- 1postgresql批量插入数据脚本_postgresql优化数据的批量插入
- 2gcc环境变量_gcc 环境变量
- 3HarmonyOS page生命周期函数讲解_鸿蒙page生命周期
- 4Android Studio 打包 Maker MV apk 详细步骤
- 5SwiftUI如何修改页面状态?@state的使用_swiftui @state
- 6【Linux】文件缓冲区|理解文件系统
- 7centos7 openssh升级9.7p1 简单详细教程(傻瓜教学方式)
- 8如何自己开发一个小程序?_如何自己开发小程序
- 9docker部署jaeger+es+kibana链路追踪_docker jaeger
- 10【C++软件开发】面试经典题型汇总_c++客户端开发面经
目标检测与跟踪 (1)- 机器人视觉与YOLO V8_yolov8的研究意义
赞
踩
目录
1、研究背景
机器人视觉识别技术是移动机器人平台十分关键的技术,代表着机器人智能化、自动化及先进性的条件判定标准。 如何在最短时间内最精确地识别检测到出现在深度相机视野范围内的目标,将检测到的三维点云数据提取出来是机器人后续抓取三维物体的基础,并且无论对于工业用还是服务业都有着巨大的意义与研究价值。基于机器视觉的三维物体目标的识别、检测与定位技术已经成功应用于众多工业领域中。
配合着机械臂平台,以其为基础的操作系统可以完成一系列繁重复杂的工作,大大解放了人类的双手,提高了工业生产效率。作为促成这一切成果基础的机器人视觉识别技术正在逐步建立、稳定发展并一步步走向成熟。
近年来,随着机器人相关技术的快速发展,其依靠的平台也快速的更新换代。 之前价格较为昂贵的3D工业相机、3D图像传感器、3D扫描仪渐渐得到普及,传感器的微型化、智能化、低功耗以及高效率带来的深度图像设备价格大幅下降,随之机器人视觉识别技术也越发深入且成熟。
三维物体目标检测和识别、6D位姿估计、机械臂运动规划控制、移动平台的线路规划与基于即时定位与地图构建SLAM(Simultaneous Localization And Mapping)的精确导航、三维物体检测抓取是移动机器人平台的核心关键技术,其精度直接影响着最后整个移动机器人控制系统的抓取成功率以及任务的完成度。
3D物体实时检测、三维目标识别、6D位姿估计一直是机器人视觉领域的核心研究课题,最新的研究成果也广泛应用于工业信息化领域的方方面面。通过众多的传感器,例如激光扫描仪、深度摄像头、双目视觉传感即可获得三维物体的识别数据,以此为基础开展研究的计算机视觉方向领域也有着较为深入的发展。


2. 算法原理及对比
刚体的6D位姿估计按照使用的输入数据,可以分为基于2D图像的方法和基于3D点云的方法。早期基于2D图像的6D位姿估计方法处理的是纹理丰富的物体,通过提取显著性特征点,构建表征性强的描述符获得匹配点对,使用PnP方法恢复物体的6D位姿。对于弱纹理或者无纹理物体,可以使用基于模板的方法,检索得到最相似的模板图像对应的6D位姿,也可以通过基于机器学习的投票的方法,学习得到最优的位姿。
随着2011年以kinect为代表的的廉价深度传感器的出现,在获取RGB图像的同时可以获得2.5D的Depth图像,进而可以辅助基于2D图像的方法。为了不受纹理影响,也可以只在3D空间操作,此时问题变成获取的单视角点云到已有完整物体点云的part-to-whole配准问题。如果物体几何细节丰富,可以提取显著性3D特征点,构建表征性强的描述符获得3D匹配点,使用最小二乘获得初始位姿;也可以使用随机采样点一致算法(Ransac)获得大量候选6D位姿,选择误差最小的位姿。
自2012年始,深度学习在2D视觉领域一骑绝尘,很自然的会将深度学习引入到物体6D位姿估计,而且是全方位的,无论是基于纯RGB图像、RGB和Depth图像、还是只基于3D点云,无论是寻找对应、寻找模板匹配、亦或是进行投票,都展现了极好的性能。
随着在实例级物体上的6D位姿估计趋于成熟,开始涌现了类别级物体6D位姿估计的方法,只要处理的物体在纹理和几何结构上近似,就可以学习到针对这一类物体的6D位姿估计方法,这将极大提升这项技术在机器人抓取或者AR领域的实用性。
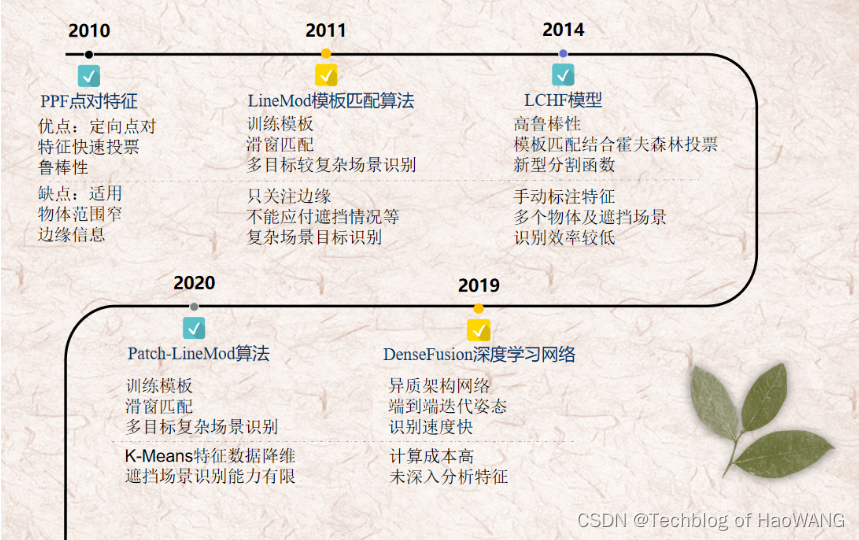
本文分别介绍基于2D图像和基于3D点云的,基于对应(Correspondence-based)、模板(Template-based)和投票(Voting-based method)的物体6D位姿估计方法,综合如下表。


2.1 点对特征(Point Pairs)
2010年Bertram Drost等人提出了基于Point Pair 特征的PPF(PointPairFeature)算法。PPF算法使用物体的全局模型描述,基于定向点对特征,通过快速投票方案在本地匹配全局模型实现物体三维到二维搜索空间上的对应匹配识别,适用于快速监测点云较为稀疏或者缺乏表面纹理信息及局部曲率变化极小的物体。
PPF算法在有噪声、部分遮挡情况下有较好的识别能力,然而其不能解决具有相似噪声背景下物体识别问题,而且并没有很好的利用物体的边缘信息。
2.2 模板匹配
2011年Stefan Hinterstoisser等人提出针对3D刚性物体的实时检测与定位算法LineMod算法。其基本原理是通过提取物体各个方向的深度图像采集模型,采用彩色图像的梯度信息结合物体表面的法向特征作为模板匹配的依据,训练其方向梯度生成物体模板后与实际图像的各对应方向位置匹配推测匹配结果。
最后利用ICP算法对检测结果进行位姿修正完成3D刚性物体的位置检测判断。虽然LineMod利用了物体的多种特征,很好的解决了多种类目标在简单场景下的物体识别,然而其在模板分类时只关注物体的边缘,导致其在稍复杂实时模板匹配时识别率大幅度下降。
2018年Tomas Hodan使用现有的数据集提出BOP算法,建立了新的模板分类基准。
然而其只能识别单个场景下多类物体的识别,遇到同类物体较多以及重叠场景算法识别能力迅速下降。
2.3 霍夫森林
2009年Juergen Gall等人提出了基于霍夫森林的目标检测算法,通过构建一个随机森林(random forest)从图像上提取图像块,在构建的随机森林中的每个决策树上进行判断处理并在霍夫空间中进行投票,图像密集块采样后输出霍夫图像完成对目标重心位置的投票。
当然在该算法提出后基于Hough Forest算法的目标检测也有着深入的发展。
2.4 深度学习
2017年Wadim Kehl等人提出了基于SSD算法的三维物体6D位姿估计,通过将2D图像深度学习的思路与三维物体RGBD图像的特点,利用深度学习网络完成局部图像2D检测、特征图与预训练核卷积,并使用投影属性来解析深度网络推断的试点及平面内旋转分数以此构建6D位姿假设。
【REF】:https://arxiv.org/abs/1905.06658
刚体6D位姿估计方法综述_Guoguang Du的博客-CSDN博客
参考文献
2012-Model based training, detection and pose estimation of texture-less 3d objects in heavily cluttered scenes
2012-3d object detection and localization using multimodal point pair features
2014-Learning 6d object pose estimation using 3d object coordinate
2014-Latent-class hough forests for 3d object detection and pose estimation
2014-Super 4PCS: Fast Global Pointcloud Registration via Smart Indexing
2015-Detection and fine 3d pose estimation of texture-less objects in rgb-d images
2015-Go-icp: A globally optimal solution to 3d icp point-set registration
2015-The YCB object and model set: Towards common benchmarks for manipulation research
2017-Bb8: a scalable, accurate, robust to partial occlusion method for predicting the 3d poses of challenging objects without using depth
2017-Posecnn: A convolutional neural network for 6d object pose estimation in cluttered scenes
2017-Ssd-6d: Making rgb-based 3d detection and 6d pose estimation great again
2018-6d pose estimation using an improved method based on point pair features
2018-Deep-6dpose: recovering 6d object pose fromasinglergbimage
2018-Implicit 3d orientation learning for 6d object detection from rgb images
2018-Label Fusion: A Pipeline for Generating Ground Truth Labels for Real RGBD Data of Cluttered Scenes
2018-Learning to predict dense correspondences for 6d pose estimation
2018-PVNet Pixel-wise Voting Network for 6DoF Pose Estimation
2018-Real-time seamless single shot 6d object pose prediction
2018-Robust 3d object tracking from monocular images using stable parts
2018-Segmentation-driven 6d object pose estimation
2019-6-pack: Category-level 6d pose tracker with anchor-based keypoints
2019-Cdpn: Coordinates-based disentangled pose network for realtime rgb-based 6-dof object pose estimation
2019-Deep closest point: Learning representations for point cloud registration
2019-Densefusion: 6d object pose estimation by iterative dense fusion
2019-Dpod: 6d pose object detector and refiner
2019-Latentfusion: End-to-end differentiable reconstruction and rendering for unseen object pose estimation
2019-Normalized object coordinate space for category-level 6d object pose and size estimation
2019-One framework to register them all: Pointnet encoding for point cloud alignment
2019-Pcrnet: Point cloud registration network using pointnet encoding
2019-Pointnetlk: Robust & efficient point cloud registration using pointnet
2019-PVN3D: A Deep Point-wise 3D Keypoints Voting Network for 6DoF Pose Estimation
2019-Recovering 6d object pose from rgb indoor image based on two-stage detection network with multi-task loss
2019-Single-stage 6d object pose estimation
2020-6d object pose regression via supervised learning on point clouds
2020-6dof object pose estimation via differentiable proxy voting loss
2020-Learning canonical shape space for category-level 6d object pose and size estimation
2020-Lrf-net: Learning local reference frames for 3d local shape description and matching
2020-Robust 6d object pose estimation by learning rgb-d features
2020-Teaser: Fast and certifiable point cloud registration
2020-Yoloff: You only learn offsets for robust 6dof object pose estimation
3、YOLO家族模型演变
在YOLO出现之前,检测图像中对象的主要方法是使用不同大小的滑动窗口依次通过原始图像的各个部分,以便分类器显示图像的哪个部分包含哪个对象。这种方法是合乎逻辑的,但非常迟缓。经过了一段时间的发展,一个特殊的模型出现了:它可以检测目标物ROI,速度最快的算法Faster R-CNN平均在0.2秒内处理一张图片,也就是每秒5帧。
在以前的方法中,原始图像的每个像素都需要被神经网络处理几百次甚至几千次。每次这些像素都通过同一个神经网络进行相同的计算。有没有可能做些什么来避免重复同样的计算?
 https://developer.aliyun.com/article/1139751
https://developer.aliyun.com/article/1139751
4、YOLO V8
YOLOv8 是 ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本,目前支持图像分类、物体检测和实例分割任务。
YOLOv8 是一个 SOTA 模型,它建立在以前 YOLO 版本的成功基础上,并引入了新的功能和改进,以进一步提升性能和灵活性。具体创新包括一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,可以在从 CPU 到 GPU 的各种硬件平台上运行。
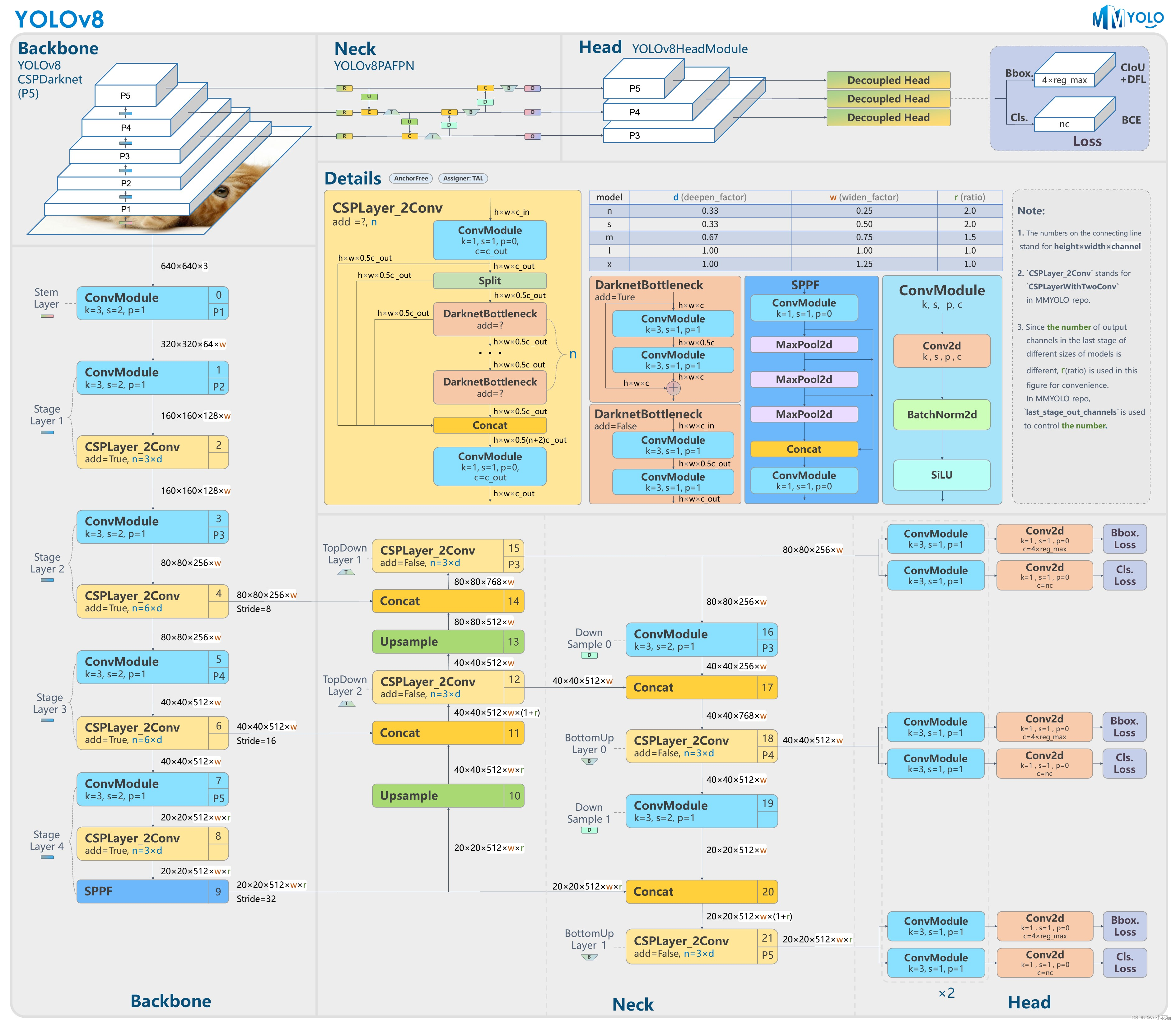
YOLOV8是YOLO系列另一个SOTA模型,该模型是相对于YOLOV5进行更新的。其主要结构如下图所示:
从图中可以看出,网络还是分为三个部分: 主干网络(backbone),特征增强网络(neck),检测头(head) 三个部分。
主干网络: 依然使用CSP的思想,改进之处主要有:1、YOLOV5中的C3模块被替换成了C2f模块;其余大体和YOLOV5的主干网络一致。
特征增强网络: YOLOv8使用PA-FPN的思想,具体实施过程中将YOLOV5中的PA-FPN上采样阶段的卷积去除了,并且将其中的C3模块替换为了C2f模块。
检测头:区别于YOLOV5的耦合头,YOLOV8使用了Decoupled-Head其它更新部分:
1、摒弃了之前anchor-based的方案,拥抱anchor-free思想。
2、损失函数方面,分类使用BCEloss,回归使用DFL Loss+CIOU Loss
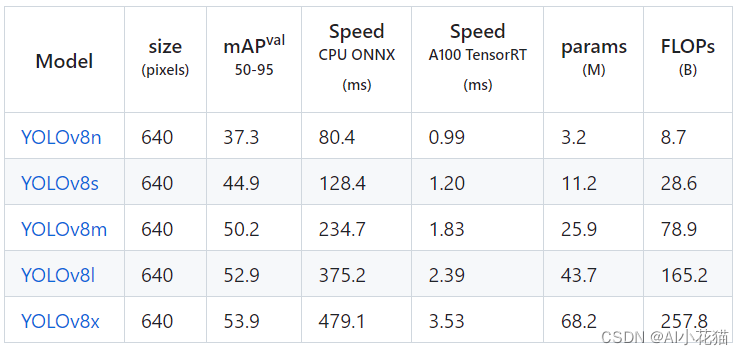
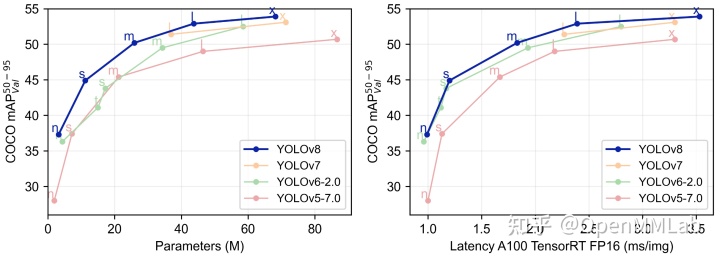
3、标签分配上Task-Aligned Assigner匹配方式YOLOV8在COCO数据集上的检测结果也是比较惊艳:
YOLOv5 原理和实现全解析
YOLOv6 原理和实现全解析
RTMDet 原理和实现全解析