
- 1Nginx详细教程_nginx教程
- 2[ADAS预研笔记]算力计算方法研究_dmips和tops换算
- 3VI/VIM下如何搜索字符串_vim 搜索字符串
- 4python--字典集合控制流
- 5【验证码逆向专栏】某度滑块、点选、旋转验证码 v1、v2 逆向分析
- 6macOS Sonoma 14.3.1 (23D60) 正式版发布,ISO、IPSW、PKG 下载
- 7小程序navigateback传值_微信小程序 页面跳转传递值几种方法详解
- 8向量数据库王冠易主!零一万物新成果登顶权威榜单,比前SOTA领先最高286%
- 9中南大学计算机学院竞赛,计算机学院成功举办第十届“三十佳”教学竞赛选拔赛...
- 10flex布局文本居中,文本溢出自动换行的方法_flex 文字换行
XML配置文件
赞
踩
XML配置文件
1、XML 概述
XML 是一种可扩展的标记语言,使用<>标签对括起来,XML 技术是 W3C 组织发布的
XML 结构清晰,是树状结构,可以用来描述层级关系之间的数据,一般作为配置文件的存在,用来传输数据
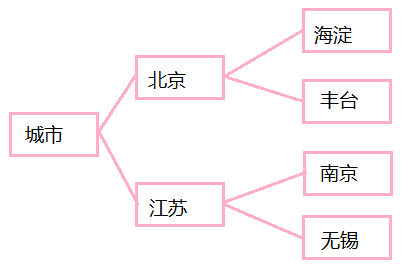
XML 语言出现的根本目的在于描述像上图那种有关系的数据。
XML是一种通用的数据交换格式
在XML语言中,它允许用户自定义标签。
一个标签用于描述一段数据,一个标签可分为开始标签和结束标签,在起始标签之间,又可以使用其他标签描述其他数据,以此来实现数据关系的描述。
XML中的数据必须通过软件程序来解析执行或显示,如 E,这样的解析程序称之为 Parse(解析器)
2、XML常见应用
- XML的出现解决了程序间数据传输的问题:
比如QQ之间的数据传送,用XML格式来传送数据,具有良好的可读性,可维护性
- XML可以做配置文件
XML文件做配置文件可以说非常普遍,比如我们的 Tomcat 服务器的server.xml,web.xml。
再比如我们的 structs 中的structs-config.xml文件,和 hibernate 的hibernate.cfg.xml等等。
- XML可以充当小型的数据库
XML 文件可以做小型数据库,也是不错的选择。
我们程序中可能用到一些经常要人工配置的数据,如果放在数据库中读取不合适(因为这会增加维护数据库的工作),则可以考虑直接用XML来做小型数据库。这种方式直接读取文件显然要比读数据库快。比如msn中保存用户聊天记录就是用XML文件。
- 入门案例:用 XML 来记录一个班级信息。
<?xml version="1.0" encoding="gb2312"?>
<class>
<stu id="001">
<name>杨过</name>
<sex>男</sex>
<age>20</age>
</stu>
<stu id="002">
<name>小龙女</name>
<sex>女</sex>
<age>21</age>
</stu>
</class>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
我们可以用浏览器打开,进行校验:
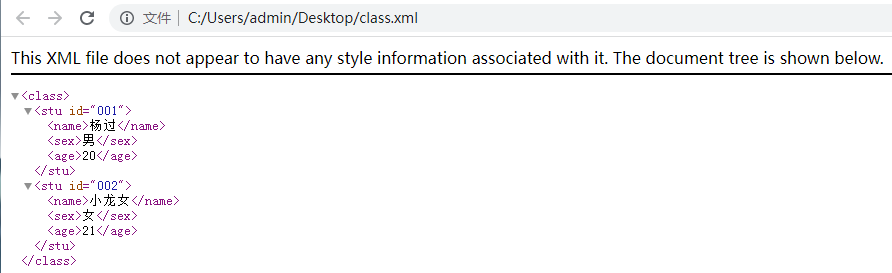
注意:在这个例子中,第一行的编码需要和浏览器的默认字符集charset保持一致,否则会报错
3、XML语法
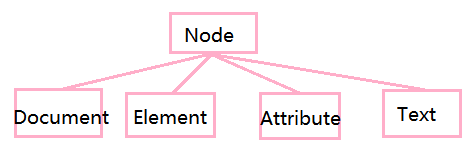
节点是文档、元素、属性、文本的统称
XML 组成部分:
- 文档:
Document
就是指一个XML文件 - 元素:
Element
在XML中使用<>括起来的就是一个个元素,比如class、stu、age
class:根元素,一个XML文档只有一个根元素 - 属性:
Attribute,简写Attr
在元素内,格式为xx=yy,xx属性名称,yy属性值,比如id=“002” - 文本:
Text
字符串内容,元素之间的内容就是文本,比如女,21
3.1、文档声明
XML声明放在XML文档的第一行
<?xml version="1.0" encoding="utf-8" standalone="yes" ?>
- 1
由以下部分组成:
version:文档符合XML1.0规范,我们学习1.0encoding:文档字符编码,比如”GB2312”或者”UTF-8”standalone:文档定义是否独立使用,yes表示不可包含其他文档- standalone=”no”为默认值。yes代表是独立使用,而no代表不是独立使用
3.2、元素(或者叫标记、节点)
3.2.1、每个XML文档必须有且只有一个根元素
在 XML 文档中,有且只有一个根标签
- 根元素是一个完全包括文档中其他所有元素的元素
- 根元素的起始标记要放在所有其他元素的起始标记之前
- 根元素的结束标记要放在所有其他元素的结束标记之后
3.2.2、XML元素指的是XML文件中出现的标签,一个标签分为开始标签和结束标签
标签有内容需成对出现,开始标签<xx>,结束标签</xx>
<a>www.sohu.com</a>
- 1
标签如果没有内容可以使用单标签<xx/>
<a></a>
简写为:<a/>
- 1
- 2
在 XML 文档中,允许标签嵌套,但不允许交叉嵌套
以下情况报错:
<a>welcome<b>
www.sohu.com</a></b>
- 1
- 2
- 3
3.2.3、对于XML标签中出现的所有空格和换行,XML解析程序都会当做标签内容进行处理
例如下面两段内容的意义是不一样的
<stu>xiaoming</stu>
- 1
<stu>
xiaoming
</stu>
- 1
- 2
- 3
由于在XML中,空格和换行都作为原始内容被处理,所以,在编写XML文件时,要特别注意
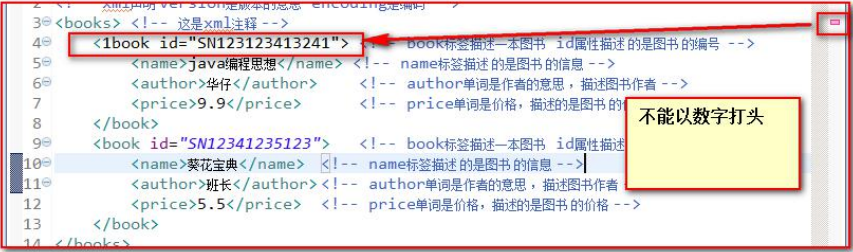
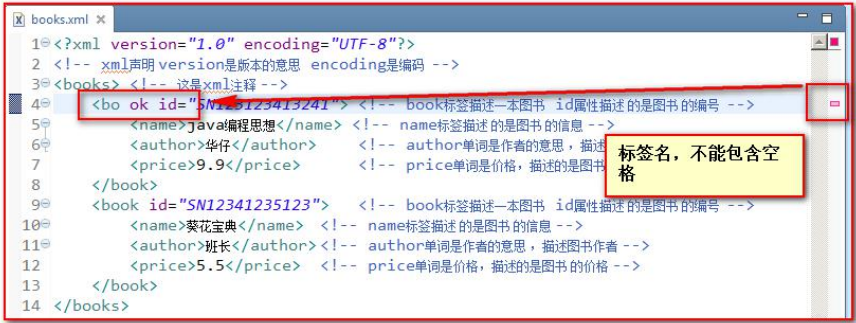
3.2.4、命名规范
一个XML元素可以包含字母、数字以及其它一些可见字符,但必须遵守以下规范:
- 区分大小写,例如,元素P和元素p是两个不同的元素
- 不能以数字或下划线”_”开头
- 元素内不能包含空格
- 名称中间不能包含冒号(:)
- 可以使用中文,但一般不这么用
- 属性必须使用引号引起来,不引会报错
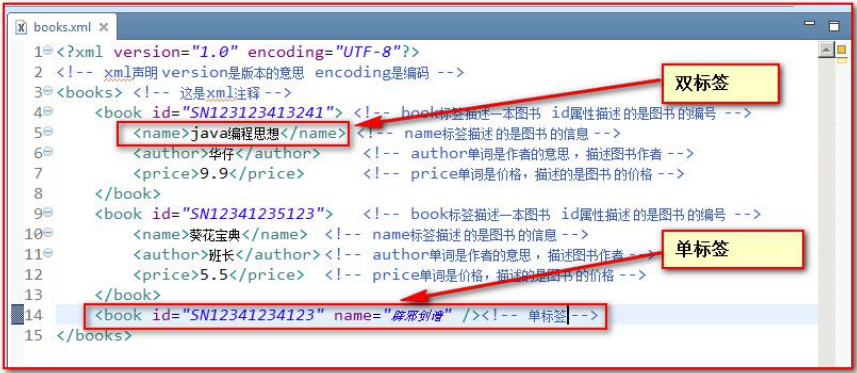
3.3、属性
<student id="100">
<name>Tom</name>
</student>
- 1
- 2
- 3
- 属性值用双引号(”)或单引号(’)分隔,如果属性值中有单引号,则用双引号分隔;如果有双引号,则用单引号分隔。

- 如果属性值中既有单引号还有双引号怎么办?这种要使用实体(转义字符,类似于html中的空格符),XML有5个预定义的实体字符,如下
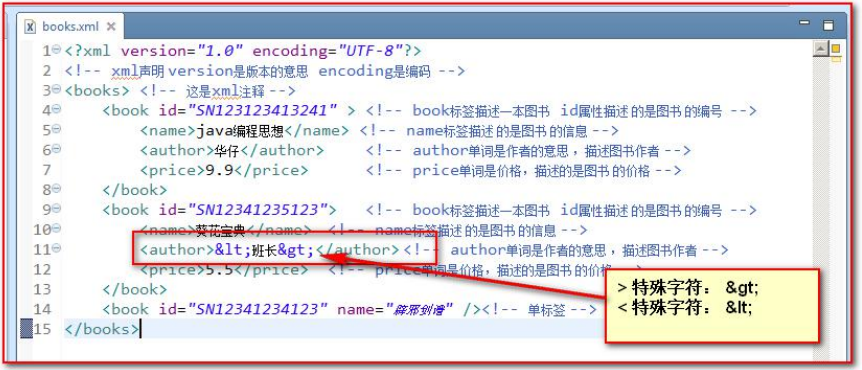
< | < |
|---|---|
> | > |
& | & |
' | ’ |
" | " |
-
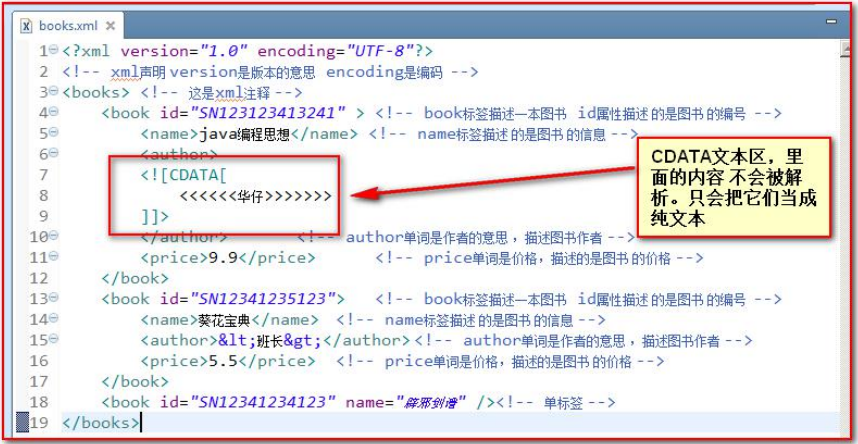
当需要转义的字符过多时候,比如需要输入大量的尖括号作为没有意义的文本,可以使用文本区域(CDATA 区)
CDATA 语法可以告诉 xml 解析器,我 CDATA 里的文本内容,只是纯文本,不需要 xml 语法解析
格式:<![CDATA[ 这里可以把你输入的字符原样显示,不会解析 xml ]]>
-
一个元素可以有多个属性,它的基本格式为
<元素名 属性名1="属性值1" 属性名2="属性值2">
- 1
- 特定的属性名称在同一个元素标记中只能出现一次
- 属性值不能包括<,>,&,如果一定要包含,也要使用实体
3.4、注释
XML的注释类似于HTML中的注释:
<!--这是一个注释-->
- 1
需要注意以下事项:
- 注释内容不要出现–
- 不要把注释放在标记中间;
- 注释不能嵌套
- 可以在除标记以外的任何地方放注释
4、 DOM解析
一般自动完成,不是重点,理解即可
4.1、XML结构分析
普通xml结构图:

通过 xml 层次结构整理如下图: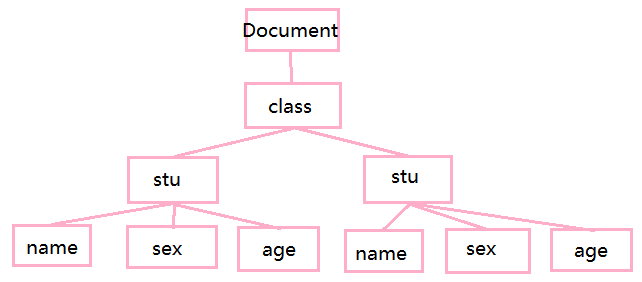
XML 的各个组成部分都需要使用一个类型来描述:
- XML文件:吧XML文档加载到内存中,使用Document对象来描述这个文档
- 标签 / 元素:所有的标签,使用Element 对象来描述
- 属性:标签的属性,使用Attribute来描述
- 文本:文本内容(文本、空格、回车),使用Text来描述
根据上面四种成员的共性,继续抽象出父类(接口):org.w3c.dom.Node
所以,在XML中,一切皆节点
而这种吧 XML 文档加载到内存之后,形成一个一个的对象,这种操作我们称为 DOM 解析
4.2、DOM简介
DOM :Document Object Model 文档对象模型思想,把文档中的成员描述成一个个对象
使用场景:
使用 js 来解析 HTML 中的数据
特点:
在加载的时候,一次性把整个 XML 文档加载进内存,在内存中形成一棵树 DOM 树(Document 对象)
我们以后使用代码操作 Document ,其实操作的是内存中的 DOM 树,和本地磁盘中的 XML 文件没有直接关系
比如:保存了一个联系人,仅仅是内存中多了一个联系人,但是在 XML 文件中没有新增的痕迹,除非做 同步操作,即把内存中的数据更新到XML文件中
(增删改操作之后,都要做同步操作)
缺点:
若 XML 文件过大,可能造成内存溢出
操作 XML 的增删改查(CRUD)的时候很简单,但是性能比较低下
5、Document 获取
XML 被程序读到内存中会形成一个 Document 对象,所以要解析 XML ,首先要先获取到 Document 对象
获取 Document 对象的步骤:
- 声明 XML 文件,File文件
File file = new File(path);
- 1
- 通过
DocumentBuilderFactory的newInstance方法获取自身对象
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
- 1
- 通过
DocumentBuilderFactory对象去获取DocumentBuilder对象
DocumentBuilder db = dbf.newDocumentBuilder();
- 1
- 通过
DocumentBuilder对象去解析获取Document对象
Document d = db.parse(file);
- 1
步骤流程图以及获取 Document 对象方法选用如下:
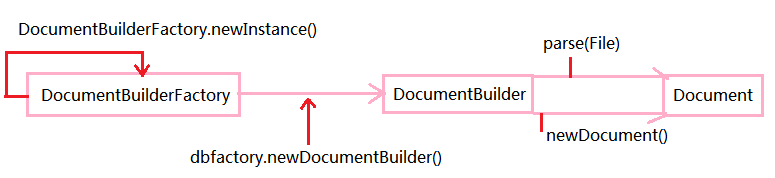
思路如下:
当需要获取Document对象,但是Document是一个接口,API里面没有合适的实现类,也没有提供方法,就看父类,父类也没有提供获取的方法,可以找有没有工厂类
该例中,有DocumentBuilder,API中已说明可以获取DOM文档实例,同时DocumentBuilder的实例可以从DocumentBuilderFactory.newDocumentBuilder()获取
而对于DocumentBuilderFactory,自己有提供方法newInstance()来获取自身的对象
什么时候用 parse(File) ,什么时候用 newDocument() ?
- newDocument():当没有 xml 文件的时候,直接在内存中去创建 DOM 树(Document 对象)
- parse(File):当存在 xml 文件的时候,使用该方法去解析 xml 文件到内存中,形成 DOM 树(Document 对象)
6、获取某个联系人姓名
需求: 获取第二个联系人的名字
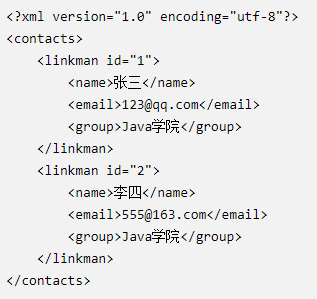
①步骤:
- 获取Document 对象
- 获取根节点 / 根标签 contacts
- 获取第二个 linkman 节点 / 标签
- 获取名字 name 节点
- 获取名字节点的文本内容
②常用API:
-
Document 对象
Element getDocumentElement ():获取根节点 -
Element 对象
NodeList getElementsByTagName(String name):获取指定名称的子元素,返回NodeList
getAttribute(String name):获取元素中的属性值 -
Node对象
String getTxetContent():获取节点的文本内容
void setTextContent(String content):设置节点的文本内容
④代码实现:
//需求: 获取第二个联系人的名字 @Test public void testGet(){ File file = new File("E:\\workspace\\atguigu\\resource\\contacts.xml"); //1、获取Document对象 DocumentBuilderFactory dbfactory = DocumentBuilderFactory.newInstance(); DocumentBuilder db = DocumentBuilderFactory.newDocumentBuilder(); org.w3c.dom.Document doc = db.parse(file); //2、获取根元素 Element root = doc.getDocumentElement(); //3、获取第二个linkman元素 NodeList list = root.getElementsByTagName("linkman"); //返回指定名称linkman的子元素集合 Element linkman = (Element)list.item(1); //返回集合中的第二个元素 //4、获取linkman元素中的name元素 Element name = (Element)linkman.getElementsByTagName("name").item(0); //5、获取name元素中的文本内容 String s = name.getTxetContent(); System.out.println(s); //获取第二个linkman中的id属性 System.out.println(linkman.getAttribute("id")); }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
6.1、获取所有标签中的内容
需要分四步操作:
-
第一步,通过创建 SAXReader 对象。来读取 xml 文件,获取 Document 对象(需要导入dom4j的jar包作为library)
里面有 index.html 是介绍使用的说明书
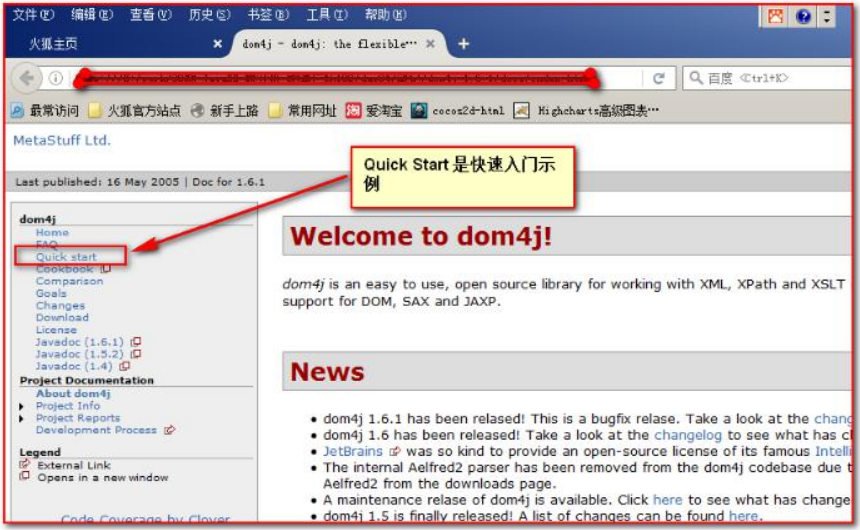
-
第二步,通过 Document 对象。拿到 XML 的根元素对象
-
第三步,通过根元素对象。获取所有的 book 标签对象
-
第四步,遍历每个 book 标签对象。然后获取到 book 标签对象内的每一个元素,再通过 getText() 方法拿到起始标签和结 束标签之间的文本内容

代码:
@Test public void readXML() throws DocumentException { //1、通过创建 SAXReader 对象。来读取 xml 文件,获取 Document 对象 //在单元测试中,相对路径是从模块开始的 SAXReader reader = new SAXReader(); Document document = reader.read("src/books.xml"); //2、通过 Document 对象。拿到 XML 的根元素对象 Element root = document.getRootElement(); //3、通过根元素对象。获取所有的 book 标签对象 //Element.elements(标签名)返回当前元素下的指定的子元素的集合,返回List //Element.element(标签名)返回当前元素下指定的子元素,返回Element List<Element> books = root.elements("book"); //4、遍历每个 book 标签对象。然后获取到 book 标签对象内的每一个元素 //Element.asXML()将当前元素对象转换成为 String,输出也是尖括号的样式 for (Element book : books) { //在这里可以打印出结果 // System.out.println(book.asXML()); Element nameElement = book.element("name"); // getText() 返回起始标签和结束标签之间的文本内容 String nameText = nameElement.getText(); // elementText() 直接获取指定标签名内的文本内容 String priceText = book.elementText("price"); String authorText = book.elementText("author"); // attributeValue() 获取指定属性名的属性值 String snText = book.attributeValue("sn"); //可以将内容封装进定义好的类中 System.out.println(new Book(snText ,nameText ,priceText ,authorText)) } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
7、插入一个联系人信息
需求: 增加一个联系人信息
①步骤:
- 获取Document 对象
- 获取根元素
- 创建一个 linkman 节点 / 标签
- 创建 name、email、group 子元素
- 给 name、email、group 子元素添加文本内容
- 将 name、email、group 子元素设置为 linkman 节点的子元素(建立父子联系)
- 将 linkman 子元素设置为根元素的子元素(建立父子联系)
- 同步操作(将代码同步到文件)
②常用API:
-
Document 对象
Element getDocumentElement():获取根节点
Element createElement(String name)):创建指定名字的元素 / 节点 -
Element 对象
NodeList getElementsByTagName(String name):通过标签名获取标签列表 -
Node对象
String getTxetContent():获取节点的文本内容
void setTextContent(String content):设置节点的文本内容
父元素.appendChild(子元素):添加父子关系 -
Transformer :同步转换器
void transform(Source xmlSource, Result outputTarget):同步操作
transform(内存中的doc, 磁盘中的XML)
Source : 源是内存中的 Document ,所以使用 DOMSource(Node doc)实现类
还有一个实现类StreamSource()
Result : 内存写到磁盘中,使用流操作文件,所以使用StreamResult(File file)实现类
还有一个实现类DOMResult()
③注意:
XML 加载到内存之后,使用一个 Document 对象来描述 XML 的结构,之后操作都是在操作内存中的 Java 对象文艺,跟磁盘中的文件没有关系,要想形成控制台与文件的同步变化,就需要进行同步操作,操作之后,才可以保证内存中的数据与磁盘中的数据一致
④代码实现:
//需求:增加一个联系人信息 @Test public void testGet(){ File file = new File("E:\\workspace\\atguigu\\resource\\contacts.xml"); //1、获取Document对象 org.w3c.dom.Document doc = DocumentBuilderFactory.newInstance().newDocumentBuilder().parse(file); //2、获取根元素对象 Element root = doc.getDocumentElement(); //3、创建linkman的XML片段 //Ctrl+D 向下复制一行 Element linkman = doc.createElement("linkman"); Element name = doc.createElement("name"); Element email = doc.createElement("email"); Element group = doc.createElement("group"); //4、设置属性 linkman.setAttribute("id", "3"); //5、设置文本内容 name.setTextContent("李五"); email.setTextContent("999@126.com"); group.setTextContent("Java学院"); //6、建立name、email、group子元素与linkman的父子联系,linkman与根元素对象的父子联系 linkman.appendChild(name); linkman.appendChild(email); linkman.appendChild(group); root.appendChild(linkman); //7、同步操作,将内存的数据同步到磁盘中XML文件 Transformer transformer = TransformerFactory.newInstance().newTransformer(); Source source = DOMSource(doc); //内存中的Document对象 Result result = StreamResult(file); //磁盘中的文件 transformer.transform(source, result) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
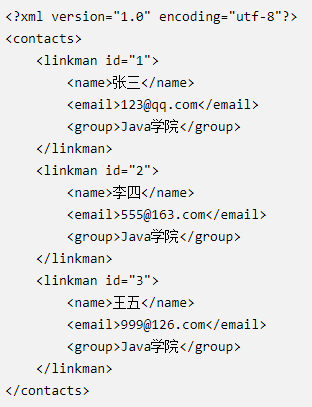
8、小结
- 获取Document对象
org.w3c.dom.Document doc = DocumentBuilderFactory.newInstance().newDocumentBuilder().parse(file); - 获取Document对象的根节点
doc.getDocumentElement(); - 获取某个元素的子元素
NodeList getElementsByTagName(String name):获取指定名称的子元素,返回NodeList - 获取元素的属性值
getAttribute(String name):获取元素中的属性值,name为属性名 - 获取节点的文本内容
getTxetContent():获取节点的文本内容 - 设置节点的文本内容
void setTextContent(String content):设置节点的文本内容 - 添加元素的父子关系
父元素.appendChild(子元素):添加父子关系 - 同步操作
void transform(Source xmlSource, Result outputTarget):同步操作 - 如果是内存中Document对象同步到磁盘中的文件中
DOMSource(Node document)、StreamResult(File file)

