
- 1mysql会话和事务_深入理解Mysql——锁、事务与并发控制
- 2Android 进阶——轻量级跨进程传递Message利器Messenger详解_android messenger
- 3Unity UGUI制作HUD Text
- 4关于前端主题切换的思考和现代前端样式的解决方案落地_css-vars-ponyfill
- 5Unity项目 - 简单时钟 Clock
- 6Unity 历史版本下载_unityloader.js 下载
- 7由UnityEngine.Object该怎么判空引发的一些思考_unity 判空 性能 gameobject
- 8qt creator 快速入门学习(5)_qt creator快速入门
- 9关于AssetBundle禁用TypeTree之后的一些可序列化的问题
- 10激活函数总结(六):ReLU系列激活函数补充(RReLU、CELU、ReLU6)_relu6激活函数的提出论文
浏览器指纹的介绍及应用_谷歌浏览器 指纹api
赞
踩
一,浏览器指纹介绍
在网站上浏览某个商品,了解了相关的商品信息,但并没有下单购买,甚至没有进行登录操作。过两天用同台电脑访问其他网站的时候却发现很多同类商品的广告。
在某博客中你有多个小号(水军),这些小号的存在就是为了刷某个帖子的热度或者进行舆论引导,又或者纯粹进行流量交易,即便你在切换账号的时候清空了cookie、本地缓存,重开路由器甚至使用vpn来进行操作,你觉得自己足够小心,并尽可能提高水军的真实性,但是管理人员可能还是知道这是同一个人在操作,从而被打击。
“浏览器指纹”是一种通过浏览器对网站可见的配置和设置信息来跟踪Web浏览器的方法,浏览器指纹就像我们人手上的指纹一样,具有个体辨识度,只不过现阶段浏览器指纹辨别的是浏览器。
人手上的指纹之所以具有唯一性,是因为每个指纹具有独特的纹路、这个纹路由凹凸的皮肤所形成。每个人指纹纹路的差异造就了其独一无二的特征。
那么浏览器指纹也是同理,获取浏览器具有辨识度的信息,进行一些计算得出一个值,那么这个值就是浏览器指纹。辨识度的信息可以是UA、时区、地理位置或者是你使用的语言等等,你所选取的信息决定了浏览器指纹的准确性。
对于网站而言,拿到浏览器指纹并没有实际价值,真正有价值的是这个浏览器指纹对应的用户信息。作为网站站长,收集用户浏览器指纹并记录用户的操作,是一个有价值的行为,特别是针对没有用户身份的场景。例如在一个内容分发网站上,用户A喜欢浏览二次元的内容,通过浏览器指纹记录这个兴趣,那么下次用户不需要登录即可向A用户推送二次元的信息。在个人PC如此普及的当下,这也是一种内容分发的方式。
对于用户而言,建立个人上网行为与浏览器指纹之间的联系或多或少都有侵犯用户隐私的意味,特别是将你的浏览器指纹和真实的用户信息相关联起来的时候。所幸的是这种方式对于用户的隐私侵犯比较有限、滥用用户行为也会透支用户对网站的好感。

二,浏览器指纹背景
浏览器指纹追踪技术到目前已经进入2.5代。
- 第一代是状态化的,主要集中在用户的cookie和evercookie上,需要用户登录才可以得到有效的信息。
- 第二代才有了浏览器指纹的概念,通过不断增加浏览器的特征值从而让用户更具有区分度,例如(UA、浏览器插件信息)
- 第三代是已经将目光放在人身上了,通过收集用户的行为、习惯来为用户建立特征值甚至模型,可以实现真正的追踪技术,这部分目前实现比较复杂,依然在探索中。
目前处于2.5代是因为现在需要解决的问题是如何解决跨浏览器识别指纹的问题上,稍后会介绍下这方面所取得的成果。
三,浏览器指纹采集
信息熵(entropy)是接收的每条消息中包含的信息的平均量,熵越高,则能传输越多的信息,熵越低,则意味着传输的信息越少。
浏览器指纹是由许多浏览器的特征信息综合起来的,其中特征值的信息熵也是不尽相同。
可以在这里(https://fingerprintjs.com/demo)查看自己的浏览器指纹ID和基本信息。

浏览器指纹也可以进行简单的分为普通指纹和高级指纹,普通指纹可以理解为容易被发现并且容易修改的部分,例如http的header
- {
- "headers": {
- "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
- "Accept-Encoding": "gzip, deflate, br",
- "Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
- "Host": "httpbin.org",
- "Sec-Fetch-Mode": "navigate",
- "Sec-Fetch-Site": "none",
- "Sec-Fetch-User": "?1",
- "Upgrade-Insecure-Requests": "1",
- "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
- }
- }
可以在这里(https://httpbin.org/headers)查看你的http头部信息。
在上面我们可以看到浏览器的Accept-Language、User-Agent,通过前者可以拿到浏览器的语言信息,这个http头部实体信息可能是通过你当前的操作系统语言,或者浏览器设置的语言信息所生成的。这个头部也不一定准确,一些网站会直接忽略掉这个头部,通过用户的ip判断地区再决定呈现网页的语言。
User-Agent包含了浏览器和操作系统的信息,例如我当前使用的是MacOS,并且使用77版本的chrome。假如在头部刻意伪造了UA,网页也可以通过navigator.userAgent来拿到真实的UA。
其他的基本信息,例如ip,物理地址、地理位置等也可以拿到:

可以在这里(https://www.whatismybrowser.com/)可以查看自己浏览器的基本信息。
除开从http中拿到的指纹,也可以通过其他方式拿到浏览器的特性信息,在(https://panopticlick.eff.org/about)这篇文档中就陈列了一些可行的特征值
- 每个浏览器的用户代理字符串
- 浏览器发送的HTTP ACCEPT标头
- 屏幕分辨率和色彩深度
- 系统设置为时区
- 浏览器中安装的浏览器扩展/插件,例如Quicktime,Flash,Java或Acrobat,以及这些插件的版本
- 计算机上安装的字体,由Flash或Java报告。
- 浏览器是否执行JavaScript脚本
- 浏览器是否能种下各种cookie和“超级cookie(super cookies)”
- 通过Canvas指纹生成的图像的哈希
- WebGL指纹生成的图像的哈希
- 是否浏览器设置为“Do Not Track”
- 系统平台(例如Win32,Linux x86)
- 系统语言(例如,cn,en-US)
- 浏览器是否支持触摸屏
拿到这些值后可以进行一些运算,得到浏览器指纹具体的信息熵以及浏览器的uuid。计算方式(https://www.eff.org/deeplinks/2010/01/primer-information-theory-and-privacy)。
下图是数个特征值的信息熵、重复概率和具体的值:

将上面的指纹信息综合起来,可以大大降低碰撞率,提高客户端uuid的准确性。指纹的也有权重之分,某些信息熵较大的特征值会有的更大的权重:
| Variable | Entropy(bits) |
|---|---|
| user agent | 10.0 |
| plugins | 15.4 |
| fonts | 13.9 |
| video | 4.83 |
| supercookies | 6.09 |
| timezone | 3.04 |
| cookies enabled | 0.353 |
普通指纹描述的信息依然不够独特,毕竟在深圳使用MacOS的人依然非常非常多。高级指纹可以将这个范围进一步缩小,几乎可以直接确定一个独一无二的浏览器身份。
Canvas指纹
Canvas是HTML5中的动态绘图标签,也可以用它生成图片或者处理图片。即便使用Canvas绘制相同的元素,但是由于系统的差别,字体渲染引擎不同,对抗锯齿、次像素渲染等算法也不同,canvas将同样的文字转成图片,得到的结果也是不同的。流程如下

具体代码实现为:
- function getCanvasFingerprint () {
- var canvas = document.getElementById("anchor-uuid");
- var context = canvas.getContext("2d");
- context.font = "18pt Arial";
- context.textBaseline = "top";
- context.fillText("Hello, user.", 2, 2);
- return canvas.toDataURL("image/jpeg");
- }
在画布上渲染一些文字,再用toDataURL转换出来,即便开启了隐私模式一样可以相同的值

可以在这里(https://browserleaks.com/canvas)测试一下你canvas指纹。从下面的报告中Uniqueness中看到在47万份数据中,只有两个人的canvas指纹和我的相同。

AudioContex指纹
AudioContext指纹和Canvas类似也是基于硬件设备或者软件的差别,来产生不同的音频输出,然后计算得到不同的hash来作为标志,当然这里的音频并没有直接在浏览器中播放出来,只需要拿到播放前的处理数据就行,音频指纹测试地址:https://audiofingerprint.openwpm.com/
WebRTC
WebRTC(网页实时通信,Web Real Time Communication),是可以让浏览器有音视频实时通信的能力,它提供了三个主要的API来让JS可以实时获取和交换音视频数据,MediaStream、RTCPeerConnection和RTCDataChannel。当然如果要使用WebRTC获得通信能力,用户的真实ip就得暴露出来(NAT穿透),所以RTCPeerConnection就提供了这样的API,直接使用JS就可以拿到用户的IP地址。
跨浏览器指纹
综上提到的浏览器指纹都是从同一个浏览器上获得。但是很多特征值都是不稳定的,例如UA、canvas指纹在相同设备的不同浏览器打开会完全不一样。同一套浏览器指纹算法在不同浏览器(本小结所说的不同浏览器是指同一台设备上的不同浏览器)上也就不可用了。
跨浏览器指纹就是即便是在不同浏览器上也可以取得相同或者近似值的稳定浏览器特征。
跨浏览器指纹也有对应的研究成果
这篇paper中列了一个这样的表
列举了浏览器特征值的在单浏览器和跨浏览器的信息熵以及稳定性,上诉说到的canvas指纹稳定性仅有8.17%。
常规的特征值很难满足在信息量足够的情况下还保持高稳定性。
挑选几个表中符合这些特征的值Task(a)~Task(r)、List of fonts(JS)、TimeZone和CPU Vritual cores、
Task(a)~Task(r),它是一种显卡渲染(Rendering Tasks)图片的特征值。例如Task(a)Texture,它是测试常规 片段着色器中的纹理功能,通过渲染一个随机的三基色值的像素,片段着色器需要在纹理中插入点,以便将纹理映射到模型上的每个点,这个插入算法在不同的显卡又是不一致的。如果纹理变化较大,那么差异也就越明显,我们可以通过记录这种差异来为这个显卡作出区分度。
List of fonts(JS),通过js获取页面支持的字体情况。获取页面支持的字体分为两种方式,Flash和JS,现在Flash渐渐退出了舞台就不考虑它了。List of fonts是值通过js拿到页面支持的字体情况以及如何绘制字体,是通过测量不同字体的文本HTML元素的填充尺寸,来和其他设备做区分。
TimeZone,时区,这个比较好理解,既然是同一台设备那么时区应该也是一致的。
CUP Vritual cores即为CPU的内核数量,最简单的方法就是通过一个navigator.hardwareConcurrency来拿到。

尽管在低版本浏览器是不支持这个API的,但也可以通过这个polyfill拿到。实现原理大致为借用Web Worker的能力,监听payload的时间,计算量达到硬件最大并发的时候就可以得到内核的数量(有点硬核)。
如何防范
如果你没有足够专业的知识或者非常频繁更换浏览器信息的话,几乎100%可以通过浏览器指纹定位到一个用户,当然这也不见得全是坏事。
- 泄露的隐私非常片面,只能说泄露了用户部分浏览网页时的行为。
- 价值不够,用户行为并未将实际的账户或者具体的人对应起来,产生的价值有限。
- 有益利用,利用浏览器指纹可以隔离部分黑产用户,防止刷票或者部分恶意行为。
但是即便如此,浏览器指纹也有一些可以防止的措施。
Do Not Track
在http头部可以声明这样一个标志“DNT”意味“Do Not Track”,如果值为1表示为不要追踪我的网页行为,0则为可以追踪。即便没有cookie也可以通过这个标志符告诉服务器我不想被追踪到,不要记录我的行为。
不好的消息是大多数网站目前并没有遵守这个约定,完全忽略了“Do Not Track”这个信号。
EFF提供了这样一个工具Privacy Badger,它是一个浏览器插件形式的广告拦截器,对于那些遵守这个约定的公司会在这个广告拦截器的白名单上,允许显示广告,从而激励更多的公司遵守“Do Not Track”,以便完全展示广告。
个人觉得这一个方向很不错的做法,如果用户使用这个工具,网站在拿用户行为之前会抉择两边的利益,从而减轻用户对于隐私泄露的风险。
Privacy Badger的更多信息可以在这里(https://www.eff.org/privacybadger)查看。
Tor Browser
通过上述我们对浏览器指纹的了解,不难发现,如果你浏览器的特征越多,越容易被追踪到。相反如果你想要刻意将某些浏览器特征隐藏或者进行魔改,那么恭喜你,你的浏览器可能就拥有了一个独一无二的浏览器指纹,都不需要刻意去计算,直接就可以将你和其他用户区分开。
所以有效的方法是尽量将特征值进行大众化,例如目前市面最广泛的搭配是Window 10 + Chrome,那么你将UA改为这个组合就是一个有效的方法,同时尽量避免网站获取信息熵非常高的特征值,例如canvas指纹。
Tor 浏览器在这上面做了很多工作,以防止它们被用来跟踪Tor用户,为了响应Panopticlick和其他指纹识别实验,Tor浏览器现在包含一些补丁程序,以防止字体指纹(通过限制网站可以使用的字体)和Canvas指纹(通过检测对HTML5 Canvas对象的读取并要求用户批准)来防止,例如上面获取Canvas指纹的代码,在Tor上会弹出如下警告
同时还可以将Tor浏览器配置为主动阻止JavaScript。
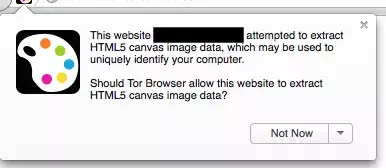
综上所述,这些措施使Tor浏览器成为抵抗指纹的强大防御工具。但是这样有安全感的浏览器牺牲的是它的速度,使用Tor浏览器访问页面会比市面的浏览器慢得多。感兴趣的同学可以尝试一下Tor Browser
禁用JS
这是一个比较暴力的方法,直接禁止网站使用JavaScript可以非常有效地防御浏览器指纹追踪,但是这样会导致页面较大部分地功能不可用。
而且非常不幸的是,即便禁止了JS但是还可以通过CSS来采取浏览器的信息,例如:
- @media(device-width: 1080px) {
- body {
- background: url("https://example.org/1080.png");
- }
- }
可以在服务器中看1080.png图片的请求日志,就可以得知哪些用户的屏幕是1080px的, 在 Mozilla Firefox 中,甚至曾经存在过可以直接查询 Windows 系统版本和 Windows 主题的 CSS 查询。现在这个问题已经被修复了(https://bugzilla.mozilla.org/show_bug.cgi?id=1396066)。
此处推荐篇论文,其指纹模型目前能够达到99%的识别率
https://nanshihui.github.io/public/crossbrowsertracking_NDSS17.pdf
文章最上方有中文翻译版

