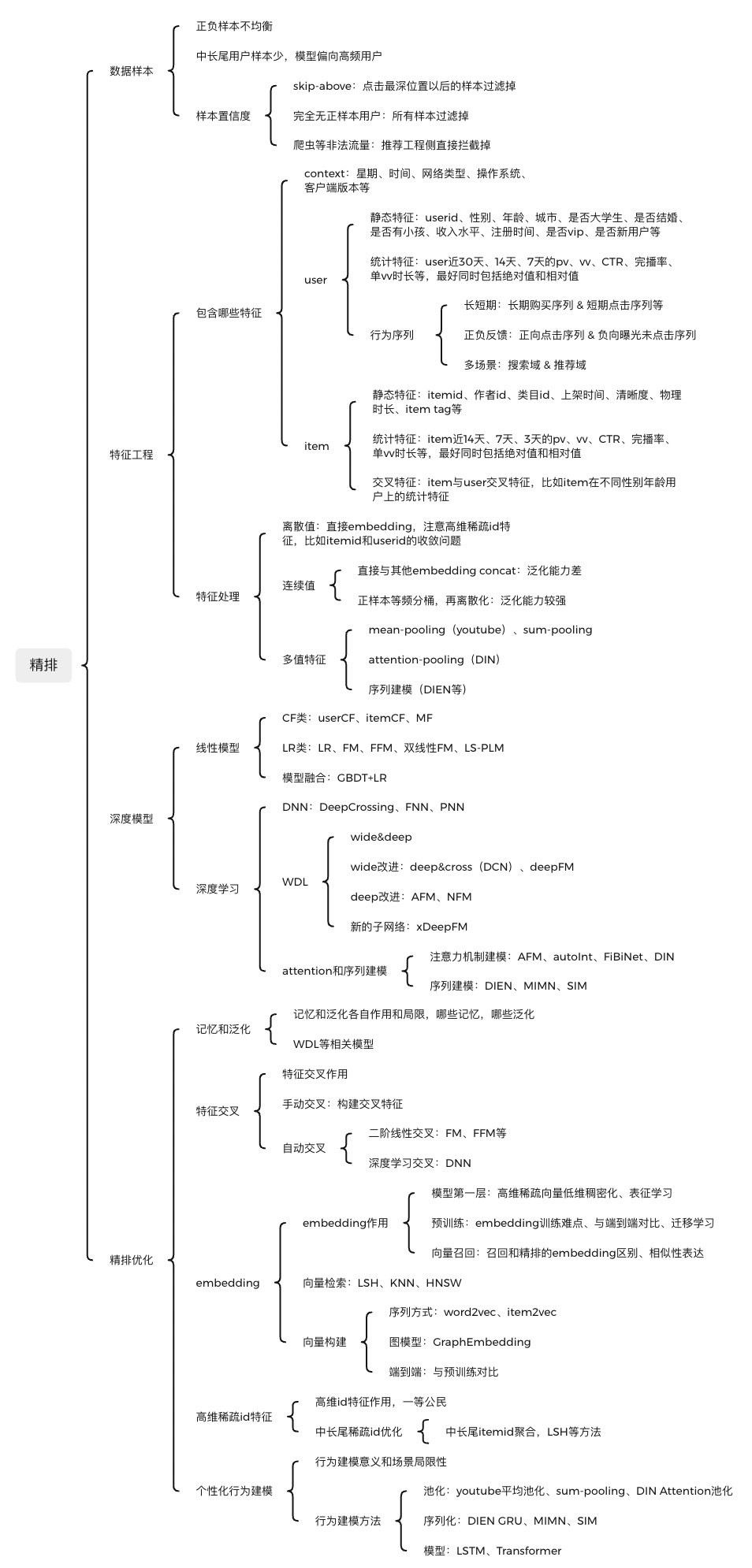
二、样本
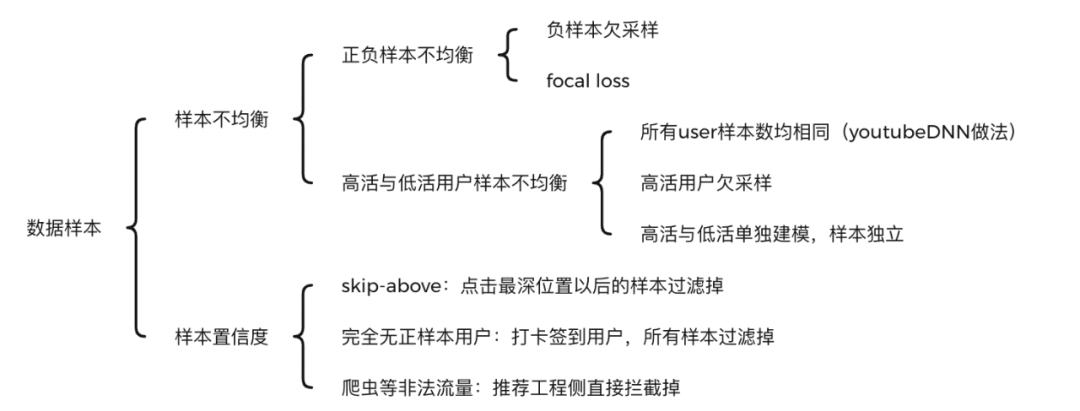
样本是模型的粮食,以CTR任务为例,一般用曝光点击作为正样本,曝光未点击作为负样本。样本方面主要问题有:
正负样本不均衡:比如CTR任务,如果点击率是5%,则正负样本1: 20,负样本远远多于正样本,导致样本不均衡。分类问题中样本不均衡,会导致模型整体偏向样本多的那个类别,导致其他类别不准确。解决方法主要有:
负采样:对负样本进行采样,可以直接采用随机负采样。一方面可以减少样本存储和模型训练的压力,另一方面可以缓解正负样本不均衡问题。但负样本其实也有很多信息的,直接丢弃实在可惜,特别是小场景样本不足的时候。
focal loss:何凯明老师在图像多分类样本不均衡中采用的方法,也可以使用到推荐场景中。通过减少负样本(易分类)在loss中的权重,使得模型更加专注于正样本(样本少,难分类)
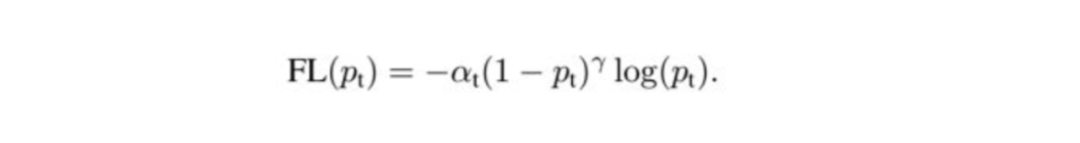
不同活跃度用户样本不均衡:中长尾用户样本少,高频用户样本多,最终模型容易偏向高频用户,从而在中长尾用户上预估越来越不准确。针对这一问题,可以对高频用户进行降采样,也可以对所有用户均采用相同的样本数(youtube做法)
样本置信度问题:曝光点击可以认为置信度较高,但曝光未点击就一定表名用户不会点击,一定是负样本吗?目前有以下集中情形:
用户完全没有正样本:用户如果只是为了签到,或者碰巧被push唤醒,抑或是随便点开了APP,完全没有正样本,全部是负样本。这个时候不点击只是用户此时意愿很差,跟你推的item是否符合他的兴趣关系不大。此时可以直接将该用户所有的负样本过滤掉。
爬虫等非法流量:推荐工程侧直接拦截掉。
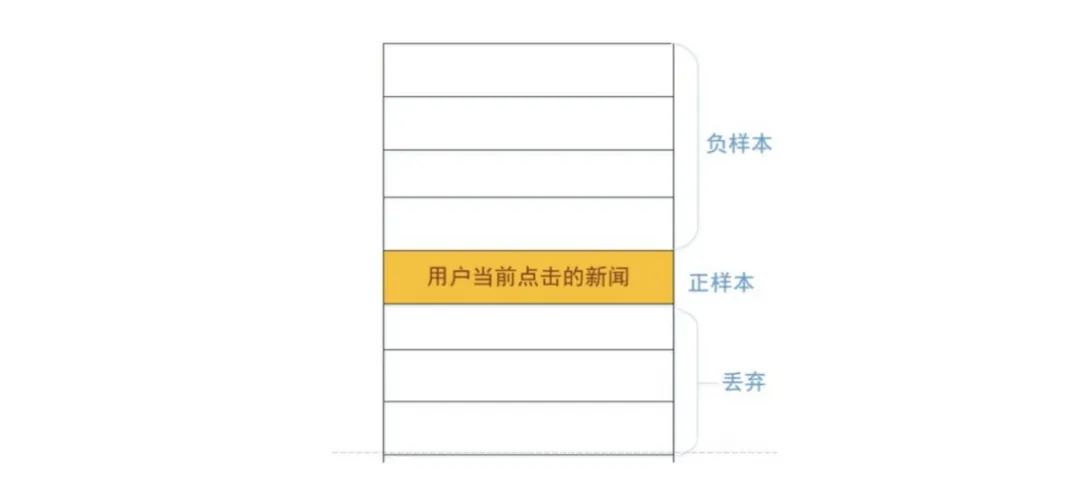
点击与否可能也与用户需求是否已经得到满足有关系。美团采用了skip-above采样方式,对用户最后一个点击位置以下的负样本,直接丢弃。
三、特征
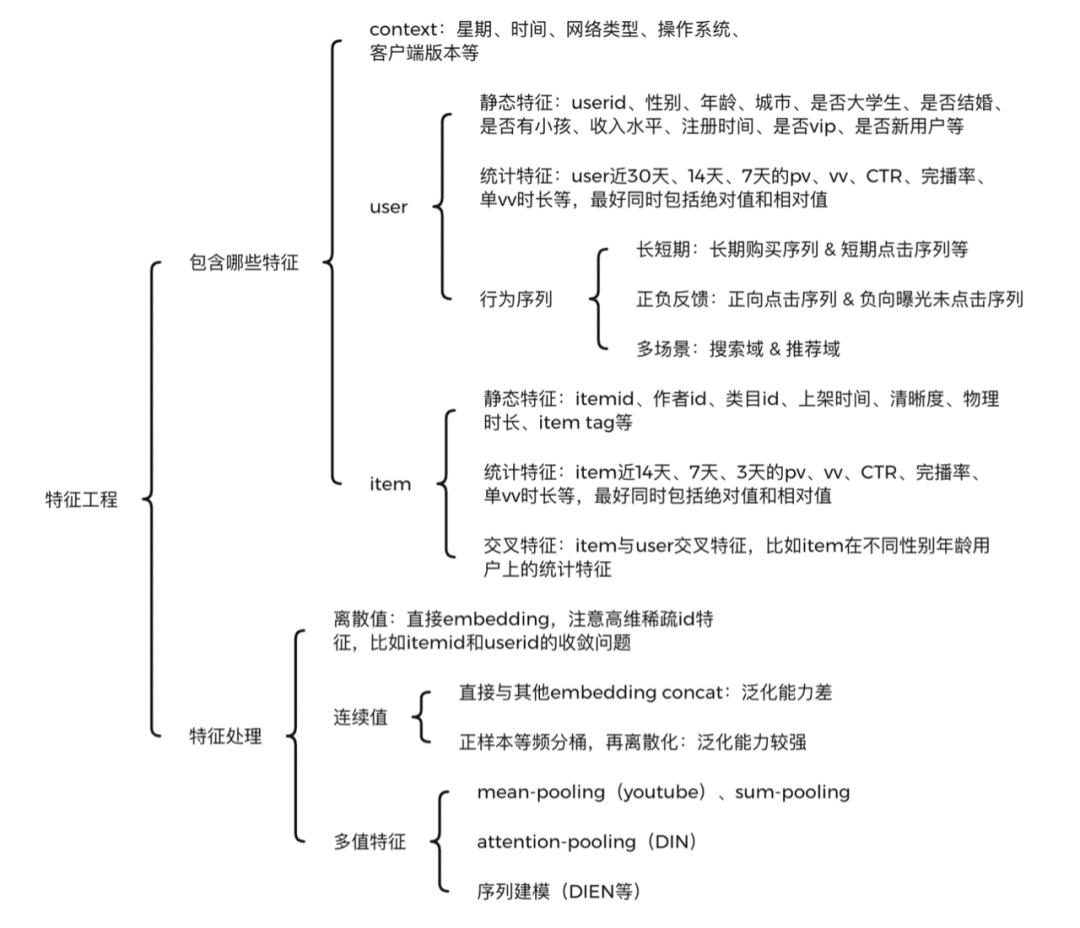
(一)主要有哪些特征
精排是特征的艺术,虽然特征工程远远没有深度模型那么fancy,但在实际业务中,基于特征工程优化,比基于模型更稳定可靠,且效果往往不比优化模型低。特征工程一定要结合业务理解,在具体业务场景上,想象自己就是一个实际用户,会有哪些特征对你是否点击、是否转化有比较大的影响。一般来说,可以枚举如下特征:
context特征:如星期、时间、网络类型、操作系统、客户端版本等。
user特征,也就是常说的用户画像,可以共享其他兄弟APP或者同一APP不同场景内的,用户各个维度的特征,主要包括三部分:
静态特征:userid、性别、年龄、城市、职业、收入水平、是否大学生、是否结婚、是否有小孩、注册时间、是否vip、是否新用户等。静态特征一般区分度还是挺大的,比如不同性别、年龄的人,兴趣会差异很大。再比如是否有小孩,会直接决定母婴类目商品是否有兴趣。
统计特征:比如user近30天、14天、7天的pv、vv、CTR、完播率、单vv时长等,最好同时包括绝对值和相对值。毕竟2次曝光1次点击,和200次曝光100次点击,CTR虽然相同,但其置信度天差地别。统计特征大多数都是后验特征,对模型predict帮助很大。统计特征一定要注意数据穿越问题,构造特征时千万不要把当天的统计数据也计算进去了。
行为序列特征:这一块目前研究很火,也是精排模型提升的关键。可以构建用户短期点击序列和长期购买序列,也可以构建用户正反馈点击购买序列和负反馈曝光未点击序列。序列长度目前是一个痛点,序列过长时,Transformer等模型计算量可能很大,导致模型RT和P99等指标扛不住,出现大量超时。
item特征,这一块不像用户画像容易兄弟APP共享,不同APP可能itemid等重要特征不能对齐,导致无法领域迁移。主要有如下特征:
静态特征:如itemid、作者id、类目id、上架时间、清晰度、物理时长、item tag等。这些特征一般由机器识别、人工打标、用户填写运营审核等方式产出,十分重要。
统计特征:如item近14天、7天、3天的pv、vv、CTR、完播率、单vv时长等,最好同时包括绝对值和相对值。跟user侧统计特征一样,要注意数据穿越问题。
交叉特征:item与user交叉特征,比如item在不同性别年龄用户上的统计特征。虽然模型可以实现自动特征交叉,但是否交叉得好就要另说了。手工构造关键的交叉特征,还是很有意义的。
(二)怎么处理特征
特征的处理主要有如下几种情况:
离散值:直接embedding,注意高维稀疏id特征,比如itemid和userid的收敛问题。
连续值:主要有两种方式:
直接与其他embedding concat:操作简单,但泛化能力差。
正样本等频分桶,再离散化:泛化能力较强,是目前通用的解决方案。
多值特征:最典型的就是用户行为序列,主要方法有:
mean-pooling(youtube)、sum-pooling:将行为序列中item特征,逐个进行mean-pooling或者sum-pooling,比如youtube的论文。这个方法十分粗糙,完全没有考虑序列中不同item对当前的打分,以及行为的时序转化关系。
att-pooling:将行为序列中各item,与待打分target item,进行attention计算再平均,也就是加权平均,比如DIN。这个方法考虑了item的重要程度,也支持引入item的重要side info,通过引入item index,其实也可以带有一定的时序信息,可以作为序列建模的baseline。
序列建模:将行为序列中各item,通过GRU等RNN模型,进行建模,取出最后一个位置的输出即可,比如DIEN。此方法考虑了用户行为的时序关系和兴趣迁移,目前基本都使用Transformer来进行时序建模,可以缓解反向传播梯度弥散、长序列建模能力差、串行耗时高等问题。
四、模型
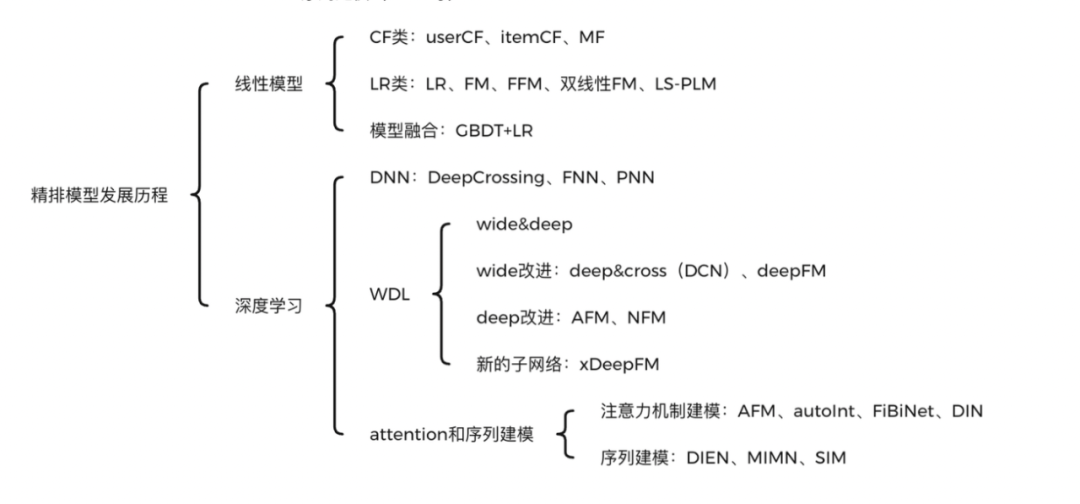
(一)精排模型发展历程——线性模型
精排模型从线性时代,已经完全步入深度学习时代。线性时代主要有三大类:
CF协同过滤类:比如userCF、itemCF、MF等。
LR逻辑回归类:LR、FM、FFM、双线性FM、LS-PLM等。
多模型融合类:GBDT+LR。
很多情况下我们不好收集用户的显式反馈信息,例如点赞点踩评论等,但隐式反馈信息,例如点击和转化,则较容易收集。协同过滤可以充分利用用户的行为,构建user与item的行为关系矩阵,矩阵的行向量即为user向量,列向量即为item向量。利用余弦相似度等计算方法,就可以找到相似的user和item,主要分为两类:
userCF:利用user向量,找到与当前user相似的其他user,再将他们感兴趣的item推荐给当前user。
itemCF:同理利用item向量,找到与当前user历史行为topK中的item相似的其他item,将它们推荐给当前用户。
二者使用的时候有什么区别呢,个人认为主要有:
userCF需要user行为较为丰富,itemCF则需要item被行为比较丰富。所以对于新闻类等item实时性要求高的场景,由于冷启item很多,所以可以考虑userCF。
一般来说用户量要远大于推荐池的item数量,也就是user向量远多于item向量,故userCF的存储压力和向量检索压力都要大于itemCF。同时也导致user向量远比item向量要稀疏,相似度计算准确性不如itemCF。
协同过滤有哪些缺点呢?
由于大部分user只对很少一部分item有行为,导致user与item的行为矩阵十分稀疏,甚至有些user根本没有任何行为,影响了向量相似度计算准确性。
user和item数量都很大,行为矩阵存储压力很大。
矩阵稀疏也带来一个问题,就是头部热门item容易与大多数item均相似,导致极其严重的马太效应。
那怎么解决这些问题呢,矩阵分解MF应运而生。它将user与item的行为矩阵,分解为user和item两个矩阵,M*N的矩阵转化为M*K和K*N的两个矩阵,user矩阵每一行就是一个K维user向量,item矩阵每一列就是一个K维item向量。由于不像CF中向量是基于行为产生的,有比较明确的含义,故MF中的向量也叫user隐向量和item隐向量。通过MF,可以解决CF向量过于稀疏的问题,同时由于K远小于M和N,使得高维稀疏向量实现了低维稠密化,大大减小了存储压力。
MF矩阵分解有哪些实现方法呢,可以基于SVD和梯度下降来计算。由于SVD有一定限制条件,基于梯度下降的比较多。因此MF也被称为model-based CF。
MF本质上仍然是基于用户行为来构建的,没有充分利用user和item的各种feature,比如用户性别年龄,导致有大量的信息丢失。LR和FM就应运而生。
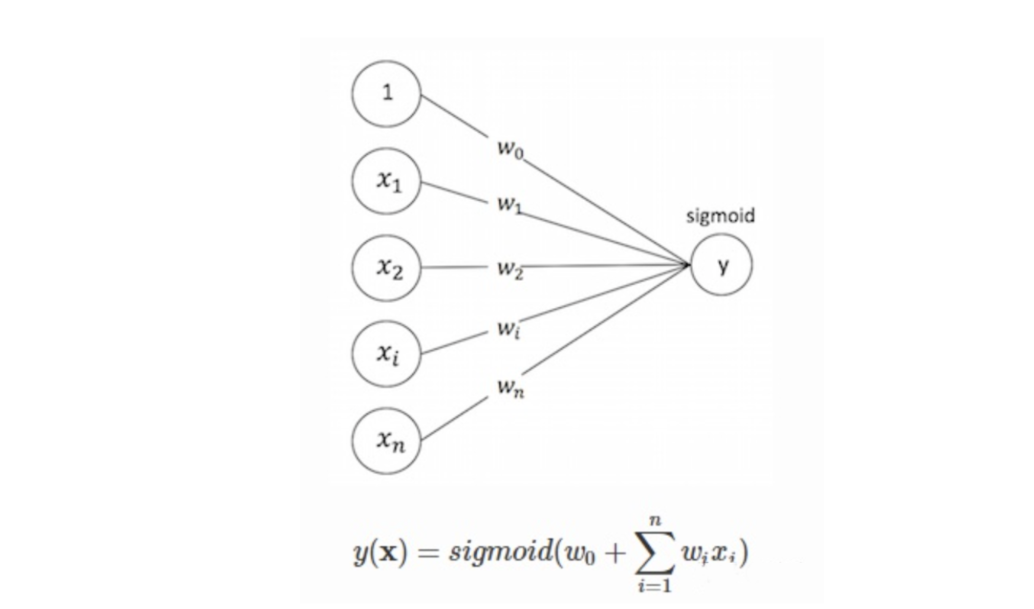
点击率和转化率预估问题,其本质仍然是一个分类问题,故完全可以采用经典的逻辑回归来解决。LR类方法的解决思路正是这样,与CF类不同,它将问题构建成一个有监督分类问题。同时可以利用use和item侧的丰富特征,表达能力比CF类要强。
LR各特征间无法交叉,因此对于辛普森悖论问题,没法得到有效解决,表达能力偏弱。FM因子分解机则应运而生。它增加了二阶特征交叉项,可以实现两个特征间的交叉。如下:

FFM则引入了field的概念,将n个特征归入f个filed内,同一个特征在不同的filed,其向量不同。相比FM,能够更好的捕捉每个域内的交叉特征。
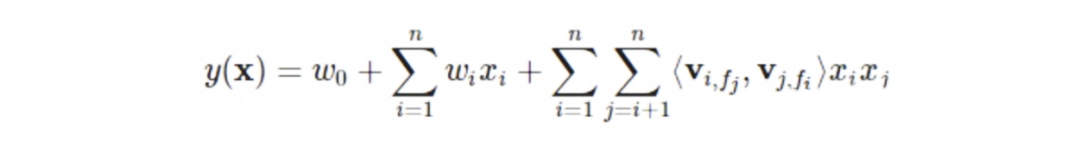
多模型融合在线性模型时代十分普遍,xgboost一度成为kaggle比赛的通用解决范式。三个臭皮匠顶个诸葛亮,利用多个模型可大大提升表达能力。model ensemble方法很多,这儿就不赘述了。我们提一下Facebook在2014年的解决方案:GBDT + LR。
GBDT梯度提升决策树,每一颗树都是拟合前一颗树和目标之间的loss,从而使得最终loss不断缩小。如下图所示:
(二)精排模型发展历程——深度模型
进入深度模型时代后,精排模型发展更为迅猛,借用王喆老师的一张图,如下:
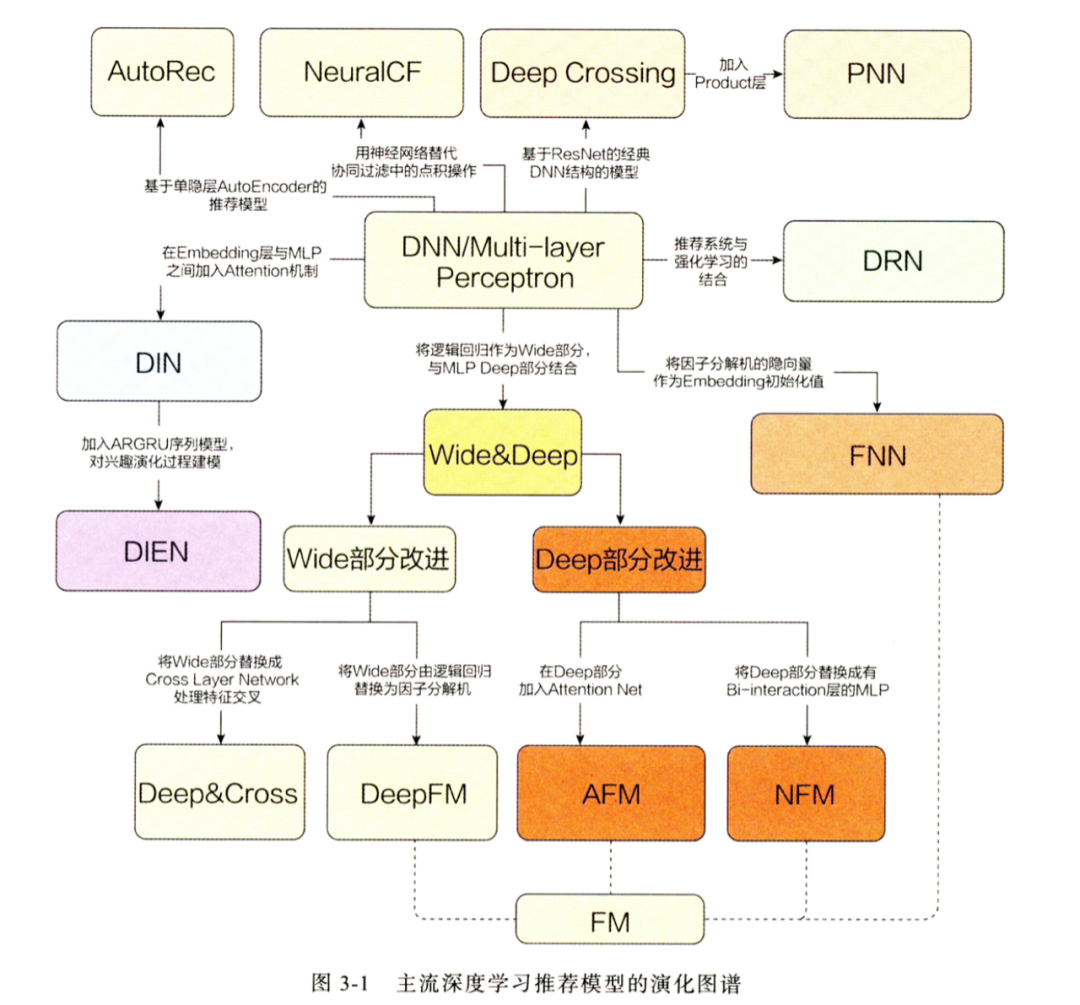
主要分为三种范式:
DNN类:DeepCrossing、FNN、PNN等
Wide&Deep异构模型类:优化记忆和泛化问题,主要包括四大类:
wide&deep:开启了异构模型时代,优化记忆和泛化问题。
wide侧改进:deep&cross(DCN)、deepFM等。
deep侧改进:AFM、NFM等。
加入新的子网络:xDeepFM等。
Attention和序列建模类:
注意力机制建模:AFM、autoInt、FiBiNet、DIN等。
序列建模:DIEN、MIMN、SIM等。
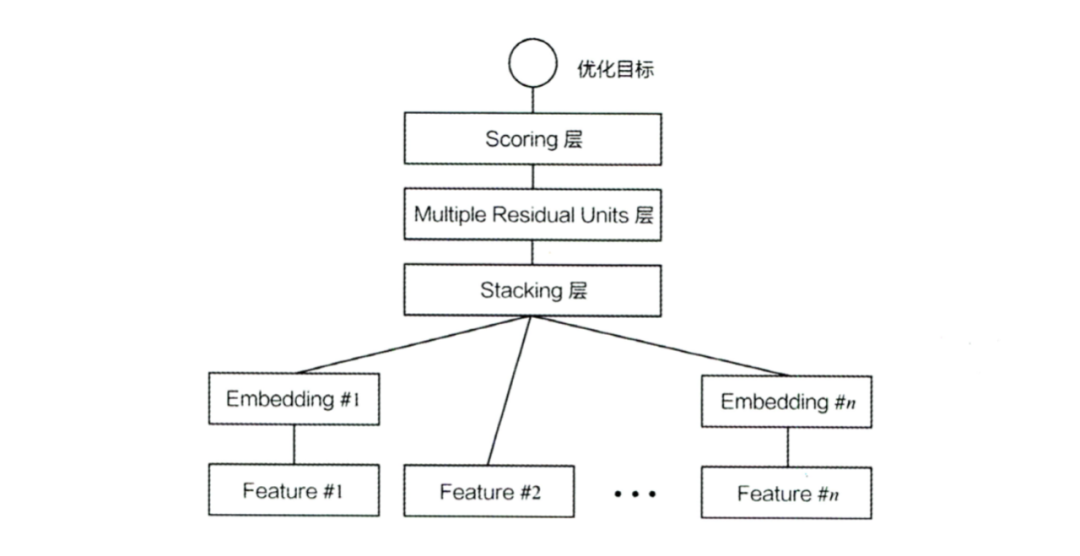
DeepCrossing
DeepCrossing是精排引入深度学习的一个关键模型,它奠定了深度学习精排模型的基本结构,完整解决了特征工程、embedding稀疏向量稠密化、多层神经网络拟合目标等关键问题。主要包括如下几层:
embedding层:将高维稀疏id特征,进行低维稠密化。对于非id类特征,则不进行embedding处理,直接进入下一层。
stacking层:把不同embedding和数值型特征,直接concat起来,进行特征融合。
DNN层:采用类似于ResNet的残差连接方式,构建了三层DNN,使用relu作为激活函数。利用DNN拟合能力强的优点,实现多特征交叉。FM只能实现二阶交叉,三阶则参数量爆炸,而DNN则可以做到高阶特征交叉。
输出层:分类问题的输出一般都是使用一个softmax,将logits转化为0~1之间,代表每个类别的概率,取概率大的则为最终的输出。也可以基于逻辑回归,将输出logits取sigmod,转化为0~1之间的概率。
loss采用交叉熵即可,利用SGD或者Adam等优化器,进行反向传播梯度下降训练模型。预测时走一遍predict即可。结构如下:
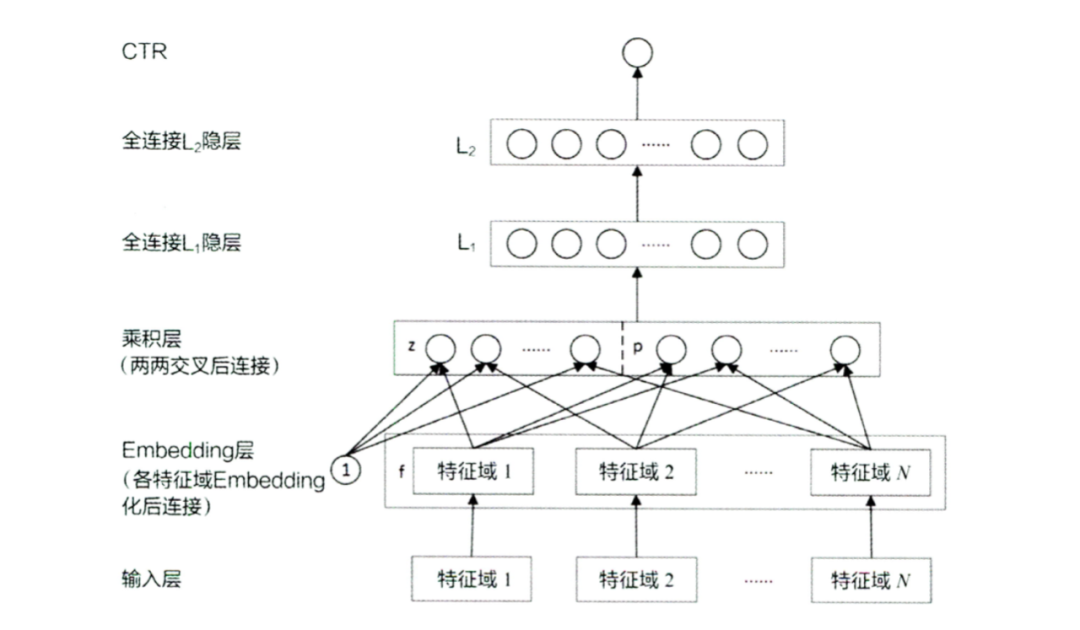
PNN
DeepCrossing的stacking层,直接将特征concat起来,表达能力偏弱。PNN认为进入DNN前,有必要先进行特征交叉,从而使得特征充分融合。它的stacking层除了一阶特征concat外,还有二阶特征交叉,然后再concat起来。特征交叉有内积和外积两种方法,分别为IPNN和OPNN。结构如下:
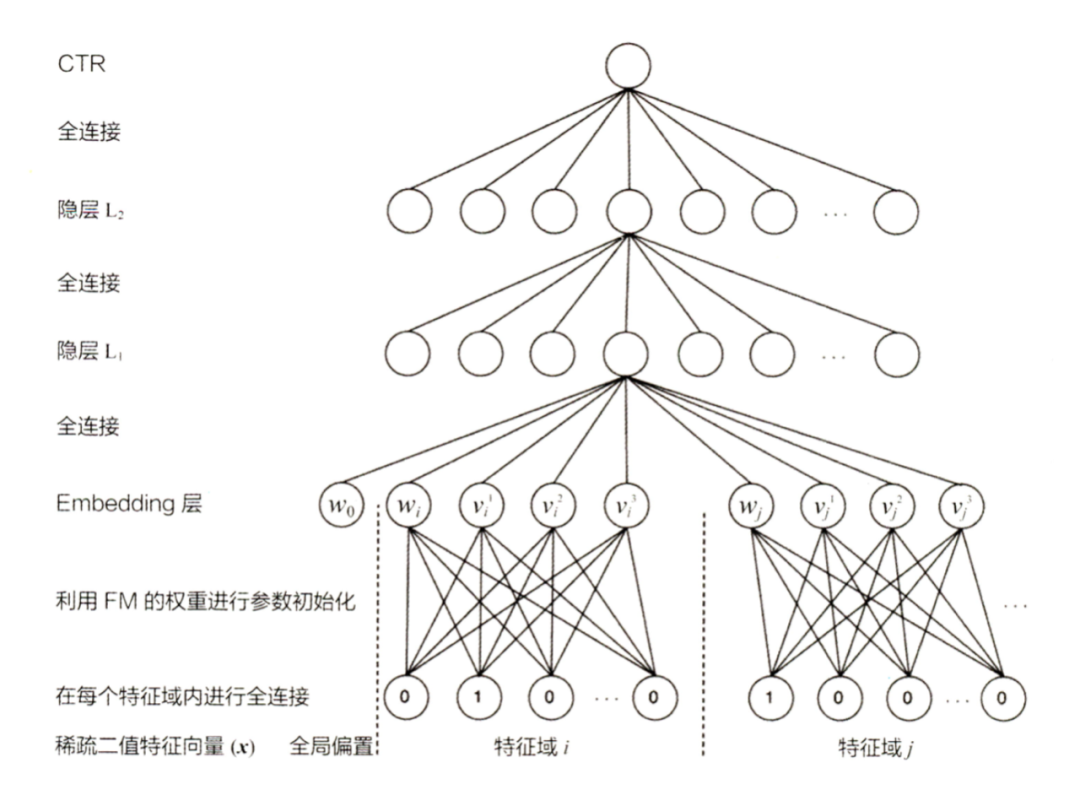
FNN
FNN则认为embedding层参数量很大,反向传播时只有该embedding有对应样本时才能得到更新,故收敛速度远低于DNN层,故可以先构建一个FM模型,然后利用各特征的embedding作为深度模型的初始化。记住FNN主要是通过FM来实现embedding初始化即可,它也是embedding预训练的一种方法。
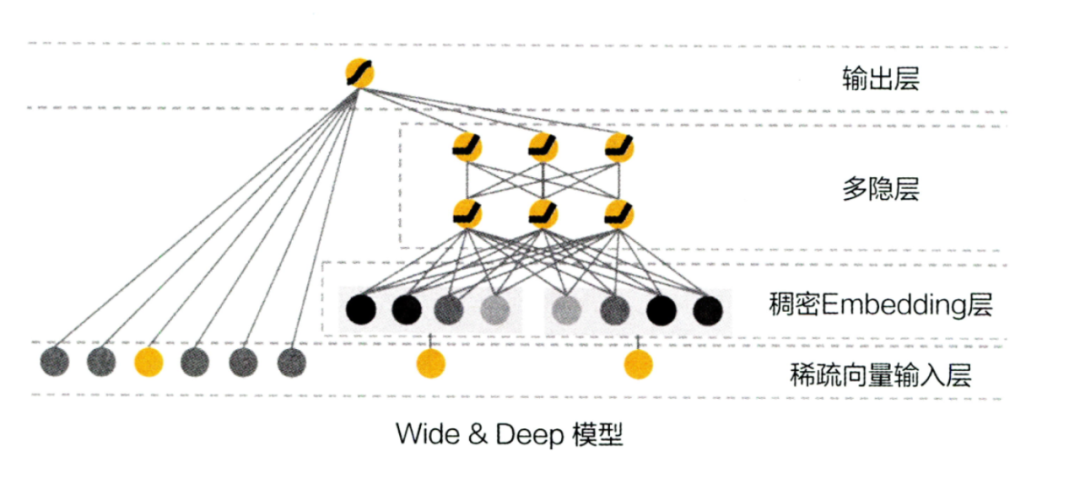
wide&deep
wide&deep是精排模型中一个里程碑式的模型,后续有各种模型都是对它的wide侧和deep侧进行改进。它主要是为了解决推荐系统中的记忆和泛化问题。也就是我们经常说的高频靠记忆,低频靠泛化。它结合了LR线性模型的记忆能力,和DNN深度模型的泛化能力,模型结构如下图:
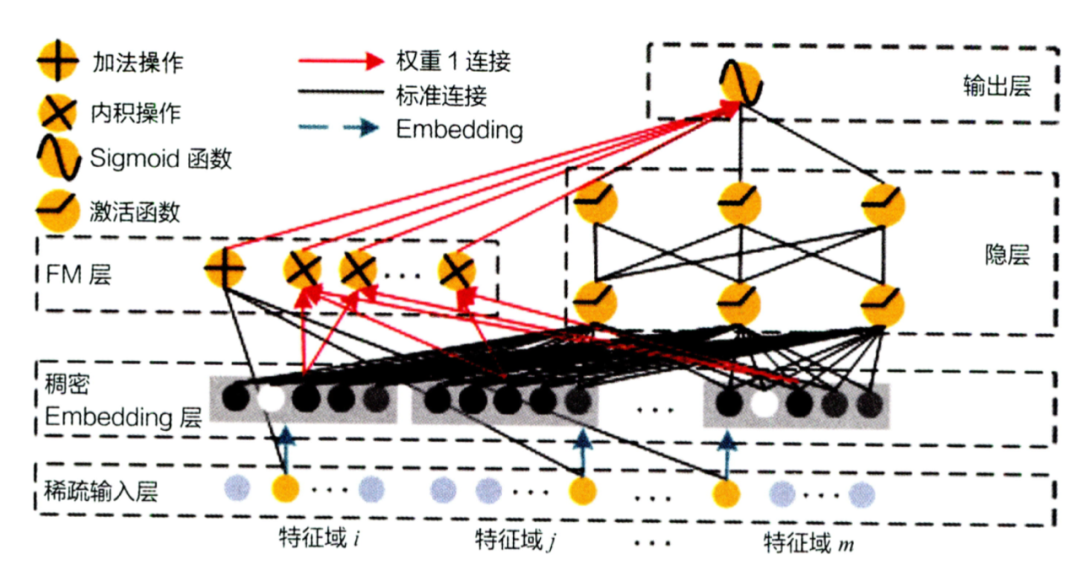
wide侧改进:DeepFM等
DeepFM则将wide部分的LR改为FM,从而增加二阶特征交叉能力,加强模型表达能力。结构如下:
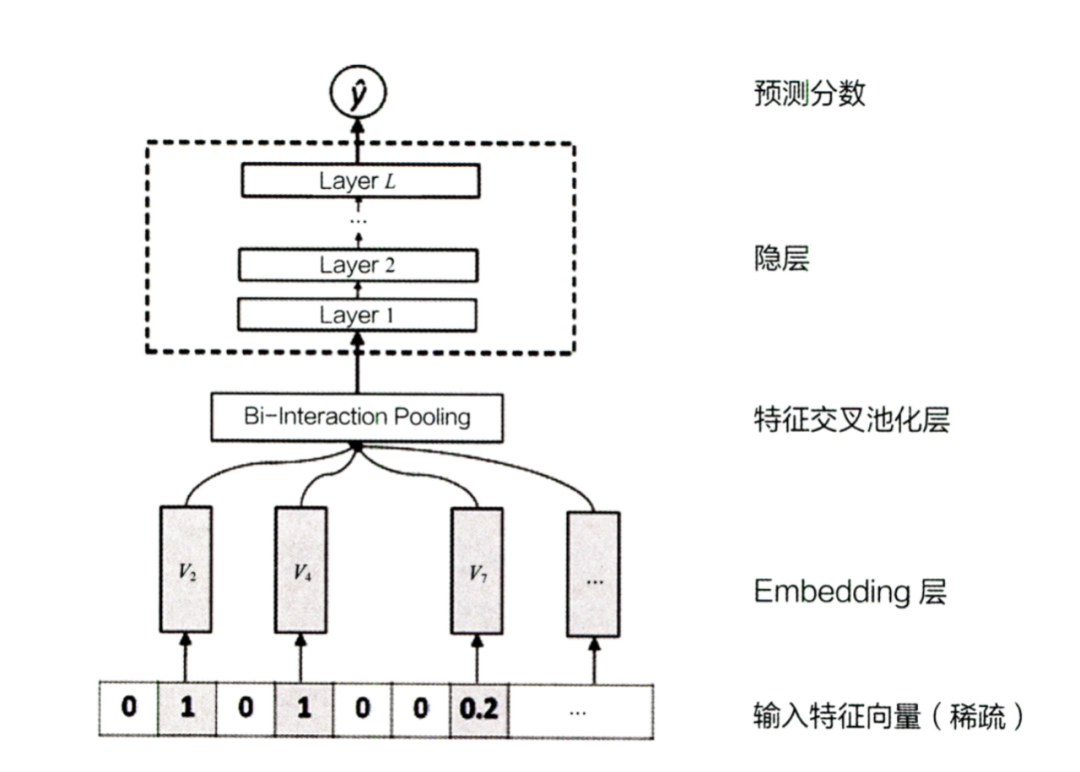
deep侧改进:NFM等
NFM则对WDL的deep部分进行了改进,它在embedding层和DNN层之间,加入了特征交叉池化层。对两个长度相同的embedding向量,进行相同位置元素内积操作再求和,从而得到池化层输出。通过加入特征交叉池化层,来增强deep部分特征交叉能力。
加入子分支:xDeepFM等
xDeepFM则在wide和deep两个分支基础上,新引入了一个分支CIN,具体就先不展开了,后面文章详细分析。如下图所示,注意新增了一个子分支CIN。
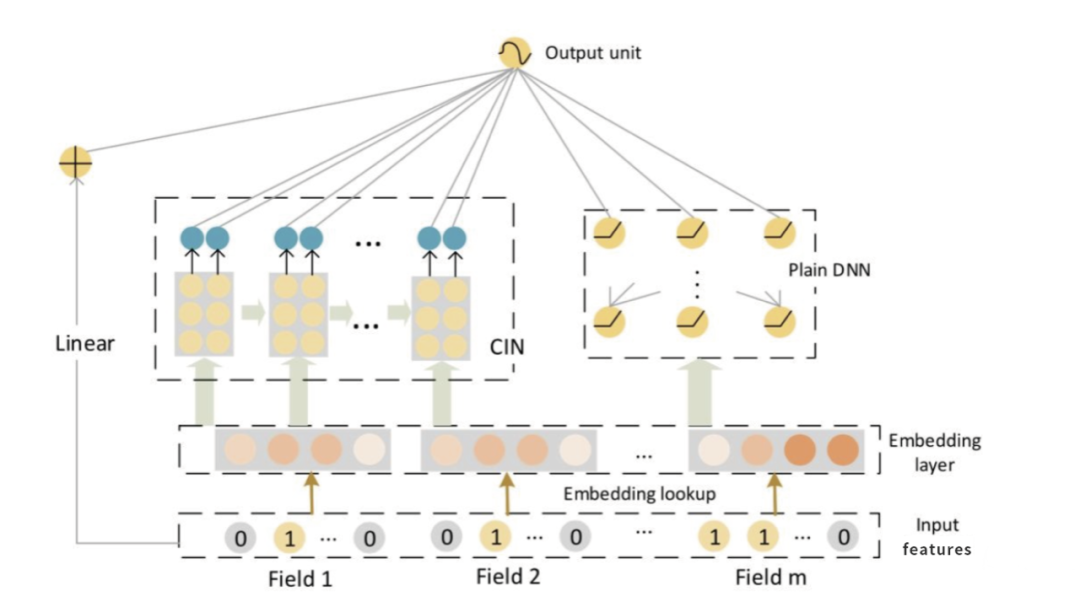
attention和序列建模都是解决多值特征的pooling问题的,最常见的多值特征就是用户行为序列,也是目前模型提升的关键。也使得精排模型融入了序列建模机制,是一个比较大的改变。
Attention:AFM、autoInt、FiBiNet、DIN等。
以DIN模型为例来讲解注意力机制的使用,用户行为序列中包括用户历史点击过的各种item,各个item与当前待打分item相关性不同,所以他们最最终模型打分的影响也不同。这个相关性怎么表达呢,这不就是Attention注意力吗。DIN对用户历史行为这个多值特征进行pooling建模,就采用了Attention加权求和的方法。
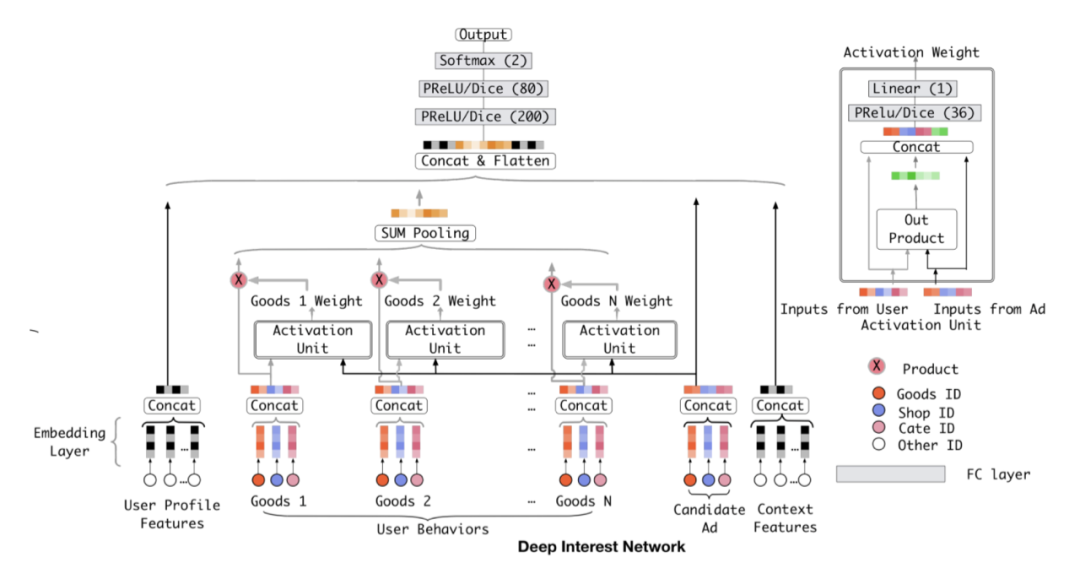
序列建模:DIEN等
DIN中对行为序列各item加入了注意力机制,能有效区分他们的重要性。但没有考虑item的时序关系,比如用户购买手机后,大概率会买手机壳和贴膜,反之则概率低,可见时序关系对用户兴趣迁移十分关键。理论上DIN中加入item的index信息作为side info后,也可以将时序信息带入。目前基本采用multi-head target attention进行用户行为序列建模,很少采用容易梯度弥散和串行计算延迟的LSTM或者GRU等RNN模型,但还是有必要讲一下DIEN等序列模型,有利于构建整体知识体系。DIEN的兴趣进化网络包含三层:
行为序列层(蓝色部分):id类特征进行embedding。
兴趣抽取层(黄色部分):利用GRU序列建模,抽取用户兴趣,每个position会有一个输出。
兴趣进化层(红色部分):加入注意力机制,与待打分item进行target attention,再利用GRU得到序列最后一个位置输出。
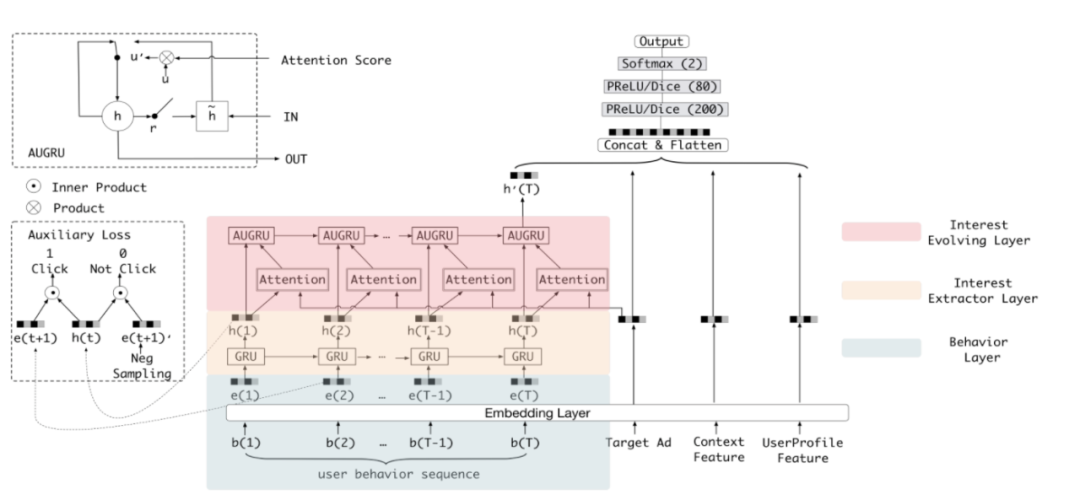
针对序列长度过大,导致的梯度弥散、存储压力、计算延迟问题,后续MIMN、SIM等模型进行了针对性优化,就不展开了。
五、精排优化
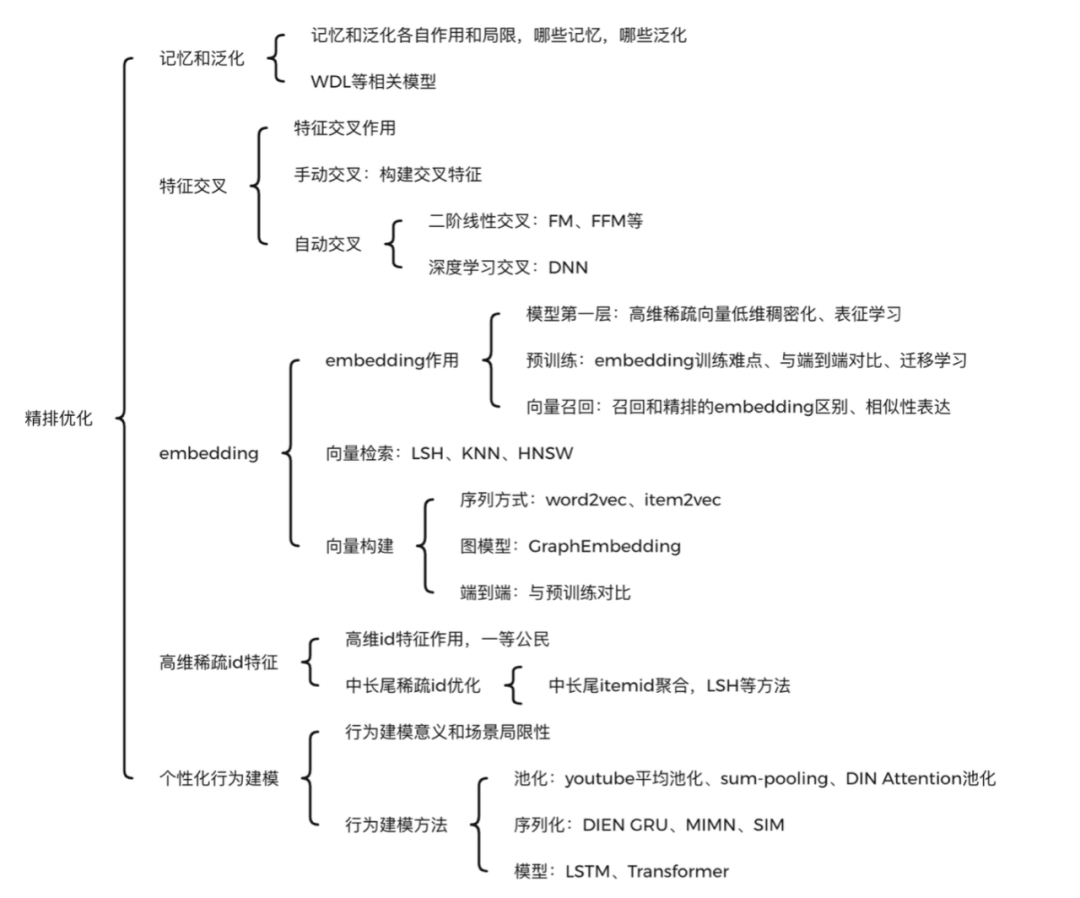
精排优化的方法和论文很多,一定要有一个全局架构认知,从而知晓每篇论文主要针对精排什么地方做的改进,类似的改进方案有哪些,各有什么优缺点。我认为万变不离其宗,主要就是五个方面的问题:
记忆和泛化:高频靠记忆,低频靠泛化,WDL类的异构模型主要就是为了解决这个问题。
特征交叉:包括手动交叉和自动交叉两类。特征工程中手动构造user和item交叉统计特征,就是手动交叉的典范,目前这种方法仍然使用很普遍。而自动交叉则可分为线性和深度模型两种。线性模型就是FM、FFM这种,深度模型则采用DNN进行特征交叉。
embedding:embedding实现了高维稀疏向量的低维稠密化,作为精排模型的第一层,已经成为了基本范式。
高维稀疏id特征:高维id特征区分度很大,对模型贡献高,但它们一般都比较稀疏,特别是中长尾的item和user样本少,加上其embedding维度高,比较难收敛。高维稀疏id特征的收敛问题也是一个待优化的关键问题。
个性化行为建模:基于用户历史行为进行个性化推荐,是目前推荐算法的一大热点。行为序列如何建模是一个关键问题,multi-head attention和序列模型给出了各自解决方案。同时序列过长会导致计算和存储压力很大,带来线上延迟,MIMN和SIM对这方面有一定优化。
作者简介

谢杨易
腾讯应用算法研究员
腾讯应用算法研究员,毕业于中国科学院,目前在腾讯负责视频推荐算法工作,有丰富的自然语言处理和搜索推荐算法经验。
推荐阅读


