
- 1基于单片机的塑料厂房气体检测系统设计
- 2【Greenhills】MULTI IDE加密狗无法识别
- 3电脑软件可以上网,但是浏览器网页打不开显示代理服务器配置出错_电脑浏览器访问不了网页,提示代理设置
- 4进程间通信(管道篇)(linux C语言)_c语言管道关闭端口
- 5新能源风电数据集_风电公开数据集
- 6STM32 位带操作 Bit-band operation详解_arm的bitband
- 7Android 编译过程介绍,Android.mk 和 Android.bp 分析, 在源码中编译 AndroidStudio 构建的 App_.mk编译目录所有.bp
- 8Android GPU Inspector
- 9在web实时展示监控视频,使用什么方案好
- 10微信公众号接入讯飞星火大模型_讯飞星火接入公众号
ChatGLM2部署实战体验
赞
踩
ChatGPT在自然语言处理领域的表现让人振奋,开启了大模型在通用人工智能领域的大门。
许多工作随之跟进,并开源,凭借相对小的参数量达到近似GPT的效果,包括LLama,alpace等。
然而,这些模型大都对中文的支持能力相当有限,国内清华大学针对这个问题,扩充中文token,采用自建的中文语料库进行训练,生成ChatGLM2模型,较上一代ChatGLM1性能有了显著提升,在答复内容的可靠性和推理速度上都有了较大提升,目前的测试结果显示,ChatGLM2模型在中文的表现上优于Chatgpt。
项目网址:GitHub - THUDM/ChatGLM2-部署实战6B: ChatGLM2-6B: An Open Bilingual Chat LLM | 开源双语对话语言模型
系统ubuntu18.04LTS
九天毕昇云服务8核CPU的RAM32G
内核:Linux dl-2307071824141la-pod-jupyter-5c6ccb995c-sfk68 4.19.90-2107.6.0.0100.oe1.bclinux.x86_64 #1 SMP Wed Dec 1 19:59:44 CST 2021 x86_64 x86_64 x86_64 GNU/Linux
2023年7月
下载:
github上分享的源码
GitHub - THUDM/ChatGLM2-6B: ChatGLM2-6B: An Open Bilingual Chat LLM | 开源双语对话语言模型
模型文件
THUDM/chatglm2-6b at main 6b-FP16
THUDM/chatglm2-6b-int4 at main 6b-int4

一、搭建环境
conda create -n ChatGLM2 python=3.10.10 -y参数:-n 后面ChatGLM2为创建的虚拟环境名称,python=之后输入自己想要的python版本,-y表示后面的请求全部为yes,这样就不用自己每次手动输入yes了。
安装完虚拟环境后,我们需要进入虚拟环境。
conda activate ChatGLM2创建ChatGLM2项目的虚拟环境
python -m venv venv
 激激活虚拟环境venv
激激活虚拟环境venv
source ./venv/bin/activate![]()
Linux系统使用source ./venv/bin/activate命令即可,
Windows则直接双击./venv/Scripts/activate.bat或者运行./venv/Scripts/activate命令、
ChatGLM2-6B安装详解(Windows/Linux)及遇到的问题解决办法_星辰同学wwq的博客-CSDN博客
二、安装软件包
- cd ChatGLM2-6B-main
- pip install -r requirements.txt -i https://pypi.douban.com/simple
进入下载好的源码目录ChatGLM2-6B-main,执行requirements.txt安装依赖包,
参数:-r 是read的意思,可以把要安装的文件统一写在一个txt中,批量下载
参数:-i 后面是下载的网址,这里使用的是豆瓣源,下载安装大概十几分钟

requirements.txt内容,我是新建requirements.txt,复制粘过去,再执行的文件
- protobuf
- transformers==4.30.2
- cpm_kernels
- torch>=2.0
- gradio
- mdtex2html
- sentencepiece
- accelerate
- sse-starlette
安装完成后,查看安装的包和版本
pip list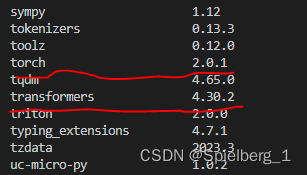
官方建议:transformers 库版本推荐为 4.30.2,torch 推荐使用 2.0 及以上的版本,以获得最佳的推理性能
三、修改启动文件
进入ChatGLM2-6B-main目录,包含下列文件
- cd ChatGLM2-6B-main
- ls

修改cli_demo.py文件
- tokenizer = AutoTokenizer.from_pretrained("/root/chatglm2-6b", trust_remote_code=True)
- model = AutoModel.from_pretrained("/root/chatglm2-6b", trust_remote_code=True).float()
参数:/root/chatglm2-6b修改为ChatGLM2-6b模型路径,注意包含tokenizer.model文件。
参数:model = AutoModel.from_pretrained("/root/chatglm2-6b", trust_remote_code=True).float()
在 CPU 上进行推理,需要大概 32GB 内存
model = AutoModel.from_pretrained("/root/chatglm2-6b", trust_remote_code=True, device='cuda'),在 GPU 上进行推理,需要大概 13GB 显存
如果你的 GPU 显存有限,可以尝试以量化方式加载模型,使用方法如下:
# 按需修改,目前只支持 4/8 bit 量化
model = AutoModel.from_pretrained("/root/chatglm2-6b", trust_remote_code=True).quantize(8).cuda()
模型量化会带来一定的性能损失,经过测试,ChatGLM2-6B 在 4-bit 量化下仍然能够进行自然流畅的生成。
如果你的内存不足,可以直接加载量化后的模型:
model = AutoModel.from_pretrained("/root/chatglm2-6b-int4",trust_remote_code=True).cuda()
cli_demo.py文件内容如下:
- import os
- import platform
- import signal
- from transformers import AutoTokenizer, AutoModel
- import readline
-
- tokenizer = AutoTokenizer.from_pretrained("/root/chatglm2-6b", trust_remote_code=True)
- model = AutoModel.from_pretrained("/root/chatglm2-6b", trust_remote_code=True).float()
- # 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量
- # from utils import load_model_on_gpus
- # model = load_model_on_gpus("THUDM/chatglm2-6b", num_gpus=2)
- model = model.eval()
-
- os_name = platform.system()
- clear_command = 'cls' if os_name == 'Windows' else 'clear'
- stop_stream = False
-
-
- def build_prompt(history):
- prompt = "欢迎使用 ChatGLM2-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序"
- for query, response in history:
- prompt += f"\n\n用户:{query}"
- prompt += f"\n\nChatGLM2-6B:{response}"
- return prompt
-
-
- def signal_handler(signal, frame):
- global stop_stream
- stop_stream = True
-
-
- def main():
- past_key_values, history = None, []
- global stop_stream
- print("欢迎使用 ChatGLM2-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序")
- while True:
- query = input("\n用户:")
- if query.strip() == "stop":
- break
- if query.strip() == "clear":
- past_key_values, history = None, []
- os.system(clear_command)
- print("欢迎使用 ChatGLM2-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序")
- continue
- print("\nChatGLM:", end="")
- current_length = 0
- for response, history, past_key_values in model.stream_chat(tokenizer, query, history=history,
- past_key_values=past_key_values,
- return_past_key_values=True):
- if stop_stream:
- stop_stream = False
- break
- else:
- print(response[current_length:], end="", flush=True)
- current_length = len(response)
- print("")
-
-
- if __name__ == "__main__":
- main()
四、测试推理
测试命令行,执行cli_demo.py文件
python cli_demo.py参数:python执行cli_demo.py文件,命令行输出,加载模型大概几分钟
(venv) (ChatGLM2) root@dl-2307071824141la-pod-jupyter-7d677494c4-7jz2f:~/ChatGLM2-6B-main# python cli_demo.py
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [02:33<00:00, 21.96s/it]
欢迎使用 ChatGLM2-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序
用户:你好
ChatGLM:你好
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

