
热门标签
热门文章
- 1C#语言的基础知识
- 2搭建QGroundControl编译环境_qgc编译
- 3CentOS7 下安装 iSCSI Target(tgt) ,使用 Ceph rbd
- 4mq系列传感器的程序_【STM32Cube_10】使用ADC读取气体传感器数据(MQ-2)
- 5TypeScript到ArkTS的适配规则_function return type inference is limited (arkts-n
- 6angularJS添加事件监听_angular 给所有的a标签添加监听事件
- 7iOS 可变参数宏__VA_ARGS___ios开发 __va_args__
- 8.NetCore项目nginx发布_.net core nginx
- 9数据仓库hive的安装说明
- 10STM32CUBEMX-读写内部Flash_stm32cubemx flash
当前位置: article > 正文
SaulLM-7B: A pioneering Large Language Model for Law
作者:我家小花儿 | 2024-03-11 15:51:24
赞
踩
SaulLM-7B: A pioneering Large Language Model for Law
SaulLM-7B: A pioneering Large Language Model for Law
相关链接:arxiv
关键字:Large Language Model、Legal Domain、SaulLM-7B、Instructional Fine-tuning、Legal Corpora
摘要
本文中,我们介绍了SaulLM-7B,这是为法律领域量身打造的大型语言模型(LLM)。SaulLM-7B拥有70亿参数,是第一个专门为了理解和生成法律文本而设计的LLM。它是基于Mistral 7B架构,并在超过300亿的英语法律语料上训练优化。SaulLM-7B在理解和处理法律文件方面表现出了前沿的专业能力。此外,我们提出了一种新颖的指导性微调方法,利用法律数据集进一步提高了SaulLM-7B在法律任务中的表现。SaulLM-7B在MIT许可下被释放。
核心方法
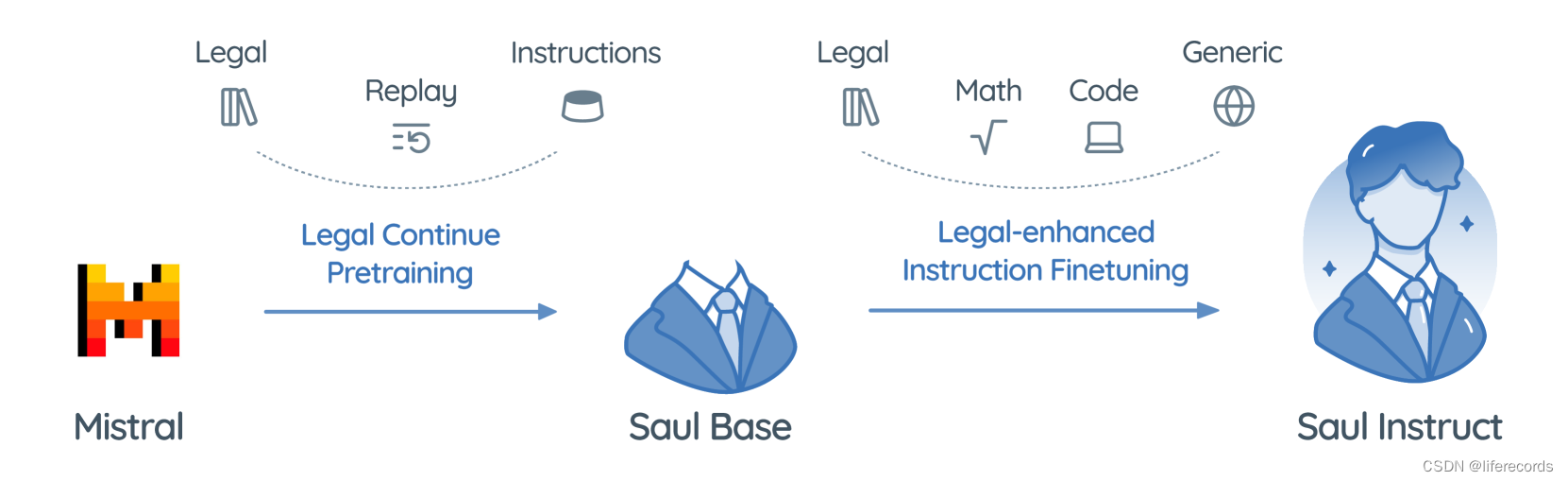
- 基于法律语料的大规模预训练: 累积了从美国、加拿大、英国和欧洲等英语法律区域的扩展预训练数据集,主要包括了案例文件、法律规则等不同类型的法律文档。
- 指导性微调(Instructional Fine-tuning): 利用法律数据集和合成数据集对模型进行特定法律任务的微调,以提升对法律语境更敏感的理解能力。
- 专注法律实践者的需求: 强化了对法律实践中常见问题类型的识别和解答能力,比如案件分析、法规回溯、解释、修辞理解和法规结论。
- SaulLM-7B-Instruct版本的发布: 发布了一个指令微调版的模型SaulLM-7B-Instruct,特别优化了对一系列法律任务的表现。
实验说明
实验结果主要包括以下几个部分:
| Model | LegalBench-Instruct | MMLU-Jurisprudence | MMLU-Professional Law | MMLU-International Law |
|---|---|---|---|---|
| SaulLM-7B-Instruct | 0.61 | 0.63 | 0.69 | 0.41 |
| Mistral-7B-Instruct-v0.1 | 0.55 | 0.60 | 0.65 | 0.38 |
| Mistral-7B-Instruct-v0.2 | 0.52 | - | - | - |
| Llama2-13B-chat | 0.45 | - | - | - |
| Zephyr | 0.44 | - | - | - |
| Llama2-7B-chat | 0.39 | - | - | - |
重点说明:
- SaulLM-7B-Instruct在LegalBench-Instruct基准测试中达到了最佳性能,显示出在法律领域的强大适应性。
- 在MMLU的法律相关任务上,SaulLM-7B-Instruct也展现出相较于其他模型更优的性能。
- 总结来看,SaulLM-7B-Instruct在法律领域的表现卓越,为法律语言理解和应用研究贡献了重要力量。
结论
我们介绍的SaulLM-7B是针对法律领域设计的开源解码器模型,其性能在7B类模型中达到了领先水平。我们的方法包括将法律数据与指令微调相结合进行训练。此外,我们还提供了LegalBench的清洗版本,并引入了一个新的文件集来衡量复杂度。我们希望我们在MIT许可下发布的模型能够为开源生态系统和社区做出贡献。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/219724
推荐阅读
相关标签

